

Existem todos os tipos de ótimasferramentas de Parsingdisponíveis. Em Python, suasopçõesparecem quase ilimitadas. No entanto, com Go, não temos muitas opções para escolher.
Go é uma linguagem excelente para desempenho e gerenciamento de memória, mas nossas bibliotecas de Parsing são bastante limitadas. Node Parser e Tokenizer são duas opções que podemos usar da biblioteca padrão do Go. Se você não está familiarizado com o funcionamento do Scraping de dados da web, dê uma olhadaneste guia. Acompanhe-nos e aprenda quando usar essas ferramentas ou quando escolher uma biblioteca de terceiros para uma solução de Scraping de dados mais completa.
Pré-requisitos
Um conhecimento básico de Go e Scraping de dados é útil aqui, mas não obrigatório. Se você está familiarizado com Go, mas gostaria de conhecer o processo de Scraping de dados, dê uma olhadaneste guia.
Para começar, você precisa ter certeza de que o Go está instalado em sua máquina. Você pode encontrar a versão mais recenteaqui. Baixe a versão mais recente para o seu sistema e vamos começar!
Crie uma nova pasta de projeto e entre nela.
mkdir goparser
cd goparser
Inicialize um novo projeto Go.
go mod init goparser
Testando sua configuração
Vá em frente e cole o seguinte código em um novo arquivo, main.go.
package main
import "fmt"
func main() {
fmt.Println("Olá, mundo!")
}
Você pode executar o arquivo com o seguinte comando.
go run main.go
Se tudo estiver funcionando, você deverá receber a seguinte saída.
Olá, mundo!
Instale nossa única dependência.
go get golang.org/x/net/html
Examinando a página
O Quotes to Scrapeé um site criado especificamente com o objetivo de extrair tutoriais. Neste tutorial, vamos extrair cada citação e seu autor da página.
Para entender melhor o objeto citação, dê uma olhada na captura de tela abaixo. Cada citação é um span e sua classe é text.
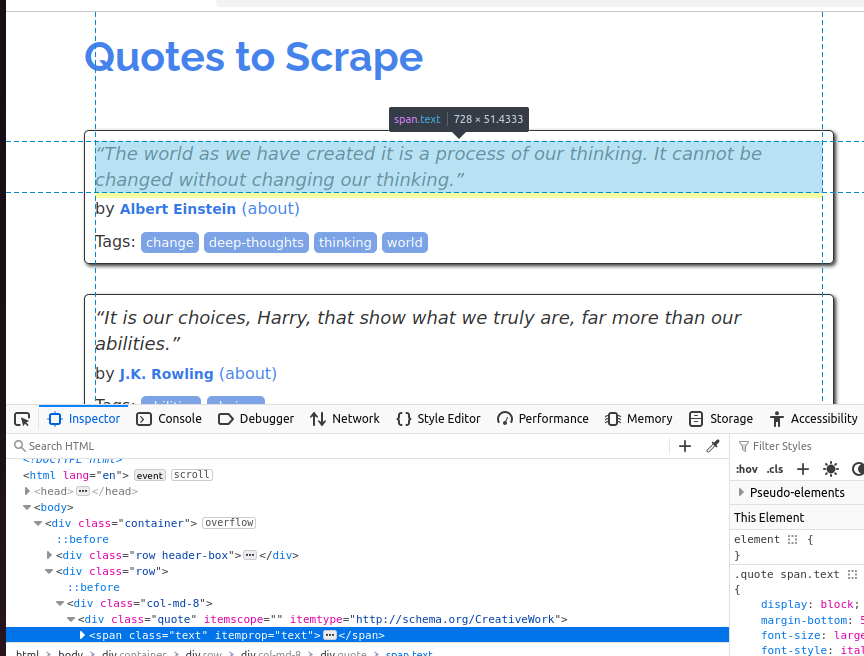
Na próxima captura de tela, inspecionamos o autor. É um elemento pequeno e sua classe é author.
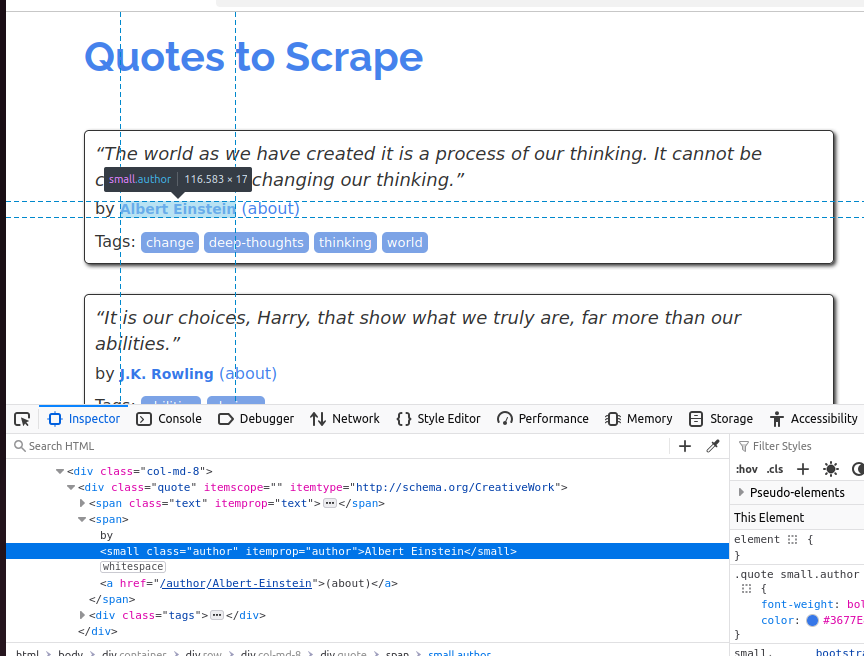
Nossos exemplos de Node Parser e Tokenizer produzirão a mesma saída que você vê abaixo.
Citação: “O mundo como o criamos é um processo do nosso pensamento. Ele não pode ser mudado sem mudar nosso pensamento.”
Autor: Albert Einstein
Citação: “São nossas escolhas, Harry, que mostram quem realmente somos, muito mais do que nossas habilidades.”
Autor: J.K. Rowling
Citação: “Existem apenas duas maneiras de viver sua vida. Uma é como se nada fosse um milagre. A outra é como se tudo fosse um milagre.”
Autor: Albert Einstein
Citação: “A pessoa, seja homem ou mulher, que não tem prazer em um bom romance, deve ser intoleravelmente estúpida.”
Autor: Jane Austen
Citação: “A imperfeição é beleza, a loucura é genialidade e é melhor ser absolutamente ridículo do que absolutamente chato.”
Autora: Marilyn Monroe
Citação: “Tente não se tornar um homem de sucesso. Em vez disso, torne-se um homem de valor.”
Autor: Albert Einstein
Citação: “É melhor ser odiado pelo que você é do que ser amado pelo que você não é.”
Autor: André Gide
Citação: “Eu não falhei. Apenas descobri 10.000 maneiras que não funcionam.”
Autor: Thomas A. Edison
Citação: “Uma mulher é como um saquinho de chá; você nunca sabe o quão forte ela é até colocá-la na água quente.”
Autor: Eleanor Roosevelt
Citação: “Um dia sem sol é como, você sabe, a noite.”
Autor: Steve Martin
Extraindo dados com o Node Parser
O Node Parser do Go nos permite percorrer o DOM (Document Object Model) e manipulá-lo recursivamente. Quando usamos o Node Parser, ele converte toda a página HTML em uma estrutura em forma de árvore de objetos Node que podemos analisar à medida que avançamos.
No código abaixo, criamos uma função recursiva: processNode(). Ela recebe um ponteiro para um nó HTML. Se o nó for um span e sua classe for text, imprimimos a citação no console. Se o nó for um pequeno elemento e sua classe for author, imprimimos o autor no console. Esses são os mesmos atributos que descobrimos anteriormente ao inspecionar a página.
package main
import (
"fmt"
"net/http"
"golang.org/x/net/html")
func main() {
resp, _ := http.Get("http://quotes.toscrape.com")
defer resp.Body.Close()
doc, _ := html.Parsing(resp.Body)
var processNode func(*html.Node)
processNode = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "span" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "text" {
fmt.Println("Quote:", n.FirstChild.Data)
}
}
}
if n.Type == html.ElementNode && n.Data == "small" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "author" {
fmt.Println("Author:", n.FirstChild.Data)
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
processNode(c)
}
}
processNode(doc)
}
A API Node Parser é ótima quando você precisa processar o documento inteiro. Para eficiência de memória, podemos usar um ponteiro para o documento real e processar nossos dados à medida que o percorremos.
Extraindo dados com o tokenizador
O tokenizador processa a página de maneira um pouco diferente. html.NewTokenizer(resp.Body) é usado para criar um objeto tokenizador a partir do corpo da nossa resposta. Em seguida, escolhemos quais tokens (tags HTML, conteúdo de texto ou atributos) gostaríamos de extrair da página.
Ao processar cada token, temos dois objetos booleanos: inQuote e inAuthor. Se o token estiver dentro de uma citação ou de um autor, nós o cortamos e imprimimos seus dados no console. Embora nossa saída desse código seja a mesma, ele na verdade funciona de maneira muito diferente. Com o Node Parser, processamos nossos dados um nó por vez à medida que percorremos a árvore. Com o tokenizer, processamos um pedaço por vez.
No código abaixo, especificamos dois tokens iniciais: span e small. Se nosso pedaço for um elemento span e sua classe for texto, nós o imprimimos no console. Se nosso pedaço for um small e sua classe for autor, também o imprimimos no console. Todos os outros tokens (tags HTML) na página são completamente ignorados.
package main
import (
"fmt"
"net/http"
"strings"
"golang.org/x/net/html"
)
func main() {
resp, _ := http.Get("http://quotes.toscrape.com")
defer resp.Body.Close()
tokenizer := html.NewTokenizer(resp.Body)
inQuote := false
inAuthor := false
for {
tt := tokenizer.Next()
switch tt {
case html.ErrorToken:
return
case html.StartTagToken:
t := tokenizer.Token()
if t.Data == "span" {
for _, a := range t.Attr {
if a.Key == "class" && a.Val == "text" {
inQuote = true
}
}
}
if t.Data == "small" {
for _, a := range t.Attr {
if a.Key == "class" && a.Val == "author" {
inAuthor = true
}
}
}
case html.TextToken:
if inQuote {
fmt.Println("Citação:", strings.TrimSpace(tokenizer.Token().Data))
inQuote = false
}
if inAuthor {
fmt.Println("Autor:", strings.TrimSpace(tokenizer.Token().Data))
inAuthor = false
}
}
}
}
O Tokenizer é um pouco mais básico do que o Node Parser, mas também é muito mais eficiente. Precisamos apenas processar os tokens relevantes (tags HTML) em vez de percorrer todo o documento. Isso é ideal para processar grandes blocos de fluxos de dados. Com o Tokenizer, você só precisa processar os dados relevantes em vez de toda a página.
Alternativas de terceiros
Tanto o Node Parser quanto o Tokenizer são de nível bastante baixo em comparação com as ferramentas que você obtém com Python e JavaScript. Aqui estão algumas ferramentas de terceiros que podem facilitar um pouco a extração de dados.
Goquery
Criado como uma alternativa Go ao Jquery,o Goqueryé uma excelente opção se você estiver procurando um analisador mais intuitivo. Com o Goquery, você obtém suporte para percorrer DOM e seletores CSS. Isso é muito mais parecido com as soluções que você pode estar acostumado em outras linguagens.
htmlquery
Semelhante ao Goquery,o htmlquerynos permite usar tanto a travessia DOM quanto os seletores. No entanto, com o htmlquery, usamos seletores XPath em vez de seletores CSS. A escolha entre Goquery e htmlquery deve realmente se basear no tipo de seletor que você prefere.
Colly
Collyé uma estrutura completa de Scraping de dados para Go. Com Colly, temos suporte para seletores CSS, concorrência e muito mais. Você pode pensar nisso como uma alternativa Go aoScrapy. Se você estiver interessado em usar Colly, temos um ótimo tutorial sobre eleaqui.
Bright Data Web Scraper
NossoScraper de dadospermite que você ignore completamente o processo de scraping. Com o Scraper de dados, fazemos o scraping da página e retornamos seus dados para você no formato JSON. Essa é uma excelente opção se você deseja apenas fazer uma solicitação de API e continuar com o seu dia, em vez de percorrer o DOM, escrever tokens ou escrever seletores. Nosso Scraper de dados não é uma biblioteca Go, é um serviço de API. Se você sabe como lidar com uma API REST, essa é uma maneira muito simples de automatizar seu processo de scraping.
Conclusão
Agora você sabe como realizar o Parsing de HTML usando Go. Para um conjunto de habilidades mais completo, dê uma olhada em nosso guia sobreintegração de Proxy em Go. Se você deseja percorrer uma página inteira, use o Node Parser. Se você deseja apenas realizar a análise de dados relevantes de uma página, experimente o Tokenizer. Se nenhuma dessas opções atender às suas necessidades, há uma variedade de ferramentas de terceiros, como os Web Scrapers da Bright Data. Inscreva-se agora e comece seu teste grátis!





