

O Scraping de dados é uma técnica automatizada para extrair e coletar grandes quantidades de dados de sites, usando diferentes ferramentas ou programas. É comumente usado para extrair tabelas HTML, que contêm dados organizados em colunas e linhas. Uma vez coletados, esses dados podem ser analisados ou usados para pesquisa. Para um guia mais detalhado, confira este artigo sobreScraping de dados em HTML.
Este tutorial ensinará como extrair tabelas HTML de sites usando Python.
Pré-requisitos
Antes de começar este tutorial, você precisainstalar o Python versão 3.8 ou mais recenteecriar um ambiente virtual. Se você é novo no Scraping de dados com Python,este artigoé um ponto de partida útil.
Depois de criar o ambiente, instale os seguintes pacotes Python:
- Requests
- Beautiful Soup
- pandas
Você pode instalar os pacotes com o seguinte comando:
pip install requests beautifulsoup4 pandas
Entendendo a estrutura da página da Web
Neste tutorial, você irá extrair dados dosite Worldometer. Esta página da Web contém dados atualizados sobre países ao redor do mundo, incluindo seus respectivos números populacionais para 2024:
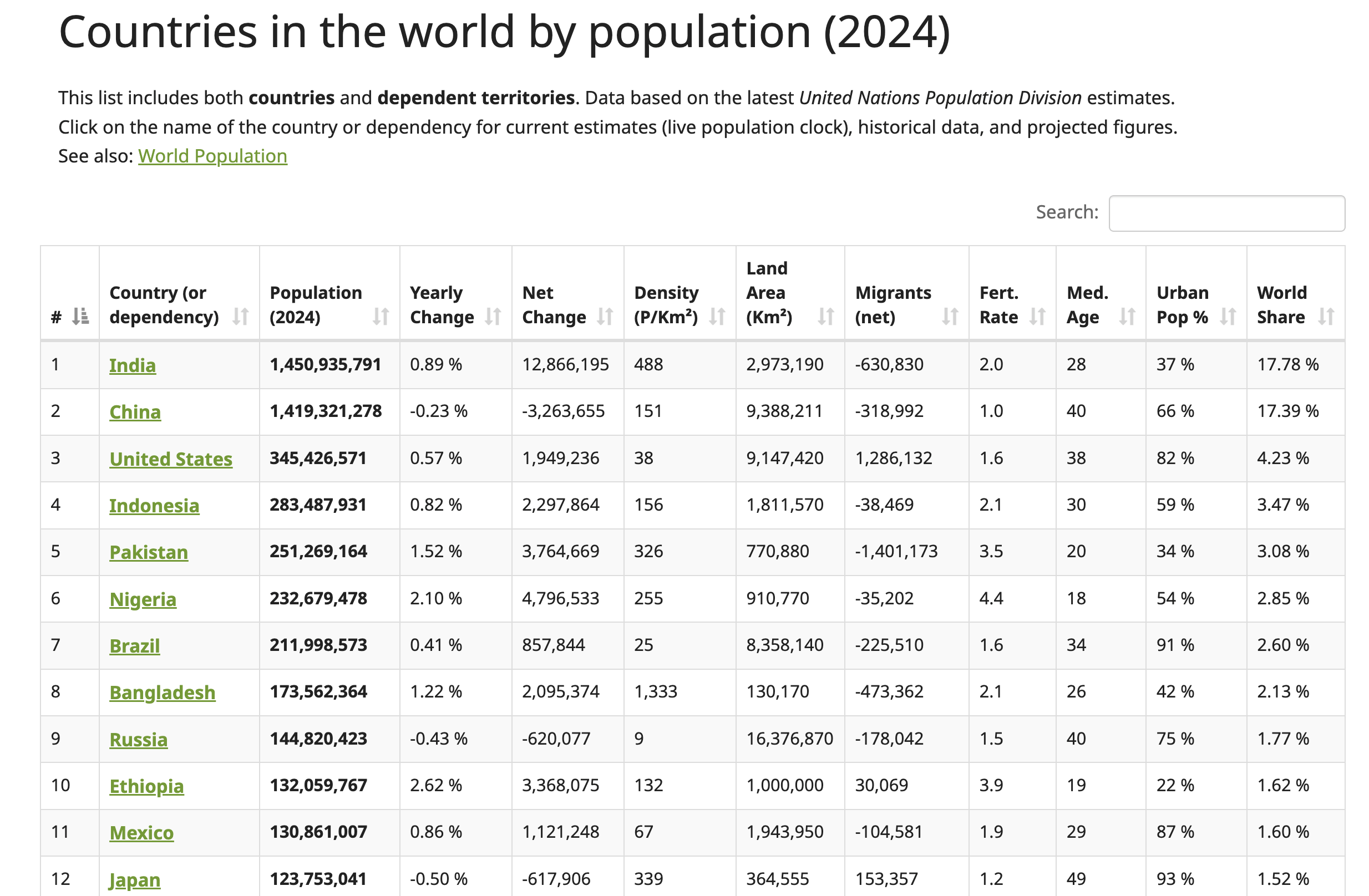
Para localizar a estrutura da tabela HTML, clique com o botão direito do mouse na tabela (mostrada na captura de tela anterior) e selecione Inspecionar. Essa ação abre o painel Ferramentas do desenvolvedor, que exibe o código HTML da página, com o elemento selecionado destacado:
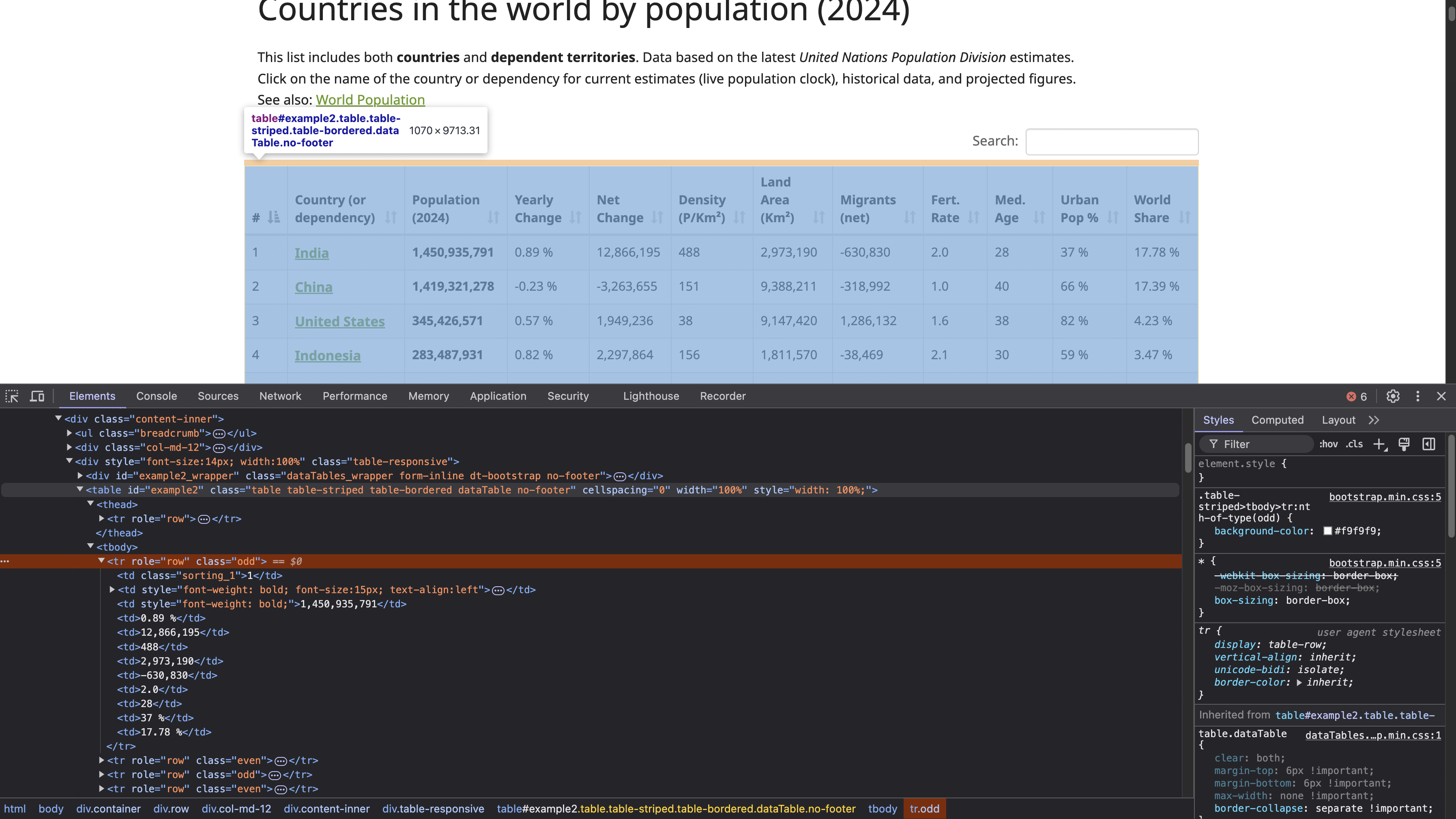
A tag <table> com ID example2 define o início da estrutura da tabela. Essa tabela tem cabeçalhos com as tags <th>, e as linhas são definidas pelas tags <tr>, com cada <tr> representando uma nova linha horizontal na tabela. Dentro de cada <tr>, a tag <td> cria células individuais dentro dessa linha, contendo os dados exibidos em cada célula.
Observação: antes de fazer qualquer raspagem, é importante que você revise e cumpra a política de privacidade e os termos de serviço do site para garantir que você siga todas as restrições sobre uso de dados e acesso automatizado.
Envie uma solicitação HTTP para acessar a página da web
Para enviar uma solicitação HTTP e acessar a página da web, crie um arquivo Python (por exemplo, html_table_scraper.py) e importe os pacotes requests, BeautifulSoup e pandas:
# importar pacotes
import requests
from bs4 import BeautifulSoup
import pandas as pd
Em seguida, defina a URL da página da web que você deseja extrair e envie uma solicitação GET para essa página da web usando https://www.worldometers.info/world-population/population-by-country/:
# Enviar uma solicitação ao site para obter o conteúdo da página
url = 'https://www.worldometers.info/world-population/population-by-country/'
Para verificar se a resposta foi bem-sucedida ou não, envie uma solicitação usando o método get() do Requests:
# Obter o conteúdo da URL
response = requests.get(url)
# Verificar o status da resposta.
if response.status_code == 200:
print("A solicitação foi bem-sucedida!")
else:
print(f"Erro: {response.status_code} - {response.text}")
Este código envia uma solicitação GET para uma URL especificada e, em seguida, verifica o status da resposta. Uma resposta 200 indica que a solicitação foi bem-sucedida.
Use o seguinte comando para executar o script Python no seu terminal:
python html_table_scraper.py
Sua saída deve ser semelhante a esta:
A solicitação foi bem-sucedida!
Como a solicitação GET foi bem-sucedida, agora você tem o conteúdo HTML de toda a página da web, incluindo a tabela HTML.
Parsing do HTML usando o Beautiful Soup
O Beautiful Soup pode lidar com conteúdo HTML mal formatado ou corrompido, o que é comum ao scraping de dados. Aqui, você usa o pacote Beautiful Soup para fazer o seguinte:
- Parsing do conteúdo HTML da página da web para encontrar a tabela que apresenta os dados populacionais.
- Colete os cabeçalhos da tabela.
- Colete todos os dados apresentados nas linhas da tabela.
Para analisar o conteúdo coletado, crie um objeto Beautiful Soup:
# Analise o conteúdo HTML usando BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
Em seguida, localize o elemento da tabela no HTML com o atributo id “example2”. Essa tabela contém a população dos países em 2024:
# Encontre a tabela que contém os dados populacionais
table = soup.find('table', attrs={'id': 'example2'})
Colete os cabeçalhos da tabela
A tabela tem um cabeçalho localizado nas tags HTML <thead> e <th>. Use o método find() do pacote Beautiful Soup para extrair os dados na tag <thead> e o método find_all() para coletar todos os cabeçalhos:
# Colete os cabeçalhos da tabela
headers = []
# Localize a linha do cabeçalho dentro da tag <thead>
header_row = table.find('thead').find_all('th')
for th in header_row:
# Adicione o texto do cabeçalho à lista de cabeçalhos
headers.append(th.text.strip())
Este código cria uma lista Python vazia chamada cabeçalhos, localiza a tag HTML <thead> para encontrar todos os cabeçalhos dentro das tags HTML <th> e, em seguida, acrescenta cada cabeçalho coletado à lista de cabeçalhos.
Coletar dados da linha da tabela
Para coletar os dados em cada linha, crie uma lista Python vazia chamada data para armazenar os dados coletados:
# Inicialize uma lista vazia para armazenar nossos dados
data = []
Em seguida, extraia os dados em cada linha da tabela usando o método find_all() e acrescente-os à lista Python:
# Percorra cada linha da tabela (ignorando a linha do cabeçalho)
for tr in table.find_all('tr')[1:]:
# Crie uma lista dos dados da linha atual
row = []
# Encontre todas as células de dados na linha atual
for td in tr.find_all('td'):
# Obtenha o conteúdo de texto da célula e remova espaços extras
cell_data = td.text.strip()
# Adicione os dados da célula limpos à lista de linhas
row.append(cell_data)
# Depois de obter todas as células desta linha, adicione a linha à nossa lista de dados
data.append(row)
# Converta os dados coletados em um DataFrame pandas para facilitar o manuseio
df = pd.DataFrame(data, columns=headers)
# Imprima o DataFrame para ver o número de linhas e colunas
print(df.shape)
Este código itera por todas as tags HTML <tr> encontradas na tabela, começando pela segunda linha (ignorando a linha do cabeçalho). Para cada linha (<tr>), uma linha de lista vazia é criada para armazenar os dados das células dessa linha. Dentro da linha, o código encontra todas as tags HTML <td> usando o método find_all(), representando células de dados individuais na linha.
Para cada tag HTML <td>, o código extrai o conteúdo do texto usando o atributo .texte aplica o método .strip() para remover qualquer espaço em branco à esquerda ou à direita do texto. Os dados limpos da célula são anexados à lista de linhas. Depois de processar todas as células da linha atual, a linha inteira é anexada à lista de dados. Por fim, você converte os dados coletados em um DataFrame do pandas com os nomes das colunas definidos pela lista de cabeçalhos e, em seguida, mostra a forma dos dados.
O script Python completo deve ficar assim:
# Importar pacotes
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Enviar uma solicitação ao site para obter o conteúdo da página
url = 'https://www.worldometers.info/world-population/population-by-country/'
# Obter o conteúdo da URL
response = requests.get(url)
# Verificar se a solicitação foi bem-sucedida
if response.status_code == 200:
# Analisar o conteúdo HTML usando Beautiful Soup
soup = BeautifulSoup(response.content, 'html.parser')
# Localizar a tabela que contém os dados populacionais por seu ID
table = soup.find('table', attrs={'id': 'example2'})
# Colete os cabeçalhos da tabela
headers = []
# Localize a linha do cabeçalho dentro da tag HTML <thead>
header_row = table.find('thead').find_all('th')
for th in header_row:
# Adicione o texto do cabeçalho à lista de cabeçalhos
headers.append(th.text.strip())
# Inicializar uma lista vazia para armazenar nossos dados
data = []
# Percorrer cada linha da tabela (ignorando a linha do cabeçalho)
para tr em table.find_all('tr')[1:]:
# Criar uma lista dos dados da linha atual
row = []
# Encontre todas as células de dados na linha atual
para td em tr.find_all('td'):
# Obtenha o conteúdo de texto da célula e remova espaços extras
cell_data = td.text.strip()
# Adicione os dados da célula limpos à lista de linhas
row.append(cell_data)
# Depois de obter todas as células desta linha, adicione a linha à nossa lista de dados
data.append(row)
# Converta os dados coletados em um DataFrame pandas para facilitar o manuseio
df = pd.DataFrame(data, columns=headers)
# Imprima o DataFrame para ver os dados coletados
print(df.shape)
else:
print(f"Erro: {response.status_code} - {response.text}")
Use o seguinte comando para executar o script Python no seu terminal:
python html_table_scraper.py
Sua saída deve ser semelhante a esta:
(234,12)
Neste ponto, você extraiu com sucesso 234 linhas e 12 colunas da tabela HTML.
Em seguida, use o método head() do pandas e print() para visualizar as primeiras dez linhas dos dados extraídos:
print(df.head(10))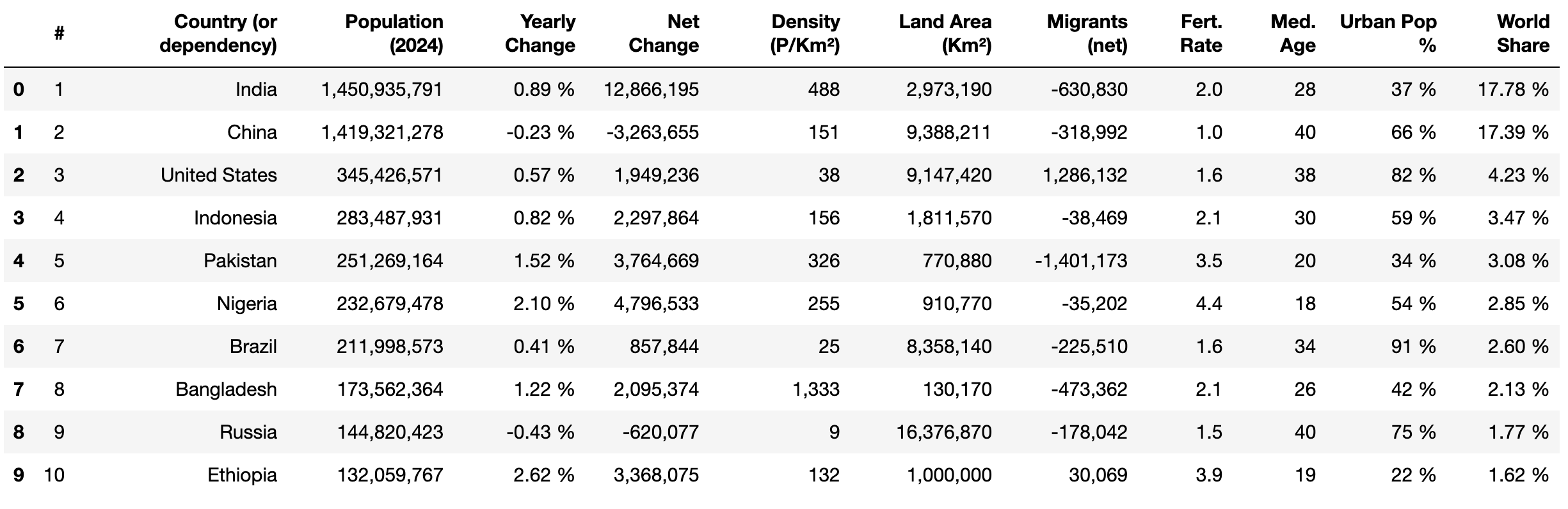
Limpe e estruture os dados
Ao extrair dados de uma tabela HTML, é importante limpá-los para garantir consistência, precisão e usabilidade adequada para análise. Os dados brutos extraídos de uma tabela HTML podem conter vários problemas, como valores ausentes, problemas de formatação, caracteres indesejados ou tipos de dados incorretos. Esses problemas podem levar a análises imprecisas e resultados não confiáveis. A limpeza adequada ajuda a padronizar o conjunto de dados e garante que ele esteja alinhado com a estrutura pretendida para análise.
Nesta seção, as seguintes tarefas de limpeza de dados são realizadas:
- Renomear nomes de colunas
- Substituir valores ausentes apresentados nos dados da linha
- Remover vírgulas e converter os tipos de dados para o formato correto
- Remover o sinal de porcentagem (%) e converter os tipos de dados para o formato correto
- Alterar os tipos de dados para colunas numéricas
Renomear nomes de colunas
O pandas possui um método chamado rename() que altera o nome de uma coluna específica para o que você desejar. Esse método é útil quando os nomes das colunas não são descritivos ou quando você deseja facilitar o trabalho com os nomes das colunas.
Para renomear uma coluna específica, você passa um dicionário para o parâmetro columns, onde as chaves são os nomes das colunas atuais e os valores são os novos nomes que você deseja atribuir. Aplique este método para alterar os seguintes nomes de colunas:
#paraClassificarVariação anualparaVariação anual %Participação mundialparaParticipação mundial %
# Renomear colunas
df.rename(columns={'#': 'Rank'}, inplace=True)
df.rename(columns={'Yearly Change': 'Yearly Change %'}, inplace=True)
df.rename(columns={'World Share': 'World Share %'}, inplace=True)
# Mostrar as primeiras 5 linhas
print(df.head())
Suas colunas agora devem estar assim:

Substitua valores ausentes
Os valores ausentes nos dados podem afetar cálculos, como médias ou somas, levando a resultados imprecisos e insights incorretos. Você precisa removê-los, substituí-los ou preenchê-los com valores específicos antes de fazer qualquer cálculo ou análise no conjunto de dados.
A coluna Urban Pop % contém atualmente valores ausentes rotulados como N.A.. Substitua N.A. por 0% usando o método replace() do pandas desta forma:
# Substitua 'N.A.' por '0%' na coluna 'Urban Pop %'
df['Urban Pop %'] = df['Urban Pop %'].replace('N.A.', '0%')
Remova os sinais de porcentagem e converta os tipos de dados
As colunas Yearly Change %, Urban Pop % e World Share % contêm valores numéricos seguidos por um sinal de porcentagem (por exemplo, 37,0%). Isso dificulta a realização de operações matemáticas, como o cálculo da média, do máximo e do desvio padrão, para análise.
Para corrigir isso, você pode aplicar o método replace() para remover o sinal % e, em seguida, aplicar o método astype() para convertê-los em um tipo de dados float para análise:
# Remova o sinal '%' e converta para float
df['Variação anual %'] = df['Variação anual %'].replace('%', '', regex=True).astype(float)
df['População urbana %'] = df['População urbana %'].replace('%', '', regex=True).astype(float)
df['World Share %'] = df['World Share %'].replace('%', '', regex=True).astype(float)
# Mostrar as primeiras 5 linhas
df.head()
Este código remove o sinal % dos valores nas colunas Variação anual %, População urbana % e Participação mundial % usando o método replace() com uma expressão regular. Em seguida, ele converte os valores limpos para um tipo de dados float usando astype(float). Por fim, ele exibe as cinco primeiras linhas do DataFrame com df.head().
Sua saída deve ficar assim:

Remover vírgulas e converter tipos de dados
Atualmente, as colunas População (2024), Variação líquida, Densidade (P/Km²), Área territorial (Km²) e Migrantes (líquidos) contêm valores numéricos com vírgulas (por exemplo, 1.949.236). Isso impossibilita a realização de operações matemáticas para análise.
Para corrigir isso, você pode aplicar replace() e astype() para remover vírgulas e converter os números para o tipo de dados inteiros:
# Remover vírgulas e converter para inteiros
columns_to_convert = [
'População (2024)', 'Variação líquida', 'Densidade (P/Km²)', 'Área territorial (Km²)',
'Migrantes (líquidos)'
]
para coluna em columns_to_convert:
# Certifique-se de que a coluna seja tratada como uma string primeiro
df[coluna] = df[coluna].astype(str)
# Remova as vírgulas
df[coluna] = df[coluna].str.replace(',', '')
# Converta para inteiros
df[coluna] = df[coluna].astype(int)
Este código define uma lista, columns_to_convert, contendo os nomes das colunas que precisam ser processadas. Para cada coluna da lista, ele garante que os valores da coluna sejam tratados como strings usando astype(str). Em seguida, remove todas as vírgulas dos valores usando str.replace(',', ''), e converte os valores limpos em inteiros com astype(int), tornando os valores adequados para operações matemáticas.
Alterar tipos de dados para colunas numéricas
As colunas Rank, Med. Age e Fert. Rate apresentam dados que são armazenados como um tipo de dados objeto, mas contêm valores numéricos. Converta os dados nessas colunas para tipos de dados inteiros ou flutuantes para permitir operações matemáticas:
# Converter para tipos de dados inteiros ou flutuantes e inteiros
df['Rank'] = df['Rank'].astype(int)
df['Med. Age'] = df['Med. Age'].astype(int)
df['Fert. Rate'] = df['Fert. Rate'].astype(float)
Este código converte os valores nas colunas Rank e Med. Age em um tipo de dados inteiro e os valores em Fert. Rate em um tipo de dados flutuante.
Por fim, verifique se os dados limpos têm os tipos de dados corretos usando o método head():
print(df.head(10))
Sua saída deve ficar assim:
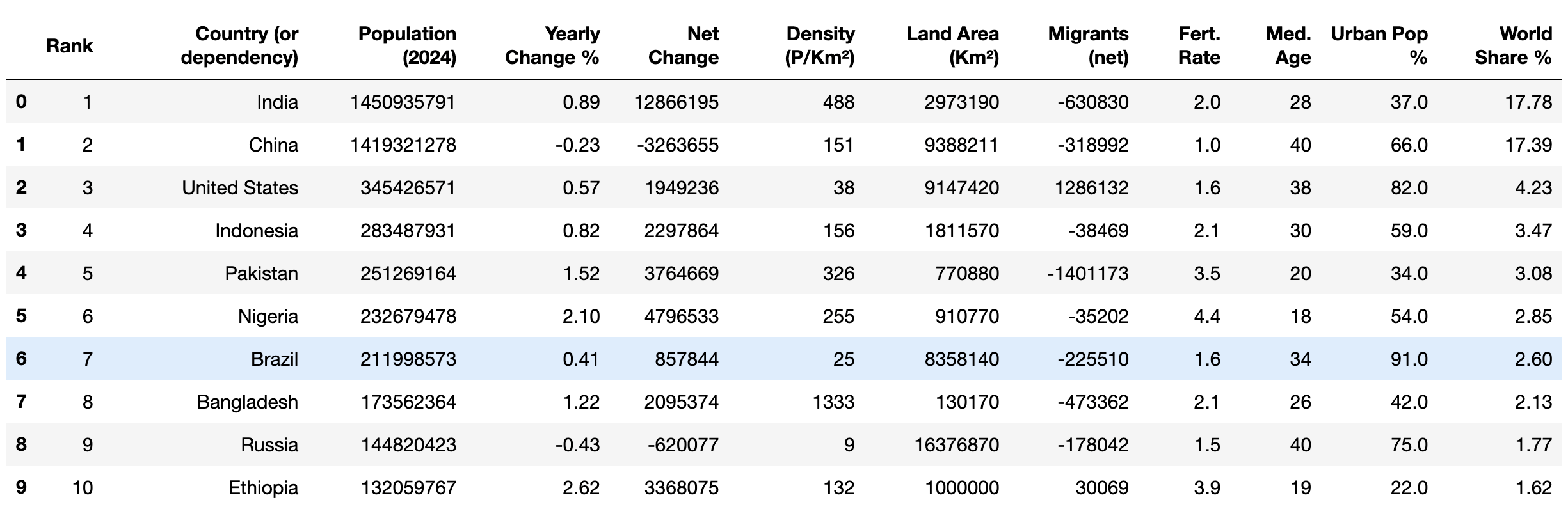
Com os dados agora limpos, você pode começar a aplicar diferentes operações matemáticas, comomédia e moda, bem como métodos analíticos, comocorrelação, para examinar os dados.
Exportar dados limpos para CSV
Após limpar seus dados, é importante salvá-los para uso e análise futuros. Você pode exportar os dados limpos para um arquivo CSV, o que permite compartilhá-los facilmente com outras pessoas ou processá-los/analisá-los ainda mais usando diferentes ferramentas e softwares compatíveis.
O método to_csv() no pandas permite exportar os dados de um DataFrame para um arquivo CSV chamado world_population_by_country.csv:
# Salve os dados em um arquivo
filename = 'world_population_by_country.csv'
df.to_csv(filename, index=False)
Conclusão
O pacote Beautiful Soup Python permite que você faça Parsing de documentos HTML e extraia dados de uma tabela HTML. Neste artigo, você aprendeu como extrair, limpar e exportar dados para um arquivo CSV.
Embora este tutorial tenha sido simples, extrair dados de sites complexos pode ser difícil e demorado. Por exemplo, trabalhar com tabelas HTML paginadas ou estruturas aninhadas, nas quais os dados estão incorporados em elementos pai e filho, requer uma análise cuidadosa para entender o layout. Além disso, as estruturas dos sites podem mudar com o tempo, exigindo manutenção contínua do seu código e infraestrutura.
Para economizar tempo e facilitar as coisas, considere usar aAPI Bright Data Web Scraper. Essa ferramenta poderosa oferece uma solução de extração pré-construída, permitindo que você extraia dados de sites complexos com o mínimo de conhecimento técnico. A API automatiza a coleta de dados, lidando com desafios como conteúdo dinâmico, páginas renderizadas em JavaScript e verificação CAPTCHA.
Inscreva-se e comece seu teste gratuito da API Web Scraper!





