
Uma instituição financeira global precisa combinar dados de mercado em tempo real da web com análises internas confidenciais. Seus dados são divididos entre um armazém local (para dados confidenciais de clientes) e o Azure Data Lake (para análises escaláveis). Este guia ensina como conectar os dois através das APIs da Bright Data para uma integração segura e quase em tempo real.
Você aprenderá:
- Por que as organizações financeiras precisam de configurações de dados híbridas
- Como coletar dados da web em conformidade com a Bright Data
- Como configurar uma sincronização bidirecional segura entre o Azure Data Lake e um armazém local
- Como validar a sincronização de dados de ponta a ponta
- Como executar análises unificadas sem mover dados confidenciais
- Onde encontrar as configurações e scripts de amostra no GitHub
O que é integração de dados híbrida e por que o setor financeiro precisa dela
As organizações financeiras operam sob regulamentações rígidas, como GDPR, SOC 2, MiFID II e Basileia III, que controlam onde os dados podem residir. Os dados públicos da Web alimentam a inteligência de mercado em tempo real, enquanto os Conjuntos de dados internos existentes oferecem suporte à modelagem e conformidade de longo prazo. Os sistemas ETL tradicionais raramente unificam ambos com segurança.
O desafio: como combinar dados de mercado externos com análises internas sem comprometer a segurança ou a conformidade?
A solução: a Bright Data fornece dados da web estruturados e em conformidade por meio de APIs, enquanto a infraestrutura híbrida do Azure mantém os dados confidenciais no local.
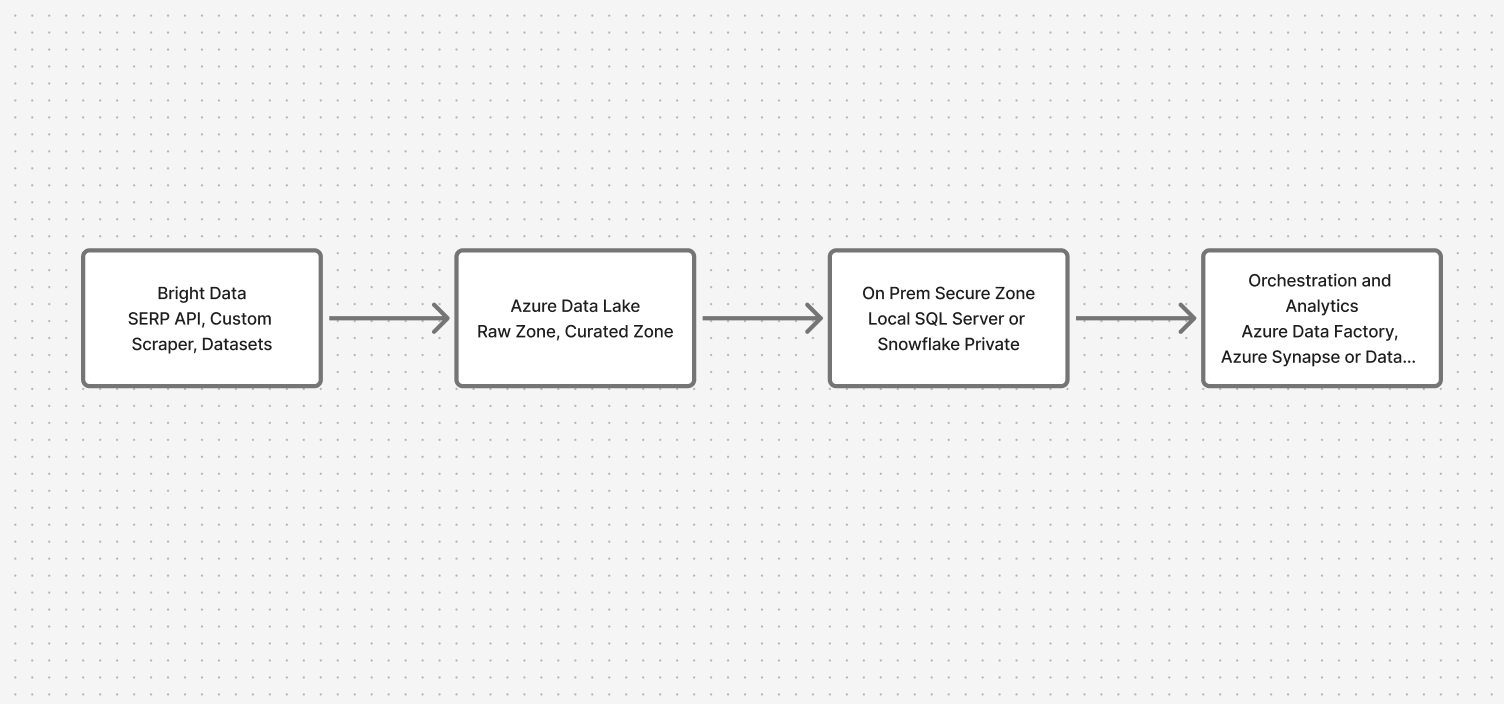
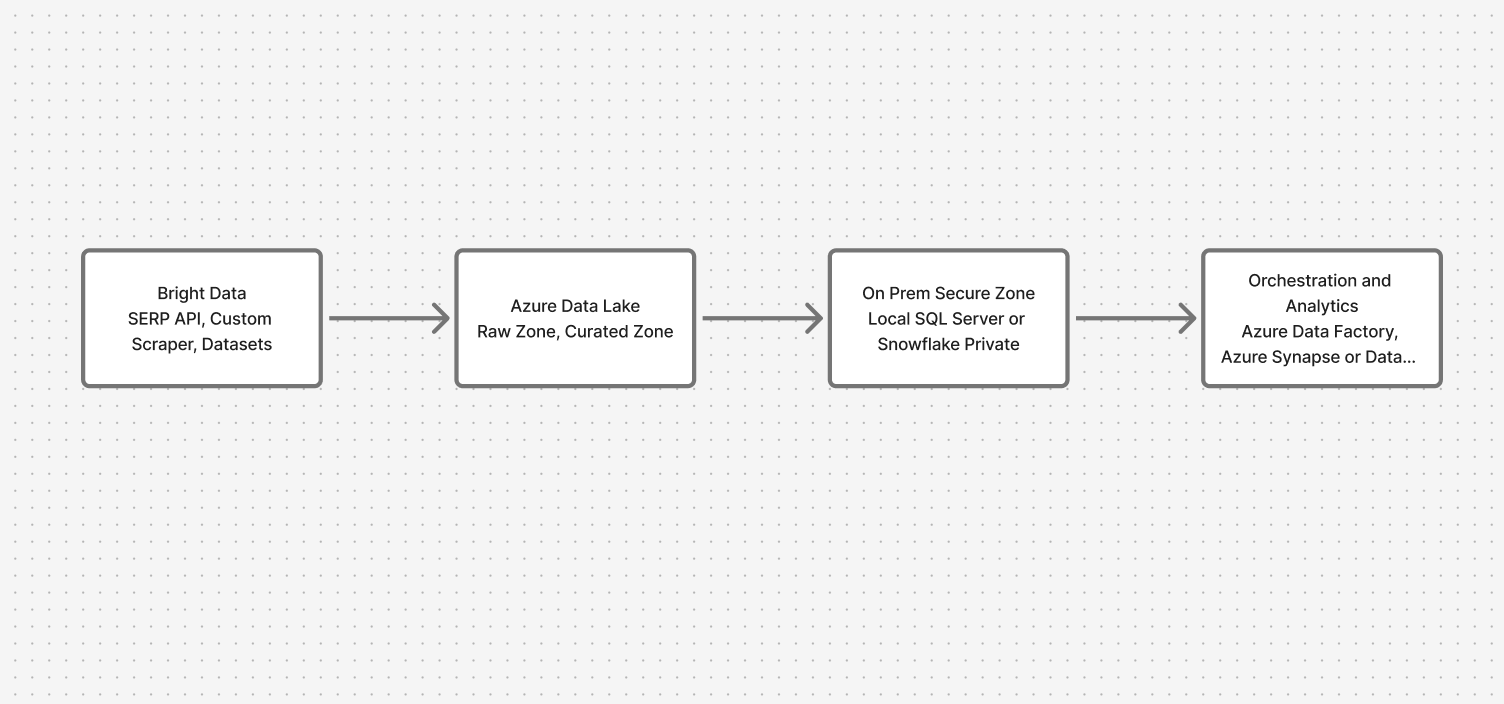
Visão geral da arquitetura: conectando a nuvem e o local com segurança
O sistema passa por quatro camadas principais:
- Coleta de dados: APIs da Bright Data (API SERP, Scraper personalizado, Conjuntos de dados)
- Zona de aterrissagem na nuvem: Azure Data Lake (zonas brutas e curadas)
- Zona segura local: SQL Server local ou Snowflake
- Orquestração e análise: Azure Data Factory com pontos de extremidade privados, Synapse/Databricks para consultas federadas
Isso garante que os dados da web fluam enquanto os dados confidenciais permanecem onde estão.
Pré-requisitos
Antes de começar:
- Conta ativa da Bright Data com acesso à API
- Assinatura do Azure com Data Lake, Data Factory e Synapse ou Databricks
- Banco de dados local acessível por meio de rede privada (ODBC ou JDBC)
- Link privado seguro (ExpressRoute, VPN site a site ou endpoint privado)
- Conta GitHub para clonar o repositório de amostra
💡 Dica: execute todas as etapas primeiro em um espaço de trabalho que não seja de produção.
Implementação passo a passo
1. Colete dados financeiros da Web com o Bright Data
Configuraremos o Custom Scraper da Bright Data para extrair preços de ações, registros regulatórios e notícias financeiras. O scraper gera um JSON estruturado pronto para análise.
Veja como os dados se apresentam:
[
{
"symbol": "AAPL",
"price": 230.66,
"currency": "USD",
"timestamp": "2026-11-10T20:15:36Z",
"source": "https://finance.yahoo.com/quote/AAPL",
"sector": "Technology",
"scraped_at": "2026-11-10T20:16:10Z"
},
{
...
}
]
Configuração simplificada: o arquivo scraper_config.yaml define o que coletar e com que frequência. Ele tem como alvo sites financeiros, extrai pontos de dados específicos e agenda a coleta de hora em hora com notificações webhook.
Essa abordagem garante que você obtenha dados limpos e estruturados sem intervenção manual.
# scraper_config.yaml
nome: financial_data_aggregator
descrição: >
Coleta preços de ações em tempo real, registros da SEC e manchetes de notícias financeiras
para integração em nuvem híbrida.
alvos:
- https://finance.yahoo.com/quote/AAPL
- https://finance.yahoo.com/quote/MSFT
- https://www.reuters.com/markets/
- https://www.sec.gov/edgar/search/
seletores:
- nome: símbolo
tipo: texto
seletor: "h1[data-testid='quote-header'] span"
- nome: preço
tipo: texto
seletor: "fin-streamer[data-field='regularMarketPrice']"
- nome: título
tipo: texto
seletor: "article h3 a"
- nome: tipo_de_arquivamento
tipo: texto
seletor: "td[class*='filetype']"
- nome: data_de_arquivamento
tipo: texto
seletor: "td[class*='filedate']"
- nome: URL do arquivamento
tipo: link
seletor: "td[class*='filedesc'] a"
paginação:
tipo: próximo-link
seletor: "a[aria-label='Próximo']"
saída:
formato: json
nome_do_arquivo: financial_data.json
agendamento:
frequência: a cada hora
fuso horário: UTC
webhook: "https://<seu-ponto-final-webhook>/brightdata/ingest"
notificações:
e-mail_em_caso_de_sucesso: [email protected]
e-mail_em_caso_de_falha: [email protected]2. Ingestão segura de dados no Azure Data Lake
Agora, encaminhamos os dados coletados para o Azure Data Lake usando uma função do Azure. Essa função atua como um gateway seguro:
- Recebe dados JSON via HTTPS POST da Bright Data
- Autentica usando identidade gerenciada (sem segredos para gerenciar)
- Organiza os arquivos por fonte e carimbo de data/hora para facilitar o rastreamento
- Adiciona tags de metadados para rastreamento de conformidade
O resultado: seus dados de mercado são armazenados em pastas particionadas, facilitando o gerenciamento e a consulta.
azure_ingest.py
# azure_function_ingest.py
import azure.functions as func
import json
import os
from datetime import datetime
from azure.identity import ManagedIdentityCredential
from azure.storage.blob import BlobServiceClient, ContentSettings
# Variáveis de ambiente
STORAGE_ACCOUNT_URL = os.getenv("STORAGE_ACCOUNT_URL") # por exemplo, "https://myaccount.blob.core.windows.net"
CONTAINER_NAME = os.getenv("CONTAINER_NAME", "brightdata-market")
# Inicializar cliente blob com identidade gerenciada
credential = ManagedIdentityCredential()
blob_service_client = BlobServiceClient(account_url=STORAGE_ACCOUNT_URL, credential=credential)
def main(req: func.HttpRequest) -> func.HttpResponse:
tente:
# Analise o JSON recebido da Bright Data
payload = req.get_json()
source = detect_source(payload)
now = datetime.utcnow()
date_str = now.strftime("%Y-%m-%d")
# Preparar caminho de destino
blob_path = f"raw/source={source}/date={date_str}/financial_data_{now.strftime('%H%M%S')}.json"
# Carregar arquivo JSON
blob_client = blob_service_client.get_blob_client(container=CONTAINER_NAME, blob=blob_path)
data_bytes = json.dumps(payload, indent=2).encode("utf-8")
blob_client.upload_blob(
data_bytes,
overwrite=True,
content_settings=ContentSettings(content_type="application/json"),
metadata={
"classification": "public",
"data_category": "market_data",
"source": source,
"ingested_at": now.isoformat(),
},
)
retornar func.HttpResponse(
f"Dados de {source} salvos em {blob_path}",
status_code=200
)
exceto Exception como ex:
retornar func.HttpResponse(str(ex), status_code=500)
def detect_source(payload: dict) -> str:
"""Auxiliar simples para identificar o nome da fonte."""
# Procure o campo 'source' no primeiro elemento da matriz
if isinstance(payload, list) and payload:
src_url = payload[0].get("source", "")
if "yahoo" in src_url:
return "finance_yahoo"
elif "reuters" in src_url:
return "reuters"
elif "sec" in src_url:
return "sec"
return "unknown"3. Sincronizar subconjuntos não confidenciais para o local
Nem todos os dados precisam ser transferidos entre ambientes. Usamos o Azure Data Factory para atuar como um filtro inteligente, selecionando cuidadosamente apenas os subconjuntos de dados que são seguros para sincronização com seu armazenamento local.
Veja como o processo funciona na prática:
O pipeline começa verificando se há novos arquivos que chegaram ao seu Data Lake. Em seguida, ele aplica uma filtragem inteligente para incluir apenas dados públicos e não confidenciais, como preços de mercado e símbolos de ações, e não informações de clientes ou análises proprietárias.
O que torna isso seguro e confiável:
Os endpoints privados criam um túnel dedicado entre o Azure e sua infraestrutura local, ignorando completamente a internet pública. Isso elimina a exposição a ameaças externas e garante um desempenho consistente.
O carregamento incremental com rastreamento de marca d’água significa que o sistema move apenas registros novos ou alterados. Combinado com a validação automática do esquema, isso evita duplicatas e mantém os dois ambientes perfeitamente alinhados.
Agora, vamos ver como isso se traduz em código de pipeline real:
{
"name": "Hybrid_Cloud_OnPrem_Sync",
"properties": {
"activities": [
{
"name": "Lookup_NewFiles",
"type": "Lookup",
"dependsOn": [],
"typeProperties": {
"source": {
"type": "JsonSource"
},
"dataset": {
"referenceName": "ADLS_NewFiles_Dataset",
"type": "DatasetReference"
},
"firstRowOnly": false
}
},
{
"name": "Get_Metadata",
"type": "GetMetadata",
"dependsOn": [
{
"activity": "Lookup_NewFiles",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"dataset": {
"referenceName": "ADLS_NewFiles_Dataset",
"type": "DatasetReference"
},
"fieldList": ["childItems", "size", "lastModified"]
}
},
{
"nome": "Filtrar_DadosPúblicos",
"tipo": "Filtro",
"dependeDe": [
{
"atividade": "Obter_Metadados",
"condiçõesDeDependência": ["Bem-sucedido"]
}
],
"typeProperties": {
"items": {
"value": "@activity('Lookup_NewFiles').output.value",
"type": "Expression"
},
"condition": "@equals(item().metadata.classification, 'public')"
}
},
{
"name": "Copy_To_OnPrem_SQL",
"type": "Copy",
"dependsOn": [
{
"activity": "Filter_PublicData",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"source": {
"type": "JsonSource",
"treatEmptyAsNull": true
},
"sink": {
"type": "SqlSink",
“preCopyScript”: “IF OBJECT_ID('stg_market_data') IS NULL CREATE TABLE stg_market_data (symbol NVARCHAR(50), price FLOAT, currency NVARCHAR(10), timestamp DATETIME2, source NVARCHAR(500));”
}
},
"inputs": [
{
"referenceName": "ADLS_PublicData_Dataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "OnPrem_SQL_Dataset",
"type": "DatasetReference"
}
]
},
{
"nome": "Log_Load_Status",
"tipo": "StoredProcedure",
"dependeDe": [
{
"atividade": "Copy_To_OnPrem_SQL",
"condiçõesDeDependência": ["Bem-sucedido", "Falha"]
}
],
"typeProperties": {
"storedProcedureName": "usp_Log_HybridLoad",
"storedProcedureParameters": {
"load_source": {
"value": "BrightData",
"type": "String"
},
"status_msg": {
"value": "@activity('Copy_To_OnPrem_SQL').output",
"type": "Expression"
}
}
},
"linkedServiceName": {
"referenceName": "OnPrem_SQL_LinkedService",
"type": "LinkedServiceReference"
}
}
],
"annotations": ["HybridIntegrationDemo"]
}
}Analisando os principais componentes:
- Lookup_NewFiles atua como a verificação do seu pipeline, identificando primeiro quais novos dados chegaram ao Data Lake e precisam ser processados. Isso evita que o sistema reprocesse arquivos antigos desnecessariamente.
- Get_Metadata examina esses arquivos detalhadamente, verificando seu tamanho, datas de modificação e estrutura. Essa etapa garante que estamos trabalhando com arquivos completos e válidos antes de prosseguir.
- Filter_PublicData é onde a mágica da segurança acontece. Usando os metadados de classificação que incorporamos anteriormente, ele filtra automaticamente quaisquer dados confidenciais, garantindo que apenas informações públicas do mercado continuem no pipeline.
- O Copy_To_OnPrem_SQL lida com a transferência real, mas com proteções inteligentes. O preCopyScript garante que a tabela de destino exista com o esquema correto, enquanto a conexão de endpoint privado mantém tudo dentro da sua rede segura.
- O Log_Load_Status fornece visibilidade crucial, pois todas as operações de sincronização são registradas em seu banco de dados local. Isso cria a trilha de auditoria exigida pelas equipes de conformidade, ao mesmo tempo em que oferece à equipe de operações visibilidade imediata da integridade do pipeline.
O benefício real: sua equipe local obtém o contexto de mercado e as informações em tempo real de que precisa, enquanto os dados confidenciais dos clientes e os modelos proprietários permanecem seguros onde devem estar. É o melhor dos dois mundos: agilidade e segurança.
4. Habilite a validação de sincronização bidirecional
A consistência dos dados é essencial para tomar decisões comerciais confiáveis. Você precisa ter certeza de que suas análises na nuvem e seus relatórios locais mostram os mesmos números. Criamos verificações automatizadas de validação de dados que são executadas continuamente para fornecer essa garantia.
Veja como funciona o processo de validação:
- As comparações de contagem de linhas servem como seu primeiro sistema de alerta. Essa verificação inicial identifica rapidamente problemas importantes, como transferências com falha ou carregamentos de dados incompletos. Se as contagens não corresponderem entre a nuvem e o local, você saberá imediatamente que algo precisa ser investigado.
- As somas de verificação hash criam impressões digitais dos seus dados. Em vez de comparar manualmente milhares de registros, geramos hashes criptográficos exclusivos para cada Conjunto de dados. Mesmo uma única alteração de caractere produz um hash completamente diferente. Esse método torna a corrupção de dados ou transferências parciais instantaneamente detectáveis.
- A sincronização quase em tempo real significa que as validações são executadas a cada poucos minutos. Você não precisa esperar por trabalhos em lote durante a noite para descobrir problemas. O sistema detecta problemas em minutos, não em dias, mantendo seus dados atualizados e confiáveis.
- Os alertas automatizados transformam problemas de dados em ações imediatas. Quando o sistema detecta discrepâncias, ele envia notificações por meio do Slack, e-mail ou suas ferramentas de monitoramento existentes. Sua equipe pode resolver os problemas antes que eles afetem as decisões de negócios.
Veja como isso funciona na prática:
def validate_sync():
# Compare o número de registros entre os sistemas
cloud_count = get_cloud_record_count()
onprem_count = get_onprem_record_count()
if cloud_count != onprem_count:
alert_team(f"Discrepância no número de registros: Nuvem {cloud_count} vs Local {onprem_count}")
return False
# Gerar somas de verificação para validação da integridade dos dados
cloud_checksum = generate_data_checksum('cloud')
onprem_checksum = generate_data_checksum('onprem')
if cloud_checksum != onprem_checksum:
alert_team(f"Falha na integridade dos dados: somas de verificação não correspondem")
retornar False
# Verificar a pontualidade da sincronização
última_hora_sincronização = obter_última_hora_sincronização()
se is_sync_delayed(última_hora_sincronização):
alert_team(f"Atraso na sincronização detectado: Última sincronização {última_hora_sincronização}")
retornar False
retornar True5. Crie análises unificadas sem mover dados confidenciais
Aqui está a parte mais interessante: você pode unir dados na nuvem e locais virtualmente sem mover informações confidenciais.
Exemplo de consulta:
SELECT c.symbol,
c.stock_price,
o.risk_score
FROM adls.market_data c
JOIN external.onprem_portfolio o
ON c.symbol = o.ticker
WHERE o.client_tier = 'premium';O Azure Synapse cria tabelas externas que apontam para o seu armazém local, enquanto o Databricks usa conexões JDBC com controles de acesso baseados em funções.
Práticas recomendadas de conformidade e trilha de auditoria
Atender aos requisitos legais e de auditoria requer uma abordagem sistemática para rastreamento e segurança de dados. Veja como criamos uma estrutura em conformidade:
- O registro completo da movimentação de dados garante que todas as transferências sejam registradas no Azure Monitor e no SIEM local. Isso cria um registro imutável de quais dados foram movidos, para onde e quando, proporcionando aos auditores total rastreabilidade.
- A proveniência clara dos dados usa IDs de fonte de dados brutos como impressões digitais. Essas tags permanecem com seus dados durante todo o seu ciclo de vida, permitindo que você rastreie qualquer análise até sua coleção de origem original.
- O rastreamento automatizado da linhagem com o Azure Purview mapeia como os dados se transformam em seus pipelines. Ele documenta automaticamente quais feeds brutos contribuem para relatórios específicos e quais transformações foram aplicadas.
- O controle de acesso centralizado sincroniza o Azure AD com o LDAP local. Isso aplica suas políticas de segurança existentes a ambos os ambientes, garantindo um gerenciamento de permissões consistente entre os sistemas em nuvem e locais.
O resultado é um relatório de conformidade automatizado, gerenciamento de segurança centralizado e uma estrutura que protege os dados sem atrasar sua equipe.
Desafios comuns e como a Bright Data ajuda
| Desafio | Recurso da Bright Data |
|---|---|
| Bloqueios de IP ou limites de taxa | Proxiesresidenciais e de ISP (mais de 150 milhões de IPs) |
| CAPTCHAs ou barreiras de login | Web Unlocker para resolução automatizada |
| Sites com JavaScript pesado | Navegador de scraping (renderização baseada em Playwright) |
| Alterações frequentes no site | Serviços de dados gerenciados com correção automática por IA |
Conclusão e próximos passos
As organizações financeiras podem mesclar dados públicos e privados com segurança usando as APIs da Bright Data em conjunto com a infraestrutura híbrida do Azure.
O resultado é um sistema compatível que oferece agilidade e controle.
💡 Se você preferir acesso a dados totalmente gerenciado, use os Serviços de Dados Gerenciados da Bright Data para lidar com a extração e entrega de ponta a ponta.






