

Nesta postagem do blog, você aprenderá:
- Por que o TensorFlow é uma ferramenta ideal para análise de dados por meio de aprendizado de máquina.
- Em quais soluções você deve confiar para coletar dados de alta qualidade que forneçam insights valiosos para o seu negócio.
- Como utilizar o TensorFlow para realizar análises de sentimentos em avaliações de produtos da Amazon recuperadas via Bright Data.
Vamos começar!
Por que analisar dados através do TensorFlow usando aprendizado de máquina
Os dados são valiosos devido às informações que ajudam a obter. Isso é especialmente verdadeiro para empresas, que utilizam dados para tomar decisões, ajustar estratégias e otimizar resultados. Os objetivos comuns incluem melhorar a satisfação do cliente e otimizar o desempenho geral das estratégias de marketing.
Quando se trata de análise de dados, o TensorFlow é uma das bibliotecas de código aberto mais populares. Ele alimenta sistemas de aprendizado de máquina e inteligência artificial, oferecendo suporte a uma ampla gama de tarefas.
Neste artigo, utilizaremos o TensorFlow para realizar análises de sentimento em avaliações de produtos. Ao mesmo tempo, a mesma tecnologia pode ser aplicada a muitos outros casos de uso, como análise de feedback do cliente, sistemas de recomendação, modelagem preditiva e outros.
Como recuperar dados da sua empresa
Não importa o quão avançado seja seu pipeline de aprendizado de máquina ou inteligência artificial, todos os analistas de dados sabem que“mais dados superam melhores algoritmos”. Simplificando, a chave para obter insights significativos é a qualidade e a quantidade dos dados.
Mas como você obtém muitos dados bons? A obtenção de dados pode ser um desafio, e é importante contar com provedores de dados confiáveis, como a Bright Data.
A Bright Data oferece uma ampla gama de soluções de dados, incluindo:
- API Web Scraper: acesso programático a dados estruturados da web de dezenas de domínios populares, recuperados por meio do Scraping de dados.
- Dataset Marketplace: Conjuntos de dados atualizados e prontos para uso, com bilhões de entradas de mais de 100 sites.
- Serviços gerenciados de aquisição de dados: serviços de coleta de dados totalmente gerenciados e de nível empresarial, permitindo que você obtenha dados e insights sem o incômodo de desenvolvimento ou manutenção.
Esses produtos atendem a pesquisadores, PMEs (pequenas e médias empresas) e grandes empresas. Em detalhes, eles permitem a coleta de dados públicos da web para alimentar fluxos de trabalho de aprendizado de máquina, treinamento de IA, desenvolvimento de agentes e uma longa lista de outros cenários.
Como realizar uma análise de sentimentos em avaliações de produtos da Amazon recuperadas via Bright Data
Nesta seção passo a passo, você usará o TensorFlow para criar um fluxo de trabalho de análise de dados do mundo real. Abordaremos o caso de uso prático da realização de análises de sentimentos em avaliações de produtos.
Suponha que você seja uma empresa que vende vários produtos na Amazon. Para melhorar a satisfação do cliente, você precisa de um processo que monitore periodicamente as avaliações deixadas pelos usuários para cada produto e execute análises de sentimento para entender o que está funcionando bem e o que precisa ser melhorado.
Neste exemplo, vamos nos concentrar no seguinte produto da Amazon:
Observação: você pode estender esse fluxo de trabalho para vários produtos da Amazon, pois o Bright Data Amazon Reviews Scraper suporta a extração de avaliações de vários produtos com escalabilidade ilimitada.
Este é um ótimo exemplo, pois tem um grande número de avaliações que estão razoavelmente distribuídas entre todas as 5 estrelas: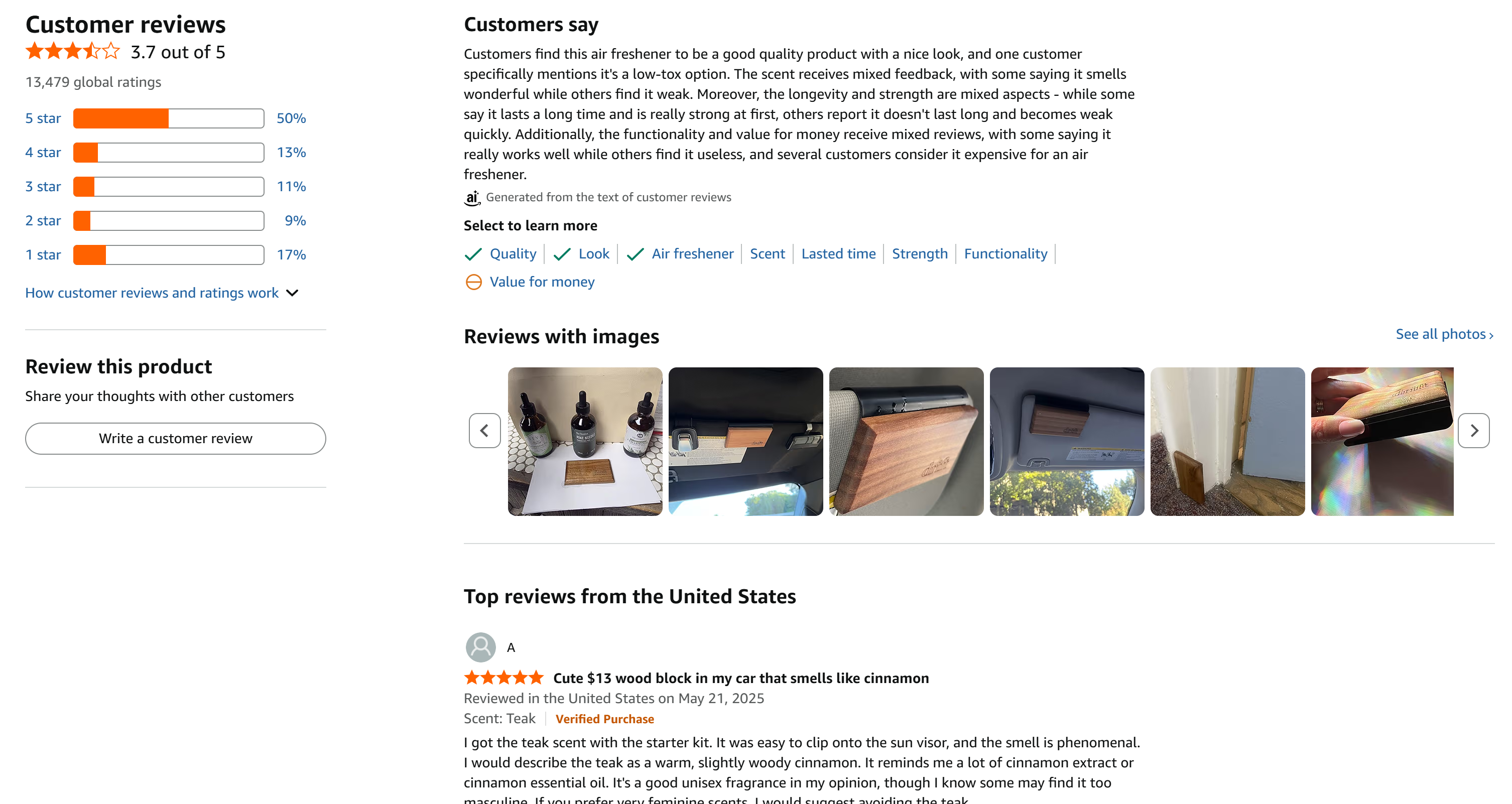
Siga as instruções abaixo para criar um processo de análise de sentimentos pronto para uso empresarial. As avaliações do produto serão recuperadas via Bright Data e, em seguida, analisadas usando fluxos de trabalho de aprendizado de máquina no TensorFlow com Python.
Pré-requisitos
Para acompanhar este tutorial, certifique-se de ter:
- Python 3.9+ instalado localmente.
- Uma conta Bright Data com uma chave API configurada.
Não se preocupe se ainda não tiver uma conta Bright Data, pois você será orientado durante o processo de configuração nas etapas a seguir.
Familiaridade com o modelo Universal Sentence Encoder, como funcionam as incorporações vetoriais e como operam os modelos Keras Sequential com camadas densas de redes neurais será muito útil para compreender totalmente a lógica do TensorFlow para análise de sentimentos.
Etapa 1: Configure um projeto JupyterLab
Como esse processo de aprendizado de máquina do TensorFlow também envolverá gráficos e visualização de dados, faz sentido usar o JupyterLab como ambiente de desenvolvimento. Assim, o código pode ser facilmente migrado para um pipeline de ML pronto para produção.
Primeiro, comece criando uma pasta de projeto. Navegue até ela:
mkdir tensorflow-brightdata-product-review-analysis
cd tensorflow-brightdata-product-review-analysisEm seguida, inicialize um ambiente virtual dentro da pasta:
python -m venv .venvHora de ativar o ambiente virtual. No macOS/Linux, execute:
source .venv/bin/activateOu, no Windows, execute:
.venvScriptsactivateNo ambiente ativo, instale o JupyterLab através do pacote jupyterlab:
pip install jupyterlabContinue iniciando o JupyterLab com:
jupyter labVocê verá a interface do JupyterLab:
Defina um novo notebook clicando no botão “Python 3 (ipykernel)” na seção “Notebook”:
Dê um nome ao seu notebook e salve-o.
Pronto! Agora você tem um ambiente Python configurado, ideal para desenvolver fluxos de trabalho de análise de dados de aprendizado de máquina usando o TensorFlow.
Etapa 2: Instale as bibliotecas
Adicione um bloco de código e instale as bibliotecas necessárias com:
!pip install tensorflow tensorflow-hub scikit-learn pandas numpy matplotlib requestsExecute este bloco para instalar todas as bibliotecas necessárias para esta implementação:
tensorflow: para construir e treinar modelos de aprendizado de máquina.tensorflow-hub: para carregar modelos de aprendizado de máquina pré-treinados.scikit-learn: para pré-processamento de dados, divisão de treinamento-teste, métricas e ponderação de classes.pandas: para lidar com dados tabulares e realizar agregações.numpy: para cálculos numéricos e manipulação de matrizes.matplotlib: Para plotar gráficos e visualizar resultados.requests: Para realizar solicitações HTTP e interagir com a API Bright Data Scraper.
Em seguida, adicione outro bloco de código para importar e configurar todas as bibliotecas necessárias:
import time
import requests
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_hub como hub
de tensorflow import keras
de keras.layers import Input, Dense, Dropout
de keras.models import Sequential
de sklearn.model_selection import train_test_split
de sklearn.metrics import classification_report
de sklearn.utils.class_weight import compute_class_weight
de IPython.display import display, HTML
plt.rcParams["figure.figsize"] = (10, 5)Incrível! Com isso, todos os seus blocos de código subsequentes estarão prontos para alimentar a recuperação do Bright Data e os fluxos de trabalho de análise baseados no TensorFlow.
Etapa 3: Comece a usar o Bright Data Amazon Reviews Scraper
Antes de escrever o código para recuperar os dados das avaliações da Amazon, reserve um tempo para configurar sua conta Bright Data e se familiarizar com a solução de scraping de dados necessária.
Neste tutorial, vamos usar a API Bright Data Amazon Reviews, que permite coletar programaticamente dados de avaliações recentes para um determinado produto. Isso é ideal se você deseja monitorar as avaliações dos seus próprios produtos.
Alternativamente, para cenários mais gerais, a Bright Data também fornece um conjunto de dados pronto para usochamado “Amazon Reviews”com mais de 28,6 milhões de avaliações: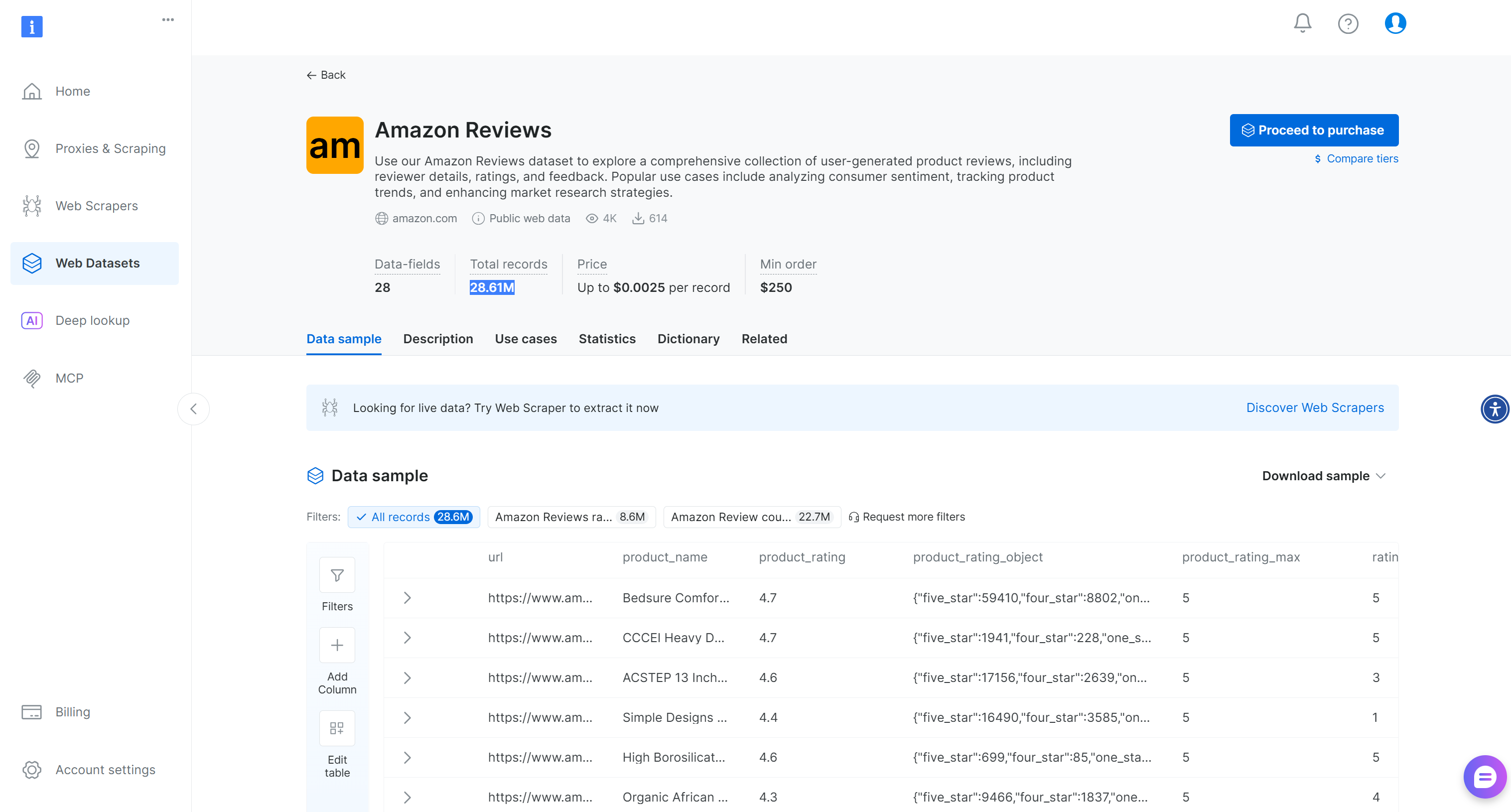
Agora, se você ainda não tem uma conta Bright Data, crie uma. Caso contrário, faça login e navegue até a página“Biblioteca de Scrapers”da sua conta:
Procure por “amazon” e selecione o Scraper “Amazon Reviews – collect by URL”:
Nesta página, você pode ver como gerar um código pronto para integração ou experimentar o Scraper diretamente através do aplicativo web sem código.
Selecione a opção “API do Scraper” e você chegará à página abaixo:
Aqui, revise os parâmetros de entrada suportados e o formato de saída. Em particular, este conjunto de dados retorna uma lista de avaliações da Amazon e tem o ID gd_le8e811kzy4ggddlq.
Para chamar este Scraper via API, você deve autenticar suas solicitações usando sua chave API da Bright Data. Se você não tiver uma, siga o guia oficial para gerá-la. Guarde-a em um local seguro, pois você precisará dela em breve.
Ótimo! Agora você está pronto para usar o Scraper de avaliações da Amazon da Bright Data e recuperar dados de avaliações de produtos para análise.
Etapa 4: Recuperar os dados das avaliações de produtos da Amazon
Crie uma nova célula no notebook e cole o seguinte código:
BRIGHT_DATA_API_KEY = "<SUA_CHAVE_API_BRIGHT Data>" # Substitua pela sua chave API Bright Data
def trigger_snapshot(amazon_product_url):
# Acione a API Bright Data Web Scraper para uma determinada URL de produto da Amazon
url = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_le8e811kzy4ggddlq", # ID do Scraper "Amazon Reviews - collect by URL"
"include_errors": "true",
}
# Formate os dados de entrada para a chamada da API
data = [{"url": amazon_product_url}]
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", # Autentique a solicitação
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Solicitação bem-sucedida! ID do instantâneo: {snapshot_id}")
return snapshot_id
else:
print(f"Solicitação falhou! Código de status: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(snapshot_id, output_file, format="csv", polling_timeout=20):
# Pesquise a API Bright Data Scraper até que o instantâneo esteja pronto e, em seguida, salve-o
snapshot_url = f"https://api.brightdata.com/conjuntos de dados/v3/snapshot/{snapshot_id}?format={format}"
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"}
imprimir(f"Consultando instantâneo para ID: {snapshot_id}...")
enquanto Verdadeiro:
resposta = solicitações.obter(snapshot_url, cabeçalhos=cabeçalhos)
se resposta.status_code == 200:
imprimir("Instantâneo está pronto. Baixando...")
snapshot_data = resposta.texto
# Gravar o instantâneo em um arquivo
with open(output_file, "w", encoding="utf-8") as file:
file.write(snapshot_data)
print(f"Instantâneo salvo em {output_file}")
return
elif response.status_code == 202:
print(f"Instantâneo ainda não está pronto. Repetindo em {polling_timeout} segundos...")
time.sleep(polling_timeout)
else:
print(f"Solicitação falhou! Código de status: {response.status_code}")
print(response.text)
break
# URL do produto Amazon para recuperar avaliações
amazon_product_url = "https://www.amazon.com/Drift-Car-Air-Freshener-Eliminator/dp/B0C1HJV7BJ/"
# Acionar instantâneo e baixar avaliações
snapshot_id = trigger_snapshot(amazon_product_url)
poll_and_retrieve_snapshot(snapshot_id, "product-reviews.csv")Substitua o espaço reservado <YOUR_BRIGHT_DATA_API_KEY> pela sua chave API Bright Data real gerada anteriormente.
O código acima:
- Aciona o scraper de avaliações usando
os Conjuntos de dados/v3/trigger, que inicia um trabalho de scraping na nuvem da Bright Data usando o scraper de avaliações da Amazon. - Pesquisa o snapshot do conjunto de dados gerado usando
conjuntos de dados/v3/snapshot/{snapshot_id}, aguardando até que a Bright Data termine de coletar as avaliações. - Exporta os dados finais como um CSV (porque
format="csv"está especificado) e os salva localmente emproduct-reviews.csv.
É exatamente assim que funciona o fluxo de trabalho da API Web Scraper. Para obter mais detalhes, consulte a documentação oficial da Bright Data.
Ao executar o bloco de código, você deverá ver algo semelhante a: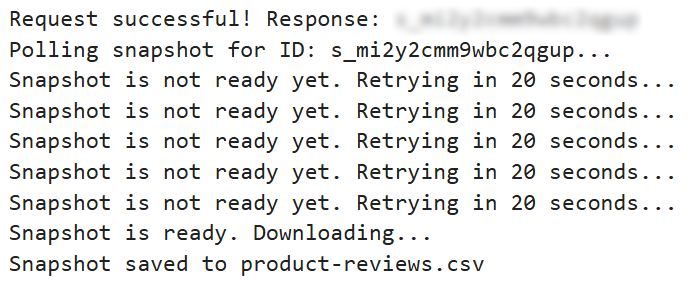
Em seguida, um arquivo product-reviews.csv aparecerá na pasta do seu projeto. Abra-o e você verá as avaliações coletadas em formato estruturado: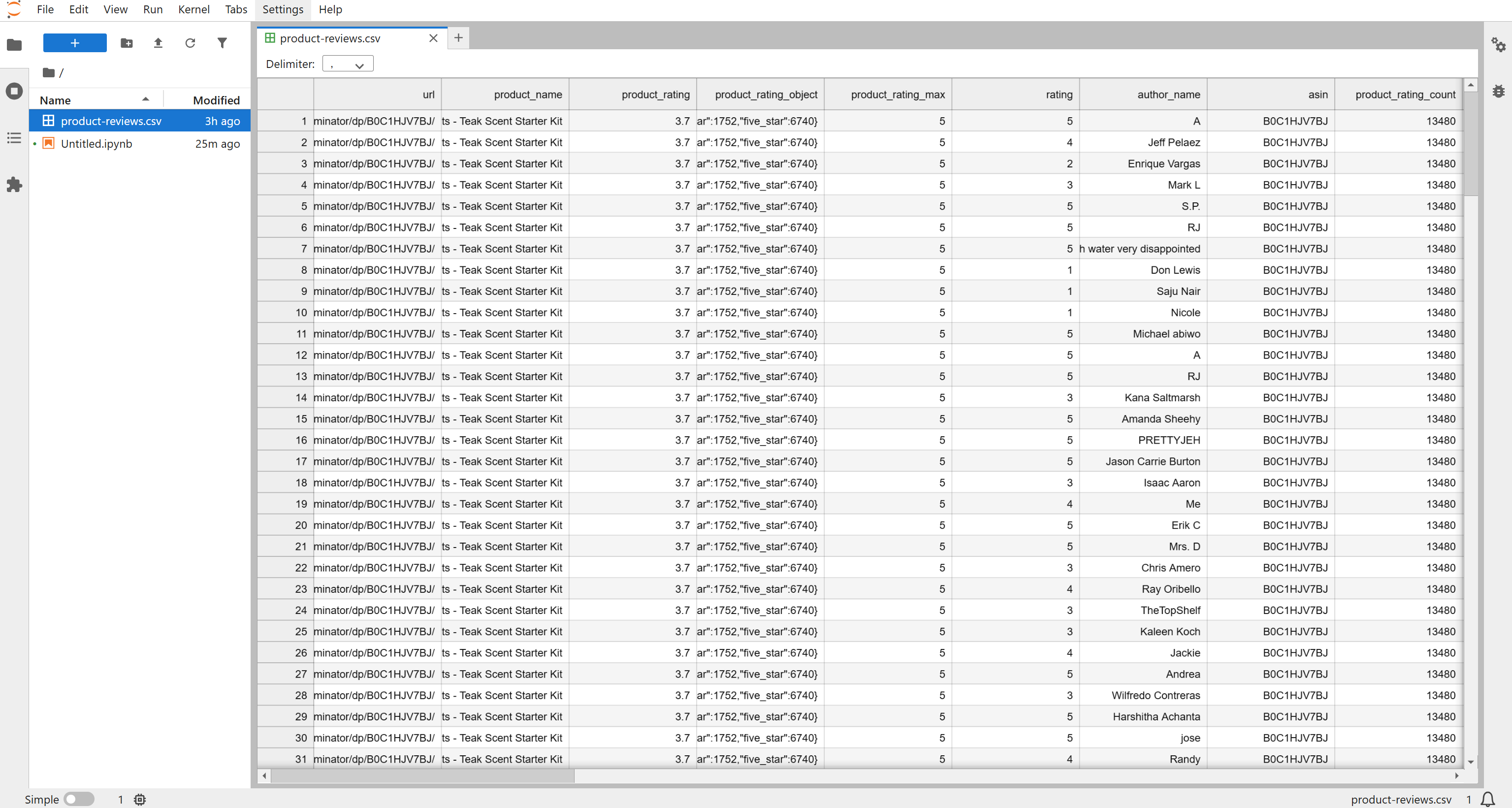
Por padrão, o Scraper retorna as últimas ~200 avaliações, mas você pode ajustar as entradas da API para obter mais, se necessário. Para este tutorial, as 196 avaliações recuperadas são mais do que suficientes para concluir o pipeline de análise de sentimentos.
Ótimo! Agora você tem dados recentes de avaliações de produtos da Amazon prontos para análise no TensorFlow.
Etapa 5: explore os dados coletados
Comece carregando os dados coletados do arquivo product-reviews.csv:
# Carregue as avaliações de produtos do arquivo CSV gerado via Bright Data
df = pd.read_csv("product-reviews.csv")
# Converta as datas de publicação das avaliações para datetime
df["date"] = pd.to_datetime(df["review_posted_date"])
# Excluir avaliações com texto ausente
df = df.dropna(subset=["review_text"])
# Classificar as avaliações por data de publicação (ascendente)
df = df.sort_values(by="date", ascending=True)
print(f"Carregadas {len(df)} avaliações.")Execute esta célula e você verá o número total de avaliações carregadas:
Carregadas 196 avaliações.Em seguida, analise a distribuição das classificações:
print(df["rating"].value_counts())Você deve obter algo semelhante a:
classificação
1 74
2 31
3 16
4 12
5 63Como mostrado acima, as avaliações estão distribuídas de maneira bastante uniforme na faixa de 1 a 5 estrelas. Para visualizar melhor essa distribuição, use um gráfico de barras com o Matplotlib:
# Calcule o número de avaliações por classificação (1 a 5 estrelas)
rating_counts = df["rating"].value_counts().sort_index()
# Trace a distribuição das classificações como um gráfico de barras
colors = plt.cm.RdYlGn(np.linspace(0, 1, len(rating_counts)))
plt.bar(
rating_counts.index,
rating_counts.values,
color=colors,
edgecolor="black",
width=0.6,
align="center"
)
plt.title("Distribuição das classificações (1–5 estrelas)")
plt.xlabel("Estrelas")
plt.ylabel("Contagem")
plt.xticks(rating_counts.index)
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.show()Você obterá um gráfico semelhante ao abaixo: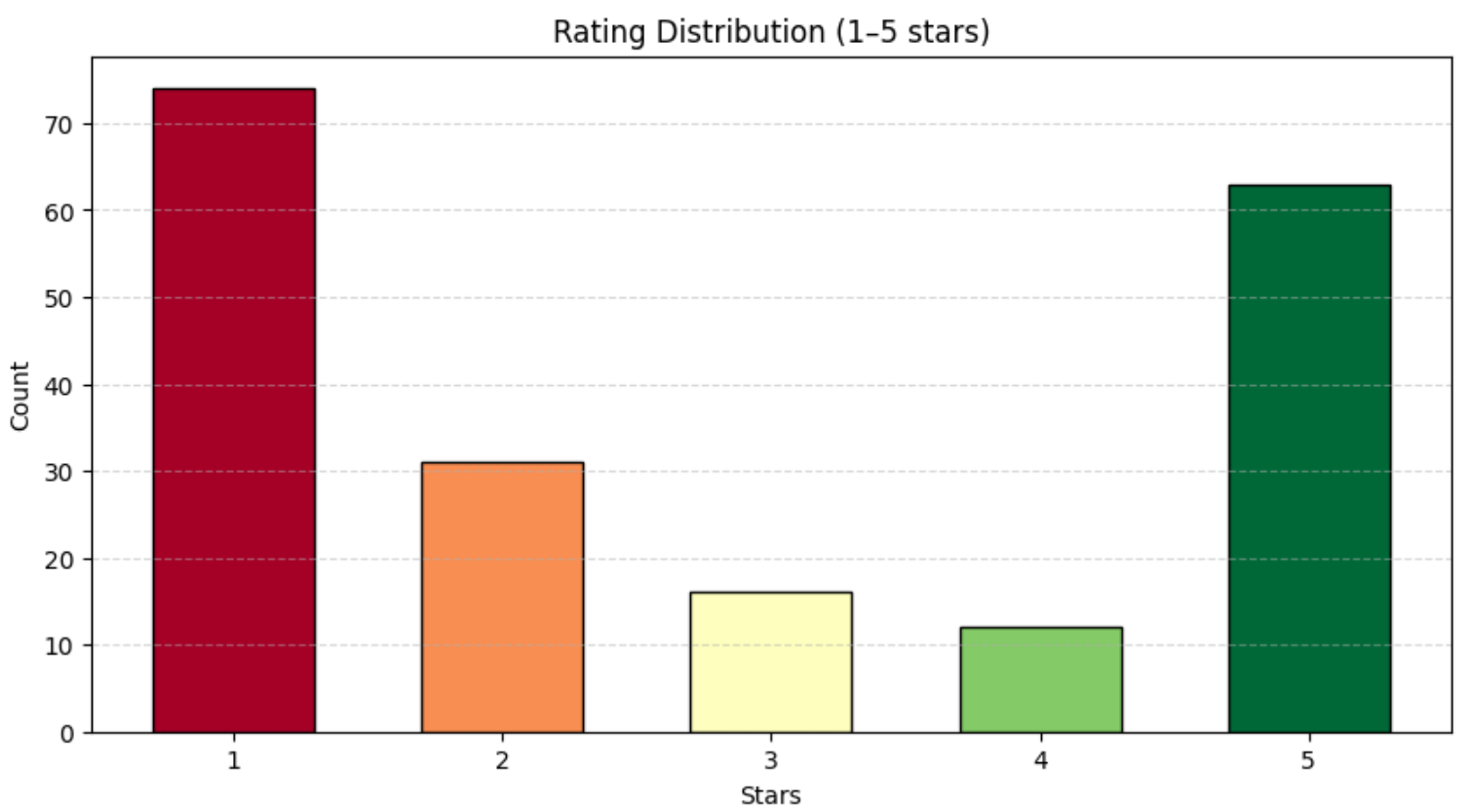
Perfeito! Agora você tem uma compreensão clara e de alto nível do conjunto de dados de avaliações da Amazon que acabou de obter. Essa base é essencial antes de passar para o treinamento do modelo e a análise de sentimentos.
Etapa 6: atribua uma pontuação de análise de sentimento às avaliações
Antes de aplicar o aprendizado de máquina, é útil simplificar a tarefa de classificação de sentimentos ignorando as avaliações de 3 estrelas. Isso porque essas avaliações geralmente são neutras e não expressam claramente um sentimento positivo ou negativo.
Manter essas avaliações forçaria o modelo a aprender um problema de três classes (positivo/neutro/negativo), o que requer mais dados e uma modelagem mais complexa. Em vez disso, vamos converter a tarefa em uma classificação binária de sentimentos, considerando:
- avaliações de 4 a 5 estrelas como “positivas” (
1); - avaliações de 1–2 estrelas como “negativas” (
0).
Diante disso, implemente a lógica de análise de sentimento no TensorFlow da seguinte maneira:
# Descartar avaliações neutras (classificação=3) para clareza binária do sentimento
df = df[df["rating"] != 3]
# Mapear classificações para sentimento: 1=positivo (>=4), 0=negativo (<4)
df["sentiment_label"] = np.where(df["rating"] >= 4, 1, 0)
# Carregar embeddings do Universal Sentence Encoder
print("Carregando embeddings do Universal Sentence Encoder...")
use = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
X_emb = np.array(use(df["review_text"].tolist()).numpy(), dtype=np.float32) # float32 fixo
y = df["sentiment_label"].values
# Dividir os conjuntos de dados em conjuntos de treinamento e validação
X_train, X_val, y_train, y_val = train_test_split(
X_emb, y, test_size=0.2, random_state=42, stratify=y
)
# Calcular pesos de classe para lidar com o desequilíbrio de classe
classes = np.unique(y_train)
class_weights = compute_class_weight("balanced", classes=classes, y=y_train)
class_weights = dict(zip(classes, class_weights))
# Construa um classificador denso simples com a camada de entrada primeiro
model = Sequential([
Input(shape=(X_emb.shape[1],)),
Dense(128, activation="relu"),
Dropout(0.3),
Dense(64, activation="relu"),
Dense(1, activation="sigmoid")
])
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
# Forçar a construção do modelo para evitar refazer o traçado
_ = model(X_emb[:1])
# Treinar o modelo
history = model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=20,
batch_size=16,
class_weight=class_weights,
verbose=1
)
# Prever no conjunto de validação e avaliar
y_pred = (model.predict(X_val, batch_size=32) > 0.5).astype(int)
print("Relatório de classificação do modelo nSentiment:")
imprimir(classification_report(y_val, y_pred))
# Prever no conjunto de dados completo e salvar pontuações de sentimento
df["sentiment_score"] = model.predict(X_emb, batch_size=32).flatten()Este bloco de código depende do Universal Sentence Encoder para converter cada avaliação em um vetor semântico. Se você não está familiarizado com esse modelo, o Universal Sentence Encoder é um modelo do Google que converte texto em vetores de incorporação de 512 dimensões para tarefas de processamento de linguagem natural, como classificação, similaridade semântica e outras.
Essas incorporações capturam significados como tom, sentimento e intenção expressos em cada avaliação. Em seguida, o modelo Keras Sequential usa camadas totalmente conectadas (Dense) para aprender padrões nas incorporações que distinguem sentimentos positivos de negativos. Sua saída é uma pontuação de probabilidade, em que:
- Valores próximos a
1,0indicam sentimento positivo; - Valores próximos a
0,0indicam sentimento negativo.
O modelo atribui uma dessas pontuações a cada avaliação. O relatório de classificação do conjunto de validação é:
Relatório de classificação do modelo de sentimento:
precisão recall f1-score suporte
0 0,91 0,95 0,93 21
1 0,93 0,87 0,90 15
precisão 0,92 36
média macro 0,92 0,91 0,91 36
média ponderada 0,92 0,92 0,92 36Isso mostra que:
- O modelo atinge 92% de precisão em dados de validação não vistos.
- A precisão e a recuperação são consistentemente fortes para as classes positivas e negativas.
- A precisão do treinamento e da validação são próximas, o que indica que o modelo não está significativamente sobreajustado.
Para visualizar melhor o processo de treinamento de aprendizado de máquina, considere adicionar um gráfico como o abaixo:
plt.plot(history.history["accuracy"], label="Precisão do treinamento")
plt.plot(history.history["val_accuracy"], label="Precisão da validação")
plt.title("Desempenho do treinamento do modelo de sentimento")
plt.xlabel("Época")
plt.ylabel("Precisão")
plt.legend()
plt.grid(True, linestyle="--", alpha=0.5)
plt.show()Isso mostrará o histórico completo do treinamento: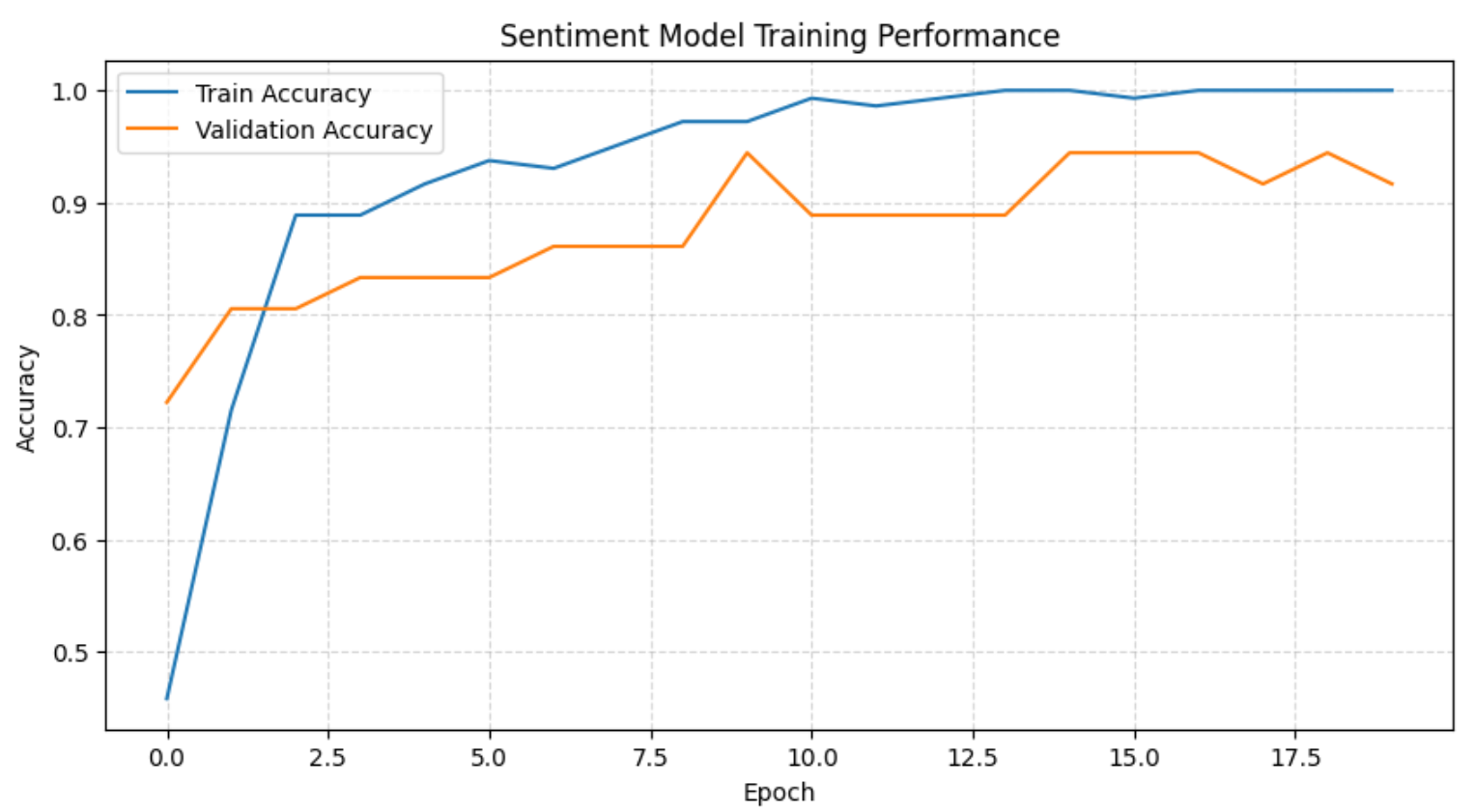
O gráfico acima, juntamente com os registros de treinamento, mostra que o modelo aprende rapidamente o limite do sentimento nas primeiras épocas antes de se estabilizar com uma forte precisão de validação. À medida que o treinamento avança, a precisão no conjunto de treinamento atinge 100%, enquanto a precisão de validação permanece consistentemente alta, indicando apenas um sobreajuste leve e aceitável, dado o tamanho do conjunto de dados.
Por último, visualize as probabilidades de sentimento previstas:
plt.hist(df["sentiment_score"], bins=20, edgecolor="black", color="skyblue")
plt.title("Distribuição da pontuação de sentimento prevista")
plt.xlabel("Pontuação de sentimento")
plt.ylabel("Contagem")
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.show()O resultado será: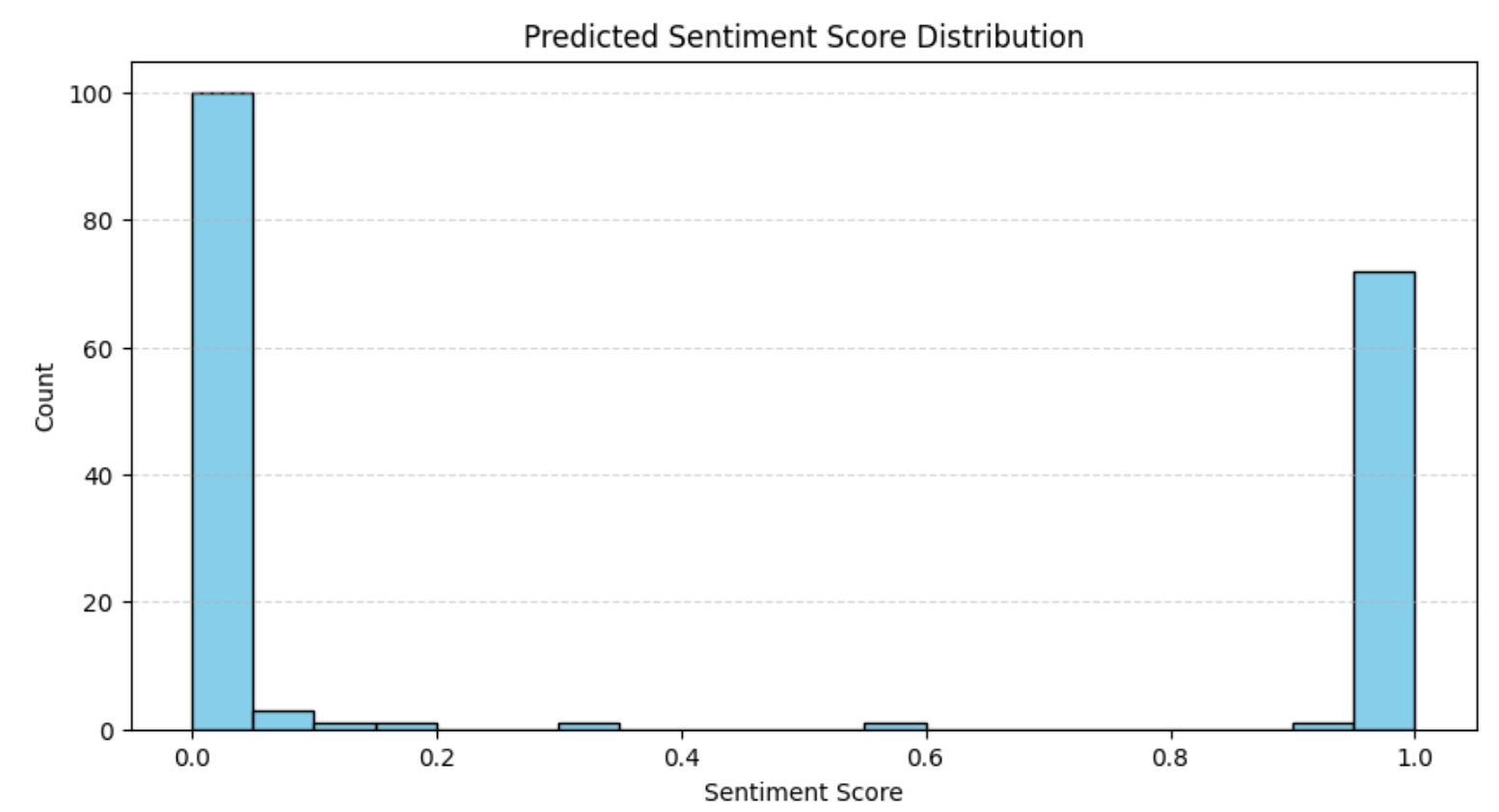
A distribuição está alinhada com o que observamos anteriormente na análise de classificação, ou seja, a maioria das avaliações é fortemente positiva ou fortemente negativa. Esse padrão é comum em plataformas de comércio eletrônico, onde opiniões polarizadas tendem a dominar.
Fantástico! Análise de sentimento concluída.
Etapa 7: Estude a análise de sentimento ao longo do tempo
Agora que todas as avaliações têm uma pontuação de sentimento, visualize como o sentimento do cliente evoluiu ao longo do último ano. Aplique uma tendência móvel de 7 dias ao sentimento médio diário para suavizar o ruído do dia a dia:
# Prepare o sentimento médio diário
daily = df.groupby(df["date"].dt.date)["sentiment_score"].mean().reset_index()
daily["date"] = pd.to_datetime(daily["date"])
daily = daily.sort_values("date")
# Filtre para o ano passado
one_year_ago = daily["date"].max() - pd.DateOffset(years=1)
daily_last_year = daily[daily["date"] >= one_year_ago]
# Calcule a tendência móvel de 7 dias
trend = daily_last_year["sentiment_score"].rolling(window=7, min_periods=1).mean()
# Definir um rótulo do eixo x por mês
monthly_labels = pd.date_range(
start=daily_last_year["date"].min(),
end=daily_last_year["date"].max(),
freq="MS" # Início do mês
)
# Traçar o sentimento diário e a tendência móvel
plt.bar(daily_last_year["date"], daily_last_year["sentiment_score"], color="skyblue", label="Sentimento diário")
plt.plot(daily_last_year["date"], trend, color="red", linewidth=2, label="Tendência móvel de 7 dias")
# Definir rótulos do eixo x
plt.xticks(ticks=monthly_labels, labels=[d.strftime("%Y-%m") for d in monthly_labels], rotation=45)
plt.title("Sentimento médio diário (último ano) + tendência")
plt.xlabel("Data")
plt.ylabel("Pontuação do sentimento")
plt.ylim(0,1)
plt.legend()
plt.grid(True, axis="y", linestyle="--", alpha=0.5)
plt.tight_layout()
plt.show()Isso produz o gráfico de sentimento ao longo do tempo abaixo: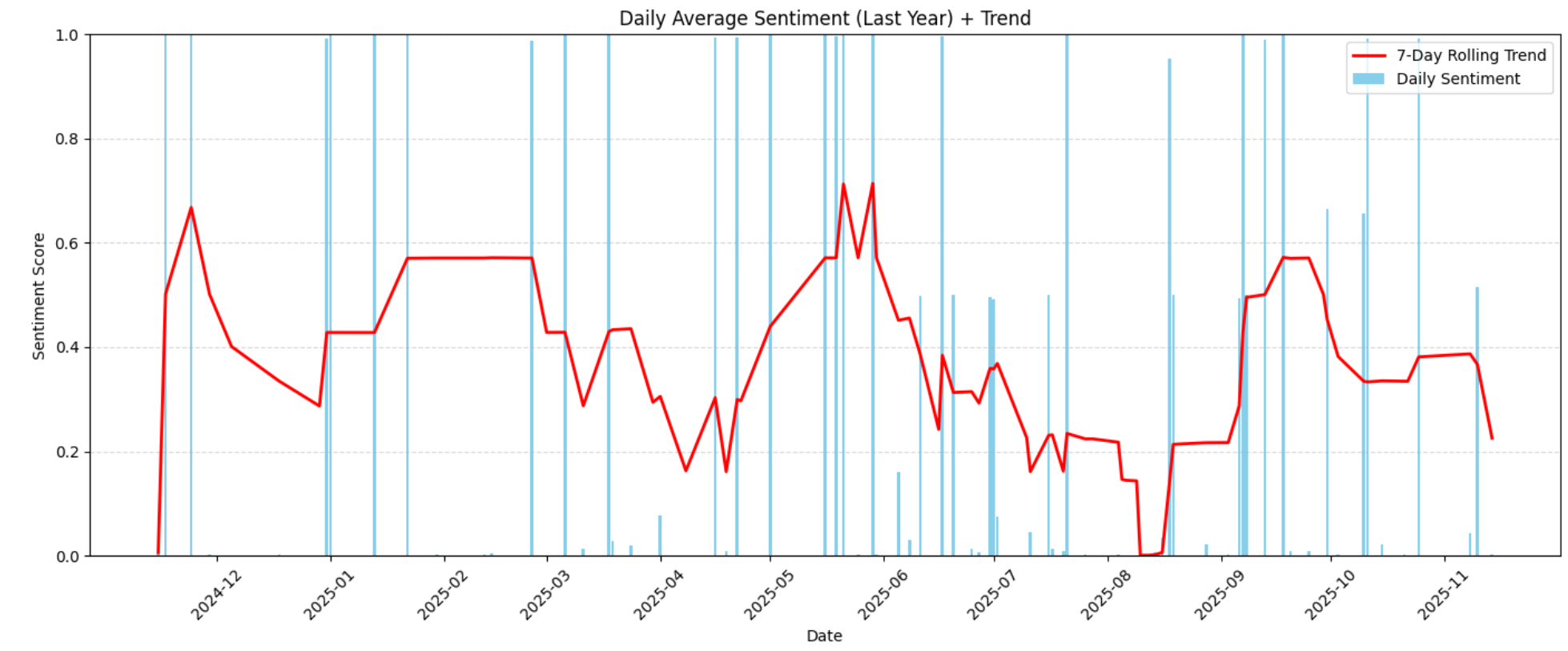
A visualização destaca padrões de sentimento crescentes ou decrescentes ao longo do ano. Essas tendências ajudam a reconhecer quando a satisfação do cliente melhorou, diminuiu e se algum fator externo (mudanças no produto, atrasos, defeitos, atualizações de preço) pode ter causado mudanças no sentimento.
Por exemplo, no gráfico, você pode ver claramente que, entre junho de 2026 e meados de agosto de 2026, o sentimento caiu drasticamente, passando de moderadamente positivo (cerca de 0,6) para extremamente negativo (perto de 0,0):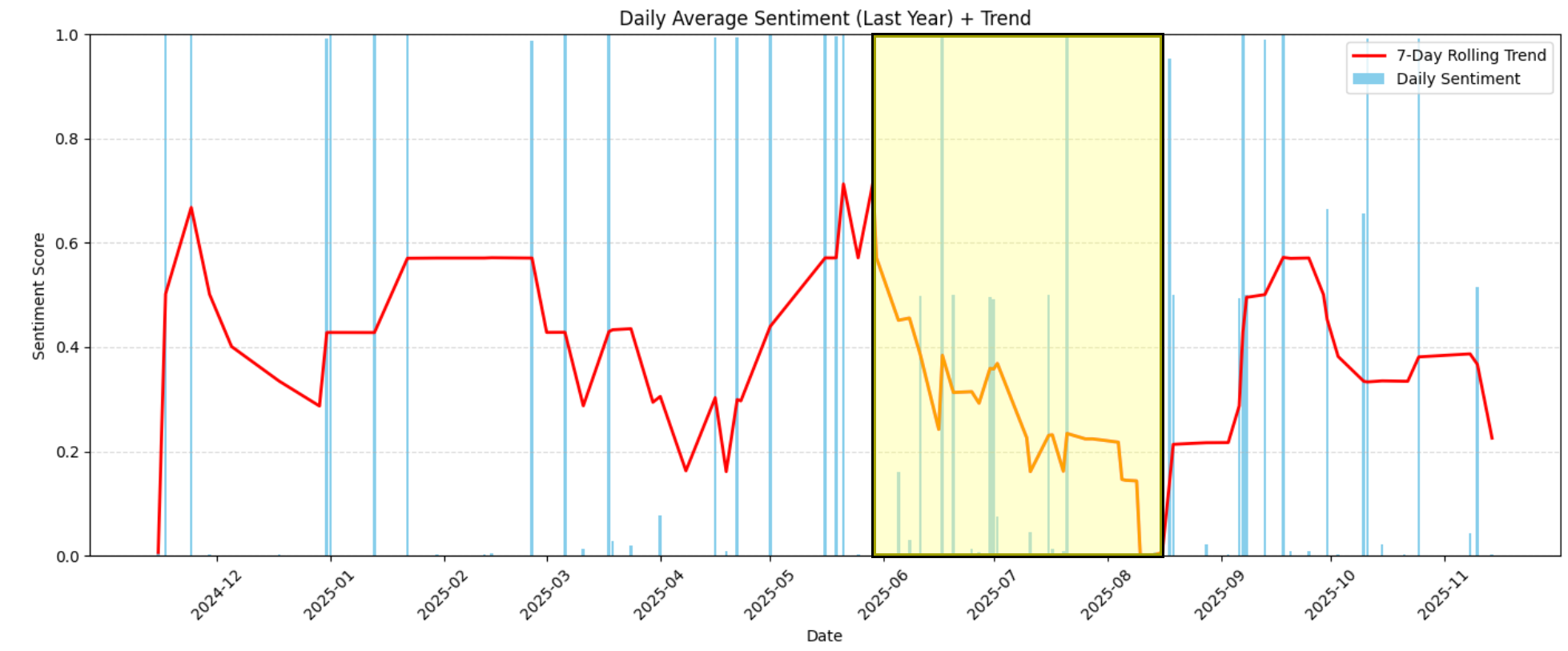
Para entender o que aconteceu durante esse período, restrinja os Conjuntos de dados a essas datas:
# Filtrar avaliações entre junho de 2026 e meados de agosto de 2026
start_date = pd.Timestamp("2026-06-01")
end_date = pd.Timestamp("2026-08-15")
df_filtered = df[(df["date"] >= start_date) & (df["date"] <= end_date)]
print(f"Número de avaliações no período: {len(df_filtered)}")Como mostra o resultado, há 34 avaliações nesse intervalo:
Número de avaliações no período: 34Em seguida, resuma como o sentimento está distribuído entre as avaliações:
rating_summary = df_filtered.groupby("rating")["sentiment_score"].agg(["count", "mean"]).reset_index()
rating_summary.rename(columns={"count":"num_reviews", "mean":"avg_sentiment"}, inplace=True)
print("Resumo da classificação:")
print(rating_summary)O resultado seria:
Resumo da classificação:
classificação num_reviews avg_sentiment
0 1 16 0,004767
1 2 11 0,048928
2 4 2 0,998977
3 5 5 0,993221Isso nos diz que 27 das 34 avaliações foram de 1 ou 2 estrelas, e suas pontuações de sentimento estão extremamente próximas de 0,0.
Trace a relação entre as classificações e o sentimento:
# Trace o sentimento em relação à classificação em um gráfico
fig, ax1 = plt.subplots(figsize=(10,6))
ax1.bar(rating_summary["rating"], rating_summary["num_reviews"], color="skyblue", label="Número de avaliações")
ax1.set_xlabel("Classificação")
ax1.set_ylabel("Número de avaliações", color="skyblue")
ax1.tick_params(axis="y", labelcolor="skyblue")
ax2 = ax1.twinx()
ax2.plot(rating_summary["rating"], rating_summary["avg_sentiment"], color="red", marker="o", label="Sentimento médio")
ax2.set_ylabel("Pontuação média do sentimento", color="red")
ax2.tick_params(axis="y", labelcolor="red")
ax2.set_ylim(0,1)
fig.suptitle("Análise de sentimento vs. classificação (01/06/2026 a 15/08/2026)")
fig.tight_layout()
plt.show()O gráfico resultante será: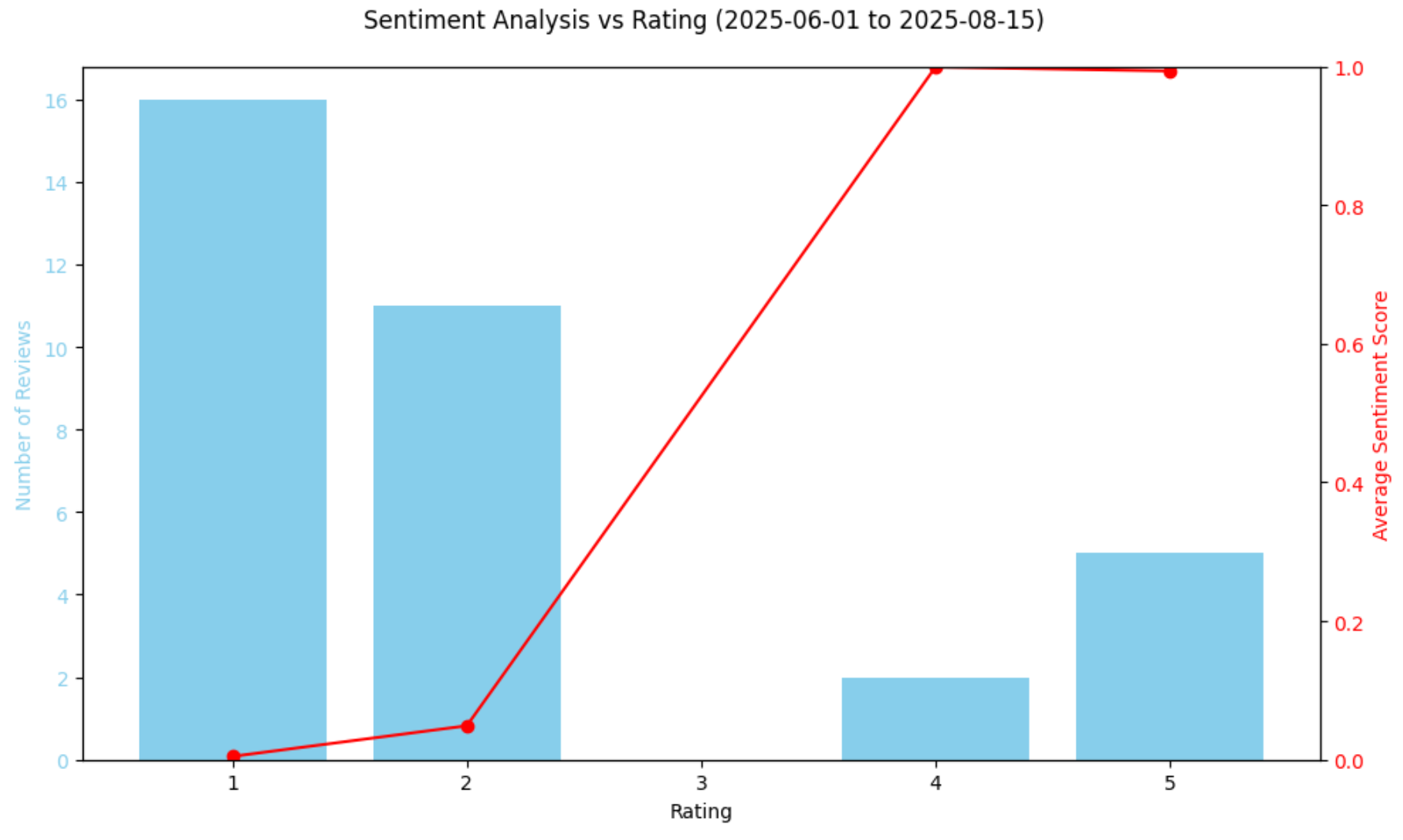
O gráfico acima confirma a queda acentuada no sentimento, com a maioria das avaliações nesse período sendo totalmente negativas. Curiosamente, o modelo classifica as avaliações de 4 estrelas de forma ligeiramente mais positiva do que as avaliações de 5 estrelas por meio de suas pontuações de análise de sentimento. Isso não é um erro, pois reflete que uma classificação por estrelas por si só nem sempre reflete o tom emocional. Algumas avaliações de 5 estrelas ainda podem conter preocupações, enquanto algumas avaliações de 4 estrelas podem expressar uma linguagem extremamente positiva.
Afinal, embora as classificações por estrelas deem uma ideia rápida de como os clientes se sentem, elas nem sempre capturam todas as nuances do texto da avaliação. Ao comparar as pontuações de sentimento previstas pelo modelo com as classificações numéricas, você pode ver se a linguagem nas avaliações está alinhada com as estrelas atribuídas. Isso ajuda a identificar anomalias, como palavras negativas em avaliações com classificação alta ou positividade sutil em avaliações com classificação mais baixa.
Vamos continuar analisando esse padrão interessante identificado nas pontuações decrescentes das avaliações!
Etapa 8: leia as avaliações relevantes
A etapa final para realmente entender o que aconteceu durante o declínio das avaliações entre junho de 2026 e meados de agosto de 2026 é inspecioná-las diretamente. Faça isso com:
# Selecione as colunas relevantes
df_table = df_filtered[["date", "review_text", "rating", "sentiment_score"]]
# Exiba a tabela no notebook via HTML
display(HTML(df_table.to_html(index=False)))O resultado será a seguinte tabela HTML:

Como você pode ver, a maioria das avaliações durante esse período reclama que o aroma desaparece rapidamente ou não é forte o suficiente. Isso destaca possíveis problemas de produção nos produtos enviados durante essas semanas.
Essa informação é extremamente valiosa, pois permite investigar o processo de produção, resolver problemas recorrentes e, potencialmente, entrar em contato com clientes insatisfeitos com soluções como vouchers ou descontos.
Observação: esse processo de análise de avaliações também poderia ser automatizado ainda mais usando um LLM, tornando-o um pipeline totalmente autônomo e pronto para produção.
Et voilà! Graças aos recursos de scraping da Bright Data, você recuperou os dados dos produtos da Amazon. Em seguida, você aplicou o TensorFlow para análise de sentimentos, estudou as tendências e identificou as razões por trás da queda nas avaliações em um período específico.
Conclusão
Neste artigo, você viu como recuperar dados de avaliações de um produto da Amazon por meio da Bright Data e processá-los para identificar tendências de análise de sentimentos usando fluxos de trabalho de aprendizado de máquina criados com o TensorFlow em um notebook Python.
O projeto apresentado aqui atende às necessidades de pequenas e médias empresas ou corporações que buscam maneiras de monitorar as avaliações dos usuários e melhorar a satisfação do cliente. Essa análise não seria possível sem os serviços de dados oferecidos pela Bright Data para empresas.
Essas soluções incluem um rico mercado de Conjuntos de dados e APIs de Scraper que ajudam você a coletar dados antigos ou recém-atualizados de mais de 100 domínios, incluindo Amazon, LinkedIn, Yahoo Finance e muitos outros. Com esses dados, você pode alimentá-los no TensorFlow ou em tecnologias semelhantes para analisá-los por meio de aprendizado de máquina.
Crie uma conta gratuita na Bright Data hoje mesmo para experimentar nossas APIs de Scraper ou explorar nossos Conjuntos de dados!




