Neste artigo, discutiremos:
- O que é um pipeline de dados?
- Como uma boa arquitetura de pipeline de dados pode ajudar as empresas
- Exemplos de arquitetura de pipeline de dados
- Pipeline de dados vs pipeline ETL
O que é um pipeline de dados?
Um pipeline de dados é o processo pelo qual os dados passam. Normalmente, um ciclo completo ocorre entre um “site de destino” e um “lago ou pool de dados” que atende a uma equipe em seu processo de tomada de decisão ou a um algoritmo em seus recursos de IA. Um fluxo típico é semelhante a este:
- Coleta
- Ingestão
- Preparação
- Computação
- Apresentação
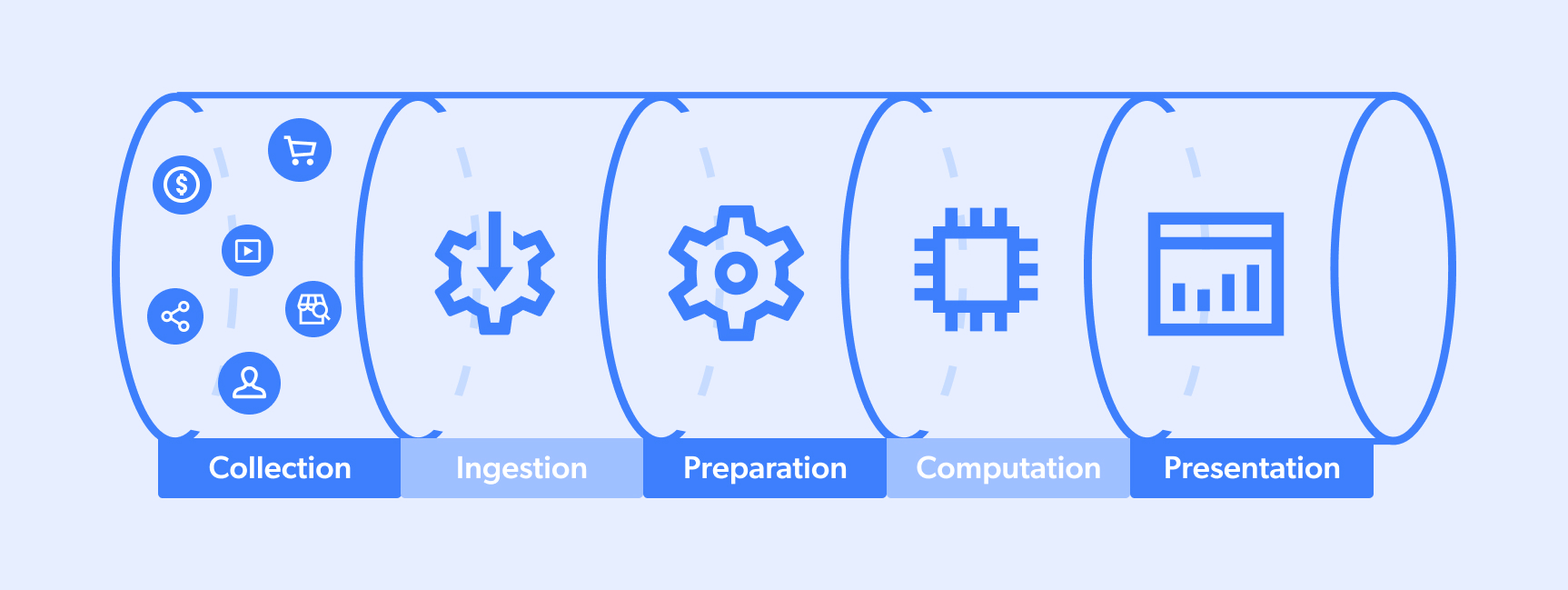
No entanto, tenha em mente que os pipelines de dados podem ter várias fontes/destinos e que, às vezes, as etapas podem ocorrer simultaneamente. Além disso, certos pipelines podem ser parciais (por exemplo, números 1-3 ou 3-5).
O que é um pipeline de big data?
Pipelines de big data são fluxos operacionais que sabem como lidar com a coleta, o processamento e a implementação de dados em escala. A ideia é que, quanto maior a “captura de dados”, menor a margem de erro ao tomar decisões comerciais cruciais.
Algumas aplicações populares de um pipeline de big data incluem:
- Análise preditiva: os algoritmos são capazes de fazer previsões em termos do mercado de ações ou da demanda por produtos, por exemplo. Esses recursos exigem “treinamento de dados” usando conjuntos de dados históricos que permitem que os sistemas compreendam os padrões de comportamento humano para prever resultados futuros potenciais.
- Captura do mercado em tempo real: essa abordagem entende que o sentimento atual do consumidor, por exemplo, pode mudar esporadicamente. Portanto, agrega grandes quantidades de informações de várias fontes, como coleta de dados de mídias sociais, dados de mercados de comércio eletrônico e dados de anúncios de concorrentes em mecanismos de busca. Ao cruzar esses pontos de dados exclusivos em grande escala, eles são capazes de tomar melhores decisões, resultando em maior captura de participação no mercado.
Ao aproveitar uma plataforma de coleta de dados, os fluxos operacionais do pipeline de big data são capazes de lidar com:
- Escalabilidade – Os volumes de dados tendem a flutuar com frequência, e os sistemas precisam estar equipados com a capacidade de ativar/desativar recursos sob comando.
- Fluidez – Ao coletar dados em grande escala de várias fontes, as operações de processamento de big data precisam dos meios para lidar com dados em muitos formatos diferentes (por exemplo, JSON, CSV, HTML), bem como do know-how para limpar, combinar, sintetizar, processar e estruturar dados não estruturados de sites-alvo.
- Gerenciamento de solicitações simultâneas – Como gosta de dizer o CEO da Bright Data, Or Lenchner: “A coleta de dados em grande escala é como esperar por uma cerveja online em um festival de música. As solicitações simultâneas são filas curtas e rápidas que recebem atendimento rápido/simultâneo. Já a outra fila é lenta/consecutiva. Quando suas operações comerciais dependem disso, em qual fila você prefere ficar?”
Como uma boa arquitetura de pipeline de dados pode ajudar as empresas
Estas são algumas das principais maneiras pelas quais uma boa arquitetura de pipeline de dados pode ajudar a otimizar os processos comerciais diários:
Primeiro: consolidação de dados
Os dados podem ter origem em muitas fontes diferentes, como mídias sociais, mecanismos de busca, mercados de ações, veículos de notícias, atividades dos consumidores em mercados, etc. Os pipelines de dados funcionam como um funil que reúne todos esses dados em um único local.
Dois: redução do atrito
Os pipelines de dados reduzem o atrito e o “tempo de insight” ao diminuir a quantidade de esforço necessário em termos de limpeza e preparação dos dados para a análise inicial.
Terceiro: Compartimentação de dados
A arquitetura do pipeline de dados implementada de maneira inteligente ajuda a garantir que apenas as partes interessadas relevantes tenham acesso a informações específicas, ajudando a manter cada ator individual no caminho certo.
Quatro: Uniformidade dos dados
Os dados vêm em muitos formatos diferentes, de uma variedade de fontes. A arquitetura do pipeline de dados sabe como criar uniformidade, além de ser capaz de copiar/mover/transferir entre vários repositórios/sistemas.
Exemplos de arquitetura de pipeline de dados
As arquiteturas de pipeline de dados precisam levar em consideração aspectos como o volume de coleta previsto, a origem e o destino dos dados, bem como o tipo de processamento que potencialmente precisaria ocorrer.
Aqui estão três exemplos arquetípicos de arquitetura de pipeline de dados:
- Um pipeline de dados de streaming: este pipeline de dados é para aplicações mais em tempo real. Por exemplo, uma agência de viagens online (OTA) que coleta dados sobre preços, pacotes e campanhas publicitárias da concorrência. Essas informações são processadas/formatadas e, em seguida, entregues às equipes/sistemas relevantes para análise posterior e tomada de decisão (por exemplo, um algoritmo responsável por reajustar os preços dos bilhetes com base nas quedas de preços da concorrência).
- Um pipeline de dados baseado em lotes: esta é uma arquitetura mais simples/direta. Normalmente consiste em um sistema/fonte que gera uma grande quantidade de Pontos de dados, que são então entregues a um destino (ou seja, uma “instalação” de armazenamento/análise de dados). Um bom exemplo disso seria uma instituição financeira que coleta grandes quantidades de dados sobre compras/vendas/volume de investidores na Nasdaq. Essas informações são enviadas para análise e, em seguida, usadas para informar a gestão de portfólio.
- Um pipeline de dados híbrido: esse tipo de abordagem é popular entre empresas/ambientes muito grandes, permitindo insights em tempo real, bem como processamento/análise em lote. Muitas empresas que optam por essa abordagem preferem manter os dados em formatos brutos para permitir maior versatilidade futura em termos de novas consultas/mudanças estruturais no pipeline.
Pipeline de dados vs. pipeline ETL
Os pipelines ETL, ou Extração, Transformação e Carregamento, normalmente servem para fins de armazenamento e integração. Normalmente, funcionam como uma forma de coletar dados de fontes distintas, transferi-los para um formato mais universal/acessível e carregá-los em um sistema de destino. Os pipelines ETL normalmente nos permitem coletar, salvar e preparar dados para acesso/análise rápidos.
Um pipeline de dados tem mais a ver com a criação de um processo sistêmico no qual os dados podem ser coletados, formatados e transferidos/carregados para os sistemas de destino. Os pipelines de dados são mais um protocolo, garantindo que todas as partes da “máquina” estejam funcionando conforme o esperado.
Conclusão
Encontrar e implementar a arquitetura de pipeline de dados certa para o seu negócio é extremamente importante para o seu sucesso como empresa. Quer opte por uma abordagem de streaming, baseada em lotes ou híbrida, vai querer aproveitar a tecnologia que pode ajudar a automatizar e adaptar soluções às suas necessidades específicas.