

Neste artigo, você descobrirá:
- O que é um Scraper do Indeed e como ele funciona
- Os tipos de dados que você pode extrair automaticamente do Indeed
- Como criar um script de scraping do Indeed usando Python
- Quando e por que você pode precisar de uma solução mais avançada
Vamos começar!
O que é um Scraper do Indeed?
Um scraper do Indeed extrai automaticamente anúncios de emprego e dados relacionados do site do Indeed. Ele funciona imitando interações humanas para navegar pelas páginas de busca de emprego. Depois disso, ele identifica elementos específicos, como cargos, empresas, locais e descrições. Por fim, obot de scrapingextrai os dados deles e os exporta para análise.
Dados que você pode encontrar no Indeed
O Indeed é um tesouro de dados relacionados a empregos, que podem ser inestimáveis para fins de análise de mercado, recrutamento ou pesquisa. Abaixo está uma lista dos principais pontos de dados que você pode extrair dele:
- Cargos: a função ou posição anunciada na lista.
- Nomes das empresas: detalhes do empregador, incluindo perfis da empresa.
- Localizações: a cidade, estado ou país onde o emprego está localizado.
- Descrições do cargo: informações detalhadas sobre a função, responsabilidades e requisitos.
- Faixas salariais: escalas salariais anunciadas (se disponíveis).
- Tipos de emprego: Tempo integral, meio período, contrato, estágio, etc.
- Datas de publicação: Quando a lista de vagas foi publicada.
- Tags e atributos: palavras-chave como “Contratação urgente” ou “Remoto”.
- Avaliações e comentários: Avaliações do empregador e feedback dos funcionários.
- Opções de candidatura: Indicadores como a disponibilidade de “Candidatura fácil”.
Se o seu foco são vagas de emprego, siga nosso guia sobre como extrair anúncios de emprego.
Como coletar dados do Indeed: guia passo a passo
Nesta seção do tutorial, você verá como criar um Scraper do Indeed. Você será guiado pelo processo de criação de um script Python para coletar dados da página de anúncios de vagas de “cientista de dados” do Indeed:
Siga as instruções e aprenda a coletar dados do Indeed!
Etapa 1: Configuração do projeto
Antes de começar, certifique-se de que você tem o Python 3 instalado em seu computador. Caso contrário, baixe-o e instale-o.
Agora, execute o comando abaixo no terminal para criar um diretório para o seu projeto:
mkdir indeed_scraper
indeed_scraper conterá seu Scraper Python do Indeed.
Digite-o no terminal e inicialize um ambiente virtual dentro dele:
cd indeed_scraper
python -m venv env
Em seguida, carregue a pasta do projeto em seu IDE Python favorito. O Visual Studio Code com a extensão Python e o PyCharm Community Edition são boas opções.
Crie um arquivo scraper.py no diretório do projeto, que agora deve conter esta estrutura de arquivos:

O Scraper.py logo conterá a lógica de raspagem desejada.
É hora de ativar o ambiente virtual no terminal do IDE. No Linux ou macOS, faça isso com este comando:
./env/bin/activate
De forma equivalente, no Windows, execute:
env/Scripts/activate
Ótimo! Você tem um ambiente Python para Scraping de dados do Indeed.
Etapa 2: escolha a biblioteca de scraping certa
O próximo passo é determinar se o Indeed depende de páginas dinâmicas ou estáticas. Para fazer isso, abra a página de destino do Indeed no modo de navegação anônima do seu navegador e comece a explorá-la. Como você pode perceber facilmente, a maioria dos dados da página é carregada dinamicamente:
Isso é suficiente para dizer que você precisa de uma ferramenta de automação de navegador como o Selenium para fazer o scraping do Indeed de forma eficaz. Para obter mais orientações sobre esse processo, leia nosso guia sobre Scraping de dados com Selenium.
O Selenium permite controlar programaticamente um navegador da web para simular interações do usuário e fazer scraping de conteúdo renderizado por JavaScript. É hora de instalá-lo e começar a usá-lo!
Etapa 3: Instale e configure o Selenium
Em um ambiente virtual ativado, execute o seguinte comando para instalar o Selenium:
pip install -U selenium
Importe o Selenium no Scraper.py e configure um objeto WebDriver:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Configure uma instância controlável do Chrome
driver = webdriver.Chrome(service=Service())
O código acima inicializa o que você precisa para controlar uma instância do Chrome.
Observação: a Indeed implementou medidas anti-scraping para impedir que navegadores headless acessem suas páginas. Portanto, definir o sinalizador --headless faria com que seu script falhasse. Como abordagem alternativa, dê uma olhada no Playwright Stealth.
Na última linha do seu script, não se esqueça de fechar o driver da web:
driver.quit()
Ótimo! Você está totalmente configurado para fazer scraping no Indeed.
Etapa 4: visite a página de destino
Com o método get() do Selenium, instrua o navegador controlado a visitar a página de destino:
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnHP%2Cwhatautocomplete&vjk=45d1ba700870fbef")
O Scraper.py agora conterá as seguintes linhas de código:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Configure uma instância controlável do Chrome
driver = webdriver.Chrome(service=Service())
# Abrir a página de destino no navegador
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnHP%2Cwhatautocomplete&vjk=45d1ba700870fbef")
# Log de raspagem...
# Fechar o driver da web
driver.quit()
Adicione um ponto de interrupção de depuração na linha final. Execute o script com o depurador e veja abaixo o que você deve observar:
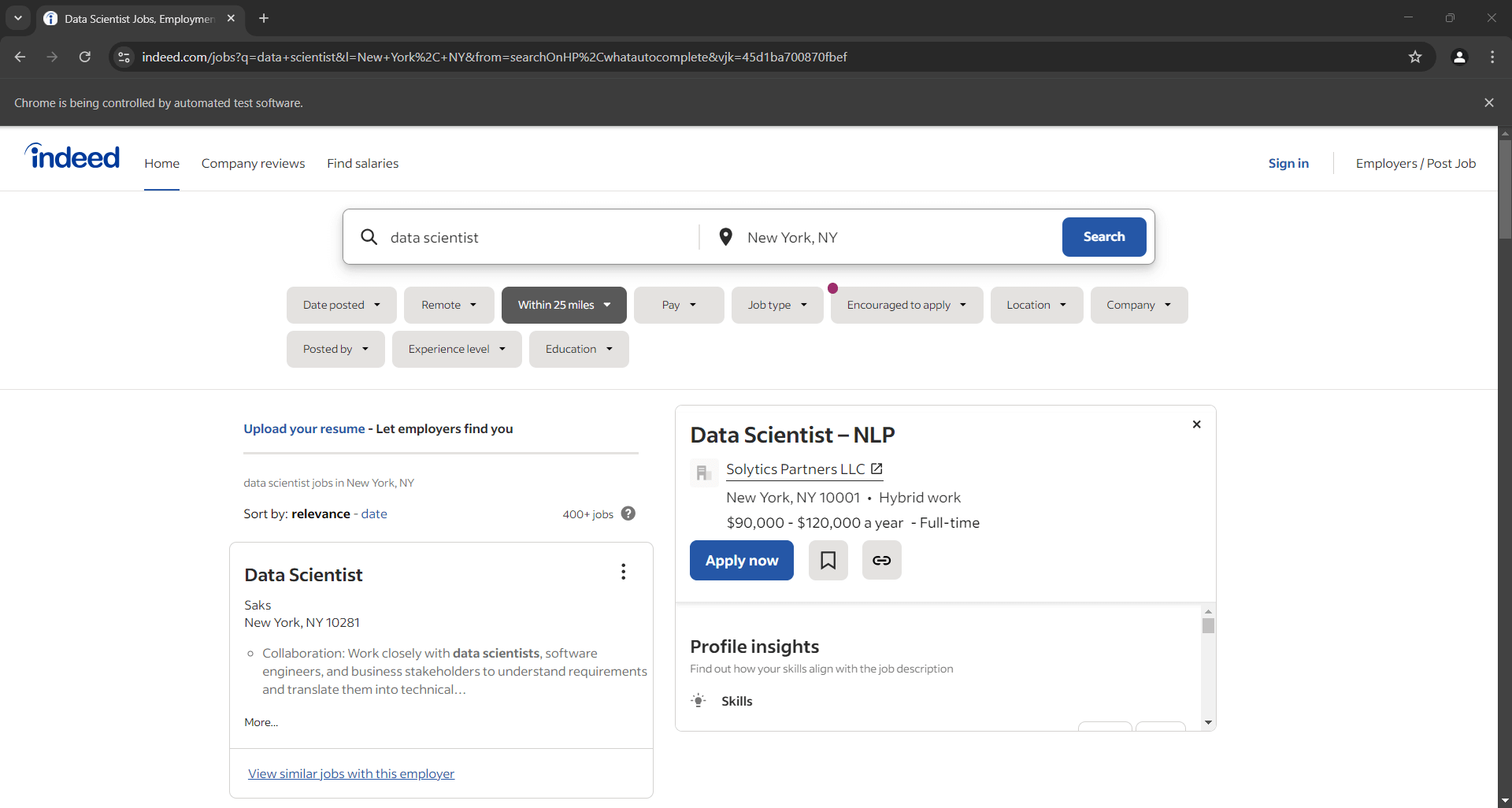
Observação: a notificação “O Chrome está sendo controlado por um software de teste automatizado” indica que o Selenium está controlando o Chrome conforme o esperado.
Muito bem!
Etapa 5: selecione os elementos da oferta de emprego
A página de busca de empregos do Indeed exibe várias vagas de emprego. Como nosso objetivo é coletar todas elas, comece inicializando uma matriz para armazenar os dados coletados:
jobs = []
Em seguida, inspecione os elementos HTML das vagas de emprego na página para entender como selecioná-los:
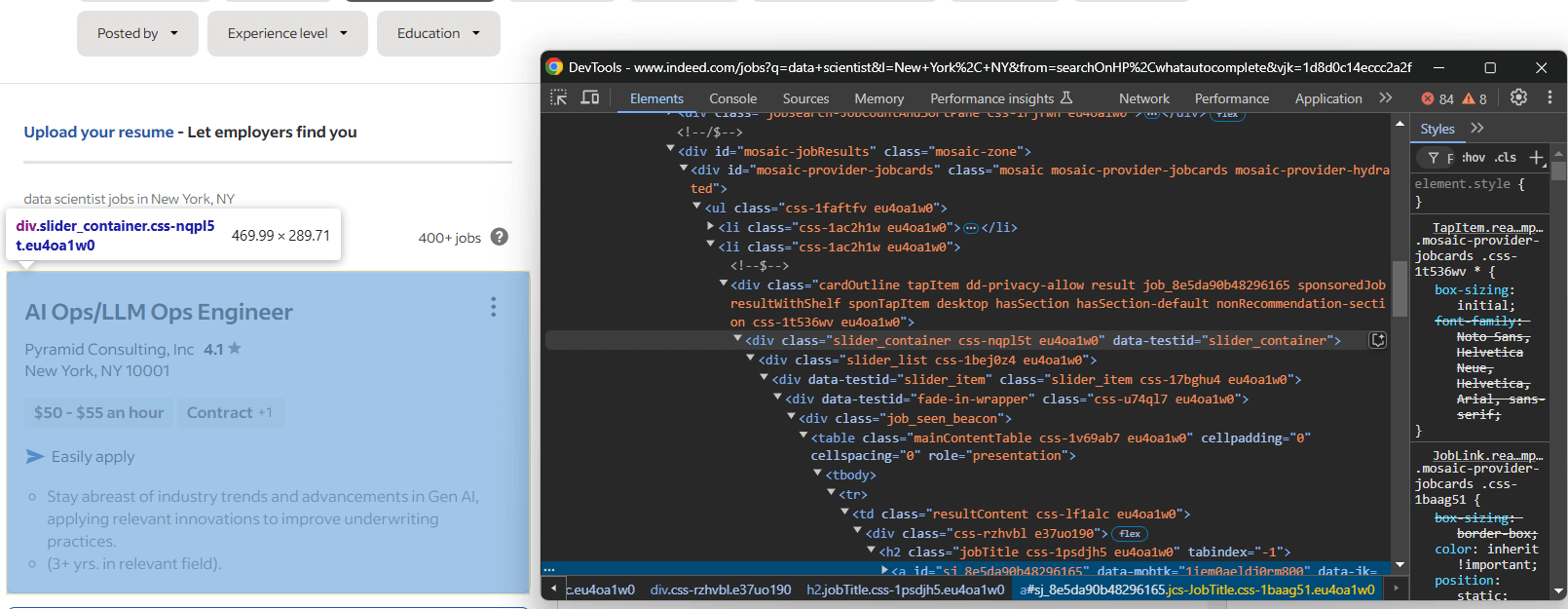
Aqui, cada elemento de vaga é um nó slider_item dentro do contêiner #mosaic-provider-jobcards.
Normalmente, você usaria classes CSS para selecionar elementos na página. No entanto, essas classes parecem ser geradas aleatoriamente, provavelmente no momento da compilação. Para garantir a estabilidade, é melhor direcionar os atributos id e data-testid, que são menos propensos a mudar com frequência.
Use o Selenium para selecionar os elementos de emprego:
jobs_container_element = driver.find_element(By.CSS_SELECTOR, "#mosaic-provider-jobcards")
job_elements = jobs_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="slider_item"]")
O método find_elements() aplica a estratégia de seletor especificada para recuperar todos os elementos correspondentes da página. Neste caso, a estratégia de seletor é um seletor CSS.
Certifique-se de importar By para que isso funcione:
from selenium.webdriver.common.by import By
Agora, itere sobre os elementos selecionados e prepare-se para extrair dados de cada um deles:
para job_element em job_elements:
# extraia os dados de cada vaga de emprego
Fantástico! Você está pronto para começar a extrair vagas de emprego do Indeed.
Etapa 6: extraia as principais informações da vaga
Inspecione um elemento do cartão, concentrando-se nas informações na seção superior do cartão:
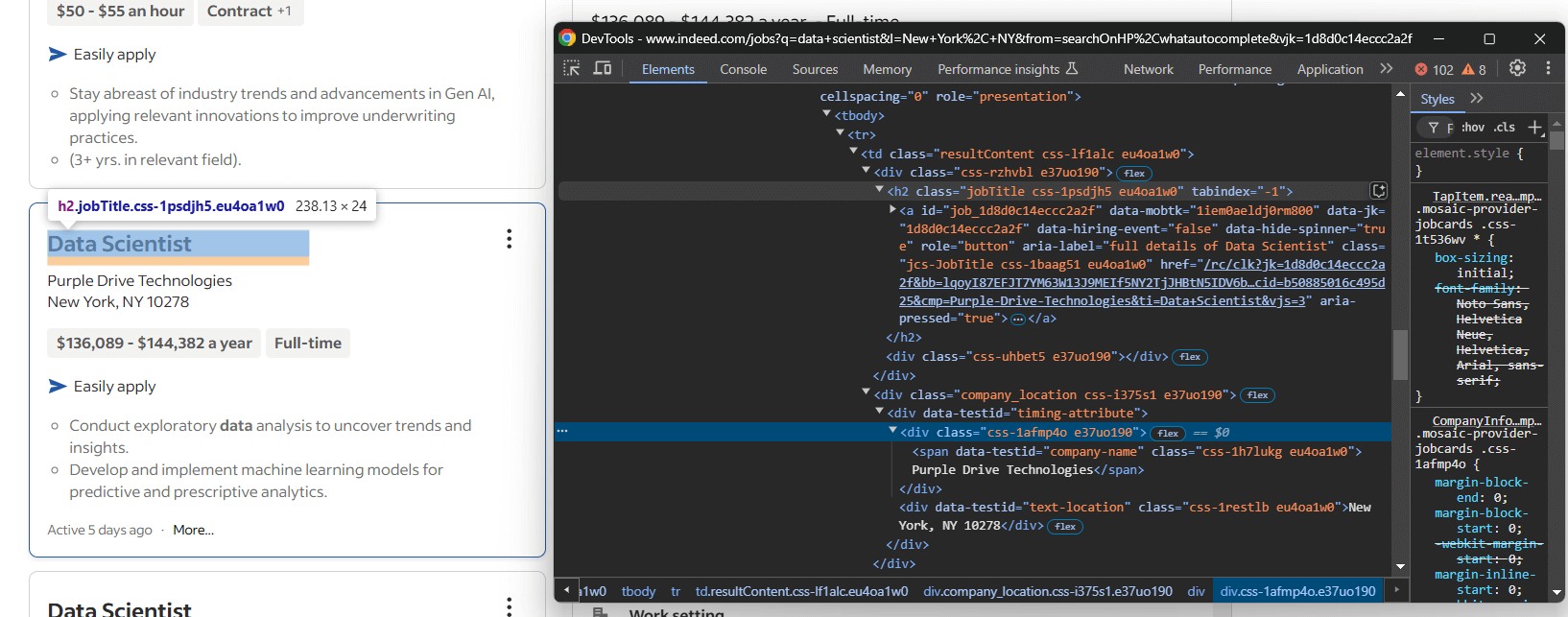
Aqui você vê que pode extrair:
- O título da vaga a partir do
<h2> - A URL da página da vaga do
<a>dentro do título<h2> - O nome da empresa do nó
[data-testid="company-name"] - A localização da empresa do elemento
[data-testid="text-location"]
Transforme as informações acima na lógica de extração da seguinte maneira:
title_element = job_element.find_element(By.CSS_SELECTOR, "h2.jobTitle")
title = title_element.text
url_element = title_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
elemento_empresa = job_element.find_element(By.CSS_SELECTOR, "[data-testid="company-name"]")
empresa = elemento_empresa.text
elemento_localização = job_element.find_element(By.CSS_SELECTOR, "[data-testid="text-location"]")
localização = elemento_localização.text
find_element() seleciona o primeiro elemento que corresponde ao seletor fornecido. Dado um nó, você pode acessar seu conteúdo de texto com o atributo text. Para obter o valor de um atributo HTML do nó, você deve usar o método get_attribute().
Ótimo! Você estabeleceu as bases para sua lógica de scraping do Indeed, mas ainda há dados úteis para serem extraídos.
Etapa 7: extraia os detalhes da vaga
Concentre-se na seção de detalhes do cartão da vaga:
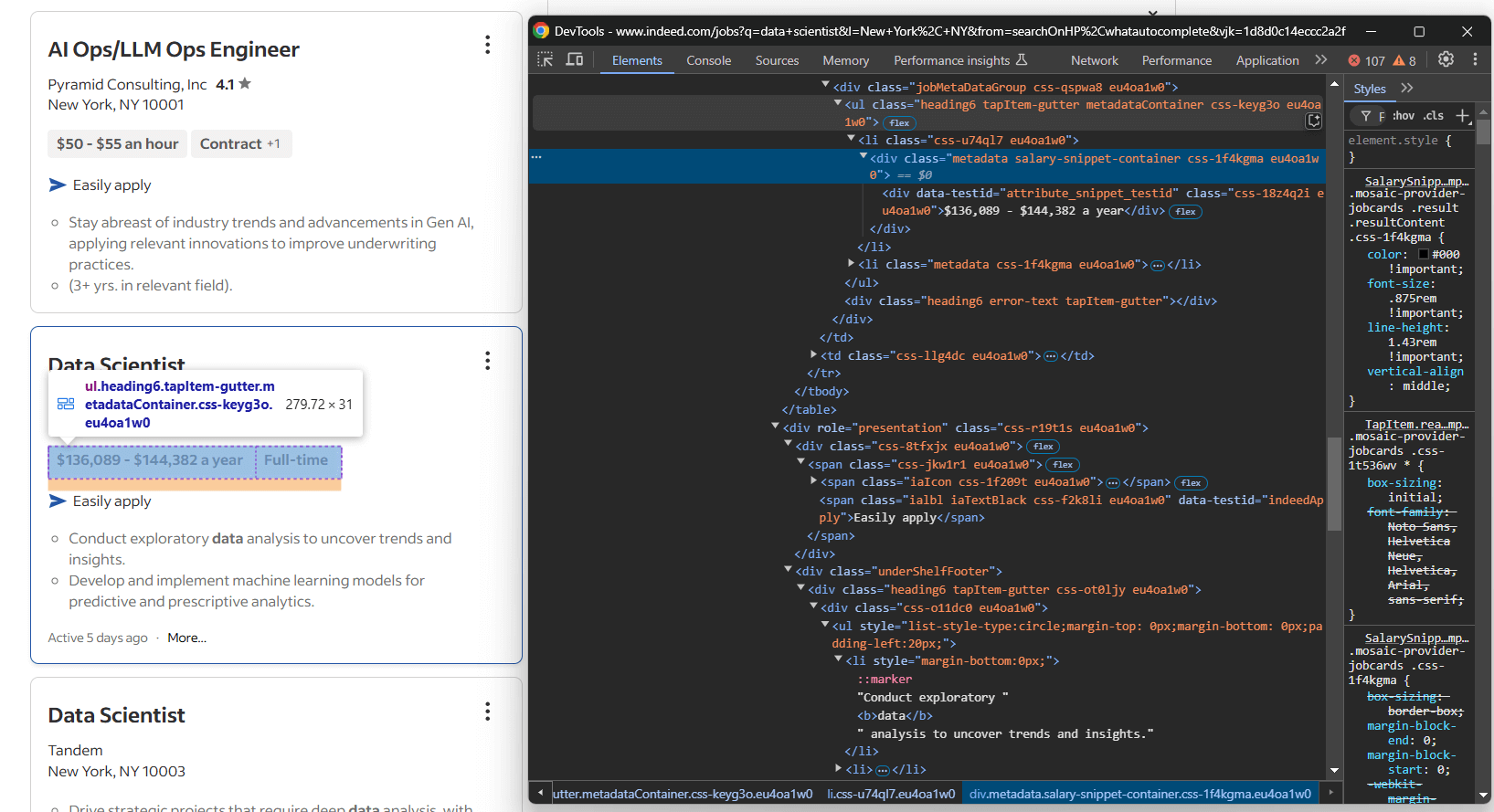
Desta vez, as informações a serem extraídas são:
- As tags da vaga em um ou mais elementos
[data-testid="attribute_snippet_testid"]dentro de um.jobMetaDataGroup<div> - Se há uma opção para se candidatar facilmente através do Indeed
- Os itens de descrição em um ou mais elementos
ul lidentro de um[role="presentation"]<div>
Vamos começar focando nas tags. Você pode coletar todas elas com:
tags = []
tags_container_element = job_element.find_element(By.CSS_SELECTOR, ".jobMetaDataGroup")
tag_elements = tags_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="attribute_snippet_testid"]")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
Primeiro, você precisa inicializar uma matriz onde armazenar todas as tags recuperadas. Isso é necessário, pois um único cartão de vaga de emprego pode conter várias tags. Depois de selecioná-las, itere sobre elas, extraia o texto e adicione as tags à matriz.
Extrair as informações de “Inscreva-se facilmente” também é complicado. O problema é que o elemento HTML que indica essa possibilidade não está presente em todas as vagas de emprego. Claramente, ele só está presente onde a opção “Inscreva-se facilmente” é suportada.
Quando você tenta selecionar um elemento que não está na página, o Selenium gera uma exceção NoSuchElementException. Assim, você pode usar isso para extrair a marcação “Inscreva-se facilmente” de forma eficaz:
tente:
job_element.find_element(By.CSS_SELECTOR, "[data-testid="indeedApply"]")
easily_apply = True
exceto NoSuchElementException:
easily_apply = False
Se o nó [data-testid="indeedApply"] não estiver na página, o Selenium gerará uma exceção NoSuchElementException. Ela será interceptada e easily_apply será definido como False.
Quanto aos itens de descrição, você pode extraí-los todos como fez com as tags:
description = []
description_container_element = job_element.find_element(By.CSS_SELECTOR, "[role="presentation"]")
description_elements = description_container_element.find_elements(By.CSS_SELECTOR, "ul li")
for description_element in description_elements:
description_item_text = description_element.text
# Ignorar strings de descrição vazias
if (description_item_text != ""):
description.append(description_item_text)
Uau! O Scraper do Indeed está quase completo.
Etapa 8: coletar os dados raspados
Com os dados coletados de cada vaga, preencha um dicionário de vagas:
job = {
"title": title,
"url": url,
"company": company,
"location": location,
"tags": tags,
"easily_apply": easily_apply,
"description": description
}
Em seguida, adicione-o à matriz de vagas:
empregos.append(emprego)
No final do loop for, os produtos devem conter algo como:
[{'title': 'Cientista de dados', 'url': 'https://www.indeed.com/rc/clk?jk=efc7b7f4a8be2882&bb=NM368jsOPyYGAfEtQk2NNae8tSeBHdJ8Y9tImVa1Q9GAipGe0zzddcUozFEL0Na_pYCR4W6ljgljsBxWTUrluVuL8Gom7x7UZlgMzs0spo3NRgisrZ7meuaPfaEcjWoe&xkcb=SoD767M34WNyEaSTwx0FbzkdCdPP&fccid=8678bc4e64c24580&vjs=3', 'company': 'GQR', 'location': 'Nova Iorque, NY', 'tags': [], 'easily_apply': False, 'description': ['Mantenha-se atualizado com as tendências do setor e as tecnologias emergentes para garantir uma vantagem competitiva.', 'Aplique técnicas estatísticas e de aprendizagem automática para melhorar o investimento...']},
# omitido por brevidade...
{'title': 'Cientista de dados, crimes financeiros - USDS', 'url': 'https://www.indeed.com/rc/clk?jk=aaa16dfd1cc6ef01&bb=NM368jsOPyYGAfEtQk2NNdxizAZQnHpzRrlr6WgbV1RtxmXz4vto1qiiqGiIj9CJFQQCV6cW59nE4hGw1yeNdokPfu8Fgl3EALBx5zdWjPm4COEu78DCFh4KTUMIFWkh&xkcb=SoAT67M34WNyEaSTwx0pbzkdCdPP&fccid=caed318a9335aac0&vjs=3', 'company': 'TikTok', 'location': 'Trabalho híbrido em Nova York, NY', 'tags': [], 'easily_apply': False, 'description': ['Como cientista de dados de crimes financeiros, você desempenhará um papel crucial no aproveitamento de técnicas de aprendizado de máquina, análise e visualização para aprimorar nosso...']}]
Maravilhoso! Você só precisa converter esses dados para um formato melhor.
Etapa 9: Exporte os dados coletados para CSV
Para tornar os dados coletados acessíveis e compartilháveis, é uma boa ideia exportá-los para um formato legível por humanos. Por exemplo, grave-os em um arquivo CSV. Para fazer isso, use estas linhas de código:
csv_file = "scraped_jobs.csv"
csv_headers = ["title", "url", "company", "location", "tags", "easily_apply", "description"]
with open(csv_file, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=csv_headers)
writer.writeheader()
for job in jobs:
writer.writerow({
"title": job["title"],
"url": job["url"],
"company": job["company"],
"location": job["location"],
"tags": ";".join(job["tags"]),
"easily_apply": "Sim" se job["easily_apply"] caso contrário "Não",
"description": ";".join(job["description"])
})
A função open() cria o arquivo CSV de saída, que é então preenchido com csv.DictWriter. Como os campos tags e description são matrizes, join() é usado para achatá-los em uma única string com elementos separados por ;.
Não se esqueça de importar csv da Biblioteca Padrão do Python:
import csv
Pronto! O Scraper do Indeed está completo.
Etapa 10: Junte tudo
Seu arquivo scraper.py final agora conterá:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
import csv
# Configure uma instância controlável do Chrome
driver = webdriver.Chrome(service=Service())
# Abra a página de destino no navegador
driver.get("https://www.indeed.com/jobs?q=data+scientist&l=New+York%2C+NY&from=searchOnDesktopSerp")
# Uma estrutura de dados onde armazenar as vagas de emprego coletadas
jobs = []
# Selecione os elementos de vagas de emprego na página
jobs_container_element = driver.find_element(By.CSS_SELECTOR, "#mosaic-provider-jobcards")
job_elements = jobs_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="slider_item"]")
# Extrair cada vaga de emprego na página
for job_element in job_elements:
title_element = job_element.find_element(By.CSS_SELECTOR, "h2.jobTitle")
title = title_element.text
url_element = title_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
elemento_empresa =element_job.find_element(By.CSS_SELECTOR, "[data-testid="nome-da-empresa"]")
empresa = elemento_empresa.text
elemento_localização = elemento_job.find_element(By.CSS_SELECTOR, "[data-testid="localização-texto"]")
localização = elemento_localização.text
tags = []
tags_container_element = job_element.find_element(By.CSS_SELECTOR, ".jobMetaDataGroup")
tag_elements = tags_container_element.find_elements(By.CSS_SELECTOR, "[data-testid="attribute_snippet_testid"]")
para tag_element em tag_elements:
tag = tag_element.text
tags.append(tag)
# Verifique se o elemento "Easy Apply" está na página
tente:
job_element.find_element(By.CSS_SELECTOR, "[data-testid="indeedApply"]")
easily_apply = True
exceto NoSuchElementException:
aplicar_facilmente = False
descrição = []
elemento_contêiner_descrição = elemento_trabalho.find_element(By.CSS_SELECTOR, "[role="presentation"]")
description_elements = description_container_element.find_elements(By.CSS_SELECTOR, "ul li")
para description_element em description_elements:
description_item_text = description_element.text
# Ignorar strings de descrição vazias
se (description_item_text != ""):
description.append(description_item_text)
# Armazene os dados coletados
job = {
"title": title,
"url": url,
"company": company,
"location": location,
"tags": tags,
"easily_apply": easily_apply,
"description": description
}
jobs.append(job)
# Exportar os dados coletados para um arquivo CSV de saída
csv_file = "jobs.csv"
csv_headers = ["title", "url", "company", "location", "tags", "easily_apply", "description"]
com open(arquivo_csv, modo="w", nova_linha="", codificação="utf-8") como arquivo:
escritor = csv.DictWriter(arquivo, nomes_de_campos=csv_headers)
writer.writeheader()
for job in jobs:
writer.writerow({
"title": job["title"],
"url": job["url"],
"company": job["company"],
"location": job["location"],
"tags": ";".join(job["tags"]),
"easily_apply": "Sim" se job["easily_apply"] caso contrário "Não",
"description": ";".join(job["description"])
})
# Feche o driver da web
driver.quit()
Em menos de 100 linhas de código, você acabou de criar um Scraper do Indeed em Python!
Inicie o Scraper com o seguinte comando:
python3 script.py
Ou, no Windows:
python script.py
Um arquivo jobs.csv aparecerá na pasta do seu projeto. Abra-o e você verá:
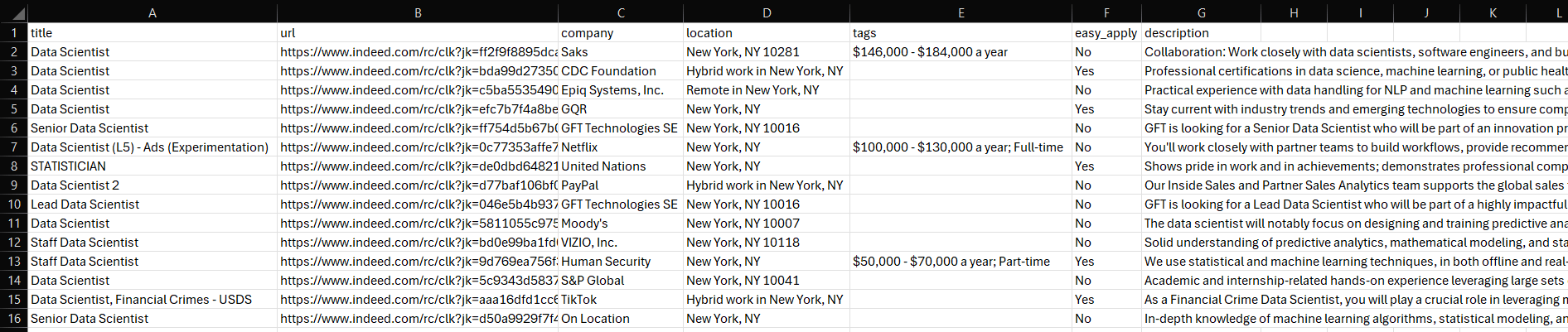
Et voilà! Missão cumprida.
Desbloqueie os dados do Indeed com facilidade
A Indeed está ciente do valor de seus dados e emprega medidas robustas para protegê-los. É por isso que, ao interagir com suas páginas usando uma ferramenta de automação de navegador como o Selenium, é provável que você encontre um CAPTCHA:
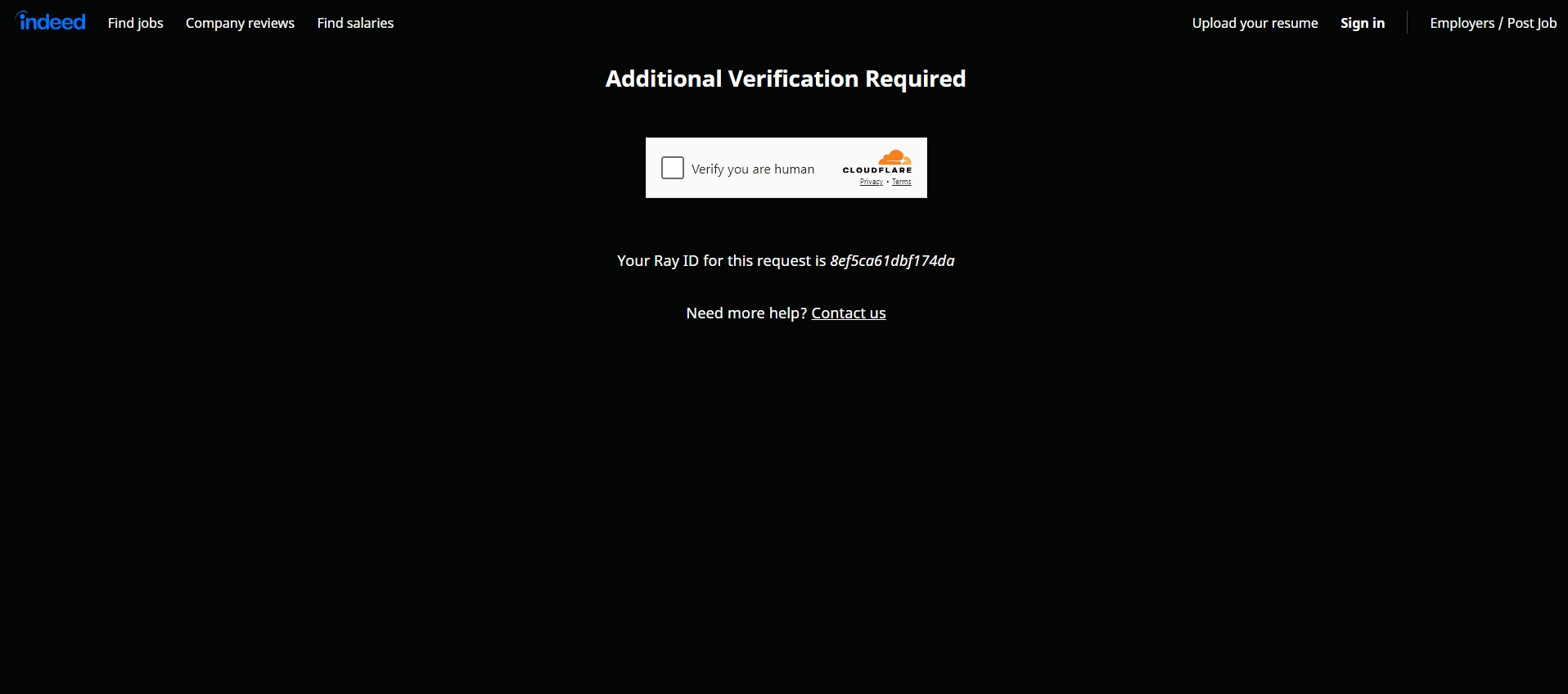
Como primeiro passo, considere seguir nosso guia sobre como contornar CAPTCHAs em Python. No entanto, esteja ciente de que o site ainda pode bloquear suas tentativas com medidas anti-bot adicionais. Descubra todas elas em nosso webinar sobre técnicas anti-bot.
Esses desafios destacam como a extração de dados do Indeed sem as ferramentas adequadas pode se tornar rapidamente frustrante e ineficiente. Além disso, a incapacidade de usar navegadores headless torna seu script de extração mais lento e mais intensivo em recursos.
A solução? A API Indeed Scraper da Bright Data, uma ferramenta que permite recuperar dados do Indeed de forma integrada por meio de chamadas de API simples — sem CAPTCHAs, sem bloqueios e sem complicações!
Conclusão
Neste guia passo a passo, você aprendeu o que é um Scraper do Indeed, os tipos de dados que ele pode recuperar e como construir um em Python. Em apenas cerca de 100 linhas de código, você criou um script que coleta automaticamente dados do Indeed.
Ainda assim, fazer scraping no Indeed traz seus desafios. A plataforma aplica medidas anti-bot rigorosas, incluindo CAPTCHAs. Elas são difíceis de contornar e podem retardar seu processo de scraping, tornando-o menos eficiente. Esqueça todos esses desafios com nossa API Indeed Scraper.
Se o Scraping de dados não é sua praia, mas você ainda está interessado em dados de vagas de emprego, explore nossos Conjuntos de dados do Indeed prontos para uso!
Crie uma conta gratuita na Bright Data hoje mesmo para experimentar nossas APIs de Scraper ou explorar nossos Conjuntos de dados.




