

Há 30 anos, o Craigslist é um mercado de referência para todos os tipos de negócios. Apesar de seu design muito simples, típico dos anos 90, o Craigslist pode ser o melhor lugar do mundo para comprar negócios “à venda pelo proprietário”.
Hoje, vamos extrair dados de carros do Craigslist usandoum Scraper Python. Siga as instruções e você estará fazendo scraping no Craigslist como um profissional em pouco tempo. Procurando por escala? Confira nossa comparação das melhores ferramentas de scraping.
O que extrair do Craigslist
Vasculhando HTML: o caminho mais difícil
A habilidade mais importante no Scraping de dados é saber onde procurar. Poderíamos escrever um analisador supercomplicado que extraísse itens individuais do código HTML.
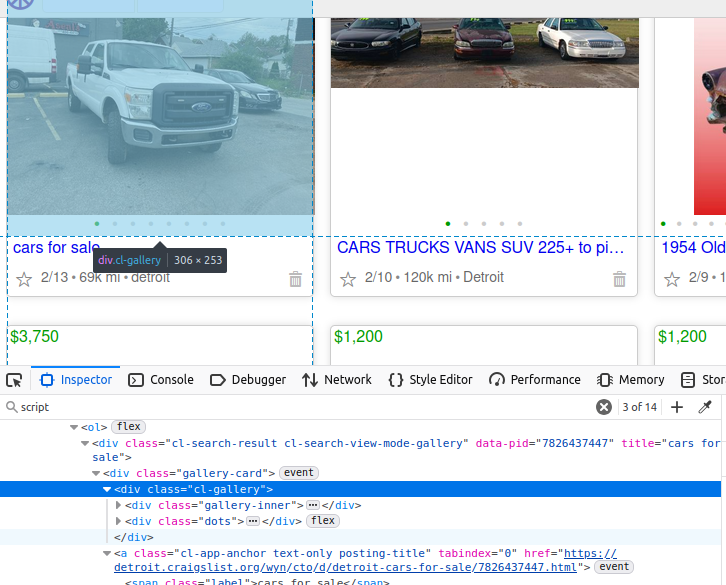
Se você observar o caminhão na imagem abaixo, seus dados estão aninhados dentro de um elemento div da classe cl-gallery. Se quisermos fazer as coisas da maneira mais difícil, podemos encontrar essa tag e, em seguida, realizar o Parsing dos elementos a partir daí.
Encontrando o JSON: economizando um tempo precioso
No entanto, há uma maneira melhor. Muitos sites, incluindo o Craigslist, usam dados JSON incorporados para construir a página inteira. Se você conseguir encontrar esse JSON, seu trabalho de Parsing será reduzido a quase zero.
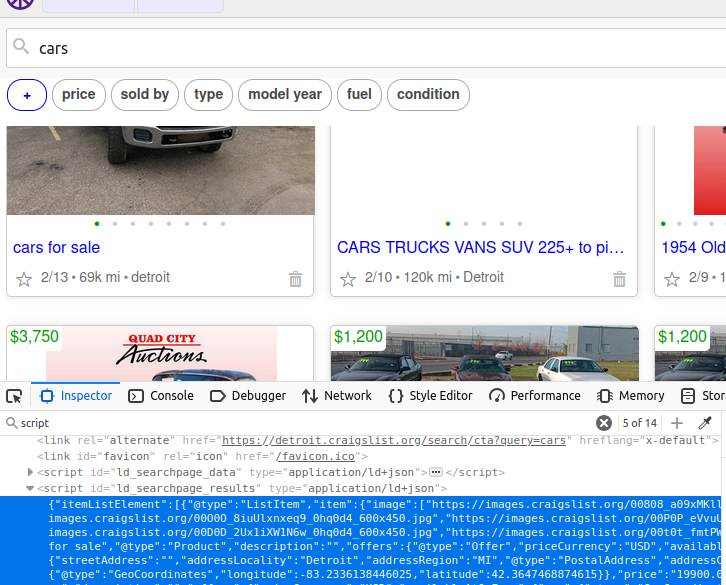
Em uma página do Craigslist, há um objeto de script que contém todos os dados que queremos. Se extrairmos esse único elemento, obteremos os dados de toda a página. Se você observar, seu id é ld_searchpage_results. Podemos localizar esse elemento com o seletor CSS: script[id='ld_searchpage_results'].
Raspando o Craigslist com Python
Agora que sabemos o que estamos tentando encontrar, fazer scraping do Craigslist será muito mais fácil. Nas próximas seções, examinaremos o código individual e, em seguida, reuniremos tudo em um Scraper funcional.
Parsing da página
def scrape_listings(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
success = False
while not success:
try:
response = requests.get(url)
#se recebermos um código de status inválido, lançaremos um erro
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']")
json_data = json.loads(embedded_json_string.text).get("itemListElement")
para dirty_item em json_data:
item = dirty_item.get("item")
ofertas = item.get("ofertas")
informações_de_localização = item.get("ofertas").get("disponívelEmOuA partirDe")
imagens = item.get("imagem")
imagem = Nenhuma
se len(imagens) > 0:
imagem = imagens[0]
item limpo = {
"nome": item.get("name"),
"imagem": imagem,
"preço": item.get("offers").get("price"),
"moeda": item.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
#concluímos todas as listagens, definimos success = True e interrompemos o loop
success = True
except Exception as e:
print(f"Falha ao extrair as listagens, {e} em {url}")
return scraped_data
- Primeiro, criamos nossas variáveis
url,scraped_dataesuccess.url: A url exata da pesquisa que queremos realizar.scraped_data: É aqui que colocamos todos os nossos resultados de pesquisa.success: Queremos que este Scraper seja persistente. Usado em combinação com um loopwhile, nosso Scraper não será encerrado até que o trabalho seja concluído e definamos success comoTrue.
- Em seguida, obtemos a página e lançamos um erro no caso de uma resposta inválida.
soup = BeautifulSoup(response.text, "html.parser")cria um objetoBeautifulSoupque podemos usar para analisar a página.- Encontramos nosso JSON incorporado com
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']"). - Em seguida, o convertemos em um
dicionáriocomjson.loads(). - Em seguida, iteramos por todos os itens e limpamos seus dados. O
clean_itemé anexado ao nossoscraped_data. - Por fim, definimos
successcomoTruee retornamos a matriz de listagens coletadas.
Armazenando nossos dados
Os dois métodos de armazenamento mais comuns no Scraping de dados são CSV e JSON. Vamos explicar como armazenar nossas listagens em ambos os formatos.
Salvando em um arquivo JSON
Este trecho básico contém nossa lógica de armazenamento JSON. Abrimos um arquivo e o passamos para json.dump() junto com nossos dados. Usamos indent=4 para tornar o arquivo JSON legível.
com open(f"{QUERY}-{LOCATION}.json", "w") como arquivo:
tente:
json.dump(listagens, arquivo, indent=4)
exceto Exception como e:
imprima(f"Falha ao salvar os resultados: {e}")
Salvando em um arquivo CSV
Salvar em CSV requer um pouco mais de trabalho. CSV não lida muito bem com matrizes. É por isso que extraímos apenas uma imagem ao limpar os dados.
Se não houver listagens, a função é encerrada. Se houver listagens, escrevemos os cabeçalhos CSV usando as chaves () do primeiro item da matriz. Em seguida, usamos csv.DictWriter() para escrever os cabeçalhos e as listagens.
def write_listings_to_csv(listings, filename):
if not listings:
print("Nenhuma listagem encontrada. Ignorando a gravação CSV.")
return
# Definir cabeçalhos de coluna CSV
fieldnames = listings[0].keys()
# Escrever dados em CSV
com open(filename, "w", newline="", encoding="utf-8") como csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(listings)
Juntando tudo
Agora, podemos juntar todas essas peças. Este código contém nosso Scraper totalmente funcional.
import requests
from bs4 import BeautifulSoup
import json
import csv
def write_listings_to_csv(listings, filename):
if not listings:
print("Nenhuma listagem encontrada. Ignorando a gravação do CSV.")
return
# Definir cabeçalhos de coluna CSV
fieldnames = listings[0].keys()
# Gravar dados em CSV
with open(filename, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(listings)
def scrape_listings(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
scraped_data = []
success = False
enquanto não for sucesso:
tente:
response = requests.get(url)
#se recebermos um código de status inválido, gerar um erro
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
embedded_json_string = soup.select_one("script[id='ld_searchpage_results']")
json_data = json.loads(embedded_json_string.text).get("itemListElement")
para dirty_item em json_data:
item = dirty_item.get("item")
offers = item.get("offers")
location_info = item.get("offers").get("availableAtOrFrom")
images = item.get("image")
image = None
se len(images) > 0:
imagem = imagens[0]
item limpo = {
"nome": item.get("name"),
"imagem": imagem,
"preço": item.get("offers").get("price"),
"moeda": item.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
#concluímos todas as listagens, definimos sucesso = Verdadeiro e interrompemos o loop
sucesso = Verdadeiro
exceto Exceção como e:
imprimir(f"Falha ao extrair as listagens, {e} em {url}")
retornar scraped_data
se __name__ == "__main__":
LOCATION = "detroit"
QUERY = "cars"
OUTPUT = "csv"
listings = scrape_listings(LOCATION, QUERY)
if OUTPUT == "json":
with open(f"{QUERY}-{LOCATION}.json", "w") as file:
try:
json.dump(listings, file, indent=4)
excepto Exception como e:
imprimir(f"Falha ao salvar os resultados: {e}")
elif OUTPUT == "csv":
tentar:
escrever_listings_para_csv(listings, f"{QUERY}-{LOCATION}.csv")
imprimir(f"Salvo {len(listagens)} listagens em {QUERY}-{LOCATION}.csv")
exceto Exceção como e:
imprimir(f"Falha ao gravar saída CSV: {e}")
else:
imprimir("Método de saída não suportado")
Dentro do bloco principal, você pode lidar com métodos de armazenamento com a variável OUTPUT. Se quiser armazenar em um arquivo JSON, defina-a como json. Se quiser um CSV, defina essa variável como csv. Na coleta de dados, você usará esses dois métodos de armazenamento o tempo todo.
Saída JSON
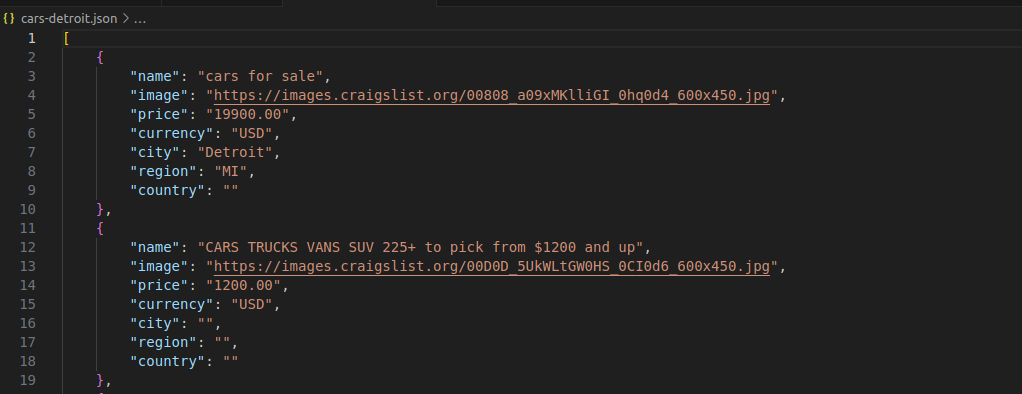
Como você pode ver na imagem abaixo, cada carro é representado por um objeto JSON legível com uma estrutura clara e organizada.
Saída CSV
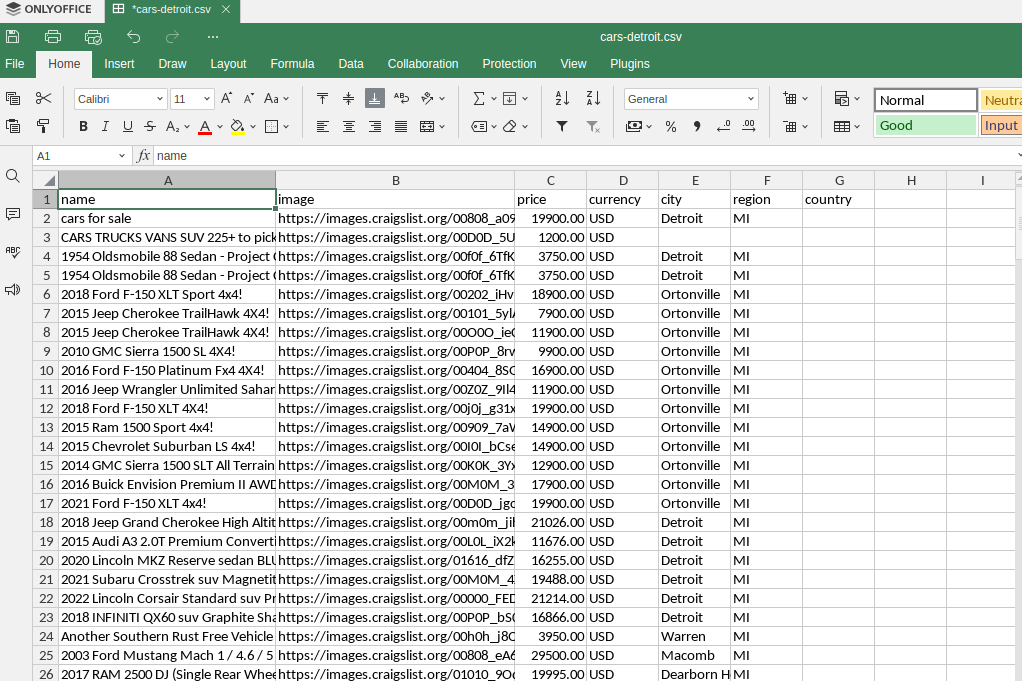
Nossa saída CSV é bastante semelhante. Obtemos uma planilha limpa contendo todas as nossas listagens.
Contorne as proteções do Craigslist com o Web Unlocker
À medida que você amplia suas operações de scraping do Craigslist, inevitavelmente encontrará obstáculos: CAPTCHAs, bloqueios de IP e sistemas de detecção anti-bot que podem impedir seus Scrapers.
O Web Unlocker da Bright Dataresolve esses desafios automaticamente com uma infraestrutura de nível empresarial projetada especificamente para coleta de dados em grande escala.
Resolução automática de CAPTCHA
Em vez de realizar a resolução de CAPTCHAs manualmente ou perder dados valiosos devido a solicitações bloqueadas, o Web Unlocker cuida disso para você:
- ✅Resolução automática de CAPTCHAspara reCAPTCHA, hCaptcha e muito mais
- ✅Randomização de impressão digital em tempo realpara evitar a detecção
- ✅Lógica de repetição inteligenteque se adapta aos mecanismos de proteção de cada site
- ✅Taxa de sucesso de 99,9%, mesmo em páginas altamente protegidas
Saiba mais sobre nossosrecursos do CAPTCHA Solver.
Integração simples
import requests
# Endpoint do Web Unlocker
WEB_UNLOCKER_URL = 'https://brd.superproxy.io:33335'
AUTH = 'brd-customer-<CUSTOMER_ID>-Zona-web_unlocker:<ZONE_PASSWORD>'
def scrape_with_unlocker(location, keyword):
url = f"https://{location}.craigslist.org/search/cta?query={keyword}"
response = requests.get(
url,
Proxies={
'http': f'http://{AUTH}@{WEB_UNLOCKER_URL}',
'https': f'http://{AUTH}@{WEB_UNLOCKER_URL}'
},
verify=False
)
retornar resposta.texto
# Raspe sem se preocupar com bloqueios ou CAPTCHAs
listagens = raspar_com_unlocker("detroit", "carros")Com o Web Unlocker, você obtém:
- Sem necessidade de realizar a resolução de CAPTCHA manualmente
- Sem dores de cabeça com gerenciamento de Proxy
- Sem configuração de rotação de IP
- Apenas coleta de dados limpa e confiável em escala
Usando o Navegador de scraping
O Navegador de scraping nos permite executar uma instância do Playwright com integração de Proxy. Isso pode levar sua raspagem a um novo patamar, operando um navegador completo a partir do seu script Python. Se você estiver interessado em integrar proxies com o Playwright
No código abaixo, nosso método de Parsing permanece praticamente o mesmo, mas usamos asyncio com async_playwright para abrir um navegador sem interface gráfica e realmente buscar a página usando esse navegador. Em vez do BeautifulSoup, passamos nosso seletor CSS para o método query_selector() do Playwright.
import asyncio
from playwright.async_api import async_playwright
import json
AUTH = 'brd-customer-<SEU-NOME-DE-USUÁRIO>-zone-<NOME-DA-SUA-ZONA>:<SUA-SENHA>'
SBR_WS_CDP = f'wss://{AUTH}@brd.superproxy.io:9222'
async def scrape_listings(palavra-chave, localização):
print('Conectando ao Navegador de scraping...')
url = f"https://{localização}.craigslist.org/search/cta?query={palavra-chave}"
scraped_data = []
async com async_playwright() como p:
browser = aguardar p.chromium.connect_over_cdp(SBR_WS_CDP)
context = aguardar browser.new_context()
page = aguardar context.new_page()
tentar:
imprimir('Conectado! Navegando para a página da web...')
await page.goto(url)
embedded_json_string = await page.query_selector("script[id='ld_searchpage_results']")
json_data = json.loads(await embedded_json_string.text_content())["itemListElement"]
para dirty_item em json_data:
item = dirty_item.get("item")
ofertas = item.get("ofertas")
informações_de_localização = item.get("ofertas").get("disponívelEmOuA partirDe")
imagens = item.get("imagem")
imagem = Nenhum
se len(imagens) > 0:
image = images[0]
clean_item = {
"name": item.get("name"),
"image": image,
"price": item.get("offers").get("price"),
"currency": item.get("offers").get("priceCurrency"),
"city": location_info.get("address").get("addressLocality"),
"region": location_info.get("address").get("addressRegion"),
"country": location_info.get("address").get("addressCountry")
}
scraped_data.append(clean_item)
exceto Exception como e:
imprimir(f"Falha ao coletar dados: {e}")
finalmente:
aguardar browser.close()
retornar scraped_data
async def main():
QUERY = "cars"
LOCATION = "detroit"
listings = aguardar scrape_listings(QUERY, LOCATION)
tentar:
com abrir(f"{QUERY}-scraping-browser.json", "w") como arquivo:
json.dump(listings, arquivo, indent=4)
exceto Exception como e:
imprimir(f"Falha ao salvar resultados {e}")
se __name__ == '__main__':
asyncio.run(main())
Usando um Scraper personalizado sem código
Aqui na Bright Data, também oferecemos um Scraper sem código para o Craigslist. Com o Scraper sem código, você especifica os dados e as páginas que deseja extrair. Em seguida, criamos e implantamos um Scraper para você!
Na seção “Meus Scrapers”, clique em “Novo” e selecione “Solicitar um Scraper personalizado”.
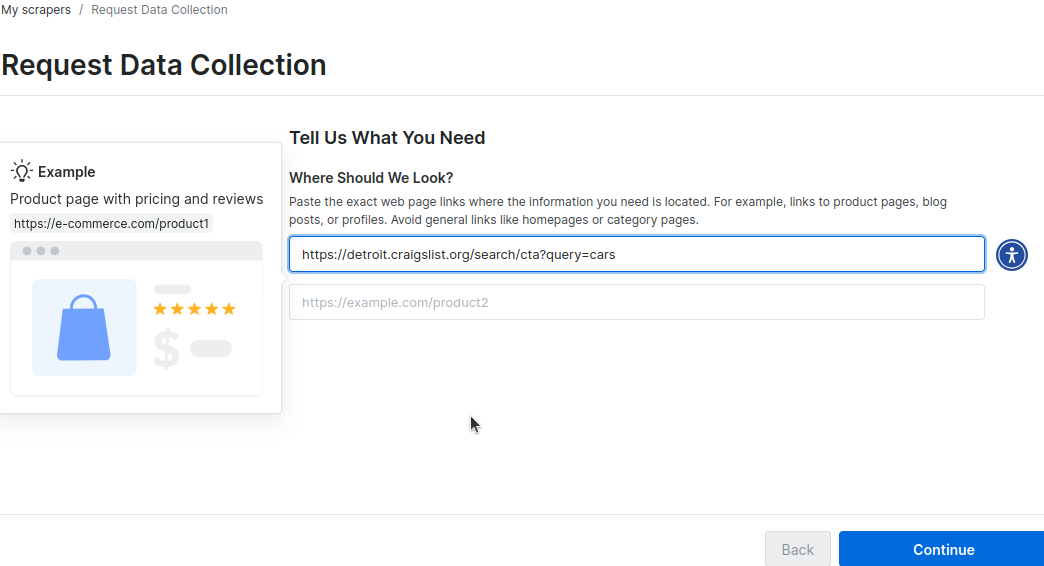
Em seguida, você será solicitado a inserir algumas URLs contendo o layout do seu site. Na imagem abaixo, passamos a URL para nossa pesquisa de carros em Detroit. Você pode adicionar uma segunda URL para sua cidade.
Por meio de nosso processo automatizado, rastreamos os sites e criamos um esquema para você revisar.
Depois que o esquema for criado, você precisará revisá-lo.
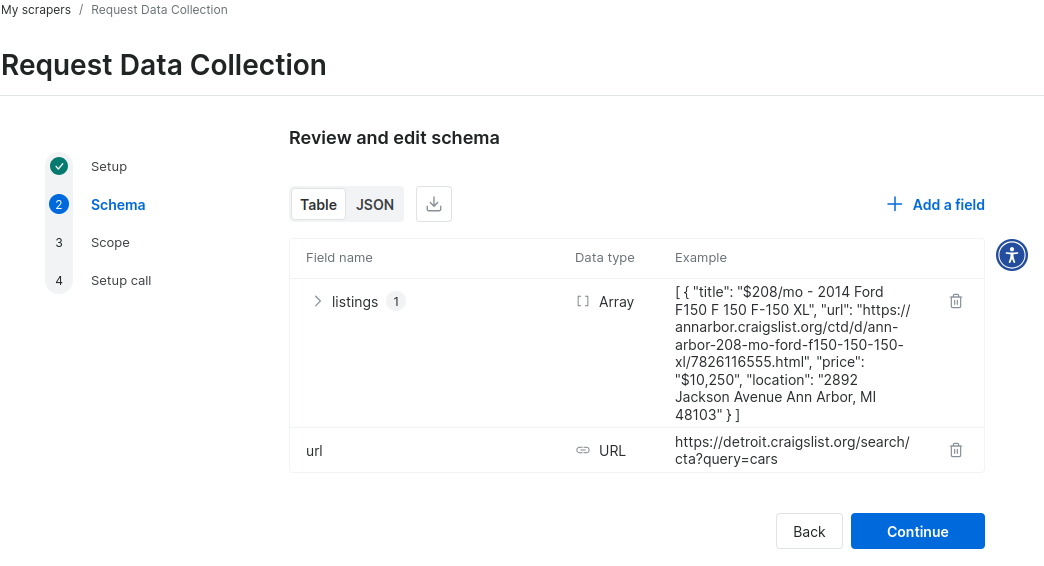
Aqui está um exemplo de dados JSON do esquema para um Scraper personalizado do Craigslist. Em poucos minutos, você terá um protótipo funcional.
{
"type": "object",
"fields": {
"listings": {
"type": "array",
"active": true,
"items": {
"type": "object",
"fields": {
"title": {
"type": "text",
"active": true,
"sample_value": "$208/mo - 2014 Ford F150 F 150 F-150 XL"
},
"url": {
"tipo": "url",
“ativo”: verdadeiro,
“valor_de_amostra”: “https://annarbor.craigslist.org/ctd/d/ann-arbor-208-mo-ford-f150-150-150-xl/7826116555.html”
},
"price": {
"type": "price",
"active": true,
"sample_value": "$10,250"
},
"localização": {
"tipo": "texto",
"ativo": verdadeiro,
"valor_de_amostra": "2892 Jackson Avenue Ann Arbor, MI 48103"
}
}
}
},
"url": {
"tipo": "url",
"obrigatório": verdadeiro,
"ativo": verdadeiro,
"valor_de_amostra": "https://detroit.craigslist.org/search/cta?query=cars"
}
}
}
Em seguida, defina o escopo da coleta. Não precisamos rastrear todo o Craigslist, nem apenas uma seção específica, então vamos alimentá-lo com URLs para iniciar o rastreamento.
Por fim, você será solicitado a agendar uma ligação com um de nossos especialistas para a implantação. Você pode pagar US$ 300 mensais para manutenção e atualização ou uma taxa única de implantação de US$ 1.000.
Conclusão
Ao coletar dados do Craigslist, agora você pode usar o Python para processar dados de forma rápida e eficiente. Você sabe como analisar e limpar os dados. Você também aprendeu como armazená-los usando CSV e JSON. Se precisar de todas as funcionalidades do navegador, você pode utilizar o Navegador de scraping para atender a essas necessidades com integração total de Proxy. Se deseja automatizar completamente seu processo de coleta de dados, agora você também sabe como usar nosso No-Code Scraper.
Além disso, se você quiser pular completamente o processo de raspagem, a Bright Data oferece Conjuntos de dados do Craigslist prontos para uso. Inscreva-se agora e comece seu Teste grátis hoje mesmo!





