

Neste guia, você verá:
- O que é um Scraper do Crunchbase e como ele funciona
- Quais dados você pode coletar automaticamente do Crunchbase
- Como criar um script de scraping do Crunchbase com Python
- Por que você pode precisar de uma solução mais avançada para fazer o scraping do site
Vamos começar!
O que é um Scraper do Crunchbase?
Um scraper do Crunchbase é uma ferramenta automatizada projetada para extrair dados das páginas da web do Crunchbase. Ele navega pelo site, identifica as informações desejadas e as coleta por meio de Scraping de dados.
O Crunchbase emprega medidas avançadas anti-bot e anti-scraping para proteger seus dados. Como resultado, um Scraper eficaz do Crunchbase deve incluir recursos como renderização JavaScript, Resolução de CAPTCHA e falsificação de impressão digital do navegador.
Quais dados extrair do Crunchbase
Abaixo está uma lista dos dados que você pode recuperar automaticamente do Crunchbase por meio do Scraping de dados:
- Informações da empresa: nome, descrição, setor, localização da sede, data de fundação, status (por exemplo, ativa, adquirida) e muito mais
- Dados de financiamento: valor total do financiamento, rodadas de financiamento, investidores e muito mais
- Pessoas-chave: fundadores, executivos, membros, funções e cargos e muito mais
- Produtos e serviços: descrições de produtos, categorias de produtos ou serviços oferecidos e muito mais
- Aquisições e fusões: detalhes de quaisquer empresas adquiridas, datas e termos das aquisições e muito mais
- Dados financeiros e de mercado: estimativas de receita, número de funcionários e muito mais
- Notícias e eventos: comunicados à imprensa, marcos ou eventos significativos e muito mais
- Concorrentes: lista de empresas concorrentes e muito mais
Como criar um Scraper do Crunchbase em Python
Nesta seção do tutorial, você aprenderá como criar um Scraper do Crunchbase usando Python. O objetivo é desenvolver um script que possa coletar automaticamente dados da página do Bright Data Crunchbase:
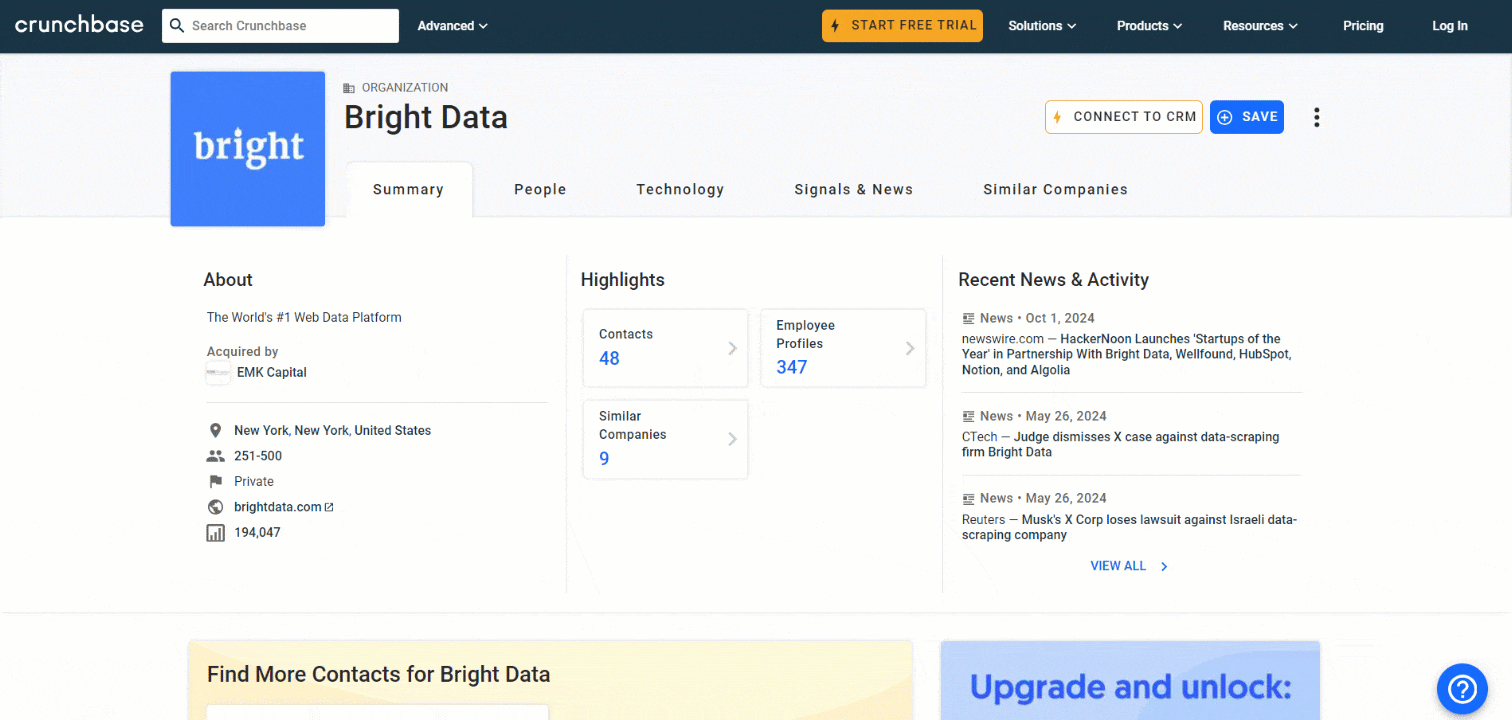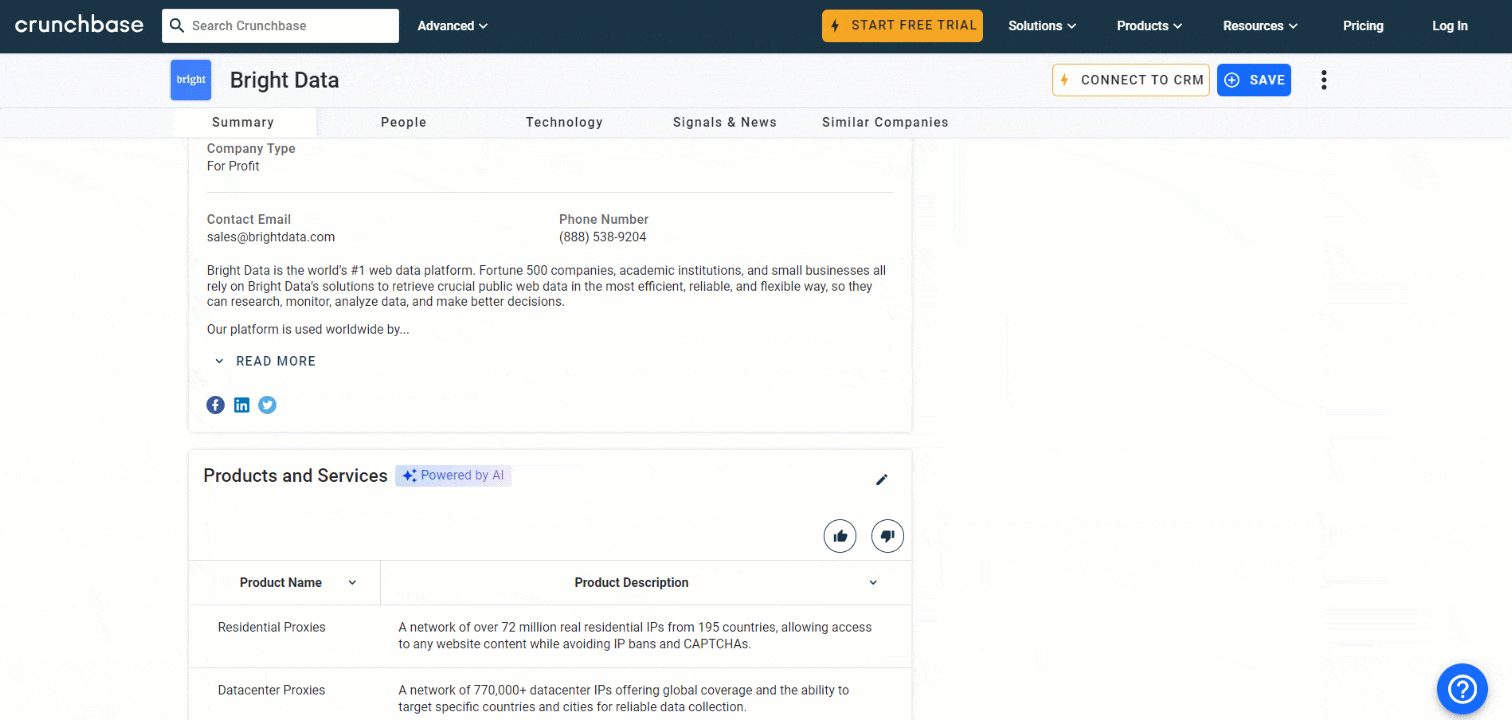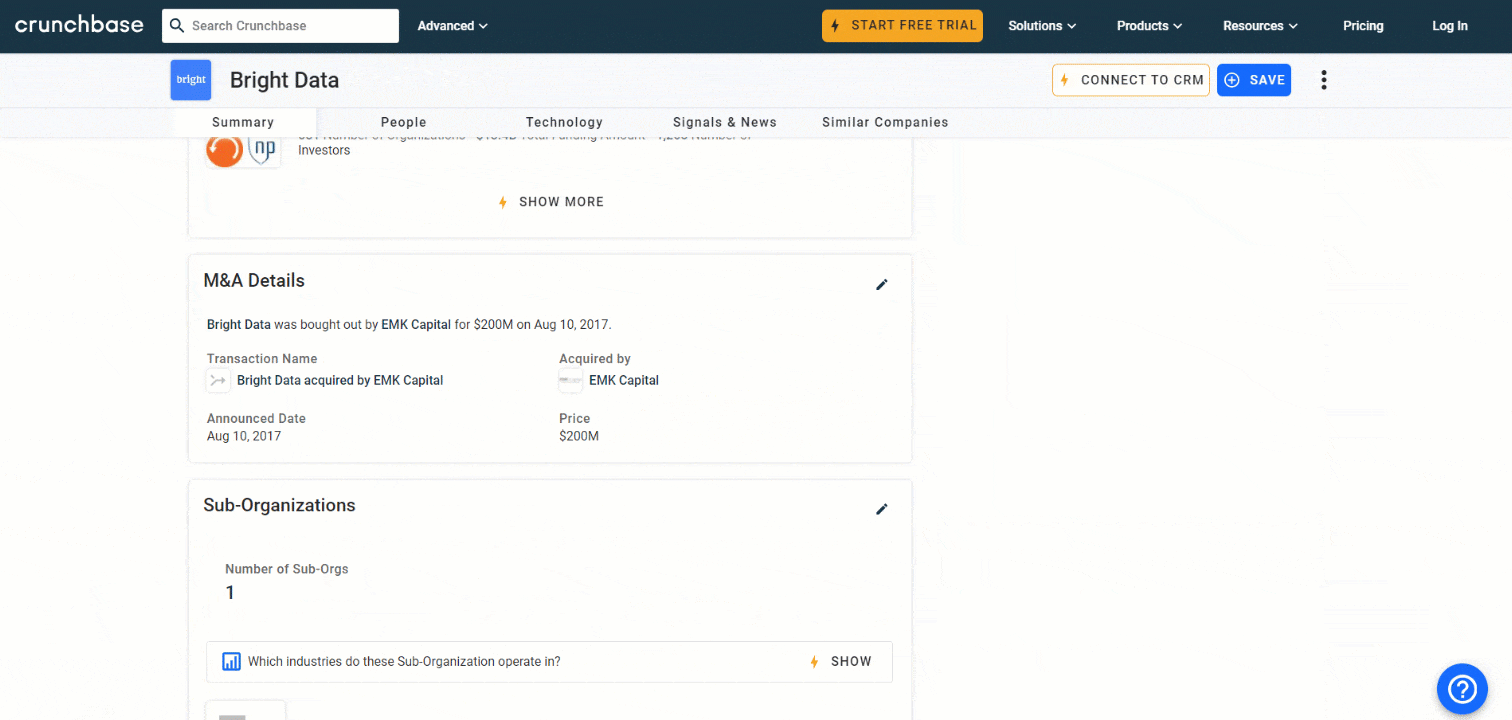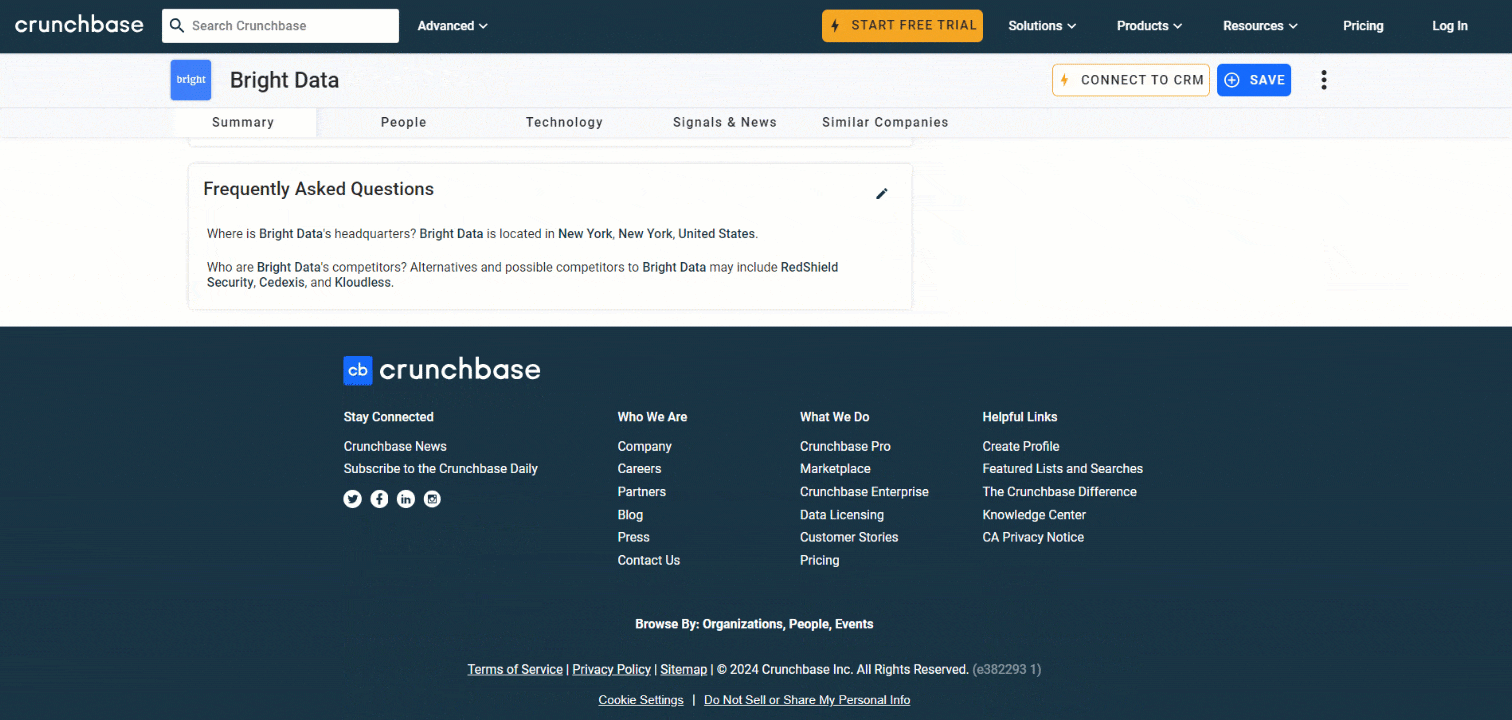
Siga as etapas abaixo para ver como fazer o scraping do Crunchbase com Python!
Etapa 1: crie um projeto Python
Primeiro, certifique-se de que você tem o Python 3+ instalado em sua máquina. Caso contrário, baixe-o do site oficial e siga as instruções.
Crie um diretório para o seu Scraper Python Crunchbase:
mkdir crunchbase-scraperA pasta crunchbase-scraper conterá seu bot de raspagem.
Abra a pasta do projeto em seu IDE Python favorito, como PyCharm Community Edition ou Visual Studio Code com a extensão Python.
Em seguida, crie um arquivo scraper.py dentro da pasta do projeto. Esse arquivo conterá a lógica de raspagem do Crunchbase.
Agora, inicialize um ambiente virtual Python. Se você é um usuário macOS ou Linux, execute:
python3 -m venv envDa mesma forma, no Windows, execute:
python -m venv envIsso adicionará um diretório env ao seu projeto.
Agora, seu projeto deve ter a seguinte estrutura:

Ative o ambiente virtual com este comando:
source env/bin/activateOu, no Windows:
envScriptsactivateÓtimo! Agora você tem um projeto Python onde pode instalar dependências locais.
Lembre-se de que você pode iniciar seu script com:
python3 Scraper.pyOu, no Windows:
python Scraper.pyEtapa 2: determine e instale as bibliotecas de scraping
Agora você precisa descobrir quais bibliotecas de scraping são mais adequadas para extrair dados do Crunchbase. Comece fazendo uma solicitação GET HTTP para a página da web de destino usando um cliente HTTP para desktop. Aqui está o resultado que você obterá:
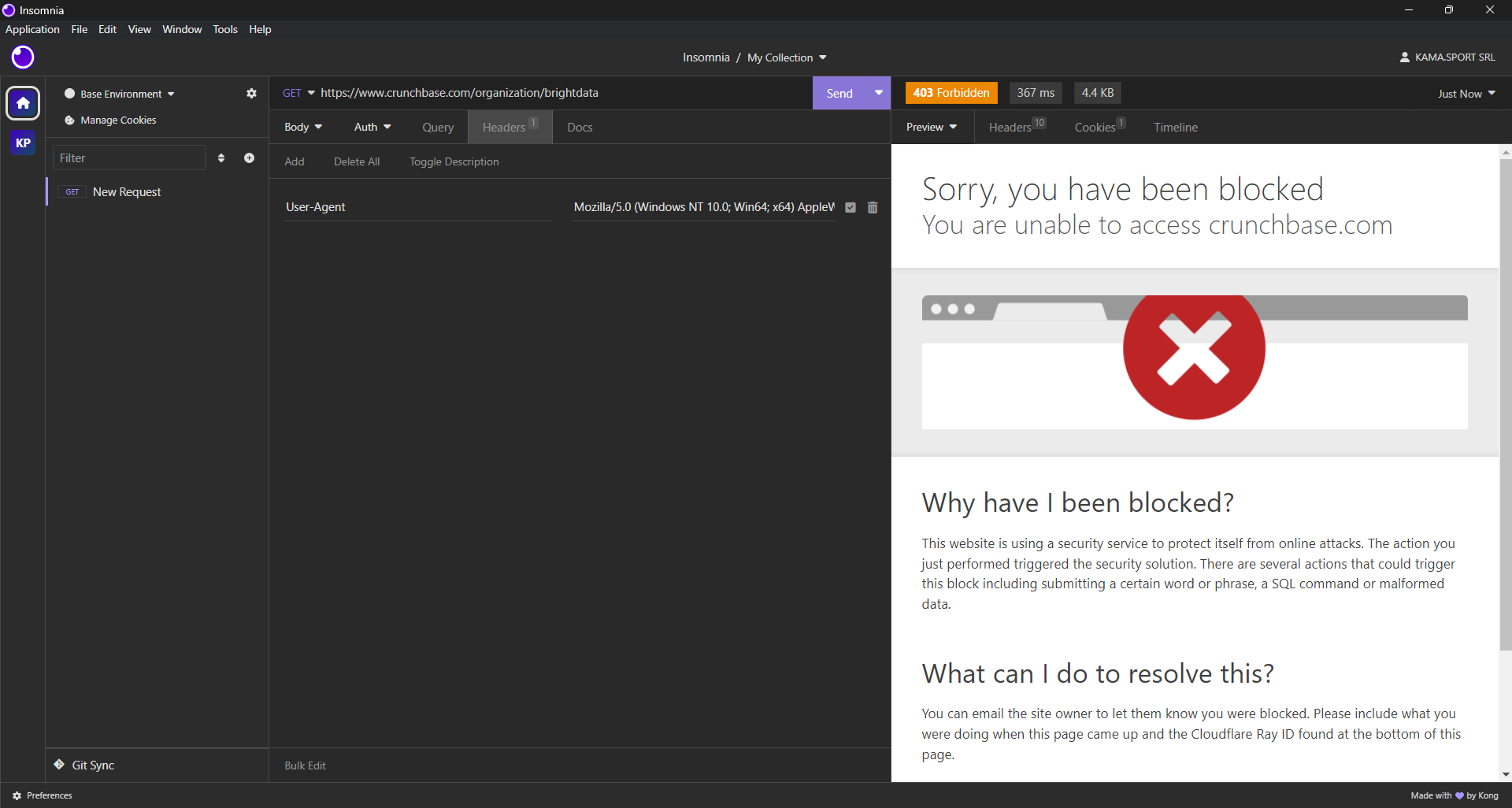
Como você pode ver, o Crunchbase bloqueia sua solicitação, mesmo que você use cabeçalhos de navegador realistas. Em outras palavras, você precisará de uma ferramenta de automação de navegador para fazer o scraping do Crunchbase de maneira eficaz. Saiba mais em nosso artigo sobre os melhores navegadores headless.
Para Python, o Selenium é uma das ferramentas de automação de navegador headless mais populares. Mais especificamente, ele permite que você instrua um navegador a realizar interações específicas e extrair dados de páginas dinâmicas.
Para instalar o Selenium, use o pacote pip selenium. Em um ambiente virtual Python ativado, execute o seguinte comando:
pip install -U seleniumEm seguida, importe o Selenium no seu arquivo scraper.py com a seguinte linha:
from selenium import webdriverÓtimo! Agora você tem tudo o que precisa para realizar o Scraping de dados no Crunchbase.
Etapa 3: acesse a página de destino
Inicialize uma instância do Chrome WebDriver e use o método get() para instruir o navegador controlado a visitar a página desejada:
driver = webdriver.Chrome()
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)Em seguida, não se esqueça de fechar o WebDriver e liberar os recursos do navegador com:
driver.quit()Atualmente, seu script de Scraper do Crunchbase conterá:
from selenium import webdriver
# inicialize o driver para controlar uma instância do Chrome
# no modo headed
driver = webdriver.Chrome()
# navegue até a página desejada do Crunchbase
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)
# lógica de raspagem...
# fechar o driver e liberar os recursos do navegador
driver.quit()Se você executá-lo, verá a seguinte página por uma fração de segundo antes que o script seja encerrado:
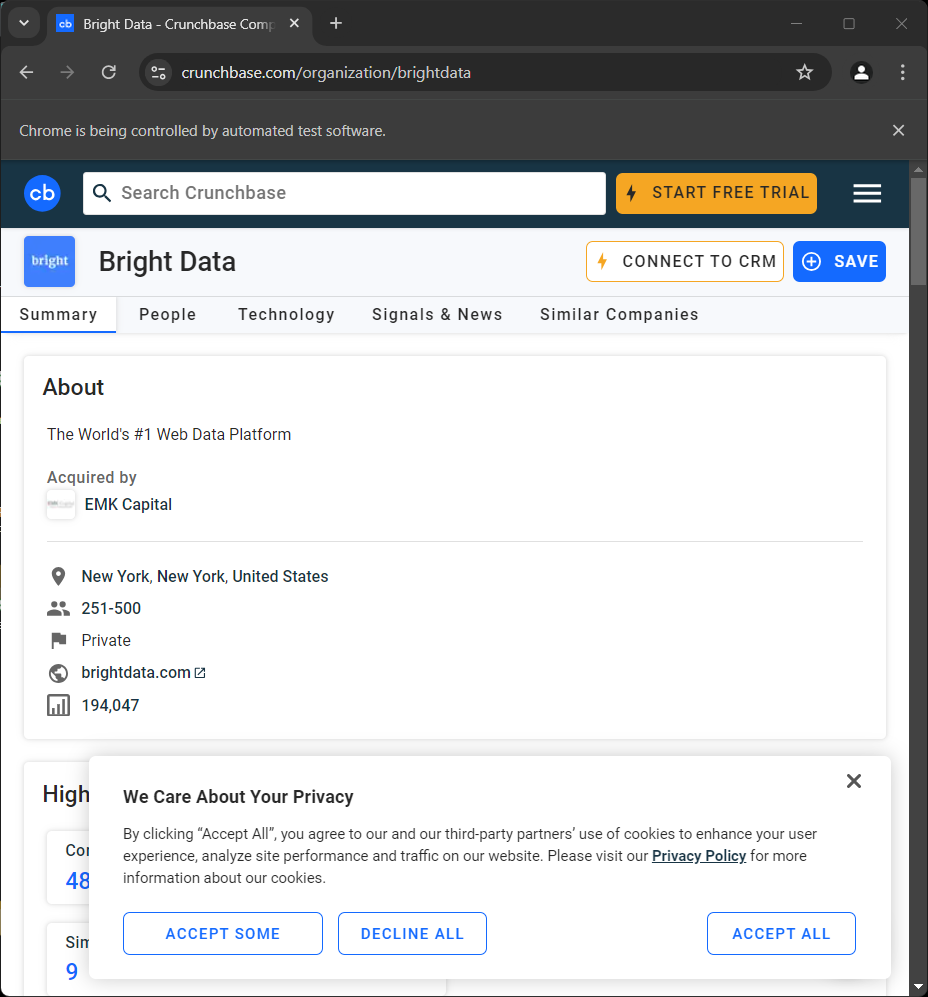
A mensagem “O Chrome está sendo controlado por um software de teste” indica que o Selenium está operando no Chrome conforme o esperado.
Normalmente, os navegadores nos scripts de scraping do Selenium são iniciados no modo headless para economizar recursos. Infelizmente, o Crunchbase possui um sistema avançado de detecção anti-bot que bloqueia navegadores headless. Portanto, você precisa manter o navegador no modo headed. Como alternativa, você pode tentar usar o Playwright Stealth para contornar esses mecanismos de detecção.
Etapa 4: lidar com o pop-up de cookies
Se você for um usuário europeu, a página exibirá o seguinte pop-up de cookies após alguns segundos:
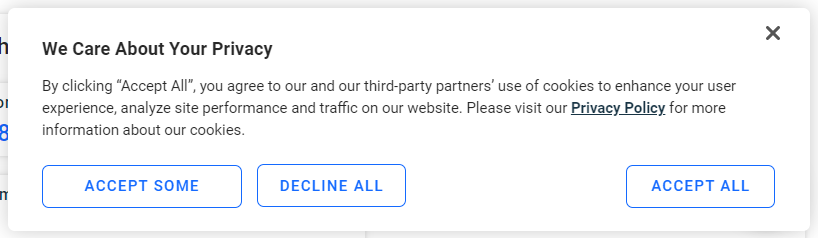
Se você não clicar no botão “Aceitar tudo”, não será possível interagir com a página. Inspecione o botão:
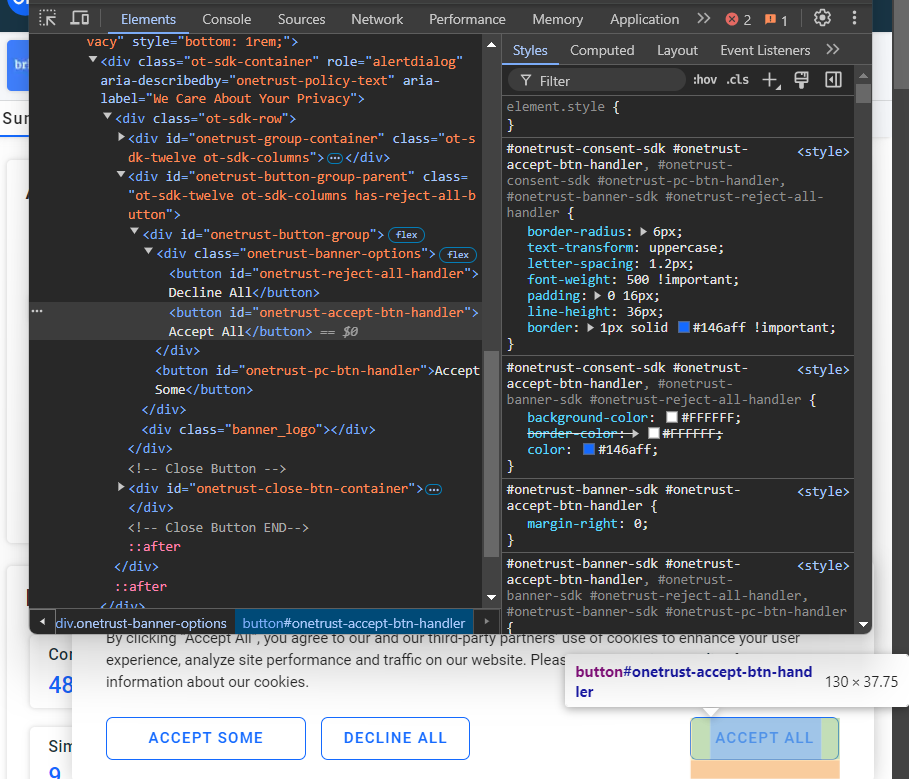
Veja que você pode selecioná-lo com o seletor CSS #onetrust-accept-btn-handler.
Agora, escreva uma função que aguarde até 60 segundos para que o botão “Aceitar tudo” apareça na página e fique clicável e, em seguida, clique nele:
def handle_cookie_banner(driver, seconds=60):
tente:
# aguarde o número de segundos especificado para que o botão “Aceitar tudo”
# do banner de cookies apareça na página
accept_button = WebDriverWait(driver, seconds).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))
)
# clicar no banner via JavaScript para evitar
# erros ElementClickInterceptedException
driver.execute_script("arguments[0].click();", accept_button)
print("Botão 'Aceitar tudo' clicado")
except:
print("Botão 'Aceitar tudo' não encontrado em {segundos} segundos")Observe que:
- O bloco
try ... excepté necessário porque o pop-up do cookie pode não estar na página. Nesse caso,o WebDriverWait irágerar umaNoSuchElementException, que será capturada peloexcept. - “Aceitar tudo” é clicado via JavaScript e não através do método
click(). O motivo é que o botão HTML aparece lentamente com uma animação de fade in. Portanto, se você tentar clicar nele comclick(), poderá receber umaElementClickInterceptedException.
Para funcionar, a função acima requer as seguintes importações:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import ByAgora você pode lidar com o pop-up de cookies chamando:
handle_cookie_banner(driver)Fantástico! Prepare-se para começar a extrair dados da página.
Etapa 5: extraia as informações sobre a empresa
A primeira informação a ser extraída no cartão “Resumo” é a descrição “Sobre” da empresa:
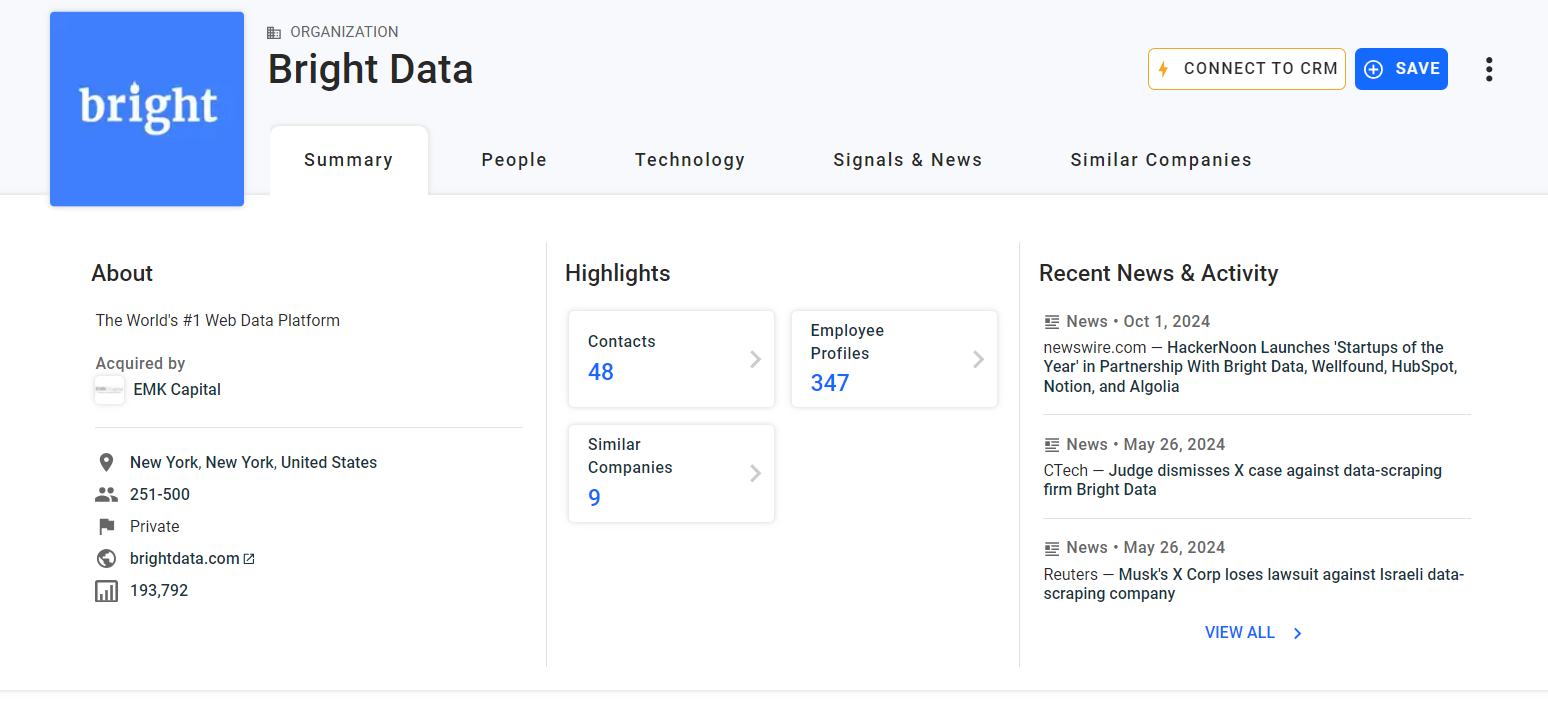
Inspecione o elemento HTML “Sobre”:
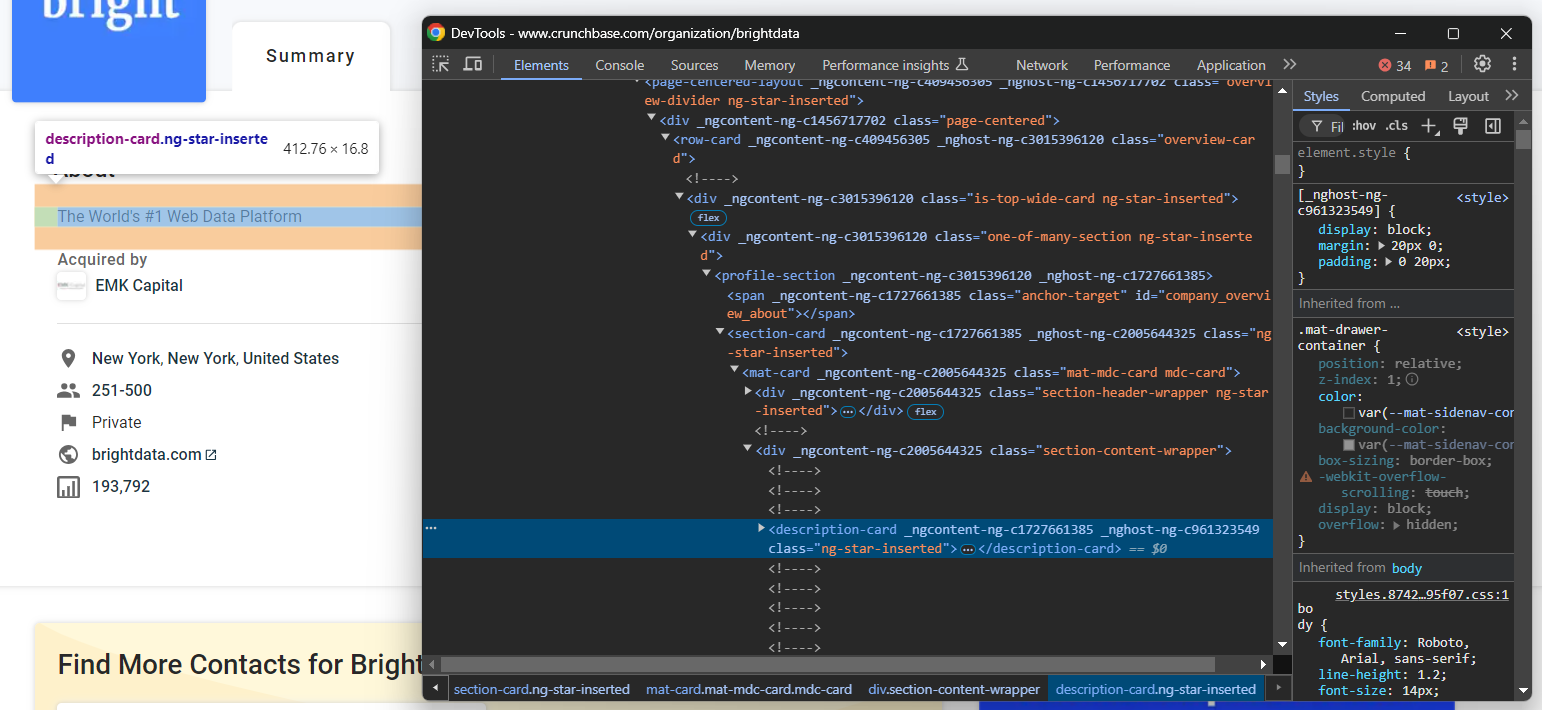
Observe que você pode selecioná-lo com o seletor CSS abaixo:
profile-section description-cardUse o método find_element() para aplicar o seletor CSS na página. Em seguida, extraia o texto dentro do nó com o atributo de texto:
about_node = driver.find_element(By.CSS_SELECTOR, "profile-section description-card")
about = about_node.textA variável about agora conterá:
“A plataforma de dados da Web nº 1 do mundo”Pronto!
Etapa 6: inspecione a estrutura da página
Agora, concentre-se nas informações contidas no cartão “Detalhes” da página:
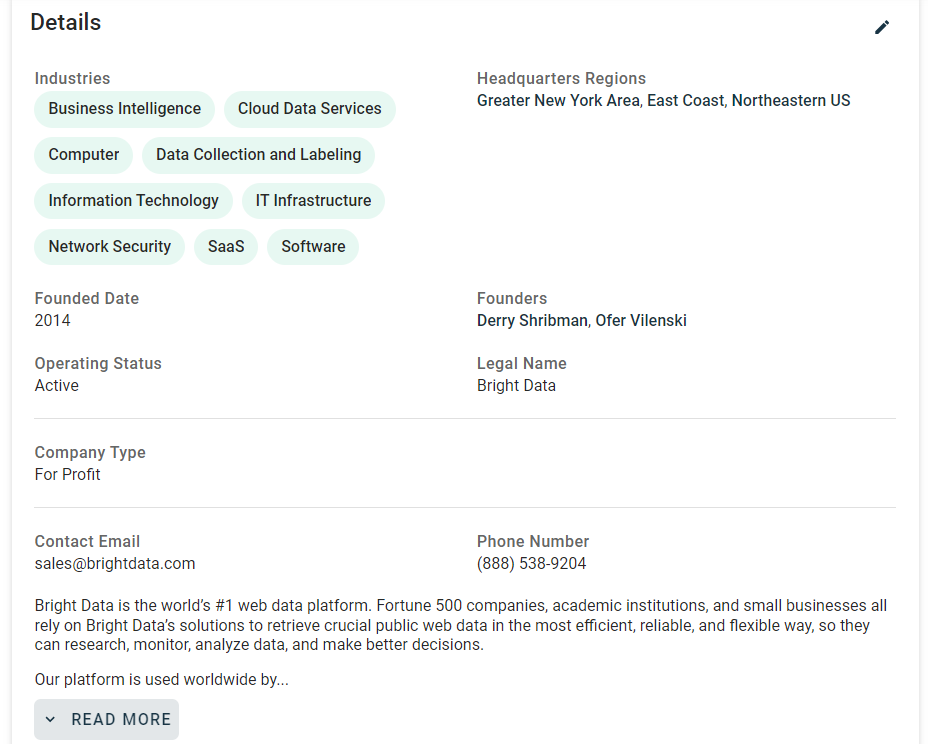
Se você inspecionar esta seção, perceberá que não há uma maneira fácil de selecionar os elementos HTML dos quais extrair dados:
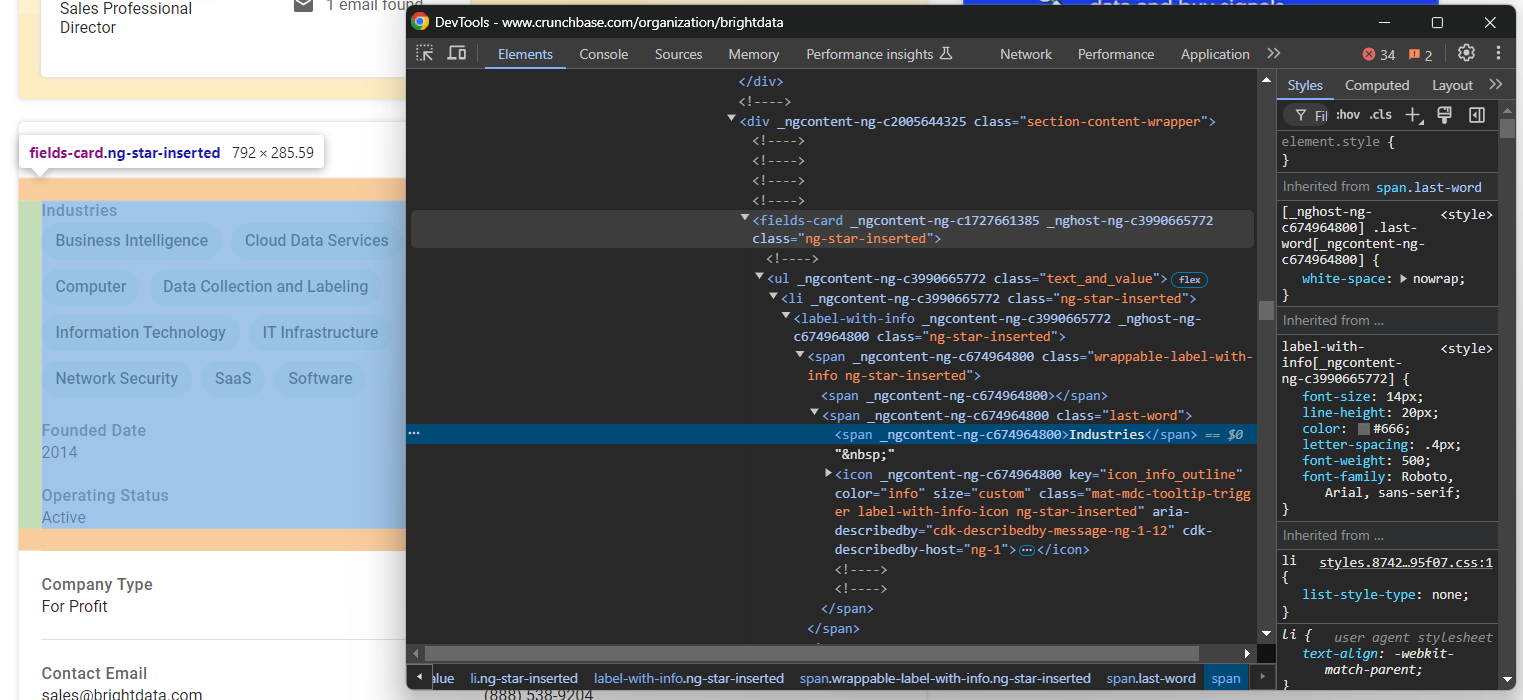
A maioria desses nós tem atributos HTML aleatórios que provavelmente são gerados no momento da compilação. Esses atributos mudam após cada implantação, portanto, você não pode confiar neles para a seleção de nós. Além disso, muitos desses elementos não são marcados com classes ou IDs exclusivos.
Uma abordagem eficaz para selecionar os elementos de interesse é concentrar-se em seus rótulos. Por exemplo, você pode selecionar o nó fields-card que contém as informações sobre os setores, identificando qual fields-card tem um nó label-with-info que contém a string “Setores”.
Essa técnica será usada para extrair dados desta seção. Portanto, faz sentido centralizar a lógica em uma função:
def find_parent_node_based_on_child_node_text(parent_nodes_selector, child_node_selector, text):
# selecionar todos os nós pai
parent_nodes = driver.find_elements(By.CSS_SELECTOR, parent_nodes_selector)
# iterar pelos nós pai para encontrar aquele
# cujo nó filho específico contém o texto desejado
for parent_node in parent_nodes:
try:
# obter o nó filho específico dentro do nó pai atual
child_node = parent_node.find_element(By.CSS_SELECTOR, child_node_selector)
# verificar se ele contém o texto desejado
if text.upper() in child_node.text.upper():
return parent_node
except:
continue
return NoneUse a função acima para selecionar o nó do cartão de campos “Indústrias” com:
nó pai das indústrias = find_parent_node_based_on_child_node_text("campos-cartão li", "label-with-info", "Indústrias")Ótimo! Agora será muito mais fácil extrair dados do Crunchbase.
Etapa 7: extrair detalhes da empresa
Inspecione o nó “Indústrias”:
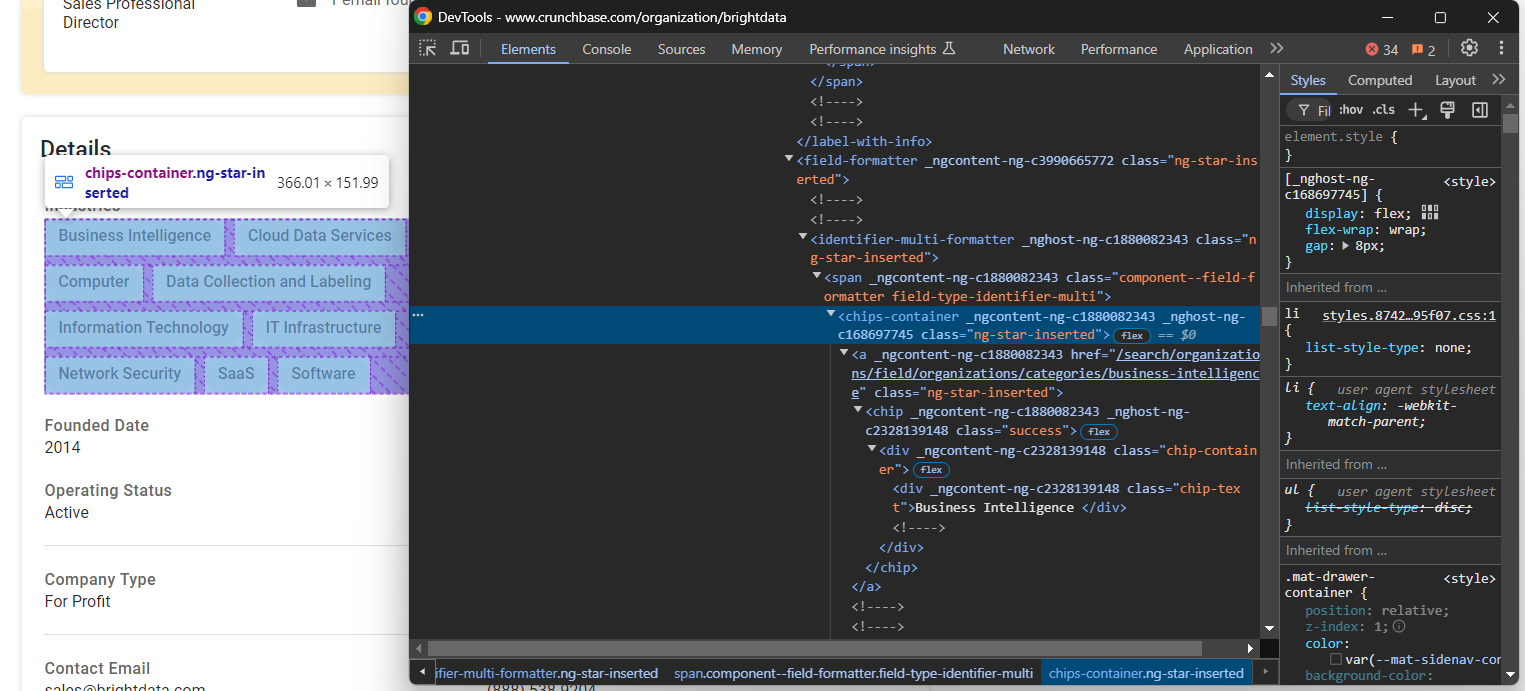
Ele armazena os setores em que a empresa atua, armazenados em chips-container a nodes. Selecione todos eles, itere sobre eles e extraia os dados:
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")
industries_nodes = industries_parent_node.find_elements(By.CSS_SELECTOR, "chips-container a")
industries = []
para industry_node em industries_nodes:
industries.append(industry_node.text)Agora, concentre-se no elemento “Data de fundação”:
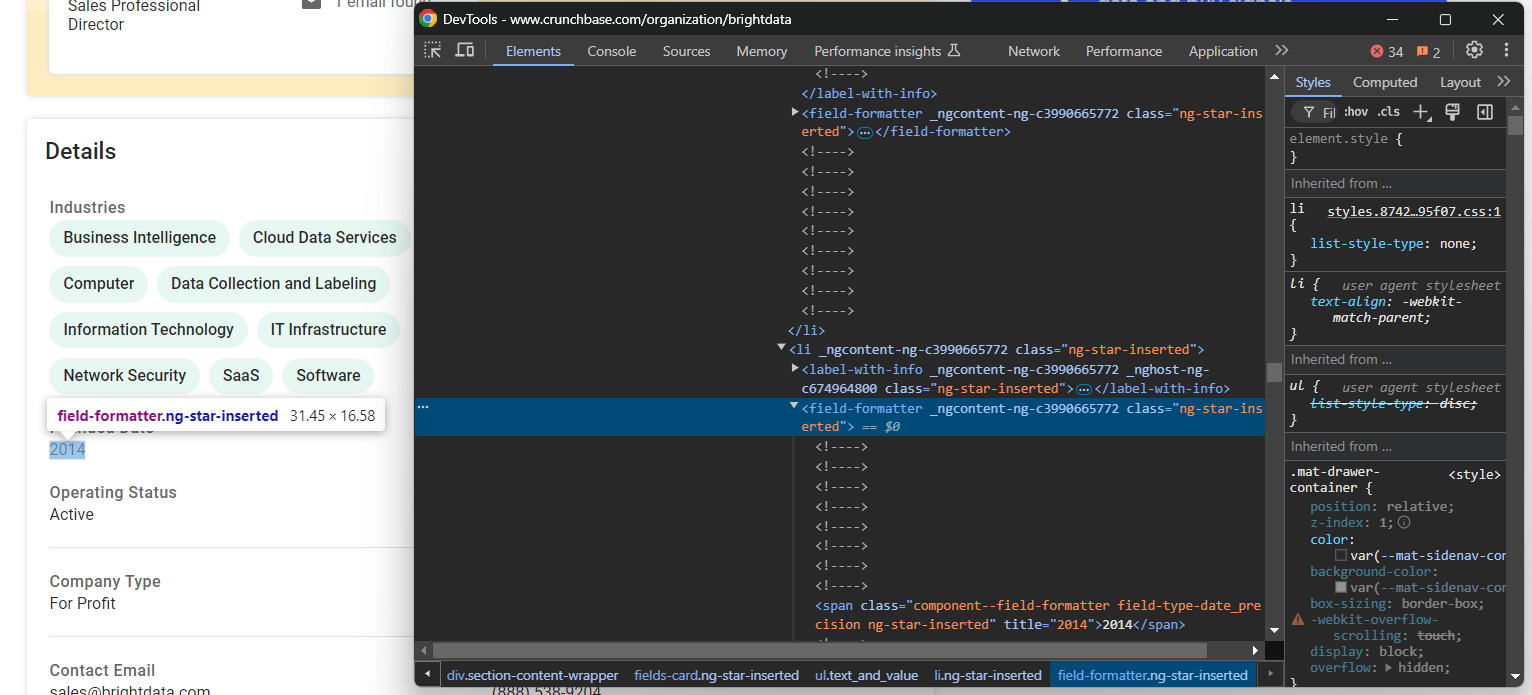
Nesse caso, a lógica de extração é mais fácil, pois você só precisa extrair o texto do elemento field-formatter dentro do nó pai fields-card li:
founded_date_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Founded Date")
founded_date_node = founded_date_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
founded_date = founded_date_node.textA mesma lógica pode ser aplicada à maioria dos outros elementos de detalhes da empresa:
company_type_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Tipo de empresa")
company_type_node = company_type_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
company_type = company_type_node.text
operating_status_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Operating Status")
operating_status_node = operating_status_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
operating_status = operating_status_node.text
headquarters_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Regiões da sede")
headquarters_node = headquarters_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
headquarters = headquarters_node.text
nó pai do nome legal = find_parent_node_based_on_child_node_text("campos-cartão li", "rótulo-com-informações", "Nome legal")
nó do nome legal = nó pai do nome legal.find_element(By.CSS_SELECTOR, "formatação de campo")
nome legal = nó do nome legal.text
contact_email_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "E-mail de contato")
contact_email_node = contact_email_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
contact_email = contact_email_node.text
phone_number_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Número de telefone")
phone_number_node = phone_number_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
phone_number = phone_number_node.textOutro nó que requer atenção especial é o elemento “Fundadores”:
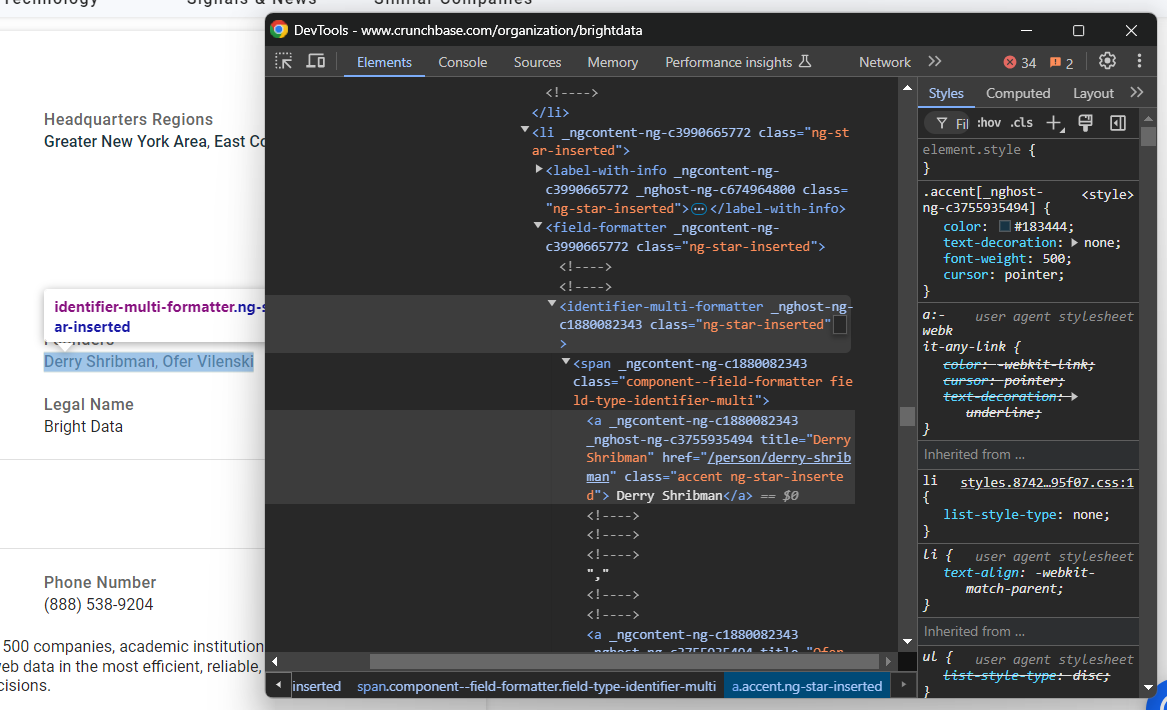
Nesse caso, você precisa iterar sobre os nós identifier-multi-formatter a e extrair os dados deles:
founders_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Fundadores")
founders_nodes = founders_parent_node.find_elements(By.CSS_SELECTOR, "identifier-multi-formatter a")
fundadores = []
para founders_node em founders_nodes:
founders.append(founders_node.text)Por fim, observe o nó de descrição no final da seção “Detalhes”:
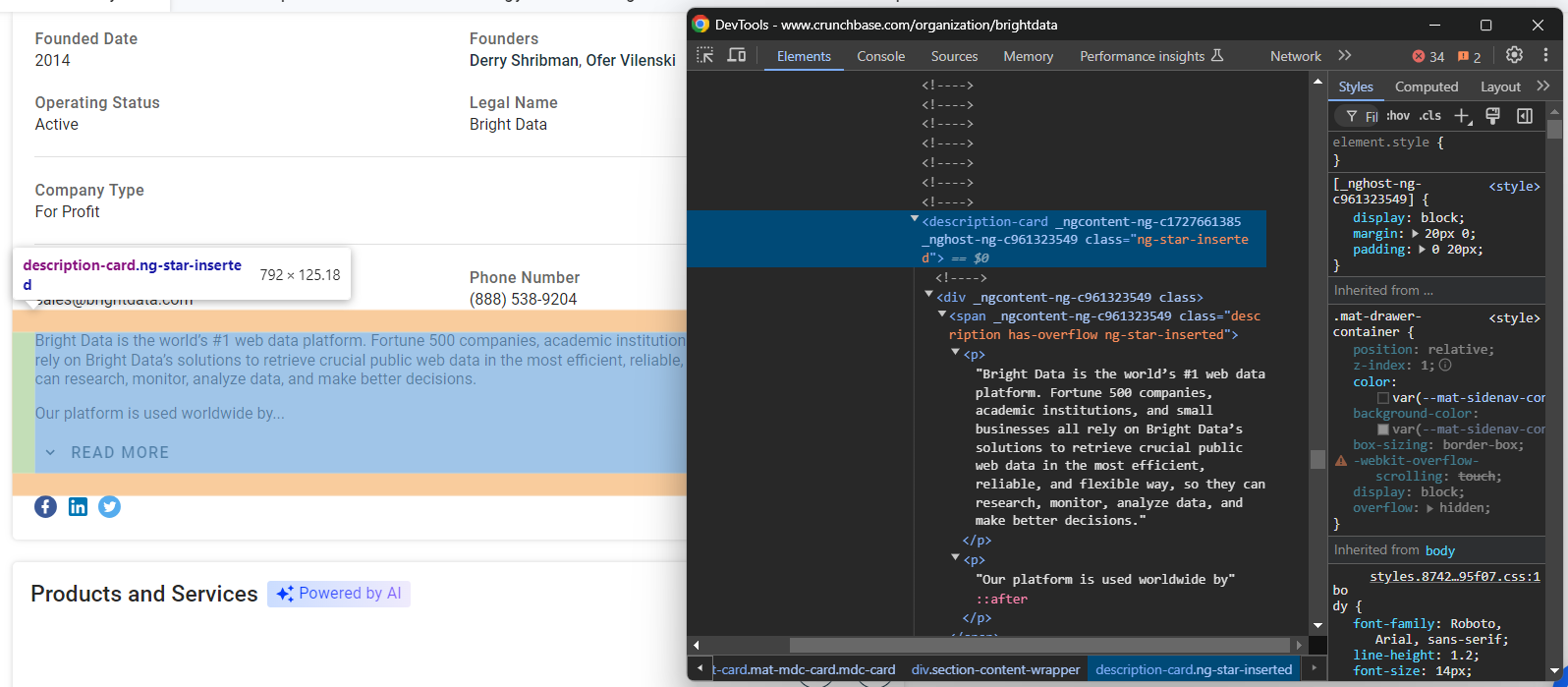
Extraia esses dados com:
description_node = driver.find_element(By.CSS_SELECTOR, "section-card description-card")
description = description_node.textIncrível! Seu Scraper do Crunchbase está quase completo.
Etapa 8: extraia a tabela de produtos e serviços
Outras informações que valem a pena coletar são a lista de produtos e serviços oferecidos pela empresa:
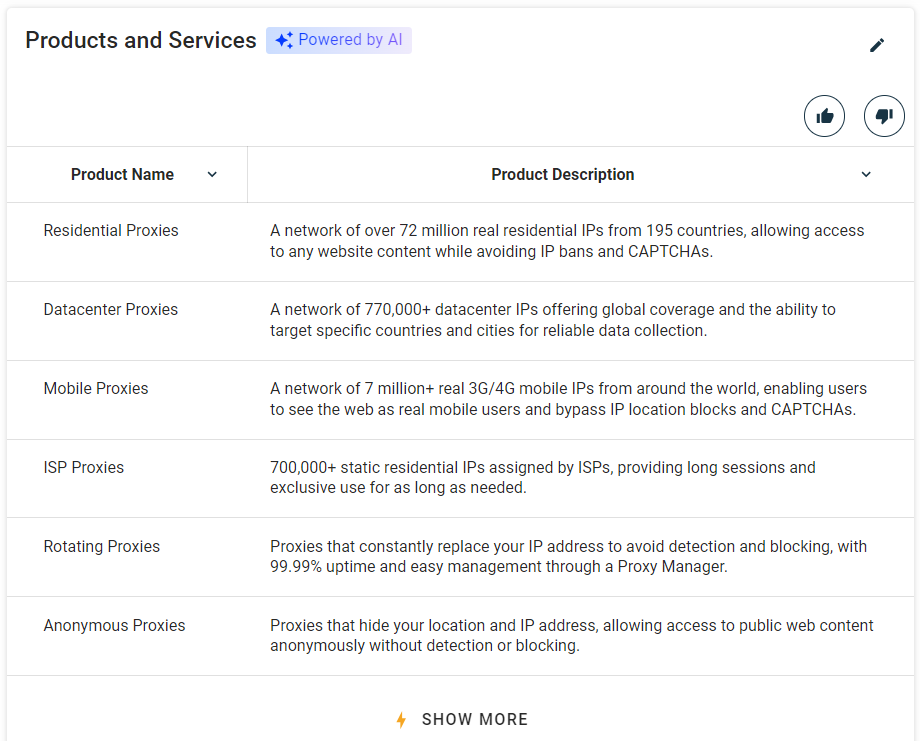
Selecione a seção “Produtos e serviços” usando a função definida anteriormente:
products_parent_node = find_parent_node_based_on_child_node_text("profile-section", ".section-title", "Produtos e serviços")Em seguida, extraia os dados da tabela com:
produtos = []
para linha em linhas_da_tabela_de_produtos:
# extraia o nome e a descrição das colunas de cada linha
nome = linha.find_element(By.CSS_SELECTOR, "td:nth-child(1)").text
descrição = linha.find_element(By.CSS_SELECTOR, "td:nth-child(2)").text
produto = {
"nome": nome,
"descrição": descrição
}
produtos.append(produto)Impressionante! A lógica de scraping do Crunchbase está concluída.
Etapa 9: Exportar os dados extraídos
Preencha um dicionário da empresa com os dados extraídos:
company = {
"about": about,
"industries": industries,
"founded_date": founded_date,
"company_type": company_type,
"operating_status": status_operacional,
"headquarters": sede,
"founders": fundadores,
"email": e-mail_de_contato,
"phone": número_de_telefone,
"description": descrição,
"products": produtos
}Em seguida, exporte-o para um arquivo company.json:
com open("company.json", "w") como json_file:
json.dump(company, json_file, indent=4)Primeiro, open() cria um arquivo de saída company.json. Em seguida, json.dump() transforma company em sua representação JSON e o grava no arquivo de saída.
Lembre-se de importar json da biblioteca padrão do Python:
import jsonEtapa 10: Junte tudo
Aqui está o arquivo scraper.py final:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import json
def find_parent_node_based_on_child_node_text(parent_nodes_selector, child_node_selector, text):
# selecionar todos os nós pai
parent_nodes = driver.find_elements(By.CSS_SELECTOR, parent_nodes_selector)
# iterar pelos nós pai para encontrar aquele
# cujo nó filho específico contém o texto desejado
for parent_node in parent_nodes:
try:
# obter o nó filho específico dentro do nó pai atual
child_node = parent_node.find_element(By.CSS_SELECTOR, child_node_selector)
# verificar se ele contém o texto desejado
if text.upper() in child_node.text.upper():
return parent_node
except:
continue
return None
def handle_cookie_popup(driver, seconds=60):
tente:
# aguarde o número de segundos especificado para que o botão "Aceitar tudo"
# do pop-up de cookies apareça na página
botão_aceitar = WebDriverWait(driver, segundos).até(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))
)
# clicar no pop-up via JavaScript para evitar
# erros ElementClickInterceptedException
driver.execute_script("arguments[0].click();", accept_button)
print("Botão 'Aceitar tudo' clicado")
except:
print("Botão 'Aceitar tudo' não encontrado em {segundos} segundos")
# inicialize o driver para controlar uma instância do Chrome
# no modo headed
driver = webdriver.Chrome()
# navegue até a página desejada do Crunchbase
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)
# lide com o pop-up de cookies, se houver
handle_cookie_popup(driver)
# lógica de scraping
about_node = driver.find_element(By.CSS_SELECTOR, "profile-section description-card")
about = about_node.text
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")
industries_nodes = industries_parent_node.find_elements(By.CSS_SELECTOR, "chips-container a")
industries = []
para industry_node em industries_nodes:
industries.append(industry_node.text)
founded_date_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Data de fundação")
founded_date_node = founded_date_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
founded_date = founded_date_node.text
nó_pai_tipo_de_empresa = encontrar_nó_pai_com_base_no_texto_do_nó_filho("campos-cartão li", "rótulo-com-informações", "Tipo de empresa")
nó_tipo_de_empresa = nó_pai_tipo_de_empresa.encontrar_elemento(By.CSS_SELECTOR, "formatação_de_campo")
tipo_de_empresa = nó_tipo_de_empresa.texto
operating_status_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Status operacional")
operating_status_node = operating_status_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
operating_status = operating_status_node.text
headquarters_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Regiões da sede")
headquarters_node = headquarters_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
headquarters = headquarters_node.text
fundadores_nó_pai = encontrar_nó_pai_com_base_no_texto_do_nó_filho("campos-cartão li", "rótulo-com-informações", "Fundadores")
fundadores_nós = fundadores_nó_pai.encontrar_elementos(By.CSS_SELECTOR, "identificador-multi-formatador a")
fundadores = []
para founders_node em founders_nodes:
fundadores.append(fundadores_node.text)
legal_name_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Nome Legal")
legal_name_node = legal_name_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
legal_name = legal_name_node.text
contact_email_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Contact Email")
contact_email_node = contact_email_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
contact_email = contact_email_node.text
phone_number_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Número de telefone")
phone_number_node = phone_number_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
phone_number = phone_number_node.text
description_node = driver.find_element(By.CSS_SELECTOR, "section-card description-card")
description = description_node.text
nó pai dos produtos = encontrar_nó pai_com_base_no_texto_do_nó filho("seção do perfil", ".section-title", "Produtos e serviços")
linhas da tabela de produtos = nó pai dos produtos.encontrar_elementos(By.CSS_SELECTOR, "table tbody tr")
# extrair a tabela de produtos
produtos = []
para linha em linhas_da_tabela_de_produtos:
# extrair o nome e a descrição das colunas de cada linha
nome = linha.find_element(By.CSS_SELECTOR, "td:nth-child(1)").text
descrição = linha.find_element(By.CSS_SELECTOR, "td:nth-child(2)").text
produto = {
"nome": nome,
"descrição": descrição
}
produtos.append(produto)
# preencher um dicionário com os dados extraídos
empresa = {
"sobre": sobre,
"setores": setores,
"data_fundação": data_fundação,
"company_type": company_type,
"operating_status": operating_status,
"headquarters": headquarters,
"founders": founders,
"email": contact_email,
"phone": phone_number,
"description": description,
"products": products
}
# exportar os dados coletados para um arquivo JSON
com open("company.json", "w") como json_file:
json.dump(company, json_file, indent=4)
# fechar o driver e liberar os recursos do navegador
driver.quit()Em pouco mais de 100 linhas de código, você acabou de criar um Scraper do Crunchbase em Python!
Execute o script com o seguinte comando:
python3 script.pyOu, no Windows:
python script.pyUm arquivo company.json aparecerá na pasta do seu projeto. Abra-o e você verá:
{
"about": "A plataforma de dados da Web nº 1 do mundo",
"industries": [
"Business Intelligence",
"Serviços de dados em nuvem",
"Computador",
"Coleta e rotulagem de dados",
"Tecnologia da informação",
"Infraestrutura de TI",
"Segurança de rede",
"SaaS",
"Software"
],
"founded_date": "2014",
"tipo_de_empresa": "Com fins lucrativos",
"status_operacional": "Ativo",
"sede": "Grande Nova York, Costa Leste, Nordeste dos EUA",
"fundadores": [
"Derry Shribman",
"Ofer Vilenski"
],
"email": "[email protected]",
"telefone": "(888) 538-9204",
"descrição": "Proxies que ocultam sua localização e endereço IP, permitindo o acesso a conteúdo público da web anonimamente, sem detecção ou bloqueio.",
"produtos": [
{
"nome": "Proxies residenciais",
"descrição": "Uma rede de 400M+ monthly IPs residencialis reais de 195 países, permitindo o acesso a qualquer conteúdo de site, evitando proibições de IP e CAPTCHAs."
},
{
"name": "Proxies de datacenter",
"description": "Uma rede de mais de 770.000 IPs de datacenter que oferece cobertura global e a capacidade de segmentar países e cidades específicos para uma coleta de dados confiável."
},
{
"name": "Proxies móveis",
"description": "Uma rede de mais de 7 milhões de IPs móveis 3G/4G reais de todo o mundo, permitindo que os usuários vejam a web como usuários móveis reais e contornem bloqueios de localização de IP e CAPTCHAs."
},
{
"name": "Proxies ISP",
"description": "Mais de 700.000 IPs residencialis estáticos atribuídos por ISPs, proporcionando sessões longas e uso exclusivo pelo tempo que for necessário."
},
{
"name": "Proxies rotativos",
"description": "Proxies que substituem constantemente seu endereço IP para evitar detecção e bloqueio, com 99,99% de tempo de atividade e fácil gerenciamento por meio de um gerenciador de proxy."
},
{
"name": "Proxies anônimos",
"description": "Proxies que ocultam sua localização e endereço IP, permitindo o acesso a conteúdo público da web de forma anônima, sem detecção ou bloqueio."
}
]
}Esses são os dados disponíveis na página da empresa Bright Data no Crunchbase.
Et voilà! Você acabou de aprender como fazer Scraping de dados no Crunchbase usando Python.
Desbloqueando os dados do Crunchbase com facilidade
O Crunchbase fornece uma grande quantidade de dados valiosos, mas também toma medidas extensivas para protegê-los de Scrapers e bots automatizados. Ao interagir com o site usando um navegador headless ou realizar determinadas ações, você pode encontrar páginas 403 Forbidden ou CAPTCHAs.
Como primeiro passo, você pode consultar nosso guia sobre como contornar CAPTCHAs em Python. No entanto, o Crunchbase emprega soluções anti-scraping avançadas adicionais que ainda podem levar a bloqueios.
Sem as ferramentas certas, o scraping do Crunchbase pode rapidamente se tornar uma experiência lenta e frustrante. A melhor solução é a API dedicada Crunchbase Scraper da Bright Data. Recupere dados do Crunchbase sem ser bloqueado!
Conclusão
Neste tutorial passo a passo, você aprendeu o que é um Scraper do Crunchbase e os tipos de dados que ele pode recuperar. Você também viu como criar um script Python para fazer scraping do Crunchbase para obter dados gerais da empresa, o que exigiu apenas cerca de 150 linhas de código.
O problema é que o Crunchbase adota medidas rigorosas contra bots e scripts automatizados. CAPTCHAs, impressões digitais do navegador e proibições de IP são apenas algumas das defesas usadas para impedir o scraping. Esqueça todos esses desafios com nossa API Crunchbase Scraper.
Se o Scraping de dados da web não é para você, mas ainda assim está interessado nos dados do Crunchbase, explore nossos Conjuntos de dados do Crunchbase!
Fale com um de nossos especialistas para descobrir qual das soluções da Bright Data melhor atende às suas necessidades.




