

O scraping do Zillow, um site de transações imobiliárias online, oferece informações valiosas sobre o mercado imobiliário, abrangendo análises de mercado, tendências do setor imobiliário e visões gerais da concorrência. Ao fazer o scraping do Zillow, você pode reunir informações abrangentes sobre preços, localizações, características e tendências históricas de imóveis, capacitando-o a realizar análises de mercado, manter-se atualizado com as tendências do setor imobiliário, avaliar as estratégias dos concorrentes e tomar decisões baseadas em dados que se alinhem com seus objetivos de investimento.
Neste tutorial, você aprenderá como fazer scraping do Zillow usando o Beautiful Soup. Além de aprender como coletar dados úteis, você também aprenderá sobre as técnicas anti-scraping empregadas pelo Zillow e como a Bright Data pode ajudar.
Quer pular a coleta e apenas obter os dados? Confira nossos Conjuntos de dados do Zillow.
Extraindo dados do Zillow
Seja você novo no Python ou já experiente nele, este tutorial está aqui para ajudá-lo a criar um Scraper da web usando bibliotecas gratuitas, como Beautiful Soup ou Requests. Então, comece agora!
Pré-requisitos
Antes de começar, é recomendável que você tenha um conhecimento básico sobre Scraping de dados e HTML. Você também precisa fazer o seguinte:
- documentação oficial
- Playwright
pip3 install beautifulsoup4
pip3 install requests
pip3 install pandas
pip3 install playwright
Entenda a estrutura do site Zillow
Antes de começar a fazer scraping no Zillow, é importante entender sua estrutura. Observe que a página inicial do Zillow possui uma barra de pesquisa conveniente, que permite pesquisar casas, apartamentos e vários imóveis. Depois de iniciar uma pesquisa, os resultados são exibidos em uma página que apresenta uma lista de imóveis, incluindo seus preços, endereços e outros detalhes relevantes. Vale mencionar que esses resultados de pesquisa podem ser classificados com base em parâmetros como preço, número de quartos e número de banheiros.
Se você quiser mais resultados de pesquisa além dos exibidos inicialmente, pode utilizar os botões de paginação localizados na parte inferior da página. Cada página normalmente inclui quarenta listagens, permitindo que você acesse propriedades adicionais. Ao utilizar os filtros localizados no lado esquerdo da página, você pode refinar sua pesquisa com base em suas preferências e requisitos.
Para entender a estrutura HTML do site, siga estas etapas:
- Visite o site da Zillow: www.zillow.com.
- Digite uma cidade ou CEP na barra de pesquisa e pressione Enter.
- Clique com o botão direito do mouse em um cartão de imóvel e clique em Inspecionar para abrir as ferramentas de desenvolvedor do navegador.
- Analise a estrutura HTML para identificar as tags e atributos que contêm os dados que você deseja extrair.
Identifique os principais pontos de dados
Para coletar informações do Zillow de maneira eficaz, você precisa identificar o conteúdo exato que deseja extrair. Este guia mostrará como extrair informações sobre um imóvel, incluindo os seguintes Pontos de dados importantes:
- Endereço: a localização do imóvel, incluindo o endereço, a cidade e o estado.
- Preço: o preço listado do imóvel, que fornece informações sobre seu valor de mercado atual.
- Zestimate: valor de mercado estimado do imóvel pelo Zillow. O Zestimate leva em consideração vários fatores e fornece uma avaliação aproximada com base nas tendências do mercado e em dados de imóveis comparáveis.
- Quartos: o número de quartos no imóvel.
- Banheiros: o número de banheiros no imóvel.
- Área útil: A área total do imóvel em metros quadrados.
- Ano de construção: O ano em que o imóvel foi construído.
- Tipo: O tipo de imóvel, que pode incluir opções como casa, apartamento, condomínio ou outras classificações relevantes.
A Zillow fornece uma ampla gama de informações que permitem avaliar e comparar facilmente diferentes anúncios, considerar as tendências de preços em bairros específicos, avaliar as condições do imóvel e identificar quaisquer comodidades adicionais. Além disso, ao analisar dados históricos e atuais do mercado, você pode se manter atualizado sobre as tendências e tomar decisões estratégicas sobre compra, venda ou investimento em imóveis.
Crie o Scraper
Agora que você identificou o que deseja extrair, é hora de criar o Scraper. Aqui, você usa a biblioteca Requests para fazer solicitações HTTP ao Zillow, o Beautiful Soup para realizar o Parsing do HTML e o Python para extrair os dados.
Extraia os dados
A primeira etapa é extrair os dados que você está procurando. Crie um novo arquivo chamado scraper.py e adicione o seguinte código:
import requests
from bs4 import BeautifulSoup
url = 'https://www.zillow.com/homes/for_sale/San-Francisco_rb/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
listings = []
para listagem em soup.find_all('div', {'class': 'property-card-data'}):
resultado = {}
resultado['endereço'] = listagem.find('endereço', {'data-test': 'property-card-addr'}).get_text().strip()
resultado['preço'] = listagem.find('span', {'data-test': 'property-card-price'}).get_text().strip()
lista_detalhes = listagem.find('ul', {'class': 'dmDolk'})
detalhes = lista_detalhes.find_all('li') se lista_detalhes else []
result['bedrooms'] = details[0].get_text().strip() se len(details) > 0 senão ''
result['bathrooms'] = details[1].get_text().strip() se len(details) > 1 senão ''
result['sqft'] = details[2].get_text().strip() se len(details) > 2 senão ''
type_div = listagem.find('div', {'class': 'gxlfal'})
resultado['tipo'] = type_div.get_text().split("-")[1].strip() se type_div else ''
listagens.append(resultado)
imprimir(listagens)
Este código faz uma solicitação HTTP GET à página de resultados de pesquisa do Zillow e, em seguida, usa o Beautiful Soup para realizar o Parsing do HTML. Ele extrai os Pontos de dados para cada propriedade e, em seguida, imprime todas as propriedades.
Executar o Scraper
Para executar o Scraper, você precisa fornecer uma URL para uma página de resultados de pesquisa do Zillow. A URL deve ser semelhante a esta: https://www.zillow.com/homes/for_sale/{city-or-zip}_rb/, onde {city-or-zip} é substituído pelo nome da cidade ou pelo código postal que você deseja extrair.
Por exemplo, se você deseja coletar informações sobre casas à venda em São Francisco, o endereço da web que você usaria seria https://www.zillow.com/homes/for_sale/San-Francisco_rb/.
Depois de inserir a URL do site, é hora de executar seu programa e começar a coletar dados. Certifique-se de salvar as alterações em scraper.py e execute o seguinte comando em seu shell ou terminal:
python3 Scraper.py
...saída...
[{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}, {'endereço': '267A Chattanooga St, São Francisco, CA 94114', 'preço': '$1.740.000', 'quartos': '2 quartos', 'banheiros': '3 banheiros', 'm²': '2.114 m²', 'tipo': 'Condomínio à venda'}, {'endereço': '998 Union St, São Francisco, CA 94133', 'preço': '$1.650.000', 'quartos': '2 quartos', 'banheiros': '1 banheiro', 'área útil': '1.181 pés quadrados', 'tipo': 'Condomínio à venda'}, {'endereço': '37-39 Mirabel Ave, São Francisco, CA 94110', 'preço': '$2.395.000', 'quartos': '7 quartos', 'banheiros': '6 banheiros', 'm²': '2.300 m²', 'tipo': 'Multi'}, {'endereço': '304 Yale St, São Francisco, CA 94134', 'preço': '$1.399.900', 'quartos': '3 quartos', 'banheiros': '4 banheiros', 'm²': '1.764 m²', 'tipo': 'Nova construção'}, {'endereço': '173 Coleridge St, São Francisco, CA 94110', 'price': '$745.000', 'bedrooms': '2 quartos', 'bathrooms': '2 banheiros', 'sqft': '905 pés quadrados', 'type': 'Condomínio à venda'}, {'address': '289 Sadowa St, São Francisco, CA 94112', 'price': '$698.000', 'bedrooms': '4 quartos', 'bathrooms': '2 banheiros', 'sqft': '1.535 pés quadrados', 'type': 'Casa à venda'}, {'address': '1739 19th Ave, São Francisco, CA 94122', 'preço': '$475.791', 'quartos': '2 quartos', 'banheiros': '2 banheiros', 'm²': '1.780 m²', 'tipo': 'Casa geminada à venda'}, {'endereço': '1725 Quesada Ave, São Francisco, CA 94124', 'preço': '$600.000', 'quartos': '3 quartos', 'banheiros': '2 banheiros', 'm²': '1.011 m²', 'tipo': 'Condomínio à venda'}]
Lembre-se de que o Scraping de dados da web deve respeitar o arquivo
robots.txte os termos de serviço do site, e o Scraping excessivo pode levar ao bloqueio do seu IP.
Salve seus dados
Agora que você extraiu seus dados, precisa salvá-los em um arquivo JSON ou CSV. Salvar os dados em um arquivo permite que você os processe e crie análises com base no que coletou.
Para salvar os dados, comece importando as bibliotecas pandas e json no topo do seu arquivo scraper.py:
import pandas as pd
import json
Em seguida, adicione o seguinte código no final do seu arquivo:
#Gravar dados no arquivo Json
with open('listings.json', 'w') as f:
json.dump(listings, f)
print('Dados gravados no arquivo Json')
#Gravar dados no csv
df = pd.DataFrame(listings)
df.to_csv('listings.csv', index=False)
print('Dados gravados no arquivo CSV')
Este código grava os dados das listagens, uma lista de dicionários, em um arquivo JSON chamado listings.json, usando json.dump(). Em seguida, ele cria um DataFrame pandas a partir dos dados das listagens e os grava em um arquivo CSV chamado listings.csv usando o método to_csv(). O código imprime mensagens indicando que os dados foram gravados com sucesso nos arquivos JSON e CSV.
Em seguida, execute o código a partir do seu shell ou terminal:
python3 Scraper.py
…saída…
[{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1.025.000', 'bedrooms': '1 quarto', 'bathrooms': '1 banheiro', 'sqft': '956 pés quadrados', 'type': 'Condomínio à venda'}, {'endereço': '267A Chattanooga St, São Francisco, CA 94114', 'preço': '$1.740.000', 'quartos': '2 quartos', 'banheiros': '3 banheiros', 'm²': '2.114 m²', 'tipo': 'Condomínio à venda'}, {'endereço': '998 Union St, São Francisco, CA 94133', 'preço': '$1.650.000', 'quartos': '2 quartos', 'banheiros': '1 banheiro', 'área útil': '1.181 pés quadrados', 'tipo': 'Condomínio à venda'}, {'endereço': '37-39 Mirabel Ave, São Francisco, CA 94110', 'preço': '$2.395.000', 'quartos': '7 quartos', 'banheiros': '6 banheiros', 'm²': '2.300 m²', 'tipo': 'Multi'}, {'endereço': '304 Yale St, São Francisco, CA 94134', 'preço': '$1.399.900', 'quartos': '3 quartos', 'banheiros': '4 banheiros', 'm²': '1.764 m²', 'tipo': 'Nova construção'}, {'endereço': '173 Coleridge St, São Francisco, CA 94110', 'price': '$745.000', 'bedrooms': '2 quartos', 'bathrooms': '2 banheiros', 'sqft': '905 pés quadrados', 'type': 'Condomínio à venda'}, {'address': '289 Sadowa St, São Francisco, CA 94112', 'price': '$698.000', 'bedrooms': '4 quartos', 'bathrooms': '2 banheiros', 'sqft': '1.535 pés quadrados', 'type': 'Casa à venda'}, {'address': '1739 19th Ave, São Francisco, CA 94122', 'preço': '$475.791', 'quartos': '2 quartos', 'banheiros': '2 banheiros', 'm²': '1.780 m²', 'tipo': 'Casa geminada à venda'}, {'endereço': '1725 Quesada Ave, São Francisco, CA 94124', 'price': '$600.000', 'bedrooms': '3 quartos', 'bathrooms': '2 banheiros', 'sqft': '1.011 pés quadrados', 'type': 'Condomínio à venda'}]
Dados gravados no arquivo Json
Dados gravados no arquivo CSV
Se funcionar, você deverá encontrar dois novos arquivos criados no diretório do seu projeto: um arquivo listings.csv e um arquivo listings.json. Esses dois arquivos devem ter conteúdo semelhante aos arquivos do repositório GitHub, respectivamente: listings.csv e listings.json.
Se você tentar executar o código várias vezes, notará uma alta taxa de falha (cerca de 50%). Isso ocorre porque o Zillow às vezes retorna uma página CAPTCHA em vez do conteúdo real quando detecta scraping automatizado. Para obter uma melhor taxa de sucesso ao fazer scraping em um site como o Zillow, você precisa usar ferramentas que possam ajudá-lo a alternar entre diferentes IPs e contornar o CAPTCHA.
Técnicas anti-scraping empregadas pelo Zillow
Para impedir que as pessoas obtenham dados sem permissão, o Zillow usa vários métodos diferentes para impedir a cópia automática de dados (também conhecida como scraping) de seu site. Esses métodos incluem o uso de CAPTCHAs, o bloqueio de endereços IP e a configuração de armadilhas honeypot.
Um CAPTCHA é um teste para determinar se um usuário é um ser humano ou um programa de computador. Normalmente, é fácil para os seres humanos resolverem, mas difícil para os programas, e pode retardar ou até mesmo impedir a extração de dados.
Outra maneira pela qual a Zillow impede o scraping é bloqueando endereços IP. Endereços IP são como endereços residenciais, mas para computadores. Se um computador estiver fazendo muitas solicitações, o que geralmente acontece com o scraping de dados, a Zillow pode bloquear esse endereço IP para impedir mais solicitações. Esses bloqueios podem ser de curto ou longo prazo, dependendo da gravidade da situação.
O Zillow também usa armadilhas honeypot. Essas armadilhas são pedaços de dados ou links que só podem ser vistos por programas, não por humanos. Se um programa interage com uma armadilha honeypot, o Zillow sabe que se trata de um bot e pode bloqueá-lo.
Todos esses métodos dificultam a extração de dados do Zillow. Isso pode ser demorado, difícil e, às vezes, impossível. Qualquer pessoa que queira extrair dados do Zillow não só precisa conhecer esses métodos, mas também entender as questões legais e morais relacionadas à extração de dados. Lembre-se de que o Zillow pode mudar a forma como usa esses métodos e pode não informar o público.
Uma alternativa melhor: use a Bright Data para extrair dados do Zillow
A Bright Data oferece uma alternativa melhor para extrair dados do Zillow, contornando as técnicas anti-extração empregadas pelo site como Navegador de scraping da Bright Data. O Navegador de scraping permite que você execute scripts Puppeteer na rede da Bright Data, que fornece acesso a milhões de endereços IP e impede a detecção pelas técnicas anti-extração do Zillow.
Extraia dados do Zillow usando o Navegador de scraping da Bright Data
Para fazer scraping do Zillow usando o Navegador de scraping da Bright Data, siga estas etapas:
1. Crie uma conta Bright Data
Se você ainda não tem uma conta na Bright Data, acesse o site da Bright Data, clique em Teste grátis e siga as instruções.
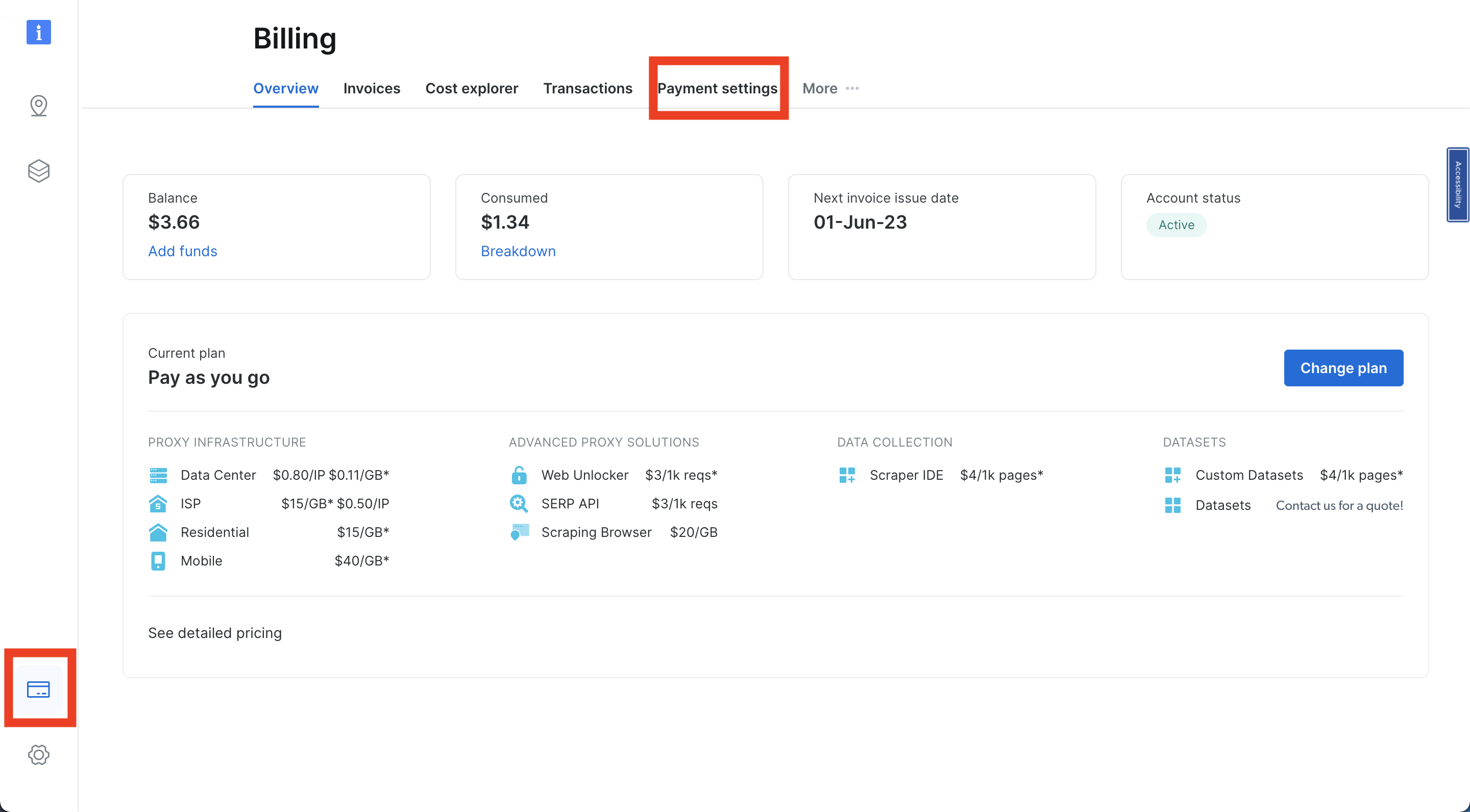
Depois de fazer login na sua conta da Bright Data, navegue até “Faturamento” clicando no ícone do cartão de crédito na parte inferior esquerda da barra de navegação. Adicione um método de pagamento com base na sua opção preferida; caso contrário, você não poderá ativar sua conta:
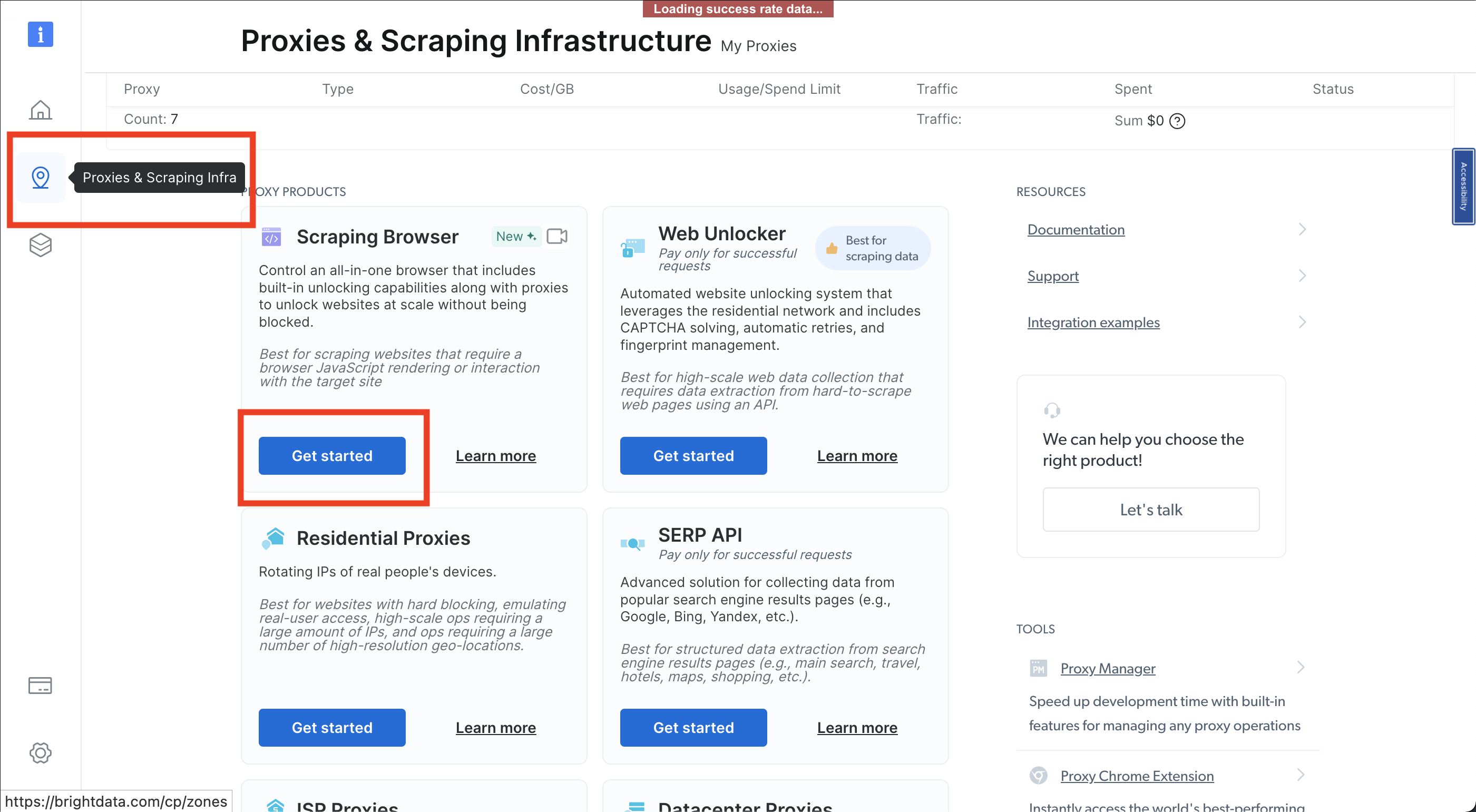
Em seguida, clique no ícone de alfinete, que abre a página Proxies e Infraestrutura de scraping; depois, selecione Navegador de scraping > Começar:
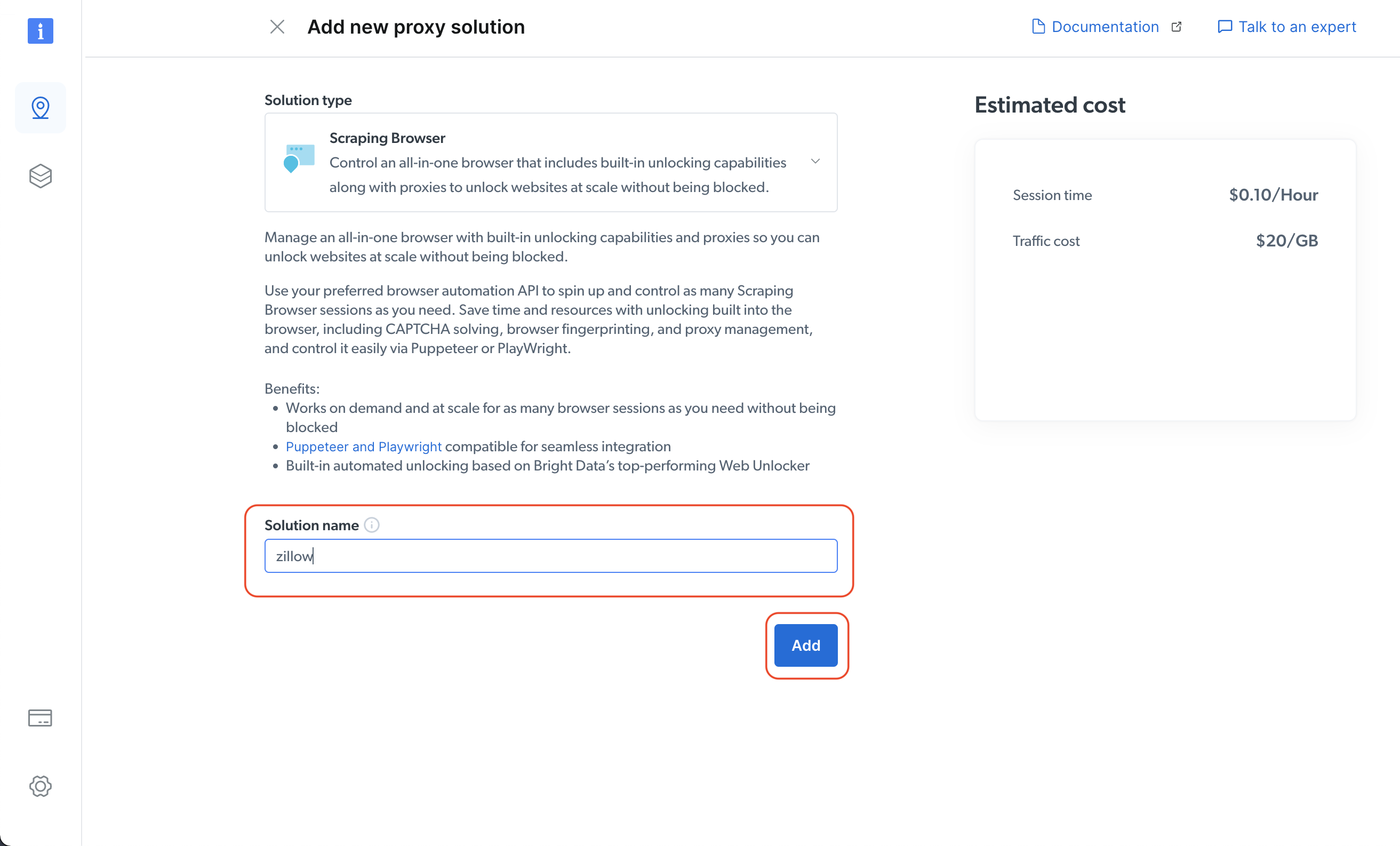
Em seguida, especifique o nome da sua solução e clique no botão Adicionar:
Em seguida, clique em Parâmetros de acesso e anote seu nome de usuário, host e senha, pois eles serão necessários mais tarde no tutorial:
Depois de concluir as etapas anteriores, você estará pronto para continuar.
2. Escreva o Scraper
Crie um novo arquivo chamado scraper-brightdata.py e adicione o seguinte código:
import asyncio
from playwright.async_api import async_playwright
import json
import pandas as pd
username='SEU_NOME_DE_USUÁRIO_BRIGHTDATA'
password='SUA_SENHA_BRIGHTDATA'
auth=f'{username}:{password}'
host = 'SEU_HOST_BRIGHTDATA'
browser_url = f'wss://{auth}@{host}'
async def main():
async with async_playwright() as pw:
print('Conectando a um navegador remoto...')
browser = await pw.chromium.connect_over_cdp(browser_url)
imprimir('Conectado. Abrindo nova página...')
página = aguardar browser.new_page()
imprimir('Navegando para o Zillow...')
aguardar página.goto('https://www.zillow.com/homes/for_sale/San-Francisco_rb/', tempo limite=3600000)
imprimir('Raspando dados...')
listagens = []
propriedades = aguardar página.query_selector_all('div.property-card-data')
para propriedade em propriedades:
resultado = {}
endereço = aguardar propriedade.query_selector('endereço[data-test="property-card-addr"]')
result['address'] = aguardar endereço.inner_text() se endereço, caso contrário ''
preço = aguardar propriedade.query_selector('span[data-test="property-card-price"]')
result['price'] = aguardar preço.inner_text() se preço, caso contrário ''
detalhes = aguardar propriedade.query_selector_all('ul.dmDolk > li')
result['bedrooms'] = aguardar detalhes[0].inner_text() se len(detalhes) >= 1 senão ''
result['bathrooms'] = aguardar detalhes[1].inner_text() se len(detalhes) >= 2 senão ''
result['sqft'] = aguardar detalhes[2].inner_text() se len(detalhes) >= 3 senão ''
type_div = aguardar property.query_selector('div.gxlfal')
result['type'] = (aguardar type_div.inner_text()).split("-")[1].strip() se type_div senão ''
listings.append(result)
aguardar browser.close()
retornar listings
# Executar a função assíncrona
listings = asyncio.run(main())
# Imprimir as listagens
para listagem em listagens:
imprimir(listagem)
# Gravar dados no arquivo Json
com open('listings-brightdata.json', 'w') como f:
json.dump(listings, f)
imprimir('Dados gravados no arquivo Json')
# Gravar dados em csv
df = pd.DataFrame(listings)
df.to_csv('listings-brightdata.csv', index=False)
print('Dados gravados no arquivo CSV')
Certifique-se de substituir YOUR_BRIGHTDATA_USERNAME, YOUR_BRIGHTDATA_PASSWORD e YOUR_BRIGHTDATA_HOST pelas credenciais reais da sua conta Bright Data.
3. Execute o Scraper
Salve as alterações em scraper-brightdata.py e execute o código a partir do seu shell ou terminal:
python3 scraper-brightdata.py
…saída…
Conectando a um navegador remoto...
Conectado. Abrindo nova página...
Navegando para o Zillow...
Raspando dados...
{'address': '1438 Green St UNIT 2B, San Francisco, CA 94109', 'price': '$995,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '974 sqft', 'type': 'Condo for sale'}
{'endereço': '815 Tennessee St UNIT 504, São Francisco, CA 94107', 'preço': '$1.195.000', 'quartos': '2 quartos', 'banheiros': '2 banheiros', 'm²': '-- m²', 'tipo': ''}
{'endereço': '455 27th Ave, São Francisco, CA 94121', 'preço': '$1.375.000', 'quartos': '2 quartos', 'banheiros': '1 banheiro', 'm²': '1.040 m²', 'tipo': 'Casa à venda'}
{'endereço': '19 Tehama St SUITE 3, São Francisco, CA 94105', 'preço': '$1.025.000', 'quartos': '1 quarto', 'banheiros': '1 banheiro', 'm²': '956 m²', 'tipo': 'Condomínio à venda'}
{'endereço': '267A Chattanooga St, São Francisco, CA 94114', 'preço': '$1.740.000', 'quartos': '2 quartos', 'banheiros': '3 banheiros', 'm²': '2.114 m²', 'tipo': 'Condomínio à venda'}
{'endereço': '998 Union St, São Francisco, CA 94133', 'preço': '$1.650.000', 'quartos': '2 quartos', 'banheiros': '1 banheiro', 'm²': '1.181 m²', 'tipo': 'Condomínio à venda'}
{'endereço': '37-39 Mirabel Ave, São Francisco, CA 94110', 'preço': '$2.395.000', 'quartos': '7 quartos', 'banheiros': '6 banheiros', 'm²': '2.300 m²', 'tipo': 'Multi'}
{'endereço': '304 Yale St, São Francisco, CA 94134', 'preço': '$1.399.900', 'quartos': '3 quartos', 'banheiros': '4 banheiros', 'm²': '1.764 m²', 'tipo': 'Nova construção'}
{'endereço': '173 Coleridge St, São Francisco, CA 94110', 'preço': '$745.000', 'quartos': '2 quartos', 'banheiros': '2 banheiros', 'm²': '905 m²', 'tipo': 'Condomínio à venda'}
Dados gravados no arquivo Json
Dados gravados no arquivo CSV
Este código se conecta ao Navegador de scraping do Bright Data, navega até a página de resultados de pesquisa do Zillow e extrai os dados. Em seguida, o código imprime os resultados e os grava nos dados de listagens, uma lista de dicionários, em um arquivo JSON chamado listings-brightdata.json, usando json.dump(). Em seguida, ele cria um DataFrame pandas a partir dos dados de listagens e os grava em um arquivo CSV chamado listings-brightdata.csv usando o método to_csv(). O código imprime mensagens indicando que os dados foram gravados com sucesso nos arquivos JSON e CSV.
Se funcionar, você deverá encontrar dois arquivos: um arquivo listings-brightdata.csv e um arquivo listings-brightdata.json. Esses arquivos devem ser semelhantes a listings-brightdata.json e listings-brightdata.csv.
Se você tentar executar este código várias vezes e perceber que não há dados salvos em seus arquivos, isso significa que seu IP foi bloqueado pelo Zillow ou que o navegador foi fechado antes de terminar. Se o navegador fechou antes que a extração fosse concluída, você precisa alterar o tempo limite para um valor maior, que, no código anterior, está relacionado ao await page.goto('https://www.zillow.com/homes/for_sale/San-Francisco_rb/', timeout=3600000).
Se o seu IP foi bloqueado pelo Zillow, você precisa alterar sua zona e, felizmente, a Bright Data oferece acesso a várias zonas.
Para alternar entre diferentes zonas, acesse Proxies & Infraestrutura de scraping clicando no ícone de alfinete, selecione Navegador de scraping e clique em Access parameters. Em seguida, clique em </> Confira exemplos de código e integração:
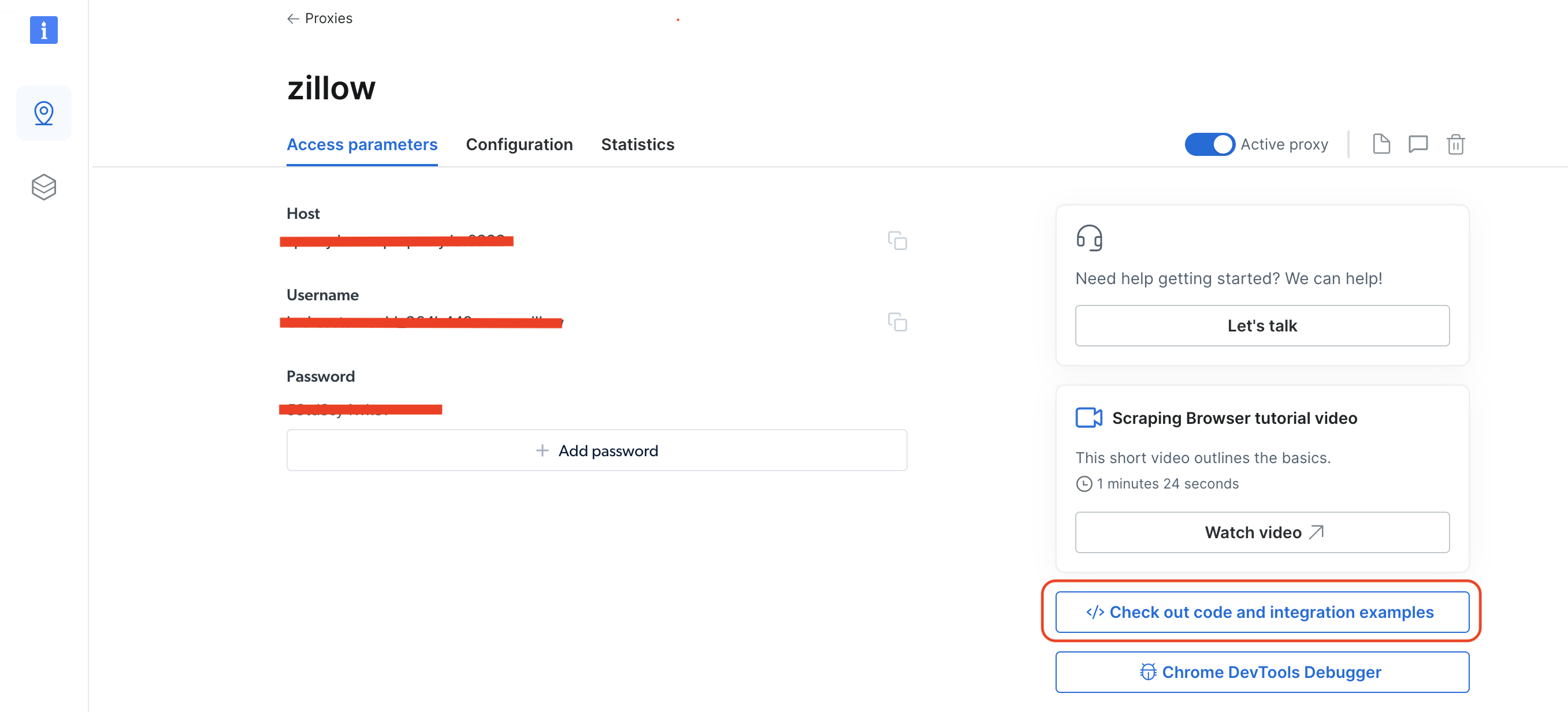
Selecione Python como idioma e, na navegação à direita, há uma lista suspensa País. Selecione o país desejado e sua zona será atualizada simultaneamente. Você verá que a variável auth muda no código de amostra Python. Você precisa obter o usuário relacionado a essa zona da variável auth. Basicamente, é o valor que está antes do :, já que a variável auth contém o nome de usuário e a senha com a seguinte sintaxe username:password:
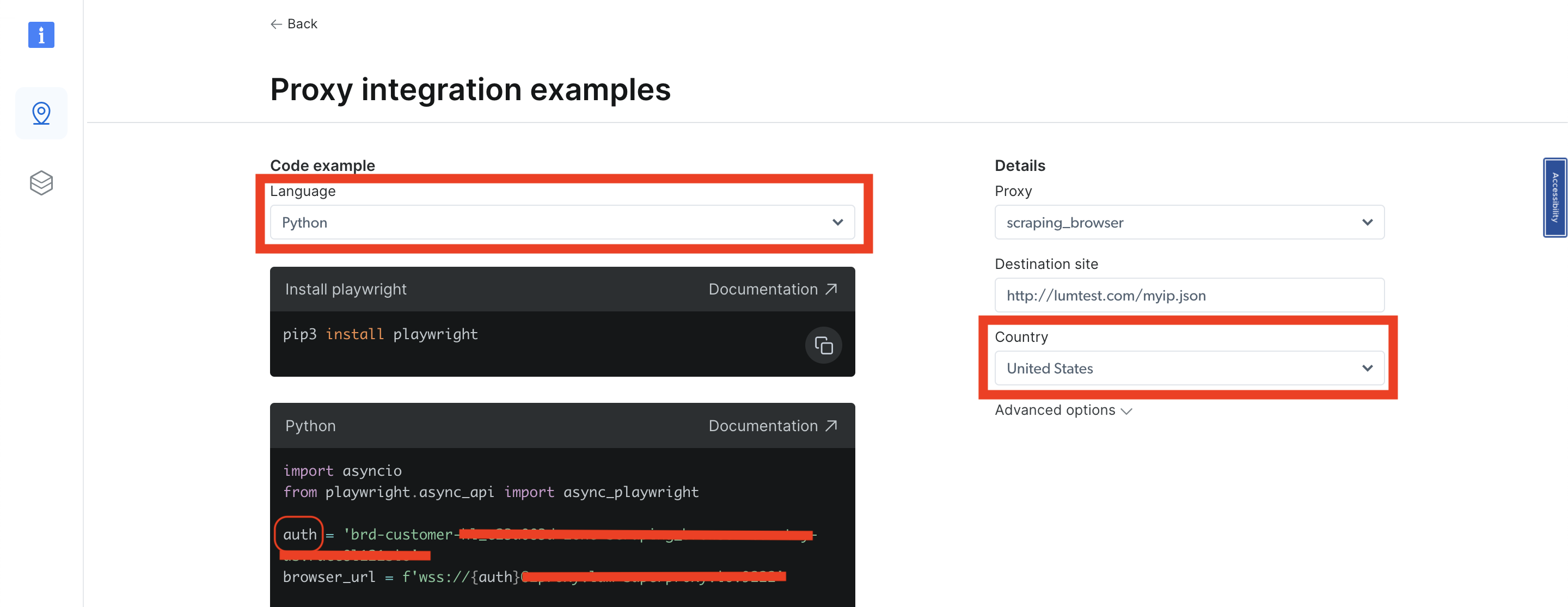
Cada vez que você altera seu país, obtém um usuário diferente para aquele país/Zona específica. Com base no nome de usuário obtido e no país selecionado, pegue o usuário, coloque-o em seu código e execute-o novamente.
Conclusão
Neste tutorial, você aprendeu como fazer scraping do Zillow usando o Beautiful Soup. Você também aprendeu quais
técnicas anti-scraping são empregadas pelo Zillow e como contorná-las. Para resolver essas questões, foi introduzido o Bright Data Scraping Browser, que ajuda você a superar os mecanismos anti-scraping do Zillow e extrair os dados desejados de forma integrada.
Além do Navegador de scraping, a API Zillow Scraper da Bright Data fornece acesso perfeito a dados abrangentes do Zillow, contornando as medidas anti-scraping para você.
Observação: este guia foi exaustivamente testado por nossa equipe no momento da redação, mas como os sites atualizam frequentemente seu código e estrutura, algumas etapas podem não funcionar mais como esperado.





