

O Etsy é um site notoriamente difícil de rastrear. Eles empregam uma variedade de táticas de bloqueio e têm um dos sistemas de bloqueio de bots mais sofisticados da web. Desde análises detalhadas de cabeçalhos até uma onda aparentemente interminável de CAPTCHAs, o Etsy é o pesadelo dos Scrapers da web em todo o mundo. Se você conseguir superar esses obstáculos, o Etsy se torna um site relativamente fácil de rastrear.
Se você conseguir fazer scraping do Etsy, terá acesso a uma grande quantidade de dados de pequenas empresas de um dos maiores mercados que a internet tem a oferecer. Acompanhe hoje e você estará fazendo scraping do Etsy como um profissional em pouco tempo. Vamos aprender como fazer scraping de todos os seguintes tipos de páginas do Etsy.
- Resultados de pesquisa
- Páginas de produtos
- Páginas da loja
Introdução
Python Requests e BeautifulSoup serão nossas ferramentas preferidas para este tutorial. Você pode instalá-las com os comandos abaixo. O Requests nos permite fazer solicitações HTTP e nos comunicar com os servidores do Etsy. O BeautifulSoup nos dá o poder de analisar as páginas da web usando Python. Sugerimos que você leia primeiro nosso guia sobre como usar o BeautifulSoup para Scraping de dados na web.
Instalar Requests
pip install requests
Instale o BeautifulSoup
pip install beautifulsoup4
O que extrair do Etsy
Se você inspecionar uma página do Etsy, poderá se deparar com uma rede complexa de elementos aninhados. Se você souber onde procurar, isso será fácil de resolver. As páginas do Etsy usam dados JSON para renderizar a página no navegador. Se você conseguir encontrar o JSON, poderá encontrar todos os dados usados para construir a página… sem precisar se aprofundar muito no HTML do documento.
Resultados da pesquisa
As páginas de pesquisa do Etsy contêm uma matriz de objetos JSON. Se você observar a imagem abaixo, todos esses dados vêm dentro de um elemento de script com type="application/ld+json". Se você olhar com atenção, esses dados JSON contêm uma matriz chamada itemListElement. Se conseguirmos extrair essa matriz, obteremos todos os dados usados para construir a página.
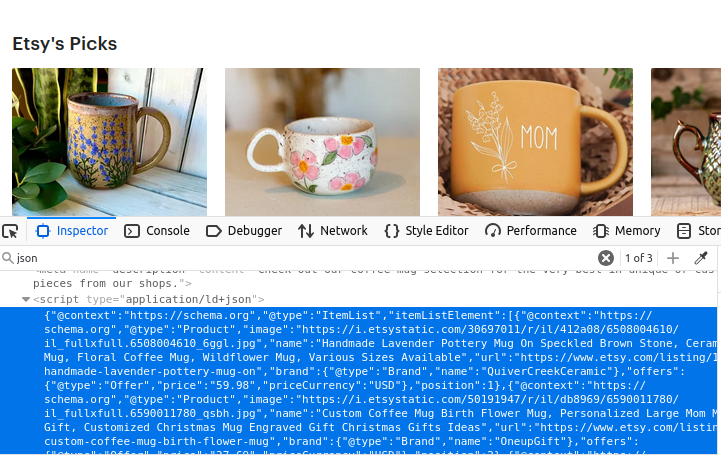
Informações do produto
As páginas de produtos não são muito diferentes. Observe a imagem abaixo: mais uma vez, temos uma tag de script com type="application/ld+json". Essa tag contém todas as informações usadas para criar a página do produto.
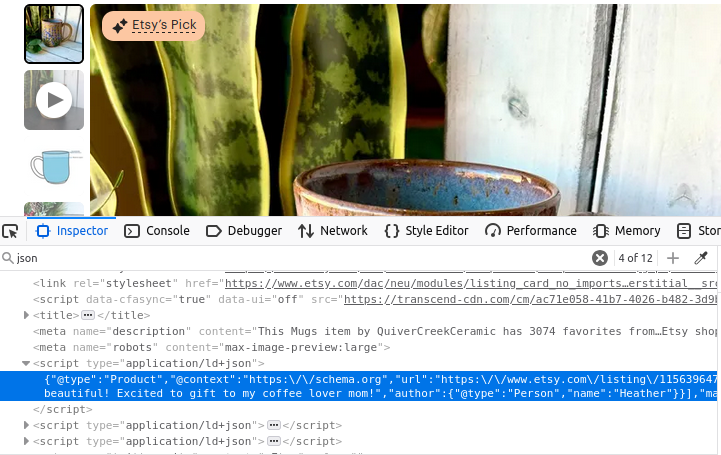
Lojas
Você provavelmente adivinhou, nossas páginas de lojas também são criadas da mesma maneira. Encontre o primeiro objeto script na página com type="application/ld+json" e você terá seus dados.
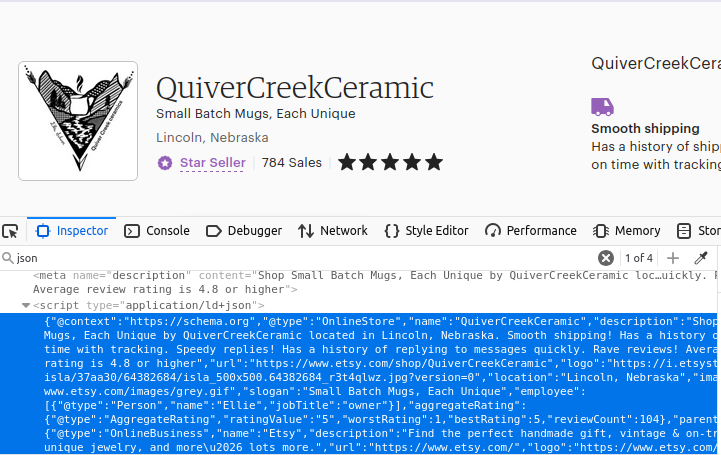
Como extrair dados do Etsy com Python
Agora, vamos examinar todos os componentes necessários que precisamos construir. Como mencionado anteriormente, o Etsy emprega uma variedade de táticas para nos impedir de acessar o site. Usamos o Web Unlocker como um canivete suíço para esses bloqueios. Ele não apenas gerencia conexões Proxy para nós, mas também realiza a resolução de CAPTCHA para todos os CAPTCHAs que aparecem em nosso caminho. Você pode tentar sem um Proxy, mas em nossos testes iniciais, não conseguimos passar pelos sistemas de bloqueio do Etsy sem o Web Unlocker.
Depois de obter uma instância do Web Unlocker, você pode configurar sua conexão Proxy criando um dicionário simples. Usamos o certificado SSL da Bright Data para garantir que nossos dados permaneçam criptografados durante o trânsito. No código abaixo, especificamos o caminho para o nosso certificado SSL e, em seguida, usamos nosso nome de usuário, nome da zona e senha para criar a URL do Proxy. Nossos proxies são criados através da construção de uma URL personalizada que encaminha todas as nossas solicitações através de um dos serviços de Proxy da Bright Data.
path_to_cert = "bright-data-cert.crt"
proxies = {
'http': 'http://brd-customer-<SEU-NOME-DE-USUÁRIO>-zone-<SEU-NOME-DE-ZONA>:<SUA-SENHA>@brd.superproxy.io:33335',
'https': 'http://brd-customer-<SEU-NOME-DE-USUÁRIO>-zone-<NOME-DA-SUA-ZONA>:<SUA-SENHA>@brd.superproxy.io:33335'
}
Resultados da pesquisa
Para extrair nossos resultados de pesquisa, fazemos uma solicitação usando nossos Proxies. Em seguida, usamos o BeautifulSoup para analisar o documento HTML recebido. Encontramos os dados dentro da tag de script e os carregamos como um objeto JSON. Em seguida, retornamos o campo itemListElement do JSON.
def etsy_search(palavra-chave):
palavra-chave-codificada = urlencode({"q": palavra-chave})
url = f"https://www.etsy.com/search?{palavra-chave-codificada}"
resposta = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
full_json = json.loads(script.text)
return full_json["itemListElement"]
Informações do produto
Nossas informações sobre o produto são extraídas basicamente da mesma maneira. A única diferença real é a ausência do itemListElement. Desta vez, usamos nosso listing_id para criar nossa url e extraímos todo o objeto JSON.
def etsy_product(listing_id):
url = f"https://www.etsy.com/listing/{listing_id}/"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
return json.loads(script.text)
Lojas
Ao extrair lojas, seguimos o mesmo modelo que usamos com produtos. Usamos o nome da loja para construir a URL. Depois de obtermos a resposta, encontramos o JSON, carregamos como JSON e retornamos os dados extraídos da página.
def etsy_shop(shop_name):
url = f"https://www.etsy.com/shop/{shop_name}"
response = requests.get(url, proxies=proxies, verify=path_to_cert)
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
return json.loads(script.text)
Armazenando os dados
Nossos dados são estruturados em JSON assim que os extraímos. Podemos gravar nossa saída em um arquivo usando o manuseio básico de arquivos do Python e json.dumps(). Nós o gravamos com indent=4 para que fique limpo e legível quando as pessoas olharem para o arquivo.
com open("products.json", "w") como arquivo:
json.dump(produtos, arquivo, indent=4)
Juntando tudo
Agora que sabemos como construir nossas peças, vamos juntar tudo. O código abaixo usa as funções que acabamos de escrever e retorna nossos dados desejados no formato JSON. Em seguida, gravamos cada um desses objetos em seus próprios arquivos JSON individuais.
import requests
import json
from bs4 import BeautifulSoup
from urllib.parse import urlencode
# Configuração de Proxy e certificado (CREDENCIAS CODIFICADAS)
path_to_cert = "bright-data-cert.crt"
proxies = {
'http': 'http://brd-customer-<SEU-NOME-DE-USUÁRIO>-zone-<SEU-NOME-DE-ZONA>:<SUA-SENHA>@brd.superproxy.io:22225',
'https': 'http://brd-customer-<SEU-NOME-DE-USUÁRIO>-zone-<NOME-DA-SUA-ZONA>:<SUA-SENHA>@brd.superproxy.io:22225'
}
def fetch_etsy_data(url):
"""Busca e analisa dados JSON-LD de uma página do Etsy."""
tente:
resposta = solicitações.get(url, proxies=proxies, verificar=path_to_cert)
resposta.raise_for_status()
exceto solicitações.exceptions.RequestException como e:
imprimir(f"Falha na solicitação: {e}")
retornar Nenhum
soup = BeautifulSoup(response.text, "html.parser")
script = soup.find("script", attrs={"type": "application/ld+json"})
if not script:
print("Script JSON-LD não encontrado na página.")
return None
tente:
retorne json.loads(script.text)
exceto json.JSONDecodeError como e:
imprima(f"Erro de Parsing JSON: {e}")
retorne None
def etsy_search(palavra-chave):
"""Pesquise no Etsy por uma determinada palavra-chave e retorne os resultados."""
encoded_keyword = urlencode({"q": palavra-chave})
url = f"https://www.etsy.com/search?{encoded_keyword}"
data = fetch_etsy_data(url)
retorne data.get("itemListElement", []) se data, caso contrário, None
def etsy_product(listing_id):
"""Buscar detalhes do produto em uma lista do Etsy."""
url = f"https://www.etsy.com/listing/{listing_id}/"
return fetch_etsy_data(url)
def etsy_shop(shop_name):
"""Busca detalhes da loja a partir de uma página da loja Etsy."""
url = f"https://www.etsy.com/shop/{shop_name}"
return fetch_etsy_data(url)
def save_to_json(data, filename):
"""Salvar dados em um arquivo JSON com tratamento de erros."""
tente:
com open(nome_do_arquivo, "w", codificação="utf-8") como arquivo:
json.dump(dados, arquivo, indent=4, ensure_ascii=False, default=str)
imprima(f"Dados salvos com sucesso em {nome_do_arquivo}")
exceto (IOError, TypeError) como e:
imprimir(f"Erro ao salvar dados em {nome_do_arquivo}: {e}")
se __name__ == "__main__":
# Pesquisa de produto
produtos = etsy_search("caneca de café")
se produtos:
salvar_em_json(produtos, "produtos.json")
# Item específico
item_info = etsy_product(1156396477)
if item_info:
save_to_json(item_info, "item.json")
# Loja Etsy
shop = etsy_shop("QuiverCreekCeramic")
if shop:
save_to_json(shop, "shop.json")
Abaixo estão alguns dados de exemplo do products.json.
{
"@context": "https://schema.org",
"@type": "Product",
"image": "https://i.etsystatic.com/34923795/r/il/8f3bba/5855230678/il_fullxfull.5855230678_n9el.jpg",
"name": "Caneca de café personalizada com foto, xícara de café com imagem personalizada, caneca de aniversário para presente para ele/ela, caneca personalizável com logotipo e texto para homens e mulheres",
"url": "https://www.etsy.com/listing/1193808036/custom-coffee-mug-with-photo",
"brand": {
"@type": "Brand",
"name": "TheGiftBucks"
},
"offers": {
"@type": "Offer",
"price": "14,99",
"priceCurrency": "USD"
},
"position": 1
},
Considere usar Conjuntos de datos
Nossos conjuntos de dados oferecem uma ótima alternativa ao Scraping de dados. Você pode comprar conjuntos de dados prontos para uso do Etsy ou um de nossos outros conjuntos de dados de comércio eletrônico e eliminar totalmente o processo de Scraping de dados! Depois de criar uma conta, acesse nosso mercado de conjuntos de dados.
Digite “Etsy” e clique no conjunto de dados Etsy.

Isso lhe dará acesso a milhões de registros de dados do Etsy… ao alcance dos seus dedos. Você pode até baixar dados de amostra para ver como é trabalhar com eles.
Conclusão
Neste tutorial, exploramos a extração de dados do Etsy em detalhes. Você recebeu um curso intensivo sobre integração de Proxy. Você sabe como usar o Web Unlocker para contornar até mesmo os bloqueadores de bots mais rigorosos. Você sabe como extrair os dados e também como armazená-los. Você também teve uma amostra de nossos Conjuntos de dados pré-criados que eliminam completamente suas tarefas de extração de dados. Independentemente de como você obtém seus dados, nós temos a solução para você.
Inscreva-se agora e comece seu teste grátis.





