

No guia de hoje, vamos escrever um Scrapy Spider e implantá-lo no AWS Lambda. No que diz respeito ao código, é bastante simples aqui. Ao trabalhar com serviços em nuvem como o Lambda, temos muitas partes móveis. Mostraremos como navegar por essas partes móveis e como lidar com elas quando algo der errado.
Pré-requisitos
Para realizar esta tarefa, você precisará do seguinte:
- aqui
- conhecimento básico de scraping com Scrapy
O que é Serverless?
A arquitetura sem servidor tem sido aclamada como o futuro da computação. Embora o tempo de execução real de um aplicativo sem servidor possa ser mais caro por hora, se você ainda não está pagando para executar um servidor, o Lambda faz sentido.
Vamos supor que seu Scraper leve um minuto para ser executado e você o execute uma vez por dia. Com um servidor tradicional, você pagaria por um mês de 24 horas de tempo de atividade, mas seu uso real é de apenas 30 minutos. Com serviços como o Lambda, você paga apenas pelo que realmente usa.
Prós
- Faturamento: você paga apenas pelo que usa.
- Escalabilidade: o Lambda se escala automaticamente, você não precisa se preocupar com isso.
- Gerenciamento de servidor: você não precisa gastar tempo gerenciando um servidor. Tudo isso é feito automaticamente.
Contras
- Latência: se sua função estiver ociosa, ela levará mais tempo para iniciar e ser executada.
- Tempo de execução: as funções Lambda são executadas com um tempo limite padrão de 3 segundos e um tempo máximo de 15 minutos. Os servidores tradicionais são muito mais flexíveis.
- Portabilidade: você não depende apenas da compatibilidade do sistema operacional, mas também fica à mercê do seu fornecedor. Não é possível simplesmente copiar sua função Lambda e executá-la no Azure ou no Google Cloud.
A Bright Data tem uma solução que não tem essas limitações. Vamos explorá-la a seguir.
Funções sem servidor: a melhor alternativa
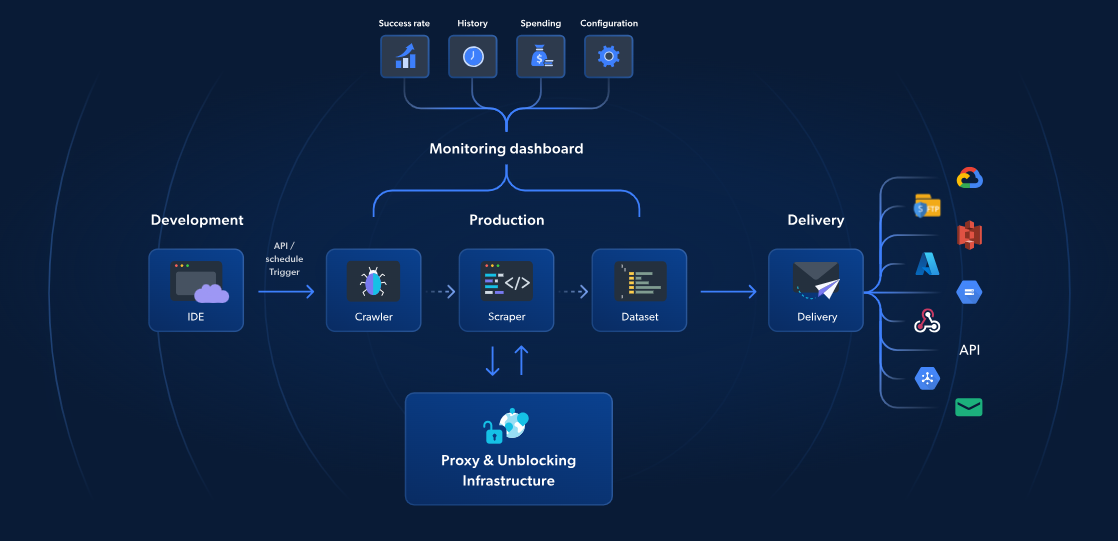
Enquanto o AWS Lambda e o Scrapy oferecem Scraping de dados sem servidor, as funções sem servidor da Bright Data fornecem uma solução específica para um Scraping de dados mais rápido e confiável. Com mais de 70 modelos JavaScript pré-construídos, um IDE integrado baseado em nuvem e uma solução de desbloqueio alimentada por IA, você pode contornar CAPTCHAs, escalar sem esforço e se concentrar na extração de dados sem o incômodo de gerenciar a infraestrutura.
Ao contrário da abordagem da AWS e do Scrapy, a solução da Bright Data inclui gerenciamento de Proxy, escalonamento automático e integração direta com plataformas de armazenamento como S3 ou Google Cloud. A partir de apenas US$ 2,7/1.000 carregamentos de página, as Funções sem servidor tornam o Scraping de dados da web mais simples, rápido e econômico.
Agora, vamos continuar com nosso guia do Scrapy e da AWS.
Introdução
Configurando os serviços
Depois de criar sua conta AWS, você precisará de um bucket S3. Acesse a página “Todos os serviços” e role para baixo.
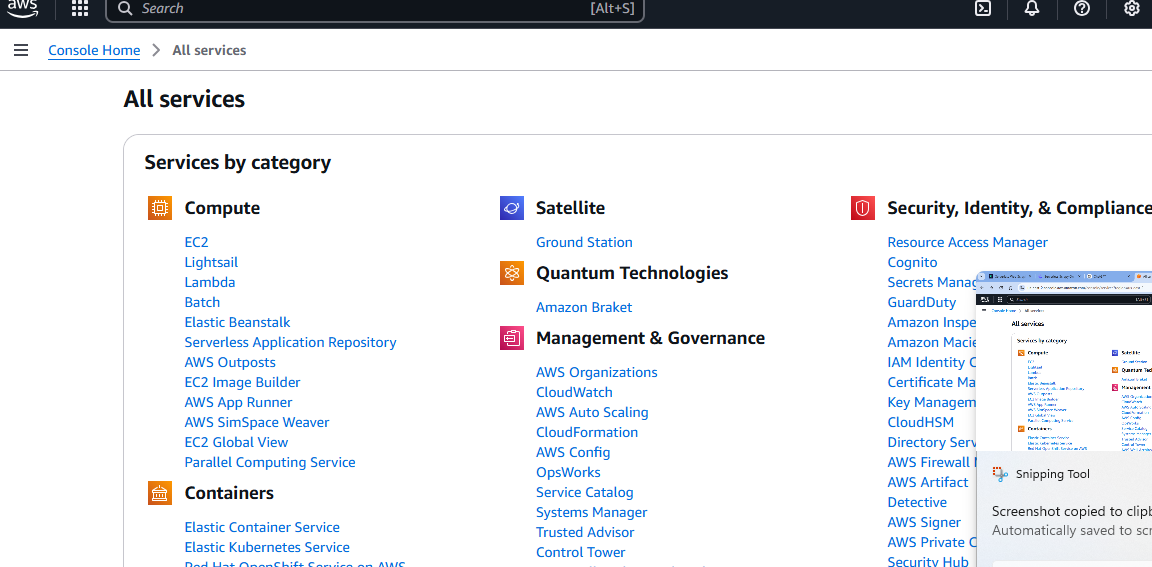
Por fim, você verá uma seção chamada Armazenamento. A primeira opção nessa seção é chamada S3. Clique nela.
Em seguida, clique no botão Criar bucket.
Agora, você precisa nomear seu bucket e escolher suas configurações. Vamos usar as configurações padrão.
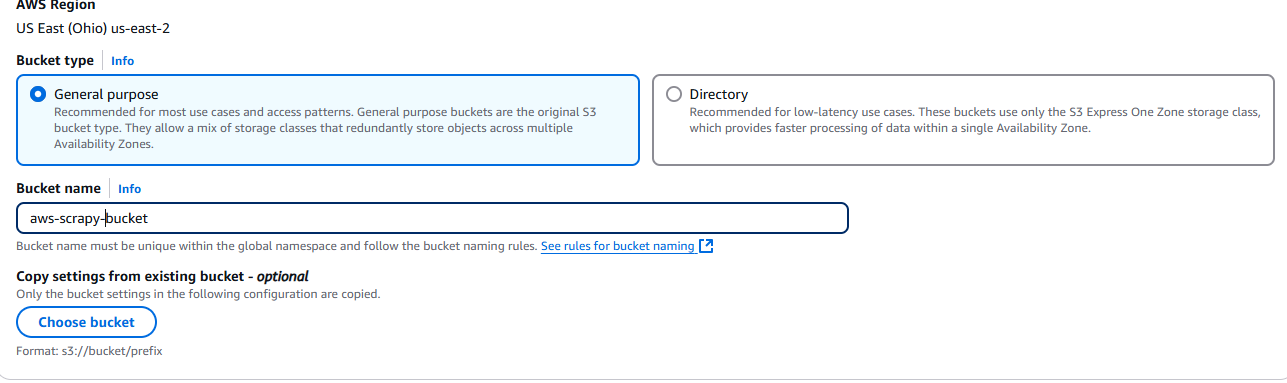
Quando terminar, clique no botão Criar bucket localizado no canto inferior direito da página.

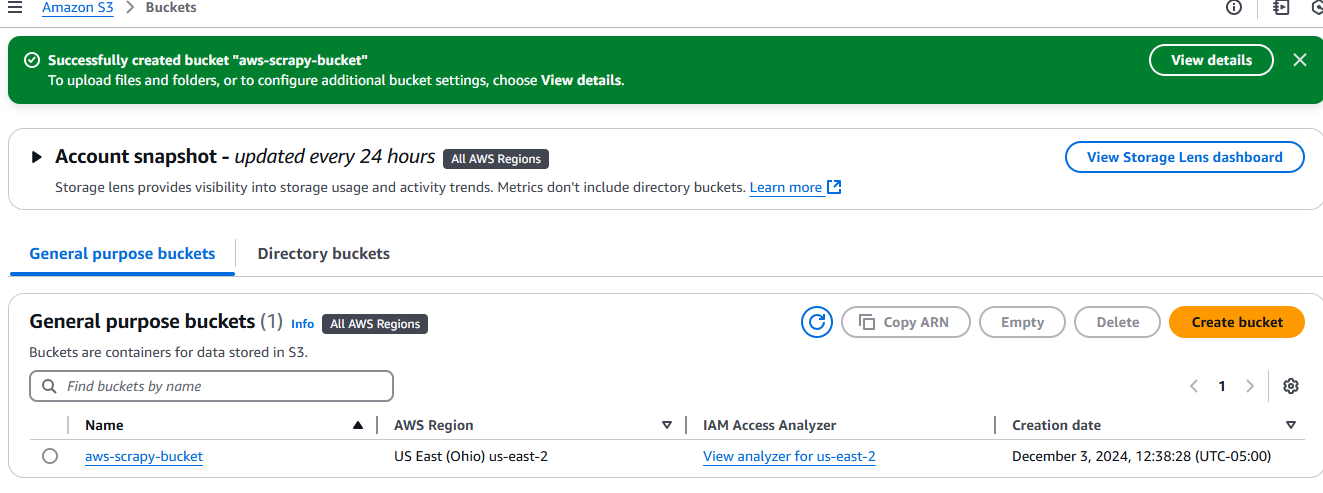
Depois de criá-lo, seu bucket aparecerá na guia Buckets em Amazon S3.
Configurando seu projeto
Crie uma nova pasta de projeto.
mkdir scrapy_aws
Vá para a nova pasta e crie um ambiente virtual.
cd scrapy_aws
python3 -m venv venv
Ative o ambiente.
source venv/bin/activate
Instale o Scrapy.
pip install scrapy
O que coletar
Para sites dinâmicos, medidas anti-bot ou scraping em grande escala, use o Navegador de scraping da Bright Data. Ele automatiza tarefas, ignora CAPTCHAs e se adapta perfeitamente.
Usaremos o site books.toscrape como nosso alvo. É um site educacional dedicado inteiramente ao Scraping de dados. Se você observar a imagem abaixo, cada livro é um artigo com o nome da classe product_pod. Queremos extrair todos esses elementos da página.
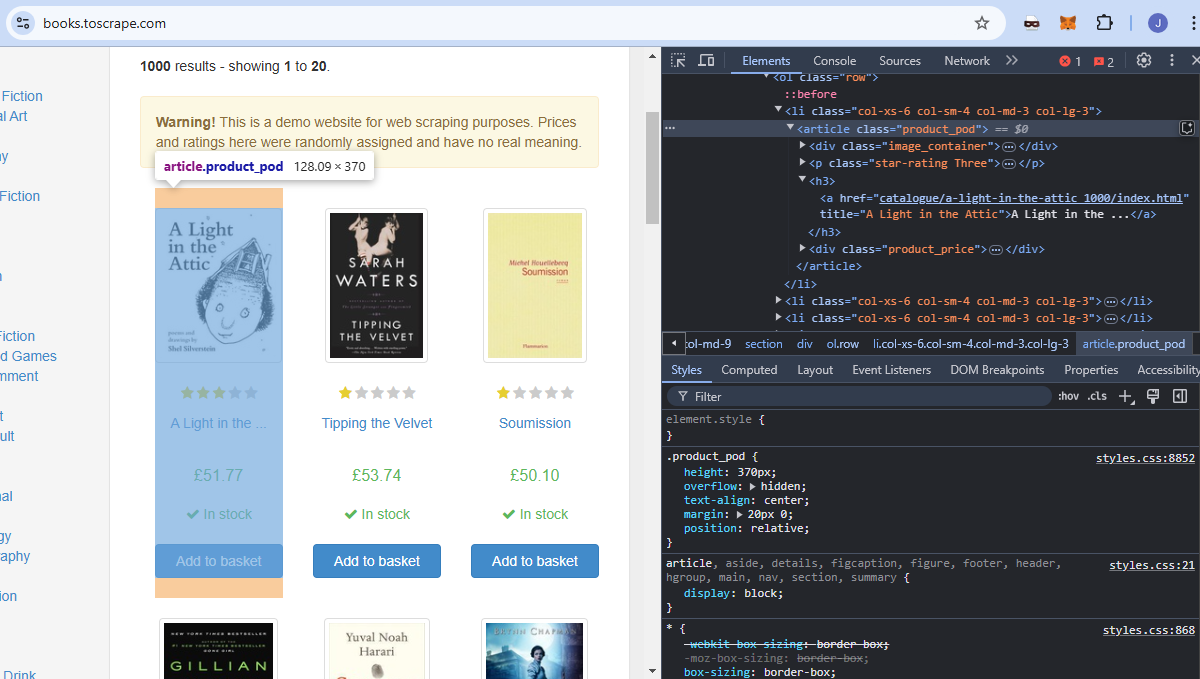
O título de cada livro está incorporado em um elemento a, que está aninhado dentro de um elemento h3.

Cada preço está incorporado em um p que está aninhado dentro de um div. Ele tem um nome de classe price_color.
Escrevendo nosso código
Agora, vamos escrever nosso Scraper e testá-lo localmente. Abra um novo arquivo Python e cole o código a seguir nele. Nomeamos o nosso como aws_spider.py.
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
allowed_domains = ["books.toscrape.com"]
start_urls = ["https://books.toscrape.com"]
def parse(self, response):
for card in response.css("article"):
yield {
"title": card.css("h3 > a::text").get(),
"price": card.css("div > p::text").get(),
}
next_page = response.css("li.next > a::attr(href)").get()
if next_page:
yield scrapy.Request(response.urljoin(next_page))
Você pode testar o spider com o seguinte comando. Ele deve gerar um arquivo JSON cheio de livros com preços.
python -m scrapy runspider aws_spider.py -o books.json
Agora, precisamos de um manipulador. A função do manipulador é simples: executar o spider. Aqui, criaremos dois manipuladores que são basicamente iguais. A principal diferença é que estamos executando um localmente e outro no Lambda.
Aqui está nosso manipulador local, que chamamos de lambda_function_local.py.
import subprocess
def handler(event, context):
# Caminho do arquivo de saída para testes locais
output_file = "books.json"
# Executar o spider Scrapy com o sinalizador -o para salvar a saída em books.json
subprocess.run(["python", "-m", "scrapy", "runspider", "aws_spider.py", "-o", output_file])
# Retornar mensagem de sucesso
return {
'statusCode': '200',
'body': f"Rastreamento concluído! Saída salva em {output_file}",
}
# Adicione este bloco para testes locais
if __name__ == "__main__":
# Simule um evento e contexto de invocação do AWS Lambda
fake_event = {}
fake_context = {}
# Chame o manipulador e imprima o resultado
result = handler(fake_event, fake_context)
print(result)
Exclua books.json. Você pode testar o manipulador local com o seguinte comando. Se tudo estiver funcionando corretamente, você verá um novo books.json na pasta do seu projeto. Lembre-se de alterar bucket_name para o seu próprio bucket.
python lambda_function_local.py
Agora, aqui está o manipulador que usaremos para o Lambda. É bastante semelhante, apenas tem alguns pequenos ajustes para armazenar nossos dados em nosso bucket S3.
import subprocess
import boto3
def handler(event, context):
# Defina os caminhos dos arquivos de saída local e S3
local_output_file = "/tmp/books.json" # Deve estar em /tmp para Lambda
bucket_name = "aws-scrapy-bucket"
s3_key = "scrapy-output/books.json" # Caminho no bucket S3
# Execute o spider Scrapy e salve a saída localmente
subprocess.run(["python3", "-m", "scrapy", "runspider", "aws_spider.py", "-o", local_output_file])
# Carregar o arquivo para o S3
s3 = boto3.client("s3")
s3.upload_file(local_output_file, bucket_name, s3_key)
retorne {
'statusCode': 200,
'body': f"Raspagem concluída! Saída enviada para s3://{bucket_name}/{s3_key}"
}
- Primeiro, salvamos nossos dados em um arquivo temporário:
local_output_file = "/tmp/books.json". Isso evita que eles sejam perdidos. - Nós os enviamos para o nosso bucket com
s3.upload_file(local_output_file, bucket_name, s3_key).
Implantação no AWS Lambda
Agora, precisamos implantar no AWS Lambda.
Crie uma pasta de pacote.
mkdir package
Copie nossas dependências para a pasta do pacote.
cp -r venv/lib/python3.*/site-packages/* package/
Copie os arquivos. Certifique-se de copiar o manipulador que você criou para o Lambda, não o manipulador local que testamos anteriormente.
cp lambda_function.py aws_spider.py package/
Compacte a pasta do pacote em um arquivo zip.
zip -r lambda_function.zip package/
Depois de criar o arquivo ZIP, precisamos acessar o AWS Lambda e selecionar Criar função. Quando solicitado, insira suas informações básicas, como tempo de execução (Python) e arquitetura.
Certifique-se de adicionar permissão para acessar seu bucket S3.
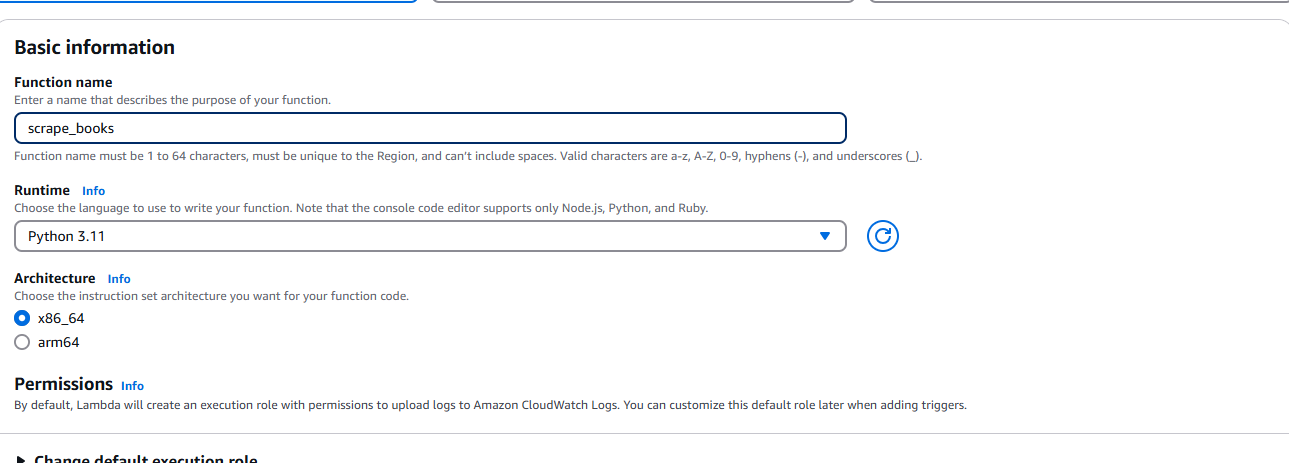
Depois de criar a função, selecione Upload from ( Carregar de) no menu suspenso. Ele está localizado no canto superior direito da guia Source (Fonte).

Escolha o arquivo .zip e carregue o arquivo ZIP que você criou.
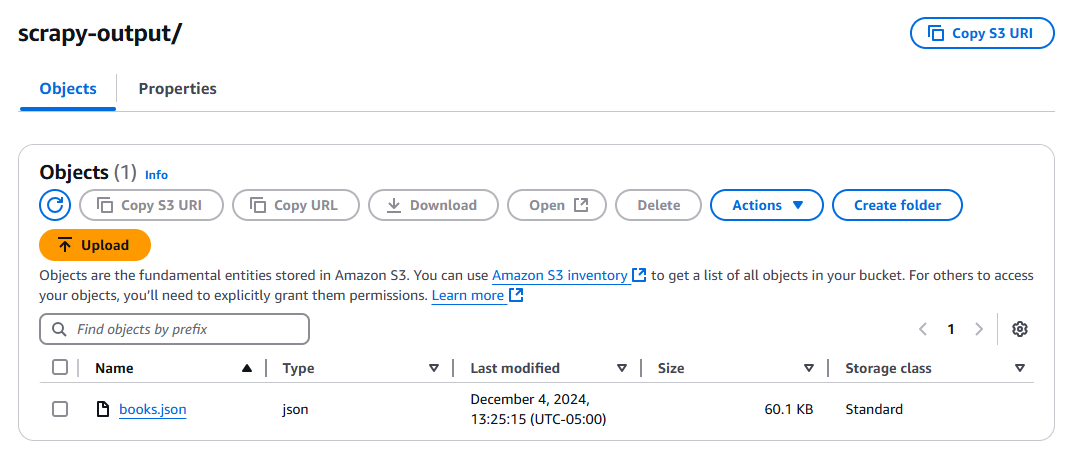
Clique no botão Testar e aguarde a execução da função. Após a execução, verifique seu bucket S3 e você deverá ter um novo arquivo, books.json.
Dicas para solução de problemas
Não é possível encontrar o Scrapy
Você pode receber uma mensagem de erro informando que o Scrapy não foi encontrado. Se isso acontecer, você precisará adicionar o seguinte à sua matriz de comandos em subprocess.run().

Problemas gerais de dependência
Você precisa se certificar de que suas versões do Python são as mesmas. Verifique sua instalação local do Python.
python --version
Se este comando apresentar uma versão diferente da sua função Lambda, altere a configuração do Lambda para que corresponda.
Problemas com o manipulador

Seu manipulador deve corresponder à função que você escreveu em lambda_function.py. Como você pode ver acima, temos lambda_function.handler. lambda_function representa o nome do seu arquivo Python. handler é o nome da função.
Não é possível gravar no S3
Você pode encontrar problemas de permissões ao armazenar a saída. Se isso acontecer, você precisará adicionar essas permissões à sua instância Lambda.
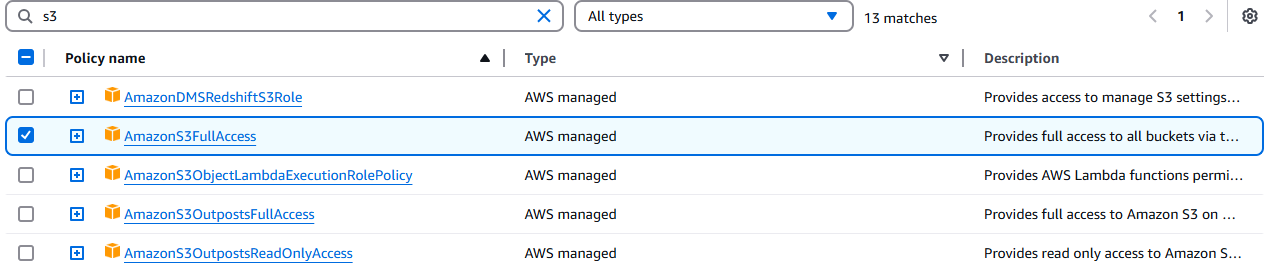
Acesse o Console IAM e procure sua função Lambda. Clique nela e, em seguida, clique no menu suspenso Adicionar permissões.
Clique em Anexar políticas.
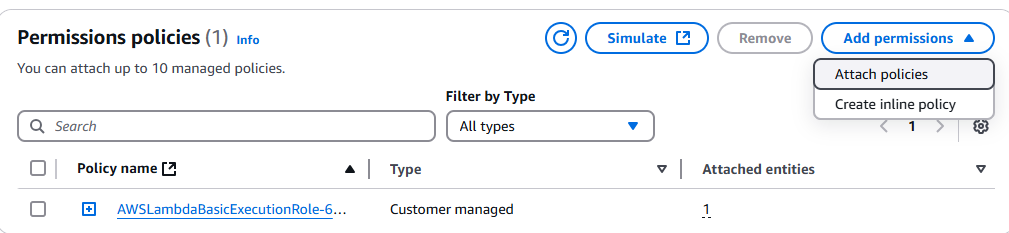
Selecione AmazonS3FullAccess.
Conclusão
Você conseguiu! Neste ponto, você deve ser capaz de se virar na interface de usuário complicada conhecida como console AWS. Você sabe como escrever um rastreador com o Scrapy. Você sabe como empacotar o ambiente com Linux ou WSL para garantir a compatibilidade binária com o Amazon Linux.
Se você não gosta de fazer scraping manual, confira nossas APIs de Scraper e Conjuntos de dados prontos. Inscreva-se agora para iniciar seu teste grátis!





