

Neste artigo, você aprenderá:
- O que é o Apache Spark Structured Streaming e o que ele oferece.
- Por que integrar a API SERP da Bright Data a um pipeline do Spark Structured Streaming é uma estratégia vencedora.
- Como construir um pipeline PySpark que ingira continuamente dados de pesquisa na web em tempo real usando a API SERP da Bright Data.
Vamos começar!
O que é o Apache Spark Structured Streaming?
O Apache Spark Structured Streaming é um mecanismo de processamento de fluxos escalável e tolerante a falhas, construído sobre o mecanismo Spark SQL. Ao contrário da biblioteca Spark Streaming mais antiga (que divide os dados em micro-lotes discretos baseados em RDD usando DStreams), o Structured Streaming trata um fluxo de dados em tempo real como uma tabela ilimitada à qual novos dados são continuamente anexados. Você escreve o mesmo código de DataFrame e API SQL que escreveria para um trabalho em lote estático, e o Spark se encarrega de executá-lo de forma incremental à medida que novos dados chegam.
O mecanismo opera em um modelo de execução de micro-lotes por padrão. A cada intervalo de acionamento, o Spark lê os dados mais recentes da fonte, processa-os e grava os resultados em um destino. Ele rastreia o progresso por meio de pontos de verificação, de modo que o pipeline pode se recuperar de falhas e retomar exatamente de onde parou, oferecendo garantias de ponta a ponta e tolerância a falhas.
O Structured Streaming oferece suporte a uma variedade de fontes integradas: tópicos do Kafka, tabelas Delta, armazenamento de objetos na nuvem via Auto Loader, geradores de taxa (para testes) e muito mais. Para fontes não cobertas nativamente (como uma API REST), você pode usar o método de extensão foreachBatch, que entrega cada micro-lote a uma função Python onde você pode expressar uma lógica de ingestão arbitrária. Essa é a abordagem que usaremos aqui.
Spark Streaming vs. Spark Structured Streaming: Qual é a diferença?
Se você está familiarizado com a biblioteca Spark Streaming legada, talvez esteja se perguntando como ela se relaciona com o Structured Streaming. As duas compartilham o mesmo mecanismo Spark subjacente, mas diferem em aspectos importantes:
O Spark Streaming é baseado em DStreams, uma sequência de RDDs produzida pela divisão de um fluxo de entrada em lotes delimitados por tempo. Todas as transformações operam em RDDs, o que significa que você trabalha em uma API de nível inferior. Ele tem suporte limitado para semântica de tempo de evento (ou seja, ordenar dados pela data em que foram gerados, não quando foram ingeridos) e não é mais desenvolvido ativamente.
O Spark Structured Streaming é construído sobre as APIs DataFrame e Dataset, dando a você acesso ao otimizador completo do Spark SQL. Ele oferece janelas de tempo de evento nativas, watermarking para lidar com dados atrasados, agregações com estado e um modelo de tolerância a falhas mais limpo por meio de checkpoints. Como usa a mesma API que os DataFrames em lote, você pode misturar dados de streaming e estáticos no mesmo trabalho (por exemplo, junções de streaming com uma tabela de pesquisa estática).
Em resumo, o Spark Streaming é um projeto legado mantido para compatibilidade com versões anteriores, enquanto o Structured Streaming é o mecanismo ativamente desenvolvido e recomendado para todas as novas cargas de trabalho de streaming.
Por que integrar a API SERP da Bright Data ao Spark Structured Streaming?
O Spark Structured Streaming oferece um mecanismo poderoso para transformar e agregar dados em escala, mas precisa de uma fonte confiável e estruturada de dados da web em tempo real para atuar. É aí que entra a API SERP da Bright Data.
A API SERP permite que você envie consultas programaticamente aos principais mecanismos de busca (incluindo Google, Bing, DuckDuckGo, Yandex e outros) e recupere páginas completas de resultados de busca (SERPs) sem ser bloqueado. Os resultados são retornados em vários formatos: JSON analisado, uma variante leve (parsed_light) com apenas os principais resultados orgânicos, HTML bruto ou Markdown limpo e pronto para IA. Como o scraping direto de mecanismos de busca é notoriamente difícil devido a medidas anti-bot, limites de taxa e renderização dinâmica, o encaminhamento de suas consultas pela infraestrutura da Bright Data elimina toda essa complexidade do seu pipeline.
Combinar isso com o mecanismo de micro-lotes do Spark Structured Streaming cria um pipeline em execução contínua que extrai periodicamente dados SERP atualizados, aplica transformações e agregações em escala e grava resultados estruturados em qualquer destino de sua escolha, sem que você precise gerenciar Proxies, CAPTCHAs ou Infraestrutura de scraping.
Essa abordagem é especialmente útil para:
- Monitorar como um conjunto de palavras-chave alvo se classifica nos mecanismos de busca em intervalos regulares, gravar os resultados em uma tabela Delta e calcular as mudanças de classificação ao longo do tempo.
- Buscar continuamente SERPs para marcas ou produtos de concorrentes, realizar o Parsing dos resultados estruturados e transmiti-los para um data warehouse para geração de painéis.
- Pesquisar resultados do Google News em vários tópicos em micro-lotes paralelos, deduplicar artigos usando as agregações com estado do Spark e enviar resultados selecionados para um data lake.
- Ingerir continuamente resultados de SERP para detectar quando anúncios pagos aparecem para suas palavras-chave alvo, capturar o texto do anúncio e as URLs e alertar os sistemas a jusante.
Ao combinar o processamento distribuído e escalável do Spark Structured Streaming com a infraestrutura de acesso à web da Bright Data para IA e pipelines de dados, você cria pipelines que reagem continuamente aos dados de pesquisa do mundo real, sem precisar manter nenhuma infraestrutura de scraping própria.
Como criar um pipeline de ingestão contínua de SERP com o Spark Structured Streaming
Nesta seção guiada, você criará um pipeline PySpark que:
- É acionado em uma programação usando a fonte de taxa integrada do Spark como um relógio.
- Chama a API SERP da Bright Data dentro de uma função
foreachBatchem cada micro-lote para buscar resultados ao vivo do Google News para um tópico-alvo. - Parses e transforma a resposta JSON estruturada em um DataFrame do Spark limpo.
- Grava os resultados em um sink (tanto em um diretório de saída JSON local quanto no console) para que você possa inspecionar os dados em tempo real.
Observação: este exemplo demonstra um caso de uso de monitoramento de notícias, mas o mesmo padrão se aplica a qualquer cenário de ingestão contínua de SERP: rastreamento de classificação de palavras-chave, monitoramento de anúncios, comparação de preços por meio de pesquisa na web e assim por diante.
Pré-requisitos
Para acompanhar, certifique-se de ter:
- Python 3.8+ instalado.
- Apache Spark 3.3+ instalado localmente ou acesso a um cluster Databricks / AWS EMR / Google Dataproc.
- PySpark instalado:
pip install pyspark. - A biblioteca
requestsinstalada:pip install requests. - Uma conta Bright Data com uma zona de API SERP ativa e uma chave de API (com permissões de administrador).
Siga a documentação oficial da Bright Data para configurar sua zona de API SERP e recuperar sua chave de API. Guarde sua chave de API e o nome da zona em um local seguro; você precisará deles em breve.
Etapa 1: Configure seu projeto
Crie um novo diretório de projeto e configure os arquivos necessários:
mkdir spark-serp-pipeline
cd spark-serp-pipeline
touch pipeline.py
touch config.py
mkdir -p output/checkpointAbra o arquivo config.py e adicione suas credenciais da Bright Data e a configuração de pesquisa:
# config.py
BRIGHT_DATA_API_KEY = "SUA_CHAVE_API_BRIGHT_DATA"
SERP_API_ZONE = "SUA_ZONA_API_SERP"
# A consulta de pesquisa a ser monitorada (personalize-a de acordo com seu caso de uso)
SEARCH_QUERY = "notícias sobre inteligência artificial"
# Frequência para acionar um novo micro-lote (em segundos)
TRIGGER_INTERVAL_SECONDS = 60
# Diretório de saída para resultados JSON
OUTPUT_PATH = "output/serp_results"
CHECKPOINT_PATH = "output/checkpoint"Dica de segurança: Em um ambiente de produção, evite codificar credenciais diretamente nos arquivos de origem. Use variáveis de ambiente, um gerenciador de segredos (por exemplo, AWS Secrets Manager, Azure Key Vault, HashiCorp Vault) ou Databricks Secrets para injetar esses valores em tempo de execução.
Etapa 2: Inicialize a SparkSession
Abra pipeline.py e comece criando sua SparkSession. Este é o ponto de entrada para todas as funcionalidades do Spark:
# pipeline.py
from pyspark.sql import SparkSession
from pyspark.sql.types import (
StructType, StructField, StringType, IntegerType, ArrayType
)
from pyspark.sql import functions as F
import requests
import json
import config
# Inicializar SparkSession
spark = SparkSession.builder
.appName("BrightDataSERPStream")
.config("spark.sql.shuffle.partitions", "4")
.getOrCreate()
# Reduzir a verbosidade do log para uma saída mais limpa
spark.sparkContext.setLogLevel("WARN")
print("SparkSession inicializada.")Definir spark.sql.shuffle.partitions para um número pequeno, como 4, é apropriado para um ambiente de desenvolvimento local. Em um cluster, você ajustaria isso com base no tamanho dos seus dados e no número de núcleos do executor.
Etapa 3: Defina a função de busca da API SERP
Em seguida, defina a função Python que chamará a API SERP da Bright Data e retornará os resultados analisados. Essa função será invocada de dentro do callback foreachBatch do Spark no driver, portanto, ela usa a biblioteca requests padrão em vez de qualquer mecanismo distribuído do Spark:
# pipeline.py (continuação)
def fetch_serp_results(query: str) -> list[dict]:
"""
Chama a API SERP da Bright Data e retorna uma lista de resultados de notícias analisados.
Utiliza o formato de dados parsed_light para uma saída JSON leve e estruturada.
"""
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {config.BRIGHT_DATA_API_KEY}"
}
payload = {
"zone": config.SERP_API_ZONE,
"url": f"https://www.google.com/search?q={query}&tbm=nws&hl=en&gl=us",
"format": "raw",
"data_format": "parsed_light"
}
try:
response = requests.post(url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
data = response.json()
# O formato parsed_light retorna uma matriz "news" de objetos de resultado
results = data.get("news", [])
print(f"[API SERP] Obtidos {len(results)} resultados para a consulta: '{query}'")
return results
except requests.exceptions.RequestException as e:
print(f"[API SERP] Falha na solicitação: {e}")
return []Vamos detalhar os principais parâmetros da solicitação:
zone: O nome da sua zona da API SERP no painel do Bright Data.url: A URL de pesquisa do Google. O parâmetrotbm=nwsrestringe os resultados ao Google Notícias.hl=endefine o idioma da interface como inglês, egl=usdireciona os resultados para os Estados Unidos.format: Defina como"raw"para receber o corpo da resposta diretamente.data_format: Defina como"parsed_light"para receber uma matriz JSON limpa dos principais resultados orgânicos/de notícias com títulos, URLs, fontes e datas — sem anúncios ou painéis de conhecimento. Para dados SERP completos, incluindo anúncios e painéis de conhecimento, use"parsed". Para uma saída compatível com LLM, use"markdown".
Etapa 4: Crie a fonte de streaming usando o gerador de taxa
Como o Spark Structured Streaming não possui uma fonte HTTP nativa, usamos um padrão bem estabelecido: a fonte de taxa integrada atua como um relógio, gerando uma linha por segundo (ou pela taxa configurada). Cada micro-lote produzido pela fonte de taxa aciona nosso callback foreachBatch, dentro do qual chamamos a API SERP.
Adicione a definição do fluxo de taxa ao pipeline.py:
# pipeline.py (continuação)
rate_stream = spark.readStream
.format("rate")
.option("rowsPerSecond", 1)
.load()
print("Fluxo de taxa criado. O pipeline será acionado a cada intervalo de micro-lote.")A fonte de taxa foi projetada explicitamente para cenários de teste e orientados por relógio, como este. Como se aplicam limites de taxa de API do mundo real, configuraremos o intervalo de acionamento na Etapa 5 para que o pipeline chame a API SERP apenas uma vez por minuto, e não uma vez por segundo.
Etapa 5: Definir o manipulador foreachBatch
O manipulador foreachBatch é o coração do pipeline. O Spark chama essa função a cada micro-lote, passando um DataFrame das linhas desse lote e um ID de lote exclusivo. Dentro da função, chamamos a API SERP, convertemos os resultados em um DataFrame do Spark, aplicamos transformações e gravamos no coletor de saída:
# pipeline.py (continuação)
# Defina o esquema para os resultados SERP analisados
serp_schema = StructType([
StructField("title", StringType(), True),
StructField("link", StringType(), True),
StructField("source", StringType(), True),
StructField("date", StringType(), True),
StructField("global_rank", IntegerType(), True),
])
def process_batch(batch_df, batch_id):
"""
Chamado pelo Spark a cada acionamento de micro-lote.
Busca dados SERP da Bright Data, converte os resultados em um DataFrame
e os grava no destino de saída.
"""
print(f"n--- Processando lote {batch_id} ---")
# Busca resultados SERP em tempo real da Bright Data
results = fetch_serp_results(config.SEARCH_QUERY)
if not results:
print(f"Lote {batch_id}: Nenhum resultado retornado. Ignorando gravação.")
return
# Converte a lista de resultados em um DataFrame do Spark
results_df = spark.createDataFrame(results, schema=serp_schema)
# Adicionar colunas de metadados para rastreamento
enriched_df = results_df
.withColumn("query", F.lit(config.SEARCH_QUERY))
.withColumn("batch_id", F.lit(batch_id))
.withColumn("ingested_at", F.current_timestamp())
# Imprimir no console para visualização
enriched_df.show(truncate=False)
# Gravar na saída JSON (modo de acréscimo, particionado por data de ingestão)
enriched_df
.withColumn("ingestion_date", F.to_date("ingested_at"))
.write
.mode("append")
.partitionBy("ingestion_date")
.json(config.OUTPUT_PATH)
print(f"Lote {batch_id}: Gravados {enriched_df.count()} registros em {config.OUTPUT_PATH}")Algumas observações sobre este projeto:
spark.createDataFrame(results, schema=serp_schema) converte a lista Python de dicionários retornada pela API SERP em um DataFrame do Spark tipado. É preferível fornecer um esquema explícito em vez de inferência de esquema — isso torna o trabalho mais rápido e previsível.
F.lit(batch_id) anexa o ID do micro-lote atual a cada linha, o que é útil para a deduplicação caso o pipeline repita um lote com falha (já que o foreachBatch oferece garantias de entrega pelo menos uma vez por padrão).
F.current_timestamp() marca cada linha com a hora de ingestão no driver, fornecendo uma trilha de auditoria confiável sobre quando cada resultado entrou no pipeline.
Etapa 6: Inicie a consulta de streaming
Agora, conecte tudo anexando o manipulador foreachBatch ao fluxo de taxa e iniciando a consulta:
# pipeline.py (continuação)
# Anexe o manipulador foreachBatch e configure o intervalo de acionamento
query = rate_stream.writeStream
.foreachBatch(process_batch)
.trigger(processingTime=f"{config.TRIGGER_INTERVAL_SECONDS} segundos")
.option("checkpointLocation", config.CHECKPOINT_PATH)
.start()
print(f"Consulta de streaming iniciada. Acionada a cada {config.TRIGGER_INTERVAL_SECONDS} segundos.")
print("Pressione Ctrl+C para parar.")
# Aguarde a conclusão da consulta (ela é executada indefinidamente até ser interrompida)
query.awaitTermination()A chamada .trigger(processingTime="60 segundos") instrui o Spark a disparar um novo micro-lote a cada 60 segundos — uma vez por minuto — independentemente de quantas linhas a fonte de taxa tenha gerado. Esse é o mecanismo que regula o ritmo das chamadas da API SERP, mantendo você dentro dos limites de taxa enquanto continua em execução contínua.
O .option("checkpointLocation", ...) é essencial para a tolerância a falhas. O Spark grava os metadados de progresso da consulta (offsets, lotes confirmados) neste diretório. Se o processo travar e reiniciar, o Spark lê o ponto de verificação para determinar quais lotes já foram processados e retoma a execução de forma limpa a partir do ponto correto.
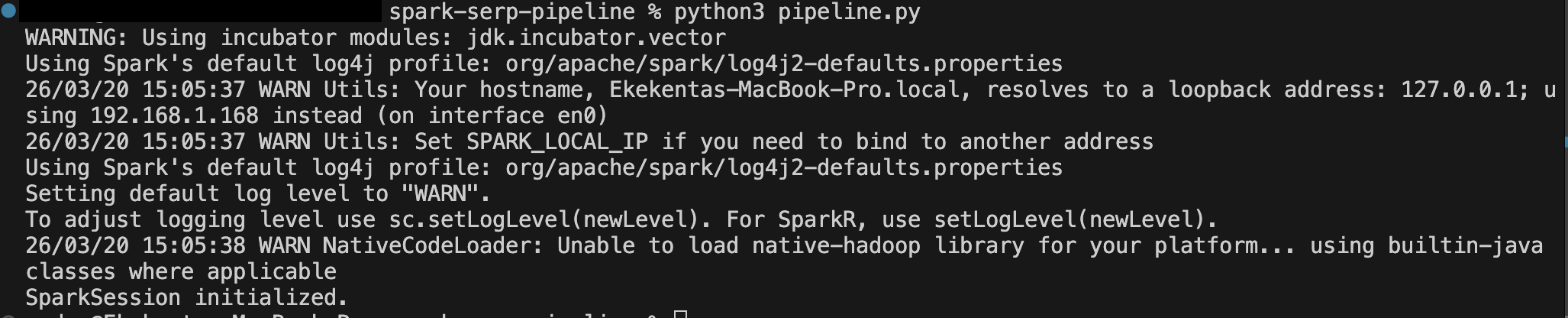
Etapa 7: Execute e inspecione os resultados
Execute o pipeline a partir do seu terminal:
python pipeline.pyVocê deve ver uma saída semelhante à seguinte após o primeiro gatilho ser acionado:
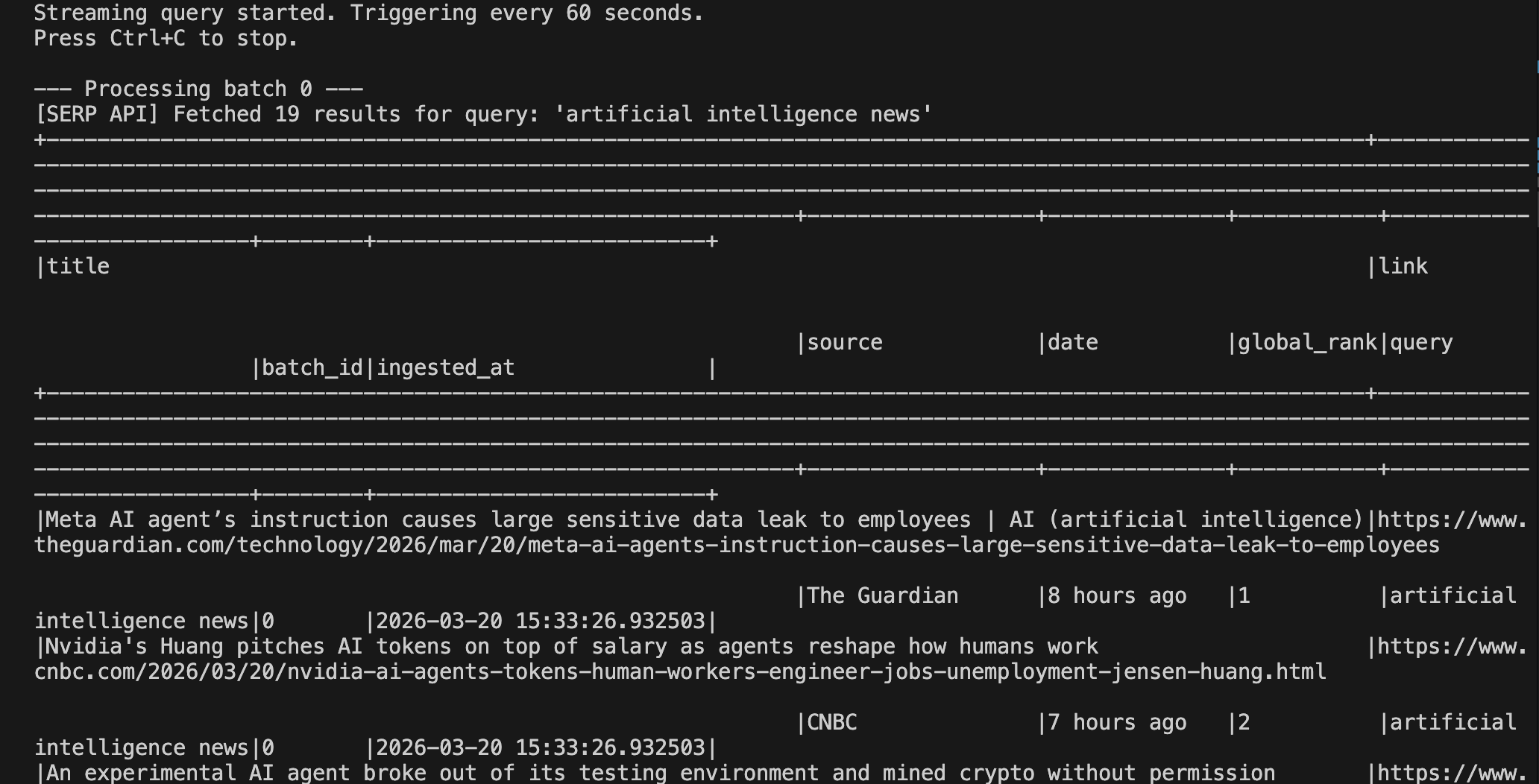
Você pode ver a saída sendo executada no Spark em localhost:4040:
Após alguns minutos de execução, verifique o diretório de saída:
ls output/serp_results/
ls output/serp_results/ingestion_date=2025-03-19/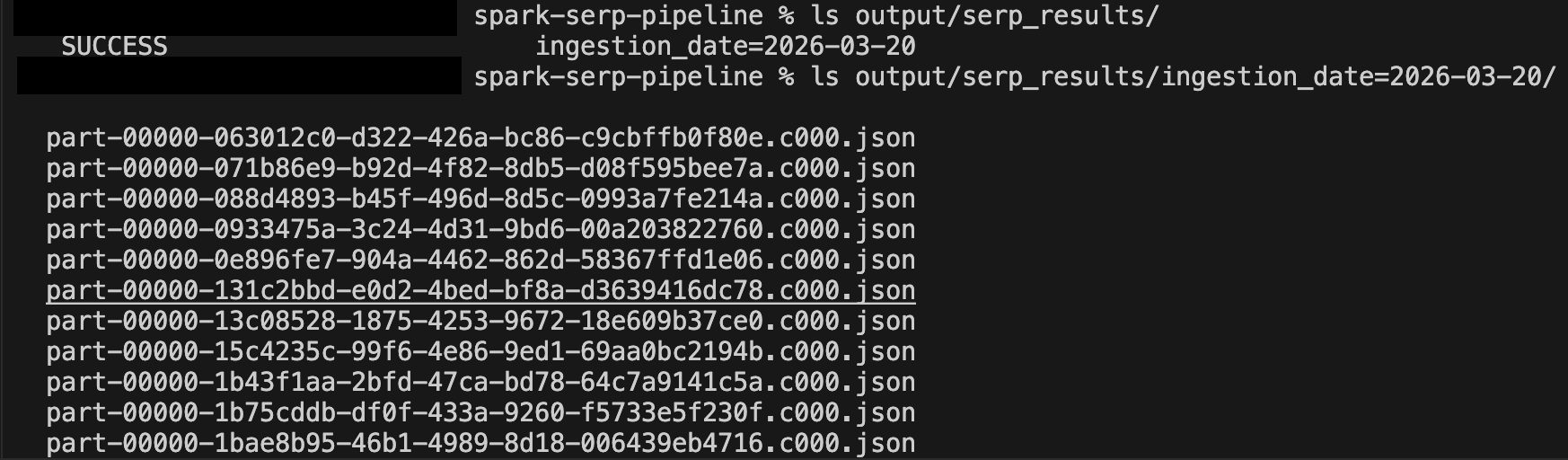
Você pode ler os resultados de volta no Spark para análise ad hoc a qualquer momento:
# Leia os resultados acumulados
df = spark.read.json("output/serp_results/")
df.orderBy("ingested_at", ascending=False).show(20, truncate=False)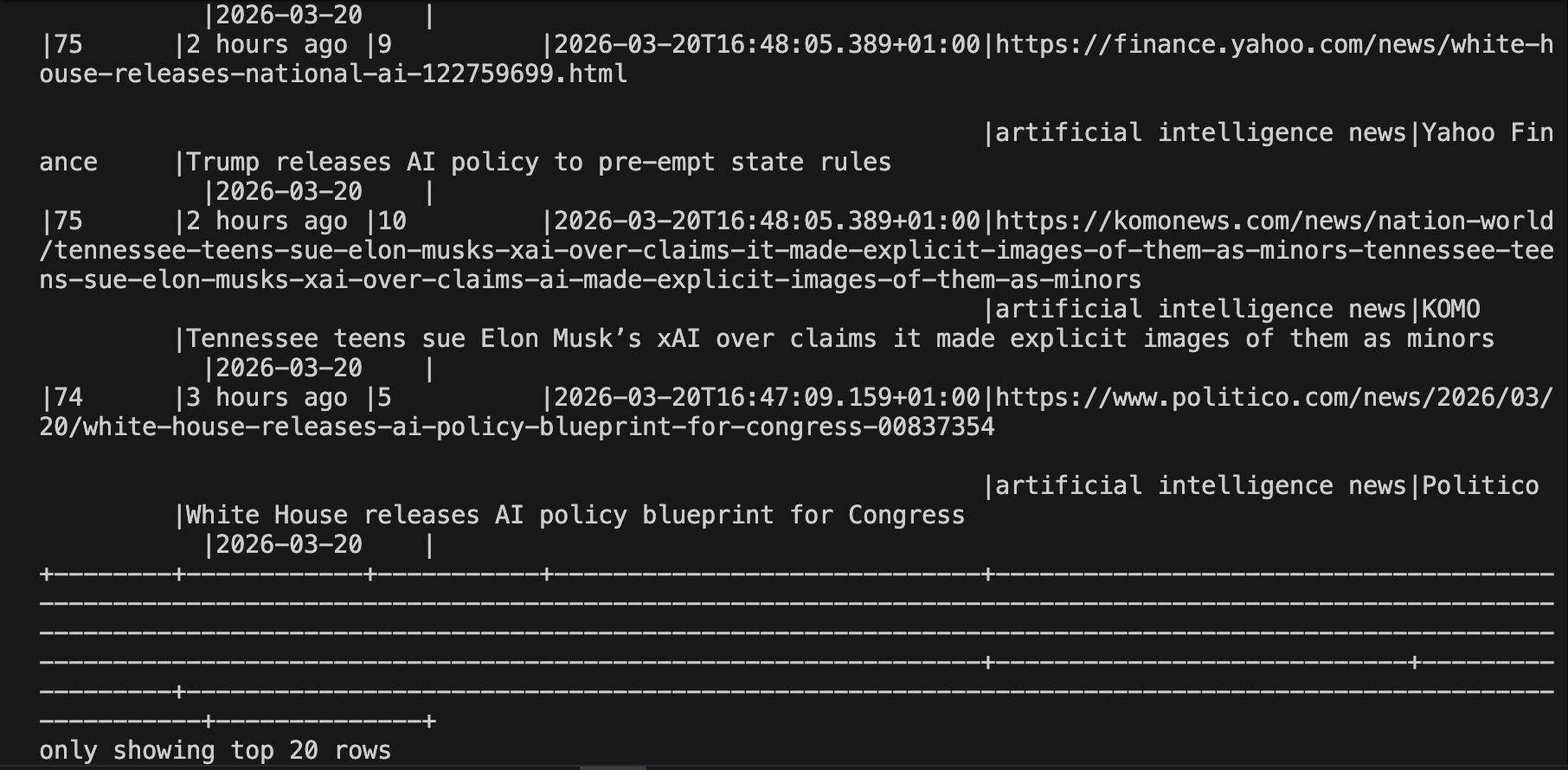
Aqui está o código completo do pipeline em um único lugar para facilitar a consulta.
Aprofundando
Este exemplo demonstra um padrão básico de ingestão, mas há muitas direções que você pode seguir:
- Em vez de um único tópico, mantenha uma lista de palavras-chave e distribua para chamadas paralelas da API SERP dentro de cada invocação
do foreachBatch. Useo concurrent.futures.ThreadPoolExecutordo Python para chamar a API para várias consultas simultaneamente dentro do mesmo micro-lote. - Substitua o sink JSON por uma tabela Delta para gravações incrementais compatíveis com ACID, com suporte à evolução de esquema. Isso torna as consultas históricas e a deduplicação muito mais simples.
- A API SERP da Bright Data suporta consultas no mecanismo de busca Bing, além do Google, DuckDuckGo, Yandex e outros. Consulte vários mecanismos em paralelo dentro do mesmo lote e mescle os conjuntos de resultados.
- Use o Web Unlocker da Bright Data para seguir as URLs retornadas pela API SERP e recuperar o conteúdo HTML ou Markdown completo de cada artigo. Encaminhe esse conteúdo para um estágio de NLP a jusante dentro do mesmo pipeline do Spark.
- Implemente o pipeline no Databricks, AWS EMR ou Google Dataproc para obter escalabilidade de nível de produção. No Databricks, você também pode usar Delta Live Tables para gerenciar o pipeline de forma declarativa.
- Grave os resultados SERP enriquecidos em um tópico do Kafka e consuma-os em tempo real a partir de microsserviços, painéis ou sistemas de alerta a jusante.
Conclusão
Neste tutorial, você aprendeu a usar a API SERP da Bright Data para ingestar continuamente resultados de busca em tempo real e processá-los com o Apache Spark Structured Streaming. Usando a fonte de taxa como um relógio de agendamento e o foreachBatch como ponte de integração, você construiu um pipeline em execução contínua que busca dados SERP atualizados a cada acionamento, os transforma em um Spark DataFrame tipado e grava os resultados em um sink JSON particionado, tudo com checkpoints tolerantes a falhas integrados.
Esse padrão é ideal para qualquer equipe que precise processar sinais de pesquisa na web em tempo real em grande escala: rastreamento de classificação de palavras-chave, monitoramento da concorrência, agregação de notícias, inteligência de anúncios e muito mais. Ao contrário da sondagem ad hoc baseada em scripts, um pipeline do Spark Structured Streaming oferece uma base distribuída, recuperável e facilmente extensível que cresce junto com seus volumes de dados.
Para construir pipelines mais avançados, explore o conjunto completo de produtos de dados da web da Bright Data, incluindo o Web Unlocker para contornar a proteção contra bots em URLs arbitrárias, o Navegador de scraping para sites com uso intenso de JavaScript e Conjuntos de dados prontos para as plataformas mais populares.
Cadastre-se hoje mesmopara obter uma conta gratuita da Bright Data e comece a alimentar seus pipelines de dados com dados da web confiáveis e em tempo real.






