

Neste guia sobre Scraping de dados com Parsel em Python, você aprenderá:
- O que é o Parsel
- Por que usá-lo para Scraping de dados
- Um tutorial passo a passo que mostra como usar o Parsel para Scraping de dados
- Cenários avançados de scraping com o Parsel em Python
Vamos começar!
O que é o Parsel?
O Parsel é uma biblioteca Python para Parsing e extração de dados de documentos HTML, XML e JSON. Ele se baseia no lxml, fornecendo uma interface de nível superior e mais fácil de usar para Scraping de dados. Em detalhes, ele oferece uma API intuitiva que simplifica o processo de extração de dados de documentos HTML e XML.
Por que usar o Parsel para Scraping de dados
O Parsel vem com recursos interessantes para Scraping de dados, tais como:
- Suporte para seletores XPath e CSS: use seletores XPath ou CSS para localizar elementos em documentos HTML ou XML. Saiba mais em nosso guia sobre seletores XPath vs CSS para Scraping de dados.
- Extração de dados: recupere texto, atributos ou outro conteúdo dos elementos selecionados.
- Seletores em cadeia: encadeie vários seletores para refinar sua extração de dados.
- Escalabilidade: a biblioteca funciona bem com projetos de scraping pequenos e grandes.
Observe que a biblioteca está totalmente integrada ao Scrapy, que a utiliza para realizar Parsing e extrair dados de páginas da web. Ainda assim, o Parsel também pode ser utilizado como uma biblioteca independente.
Como usar o Parsel em Python para Scraping de dados: um tutorial passo a passo
Esta seção irá guiá-lo pelo processo de scraping de dados da Web com o Parsel em Python. O site de destino será“Hockey Teams: Forms, Searching and Pagination”(Equipes dehóquei: formulários, pesquisa epaginação):

O Scraper Parsel extrairá todos os dados da tabela acima. Siga as etapas abaixo e veja como construí-lo!
Pré-requisitos e dependências
Para replicar este tutorial, você deve ter o Python 3.10.1 ou superior instalado em sua máquina. Em particular, observe que o Parsel removeu recentemente o suporte para Python 3.8.
Suponha que você chame a pasta principal do seu projeto de parsel_scraping/. Ao final desta etapa, a pasta terá a seguinte estrutura:
parsel_scraping/
├── parsel_scraper.py
└── venv/Onde:
parsel_scraper.pyé o arquivo Python que contém a lógica de scraping.venv/contém o ambiente virtual.
Você pode criar o diretório do ambiente virtual venv/ da seguinte maneira:
python -m venv venvPara ativá-lo, no Windows, execute:
venvScriptsactivateDe forma equivalente, no macOS e no Linux, execute:
source venv/bin/activateEm um ambiente virtual ativado, instale as dependências com:
pip install parsel requestsEssas duas dependências são:
parsel: uma biblioteca para Parsing de HTML e extrair dados.requests: necessária porqueo parselé apenas um analisador HTML. Para realizar o Scraping de dados da web, você também precisa de um cliente HTTP como o Requests para recuperar os documentos HTML das páginas que deseja extrair.
Ótimo! Agora você tem o que precisa para realizar Scraping de dados com o Parsel em Python.
Etapa 1: Defina a URL de destino e faça o Parsing do conteúdo
Como primeira etapa deste tutorial, você precisa importar as bibliotecas:
import requests
from parsel import SelectorEm seguida, defina a página da web de destino, busque o conteúdo com Requests e faça o Parsing com Parsel:
url = "https://www.scrapethissite.com/pages/forms/"
response = requests.get(url)
selector = Selector(text=response.text)O trecho acima instancia a classe Selector() do Parsel. Isso realiza o Parsing do HTML lido da resposta da solicitação HTTP feita com get().
Etapa 2: extrair todas as linhas da tabela
Se você inspecionar a tabela na página da web de destino no navegador, verá o seguinte HTML:
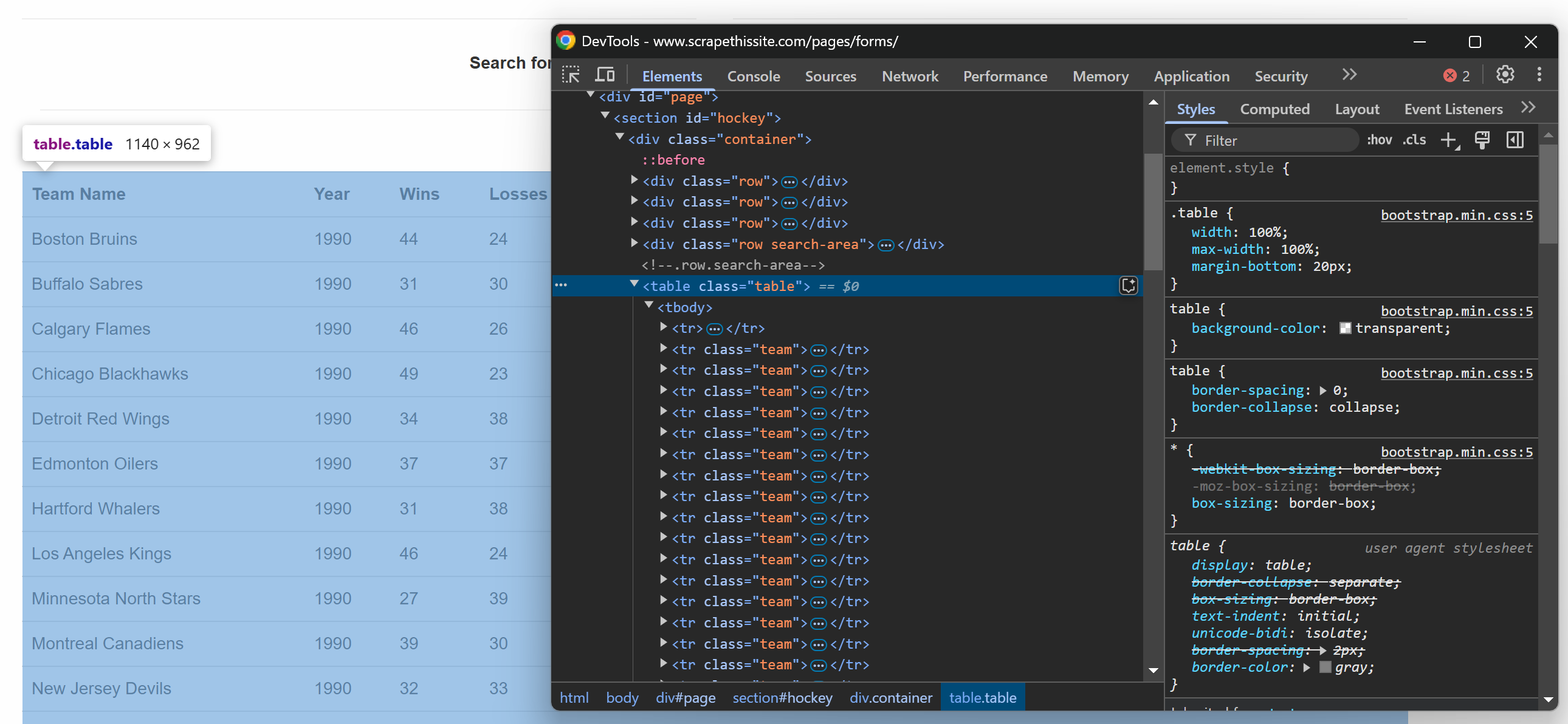
Como a tabela contém várias linhas, inicialize uma matriz onde armazenar os dados extraídos:
data = []Agora, observe que a tabela HTML tem uma classe .table. Para selecionar todas as linhas da tabela, você pode usar a linha de código abaixo:
linhas = seletor.css("table.table tr.team")Isso usa o método css() para aplicar o seletor CSS na estrutura HTML parsed.
É hora de iterar sobre as linhas selecionadas e extrair os dados delas!
Etapa 3: Iterar sobre as linhas
Assim como antes, inspecione uma linha dentro da tabela:
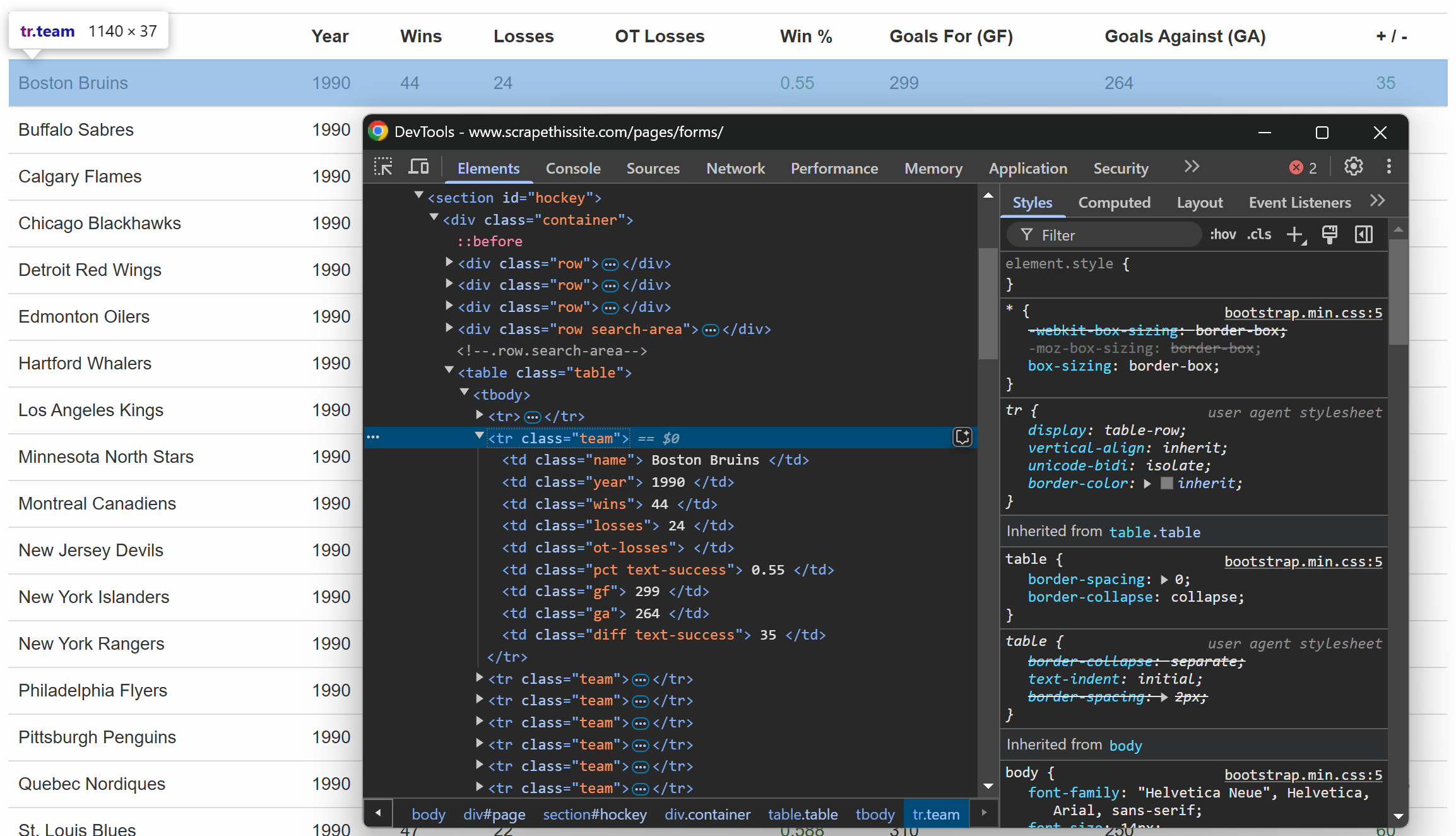
O que você pode notar é que cada linha contém as seguintes informações em colunas dedicadas:
- Nome da equipe → dentro do elemento
.name - Ano da temporada → dentro do elemento
.year - Número de vitórias → dentro do elemento
.wins - Número de derrotas → dentro do elemento
.losses - Derrotas na prorrogação → dentro do elemento
.ot-losses - Porcentagem de vitórias → dentro do elemento
.pct - Gols marcados (Gols a favor – GF) → dentro do elemento
.gf - Gols sofridos (Gols Contra – GA) → dentro do elemento
.ga - Diferença de gols → dentro do elemento
.diff
Você pode extrair todas essas informações com a seguinte lógica:
para linha em linhas:
# Extrair dados de cada coluna
nome = linha.css("td.name::text").get()
ano = linha.css("td.year::text").get()
vitórias = linha.css("td.wins::text").get()
derrotas = linha.css("td.losses::text").get()
ot_losses = row.css("td.ot-losses::text").get()
pct = row.css("td.pct::text").get()
gf = row.css("td.gf::text").get()
ga = row.css("td.ga::text").get()
diff = row.css("td.diff::text").get()
# Anexar os dados extraídos
data.append({
"name": name.strip(),
"year": year.strip(),
"wins": wins.strip(),
"losses": losses.strip(),
"ot_losses": ot_losses.strip(),
"pct": pct.strip(),
"gf": gf.strip(),
"ga": ga.strip(),
"diff": diff.strip()
})Aqui está o que o código acima faz:
- O método
get()seleciona nós de texto usando pseudoelementos CSS3. - O método
strip()remove quaisquer espaços em branco à esquerda e à direita. - O método
append()acrescenta o conteúdo à listade dados.
Ótimo! A lógica de extração de dados do Parsel foi concluída.
Etapa 4: imprima os dados e execute o programa
Como etapa final, imprima os dados extraídos na CLI:
# Imprimir os dados extraídos
print("Dados da página:")
para entrada nos dados:
print(entrada)Execute o programa:
python parsel_scraper.pyEste é o resultado esperado:
Incrível! São exatamente os dados da página, mas em um formato estruturado.
Etapa 5: gerenciar a paginação
Até a etapa anterior, você recuperou os dados da página principal do URL de destino. E se agora você quiser recuperar tudo? Para fazer isso, você precisa gerenciar a paginação fazendo algumas alterações no código.
Primeiro, você deve encapsular o código anterior em uma função como esta:
def scrape_page(url):
# Buscar o conteúdo da página
response = requests.get(url)
# Parsing do conteúdo HTML
selector = Selector(text=response.text)
# Lógica de scraping...
return dataAgora, observe o elemento HTML que gerencia a paginação:
Isso inclui uma lista de todas as páginas, cada uma com a URL incorporada em um elemento <a>. Encapsule a lógica para recuperar todas as URLs de paginação em uma função:
def get_all_page_urls(base_url="https://www.scrapethissite.com/pages/forms/"):
# Busque a primeira página para extrair os links de paginação
response = requests.get(base_url)
# Analise a página
selector = Selector(text=response.text)
# Extraia todos os links da página da área de paginação
page_links = selector.css("ul.pagination li a::attr(href)").getall() # Ajuste o seletor com base na estrutura HTML
links_únicos = list(set(links_da_página)) # Remova duplicatas, se houver
# Construa URLs completas para todas as páginas
urls_completas = [urljoin(url_base, link) para link em links_únicos]
retorne urls_completasEsta função faz o seguinte:
- O método
getall()recupera todos os links de paginação. - O método
list(set())remove duplicatas para evitar visitar a mesma página duas vezes. - O método
urljoin(), da bibliotecaurlib.parse, converte todas as URLs relativas em URLs absolutas para que possam ser usadas em outras solicitações HTTP.
Para que o código acima funcione, certifique-se de importar urljoin da biblioteca padrão do Python:
from urllib.parse import urljoin Agora você pode extrair todas as páginas com:
# Onde armazenar os dados extraídos
data = []
# Obter todos os URLs da página
page_urls = get_all_page_urls()
# Itere sobre elas e aplique a lógica de extração
for url in page_urls:
# Extraia a página atual
page_data = scrape_page(url)
# Adicione os dados extraídos à lista
data.extend(page_data)
# Imprima os dados extraídos
print("Dados de todas as páginas:")
for entry in data:
print(entry)O trecho acima:
- Recupera todas as URLs das páginas chamando a função
get_all_page_urls(). - Rastreia os dados de cada página chamando a função
scrape_page(). Em seguida, agrega os resultados com o métodoextend(). - Imprime os dados coletados.
Fantástico! A lógica de paginação do Parsel agora está implementada.
Etapa 6: Junte tudo
Abaixo está o que o arquivo parsel_scraper.py deve conter agora:
import requests
from parsel import Selector
from urllib.parse import urljoin
def scrape_page(url):
# Busca o conteúdo da página
response = requests.get(url)
# Analisa o conteúdo HTML
selector = Selector(text=response.text)
# Onde armazenar os dados coletados
data = []
# Selecionar todas as linhas no corpo da tabela
rows = selector.css("table.table tr.team")
# Iterar sobre cada linha e extrair os dados dela
for row in rows:
# Extrair dados de cada coluna
name = row.css("td.name::text").get()
year = row.css("td.year::text").get()
wins = row.css("td.wins::text").get()
losses = row.css("td.losses::text").get()
ot_losses = row.css("td.ot-losses::text").get()
pct = row.css("td.pct::text").get()
gf = row.css("td.gf::text").get()
ga = row.css("td.ga::text").get()
diff = row.css("td.diff::text").get()
# Anexar os dados extraídos à lista
data.append({
"name": name.strip(),
"year": year.strip(),
"wins": wins.strip(),
"losses": losses.strip(),
"ot_losses": ot_losses.strip(),
"pct": pct.strip(),
"gf": gf.strip(),
"ga": ga.strip(),
"diff": diff.strip(),
})
retornar dados
def obter_todos_os_urls_da_página(url_base="https://www.scrapethissite.com/pages/forms/"):
# Buscar a primeira página para extrair os links de paginação
resposta = requests.get(url_base)
# Analisar a página
seletor = Selector(text=resposta.text)
# Extrair todos os links da página da área de paginação
links_da_página = seletor.css("ul.pagination li a::attr(href)").getall() # Ajustar o seletor com base na estrutura HTML
links_únicos = lista(conjunto(links_da_página)) # Remover duplicatas, se houver
# Construir URLs completas para todas as páginas
full_urls = [urljoin(base_url, link) for link in unique_links]
return full_urls
# Onde armazenar os dados coletados
data = []
# Obter todas as URLs da página
page_urls = get_all_page_urls()
# Iterar sobre elas e aplicar a lógica de extração
para url em page_urls:
# Extrair a página atual
page_data = scrape_page(url)
# Adicionar os dados extraídos à lista
data.extend(page_data)
# Imprimir os dados extraídos
imprimir("Dados de todas as páginas:")
para entrada em data:
imprimir(entrada)Muito bem! Você concluiu seu primeiro projeto de scraping com o Parsel.
Cenários avançados de Scraping de dados com o Parsel em Python
Na seção anterior, você aprendeu a usar o Parsel em Python para extrair os dados de uma página da web alvo usando seletores CSS. É hora de considerar alguns cenários mais avançados!
Selecionar elementos por texto
O Parsel oferece diferentes métodos de consulta para recuperar o texto do HTML usando XPath. Nesse caso, a função text() é usada para extrair o conteúdo de texto de um elemento.
Imagine que você tem um código HTML como este:
<html>
<body>
<h1>Bem-vindo ao Parsel</h1>
<p>Este é um parágrafo.</p>
<p>Outro parágrafo.</p>
</body>
</html>Você pode recuperar todo o texto assim:
from parsel import Selector
html = """
<html>
<body>
<h1>Bem-vindo ao Parsel</h1>
<p>Este é um parágrafo.</p>
<p>Outro parágrafo.</p>
</body>
</html>
"""
selector = Selector(text=html)
# Extrair texto da tag <h1>
h1_text = selector.xpath("//h1/text()").get()
print("Texto H1:", h1_text)
# Extrair texto de todas as tags <p>
p_texts = selector.xpath("//p/text()").getall()
print("Nós de texto do parágrafo:", p_texts)Este trecho localiza as tags <p> e <h1> e extrai o texto delas com text(), resultando em:
Texto H1: Bem-vindo ao Parsel
Nós de texto do parágrafo: ['Este é um parágrafo.', 'Outro parágrafo.']Outra função útil é contains(), que pode ser usada para corresponder elementos que contêm texto específico. Por exemplo, suponha que você tenha um código HTML como este:
<html>
<body>
<p>Este é um parágrafo de teste.</p>
<p>Outro parágrafo de teste.</p>
<p>Conteúdo não relacionado.</p>
</body>
</html>Agora você deseja extrair o texto dos parágrafos que contêm apenas a palavra “teste”. Você pode fazer isso com o seguinte código:
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# Extrair parágrafos que contêm a palavra “teste”
test_paragraphs = selector.xpath("//p[contains(text(), 'test')]/text()").getall()
print("Parágrafos que contêm 'teste':", test_paragraphs)O Xpath p[contains(text(), 'test')]/text() se encarrega de consultar o parágrafo que contém apenas “test”. O resultado será:
Parágrafos que contêm 'teste': ['Este é um parágrafo de teste.', 'Outro parágrafo de teste.']Mas e se você quiser interceptar o texto que começa com um valor específico de uma string? Bem, você pode usar a função starts-with()! Considere este HTML:
<html>
<body>
<p>Comece aqui.</p>
<p>Comece novamente.</p>
<p>Termine aqui.</p>
</body>
</html>Para recuperar o texto dos parágrafos que começam com a palavra “começar”, use p[starts-with(text(), 'Começar')]/text() da seguinte maneira:
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# Extraia os parágrafos cujo texto começa com “Comece”
start_paragraphs = selector.xpath("//p[starts-with(text(), 'Comece')]/text()").getall()
print("Parágrafos que começam com 'Comece':", start_paragraphs)O trecho acima produz:
Parágrafos que começam com 'Iniciar': ['Inicie aqui.', 'Inicie novamente.']Saiba mais sobre seletores CSS vs. XPath.
Usando expressões regulares
O Parsel permite recuperar texto para condições avançadas usando expressões regulares com a função re:test().
Considere este HTML:
<html>
<body>
<p>Item 12345</p>
<p>Item ABCDE</p>
<p>Um parágrafo</p>
<p>2026 é o ano atual</p>
</body>
</html>Para extrair o texto dos parágrafos que contêm apenas valores numéricos, você pode usar re:test() da seguinte maneira:
from parsel import Selector
# html = """..."""
selector = Selector(text=html)
# Extraia os parágrafos cujo texto corresponda a um padrão numérico
numeric_items = selector.xpath("//p[re:test(text(), 'd+')]/text()").getall()
print("Itens numéricos:", numeric_items)O resultado é:
Itens numéricos: ['Item 12345', '2026 é o ano atual']Outro uso típico de expressões regulares é interceptar endereços de e-mail. Isso pode ser usado para extrair texto de parágrafos que contêm apenas endereços de e-mail. Por exemplo, considere o seguinte HTML:
<HTML>
<BODY>
<P>Contate-nos em [email protected]</P>
<P>Envie um e-mail para [email protected]</P>
<P>Não há e-mail aqui.</P>
</BODY>
</HTML>Veja abaixo como você pode usar re:test() para selecionar nós que contêm endereços de e-mail:
from parsel import Selector
selector = Selector(text=html)
# Extrair parágrafos que contêm endereços de e-mail
emails = selector.xpath("//p[re:test(text(), '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}')]/text()").getall()
print("Correspondências de e-mail:", emails)Isso resulta em:
Correspondências de e-mail: ['Contate-nos em [email protected]', 'Envie um e-mail para [email protected]']Navegando pela árvore HTML
O Parsel permite que você navegue pela árvore HTML com XPath, independentemente do nível de aninhamento.
Considere este HTML:
<html>
<body>
<div>
<h1>Título</h1>
<p>Primeiro parágrafo</p>
</div>
</body>
</html>Você pode obter todos os elementos pai do nó <p> desta forma:
from parsel import Selector
selector = Selector(text=html)
# Selecione o pai da tag <p>
parent_of_p = selector.xpath("//p/parent::*").get()
print("Pai de <p>:", parent_of_p)Resultado:
Pai de <p>: <div>
<h1>Título</h1>
<p>Primeiro parágrafo</p>
</div>Da mesma forma, você pode gerenciar elementos irmãos. Suponha que você tenha o seguinte código HTML:
<html>
<body>
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
</body>
</html>Você pode usar following-sibling para recuperar nós irmãos da seguinte maneira:
from parsel import Selector
selector = Selector(text=html)
# Selecione o próximo irmão do primeiro elemento <li>
next_sibling = selector.xpath("//li[1]/following-sibling::li[1]/text()").get()
imprimir("Próximo irmão do primeiro <li>:", próximo_irmão)
# Selecione todos os irmãos do primeiro elemento <li>
todos_irmãos = seletor.xpath("//li[1]/following-sibling::li/text()").getall()
imprimir("Todos os irmãos do primeiro <li>:", todos_irmãos)O que resulta em:
Próximo irmão do primeiro <li>: Item 2
Todos os irmãos do primeiro <li>: ['Item 2', 'Item 3']Alternativas ao Parsel para Parsing de HTML em Python
O Parsel é uma das bibliotecas disponíveis em Python para Scraping de dados, mas não é a única. Abaixo estão outras bibliotecas bem conhecidas e amplamente utilizadas:
- Beautiful Soup: uma biblioteca Python que facilita a extração de informações de páginas da web. Aprenda a usá-la em nosso guia sobre Scraping de dados com Beautiful Soup.
lxml: Uma ligação Pythonic para as bibliotecaslibxml2elibxslt. Veja-a em ação em nosso tutorial sobre lxml para Parsing de dados da web.- PyQuery: uma biblioteca que permite fazer consultas jQuery em documentos XML. Isso a torna um dos 5 melhores analisadores HTML do Python.
- Scrapy: uma estrutura colaborativa e de código aberto para extrair os dados necessários de sites. Veja como usar o Scrapy para Scraping de dados.
html.parser: Um módulo da Biblioteca Padrão Python que fornece uma classe para realizar Parsing de conteúdo HTML e XTHML de texto.html5-parser: Uma implementação rápida do HTML 5 em Python.
Conclusão
Neste artigo, você aprendeu sobre o Parsel em Python e como usá-lo para Scraping de dados. Você começou com o básico e depois explorou cenários mais complexos.
Independentemente da biblioteca de scraping Python que você usa, o maior obstáculo é que a maioria dos sites protege seus dados com medidas anti-bot e anti-scraping. Essas defesas podem identificar e bloquear solicitações automatizadas, tornando as técnicas tradicionais de scraping ineficazes.
Felizmente, a Bright Data oferece um conjunto de soluções para evitar qualquer problema:
- Web Unlocker: uma API que contorna as proteções anti-scraping e fornece HTML limpo de qualquer página da web com o mínimo de esforço.
- Navegador de scraping: um navegador controlável baseado em nuvem com renderização JavaScript. Ele lida automaticamente com CAPTCHAs, impressões digitais do navegador, novas tentativas e muito mais para você. Ele se integra perfeitamente com Panther ou Selenium PHP.
- Web Scraper APIs: pontos finais para acesso programático a dados estruturados da web de dezenas de domínios populares.
Não quer lidar com Scraping de dados, mas ainda está interessado em dados online? Explore nossos conjuntos de dados prontos para uso!
Inscreva-se agora na Bright Data e comece seu teste grátis para experimentar nossas soluções de scraping.





