

Neste guia, você aprenderá:
- O que é
o curl_cffie os recursos que ele oferece - Como ele minimiza a detecção de bots baseada em impressão digital TLS
- Como usá-lo com Python para Scraping de dados
- Uso e métodos avançados
- Uma comparação com clientes HTTP semelhantes
Vamos começar!
O que é curl_cffi?
curl_cffi é uma biblioteca que fornece ligações Python para o fork curl-impersonate via CFFI. Em outras palavras, é um cliente HTTP capaz de se passar por impressões digitais TLS/JA3/HTTP2 do navegador. Isso torna a biblioteca uma excelente solução para contornar bloqueios anti-bot baseados em impressões digitais TLS.
⚙️ Recursos
- Suporta a simulação de impressões digitais JA3/TLS e HTTP2, incluindo navegadores recentes e impressões digitais personalizadas
- Muito mais rápido que
requestsehttpx, equivalente aoaiohttp - Imita a API
de solicitações - Suporta
asynciopara solicitações HTTP assíncronas - Suporte para rotação de Proxy em cada solicitação
- Suporta HTTP/2.0
- Suporta
WebSockets
Como funciona
O curl_cffi é baseado no cURL Impersonate, uma biblioteca que gera impressões digitais TLS correspondentes a navegadores reais.
Quando você envia uma solicitação HTTPS, ocorre um handshake TLS, produzindo uma impressão digital TLS exclusiva. Como os clientes HTTP diferem dos navegadores, suas impressões digitais podem expor a automação, acionando defesas anti-bot.
O cURL Impersonate modifica o cURL para corresponder às impressões digitais TLS dos navegadores reais:
- Ajustes na biblioteca TLS: confie nas bibliotecas para conexão TLS usadas pelos navegadores em vez daquelas do cURL.
- Alterações de configuração: ajuste as extensões TLS e as opções SSL para imitar os navegadores.
- Personalização HTTP/2: corresponda às configurações de handshake do navegador.
- Sinalizadores cURL não padrão: defina
--ciphers,--curvese cabeçalhos personalizados para maior precisão.
Isso faz com que as solicitações pareçam semelhantes às do navegador, ajudando a contornar a detecção de bots. Para obter mais informações, consulte nosso guia sobre o cURL Impersonate.
Como usar o curl_cffi para Scraping de dados: guia passo a passo
Suponha que seu objetivo seja fazer o scraping da página “Teclado” do Walmart:
Se você tentar acessar essa página usando qualquer cliente HTTP, receberá a seguinte página de erro:
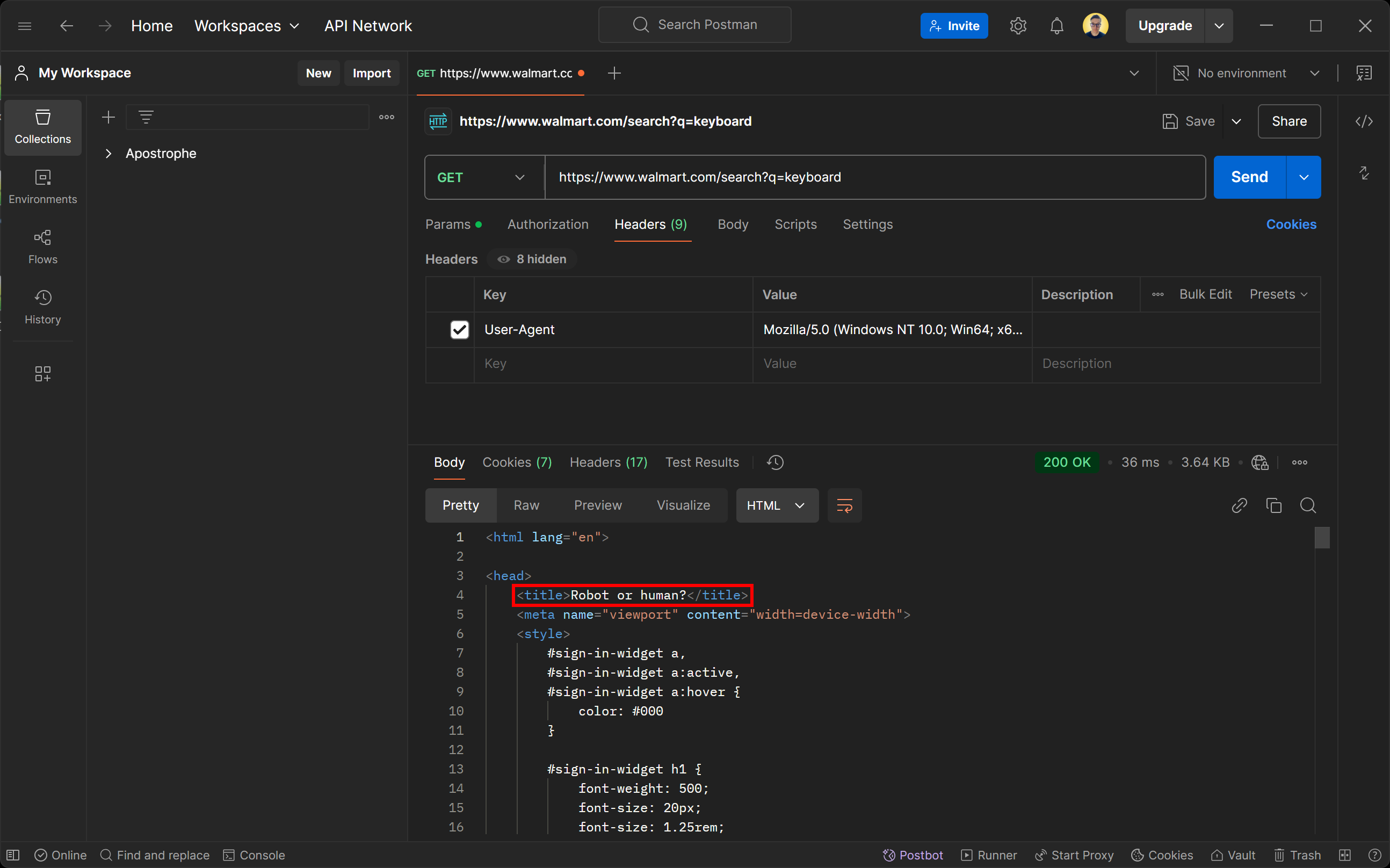
Não se deixe enganar pelo status de resposta 200 OK. A página retornada pelo servidor do Walmart é, na verdade, uma página de detecção de bots. Ela solicita especificamente que você verifique se é humano com um desafio CAPTCHA.
Você pode se perguntar: como isso é possível, mesmo se você definir o User-Agent para simular um navegador real? A resposta é a impressão digital TLS!
Agora, vamos ver como usar o curl_cffi para evitar medidas anti-bot e realizar Scraping de dados com facilidade.
Etapa 1: Configuração do projeto
Primeiro, certifique-se de que você tenha o Python 3+ instalado em sua máquina. Caso contrário, baixe-o do site oficial e siga as instruções de instalação.
Em seguida, crie um diretório para o seu projeto de scraping curl_cffi usando este comando:
mkdir curl-cfii-scraper
Navegue até esse diretório e configure um ambiente virtual dentro dele:
cd curl-cfii-Scraper
python -m venv env
Abra a pasta do projeto em seu IDE Python preferido. O Visual Studio Code com a extensão Python ou o PyCharm Community Edition são opções válidas.
Agora, crie um arquivo scraper.py dentro da pasta do projeto. Ele estará vazio no início, mas você logo adicionará a lógica de scraping a ele.
No terminal do seu IDE, ative o ambiente virtual. No Linux ou macOS, use:
./env/bin/activate
De forma equivalente, no Windows, execute:
env/Scripts/activate
Ótimo! Você está pronto para começar.
Etapa 2: Instale o curl_cffi
Em um ambiente virtual ativado, instale o cliente HTTP por meio do pacote pip curl-cffi:
pip install curl-cffi
Nos bastidores, essa biblioteca baixa automaticamente os binários de representação do curl para Windows, macOS e Linux.
Etapa 3: Conecte-se à página de destino
Importe solicitações do curl_cffi:
from curl_cffi import requests
Este objeto expõe uma API de alto nível semelhante à da biblioteca Python Requests.
Você pode usá-la para realizar uma solicitação HTTP GET para a página de destino da seguinte maneira:
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")
O argumento impersonate="chrome" diz ao curl_cffi para fazer com que a solicitação HTTP pareça ter sido enviada pela versão mais recente do Chrome. Como resultado, o Walmart tratará a solicitação automatizada como uma solicitação normal do navegador, retornando a página da web padrão em vez de uma página anti-bot.
Você pode acessar o conteúdo HTML da página de destino com:
html = resposta.texto
Se você imprimir html, verá:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charSet="utf-8"/>
<meta property="fb:app_id" content="105223049547814"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1, interactive-widget=resizes-content"/>
<link rel="dns-prefetch" href="https://tap.walmart.com "/>
<link rel="preload" fetchpriority="high" crossorigin="anonymous" href="https://i5.walmartimages.com/dfw/63fd9f59-a78c/fcfae9b6-2f69-4f89-beed-f0eeb4237946/v1/BogleWeb_subset-Bold.woff2" as="font" type="font/woff2"/>
<link rel="preload" fetchpriority="high" crossorigin="anonymous" href="https://i5.walmartimages.com/dfw/63fd9f59-a78c/fcfae9b6-2f69-4f89-beed-f0eeb4237946/v1/BogleWeb_subset-Regular.woff2" as="font" type="font/woff2"/>
<link rel="preconnect" href="https://beacon.walmart.com"/>
<link rel="preconnect" href="https://b.wal.co"/>
<title>Electrónica - Walmart.com</title>
<!-- omitido por motivos de concisão ... -->
Ótimo! Esse é o HTML da página normal do produto “teclado” do Walmart.
Etapa 4: Adicione a lógica de extração de dados
O curl_cffi é apenas um cliente HTTP que ajuda a recuperar o HTML de uma página. Se você quiser fazer Scraping de dados, também precisará de uma biblioteca para Parsing de HTML, como o BeautifulSoup. Para obter mais orientações, consulte nosso guia sobre Scraping de dados com o BeautifulSoup.
No ambiente virtual ativado, instale o BeautifulSoup:
pip install beautifulsoup4
Importe-o em scraper.py:
from bs4 import BeautifulSoup
Em seguida, use-o para realizar o Parsing do HTML da página:
soup = BeautifulSoup(response.text, "html.parser")
"html.parser" é o analisador HTML padrão da biblioteca padrão do Python usado pelo BeautifulSoup para realizar o Parsing da string HTML. Agora, soup contém todos os métodos necessários para selecionar elementos HTML na página e extrair dados deles.
Neste exemplo, como o Parsing não é o mais importante, vamos extrair apenas o título da página. Você pode selecioná-lo por meio de um seletor CSS usando o método find() e, em seguida, acessar seu texto com o atributo text:
title_element = soup.find("title")
title = title_element.text
Para uma lógica de extração mais avançada, consulte nosso guia sobre como extrair dados do Walmart.
Por fim, imprima o título da página:
print(title)
Ótimo! Você implementou a lógica básica de Scraping de dados.
Etapa 5: Junte tudo
Este é o seu script final de Scraping de dados da web curl_cffi:
from curl_cffi import requests
from bs4 import BeautifulSoup
# Envie uma solicitação GET para a página de pesquisa do Walmart para “keyboard”
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")
# Extraia o HTML da página
html = response.text
# Analise o conteúdo da resposta com BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Encontre a tag de título usando um seletor CSS e imprima-a
title_element = soup.find("title")
# Extraia os dados dela
title = title_element.text
# Lógica de scraping mais complexa...
# Imprima os dados extraídos
print(title)
Inicie com o seguinte comando:
python3 Scraper.py
Ou, de forma equivalente, no Windows:
python Scraper.py
O resultado será:
Eletrônicos - Walmart.com
Se você remover o argumento impersonate="chrome", obterá:
Robô ou humano?
Isso demonstra como a simulação do navegador faz toda a diferença quando se trata de evitar medidas anti-scraping.
Missão cumprida!
curl_cffi: uso avançado
Agora que você sabe como a biblioteca funciona, está pronto para explorar alguns cenários mais avançados.
Seleção de representação do navegador
O curl_cffi suporta a simulação de vários navegadores. Cada navegador está associado a um rótulo exclusivo que você pode passar para o argumento de simulação, conforme abaixo:
response = requests.get("<SUA_URL>", impersonate="<RÓTULO_DO_NAVEGADOR>")
Aqui estão os rótulos para os navegadores suportados:
chrome99,chrome100,chrome101,chrome104,chrome107,chrome110,chrome116,chrome119,chrome120,chrome123,chrome124,chrome131chrome99_android,chrome131_androidedge99,edge101safari15_3,safari15_5,safari17_0,safari17_2_ios,safari18_0,safari18_0_ios
Observações:
- Para sempre simular as versões mais recentes dos navegadores, basta usar
chrome,safariesafari_ios. - O Firefox não está disponível no momento, pois apenas navegadores baseados em WebKit são suportados.
- As versões do navegador são adicionadas apenas quando suas impressões digitais são alteradas. Se uma versão, como
chrome122, for ignorada, você ainda poderá representá-la usando os cabeçalhos da versão anterior. - Para destinos que não sejam navegadores, use
ja3,akamaie argumentos semelhantes para especificar suas próprias impressões digitais TLS personalizadas. Para obter detalhes, consulte a documentação sobre representação.
Gerenciamento de sessão
Assim como a biblioteca de solicitações, o curl-cfii oferece suporte a sessões. Os objetos de sessão permitem que você mantenha determinados parâmetros em várias solicitações, como cookies, cabeçalhos ou outros dados específicos da sessão.
Veja como você pode definir uma sessão usando as ligações Python para a biblioteca cURL Impersonate:
# Criar uma nova sessão
session = requests.Session()
# Este endpoint define um cookie no servidor
session.get("https://httpbin.io/cookies/set/userId/5", impersonate="chrome")
# Imprimir os cookies da sessão para confirmar que eles estão sendo armazenados
print(session.cookies)
A saída do script acima será:
<Cookies[<Cookie userId=5 para httpbin.org />]>
O resultado prova que a sessão está mantendo o estado entre as solicitações, como o armazenamento de cookies definidos pelo servidor.
Integração de Proxy
Assim como a biblioteca de solicitações, o curl_cffi oferece suporte à integração de Proxy por meio de um objeto Proxy:
# Defina sua URL de Proxy
proxy = "SUA_URL_DE_PROXY"
# Crie um dicionário de proxies para HTTP e HTTPS
proxies = {"http": proxy, "https": proxy}
# Faça uma solicitação usando um Proxy e a simulação do navegador
response = requests.get("<YOUR_URL>", impersonate="chrome", proxies=proxies)
Como as APIs subjacentes são muito semelhantes às solicitações, consulte nosso guia sobre como usar um Proxy em Solicitações.
API assíncrona
O curl_cffi suporta solicitações assíncronas por meio do asyncio através do objeto AsyncSession:
from curl_cffi.requests import AsyncSession
import asyncio
# Defina uma função assíncrona para executar o código assíncrono
async def fetch_data():
async with AsyncSession() as session:
# Execute a solicitação GET assíncrona
response = await session.get("https://httpbin.org/anything", impersonate="chrome")
# Imprimir o texto da resposta
print(response.text)
# Executar a função assíncrona
asyncio.run(fetch_data())
O uso do AsyncSession facilita o tratamento eficiente de várias solicitações assíncronas, o que é vital para acelerar o Scraping de dados.
Conexão WebSockets
O curl_cffi também oferece suporte a WebSocketspor meio da classe WebSocket:
from curl_cffi.requests import WebSocket
# Defina uma função de retorno de chamada para lidar com mensagens recebidas
def on_message(ws, message):
print(message)
# Inicialize a conexão WebSocket com o callback
ws = WebSocket(on_message=on_message)
# Conecte-se a um servidor WebSocket de amostra e aguarde mensagens
ws.run_forever("wss://api.gemini.com/v1/marketdata/BTCUSD")
Isso é particularmente útil para extrair dados em tempo real de sites ou APIs que usam WebSocket para preencher dados dinamicamente. Alguns exemplos são sites com dados do mercado financeiro, resultados esportivos ao vivo ou chats ao vivo.
Em vez de coletar páginas renderizadas, você pode direcionar diretamente o canal WebSocket para uma recuperação eficiente dos dados.
Observação: você pode usar WebSocketsde forma assíncrona graças à classe AsyncWebSocket.
curl_cffi vs Requests vs AIOHTTP vs HTTPX para Scraping de dados
Abaixo está uma tabela resumida para comparar o curl_cffi com outros clientes HTTP Python populares para Scraping de dados:
| Recurso | curl_cffi | Requests | AIOHTTP | HTTPX |
|---|---|---|---|---|
| API de sincronização | ✔️ | ✔️ | ❌ | ✔️ |
| API assíncrona | ✔️ | ❌ | ✔️ | ✔️ |
Suporte para **WebSockets** |
✔️ | ❌ | ✔️ | ❌ |
| Pool de conexões | ✔️ | ✔️ | ✔️ | ✔️ |
| Suporte para HTTP/2 | ✔️ | ❌ | ❌ | ✔️ |
Personalização do **User-Agent** |
✔️ | ✔️ | ✔️ | ✔️ |
| Falsificação de impressão digital TLS | ✔️ | ❌ | ❌ | ❌ |
| Velocidade | Alta | Média | Alta | Média |
| Mecanismo de repetição | ❌ | Disponível via HTTPAdapters |
Disponível apenas por meio de uma biblioteca de terceiros | Disponível via transportesintegrados |
| Integração de Proxy | ✔️ | ✔️ | ✔️ | ✔️ |
| Tratamento de cookies | ✔️ | ✔️ | ✔️ | ✔️ |
Alternativasao curl_cffi para Scraping de dados
O curl_cffi envolve uma abordagem manual para Scraping de dados, na qual você precisa escrever a maior parte do código sozinho. Embora seja adequado para sites estáticos simples, ele tende a apresentar desafios quando se trata de sites dinâmicos ou mais seguros.
A Bright Data oferece uma variedade de alternativas ao curl_cffi para Scraping de dados:
- API do navegador de scraping: instâncias de navegador em nuvem totalmente gerenciadas integradas com Puppeteer, Selenium e Playwright. Esses navegadores oferecem Resolução de CAPTCHA integrada e Proxy rotativo, contornando as defesas anti-bot enquanto interagem com sites como usuários reais.
- Web Scraper APIs: pontos de extremidade pré-configurados para recuperar dados novos e estruturados de mais de 100 domínios populares. Essas APIs são éticas e compatíveis, permitindo a fácil extração de dados usando HTTPX ou qualquer outro cliente HTTP.
- No-Code Scraper: um serviço intuitivo de coleta de dados sob demanda que elimina a necessidade de codificação. Ele oferece controle, escalabilidade e flexibilidade sem lidar com infraestrutura, Proxies ou obstáculos anti-scraping.
- Conjuntos de dados: acesse conjuntos de dados pré-construídos de vários sites ou personalize coleções de dados para atender às suas necessidades.
Essas soluções simplificam a extração de dados, oferecendo ferramentas robustas, escaláveis e em conformidade que reduzem o esforço manual.
Conclusão
Neste artigo, você descobriu como usar a biblioteca curl_cffi para Scraping de dados. Você explorou sua finalidade, principais recursos e vantagens. Este cliente HTTP se destaca como uma opção rápida e confiável para fazer solicitações que imitam navegadores reais.
No entanto, as solicitações HTTP automatizadas podem expor seu endereço IP público, revelando potencialmente sua identidade e localização, o que representa um risco à privacidade. Para proteger sua segurança e anonimato, uma das soluções mais eficazes é usar um Proxy para ocultar seu endereço IP.
A Bright Data controla os melhores servidores Proxy do mundo, atendendo empresas da Fortune 500 e mais de 20.000 clientes. Sua oferta inclui uma ampla variedade de tipos de Proxy:
- Proxies de datacenter – Mais de 770.000 IPs de datacenter.
- Proxies residenciais – Mais de 72 milhões de IPs residencialis em mais de 195 países.
- Proxy ISP – Mais de 700.000 IPs de ISP.
Crie hoje mesmo uma conta gratuita na Bright Data para testar nossos Proxies e soluções de scraping!




