

Nesta postagem do blog, você aprenderá:
- O que é um raspador OpenSea
- Os tipos de dados que você pode extrair automaticamente do OpenSea
- Como criar um script de raspagem do OpenSea usando Python
- Quando e por que uma solução mais avançada pode ser necessária
Vamos mergulhar de cabeça!
O que é um OpenSea Scraper?
Um coletor de dados do OpenSea é uma ferramenta projetada para coletar dados do OpenSea, o maior mercado de NFT do mundo. O principal objetivo dessa ferramenta é automatizar a coleta de várias informações relacionadas a NFTs. Normalmente, ela usa soluções de navegador automatizadas para recuperar dados do OpenSea em tempo real sem a necessidade de esforço manual.
Dados a serem extraídos do OpenSea
Aqui estão alguns dos principais pontos de dados que você pode extrair do OpenSea:
- Nome da coleção NFT: O título ou nome da coleção NFT.
- Classificação da coleção: a classificação ou posição da coleção com base em seu desempenho.
- Imagem NFT: A imagem associada à coleção ou ao item do NFT.
- Preço mínimo: O preço mínimo listado para um item na coleção.
- Volume: O volume total de negociação da coleção NFT.
- Mudança de porcentagem: A variação de preço ou a variação percentual no desempenho da coleção em um período específico.
- ID do token: o identificador exclusivo de cada NFT na coleção.
- Último preço de venda: O preço de venda mais recente de um NFT na coleção.
- Histórico de vendas: O histórico de transações de cada item NFT, incluindo preços e compradores anteriores.
- Ofertas: Ofertas ativas feitas para um NFT na coleção.
- Informações do criador: Detalhes sobre o criador do NFT, como seu nome de usuário ou perfil.
- Características/Atributos: Características ou propriedades específicas dos itens NFT (por exemplo, raridade, cor, etc.).
- Descrição do item: Uma breve descrição ou informação sobre o item NFT.
Como fazer scraping do OpenSea: Guia passo a passo
Nesta seção guiada, você aprenderá a criar um coletor de dados do OpenSea. O objetivo é desenvolver um script Python que reúna automaticamente dados sobre coleções NFT na seção “Top” da página “Gaming”:
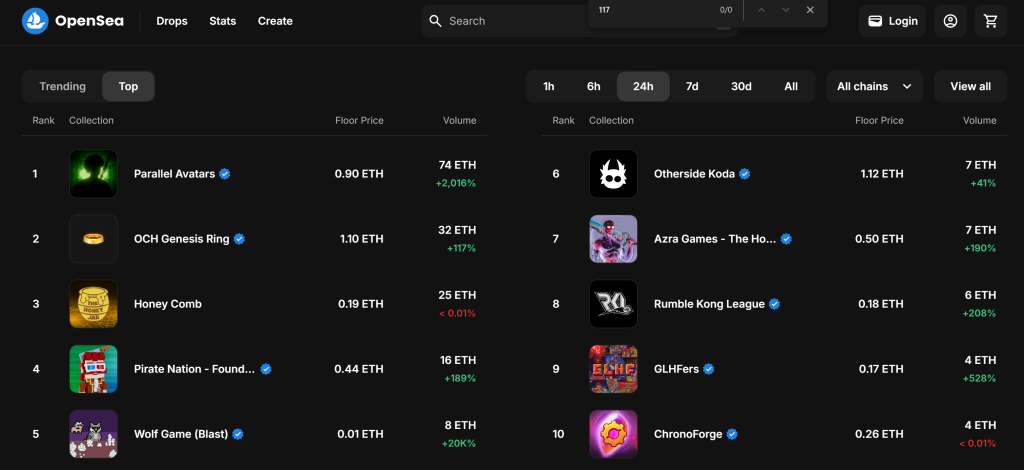
Siga as etapas abaixo e veja como fazer o scraping do OpenSea!
Etapa 1: Configuração do projeto
Antes de começar, verifique se você tem o Python 3 instalado em seu computador. Caso contrário, faça o download e siga as instruções de instalação.
Use o comando abaixo para criar uma pasta para seu projeto:
mkdir opensea-scraper
O diretório opensea-scraper representa a pasta do projeto do seu coletor de dados Python OpenSea.
Navegue até ele no terminal e inicialize um ambiente virtual dentro dele:
cd opensea-scraper
python -m venv venv
Carregue a pasta do projeto em seu IDE Python favorito. O Visual Studio Code com a extensão Python ou o PyCharm Community Edition são suficientes.
Crie um arquivo scraper.py na pasta do projeto, que agora deve conter essa estrutura de arquivo:

No momento, o scraper.py é um script Python em branco, mas em breve conterá a lógica de raspagem desejada.
No terminal do IDE, ative o ambiente virtual. No Linux ou macOS, execute este comando:
./env/bin/activate
De forma equivalente, no Windows, execute:
env/Scripts/activate
Incrível, agora você tem um ambiente Python para raspagem da Web!
Etapa 2: Escolha a biblioteca de raspagem
Antes de começar a codificar, você precisa determinar as melhores ferramentas de raspagem para extrair os dados necessários. Para fazer isso, você deve primeiro realizar um teste preliminar para analisar como o site de destino se comporta da seguinte forma:
- Abra a página de destino no modo de navegação anônima para evitar que os cookies e as preferências pré-armazenados afetem sua análise.
- Clique com o botão direito do mouse em qualquer lugar da página e selecione “Inspecionar” para abrir as ferramentas de desenvolvimento do navegador.
- Navegue até a guia “Network” (Rede).
- Recarregue a página e interaja com ela – por exemplo, clicando nos botões “1h” e “6h”.
- Monitore a atividade na guia “Fetch/XHR”.
Isso lhe dará uma visão sobre se a página da Web carrega e renderiza dados dinamicamente:
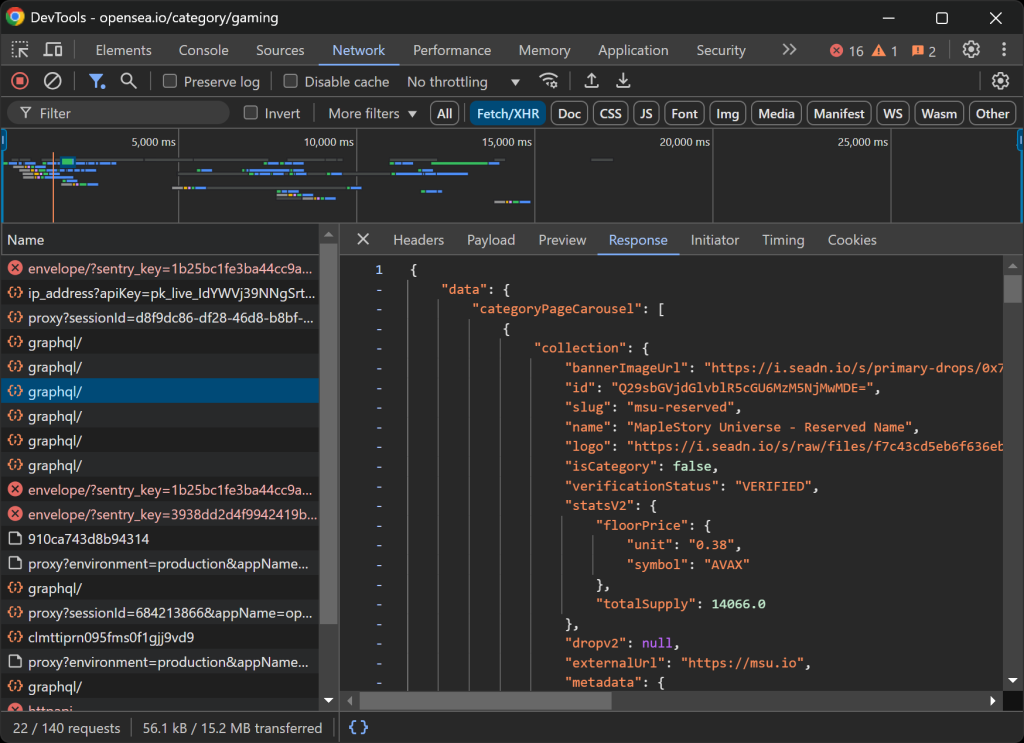
Nessa seção, é possível ver todas as solicitações AJAX que a página faz em tempo real. Ao inspecionar essas solicitações, você perceberá que o OpenSea obtém dados do servidor de forma dinâmica. Além disso, uma análise mais aprofundada revela que algumas interações de botões acionam a renderização de JavaScript para atualizar dinamicamente o conteúdo da página.
Isso indica que a raspagem do OpenSea requer uma ferramenta de automação do navegador como o Selenium!
O Selenium permite controlar um navegador da Web de forma programática, imitando interações reais do usuário para extrair dados de forma eficaz. Agora, vamos instalá-lo e começar.
Etapa 3: Instalar e configurar o Selenium
Você pode obter o Selenium por meio do pacote selenium pip. Em um ambiente virtual ativado, execute o comando abaixo para instalar o Selenium:
pip install -U selenium
Para obter orientação sobre como usar a ferramenta de automação do navegador, leia nosso guia sobre raspagem da Web com o Selenium.
Importe o Selenium em scraper.py e inicialize um objeto WebDriver para controlar o Chrome:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
O snippet acima configura uma instância do WebDriver para interagir com o Chrome. Lembre-se de que o OpenSea emprega medidas antirrastreamento que detectam navegadores sem cabeça e os bloqueiam. Especificamente, o servidor retorna uma página de “Acesso negado”.
Isso significa que você não pode usar o sinalizador --headless para esse raspador. Como uma abordagem alternativa, considere explorar o Playwright Stealth ou o SeleniumBase.
Como o OpenSea adapta seu layout com base no tamanho da janela, maximize a janela do navegador para garantir que a versão para desktop seja renderizada:
driver.maximize_window()
Por fim, certifique-se sempre de fechar adequadamente o WebDriver para liberar recursos:
driver.quit()
Maravilhoso! Agora você está totalmente configurado para começar a fazer o scraping do OpenSea.
Etapa 4: Visite a página de destino
Use o método get() do Selenium WebDriver para dizer ao navegador para acessar a página desejada:
driver.get("https://opensea.io/category/gaming")
Seu arquivo scraper.py agora deve conter estas linhas:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# To avoid the responsive rendering
driver.maximize_window()
# Visit the target page
driver.get("https://opensea.io/category/gaming")
# Scraping logic...
# close the browser and release its resources
driver.quit()
Coloque um ponto de interrupção de depuração na linha final do script e execute-o. Aqui está o que você deve ver:
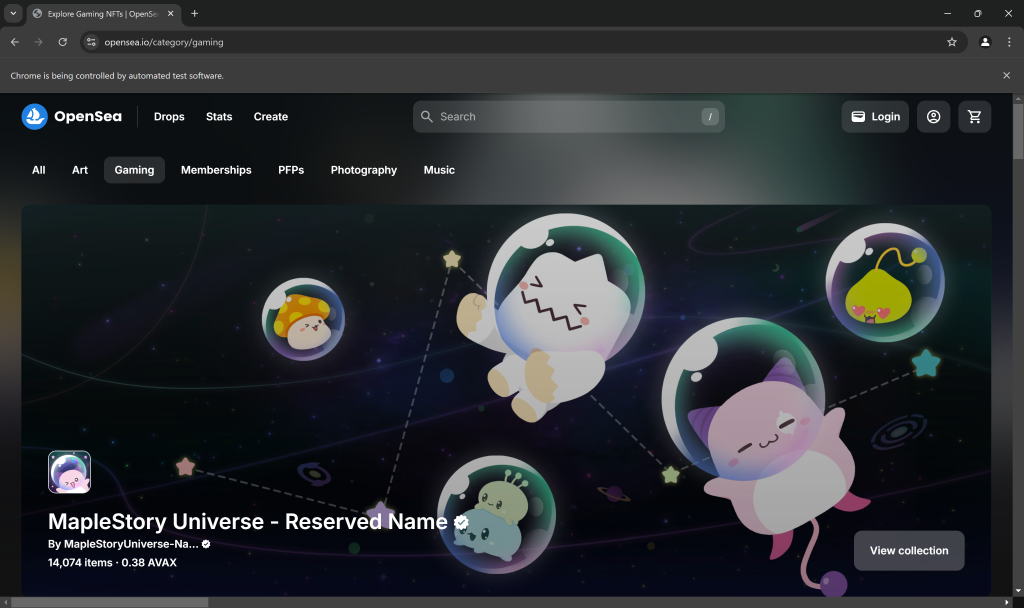
A mensagem “O Chrome está sendo controlado por um software de teste automatizado.” certifica que o Selenium está controlando o Chrome conforme o esperado. Muito bem!
Etapa 5: Interaja com a página da Web
Por padrão, a página “Gaming” (Jogos) mostra as coleções NFT “Trending” (Tendências):
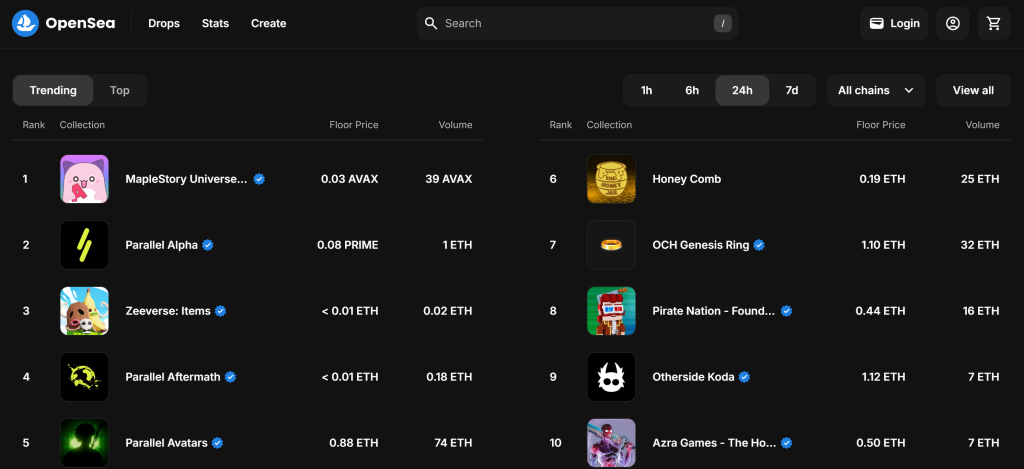
Lembre-se de que você está interessado na coleção “Top” do NFT. Em outras palavras, você deseja instruir o coletor de dados do OpenSea a clicar no botão “Top”, conforme abaixo:
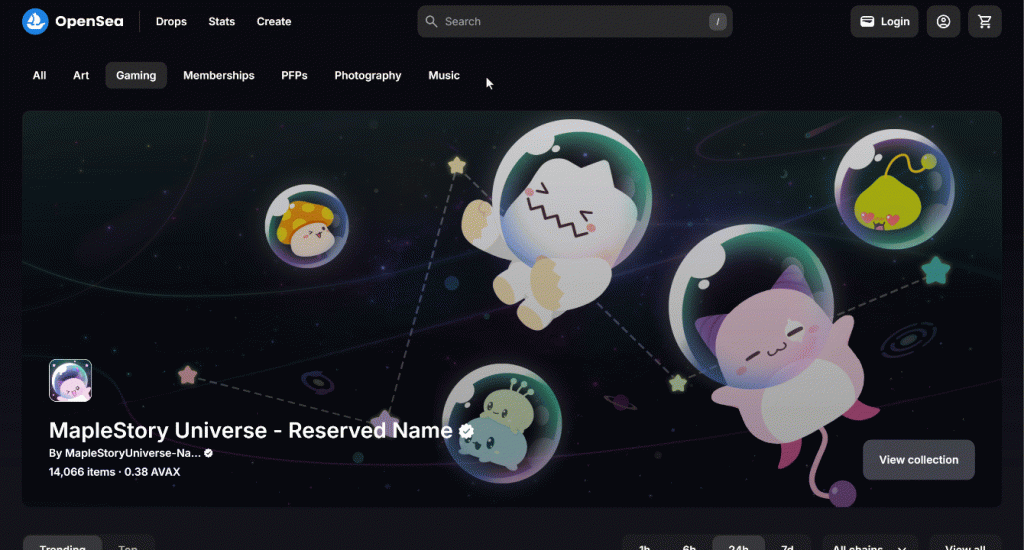
Como primeira etapa, inspecione o botão “Top” clicando com o botão direito do mouse sobre ele e selecionando a opção “Inspect” (Inspecionar):
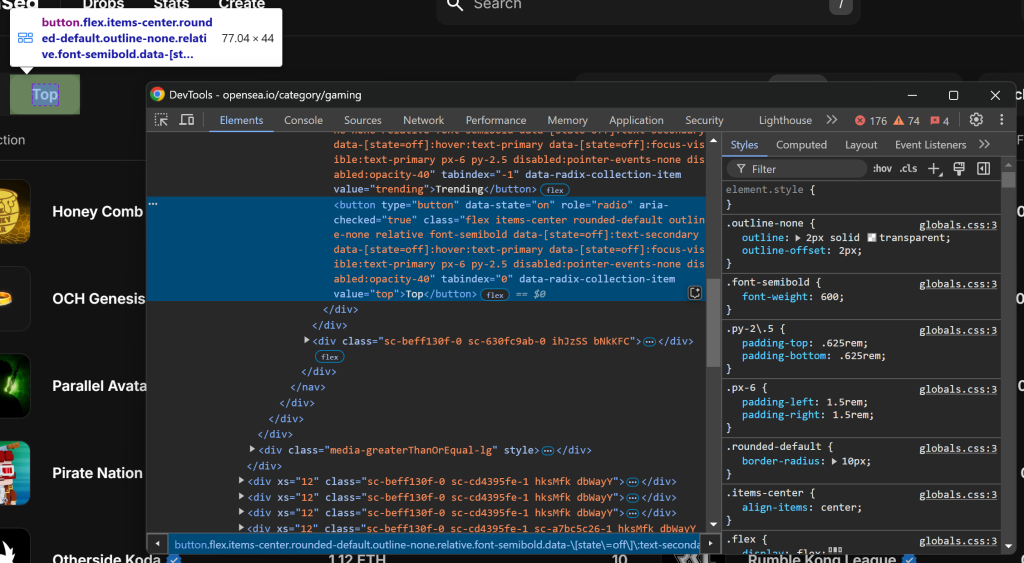
Observe que você pode selecioná-lo usando o seletor CSS [value="top"]. Use find_element() do Selenium para aplicar esse seletor CSS na página. Em seguida, depois de selecionar o elemento, clique nele com click():
top_element = driver.find_element(By.CSS_SELECTOR, "[value="top"]")
top_element.click()
Para que o código acima funcione, não se esqueça de adicionar a importação By:
from selenium.webdriver.common.by import By
Excelente! Essas linhas de código simularão a interação desejada.
Etapa nº 6: Prepare-se para raspar as coleções de NFT
A página de destino exibe as 10 principais coleções NFT da categoria selecionada. Como essa é uma lista, inicialize uma matriz vazia para armazenar as informações extraídas:
nft_collections = []
Em seguida, inspecione um elemento HTML de entrada de coleção NFT:
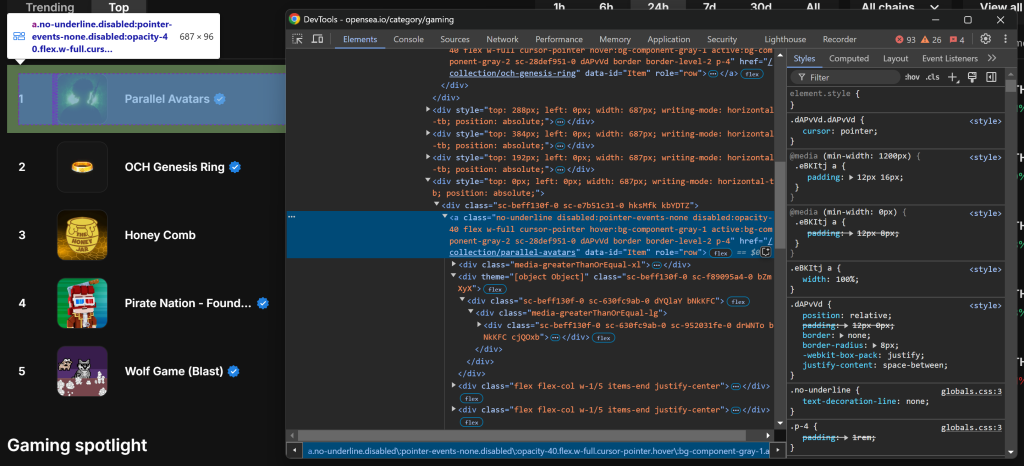
Observe que você pode selecionar todas as entradas da coleção NFT usando o seletor CSS a[data-id="Item"]. Como alguns nomes de classe nos elementos parecem ser gerados aleatoriamente, evite direcioná-los diretamente. Em vez disso, concentre-se nos atributos data-*, pois eles são normalmente usados para testes e permanecem consistentes ao longo do tempo.
Recupere todos os elementos de entrada da coleção NFT usando find_elements():
item_elements = driver.find_elements(By.CSS_SELECTOR, "a[data-id="Item"]")
Em seguida, itere pelos elementos e prepare-se para extrair dados de cada um deles:
for item_element in item_elements:
# Scraping logic...
Excelente! Você está pronto para começar a extrair dados dos elementos do OpenSea NFT.
Etapa nº 7: Extraia os elementos da coleção NFT
Inspecionar uma entrada de coleta de NFT:
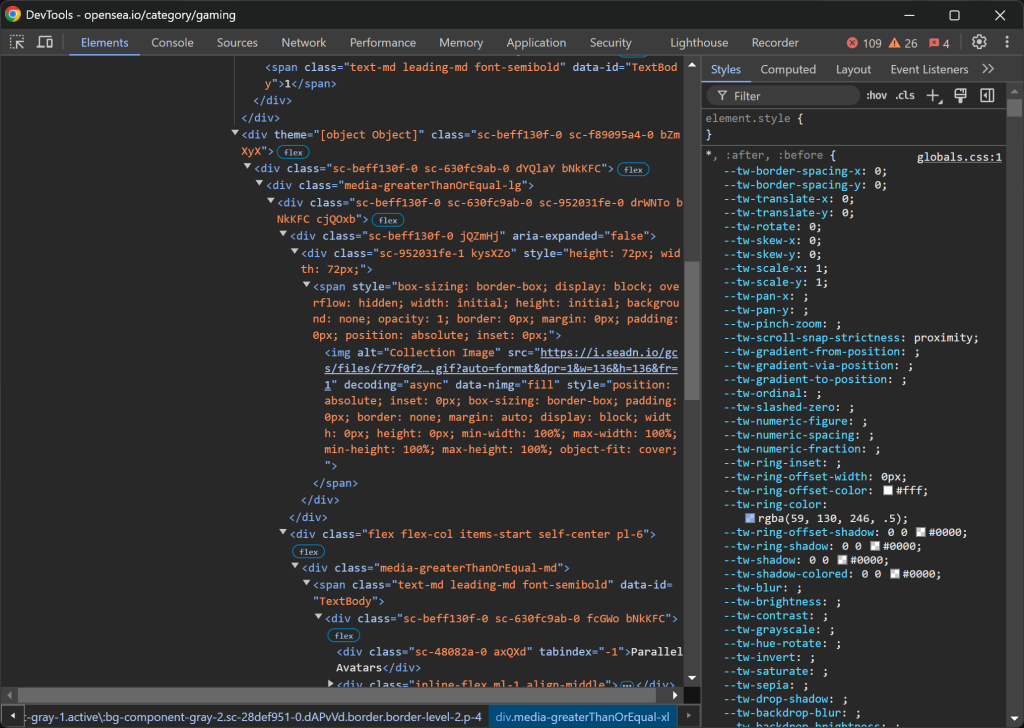
A estrutura HTML é bastante complexa, mas você pode extrair os seguintes detalhes:
- A imagem da coleção de
img[alt="Imagem da coleção"] - A classificação da coleção de
[data-id="TextBody"] - O nome da coleção de
[tabindex="-1"]
Infelizmente, esses elementos não têm atributos exclusivos ou estáveis, portanto, você precisará confiar em seletores potencialmente instáveis. Comece implementando a lógica de raspagem para esses três primeiros atributos:
image_element = item_element.find_element(By.CSS_SELECTOR, "img[alt="Collection Image"]")
image = image_element.get_attribute("src")
rank_element = item_element.find_element(By.CSS_SELECTOR, "[data-id="TextBody"]")
rank = int(rank_element.text)
name_element = item_element.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
name = name_element.text
A propriedade .text recupera o conteúdo de texto do elemento selecionado. Como a classificação será usada posteriormente para ordenar os dados extraídos, ela é convertida em um número inteiro. Enquanto isso, .get_attribute("src") obtém o valor do atributo src, extraindo o URL da imagem.
Em seguida, concentre-se nas colunas .w-1/5:
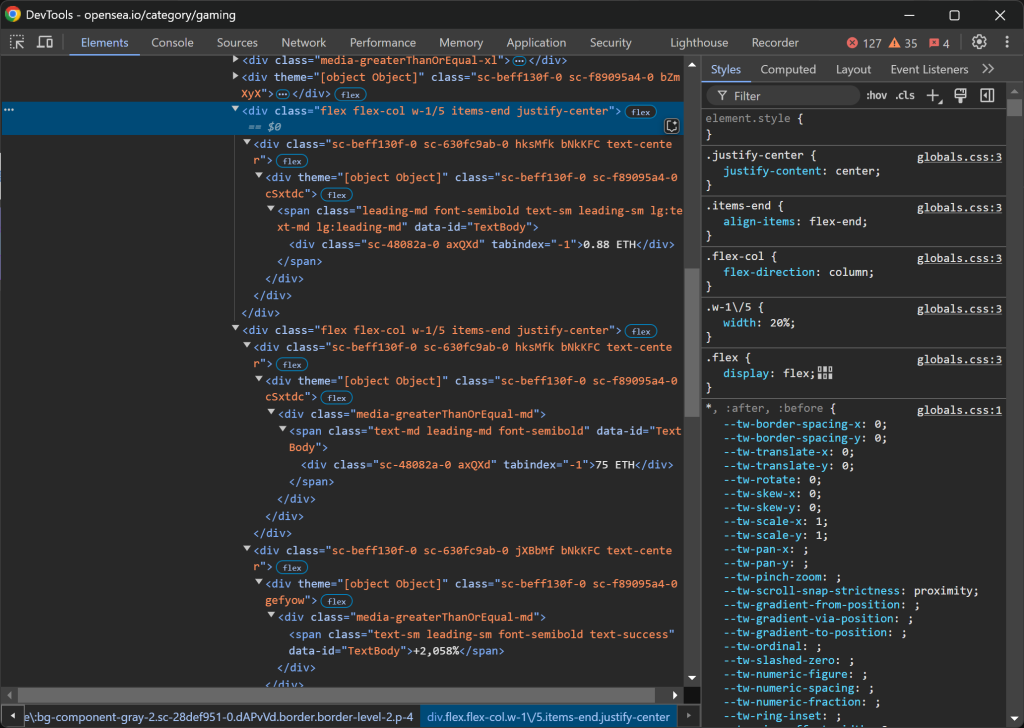
Veja como os dados estão estruturados:
- A primeira coluna
.w-1/5contém o preço mínimo. - A segunda coluna
.w-1/5contém o volume e a alteração percentual, cada um em elementos separados.
Extraia esses valores com a seguinte lógica:
floor_price_element = item_element.find_element(By.CSS_SELECTOR, ".w-1/5")
floor_price = floor_price_element.text
volume_column = item_element.find_elements(By.CSS_SELECTOR, ".w-1/5")[1]
volume_element = volume_column.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
volume = volume_element.text
percentage_element = volume_column.find_element(By.CSS_SELECTOR, ".leading-sm")
percentage = percentage_element.text
Observe que você não pode usar .w-1/5 diretamente, mas precisa escapar / com .
Aqui vamos nós! A lógica de raspagem do OpenSea para obter coleções NFT está completa.
Etapa nº 8: coletar os dados extraídos
Atualmente, você tem os dados extraídos espalhados por diversas variáveis. Preencha um novo objeto nft_collection com esses dados:
nft_collection = {
"rank": rank,
"image": image,
"name": name,
"floor_price": floor_price,
"volume": volume,
"percentage": percentage
}
Em seguida, não se esqueça de adicioná-lo à matriz nft_collections:
nft_collections.append(nft_collection)
Fora do loop for, classifique os dados extraídos em ordem crescente:
nft_collections.sort(key=lambda x: x["rank"])
Fantástico! Só falta exportar essas informações para um arquivo legível por humanos, como o CSV.
Etapa 9: Exportar os dados extraídos para CSV
O Python tem suporte integrado para exportar dados para formatos como CSV. Faça isso com estas linhas de código:
csv_filename = "nft_collections.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=nft_collections[0].keys())
writer.writeheader()
writer.writerows(nft_collections)
Esses snippets exportam os dados extraídos da lista nft_collections para um arquivo CSV chamado nft_collections.csv. Ele usa o módulo csv do Python para criar um objeto escritor que grava os dados em um formato estruturado. Cada entrada é armazenada como uma linha com cabeçalhos de coluna correspondentes às chaves do dicionário na lista nft_collections.
Importar csv da biblioteca padrão do Python com:
imprort csv
Etapa nº 10: Juntar tudo
Esse é o código final de seu coletor de dados OpenSea:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# To avoid the responsive rendering
driver.maximize_window()
# Visit the target page
driver.get("https://opensea.io/category/gaming")
# Select the "Top" NFTs
top_element = driver.find_element(By.CSS_SELECTOR, "[value="top"]")
top_element.click()
# Where to store the scraped data
nft_collections = []
# Select all NFT collection HTML elements
item_elements = driver.find_elements(By.CSS_SELECTOR, "a[data-id="Item"]")
# Iterate over them and scrape data from them
for item_element in item_elements:
# Scraping logic
image_element = item_element.find_element(By.CSS_SELECTOR, "img[alt="Collection Image"]")
image = image_element.get_attribute("src")
rank_element = item_element.find_element(By.CSS_SELECTOR, "[data-id="TextBody"]")
rank = int(rank_element.text)
name_element = item_element.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
name = name_element.text
floor_price_element = item_element.find_element(By.CSS_SELECTOR, ".w-1/5")
floor_price = floor_price_element.text
volume_column = item_element.find_elements(By.CSS_SELECTOR, ".w-1/5")[1]
volume_element = volume_column.find_element(By.CSS_SELECTOR, "[tabindex="-1"]")
volume = volume_element.text
percentage_element = volume_column.find_element(By.CSS_SELECTOR, ".leading-sm")
percentage = percentage_element.text
# Populate a new NFT collection object with the scraped data
nft_collection = {
"rank": rank,
"image": image,
"name": name,
"floor_price": floor_price,
"volume": volume,
"percentage": percentage
}
# Add it to the list
nft_collections.append(nft_collection)
# Sort the collections by rank in ascending order
nft_collections.sort(key=lambda x: x["rank"])
# Save to CSV
csv_filename = "nft_collections.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=nft_collections[0].keys())
writer.writeheader()
writer.writerows(nft_collections)
# close the browser and release its resources
driver.quit()
E pronto! Em menos de 100 linhas de código, você pode criar um script simples de raspagem do OpenSea em Python.
Inicie-o com o seguinte comando no terminal:
python scraper.py
Depois de algum tempo, esse arquivo nft_collections.csv aparecerá na pasta do projeto:
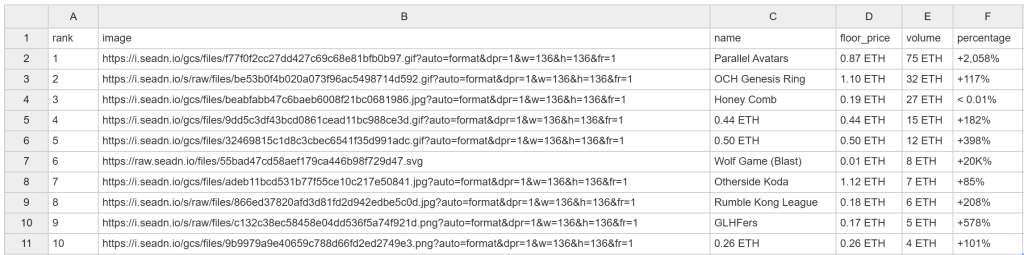
Parabéns! Você acabou de raspar o OpenSea como planejado.
Desbloqueando dados do OpenSea com facilidade
O OpenSea oferece muito mais do que apenas classificações de coleções NFT. Ele também fornece páginas detalhadas para cada coleção de NFT e os itens individuais dentro delas. Como os preços das NFTs flutuam com frequência, seu script de raspagem precisa ser executado automática e frequentemente para capturar dados novos. No entanto, a maioria das páginas do OpenSea é protegida por medidas rigorosas contra raspagem, o que torna a recuperação de dados um desafio.
Como observamos anteriormente, usar navegadores sem cabeça não é uma opção, o que significa que você estará gastando recursos para manter a instância do navegador aberta. Além disso, ao tentar interagir com outros elementos da página, você poderá ter problemas:
Por exemplo, o carregamento de dados pode travar e as solicitações de AJAX no navegador podem ser bloqueadas, resultando em um erro 403 Forbidden:
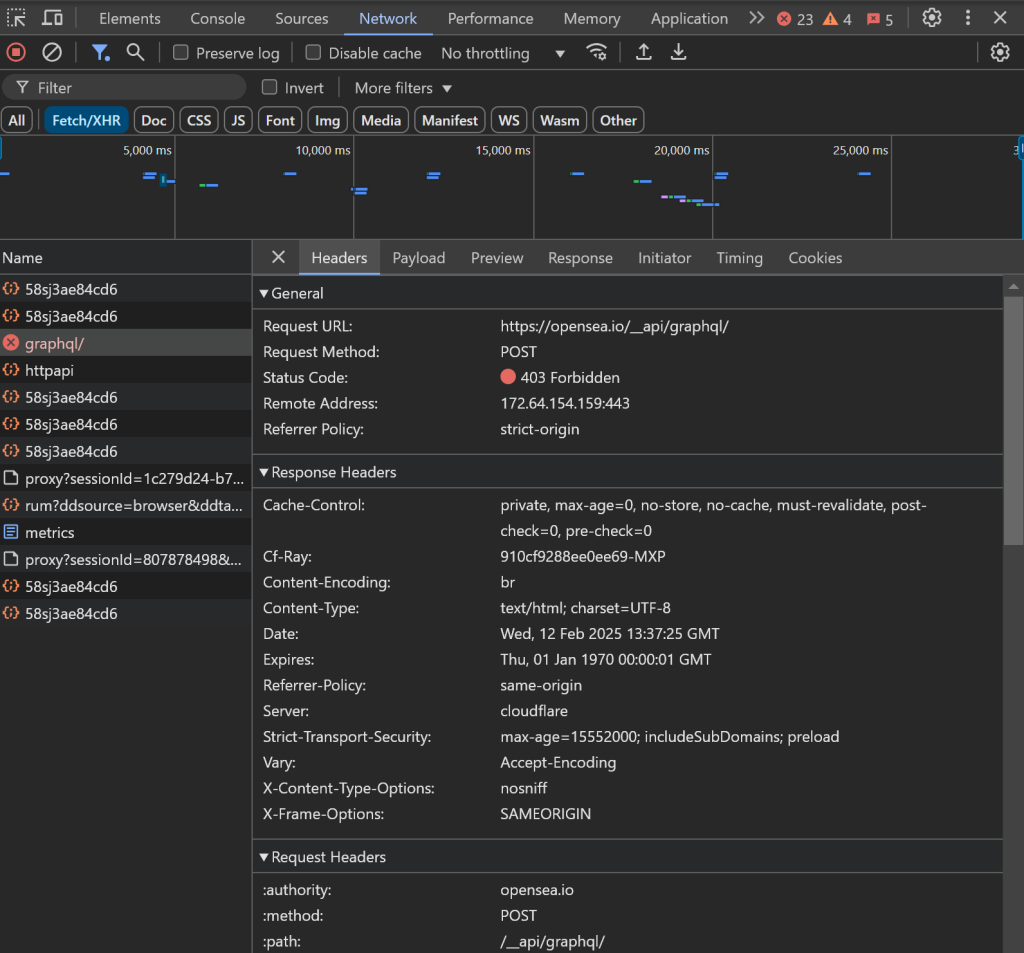
Isso acontece devido às medidas anti-bot avançadas implementadas pelo OpenSea para bloquear bots de raspagem.
Esses problemas tornam a raspagem do OpenSea sem as ferramentas certas uma experiência frustrante. A solução? Use o OpenSea Scraper dedicado da Bright Data, que permite que você recupere dados do site por meio de chamadas de API simples ou sem código, sem o risco de ser bloqueado!
Conclusão
Neste tutorial passo a passo, você aprendeu o que é um scraper do OpenSea e os tipos de dados que ele pode coletar. Você também criou um script Python para coletar dados do OpenSea NFT, tudo isso com menos de 100 linhas de código.
O desafio está nas rigorosas medidas anti-bot do OpenSea, que bloqueiam as interações automatizadas do navegador. Contorne esses problemas com nosso OpenSea Scraper, uma ferramenta que você pode integrar facilmente com a API ou sem código para recuperar dados públicos de NFT, incluindo nome, descrição, ID do token, preço atual, último preço de venda, histórico, ofertas e muito mais.
Crie uma conta gratuita na Bright Data hoje mesmo e comece a usar nossas APIs de raspagem!




