

Neste guia, você verá:
- Os motivos pelos quais a análise de HTML no PHP é útil
- Os pré-requisitos para começar a trabalhar com o objetivo do artigo
- Como analisar HTML em PHP usando:
DomHTMLDocument- Analisador HTML DOM simples
DomCrawlerdo Symfony
- Uma tabela de comparação das três abordagens
Vamos mergulhar de cabeça!
Por que analisar HTML em PHP?
A análise de HTML no PHP envolve a conversão do conteúdo HTML em sua estrutura DOM(Document Object Model). Uma vez no formato DOM, você pode navegar e manipular facilmente o conteúdo HTML.
Em particular, os principais motivos para analisar HTML no PHP são:
- Extração de dados: Coleta de conteúdo específico de páginas da Web, como texto ou atributos de elementos HTML.
- Automação: Automatize tarefas como raspagem de conteúdo, geração de relatórios e agregação de dados a partir de conteúdo HTML.
- Manipulação de conteúdo HTML no lado do servidor: Analise o HTML para manipular, limpar ou formatar o conteúdo da Web no servidor antes de exibi-lo em seu aplicativo.
Descubra as melhores bibliotecas de análise de HTML!
Pré-requisitos
Antes de começar a programar, verifique se o PHP 8.4+ está instalado em seu computador. Você pode verificar isso executando o seguinte comando:
php -v
O resultado deve ser semelhante a este:
PHP 8.4.3 (cli) (built: Jan 19 2026 14:20:58) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.4.3, Copyright (c) Zend Technologies
with Zend OPcache v8.4.3, Copyright (c), by Zend Technologies
Em seguida, você deseja inicializar um projeto do Composer para facilitar o gerenciamento de dependências. Se o Composer não estiver instalado em seu sistema, faça o download e siga as instruções de instalação.
Primeiro, crie uma nova pasta para seu projeto PHP HTML:
mkdir php-html-parser
Navegue até a pasta em seu terminal e inicialize um projeto do Composer dentro dela usando o comando composer init:
composer init
Durante esse processo, você será solicitado a responder a algumas perguntas. As respostas padrão funcionarão, mas fique à vontade para adicionar detalhes mais específicos para seu projeto de análise de HTML PHP, se desejar.
Em seguida, abra a pasta do projeto em seu IDE favorito. O Visual Studio Code com a extensão PHP ou o IntelliJ WebStorm são boas opções para o desenvolvimento de PHP.
Agora, adicione um arquivo index.php vazio à pasta do projeto. A estrutura de seu projeto deve ter a seguinte aparência:
php-html-parser/
├── vendor/
├── composer.json
└── index.php
Abra o index.php e adicione o seguinte código para inicializar seu projeto:
<?php
require_once __DIR__ . "/vendor/autoload.php";
// scraping logic...
Em breve, esse arquivo conterá a lógica para analisar o HTML no PHP.
Agora você pode executar seu script com este comando:
php index.php
Ótimo! Você está pronto para começar a analisar o HTML no PHP. A partir daqui, você pode começar a adicionar a lógica necessária de recuperação e análise de HTML ao seu script.
Recuperação de HTML em PHP
Antes de analisar o HTML no PHP, você precisa de algum HTML para analisar. Nesta seção, veremos duas abordagens diferentes para acessar o conteúdo HTML no PHP.
Com o CURL
O PHP suporta nativamente o cURL, um cliente HTTP popular usado para realizar solicitações HTTP. Ative a extensão cURL ou instale-a no Linux com:
sudo apt-get install php8.4-curl
Você pode usar o cURL para enviar uma solicitação HTTP GET a um servidor on-line e recuperar o documento HTML retornado pelo servidor.
Aqui está um script de exemplo que faz uma solicitação GET simples e recupera o conteúdo HTML:
// initialize cURL session
$ch = curl_init();
// set the URL you want to make a GET request to
curl_setopt($ch, CURLOPT_URL, "https://www.scrapethissite.com/pages/forms/?per_page=100");
// return the response instead of outputting it
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// execute the cURL request and store the result in $response
$html = curl_exec($ch);
// close the cURL session
curl_close($ch);
// output the HTML response
echo $html;
Adicione o snippet acima ao index.php e inicie-o. Ele produzirá o seguinte código HTML:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hockey Teams: Forms, Searching and Pagination | Scrape This Site | A public sandbox for learning web scraping</title>
<link rel="icon" type="image/png" href="/static/images/scraper-icon.png" />
<!-- Omitted for brevity... -->
</html>
Saiba mais em nosso guia sobre solicitações cURL GET em PHP.
De um arquivo
Outra maneira de obter o conteúdo HTML é armazená-lo em um arquivo dedicado. Para fazer isso:
- Visite uma página de sua escolha no navegador
- Clique com o botão direito do mouse na página
- Selecione a opção “View page source” (Exibir origem da página)
- Copie e cole o HTML em um arquivo
Como alternativa, você pode escrever sua própria lógica HTML em um arquivo.
Para este exemplo, assumiremos que o arquivo se chama index.html. Ele contém o HTML da página “Hockey Teams” do Scrape This Site, que foi recuperado anteriormente usando o cURL:
Análise de HTML em PHP: 3 abordagens
Nesta seção, você aprenderá a usar três bibliotecas diferentes para analisar HTML no PHP:
- Usando
DomHTMLDocumentpara o PHP básico - Usando a biblioteca Simple HTML DOM Parser
- Usando o componente
DomCrawlerdo Symfony
Nos três casos, você verá como analisar a cadeia de caracteres HTML recuperada via cURL ou o conteúdo HTML lido do arquivo index.html local.
Em seguida, você aprenderá a usar os métodos fornecidos por cada biblioteca de análise de HTML do PHP para selecionar todas as entradas do time de hóquei na página e extrair dados delas:
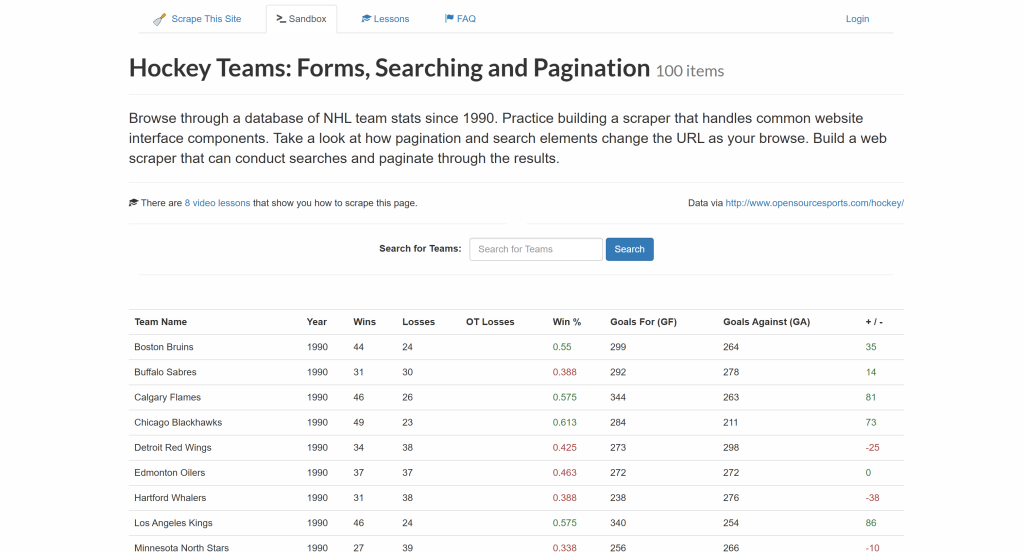
O resultado final será uma lista de entradas de times de hóquei raspados contendo os seguintes detalhes:
- Nome da equipe
- Ano
- Vitórias
- Perdas
- Vitória %
- Gols a favor (GF)
- Gols contra (GA)
- Diferença de gols
Você pode extraí-los da tabela HTML com essa estrutura:
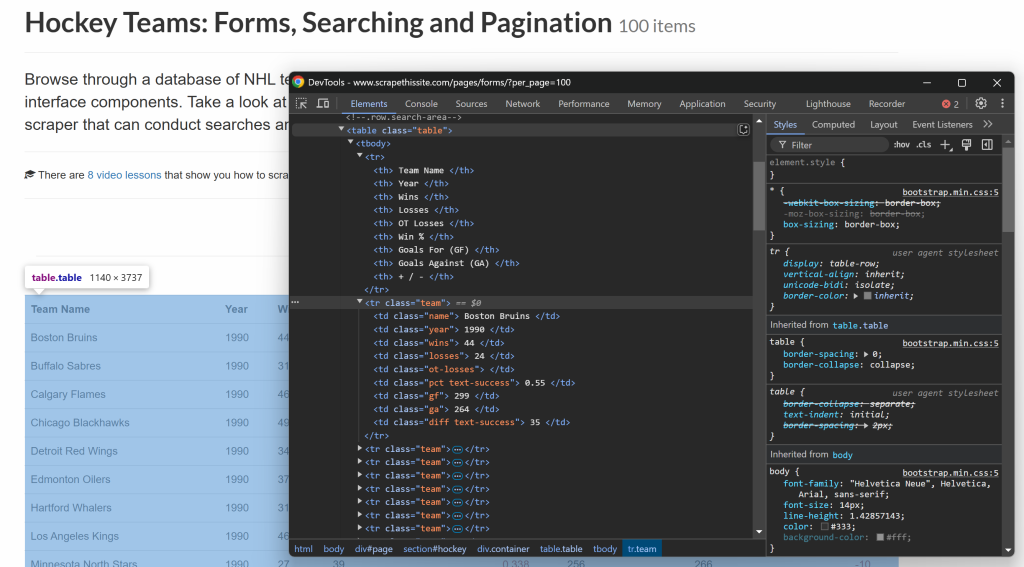
Como você pode ver, cada coluna em uma linha da tabela tem uma classe específica. Você pode extrair dados dela selecionando elementos usando sua classe como um seletor CSS e, em seguida, recuperando seu conteúdo acessando seu texto.
Lembre-se de que a análise de HTML é apenas uma etapa em um script de raspagem da Web. Para se aprofundar, leia nosso tutorial sobre raspagem da Web com PHP.
Agora, vamos explorar três abordagens diferentes para a análise de HTML no PHP.
Abordagem nº 1: com DomHTMLDocument
O PHP 8.4+ vem com uma classe DomHTMLDocument integrada. Ela representa um documento HTML e permite que você analise o conteúdo HTML e navegue na árvore DOM. Veja como usá-la para análise de HTML no PHP!
Etapa 1: Instalação e configuração
DomHTMLDocument faz parte da biblioteca padrão do PHP. Ainda assim, você precisa ativar a extensão DOM ou instalá-la com este comando do Linux para usá-la:
sudo apt-get install php-dom
Nenhuma ação adicional é necessária. Agora você está pronto para usar o DomHTMLDocument para análise de HTML no PHP.
Etapa 2: Análise de HTML
Você pode analisar a cadeia de caracteres HTML da seguinte forma:
$dom = DOMHTMLDocument::createFromString($html);
De forma equivalente, você pode analisar o arquivo index.html com:
$dom = DOMHTMLDocument::createFromFile("./index.html");
$dom é um objeto DomHTMLDocument que expõe os métodos necessários para a análise de dados.
Etapa #3: Análise de dados
Você pode selecionar todas as entradas do time de hóquei usando DOMHTMLDocument com a seguinte abordagem:
// select each row on the page
$table = $dom->getElementsByTagName("table")->item(0);
$rows = $table->getElementsByTagName("tr");
// iterate through each row and extract data
foreach ($rows as $row) {
$cells = $row->getElementsByTagName("td");
// extracting the data from each column
$team = trim($cells->item(0)->textContent);
$year = trim($cells->item(1)->textContent);
$wins = trim($cells->item(2)->textContent);
$losses = trim($cells->item(3)->textContent);
$win_pct = trim($cells->item(5)->textContent);
$goals_for = trim($cells->item(6)->textContent);
$goals_against = trim($cells->item(7)->textContent);
$goal_diff = trim($cells->item(8)->textContent);
// create an array for the scraped team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print ("n");
}
O DOMHTMLDocument não oferece métodos de consulta avançados. Portanto, você precisa confiar em métodos como getElementsByTagName() e iteração manual.
Aqui está um detalhamento dos métodos usados:
getElementsByTagName(): Recupera todos os elementos de uma determinada tag (como<table>,<tr>ou<td>) dentro do documento.item(): Retorna um elemento individual de uma lista de elementos retornados porgetElementsByTagName().textContent: Essa propriedade fornece o conteúdo de texto bruto de um elemento, permitindo que você extraia os dados visíveis (como o nome da equipe, o ano etc.).
Também usamos trim() para remover espaços em branco extras antes e depois do conteúdo do texto para obter dados mais limpos.
Quando adicionado ao index.php, o snippet acima produzirá este resultado:
Array
(
[team] => Boston Bruins
[year] => 1990
[wins] => 44
[losses] => 24
[win_pct] => 0.55
[goals_for] => 299
[goals_against] => 264
[goal_diff] => 35
)
// omitted for brevity...
Array
(
[team] => Detroit Red Wings
[year] => 1994
[wins] => 33
[losses] => 11
[win_pct] => 0.688
[goals_for] => 180
[goals_against] => 117
[goal_diff] => 63
)
Abordagem nº 2: usando um analisador HTML DOM simples
O Simple HTML DOM Parser é uma biblioteca PHP leve que facilita a análise e a manipulação do conteúdo HTML. A biblioteca é mantida ativamente e tem mais de 880 estrelas no GitHub.
Etapa 1: Instalação e configuração
Você pode instalar o Simple HTML Dom Parser via Composer com este comando:
composer require voku/simple_html_dom
Como alternativa, você pode fazer o download manual e incluir o arquivo simple_html_dom.php em seu projeto.
Em seguida, importe-o no index.php com esta linha de código:
use vokuhelperHtmlDomParser;
Etapa 2: Análise de HTML
Para analisar uma cadeia de caracteres HTML, use o método file_get_html():
$dom = HtmlDomParser::str_get_html($html);
Para analisar o index.html, escreva file_get_html() em vez disso:
$dom = HtmlDomParser::file_get_html($str);
Isso carregará o conteúdo HTML em um objeto $dom, o que permite que você navegue facilmente no DOM.
Etapa #3: Análise de dados
Extraia os dados do time de hóquei do HTML usando o Simple HTML DOM Parser:
// find all rows in the table
$rows = $dom->findMulti("table tr.team");
// loop through each row to extract the data
foreach ($rows as $row) {
// extract data using CSS selectors
$team_element = $row->findOne(".name");
$team = trim($team_element->plaintext);
$year_element = $row->findOne(".year");
$year = trim($year_element->plaintext);
$wins_element = $row->findOne(".wins");
$wins = trim($wins_element->plaintext);
$losses_element = $row->findOne(".losses");
$losses = trim($losses_element->plaintext);
$win_pct_element = $row->findOne(".pct");
$win_pct = trim($win_pct_element->plaintext);
$goals_for_element = $row->findOne(".gf");
$goals_for = trim($goals_for_element->plaintext);
$goals_against_element = $row->findOne(".ga");
$goals_against = trim(string: $goals_against_element->plaintext);
$goal_diff_element = $row->findOne(".diff");
$goal_diff = trim(string: $goal_diff_element->plaintext);
// create an array with the extracted team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print("n");
}
Os recursos do Simple HTML DOM Parser usados acima são:
findMulti(): Seleciona todos os elementos identificados pelo seletor CSS fornecido.findOne(): Localiza o primeiro elemento que corresponde ao seletor CSS fornecido.plaintext: Um atributo para obter o conteúdo de texto bruto dentro de um elemento HTML.
Desta vez, usamos seletores CSS com uma lógica mais completa e robusta. Ainda assim, o resultado será o mesmo da abordagem inicial de PHP para análise de HTML.
Abordagem nº 3: usando o componente DomCrawler do Symfony
O componente DomCrawler do Symfony oferece uma maneira fácil de analisar documentos HTML e extrair dados deles.
Observação: o componente faz parte da estrutura do Symfony, mas também pode ser usado de forma autônoma, como faremos nesta seção.
Etapa 1: Instalação e configuração
Instale o componente DomCrawler do Symfony com este comando do Composer:
composer require symfony/dom-crawler
Em seguida, importe-o no arquivo index.php:
use SymfonyComponentDomCrawlerCrawler;
Etapa 2: Análise de HTML
Para analisar uma string HTML, crie uma instância do Crawler com o método html():
$crawler = new Crawler($html);
Para analisar um arquivo, use file_get_contents() e crie a instância do rastreador:
$crawler = new Crawler(file_get_contents("./index.html"));
As linhas acima carregarão o conteúdo HTML no objeto $crawler, que fornece métodos fáceis para analisar e extrair dados.
Etapa #3: Análise de dados
Extraia os dados do time de hóquei usando o componente DomCrawler:
// select all rows within the table
$rows = $crawler->filter("table tr.team");
// loop through each row to extract the data
$rows->each(function ($row, $i) {
// extract data using CSS selectors
$team_element = $row->filter(".name");
$team = trim($team_element->text());
$year_element = $row->filter(".year");
$year = trim($year_element->text());
$wins_element = $row->filter(".wins");
$wins = trim($wins_element->text());
$losses_element = $row->filter(".losses");
$losses = trim($losses_element->text());
$win_pct_element = $row->filter(".pct");
$win_pct = trim($win_pct_element->text());
$goals_for_element = $row->filter(".gf");
$goals_for = trim($goals_for_element->text());
$goals_against_element = $row->filter(".ga");
$goals_against = trim($goals_against_element->text());
$goal_diff_element = $row->filter(".diff");
$goal_diff = trim($goal_diff_element->text());
// create an array with the extracted team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print ("n");
});
Os métodos do DomCrawler usados são:
each(): Para iterar em uma lista de elementos selecionados.filter(): Selecionar elementos com base em seletores CSS.text(): Extrai o conteúdo de texto dos elementos selecionados.
Maravilhoso! Agora você é um mestre em análise de HTML em PHP.
Analisando HTML em PHP: Tabela de comparação
Você pode comparar as três abordagens de análise de HTML no PHP exploradas aqui na tabela de resumo abaixo:
| Documento HTML | Analisador HTML DOM simples | DomCrawler do Symfony | |
|---|---|---|---|
| Tipo | Componente PHP nativo | Biblioteca externa | Componente Symfony |
| Estrelas do GitHub | – | 880+ | 4,000+ |
| Suporte a XPath | ❌ | ✔️ | ✔️ |
| Suporte ao seletor CSS | ❌ | ✔️ | ✔️ |
| Curva de aprendizado | Baixa | Baixo a médio | Médio |
| Simplicidade de uso | Médio | Alta | Alta |
| API | Básico | Rico | Rico |
Conclusão
Neste artigo, você aprendeu sobre três abordagens para a análise de HTML no PHP, que vão desde o uso de extensões integradas do Vanilla até bibliotecas de terceiros.
Embora todas essas soluções funcionem, lembre-se de que a página da Web de destino pode usar JavaScript para renderização. Nesse caso, abordagens simples de análise de HTML, como as apresentadas acima, não funcionarão. Em vez disso, você precisa de um navegador de raspagem completo com recursos avançados de análise de HTML, como o Scraping Browser.
Deseja ignorar a análise de HTML e obter os dados imediatamente? Confira nossos conjuntos de dados prontos para uso que abrangem centenas de sites!
Crie uma conta gratuita na Bright Data hoje mesmo para testar nossos dados e soluções de raspagem com uma avaliação gratuita!




