

Neste guia, você aprenderá:
- O que é o Selenium Wire
- Por que você deve usar o Selenium Wire para Scraping de dados
- Os principais recursos do Selenium Wire
- Um caso de uso de Scraping de dados do Selenium Wire com Proxy rotativo
- Integração do Proxy Bright Data com o Selenium Wire
Vamos começar!
O que é o Selenium Wire?
O Selenium Wireé uma extensão para as ligações Python do Selenium que fornece controle sobre as solicitações do navegador. Especificamente, ele permite interceptar e modificar solicitações e respostas em tempo real diretamente do seu código Python enquanto usa o Selenium.
Observação: embora a biblioteca não seja mais mantida, várias tecnologias e scripts de scraping ainda dependem dela.
Por que usar o Selenium Wire para Scraping de dados?
O Selenium é uma estrutura popular de automação de navegadores usada no Scraping de dados para interagir com sites como usuários humanos comuns fariam. Saiba mais em nossoguia de Scraping de dados com Selenium.
O problema é que os navegadores têm certas limitações que podem tornar o Scraping de dados um desafio. Por exemplo, eles não permitem que você defina URLs de Proxy autorizados ou use Proxy rotativo em tempo real. O Selenium Wire ajuda você a superar essas limitações.
Aqui estão três boas razões pelas quais você deve usar o Selenium Wire para Scraping de dados:
- Acesse a camada de rede: interprete, inspecione e modifique o tráfego de rede AJAX para extração avançada de dados.
- Contorne antibots:
o ChromeDriverexpõe uma quantidade significativa de informações que os sistemas antibot podem usar para identificá-lo como um bot. O Selenium Wire é usado por tecnologias comoo undetected-chromedriverpara evitar isso e ajudar a contornar a maioria das soluções antibot. - Supere as limitações dos navegadores: os navegadores modernos usam sinalizadores para configurar comportamentos na inicialização, mas essas configurações são estáticas e exigem uma reinicialização para serem alteradas. O Selenium Wire supera essa limitação ao oferecer suporte a modificações dinâmicas. Dessa forma, você pode atualizar cabeçalhos de solicitação ou Proxies durante a mesma sessão do navegador, o que é ideal para o Scraping de dados.
Principais recursos do Selenium Wire
Agora você sabe o que é o Selenium Wire e por que deve usá-lo para Scraping de dados. É hora de explorar seus recursos mais importantes!
Acesse solicitações e respostas
O Selenium Wire pode capturar o tráfego HTTP/HTTPS feito pelo navegador, dando a você acesso aos seguintes atributos:
| Atributo | Descrição |
|---|---|
driver.requests |
Relata a lista de solicitações capturadas em ordem cronológica |
driver.last_request |
Relata a solicitação capturada mais recentemente (Isso é mais eficiente do que usar driver.requests[-1]) |
driver.wait_for_request(pat, timeout=10) |
Este método aguardará — o tempo é definido pelo parâmetrotimeout— até encontrar uma solicitação que corresponda a um padrão, definido pelo parâmetropat— que pode ser uma substring ou umaexpressão regular. |
driver.har |
Um arquivoHARformatado em JSON das transações HTTP que ocorreram. |
driver.iter_requests() |
Retorna um iterador sobre as solicitações capturadas. |
Em detalhes, um objeto Selenium Wire Request tem os seguintes atributos:
| Atributo | Descrição |
|---|---|
corpo |
A solicitação do corpo é apresentada em bytes. Se a solicitação não tiver corpo, o valor do corpo ficará vazio (por exemplo: b''). |
cert |
Relata informações sobre o certificado SSL do servidor em formato de dicionário (fica vazio para solicitações não HTTPS). |
data |
Mostra a data e hora em que a solicitação foi feita. |
cabeçalhos |
Relata um objeto semelhante a um dicionário dos cabeçalhos da solicitação (observe que, no Selenium Wire, os cabeçalhos não diferenciam maiúsculas de minúsculas e duplicatas são permitidas). |
host |
Relata o host da solicitação (por exemplo, https://brightdata.com/). |
método |
Especifica o método HHTP (GET, POST, etc…). |
parâmetros |
Relata um dicionário dos parâmetros da solicitação (observe que, se um parâmetro com o mesmo nome aparecer mais de uma vez na solicitação, seu valor no dicionário será uma lista). |
caminho |
Relata o caminho da solicitação. |
querystring |
Relata a string de consulta. |
resposta |
Relata o objeto de resposta associado à solicitação (observe que o valor será None se a solicitação não tiver resposta). |
url |
Relata a URL da solicitação completa com host, caminho e string de consulta. |
ws_messages |
No caso de uma solicitação ser um WebSocket (nesse caso, a URL geralmente é semelhante a wss://), as mensagens ws_messages conterão todas as mensagens websocket enviadas e recebidas. |
Em vez disso, um objeto Response expõe estes atributos:
| Atributo | Descrição |
|---|---|
corpo |
A resposta do corpo é apresentada em bytes. Se a resposta não tiver corpo, o valor do corpo ficará vazio (por exemplo: b''). |
data |
Mostra a data e hora em que a resposta foi recebida. |
cabeçalhos |
Relata um objeto semelhante a um dicionário dos cabeçalhos da resposta (observe que, no Selenium Wire, os cabeçalhos não diferenciam maiúsculas de minúsculas e duplicatas são permitidas). |
motivo |
Relata a frase do motivo da resposta, como OK, Não encontrado, etc… |
código_de_status |
Relata o status da resposta, como 200, 404, etc… |
Para testar esse recurso, você pode criar um script Python como o seguinte:
from seleniumwire import webdriver
# Inicialize o WebDriver com o Selenium Wire
driver = webdriver.Chrome()
try:
# Abra o site de destino
driver.get("https://brightdata.com/")
# Acesse e imprima todas as solicitações capturadas
for request in driver.requests:
print(f"URL: {request.url}")
imprimir(f"Método: {request.method}")
imprimir(f"Cabeçalhos: {request.headers}")
imprimir(f"Código de status da resposta: {request.response.status_code if request.response else 'Sem resposta'}")
imprimir("-" * 50)
finalmente:
# Fechar o navegador
driver.quit()
O código acima abre o site de destino e captura as solicitações usando driver.requests. Em seguida, ele percorre um loop for para interceptar alguns atributos da solicitação, como url, método e cabeçalhos.
Aqui está o resultado esperado:
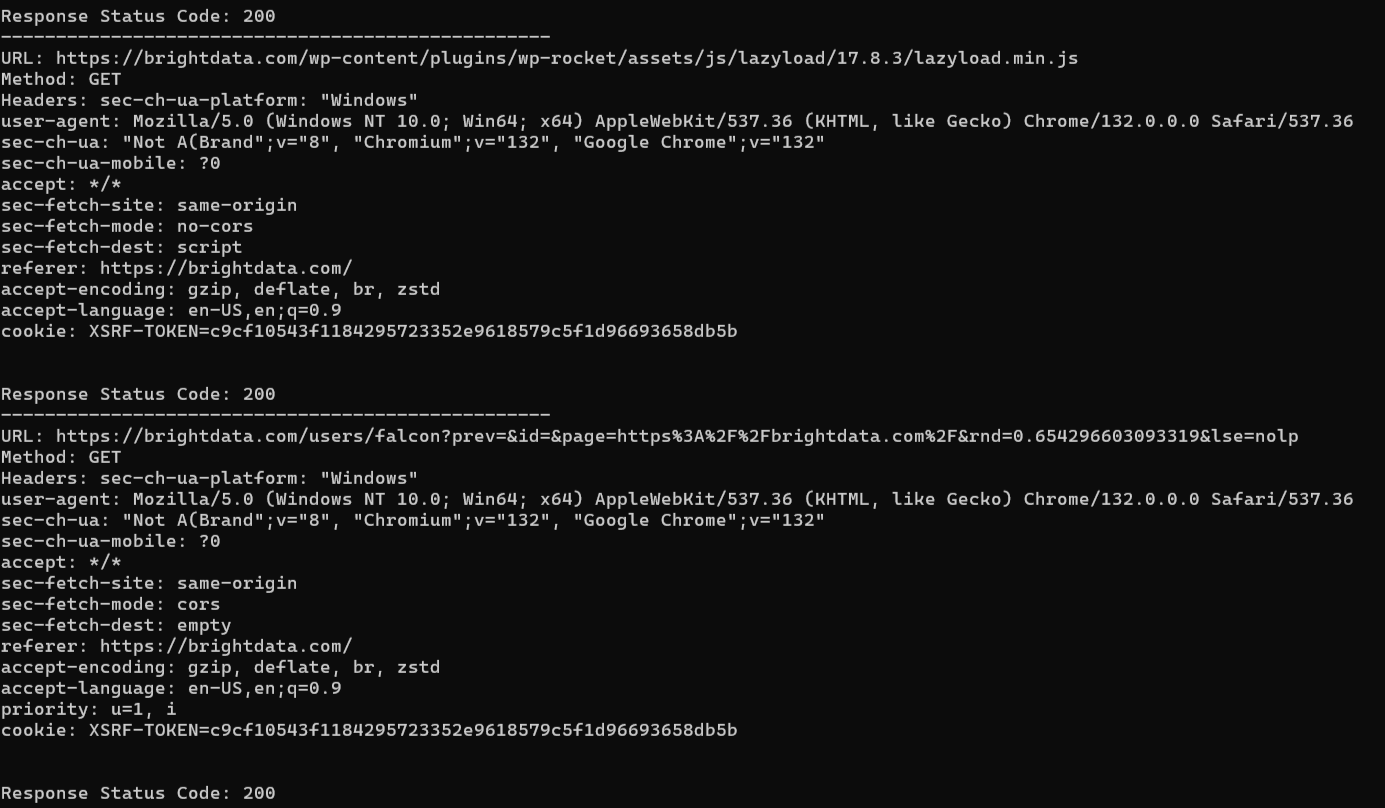
A página de destino faz várias solicitações, e o script rastreia todas elas.
Interceptar solicitações e respostas
O Selenium Wire pode interceptar e modificar solicitações e respostas graças aos interceptadores. Um interceptador é uma função invocada com solicitações e respostas à medida que elas passam pelo navegador.
Existem dois interceptadores separados:
driver.request_interceptor: ele intercepta solicitações e aceita um único argumento.driver.response_interceptor: intercepta a resposta e aceita dois argumentos, um para a solicitação de origem e outro para a resposta.
Aqui está um exemplo que mostra como usar um interceptador de solicitação:
from seleniumwire import webdriver
# Define a função interceptor de solicitação
def interceptor(request):
# Adiciona um cabeçalho personalizado a todas as solicitações
request.headers["X-Test-Header"] = "MyCustomHeaderValue"
# Bloqueia solicitações para um domínio específico
if "example.com" in request.url:
print(f"Bloqueando solicitação para: {request.url}")
request.abort() # Aborta a solicitação
# Inicializa o WebDriver com o Selenium Wire
driver = webdriver.Chrome()
# Atribuir a função interceptadora ao driver
driver.request_interceptor = interceptor
tentar:
# Abrir um site que faz várias solicitações
driver.get("https://brightdata.com/")
# Imprimir todas as solicitações capturadas
para solicitação em driver.requests:
imprimir(f"URL: {request.url}")
imprimir(f"Cabeçalhos: {request.headers}")
imprimir("-" * 50)
finalmente:
# Fechar o navegador
driver.quit()
É isso que este trecho faz:
- Função interceptadora: cria uma função interceptadora a ser chamada para cada solicitação enviada. Isso adiciona um cabeçalho personalizado a todas as solicitações enviadas com
request.headers[]. Além disso, bloqueia as solicitações do navegador para o domínioexample.com. - Captura solicitações: após o carregamento da página, todas as solicitações capturadas são impressas, incluindo os cabeçalhos modificados.
Observação: o bloqueio de solicitações é útil quando as páginas carregam recursos adicionais, como anúncios, scripts de análise ou widgets de terceiros que são irrelevantes para o seu objetivo. Bloquear essas solicitações pode melhorar significativamente a velocidade de raspagem e reduzir o uso de largura de banda do navegador.
O resultado esperado é algo como isto:
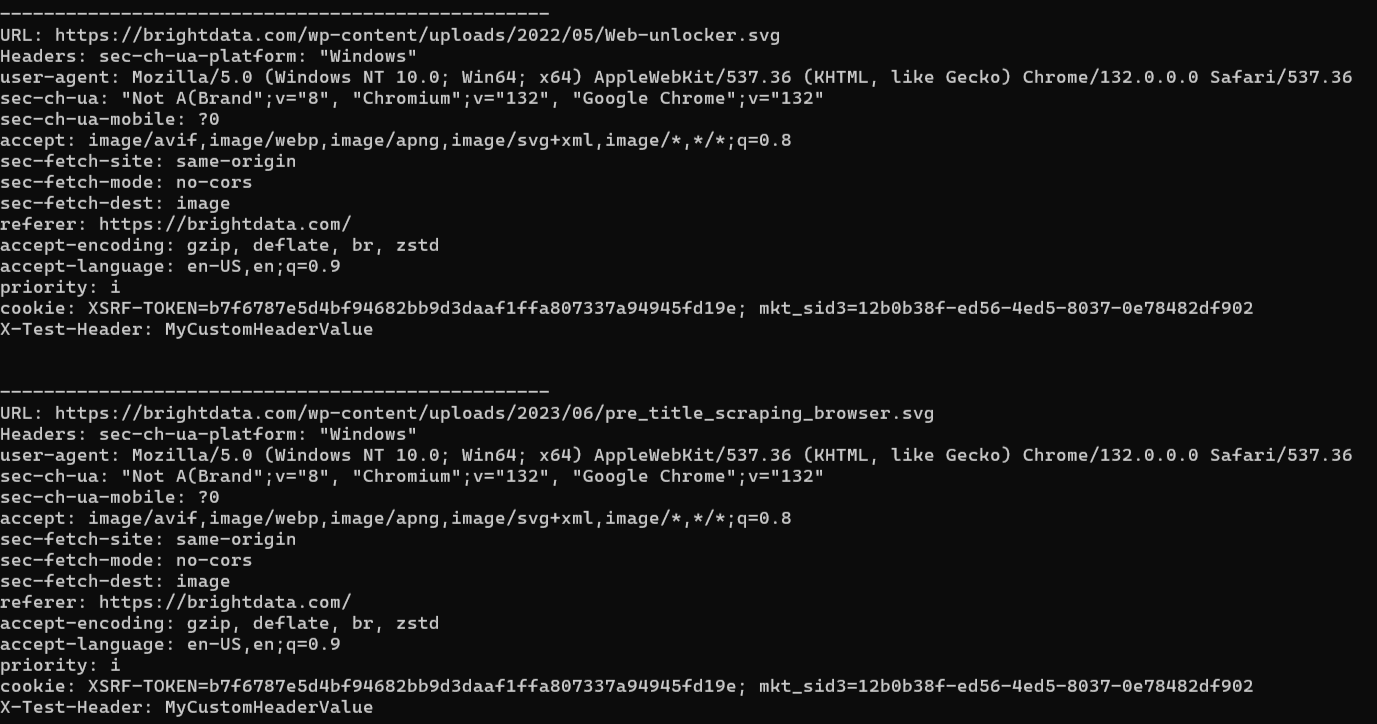
Veja como a solicitação feita pelo navegador foi interceptada e o valor do cabeçalho adicional foi adicionado a ela.
Monitoramento de WebSocket
Muitas páginas da web modernas usamWebSocketspara comunicação em tempo real com servidores.Os WebSocketsestabelecem uma conexão persistente entre o navegador e o servidor. Dessa forma, os dados podem ser trocados continuamente sem a sobrecarga das solicitações HTTP tradicionais.
Frequentemente, dados críticos fluem por esses canais, e acessá-los diretamente pode ser inestimável para a recuperação de dados. Ao interceptar a comunicação WebSocket, você pode extrair os dados brutos enviados pelo servidor sem esperar que o navegador os transforme ou que a página os renderize.
Você já aprendeu que os objetos de solicitação têm o atributo ws_messages para gerenciar WebSockets. Estes são os atributos de um objeto Selenium Wire WebSocket:
| Atributo | Descrição |
|---|---|
conteúdo |
Ele relata o conteúdo da mensagem, que pode ser um str ou no formato bytes. |
data |
Mostra a data e hora da mensagem. |
cabeçalhos |
Relata um objeto semelhante a um dicionário dos cabeçalhos da resposta (observe que, no Selenium Wire, os cabeçalhos não diferenciam maiúsculas de minúsculas e duplicatas são permitidas). |
do_cliente |
É um booleano que retorna True quando a mensagem foi enviada pelo cliente e False quando foi enviada pelo servidor. |
Gerenciar proxies
Os servidores Proxyatuam como intermediários entre o seu dispositivo e os sites de destino, mascarando o seu endereço IP no processo. Eles são essenciais para o Scraping de dados da web, pois:
- Ajudam a contornar restrições baseadas em IP
- Impedem o bloqueio em caso de limitadores de taxa
- Permitem a extração de conteúdo de sites com restrições geográficas
Veja abaixo como você pode configurar um Proxy no Selenium Wire:
# Configure as opções do Selenium Wire
options = {
"proxy": {
"http": "<YOUR_HTTP_PROXY_URL>",
"https": "<YOUR_HTTPS_PROXY_URL>"
}
}
# Inicialize o WebDriver com o Selenium Wire
driver = webdriver.Chrome(seleniumwire_options=options)
Essa configuração difere da configuração de umProxy no Selenium básico, onde você precisa usar o sinalizador--proxy-serverdo Chrome. Isso significa que a configuração do Proxy é estática no Selenium básico.
Depois de definir um Proxy, ele se aplica a toda a sessão do navegador e não pode ser alterado sem reiniciar o navegador. Essa limitação pode ser restritiva, especialmente em cenários em que você precisa alternar proxies dinamicamente.
Em contrapartida, o Selenium Wire oferece flexibilidade para alterar Proxies dinamicamente dentro da mesma instância do navegador. Isso é possível graças ao atributo Proxy:
# Alterar dinamicamente o Proxy
driver.proxy = {
"http": "<NEW_HTTP_PROXY_URL>",
"https": "<NEW_HTTPS_PROXY_URL>"
}
Além disso, o sinalizador --proxy-server do Chrome não oferece suporte a proxies com credenciais de autenticação na URL:
protocolo://nome de usuário:senha@host:porta
Em vez disso, o Selenium Wire oferece suporte total a proxies autenticados, tornando-o a melhor opção para Scraping de dados.
Como a configuração de Proxy é uma das vantagens mais significativas do Selenium Wire, exploraremos esse tópico mais a fundo no próximo capítulo.
Caso de uso de Scraping de dados: Proxy rotativo no Selenium Wire
Como mencionado anteriormente, a principal razão para usar o Selenium Wire para Scraping de dados são seus recursos avançados de gerenciamento de Proxy.
Nesta seção guiada, você verá como configurar um projeto do Selenium Wire para Proxy rotativo. Isso ajudará você a alterar seu IP de saída a cada solicitação.
Requisitos
Para replicar este tutorial, seu sistema deve atender aos seguintes pré-requisitos:
- Python 3.7 ou superior: qualquer versão do Python superior a 3.7 servirá. Especificamente, instalaremos as dependências via pip, que já vem instalado com qualquer versão do Python superior a 3.4.
- Um navegador da web compatível: o Selenium Wire estende o Selenium, então você precisa de umnavegador compatível.
Antes de instalar o Selenium Wire, você pode criar um diretóriode ambiente virtualassim:
python -m venv venv
Para ativá-lo, no Windows, execute:
venvScriptsactivate
De forma equivalente, no macOS/Linux, execute:
source venv/bin/activate
Agora você pode instalar o Selenium Wire com:
pip install selenium-wire
Observação: você não precisa instalar o Selenium. Sua instalação ocorre com o Selenium Wire, pois é uma de suas dependências.
Suponha que você chame sua pasta principal de selenium_wire/. Ao final desta etapa, a pasta terá a seguinte estrutura:
selenium_wire/
├── selenium_wire.py
└── venv/
Onde selenium_wire.py é o arquivo Python que conterá toda a lógica que você implementará nas próximas etapas.
Etapa 1: Randomizar Proxies
Primeiro, você precisa de uma lista de URLs de Proxy válidos. Se você não sabe onde obtê-los, dê uma olhada em nossa lista deProxy gratuitos. Adicione-os a uma lista e userandom.choice()para escolher um elemento aleatório dela:
def get_random_Proxy():
proxies = [
"http://PROXY_1:PORT_NUMBER_X",
"http://PROXY_2:PORT_NUMBER_Y",
"http://PROXY_3:PORT_NUMBER_Z",
# ...
]
# Randomize a lista
return random.choice(Proxies)
Uma vez chamada, esta função retorna um URL Proxy aleatório da lista.
Para que funcione, não se esqueça de importar random:
import random
Passo 2: Configure o Proxy
Chame a função get_random_proxy() para obter um URL de Proxy:
Proxy = get_random_Proxy()
Em seguida, inicialize a instância do navegador e defina o Proxy selecionado:
# Configuração do Selenium Wire com o Proxy
seleniumwire_options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Configuração do navegador
chrome_options = Options()
chrome_options.add_argument("--headless") # Execute o navegador no modo headless
# Inicialize uma instância do navegador com as configurações fornecidas
driver = webdriver.Chrome(service=Service(), options=chrome_options, seleniumwire_options=seleniumwire_options)
O trecho acima requer as seguintes importações:
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
Para alterar dinamicamente o Proxy durante a sessão do navegador, você usaria este código:
driver.proxy = {
"http": Proxy,
"https": Proxy
}
Incrível, a instância controlada do Chrome agora encaminhará as solicitações através do Proxy fornecido.
Etapa 3: visite a página de destino
Visite o site de destino, extraia a saída e feche o navegador:
tente:
# Visite a página de destino
driver.get("https://httpbin.io/ip")
# Extraia a saída da página
body = driver.find_element(By.TAG_NAME, "body").text
print(body)
except Exception as e:
# Trate quaisquer erros que ocorram com o navegador ou o Proxy
print(f"Erro com o Proxy {Proxy}: {e}")
finalmente:
# Feche o navegador
driver.quit()
Para que funcione, importe By do Selenium:
from selenium.webdriver.common.by import By
Neste exemplo, a página de destino é o endpoint/ipdo projeto HTTPBin. Essa foi uma escolha deliberada, pois a página retorna o endereço IP do chamador. Se tudo correr como esperado, o script deve imprimir um IP diferente da lista de Proxies a cada execução.
Hora de verificar isso!
Etapa 4: Junte tudo
Esta é toda a lógica de rotação de Proxy do Selenium Wire que deve estar no seu arquivo selenium_wire.py:
import random
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
def get_random_proxy():
proxies = [
"http://PROXY_1:PORT_NUMBER_X",
"http://PROXY_2:PORT_NUMBER_Y",
"http://PROXY_3:PORT_NUMBER_Z",
# Adicione mais proxies aqui...
]
# Escolha aleatoriamente um Proxy
return random.choice(proxies)
# Escolha um URL de Proxy aleatório
proxy = get_random_proxy()
# Configuração do Selenium Wire com o Proxy
seleniumwire_options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Configuração do navegador
chrome_options = Options()
chrome_options.add_argument("--headless") # Execute o navegador no modo headless
# Inicialize uma instância do navegador com as configurações fornecidas
driver = webdriver.Chrome(service=Service(), options=chrome_options, seleniumwire_options=seleniumwire_options)
tente:
# Visite a página de destino
driver.get("https://httpbin.io/ip")
# Extraia a saída da página
body = driver.find_element(By.TAG_NAME, "body").text
print(body)
except Exception as e:
# Trate quaisquer erros que ocorram com o navegador ou o Proxy
print(f"Erro com o Proxy {Proxy}: {e}")
finally:
# Feche o navegador
driver.quit()
Para executar o arquivo, inicie:
python3 selenium_wire.py
A cada execução, a saída deve ser:
{
"origin": "PROXY_1:XXXX"
}
Ou:
{
"origin": "PROXY_2:YYYY"
}
E assim por diante…
Execute o script várias vezes e você verá um endereço IP diferente a cada vez. A rotação de Proxy está funcionando!
Uma abordagem melhor para a rotação de proxy: proxies Bright Data
Como acabamos de ver, a rotação manual de proxies no Selenium Wire envolve muito código padrão e requer a manutenção de uma lista de URLs de proxy válidos.
Felizmente,os proxies rotativos da Bright Datasão uma solução mais eficiente!
Nossos proxies rotativos lidam automaticamente com as alterações de endereço IP, eliminando a necessidade de gerenciamento manual de proxies. Com cobertura em 195 países, garantimos um tempo de atividade excepcional da rede e uma taxa de sucesso de 99,9%. Nossa rede mundial de proxies inclui:
- Proxies de datacenter– Mais de 770.000 IPs de datacenter.
- Proxies residenciais– Mais de 72 milhões de IPs residencialis em mais de 195 países.
- Proxies ISP– Mais de 700.000 IPs de ISP.
Siga as etapas abaixo e aprenda a usar os Proxies da Bright Data no Selenium Wire.
Se você já possui uma conta, faça login na Bright Data. Caso contrário, crie uma conta gratuitamente. Você terá acesso ao seguinte painel do usuário:
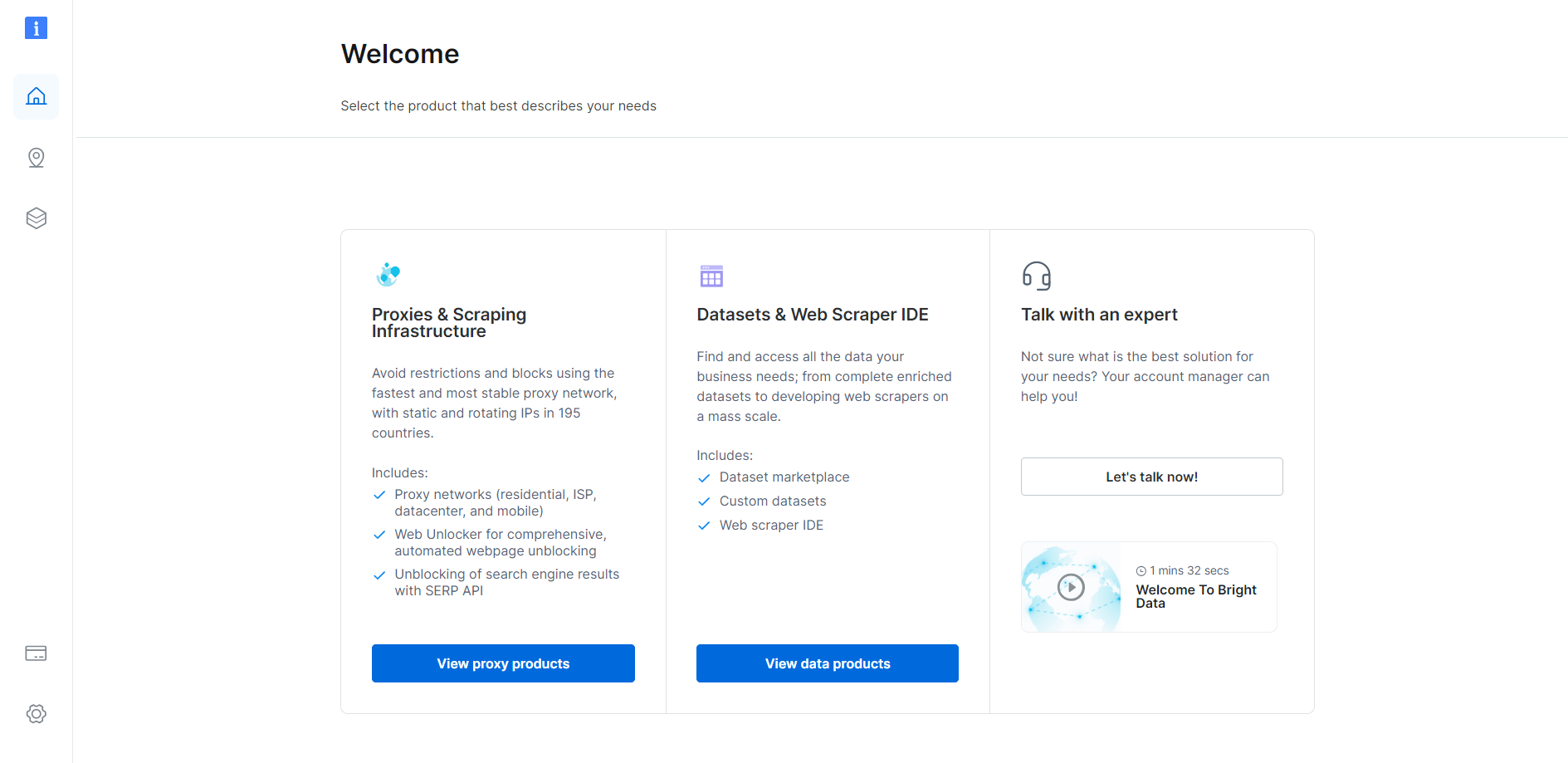
Clique no botão “Ver produtos Proxy”:
Você será redirecionado para a página “Proxies e Infraestrutura de scraping” abaixo:
Role para baixo, encontre o cartão“Proxies residenciais”e clique no botão “Começar”:
Você chegará ao painel de configuração do Proxy residencial. Siga o assistente guiado e configure o serviço de Proxy de acordo com suas necessidades. Se tiver alguma dúvida sobre como configurar o Proxy, entreem contato com o suporte 24 horas por dia, 7 dias por semana:
Vá para a guia “Parâmetros de acesso” e recupere o host, a porta, o nome de usuário e a senha do seu Proxy da seguinte maneira:
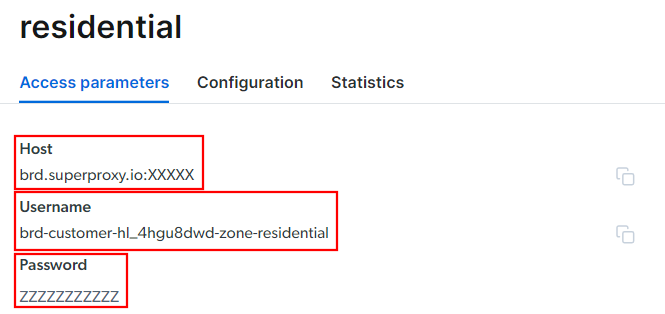
Observe que o campo “Host” já inclui a porta.
Isso é tudo o que você precisa para criar a URL do Proxy e configurá-la no Selenium Wire. Reúna todas as informações e crie uma URL com a seguinte sintaxe:
<nome de usuário>:<senha>@<host>
Por exemplo, neste caso, seria:
brd-customer-hl_4hgu8dwd-zona-residential:[email protected]:XXXXX
Alterne “Proxy ativo”, siga as últimas instruções e você estará pronto para começar!

Seu trecho de Proxy do Selenium Wire para integração com a Bright Data ficará assim:
# URL do Proxy Bright Data
proxy = "brd-customer-hl_4hgu8dwd-zona-residencial:[email protected]:XXXXX"
# Configure as opções do Selenium Wire
options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Inicializar o WebDriver com o Selenium Wire
driver = webdriver.Chrome(seleniumwire_options=options)
A rotação de Proxy é muito mais fácil com essa abordagem!
Selenium vs Selenium Wire para Scraping de datos
Para resumir, dê uma olhada na tabela comparativa entre Selenium e Selenium Wire abaixo:
| Selenium | Selenium Wire | |
|---|---|---|
| Objetivo | Ferramenta para automatizar navegadores da web para realizar testes de interface do usuário e interações na web | Estende o Selenium para fornecer recursos adicionais para inspecionar e modificar solicitações e respostas HTTP/HTTPS |
| Tratamento de solicitações HTTP/HTTPS | Não fornece acesso direto a solicitações ou respostas HTTP/HTTPS | Permite a inspeção, modificação e captura de solicitações e respostas HTTP/HTTPS |
| Suporte a Proxy | Suporte limitado a Proxy (requer configuração manual) | Gerenciamento avançado de Proxy, com suporte para configuração dinâmica |
| Desempenho | Leve e rápido | Ligeiramente mais lento devido à sobrecarga de captura e processamento do tráfego de rede |
| Casos de uso | Usado principalmente para testes funcionais de aplicativos da web, mas também útil para casos básicos de Scraping de dados | Útil para testar APIs, depurar tráfego de rede e Scraping de dados |
Conclusão
Nesta postagem do blog, você aprendeu o que é o Selenium Wire e como ele pode ser usado para Scraping de dados. Em particular, focamos na integração de Proxy e Proxy rotativo. Lembre-se de que, embora o Selenium Wire seja útil, ele não é uma solução única para todos os casos. Além disso, ele não é mais mantido ativamente.
A melhor abordagem não é estender o Selenium Wire, mas sim usar o Selenium básico ou outra ferramenta de automação de navegador junto com um Navegador de scraping dedicado.
O Navegador de scraping da Bright Dataé um navegador em nuvem escalável que funciona com Playwright, Puppeteer, Selenium e outros. Ele alterna automaticamente os IPs de saída a cada solicitação e pode lidar com impressões digitais do navegador, novas tentativas,resolução de CAPTCHA e muito mais. Esqueça o bloqueio e otimize sua operação de scraping.
Inscreva-se agora e comece seu teste grátis!






