

Neste guia, você verá:
- Tudo o que você precisa saber para dar os primeiros passos com o scraping do DuckDuckGo.
- As abordagens mais populares e eficazes para Scraping de dados no DuckDuckGo.
- Como criar um Scraper personalizado do DuckDuckGo.
- Como usar a biblioteca DDGS para fazer scraping no DuckDuckGo.
- Como recuperar dados de resultados de mecanismos de pesquisa por meio da API SERP da Bright Data.
- Como fornecer dados de pesquisa do DuckDuckGo a um agente de IA por meio do MCP.
Vamos começar!
Introdução ao scraping do DuckDuckGo
O DuckDuckGo é um mecanismo de pesquisa que oferece proteção integrada contra rastreadores online. Os usuários apreciam sua política focada na privacidade, pois ele não rastreia pesquisas ou histórico de navegação. Dessa forma, ele se destaca das plataformas de pesquisa convencionais e tem visto um aumento constante no uso ao longo dos anos.
O mecanismo de pesquisa DuckDuckGo está disponível em duas variantes:
- Versão dinâmica: a versão padrão, que requer JavaScript e inclui recursos como“Search Assist”, uma alternativa às visões gerais da IA do Google.
- Versão estática: uma versão simplificada que funciona mesmo sem renderização JavaScript.
Dependendo da versão escolhida, serão necessárias diferentes abordagens de scraping, conforme descrito nesta tabela resumida:
| Recurso | Versão SERP dinâmica | Versão SERP estática |
|---|---|---|
| JavaScript necessário | Sim | Não |
| Formato da URL | https://duckduckgo.com/?q=<SEARCH_QUERY> |
https://html.duckduckgo.com/html/?q=<SEARCH_QUERY> |
| Conteúdo dinâmico | Sim, como resumos de IA e elementos interativos | Não |
| Paginação | Complexa, com base no botão “Mais resultados” | Simples, por meio de um botão tradicional “Próximo” com recarga da página |
| Abordagem de scraping | Ferramentas de automação do navegador | Cliente HTTP + analisador HTML |
É hora de explorar as implicações do scraping para as duas versões da SERP (página de resultados do mecanismo de pesquisa) do DuckDuckGo!
DuckDuckGo: Versão SERP dinâmica
Por padrão, o DuckDuckGo carrega uma página da web dinâmica que requer renderização JavaScript, com uma URL como:
https://duckduckgo.com/?q=<SEARCH_QUERY>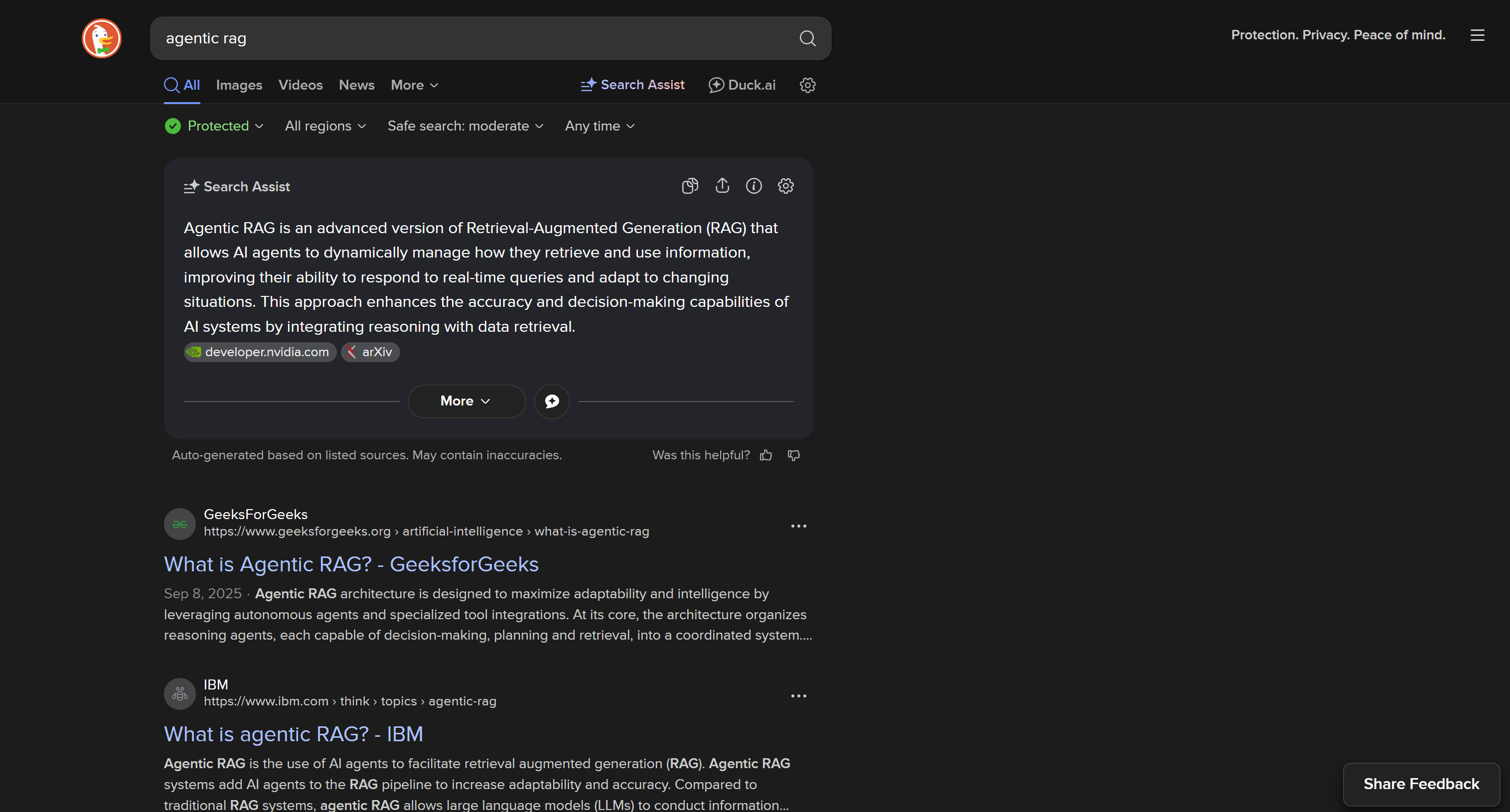
Esta versão inclui interações complexas do usuário na página, como o botão “Mais resultados” para carregar dinamicamente outros resultados:
A SERP dinâmica do DuckDuckGo vem com mais recursos e informações mais ricas, mas requer ferramentas de automação do navegador para o scraping. O motivo é que apenas um navegador pode renderizar páginas que dependem de JavaScript.
O problema é que controlar um navegador introduz complexidade adicional e uso de recursos. É por isso que a maioria dos Scrapers depende da versão estática do site!
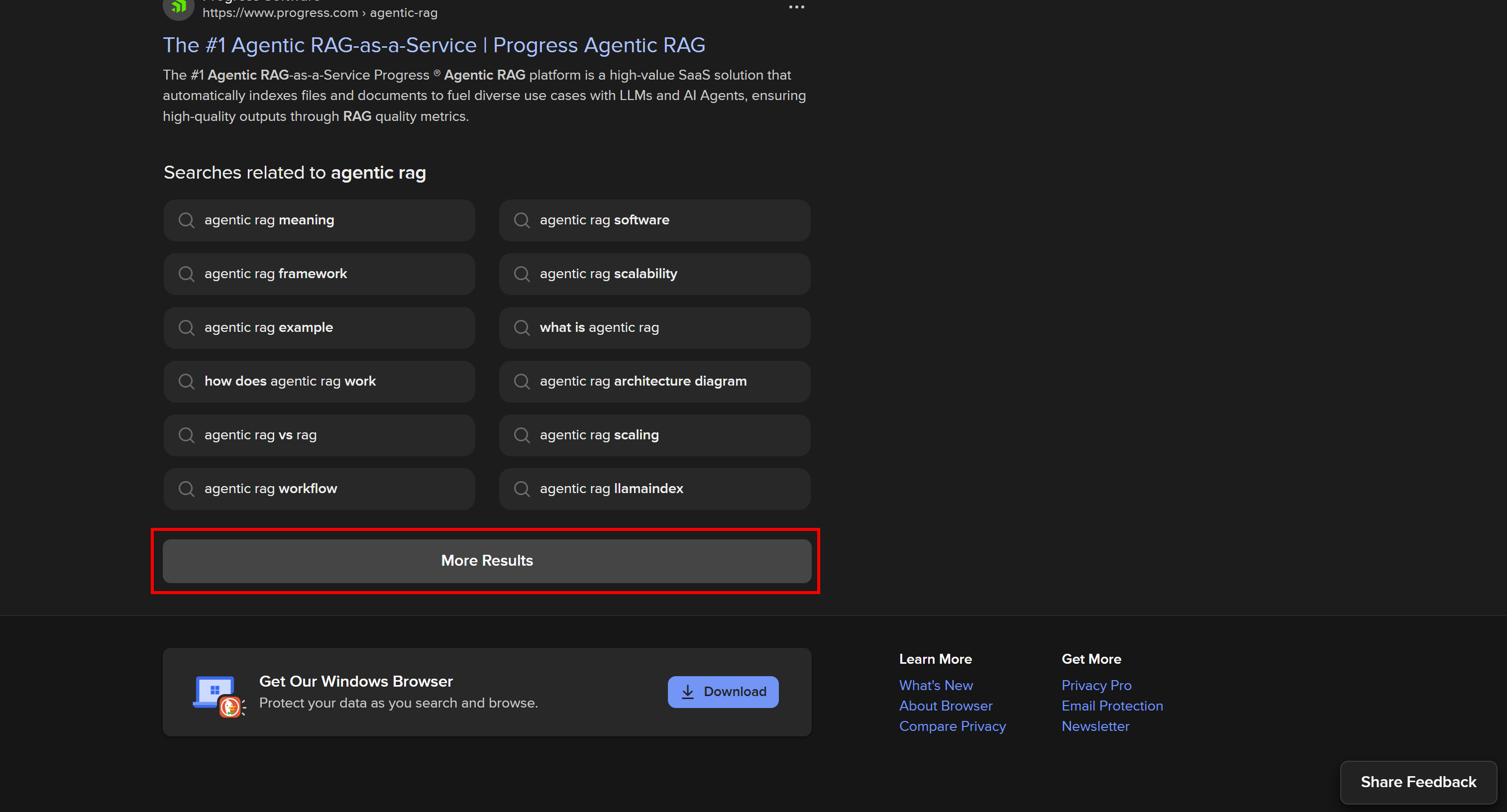
DuckDuckGo: versão estática do SERP
Para dispositivos que não suportam JavaScript, o DuckDuckGo também suporta uma versão estática de seus SERPs. Essas páginas seguem um formato de URL como abaixo:
https://html.duckduckgo.com/html/?q=<SEARCH_QUERY>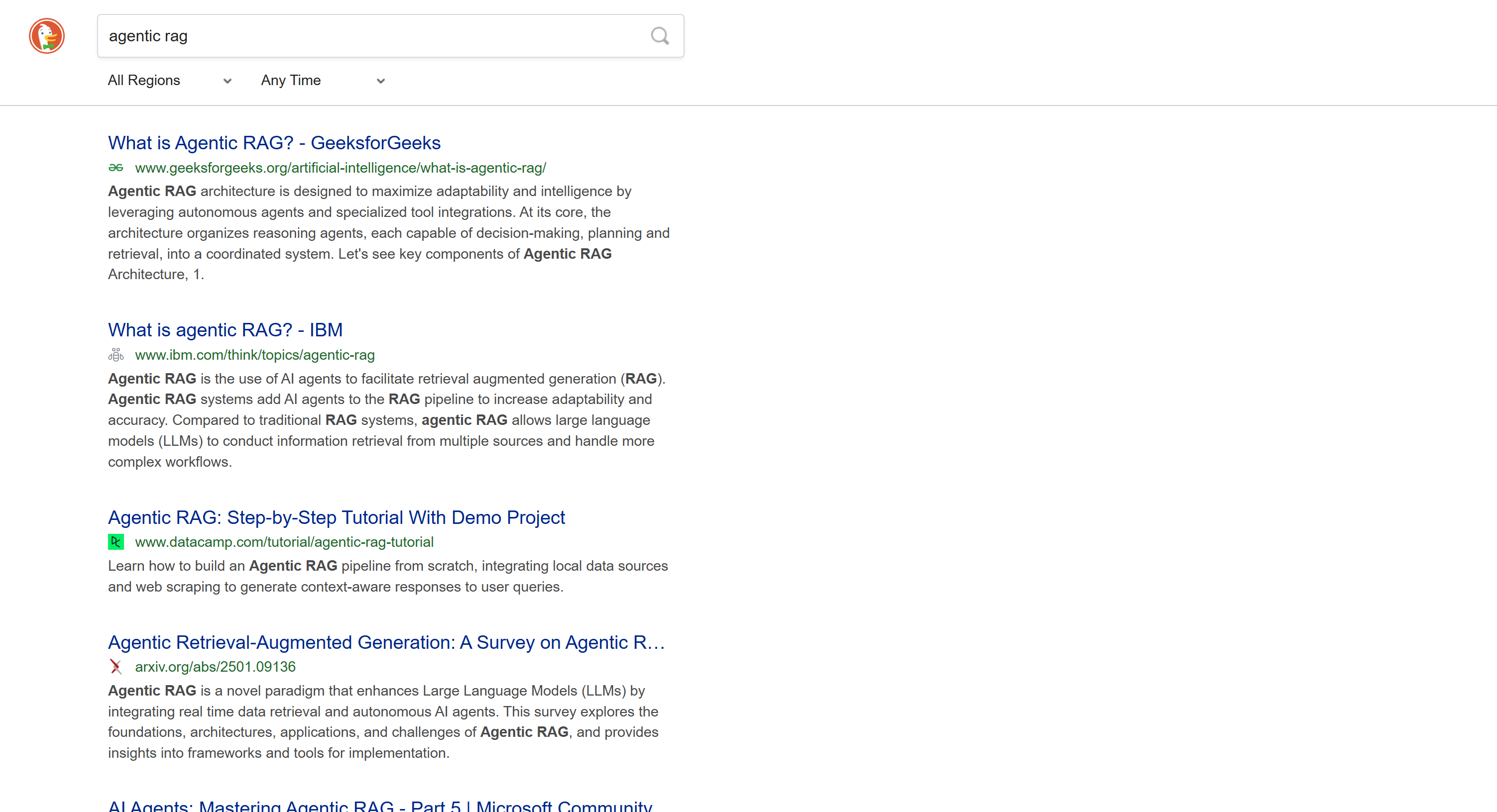
Essa versão não inclui conteúdo dinâmico, como o resumo gerado pela IA. Além disso, a paginação segue uma abordagem mais tradicional, com um botão “Próximo” que leva você para a próxima página:
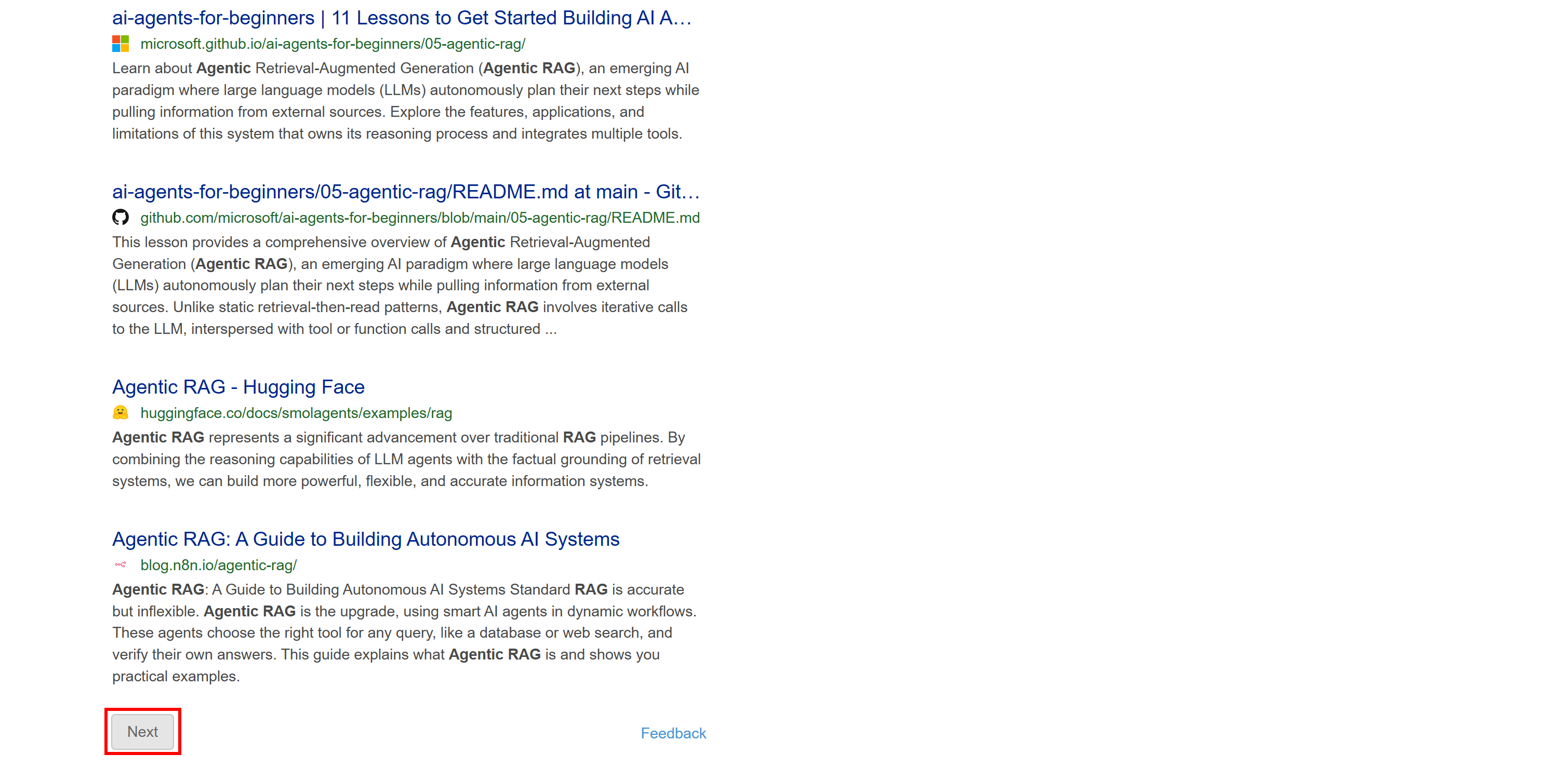
Como essa SERP é estática, você pode extraí-la usando uma abordagem tradicional de cliente HTTP + analisador HTML. Esse método é mais rápido, mais fácil de implementar e consome menos recursos.
Abordagens possíveis para extrair dados do DuckDuckGo
Confira as quatro abordagens possíveis para o Scraping de dados do DuckDuckGo que apresentaremos neste artigo:
| Abordagem | Complexidade da integração | Requer | Preço | Risco de bloqueios | Escalabilidade |
|---|---|---|---|---|---|
| Criar um Scraper personalizado | Médio/Alto | Conhecimentos de programação em Python | Gratuito (pode exigir proxies premium para evitar bloqueios) | Possível | Limitado |
| Depende de uma biblioteca de scraping do DuckDuckGo | Baixo | Conhecimentos de Python / uso de CLI | Gratuito (pode exigir proxies premium para evitar bloqueios) | Possível | Limitado |
| Use a API SERP da Bright Data | Baixo | Qualquer cliente HTTP | Pago | Nenhum | Ilimitado |
| Integrar o servidor Web MCP | Baixo | Estruturas/soluções de agentes de IA compatíveis com MCP | Nível gratuito disponível, depois pago | Nenhuma | Ilimitado |
Você aprenderá mais sobre cada um deles ao longo deste tutorial.
Independentemente da abordagem que você seguir, a consulta de pesquisa alvo nesta postagem do blog será “agentic rag”. Em outras palavras, você verá como recuperar os resultados de pesquisa do DuckDuckGo para essa consulta.
Vamos supor que você já tenha o Python instalado localmente e esteja familiarizado com ele.
Abordagem nº 1: criar um Scraper personalizado
Utilize uma ferramenta de automação de navegador ou um cliente HTTP combinado com um analisador HTML para criar um bot de Scraping de dados do DuckDuckGo do zero.
👍 Prós:
- Controle total sobre a lógica de scraping.
- Pode ser personalizado para extrair exatamente o que você precisa.
👎 Contras:
- Requer configuração e codificação.
- Pode encontrar bloqueios de IP se a extração for em grande escala.
Abordagem nº 2: Confie em uma biblioteca de raspagem do DuckDuckGo
Use uma biblioteca de scraping existente para o DuckDuckGo, como o DDGS (Duck Distributed Global Search), que oferece todas as funcionalidades necessárias sem precisar escrever uma única linha de código.
👍 Prós:
- Configuração mínima necessária.
- Lida com tarefas de scraping de mecanismos de pesquisa automaticamente, por meio de código Python ou comandos CLI simples.
👎 Contras:
- Menos flexibilidade em comparação com um Scraper personalizado, com controle limitado sobre casos de uso avançados.
- Ainda enfrenta bloqueios de IP.
Abordagem nº 3: Use a API SERP da Bright Data
Aproveite o endpoint premium da API SERP da Bright Data, que você pode chamar a partir de qualquer cliente HTTP. Ele oferece suporte a vários mecanismos de pesquisa, incluindo o DuckDuckGo. Ele lida com todas as complexidades para você, ao mesmo tempo em que fornece raspagem escalável e de alto volume.
👍 Prós:
- Escalabilidade ilimitada.
- Evita bloqueios de IP e medidas anti-bot.
- Integra-se com clientes HTTP em qualquer linguagem de programação ou mesmo com ferramentas visuais como o Postman.
👎 Contras:
- Serviço pago.
Abordagem nº 4: integrar o servidor Web MCP
Forneça ao seu agente de IA recursos de scraping do DuckDuckGo acessando a API SERP da Bright Data gratuitamente através do Bright Data Web MCP.
👍 Prós:
- Fácil integração com IA.
- Nível gratuito disponível.
- Fácil de usar em agentes de IA e fluxos de trabalho.
👎 Contras:
- Não é possível controlar totalmente os LLMs.
Abordagem nº 1: Crie um Scraper DuckDuckGo personalizado com Python
Siga as etapas abaixo para aprender a criar um script de scraping personalizado do DuckDuckGo em Python.
Observação: para um Parsing simplificado e rápido, usaremos a versão estática do DuckDuckGo. Se você estiver interessado em coletar “Assistências de Pesquisa” geradas por IA, leia nosso guia sobre como criar um scraper para resultados de visão geral de IA do Google. Você pode adaptá-lo facilmente ao DuckDuckGo.
Etapa 1: Configure seu projeto
Comece abrindo seu terminal e criando uma nova pasta para seu projeto de Scraper DuckDuckGo:
mkdir duckduckgo-ScraperA pasta duckduckgo-scraper/ conterá seu projeto de scraping.
Em seguida, navegue até o diretório do projeto e crie um ambiente virtual Python dentro dele:
cd duckduckgo-Scraper
python -m venv .venvAgora, abra a pasta do projeto em seu IDE Python preferido. Recomendamos o Visual Studio Code com a extensão Python ou o PyCharm Community Edition.
Crie um novo arquivo chamado scraper.py na raiz do diretório do seu projeto. A estrutura do seu projeto deve ficar assim:
duckduckgo-Scraper/
├── .venv/
└── agent.pyNo terminal, ative o ambiente virtual. No Linux ou macOS, execute:
source venv/bin/activateDe forma equivalente, no Windows, execute:
venv/Scripts/activateCom o ambiente virtual ativado, instale as dependências do projeto com:
pip install requests beautifulsoup4As duas bibliotecas necessárias são:
requests: Um popular cliente HTTP Python. Ele será usado para buscar a versão estática do SERP do DuckDuckGo.beautifulsoup4: uma biblioteca Python para Parsing de HTML, permitindo extrair dados da página de resultados do DuckDuckGo.
Ótimo! Seu ambiente de desenvolvimento Python agora está pronto para criar um script de scraping do DuckDuckGo.
Etapa 2: Conecte-se à página de destino
Comece importando requests em scraper.py:
import requestsEm seguida, execute uma solicitação GET semelhante à de um navegador para a versão estática do DuckDuckGo usando o método requests.get():
# URL base da versão estática do DuckDuckGo
base_url = "https://html.duckduckgo.com/html/"
# Exemplo de consulta de pesquisa
search_query = "agentic rag"
# Para simular uma solicitação do navegador e evitar erros 403
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
}
# Conecte-se à página SERP de destino
params = {
"q": search_query
}
response = requests.get(base_url, params=params, headers=headers)Se você não estiver familiarizado com essa sintaxe, consulte nosso guia sobre solicitações HTTP em Python.
O trecho acima enviará uma solicitação HTTP GET para https://html.duckduckgo.com/html/?q=agentic+rag (a SERP de destino deste tutorial) com o seguinte cabeçalho User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/140.0.0.0 Safari/537.36É necessário definir um User-Agent real como o acima para evitar receber erros 403 Forbidden do DuckDuckGo. Saiba mais sobre a importância do cabeçalho User-Agent no Scraping de dados.
O servidor responderá à solicitação GET com o HTML da página estática do DuckDuckGo. Acesse-a com:
html = response.textVerifique o conteúdo da página imprimindo-o:
print(html)Você deverá ver um HTML semelhante a este:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=3.0, user-scalable=1" />
<meta name="referrer" content="origin" />
<meta name="HandheldFriendly" content="true" />
<meta name="robots" content="noindex, nofollow" />
<title>agentic rag no DuckDuckGo</title>
<!-- Omitido por brevidade... -->
</head>
<!-- Omitido por brevidade... -->
<body>
<div>
<div class="serp__results">
<div id="links" class="results">
<div class="result results_links results_links_deep web-result">
<div class="links_main links_deep result__body">
<h2 class="result__title">
<a rel="nofollow" class="result__a"
href="//duckduckgo.com/l/?uddg=https%3A%2F%2Fwww.geeksforgeeks.org%2Fartificial%2Dintelligence%2Fwhat%2Dis%2Dagentic%2Drag%2F&rut=db125a181b0852a6be3a488cb8060da7f7359f97d50cdc2b70fd9cd4dd3d1df9">
O que é Agentic RAG? - GeeksforGeeks
</a>
</h2>
<!-- Omitido por brevidade... -->
</div>
</div>
<!-- Outros resultados ... -->
</div>
</div>
</div>
</body>
</html>Ótimo! Este HTML contém todos os links SERP que você está interessado em extrair.
Etapa 3: Parsing do HTML
Importe o Beautiful Soup no scraper.py:
from bs4 import BeautifulSoupEm seguida, use-o para realizar o Parsing da string HTML recuperada anteriormente em uma estrutura de árvore navegável:
soup = BeautifulSoup(html, "html.parser")Isso realiza o Parsing do HTML usando o "html.parser" integrado ao Python. Você também pode configurar outros analisadores, como lxml ou html5lib, conforme explicado em nosso guia de Scraping de dados do BeautifulSoup.
Muito bem! Agora você pode usar a API do BeautifulSoup para selecionar elementos HTML na página e extrair os dados necessários.
Etapa 4: Prepare-se para extrair todos os resultados da SERP
Antes de se aprofundar na lógica de scraping, você deve se familiarizar com a estrutura das SERPs do DuckDuckGo. Abra esta página da web no modo de navegação anônima (para garantir uma sessão limpa) no seu navegador:
https://html.duckduckgo.com/html/?q=agentic+ragEm seguida, clique com o botão direito do mouse em um elemento do resultado SERP e selecione a opção “Inspecionar” para abrir o DevTools do navegador:
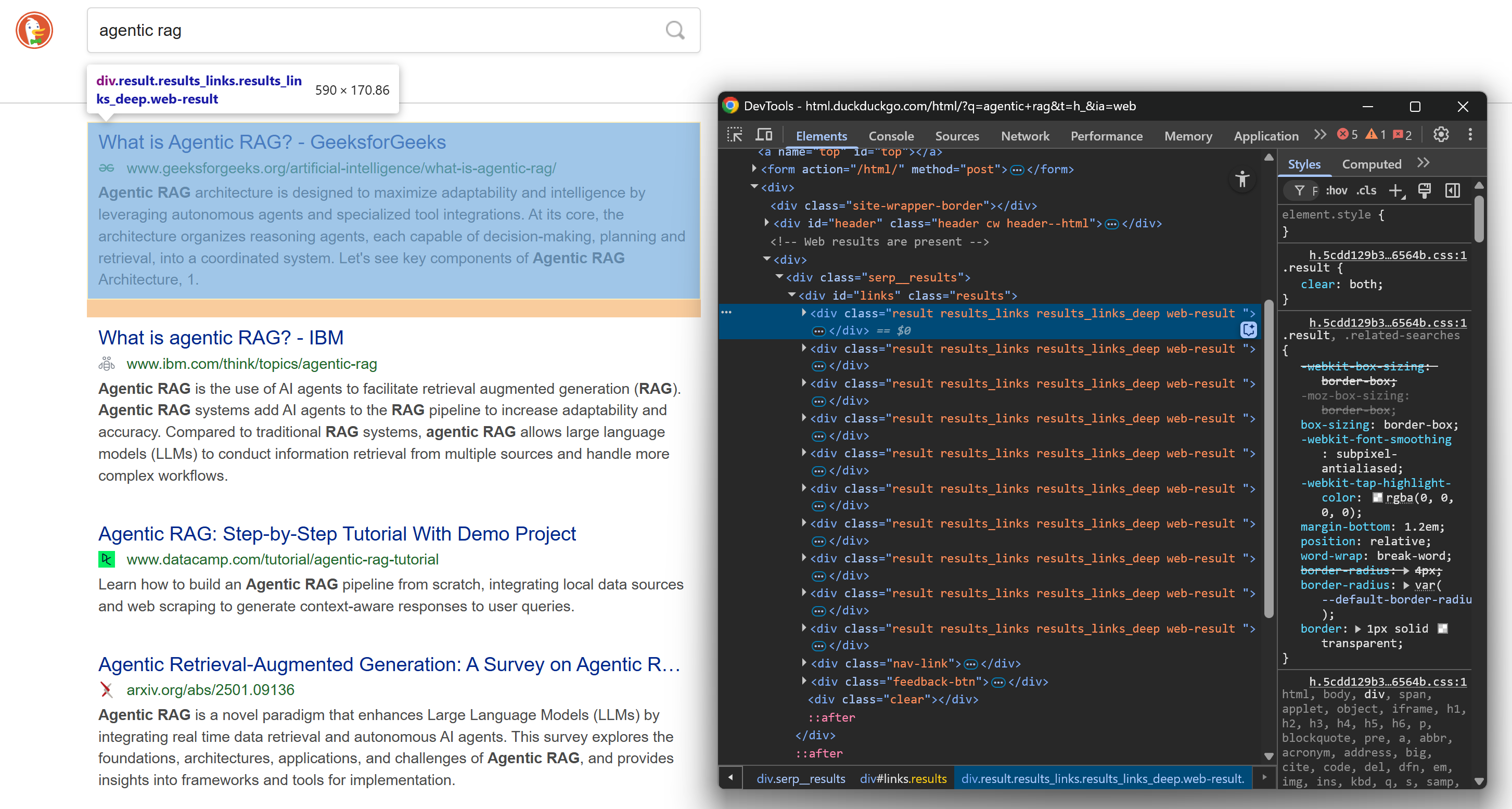
Dê uma olhada na estrutura HTML. Observe que cada elemento SERP tem a classe de resultado e está contido em um <div> identificado pelo ID dos links. Isso significa que você pode selecionar todos os elementos de resultado de pesquisa usando este seletor CSS:
#links .resultAplique esse seletor à página parsed com o método select() do Beautiful Soup:
result_elements = soup.select("#links .result") Como a página contém vários elementos SERP, você precisará de uma lista para armazenar os dados coletados. Inicialize uma lista assim:
serp_results = []Por fim, itere sobre cada elemento HTML selecionado. Prepare-se para aplicar sua lógica de coleta para extrair os resultados de pesquisa do DuckDuckGo e preencher a lista serp_results:
para result_element em result_elements:
# Lógica de Parsing de dados...Ótimo! Agora você está perto de atingir seu objetivo de extração do DuckDuckGo.
Etapa 5: extraia os dados dos resultados
Mais uma vez, inspecione a estrutura HTML de um elemento SERP na página de resultados:
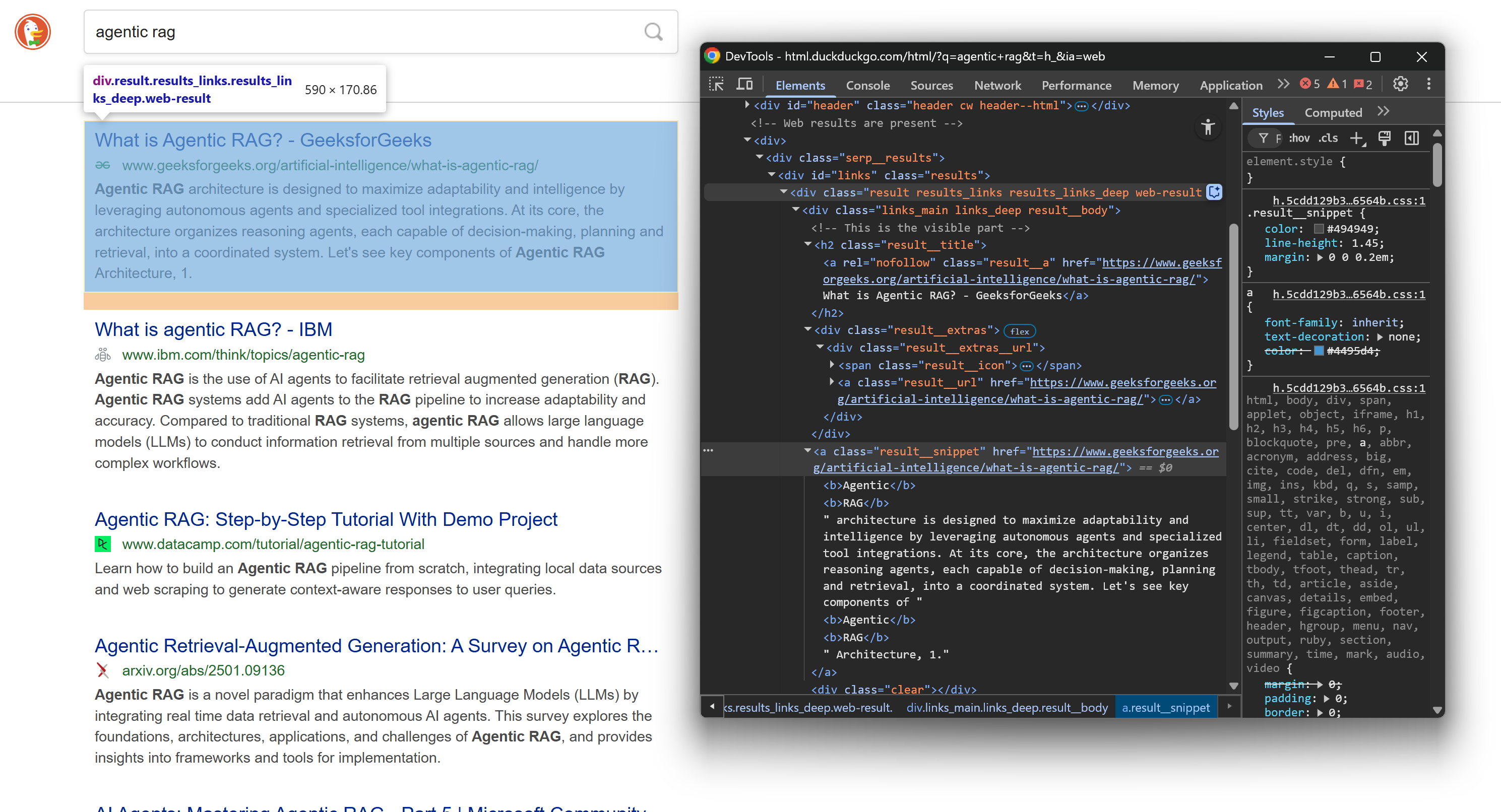
Desta vez, concentre-se nos seus nós HTML aninhados. Como você pode ver, a partir desses elementos, você pode extrair:
- Título do resultado do texto
.result__a - URL do resultado do atributo
.result__ahref - URL de exibição do texto
.result__url - Trecho/descrição do resultado a partir do texto
.result__snippet
Aplique o método select_one() do BeautifulSoup para selecionar o nó específico e, em seguida, use .get_text() para extrair o texto ou [<attribute_name>] para acessar um atributo HTML.
Implemente a lógica de scraping com:
title_element = result_element.select_one(".result__a")
url = "https:" + title_element["href"]
title = title_element.get_text(strip=True)
url_element = result_element.select_one(".result__url")
display_url = url_element.get_text(strip=True)
snippet_element = result_element.select_one(".result__snippet")
snippet = snippet_element.get_text(strip=True)Observação: strip=True é útil porque remove os espaços em branco à esquerda e à direita do texto extraído.
Se você está se perguntando por que precisa concatenar “https:” a title_element["href"], é porque o HTML retornado pelo servidor é ligeiramente diferente daquele renderizado no seu navegador. O HTML bruto, que o seu Scraper realmente analisa, contém URLs em um formato como este:
//duckduckgo.com/l/?uddg=https%3A%2F%2Fwww.geeksforgeeks.org%2Fartificial%2Dintelligence%2Fwhat%2Dis%2Dagentic%2Drag%2F&rut=db125a181b0852a6be3a488cb8060da7f7359f97d50cdc2b70fd9cd4dd3d1df9Como você pode ver, a URL começa com // em vez de incluir o esquema (https://). Ao adicionar “https:” no início, você garante que a URL se torne mais utilizável (fora dos navegadores, que também suportam esse formato).
Verifique você mesmo esse comportamento. Clique com o botão direito do mouse na página e escolha a opção “Exibir código-fonte da página”. Isso mostrará o documento HTML bruto retornado pelo servidor (sem qualquer renderização do navegador aplicada). Você verá links SERP nesse formato:
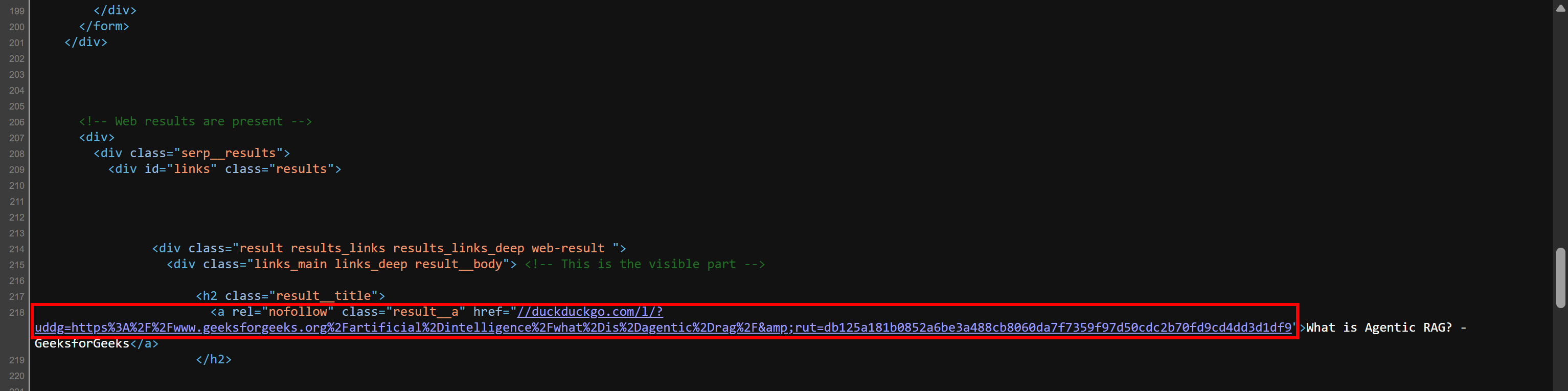
Agora, com os campos de dados extraídos, crie um dicionário para cada resultado de pesquisa e anexe-o à lista serp_results:
serp_result = {
"url": url,
"title": title,
"display_url": display_url,
"snippet": snippet
}
serp_results.append(serp_result) Perfeito! Sua lógica de Scraping de dados da web do DuckDuckGo está completa. Resta apenas exportar os dados coletados.
Etapa 6: exporte os dados coletados para CSV
Neste ponto, você tem os resultados da pesquisa do DuckDuckGo armazenados em uma lista Python. Para tornar esses dados utilizáveis por outras equipes ou ferramentas, exporte-os para um arquivo CSV usando a biblioteca csv integrada do Python:
with open("duckduckgo_results.csv", "w", newline="", encoding="utf-8") as f:
headers = serp_results[0].keys()
writer = csv.DictWriter(f, fieldnames=headers)
# Escreva o cabeçalho
writer.writeheader()
# Escreva todas as linhas de dados
writer.writerows(serp_results)Não se esqueça de importar o csv:
import csvDessa forma, seu scraper DuckDuckGo produzirá um arquivo de saída chamado duckduckgo_results.csv contendo todos os resultados coletados no formato CSV. Missão cumprida!
Etapa 7: Junte tudo
O código final contido em scraper.py é:
import requests
from bs4 import BeautifulSoup
import csv
# URL base da versão estática do DuckDuckGo
base_url = "https://html.duckduckgo.com/html/"
# Exemplo de consulta de pesquisa
search_query = "agentic rag"
# Para simular uma solicitação do navegador e evitar erros 403
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36"
}
# Conecte-se à página SERP de destino
params = {
"q": search_query
}
response = requests.get(base_url, params=params, headers=headers)
# Recupere o conteúdo HTML da resposta
html = response.text
# Analisar o HTML
soup = BeautifulSoup(html, "html.parser")
# Encontrar todos os contêineres de resultados
result_elements = soup.select("#links .result")
# Onde armazenar os dados extraídos
serp_results = []
# Iterar sobre cada resultado SERP e extrair dados dele
para result_element em result_elements:
# Lógica de Parsing
title_element = result_element.select_one(".result__a")
url = "https:" + title_element["href"]
title = title_element.get_text(strip=True)
url_element = result_element.select_one(".result__url")
display_url = url_element.get_text(strip=True)
snippet_element = result_element.select_one(".result__snippet")
snippet = snippet_element.get_text(strip=True)
# Preencha um novo objeto de resultado SERP e acrescente-o à lista
serp_result = {
"url": url,
"title": title,
"display_url": display_url,
"snippet": snippet
}
serp_results.append(serp_result)
# Exportar os dados coletados para CSV
com open("duckduckgo_results.csv", "w", newline="", encoding="utf-8") como f:
headers = serp_results[0].keys()
writer = csv.DictWriter(f, fieldnames=headers)
# Escreva o cabeçalho
writer.writeheader()
# Escreva todas as linhas de dados
writer.writerows(serp_results)Uau! Em menos de 65 linhas de código, você acabou de criar um script de extração de dados do DuckDuckGo.
Execute-o com este comando:
python Scraper.pyO resultado será um arquivo duckduckgo_results.csv, que aparecerá na pasta do seu projeto. Abra-o e você verá os dados coletados assim:

Et voilà! Você transformou resultados de pesquisa não estruturados de uma página da web do DuckDuckGo em um arquivo CSV estruturado.
[Extra] Integre proxies rotativos para evitar bloqueios
O Scraper acima funciona bem para pequenas execuções, mas não terá muito escalabilidade. Isso porque o DuckDuckGo começará a bloquear suas solicitações se perceber muito tráfego proveniente do mesmo IP. Quando isso acontece, seus servidores começam a retornar páginas de erro 403 Forbidden contendo uma mensagem como esta:
Se isso persistir, envie um e-mail para <a href="mailto:[email protected]?subject=Error getting results">nós</a>.<br />
Nosso endereço de e-mail de suporte inclui um código de erro anônimo que nos ajuda a entender o contexto da sua pesquisa.Isso significa que o servidor identificou sua solicitação como automatizada e a bloqueou, geralmente devido a um problema de limitação de taxa. Para evitar bloqueios, você precisa alternar seu endereço IP.
A solução é enviar solicitações por meio de um Proxy rotativo. Se você quiser saber mais sobre esse mecanismo, consulte nosso guia sobre como alternar um endereço IP.
A Bright Data oferece proxies rotativos apoiados por uma rede de mais de 150 milhões de IPs. Veja como integrá-los ao seu Scraper DuckDuckGo para evitar bloqueios!
Siga o guia oficial de configuração de Proxy e você obterá uma string de conexão de Proxy semelhante a esta:
<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335
Defina o Proxy em Solicitações, conforme abaixo:
proxy_url = "http://<BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335"
proxies = {
"http": proxy_url,
"https": proxy_url,
}
# definição de parâmetros e cabeçalhos...
response = requests.get(
base_url,
params=params,
headers=headers,
proxies=proxies, # encaminhe a solicitação através do Proxy rotativo
verify=False,
)Observação: verify=False desativa a verificação do certificado SSL. Isso evitará erros relacionados à validação do certificado do Proxy, mas não é seguro. Para uma implementação mais pronta para produção, consulte nossa página de documentação sobre validação de certificado SSL.
Agora, suas solicitações GET para o DuckDuckGo serão roteadas através da rede de Proxy residencial de 150 milhões de IPs da Bright Data, garantindo um IP novo a cada vez e ajudando você a evitar bloqueios relacionados ao IP.
Abordagem nº 2: contar com uma biblioteca de scraping do DuckDuckGo, como DDGS
Nesta seção, você aprenderá como usar a biblioteca DDGS. Este projeto de código aberto, com mais de 1,8 mil estrelas no GitHub, era anteriormente conhecido como duckduckgo-search porque se concentrava especificamente no DuckDuckGo. Recentemente, ele foi renomeado para DDGS (Dux Distributed Global Search), pois agora também oferece suporte a outros mecanismos de pesquisa.
Aqui, veremos como usá-lo a partir da linha de comando para extrair resultados de pesquisa do DuckDuckGo!
Passo 1: Instalar o DDGS
Instale o DDGS globalmente ou dentro de um ambiente virtual através do pacote ddgs PyPI:
pip install -U ddgsDepois de instalado, você pode acessá-lo através da ferramenta de linha de comando ddgs. Verifique a instalação executando:
ddgs --helpA saída deve ser semelhante a esta:
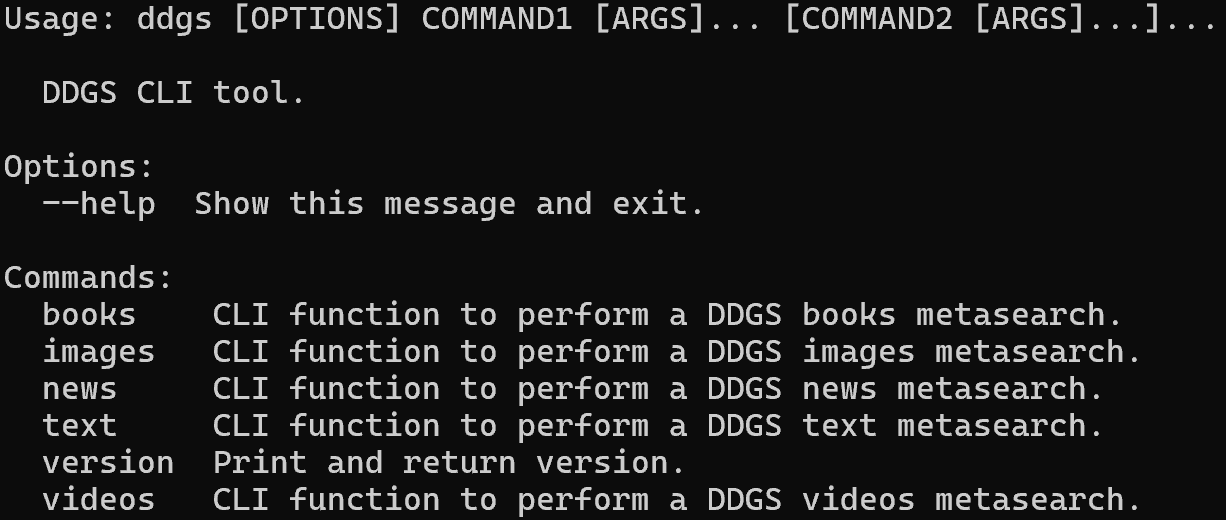
Como você pode ver, a biblioteca oferece suporte a vários comandos para extrair diferentes tipos de dados (por exemplo, texto, imagens, notícias etc.). Neste caso, você usará o comando text, que tem como alvo os resultados de pesquisa das SERPs.
Observação: você também pode chamar esses comandos por meio da API DDGS no código Python, conforme explicado na documentação.
Etapa 2: use o DDGS via CLI para Scraping de dados da Web do DuckDuckGo
Primeiro, familiarize-se com o comando text executando:
ddgs text --helpIsso exibirá todos os sinalizadores e opções suportados:
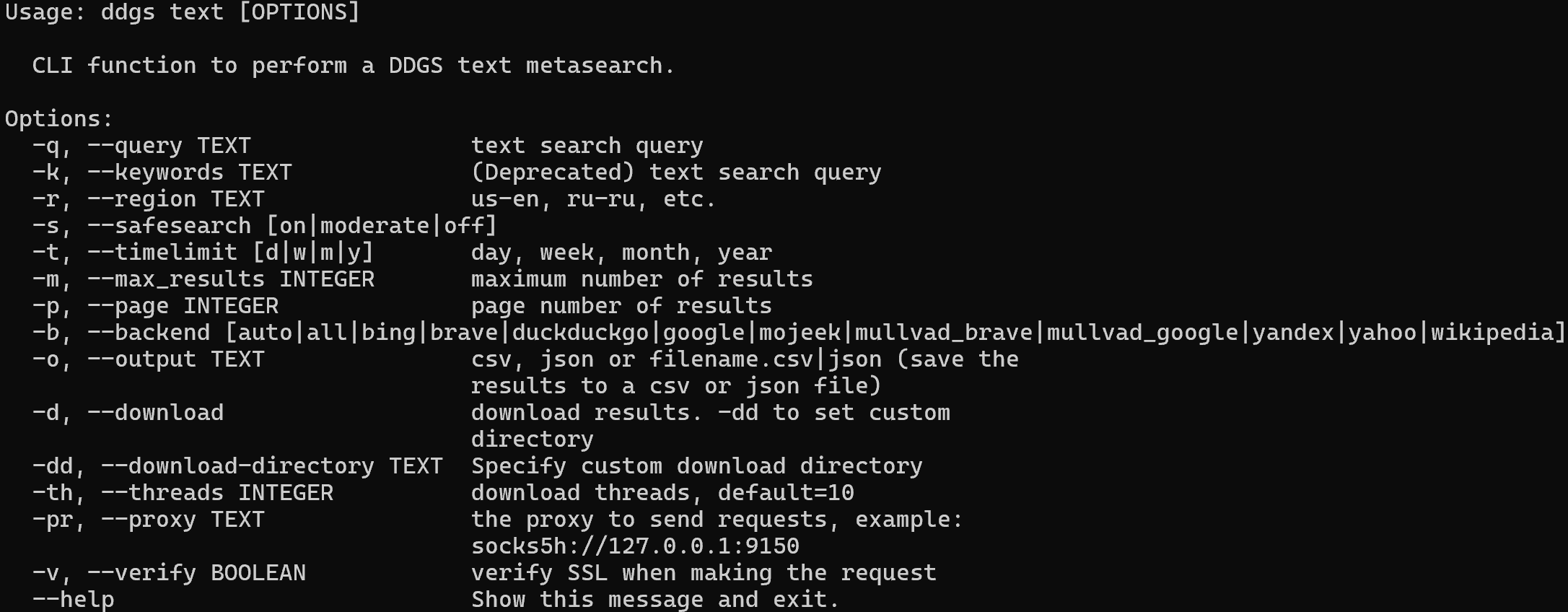
Para extrair os resultados de pesquisa do DuckDuckGo para “agentic rag” e exportá-los para um arquivo CSV, execute:
ddgs text -q "agentic rag" -b duckduckgo -o duckduckgo_results.csvO resultado será um arquivo duckduckgo_results.csv. Abra-o e você verá algo como:

Incrível! Você obteve os mesmos resultados de pesquisa que com o Scraper Python DuckDuckGo personalizado, mas com um único comando CLI.
[Extra] Integrar um Proxy rotativo
Como você acabou de ver, o DDGS é uma ferramenta extremamente poderosa de pesquisa SERP e Scraping de dados. Ainda assim, não é mágica. Em projetos de scraping em grande escala, ele encontrará os mesmos bloqueios e proibições de IP mencionados anteriormente.
Para evitar esses problemas, assim como antes, você precisa de um Proxy rotativo. Não é de se admirar que o DDGS venha com suporte nativo para integração de Proxy por meio do sinalizador -pr (ou --proxy).
Recupere sua URL de Proxy rotativo da Bright Data e defina-a em seu comando ddgs CLI desta forma:
ddgs text -q "agentic rag" -b duckduckgo -o duckduckgo_results.csv -pr <BRIGHT_DATA_PROXY_USERNAME>:<BRIGHT_DATA_PROXY_PASSWORD>@brd.superproxy.io:33335Pronto! As solicitações da web subjacentes feitas pela biblioteca agora serão roteadas através da rede de Proxy rotativo da Bright Data. Isso permite que você faça scraping de dados com segurança, sem se preocupar com bloqueios relacionados ao IP.
Abordagem nº 3: usando a API SERP da Bright Data
Neste capítulo, você aprenderá como usar a API SERP tudo-em-um da Bright Data para recuperar programaticamente os resultados de pesquisa da versão dinâmica do DuckDuckGo. Siga as instruções abaixo para começar!
Observação: para uma configuração simplificada e mais rápida, presumimos que você já tenha um projeto Python em funcionamento com a biblioteca de solicitações instalada.
Etapa 1: Configure sua zona da API SERP da Bright Data
Primeiro, crie uma conta Bright Data ou faça login se você já tiver uma. Abaixo, você será guiado pelo processo de configuração do produto API SERP para scraping do DuckDuckGo.
Para uma configuração mais rápida, você também pode consultar o guia oficial “Quick Start” (Início rápido) da API SERP. Caso contrário, continue com as etapas a seguir.
Depois de fazer login, navegue até sua conta Bright Data e clique na opção “Proxies & Scraping” para acessar esta página:
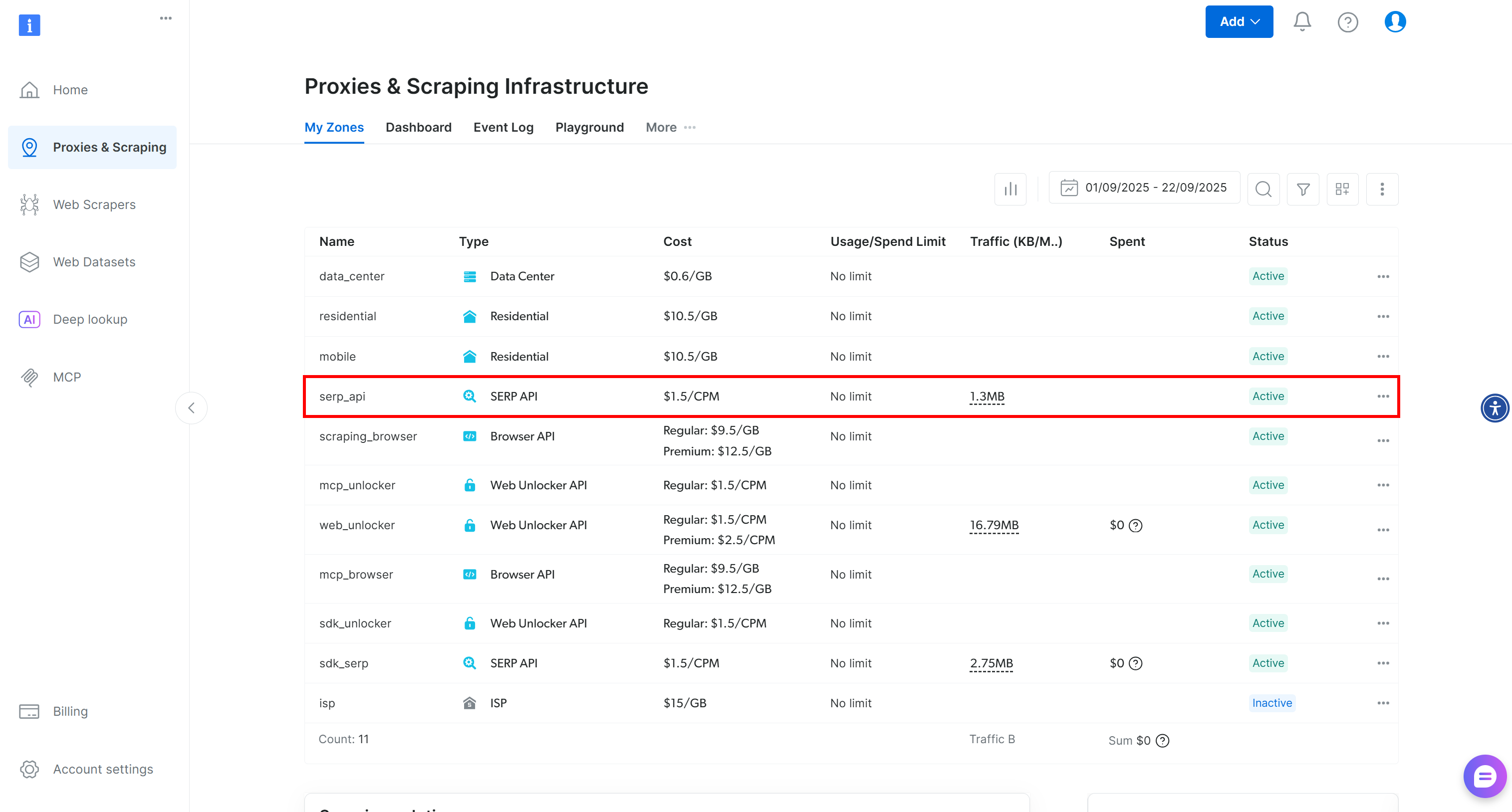
Verifique a tabela “Minhas zonas”, que lista seus produtos Bright Data configurados. Se já existir uma zona API SERP ativa, você está pronto para começar. Basta copiar o nome da zona (serp_api, neste caso), pois você precisará dele mais tarde.
Se não houver nenhuma zona, role para baixo até a seção “Soluções de Scraping” e clique no botão “Criar Zona” no cartão “API SERP”:
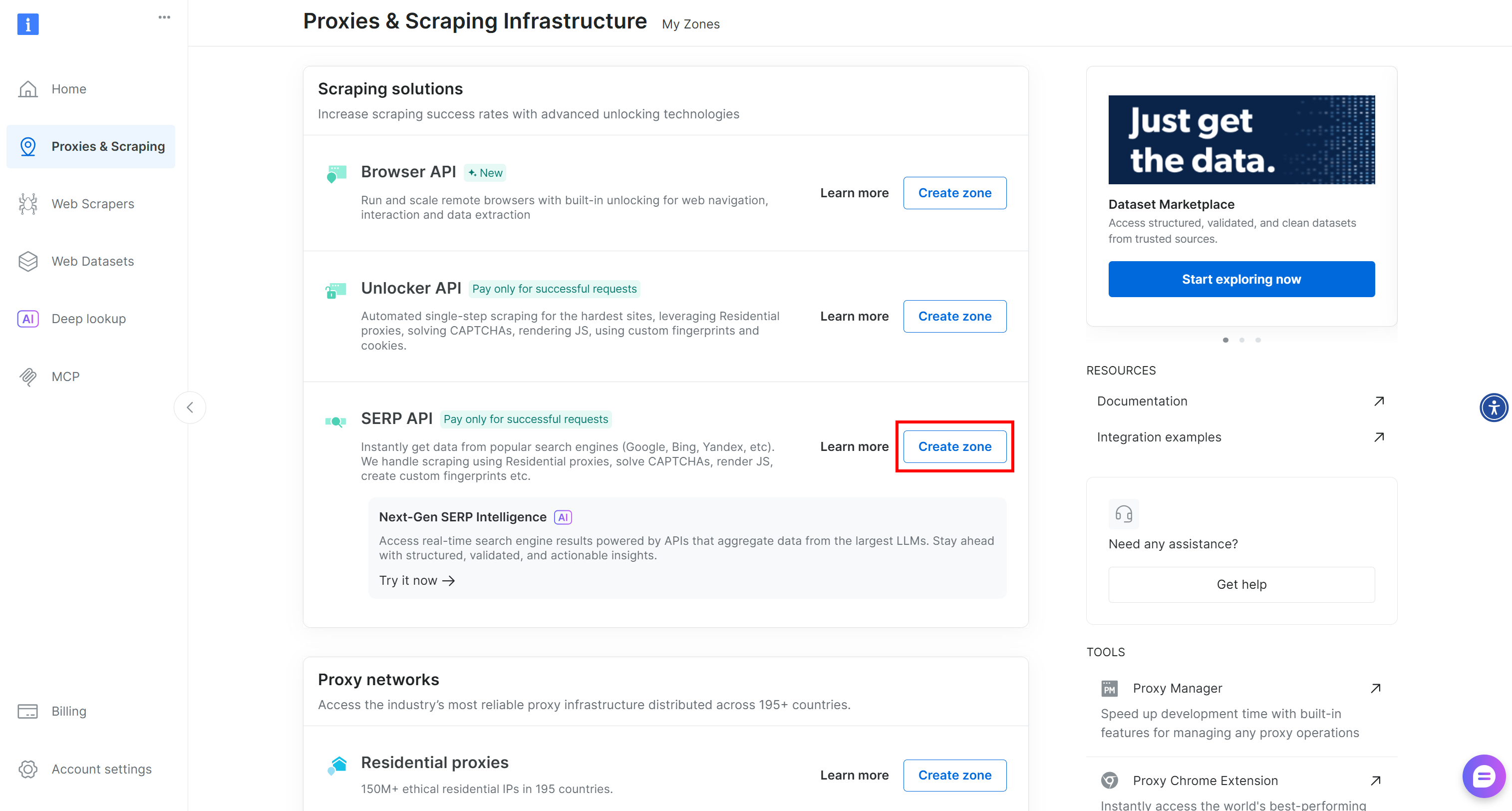
Dê um nome à sua zona (por exemplo, API SERP) e pressione “Adicionar”:
Em seguida, vá para a página do produto da Zona e certifique-se de que ela esteja ativada, alternando o botão para “Ativo”:
Ótimo! Você configurou com sucesso a API SERP da Bright Data.
Etapa 2: Recupere sua chave API da Bright Data
A maneira recomendada de autenticar solicitações da API SERP é usando sua chave API da Bright Data. Se você ainda não gerou uma, siga o guia oficial para obter a sua.
Ao fazer uma solicitação POST para a API SERP, inclua a chave da API no cabeçalho de autorização desta forma para autenticação:
"Autorização: Portador <BRIGHT_DATA_API_KEY>"Ótimo! Agora você tem todos os elementos necessários para chamar a API SERP da Bright Data em um script Python (ou através de qualquer outro cliente HTTP).
Etapa 3: Chame a API SERP
Junte tudo e chame a API SERP da Bright Data na página de pesquisa “agentic rag” do DuckDuckGo com este trecho de Python:
# pip install requests
import requests
# Credenciais da Bright Data (TODO: substitua pelos seus valores)
bright_data_api_key = "<YOUR_BRIGHT_DATA_API_KEY>"
bright_data_serp_api_zone_name = "<YOUR_SERP_API_ZONE_NAME>"
# Sua página de pesquisa DuckDuckGo alvo
duckduckgo_page_url = "https://duckduckgo.com/?q=agentic+rag"
# Realizar uma solicitação à API SERP da Bright Data
response = requests.post(
"https://api.brightdata.com/request",
headers={
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
},
json={
"zona": bright_data_serp_api_zona_name,
"url": duckduckgo_page_url,
"format": "raw"
})
# Acesse o HTML renderizado da versão dinâmica do DuckDuckGo
html = response.text
# Lógica de Parsing...Para um exemplo mais completo, confira o “Projeto Python da API SERP da Bright Data” no GitHub.
Observe que, desta vez, a URL de destino pode ser a versão dinâmica do DuckDuckGo (por exemplo, https://duckduckgo.com/?q=agentic+rag). A API SERP lida com a renderização JavaScript, integra-se à rede de proxy Bright Data para rotação de IP e gerencia outras medidas anti-scraping, como impressão digital do navegador e CAPTCHAs. Portanto, não haverá problemas ao fazer scraping de SERPs dinâmicas.
A variável html conterá o HTML totalmente renderizado da página DuckDuckGo. Verifique isso imprimindo o HTML com:
print(html)Você obterá algo como isto:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Agentic RAG no DuckDuckGo</title>
<!-- Omitido por brevidade ... -->
</head>
<body>
<div class="site-wrapper" style="min-height: 825px;">
<div id="content">
<div id="duckassist-answer" class="answer-container">
<DIV class="answer-content-block">
<P class="answer-text">
<SPAN class="highlight">O Agentic RAG</SPAN> é uma versão avançada do Retrieval-Augmented Generation (RAG) que permite que os agentes de IA gerenciem dinamicamente como recuperam e usam informações, melhorando sua capacidade de responder a consultas em tempo real e se adaptar a situações em constante mudança. Essa abordagem aumenta a precisão e a capacidade de tomada de decisão dos sistemas de IA, integrando o raciocínio à recuperação de dados.
</P>
<!-- Omitido por brevidade ... -->
</DIV>
<!-- Omitido por brevidade ... -->
</DIV>
<ul class="results-list">
<li class="result-item">
<article class="result-card">
<div <!-- Omitido por motivos de concisão ... -->
<div class="result-body">
<h2 class="result-title">
<a href="https://www.geeksforgeeks.org/artificial-intelligence/what-is-agentic-rag/" rel="noopener" target="_blank" class="result-link">
<span class="title-text">O que é Agentic RAG? - GeeksforGeeks</span>
</a>
</h2>
<div class="result-snippet-container">
<div class="result-snippet">
<div>
<span class="snippet-text">
<span class="snippet-date">8 de setembro de 2026</span>
<span>
<b>A arquitetura Agentic RAG</b> foi projetada para maximizar a adaptabilidade e a inteligência, aproveitando agentes autônomos e integrações de ferramentas especializadas. Em sua essência, a arquitetura organiza agentes de raciocínio, cada um capaz de tomar decisões, planejar e recuperar informações, em um sistema coordenado. Vejamos os principais componentes da arquitetura <b>Agentic RAG</b>, 1.
</span>
</span>
</div>
</div>
</div>
</div>
</article>
</li>
<!-- Outros resultados de pesquisa ... -->
</ul>
<!-- Omitido por brevidade ... -->
</div>
<!-- Omitido por brevidade ... -->
</div>
</body>
</html>Observação: o HTML de saída também pode incluir o resumo gerado pela IA “Search Assist”, já que você está lidando com a versão dinâmica da página.
Agora, analise este HTML conforme mostrado na primeira abordagem para acessar os dados do DuckDuckGo de que você precisa!
Abordagem nº 4: Integrando uma ferramenta de scraping do DuckDuckGo em um agente de IA via MCP
Lembre-se de que o produto API SERP também é exposto por meio da ferramenta search_engine disponível no Bright Data Web MCP.
Esse servidor MCP de código aberto fornece acesso de IA às soluções de recuperação de dados da web da Bright Data, incluindo recursos de scraping do DuckDuckGo. Mais especificamente, a ferramenta search_engine está disponível no nível gratuito do Web MCP para que você possa integrá-la aos seus agentes de IA ou fluxos de trabalho sem nenhum custo.
Para integrar o Web MCP à sua solução de IA, geralmente é necessário ter o Node.js instalado localmente e um arquivo de configuração como este:
{
"mcpServers": {
"Bright Data Web MCP": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>"
}
}
}
}Por exemplo, essa configuração funciona com o Claude Code. Descubra outras integrações na documentação.
Graças a essa integração, você poderá recuperar dados SERP em linguagem natural e usá-los em seus fluxos de trabalho ou agentes alimentados por IA.
Conclusão
Neste tutorial, você viu os quatro métodos recomendados para fazer scraping no DuckDuckGo:
- Por meio de um Scraper personalizado
- Usando DDGS
- Com a API de pesquisa do DuckDuckGo
- Graças ao Web MCP
Como demonstrado, a única maneira confiável de fazer scraping do DuckDuckGo em grande escala, evitando bloqueios, é usando uma solução de scraping estruturada, apoiada por uma tecnologia robusta de bypass anti-bot e uma grande rede de Proxy, como a Bright Data.
Crie uma conta gratuita na Bright Data e comece a explorar nossas soluções de scraper!




