
Este artigo aborda como executar cargas de trabalho de scraping de dados em grande escala usando PySpark e Bright Data. Se você precisar coletar dados de centenas de milhares de páginas de produtos, realizar o monitoramento de preços em centenas de sites ou construir Conjuntos de dados de treinamento a partir de milhões de páginas, scripts em uma única máquina não serão suficientes.
Os padrões apresentados aqui mostram como distribuir o trabalho de scraping por clusters, mantendo a confiabilidade do pipeline à medida que o volume de solicitações cresce.
Ao final, você saberá como:
- Tratar grandes listas de URLs como Conjuntos de datos distribuídos usando o PySpark
- Executar cargas de trabalho de scraping de forma eficiente no nível da partição
- Projetar workers capazes de lidar com repetições e falhas sem reiniciar todo o trabalho
- Lidar com o roteamento de Proxy e a confiabilidade da rede à medida que o volume de solicitações aumenta
Quando o Scraping de dados se torna um problema distribuído
A maioria dos projetos de scraping começa da mesma forma: um desenvolvedor escreve um script, lê uma lista de URLs, envia solicitações e salva os resultados.
As falhas aparecem assim que a carga de trabalho cresce. Trabalhos que antes levavam minutos passam a levar horas. Algumas solicitações com falha podem paralisar uma execução após o processamento de milhares de páginas, e gerenciar novas tentativas dentro do mesmo script enquanto lida com a busca e o Parsing rapidamente se transforma em uma bagunça. Já vi equipes mantendo esses Scrapers de arquivo único por meses, corrigindo um caso extremo após o outro, quando o verdadeiro problema é que a arquitetura não se adapta mais à tarefa.
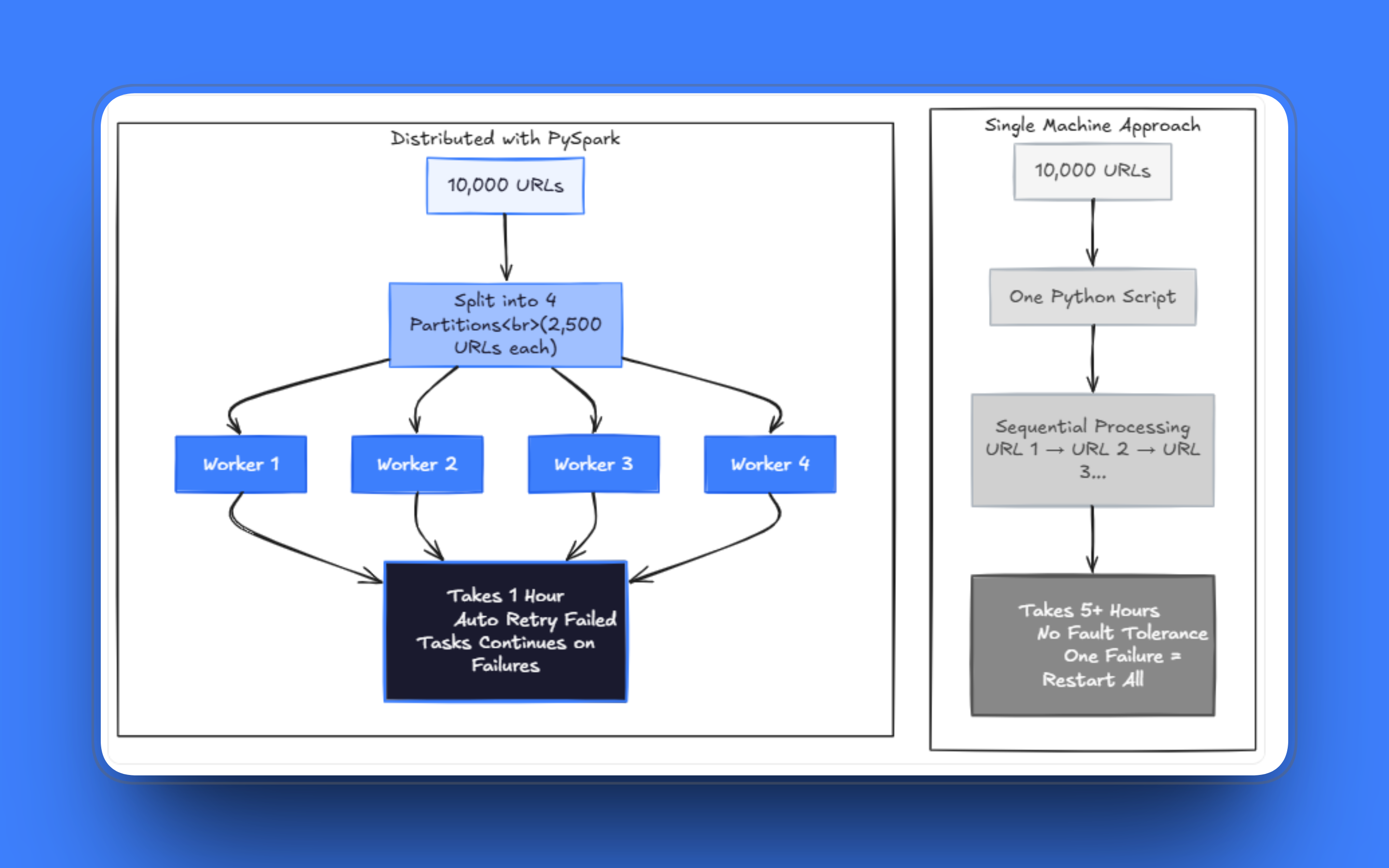
Rastrear centenas de milhares de páginas em uma única máquina leva uma quantidade impraticável de tempo, mesmo com multithreading. Em escala, você precisa executar em vários workers, e o sistema precisa continuar funcionando mesmo quando uma parte das solicitações falha. O caminho a seguir é parar de pensar na lista de URLs como uma fila ordenada e começar a tratá-la como um Conjunto de dados que você pode distribuir.
Por que o PySpark é uma boa opção aqui
O PySpark foi construído com base na ideia de dividir Conjuntos de dados em partições e processá-los em paralelo em um cluster de máquinas. O modelo se aplica diretamente ao Scraping de dados: cada URL é uma unidade de trabalho, as partições agrupam URLs em lotes e os executores processam esses lotes de forma independente.
Em vez de gerenciar uma fila com o Celery ou uma configuração de multiprocessamento feita em casa, o Spark oferece tolerância a falhas e agendamento sem que você precise construí-los. Se uma tarefa falhar, o Spark a reprograma. Se um nó cair, o trabalho é reatribuído. Você ainda precisa escrever uma lógica de repetição sensata dentro de suas tarefas, mas a camada de orquestração é cuidada para você.
Padrão 1: URLs como um conjunto de dados distribuído
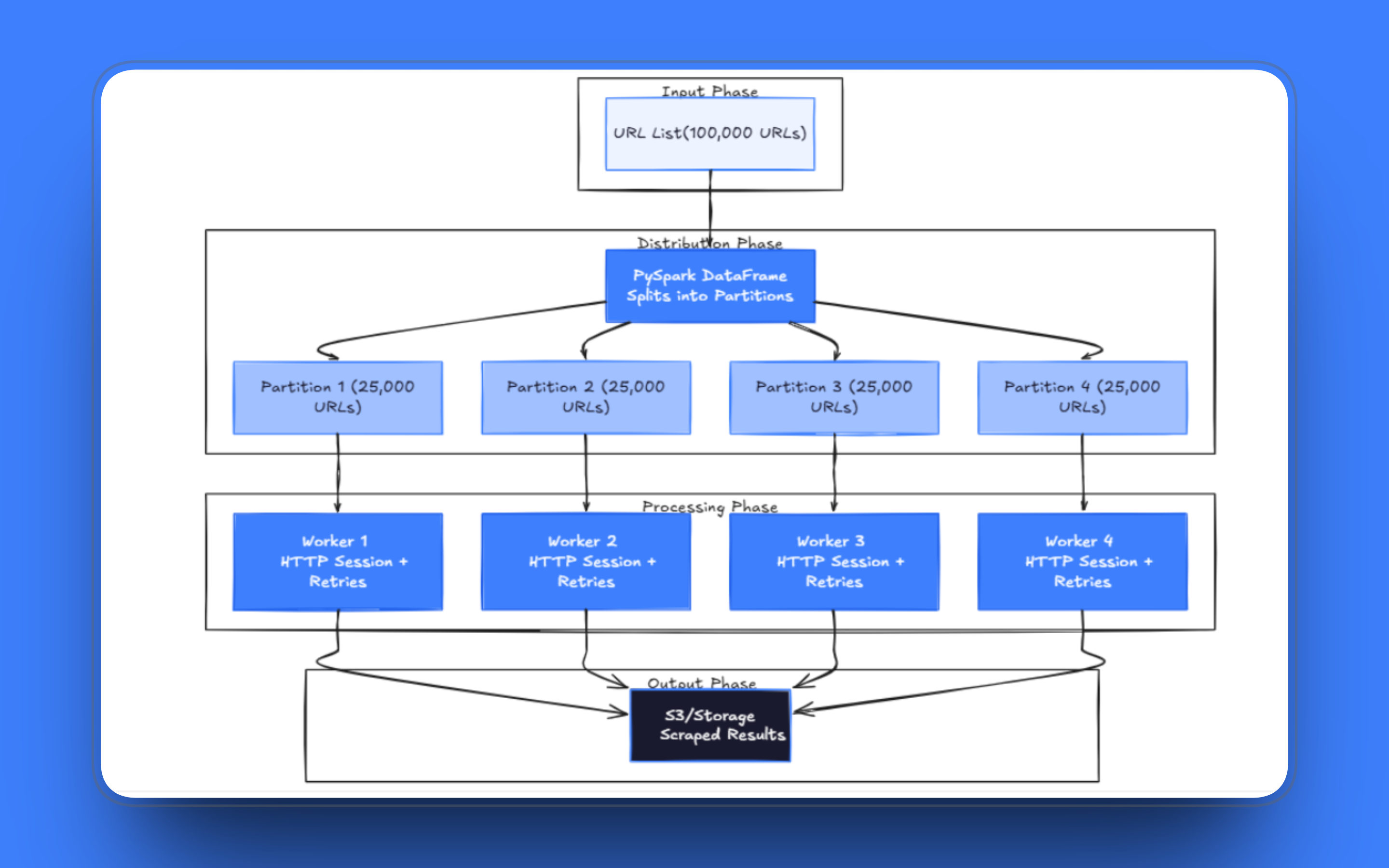
A base de qualquer pipeline de scraping distribuído é a forma como você carrega a lista de URLs. Com o PySpark, as URLs vão para um DataFrame, e o Spark as distribui automaticamente entre os workers. Cada partição contém uma fatia dos dados, e o Spark atribui essas partições aos executores disponíveis.
Uma configuração básica se parece com o seguinte:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
urls = [
("https://example.com/page1",),
("https://example.com/page2",),
("https://example.com/page3",)
]
df = spark.createDataFrame(urls, ["url"])Em produção, você carregaria a lista de URLs a partir de um arquivo, uma tabela de banco de dados ou um armazenamento de objetos, em vez de codificá-la diretamente. O esquema também é importante quando você começa a adicionar metadados, como prioridade de rastreamento ou carimbos de data/hora da última obtenção.
A contagem de partições é a primeira decisão de ajuste que você enfrentará. Com poucas partições, os workers ficam ociosos aguardando solicitações lentas; com muitas, o Spark gasta uma quantidade desproporcional de tempo com a sobrecarga de agendamento, em vez da recuperação propriamente dita.
Um ponto de partida razoável para uma carga de trabalho de scraping é de 2 a 4 partições por núcleo do executor; depois, ajuste com base nos logs das tarefas. Se os executores concluírem as partições em menos de um segundo ou demorarem consistentemente mais de 10 minutos, o tamanho da partição precisa ser ajustado.
Padrão 2: Executar solicitações no nível da partição
A primeira tentativa natural é aplicar uma transformação no nível da linha a cada URL no DataFrame. Essa abordagem funciona, mas não é adequada para Scraping de dados. Cada solicitação aciona uma chamada de função separada, o que significa uma nova conexão para cada URL, a menos que você tome cuidado. A sobrecarga se acumula rapidamente ao longo de milhões de linhas.
A abordagem correta é mapPartitions(). Em vez de processar uma linha de cada vez, ela passa para sua função uma partição inteira como um iterador. Você cria uma sessão HTTP uma vez e a reutiliza para todas as solicitações na partição. O pool de conexões em uma sessão de longa duração é significativamente mais rápido do que estabelecer uma nova conexão TCP para cada URL, especialmente com servidores que suportam HTTP keep-alive.
from pyspark.sql import SparkSession
import requests
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
urls = [
("https://example.com/page1",),
("https://example.com/page2",),
("https://example.com/page3",)
]
df = spark.createDataFrame(urls, ["url"])
def scrape_partition(rows):
session = requests.Session()
for row in rows:
url = row["url"]
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
except Exception:
yield {
"url": url,
"status_code": None,
"html": None
}
results = df.rdd.mapPartitions(scrape_partition)Solicitações com falha geram um registro com campos nulos, em vez de levantar uma exceção. A abordagem é intencional. Permitir que uma exceção se propague interrompe toda a tarefa de partição, perdendo todo o trabalho realizado antes da falha. Retornar um registro nulo mantém a partição em execução e oferece uma maneira clara de identificar e tentar novamente as URLs com falha posteriormente.
Uma coisa que vale a pena fazer logo no início é definir um esquema de saída explícito usando StructType, em vez de deixar o Spark inferi-lo a partir do RDD. A inferência de esquema requer uma varredura completa dos dados, o que é dispendioso e pode, ocasionalmente, produzir resultados inesperados quando o conteúdo da resposta está inesperadamente vazio.
Padrão 3: Projetando Workers Capazes de Lidar com Execuções Longas
Um trabalho que rastreia um milhão de páginas será executado por horas. Durante execuções longas, você verá reinicializações de conexão, timeouts de DNS, erros 429 de servidores com limitação de taxa e servidores ocasionalmente perdendo conexões no meio da resposta. Nada disso são bugs no seu código; são apenas o que acontece quando você faz solicitações HTTP em grande escala.
A função de partição é o local certo para lidar com todas essas questões. A lógica de repetição, os atrasos de recuo, as configurações de tempo limite e o registro de falhas devem estar todos lá. Manter tudo em uma única função de partição mantém o restante do pipeline do Spark limpo e permite que você teste o comportamento do worker de forma independente.
import requests
import time
def scrape_partition(rows):
session = requests.Session()
for row in rows:
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts) # recuo exponencial
if not success:
yield {
"url": url,
"status_code": None,
"html": None
}Algumas observações aqui. O atraso na repetição usa recuo exponencial em vez de um intervalo fixo. Um atraso fixo de 2 segundos é adequado para falhas ocasionais de rede, mas retarda consideravelmente os trabalhadores ao acessar um servidor que está constantemente sobrecarregado. Além disso, registre o tipo de exceção antes de retornar o registro nulo; a diferença entre um tempo limite de conexão e um erro 403 Forbidden fornece informações muito diferentes sobre o que está acontecendo no upstream.
Monitoramento de tarefas em produção
Quando uma tarefa processa milhões de URLs ao longo de várias horas, você precisa ter visibilidade do que está acontecendo enquanto ela é executada. No mínimo, acompanhe estas métricas de cada partição:
def scrape_partition(rows):
session = requests.Session()
partition_stats = {
"urls_attempted": 0,
"urls_succeeded": 0,
"urls_failed": 0,
"status_codes": {}
}
for row in rows:
partition_stats["urls_attempted"] += 1
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
partition_stats["urls_succeeded"] += 1
code = response.status_code
partition_stats["status_codes"][code] =
partition_stats["status_codes"].get(code, 0) + 1
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts)
if not success:
partition_stats["urls_failed"] += 1
yield {
"url": url,
"status_code": None,
"html": None
}
# Registre as estatísticas quando a partição for concluída
print(f"Estatísticas da partição: {partition_stats}")Observe a interface do usuário do Spark para verificar as taxas de conclusão das tarefas enquanto o trabalho estiver em execução. Se as tarefas forem concluídas em velocidades muito diferentes, suas partições estão desequilibradas. Se você observar erros 403 ou 429 constantes nos logs, sua rotação de Proxy precisa de ajuste ou você precisa adicionar atrasos nas solicitações. O objetivo é detectar problemas enquanto o trabalho ainda está em execução, não descobri-los seis horas depois, quando ele falhar.
Gravação de resultados dos workers (o padrão de produção)
Para trabalhos com duração superior a uma hora, existe um modo de falha contra o qual a lógica de repetição não oferece proteção: o processo do driver encerrar no meio da execução. O Spark reprograma tarefas individuais se elas falharem, mas quando um driver fica inoperante, todo o trabalho é perdido.
A solução é gravar os resultados em um armazenamento persistente à medida que cada partição é concluída, em vez de enviar tudo de volta para o driver e manter os resultados na memória até que o trabalho seja concluído. Use foreachPartition(), que processa cada partição e permite gravar a saída diretamente do worker sem que os dados retornem pelo driver:
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
import requests, time, uuid
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
spark.sparkContext.setCheckpointDir("s3://your-bucket/checkpoints/")
schema = StructType([
StructField("url", StringType(), True),
StructField("status_code", IntegerType(), True),
StructField("html", StringType(), True)
])
def scrape_and_write(rows):
session = requests.Session()
results = []
for row in rows:
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
results.append((url, response.status_code, response.text))
success = True
exceto Exception como e:
tentativas += 1
time.sleep(2 ** tentativas)
se sucesso for False:
resultados.append((url, None, None))
# Grave os resultados desta partição diretamente do worker
partition_id = str(uuid.uuid4())
spark.createDataFrame(results, schema).write.mode("append").parquet(
f"s3://your-bucket/scrape-results/batch={partition_id}"
)
df.rdd.foreachPartition(scrape_and_write)Cada worker grava seu próprio arquivo de saída de forma independente. Se o driver parar no meio do processo, as partições concluídas já estarão no armazenamento, e apenas as que estão em andamento precisarão ser executadas novamente. Para trabalhos com transformações Spark posteriores nos dados coletados, rdd.checkpoint() é uma alternativa mais leve: ela materializa o RDD no diretório de checkpoint antes da execução da transformação, impedindo que o Spark repita toda a etapa de coleta caso uma etapa posterior falhe.
Padrão 4: Encaminhamento de solicitações por meio de uma rede Proxy
Executar vários workers em paralelo aumenta a taxa de transferência, mas o servidor de destino receberá uma enxurrada de solicitações provenientes do intervalo de IPs do seu cluster. A maioria dos sites tem limitação de taxa ou bloqueio configurado exatamente para esse padrão de tráfego concentrado proveniente de um único intervalo de IPs. O roteamento de solicitações por meio de uma rede Proxy residencial distribui o tráfego por vários endereços IP, o que ajuda a manter os workers em execução sem acionar bloqueios.
Você configura o Proxy uma vez por sessão dentro da função de partição, e todas as solicitações feitas pela sessão são roteadas pela rede automaticamente:
import requests
BRIGHTDATA_PROXY = (
"http://brd-customer-<CUSTOMER_ID>-zona-<ZONE_NAME>:"
"<ZONE_PASSWORD>@brd.superproxy.io:33335"
)
def scrape_partition(rows):
session = requests.Session()
session.proxies = {
"http": BRIGHTDATA_Proxy,
"https": BRIGHTDATA_Proxy
}
for row in rows:
url = row["url"]
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
except Exception as e:
yield {
"url": url,
"status_code": None,
"html": None
}Dependendo da configuração da sua zona Bright Data, as solicitações podem gerar erros de verificação SSL porque o tráfego passa pela camada de certificados intermediários deles. Uma solução rápida é passar verify=False e seguir em frente, mas essa abordagem desativa totalmente a validação de certificados, o que significa que seus workers não poderão mais detectar uma conexão comprometida entre o Proxy e o destino.
A correção correta é baixar o certificado CA da Bright Data e passá-lo via verify='/path/to/brightdata-ca.crt', o que mantém a validação completa intacta. Também vale a pena notar: a URL do Proxy no exemplo deve ser obtida de uma variável de ambiente ou de um gerenciador de segredos em produção. Em um ambiente distribuído, essas credenciais são serializadas e enviadas para cada nó de worker, de modo que um vazamento expõe mais do que faria em uma única máquina.
Para destinos que servem conteúdo renderizado em JavaScript, o roteamento por meio de um Proxy padrão não será suficiente. O Navegador de scraping da Bright Data lida com a execução de JavaScript, Resolução de CAPTCHA e impressão digital do navegador, além de se integrar com o Playwright e o Puppeteer. A estrutura da função de partição permanece a mesma; você está apenas trocando a sessão de solicitação por uma instância do navegador Playwright direcionada ao endpoint do Navegador de scraping.
Solução de problemas comuns
Alguns problemas aparecem consistentemente em produção. Se as tarefas de partição atingirem o tempo limite repetidamente, verifique primeiro o tamanho da partição. Partições com mais de 10.000 URLs excederão o tempo limite padrão do Spark quando as solicitações forem lentas. Reparticione em lotes menores ou aumente spark.task.maxFailures e spark.network.timeout.
Receber erros 429 mesmo usando Proxy significa que vários workers estão acessando o mesmo domínio simultaneamente. Adicione um jitter aleatório entre as solicitações:
import random
import time
def scrape_partition(rows):
session = requests.Session()
for row in rows:
time.sleep(random.uniform(1, 3))
# ... resto da lógica de scrapingErros de memória nos executores geralmente significam que você está acumulando HTML completo antes de gravar. Grave os resultados com mais frequência ou analise e descarte o HTML dentro da função de partição se precisar apenas dos campos extraídos.
Partições que terminam em velocidades muito diferentes indicam uma distribuição desequilibrada. Reparticione com uma contagem maior para distribuir domínios lentos entre os trabalhadores.
Conclusão
Esses padrões fornecem uma base que se mantém em escala: distribua a lista de URLs, execute solicitações no nível da partição, crie workers que resistam a execuções longas e roteie o tráfego por uma rede Proxy que permaneça desbloqueada à medida que o volume cresce.
Tarefas de produção precisarão de esquemas explícitos, pontos de verificação e tratamento adequado de segredos, mas as decisões estruturais são as mesmas independentemente do tamanho. No que diz respeito à rede e à infraestrutura, a Bright Data cobre a maior parte do que você precisaria construir e manter por conta própria.






