

Neste tutorial, você verá:
- A definição de um Scraper de reservas
- Quais dados você pode extrair com ele
- Como criar um script de scraping do Booking.com com Python
Vamos começar!
O que é um scraper do Booking?
Um scraper do Booking.com é uma ferramenta para extrair automaticamente dados das páginas do Booking.com. Ele permite recuperar informações das páginas de listagem de propriedades, como nomes de hotéis, preços, avaliações, classificações, comodidades e disponibilidade. Esses dados podem ser usados para diversos fins, incluindo análise de mercado, comparação de preços e criação de Conjuntos de dados relacionados a viagens.
Dados que você pode extrair do Booking.com
Abaixo está uma lista de pontos de dados que você pode recuperar do Booking.com:
- Detalhes da propriedade: nome do hotel, endereço, distância de pontos de referência (por exemplo, centro da cidade, centro comercial, etc.)
- Informações sobre preços: preço normal, preço com desconto (se disponível)
- Avaliações e classificações: pontuação da avaliação, número de avaliações, feedback dos hóspedes
- Disponibilidade: tipos de quartos disponíveis, opções de reserva (por exemplo, cancelamento gratuito, café da manhã incluído), datas com disponibilidade
- Mídia: imagens da propriedade, imagens dos quartos
- Comodidades: instalações oferecidas (por exemplo, Wi-Fi, estacionamento, piscina), comodidades específicas do quarto
- Promoções: ofertas especiais ou descontos, ofertas por tempo limitado
- Políticas: política de cancelamento, horários de check-in e check-out
- Detalhes adicionais: descrição da propriedade, atrações próximas, número de quartos disponíveis para datas específicas
Raspagem do Booking.com em Python: guia passo a passo
Nesta seção guiada, você aprenderá como criar um Scraper do Booking.com.
O objetivo é criar um script Python que reúna automaticamente os dados da página de listagem de propriedades:
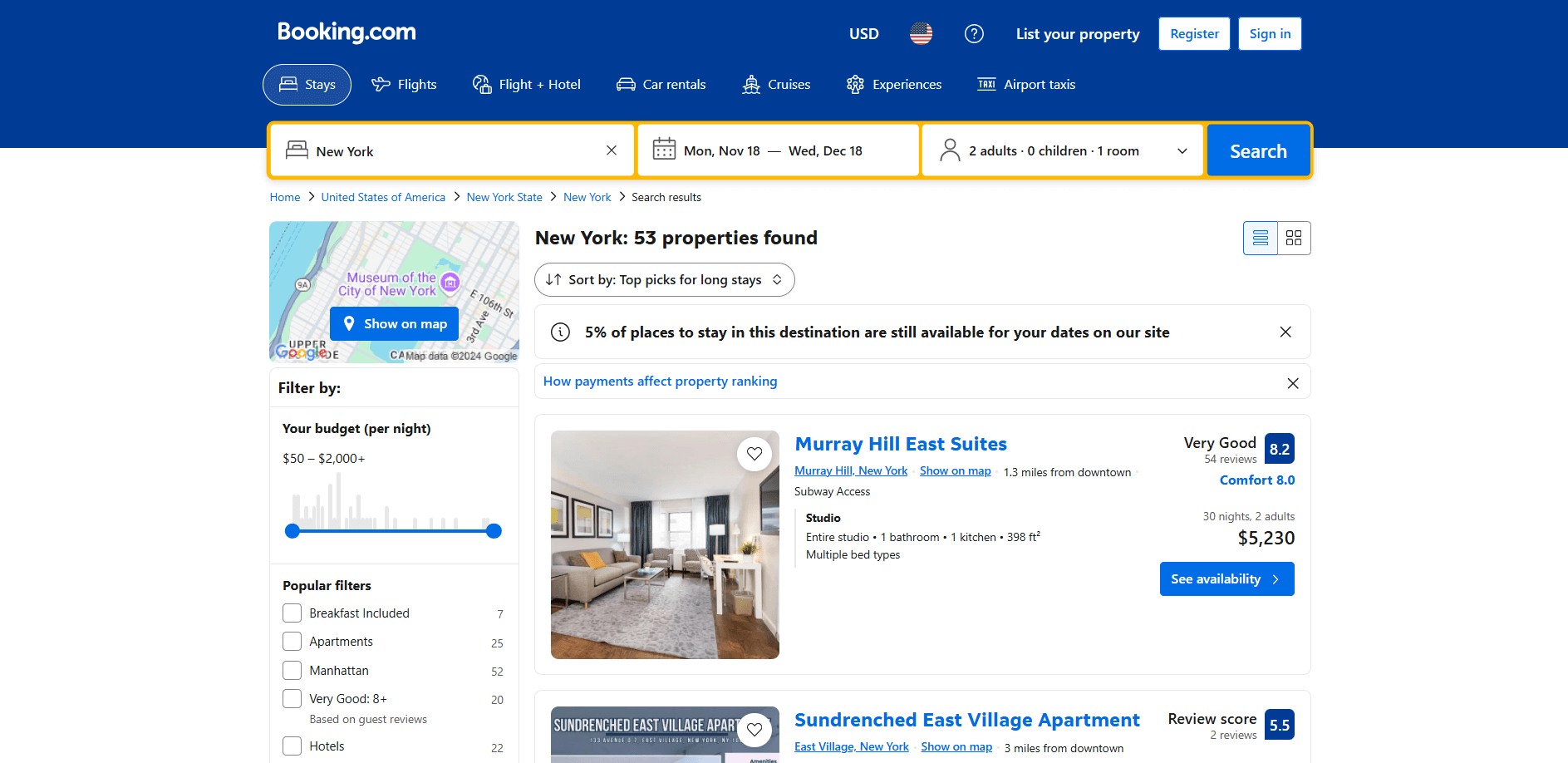
Siga as etapas abaixo!
Etapa 1: Configuração do projeto
Antes de começar, certifique-se de que o Python 3 esteja instalado em seu computador. Se não estiver, baixe-o, execute o arquivo executável e siga o assistente de instalação.
Agora, use os comandos abaixo para criar uma pasta para o seu projeto:
mkdir booking-scraper
O diretório booking-scraper representa a pasta do projeto do seu script Python para extrair dados do Booking.com.
Entre nela e inicialize um ambiente virtual dentro dela:
cd booking-Scraper
python -m venv env
Carregue a pasta do projeto em seu IDE Python favorito. O Visual Studio Code com a extensão Python e o PyCharm Community Edition são ótimas opções.
Crie um arquivo scraper.py na pasta do projeto, que deve conter esta estrutura de arquivos:
O Scraper.py agora é um script Python em branco, mas em breve conterá a lógica de scraping.
No terminal do IDE, ative o ambiente virtual. Para fazer isso, no Linux ou macOS, execute este comando:
./env/bin/activate
De forma equivalente, no Windows, execute:
env/Scripts/activate
Incrível, agora você tem um ambiente Python para Scraping de dados!
Etapa 2: selecione a biblioteca de scraping
É hora de determinar se o Booking.com é um site estático ou dinâmico e selecionar a biblioteca de scraping apropriada de acordo com isso. Isso pode ser feito inspecionando o comportamento do site. Comece abrindo o Booking.com no seu navegador. Faça uma pesquisa e navegue até a página da propriedade:
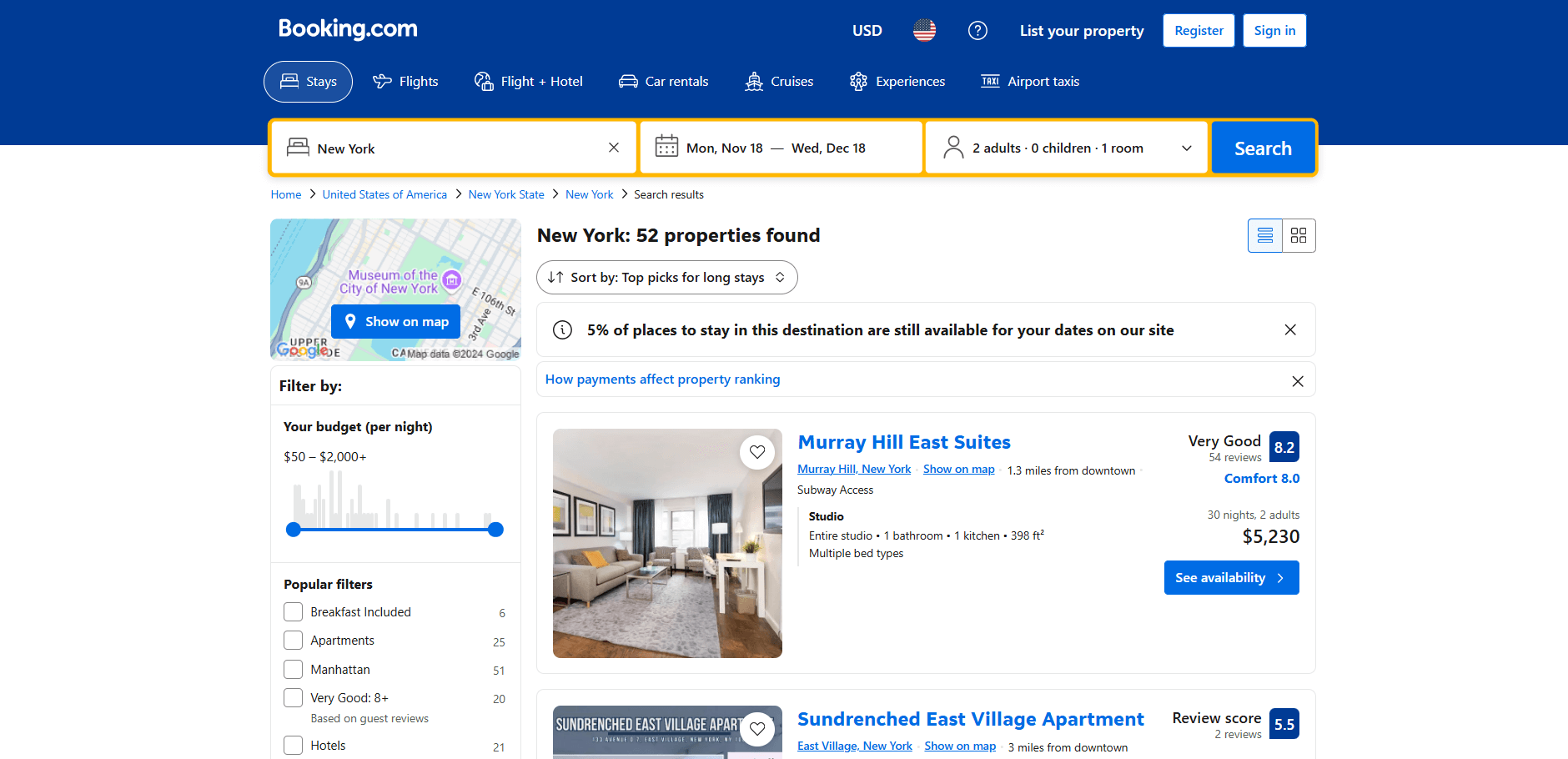
Observe que a página carrega novos dados dinamicamente à medida que você rola para baixo:
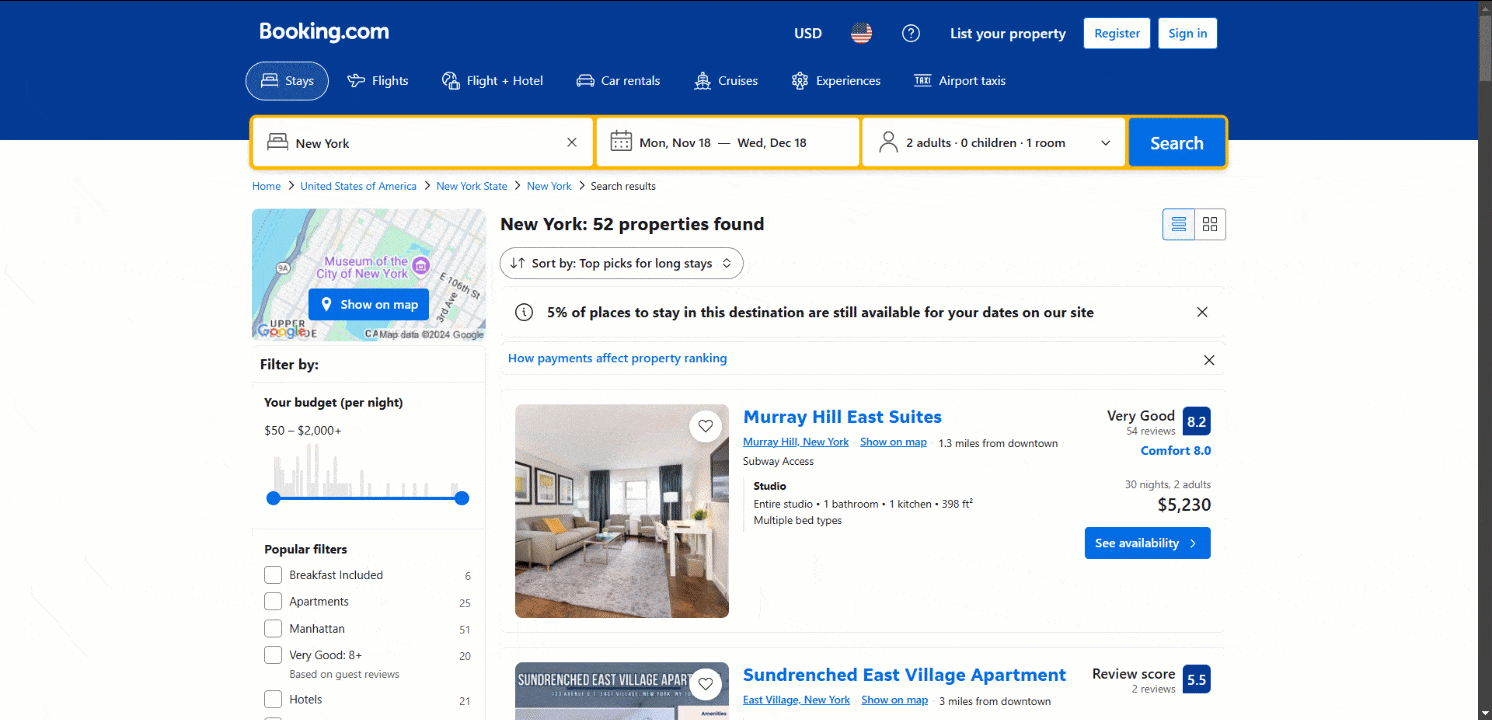
Esse padrão é conhecido como rolagem infinita e é uma característica dos sites dinâmicos. Saiba mais sobre como realizar Scraping de dados em sites dinâmicos.
Sem nem mesmo mergulhar no código HTML do documento retornado pelo servidor ou inspecionar a guia Rede no DevTools (duas etapas comuns para entender se um site é estático ou não), já podemos concluir que o Booking.com é um site dinâmico.
A melhor abordagem para fazer scraping em um site de conteúdo dinâmico é usar uma ferramenta de automação de navegador. Essas soluções permitem controlar um navegador e realizar interações específicas na página para extrair dados de maneira eficaz.
Uma das ferramentas de automação de navegador mais poderosas para Python é o Selenium, tornando-o uma excelente escolha para fazer scraping no Booking.com. Prepare-se para instalá-lo, pois será a biblioteca principal para esta tarefa!
Etapa 3: Instalar e configurar o Selenium
Em Python, o Selenium está disponível através do pacote selenium pip. Em um ambiente virtual Python ativado, instale-o com este comando:
pip install selenium
Para obter orientações sobre como usar a ferramenta, leia nosso tutorial sobre Scraping de dados com o Selenium.
Importe o Selenium em scraper.py e inicialize um objeto WebDriver para controlar uma instância do Chrome:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# crie uma instância do Chrome Web Driver
driver = webdriver.Chrome(service=Service())
O código acima inicializa uma instância do Chrome WebDriver para controlar um navegador Chrome. Observe que o Booking.com parece usar uma tecnologia anti-scraping que bloqueia navegadores headless. Portanto, evite definir o sinalizador --headless. Como solução alternativa, leia nosso guia sobre Playwright Stealth.
Na última linha do seu Scraper, lembre-se de fechar o web driver:
driver.quit()
Ótimo! Agora você está totalmente configurado para começar a fazer scraping no Booking.com.
Etapa 4: visite a página de destino
As páginas do Booking.com oferecem vários recursos interativos para refinar sua pesquisa:
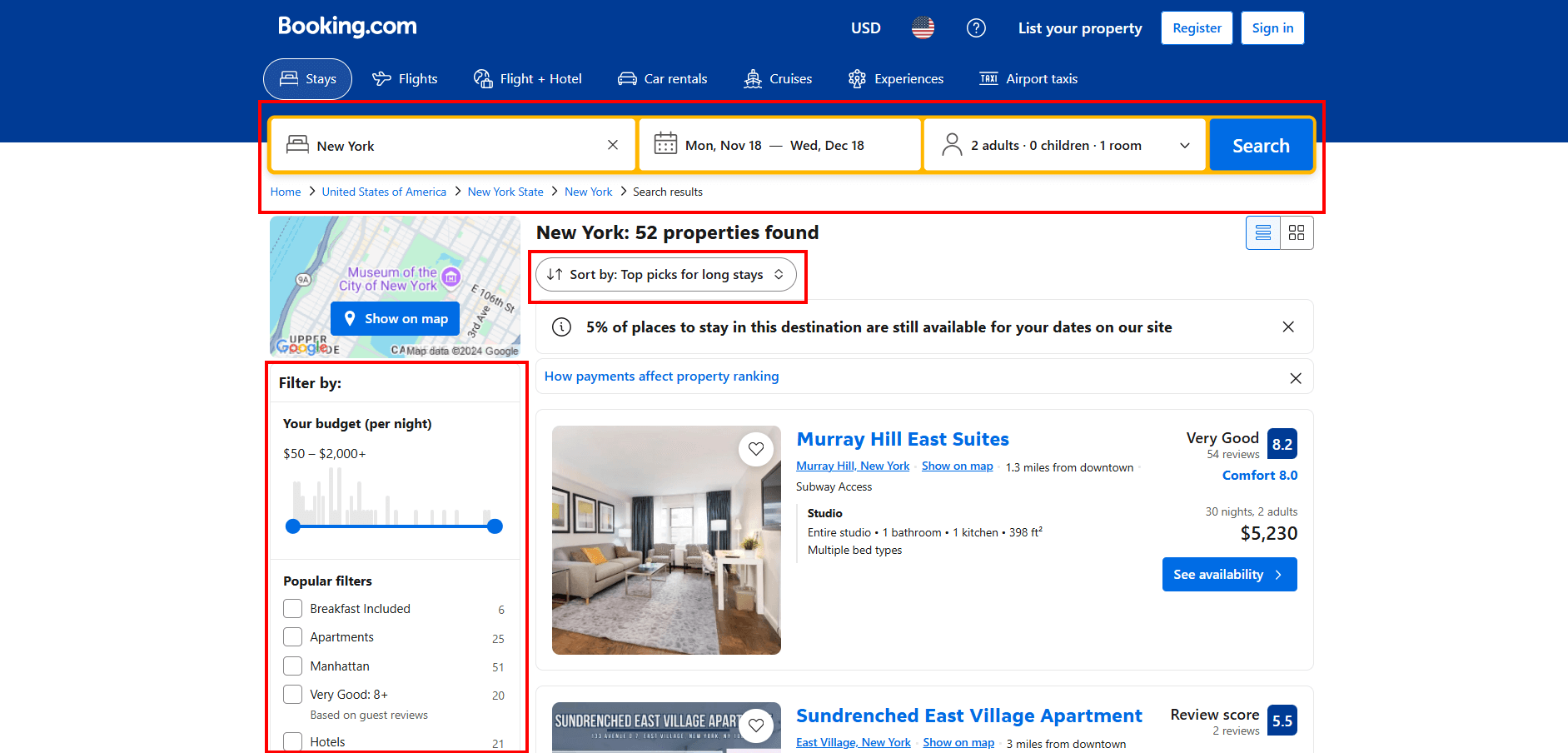
Simular todas essas interações programaticamente com o Selenium seria complexo e demorado. Portanto, para simplificar e acelerar o processo, execute as interações manualmente no seu navegador primeiro.
Depois de configurar uma consulta de pesquisa de seu interesse, copie o URL da página resultante da barra de endereços do seu navegador.
Por exemplo, o URL acima representa uma pesquisa por apartamentos em Nova York de 18 de novembro a 18 de dezembro para dois adultos.
Copie o URL e insira-o no método get() oferecido pelo Selenium:
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
Seu script de scraping se conectará automaticamente à página desejada do Booking.com.
O arquivo scraper.py agora conterá estas linhas de código:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# criar uma instância do driver web Chrome
driver = webdriver.Chrome(service=Service())
# conectar-se à página de destino
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
# lógica de scraping...
# fechar o driver da web e liberar seus recursos
driver.quit()
Coloque um ponto de interrupção de depuração na linha final e execute o script. Abaixo está o que você deve ver:
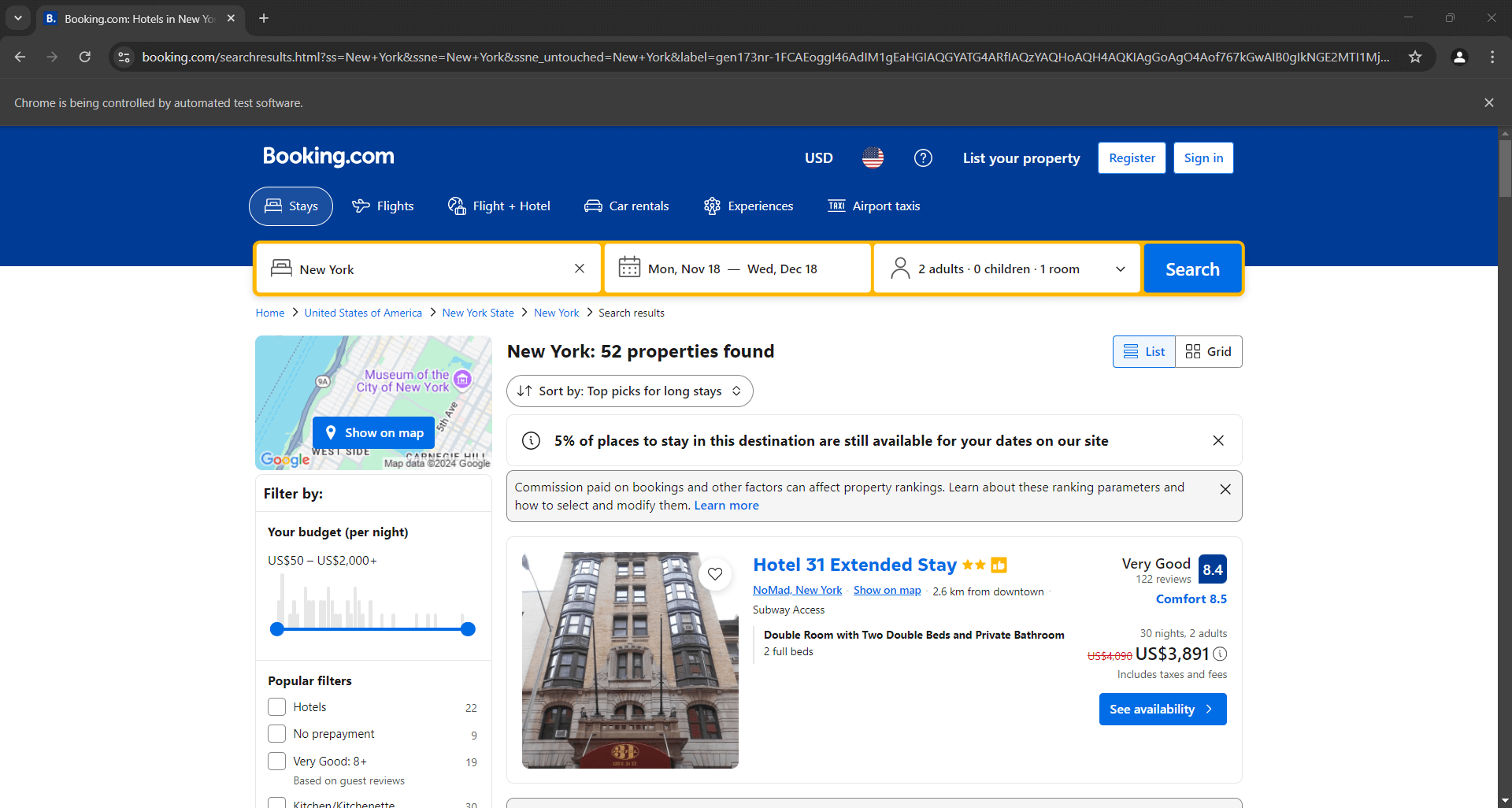
A mensagem “O Chrome está sendo controlado por um software de teste automatizado” certifica que o Selenium está operando no Chrome conforme desejado. Muito bem!
Etapa 5: lidar com o alerta de login
Quando você visita o Booking.com pela primeira vez em um navegador, o site geralmente exibe um alerta de login nos primeiros 20 segundos. Isso bloqueia o acesso ao conteúdo da página, dificultando o Scraping de dados da web:
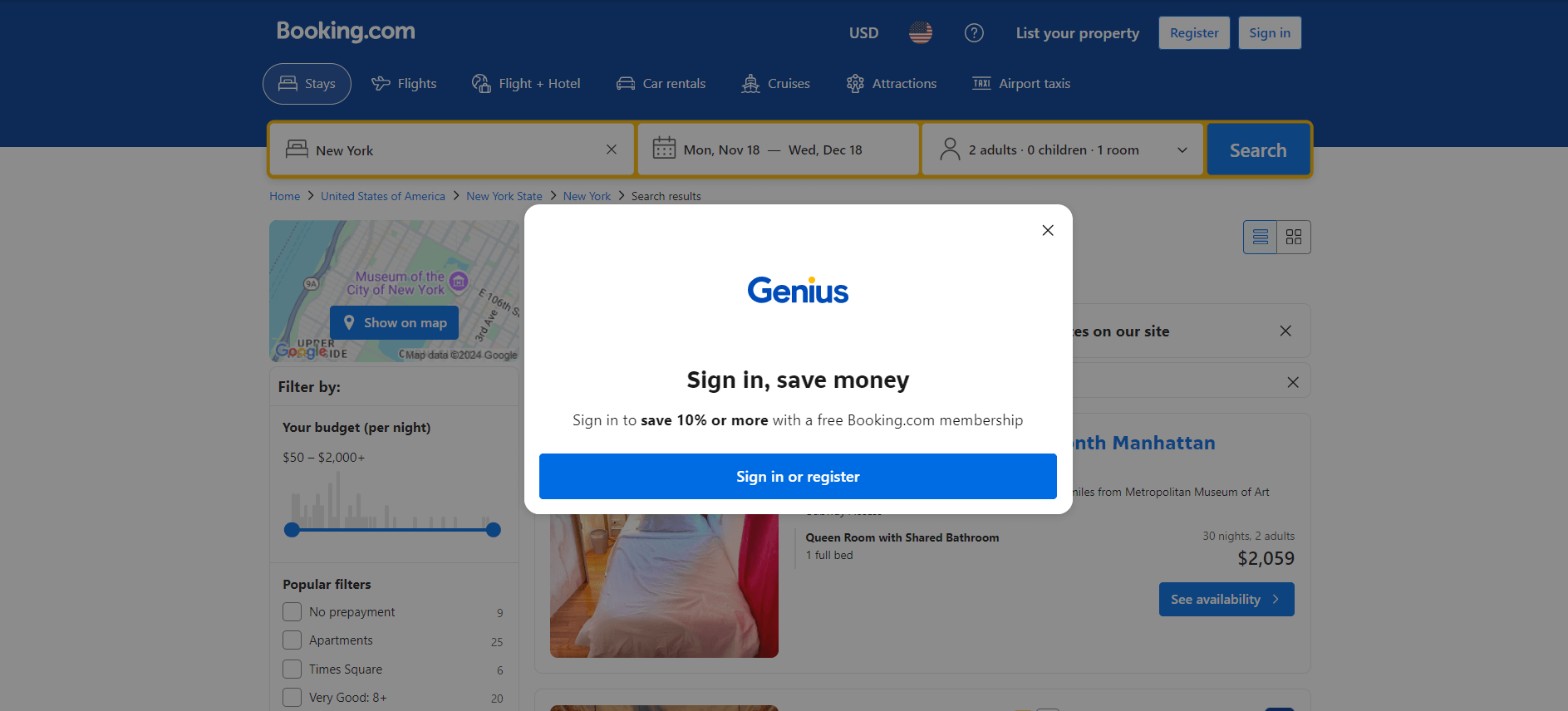
Até que você interaja com ele, não será possível acessar o conteúdo da página subjacente.
Para lidar com o alerta, feche-o usando o Selenium. Clique com o botão direito do mouse no botão Fechar e selecione a opção “Inspecionar” no menu de contexto:
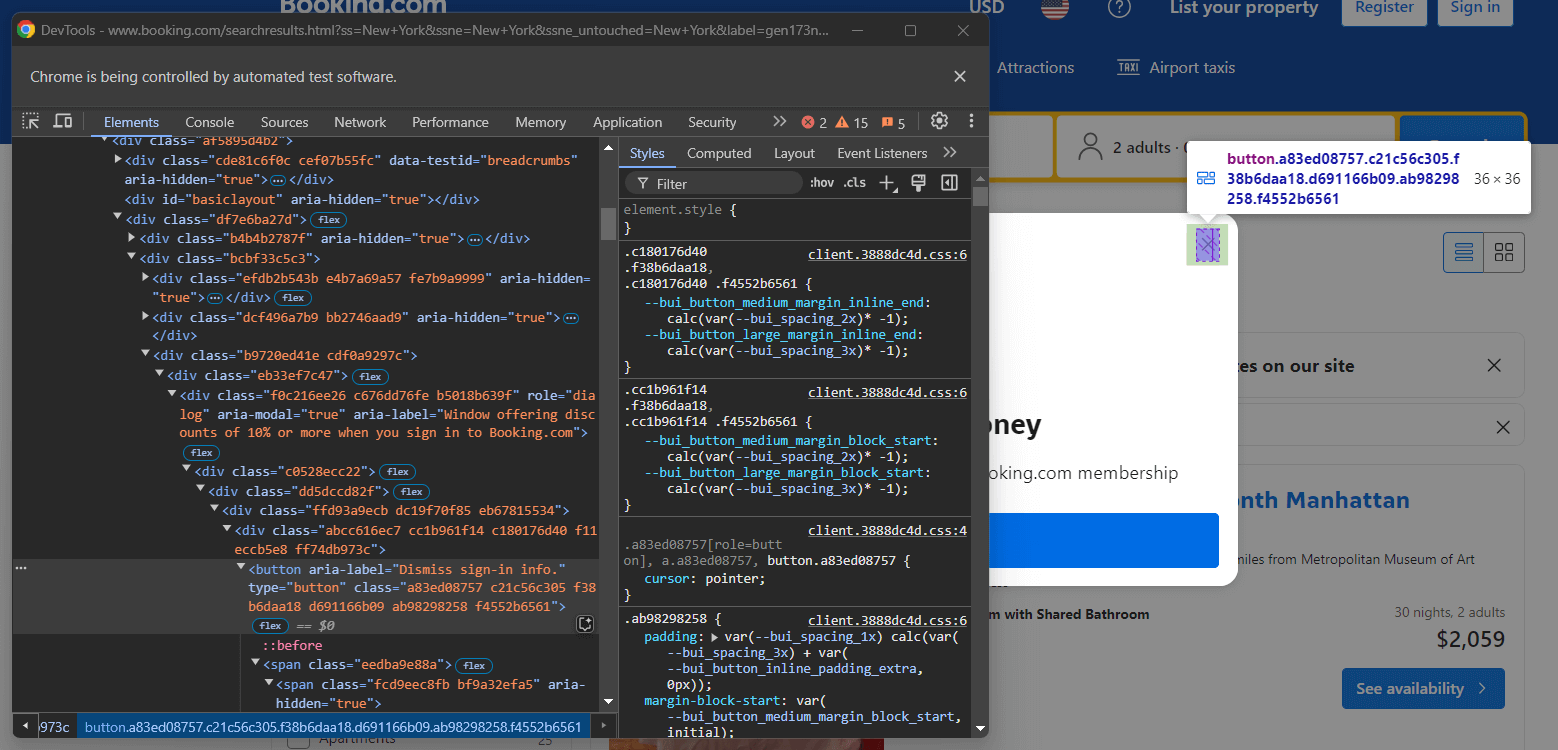
Observe que você pode fechar o modal selecionando o botão com o seguinte seletor CSS:
[role="dialog"] button[aria-label="Ignorar informações de login."]
Agora, instrua o Selenium a esperar até 10 segundos para que o alerta apareça. Quando ele aparecer, feche-o clicando no botão de descarte. Como o modal pode não aparecer sempre, faz sentido envolver essa lógica em um bloco try...except:
try:
# aguarde até 20 segundos para que o alerta de login apareça
close_button = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[role="dialog"] button[aria-label="Dismiss sign-in info."]"))
)
# clicar no botão Fechar
close_button.click()
except TimeoutException:
print("O modal de login não apareceu, continuando...")
WebDriverWait é uma classe Selenium especializada que pausa o script até que uma condição especificada na página seja atendida. No exemplo acima, ele espera até 10 segundos para que o botão Fechar do alerta apareça na página.
Se o alerta não aparecer, o Selenium gera a exceção TimeoutException. Importe-a junto com WebDriverWait, EC e By, conforme abaixo:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
Ótimo! O alerta de login não é mais um problema.
Etapa 6: Selecione os itens do Booking.com
Observe que a página do Booking.com a ser extraída contém vários itens. Como você deseja extrair todos eles, inicialize uma matriz onde armazenar os dados extraídos:
items = []
Agora, você precisa entender como selecionar os elementos HTML associados a esses itens. Abra o Booking.com no seu navegador, faça uma pesquisa e inspecione um dos itens da propriedade:
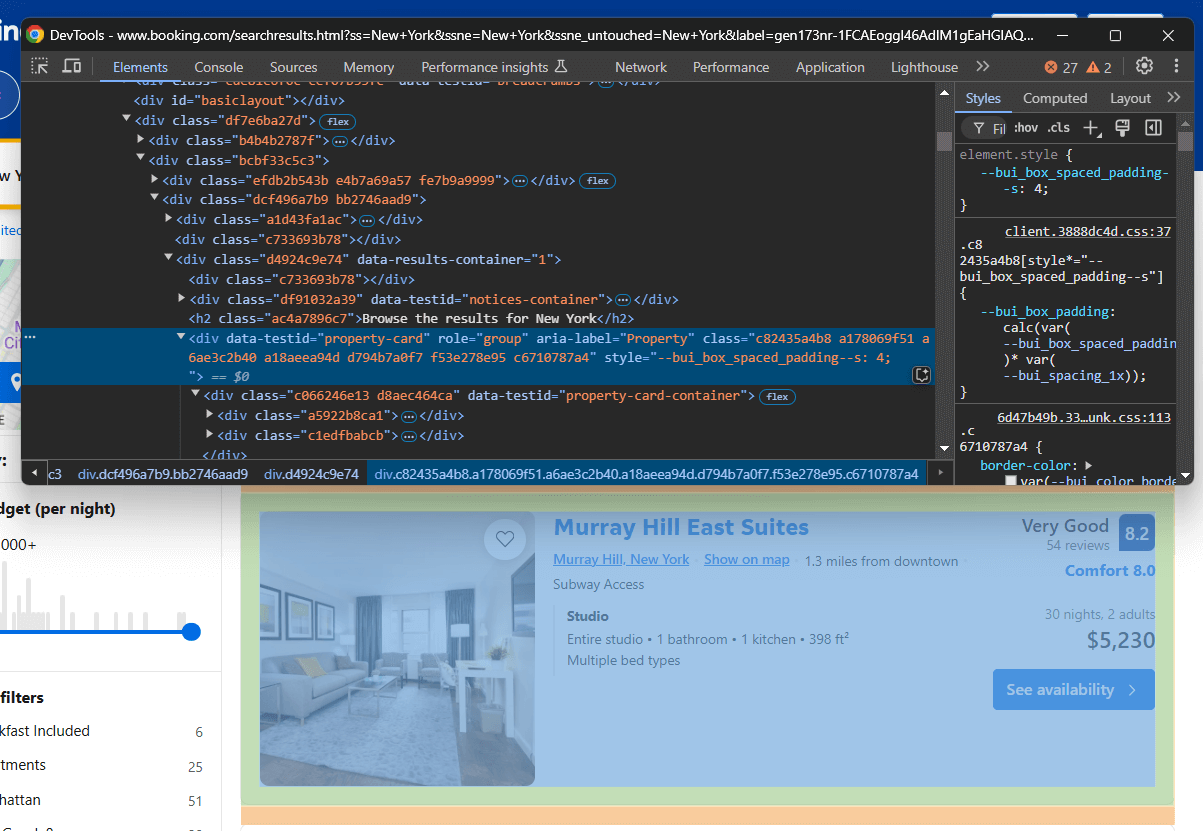
Observe que as classes dos elementos HTML parecem ser geradas aleatoriamente. Isso significa que elas provavelmente mudarão a cada implantação do site, tornando-as pouco confiáveis para a seleção de elementos. Em vez disso, concentre-se em atributos mais estáveis, como data-testid.
Os atributosdata-* são excelentes alvos para Scraping de dados.
Use o método find_elements() do Selenium para aplicar um seletor CSS na página e selecionar os elementos de interesse:
property_items = driver.find_elements(By.CSS_SELECTOR, "[data-testid="property-card"]")
Itere sobre os itens de propriedade e prepare seu Scraper do Booking.com para extrair alguns dados:
para item_de_propriedade em itens_de_propriedade:
# lógica de scraping...
Ótimo! O próximo passo é extrair dados desses elementos.
Etapa 7: extrair os itens do Booking.com
Observe os itens da propriedade na página e perceba que os elementos que eles contêm são inconsistentes:
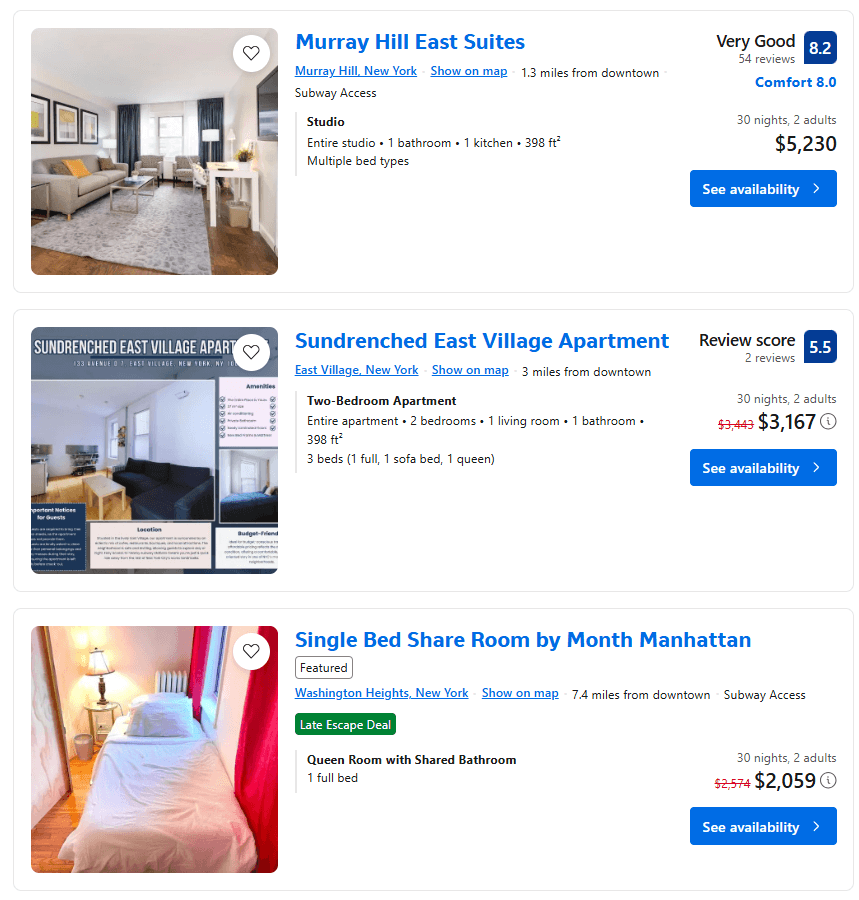
Alguns têm uma pontuação de avaliação, enquanto outros não. Novamente, alguns têm um preço com desconto, enquanto outros não.
Essas diferenças dificultam a criação de uma lógica de extração consistente para todos os itens da propriedade. Quando você tenta selecionar um elemento que não está na página, o Selenium gera uma exceção NoSuchElementException. Portanto, faz sentido definir uma função para lidar com esse cenário:
def handle_no_such_element_exception(data_extraction_task):
try:
return data_extraction_task()
except NoSuchElementException as e:
return None
A função acima aceita uma função lambda e tenta executá-la. Se ela gerar uma NoSuchElementException, ela captura a exceção e retorna None. Isso permite que seu script de scraping do Booking.com continue sem interromper.
Importar NoSuchElementException:
from selenium.common import NoSuchElementException
Inspecione um item de propriedade que contenha todos os elementos (pontuação da avaliação, preço com desconto e assim por diante):
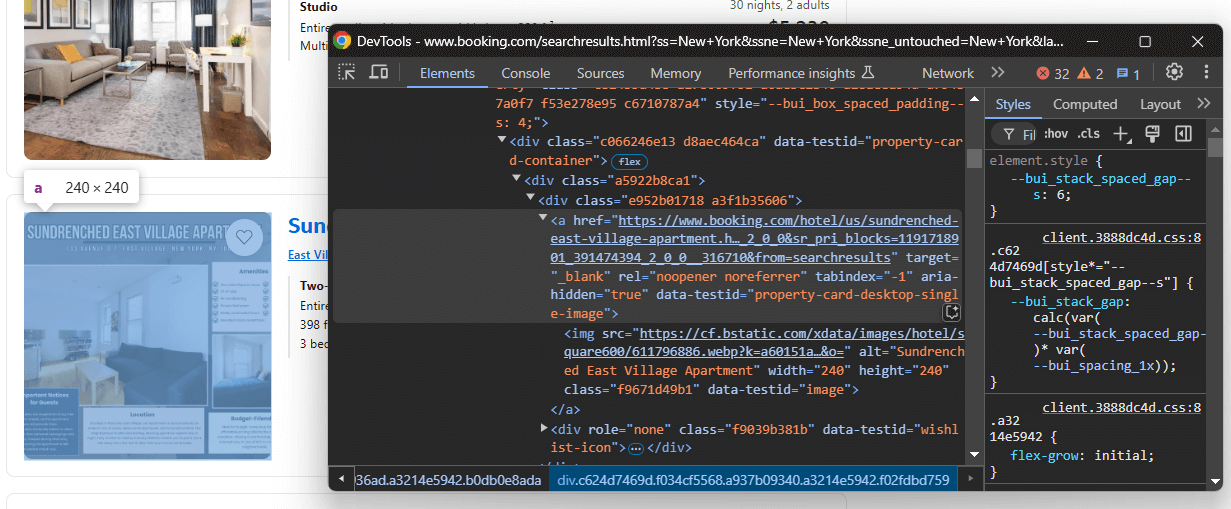
Observe que você pode extrair:
- O link da propriedade de
a[data-testid="property-card-desktop-single-image"] - A imagem da propriedade de
img[data-testid=image]
No loop for, aplique a lógica atual para selecionar esses elementos e extrair dados deles:
url = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "a[data-testid="property-card-desktop-single-image"]").get_attribute("href"))
image = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "img[data-testid="image"]").get_attribute("src"))
find_element() seleciona um único nó na página, enquanto get_attribute() obtém o conteúdo dentro do atributo HTML especificado. Observe que as instruções de extração de dados são envolvidas por handle_no_such_element_exception para lidar com NoSuchElementExceptions.
Da mesma forma, concentre-se nas informações na seção do título e logo abaixo dela:
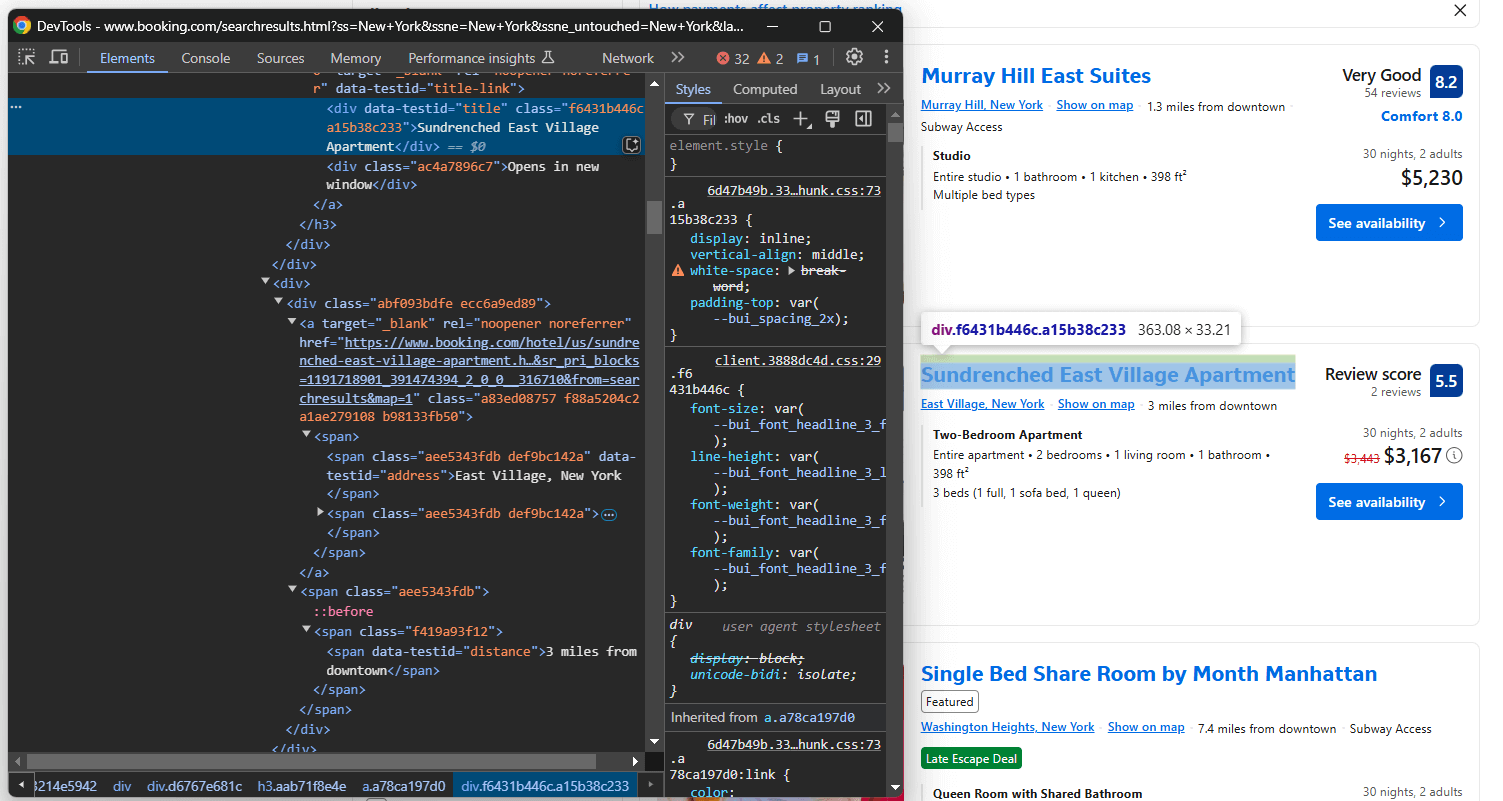
Aqui, você pode obter:
- O título da propriedade de
[data-testid="title"] - A propriedade endereço de
[data-testid="address"] - A propriedade distance de
[data-testid="distance"]
Extraia todas elas com:
title = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="title"]").text)
address = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="address"]").text)
distance = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="distance"]").text)
O atributo text contém o texto dentro dos elementos selecionados.
Em seguida, concentre-se no nó da pontuação da avaliação:
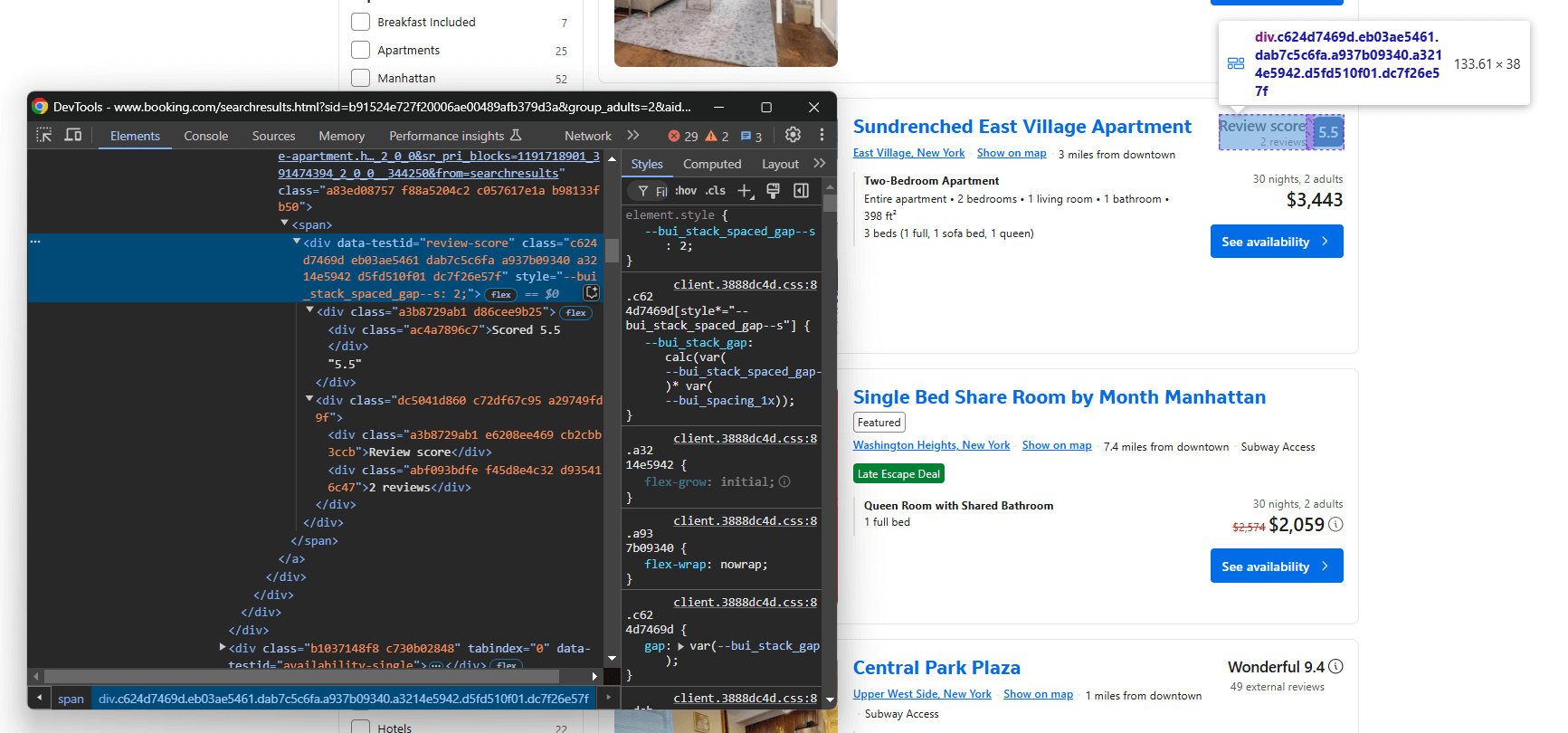
Selecione-o com data-testid="review-score" e extraia seu texto. Considere que o texto tem um formato especial, como neste exemplo:
'Pontuação 8,4n8,4nMuito bomn120 avaliações'
Com alguma lógica personalizada, você pode extrair a pontuação da avaliação e a contagem de avaliações a partir dele:
pontuação_da_avaliação = None
contagem_de_avaliações = None
texto_da_avaliação = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="review-score"]").text)
if texto_da_avaliação is not None:
# dividir a string da avaliação por n
partes = texto_da_avaliação.split("n")
# processe cada parte
for part in parts:
part = part.strip()
# verifique se esta parte é um número (pontuação potencial da avaliação)
if part.replace(".", "", 1).isdigit():
review_score = float(part)
# verificar se contém a string “reviews”
elif “reviews” in part:
# extrair o número antes de “reviews”
review_count = int(part.split(“ ”)[0].replace(“,”, ”))
Segmente o elemento de descrição:
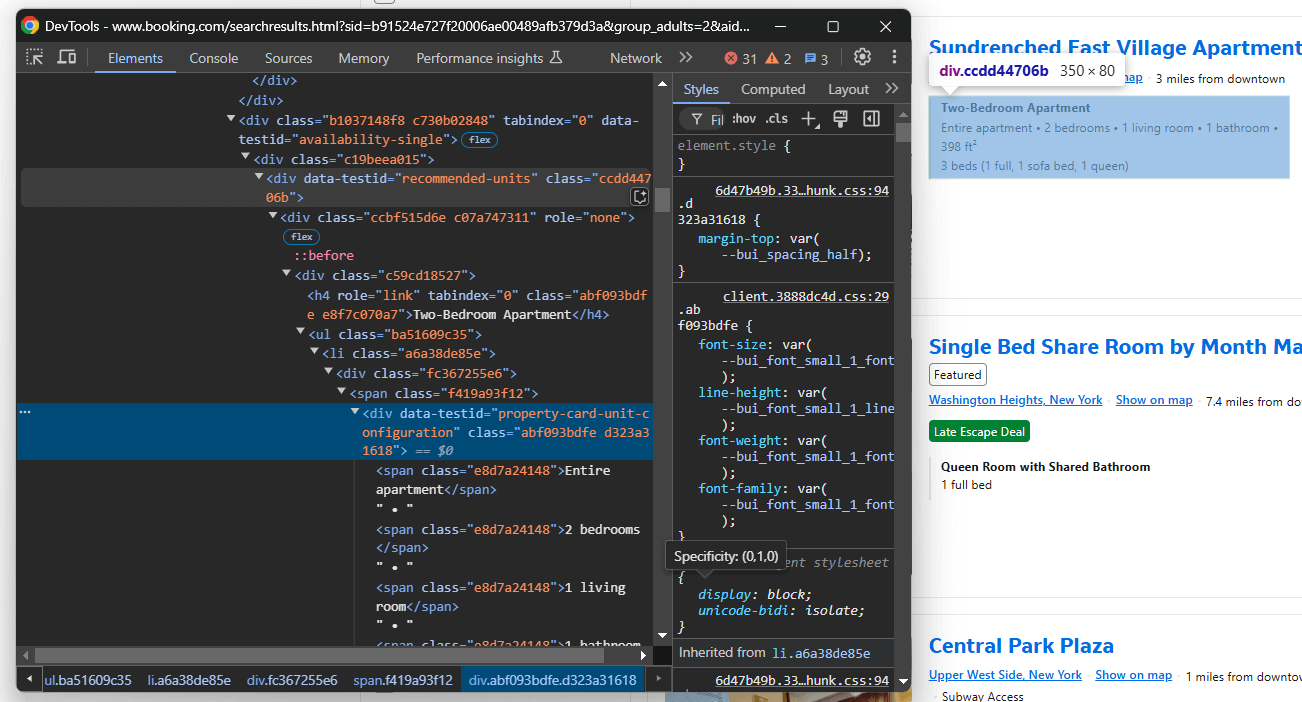
Selecione-o com data-testid="units-recomendadas" e extraia a descrição:
description = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="recommended-units"]").text)
Por último, concentre-se nos elementos de preço:
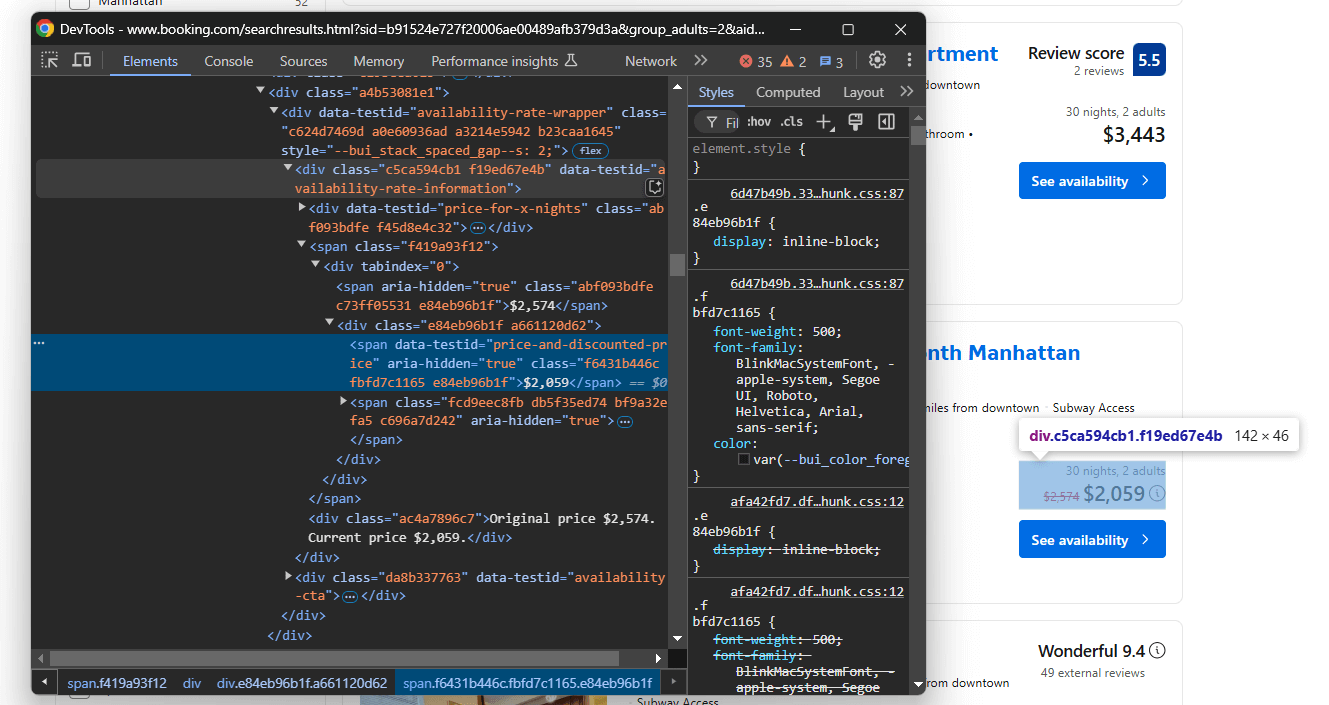
No elemento data-testid="availability-rate-information", selecione:
- O preço original do nó que tem o atributo
aria-hidden="true"e não tem o atributodata-testid - O preço com desconto/atual do
data-testid="price-and-discounted-price"
Escreva a lógica de extração de preço conforme abaixo:
price_element = handle_no_such_element_exception(lambda: (property_item.find_element(By.CSS_SELECTOR, "[data-testid="availability-rate-information"]")))
if price_element is not None:
original_price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[aria-hidden="true"]:not([data-testid])").text.replace(",", "")
))
preço = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[data-testid="price-and-discounted-price"]").text.replace(",", "")
))
Uau! A lógica de scraping do Booking.com está quase completa.
Etapa 7: coletar os dados extraídos
Agora você tem os dados coletados espalhados por várias variáveis dentro do loop for. Crie um novo objeto item, preencha-o com esses dados e acrescente-o à matriz de itens:
item = {
"url": url,
"image": image,
"title": title,
"address": address,
"distance": distance,
"review_score": review_score,
"review_count": review_count,
"description": description,
"original_price": original_price,
"price": price
}
items.append(item)
No final do loop for, os itens conterão todos os seus dados coletados. Verifique isso imprimindo os itens:
imprimir(itens)
Isso produzirá uma saída como a seguinte:
[{'url': 'https://www.booking.com/hotel/us/murray-hill-east-manhattan.html?label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&ucfs=1&arphpl=1&checkin=2024-11-18&checkout=2024-12-18&dest_id=20088325&dest_type=city&group_adults=2&req_adults=2&no_rooms=1&group_children=0&req_children=0&hpos=1&hapos=1&sr_order=popularity&srpvid=c6926559ebaa0862&srepoch=1731939905&all_sr_blocks=5604802_204869446_2_0_0&highlighted_blocks=5604802_204869446_2_0_0&matching_block_id=5604802_204869446_2_0_0&sr_pri_blocks=5604802_204869446_2_0_0__523000&from=searchresults', 'image': 'https://cf.bstatic.com/xdata/images/hotel/square600/84564452.webp?k=ff50b7387e08e01ba7a400effa788e668f894cabe4a295f60d6cd018ec9ac4d0&o=', 'title': 'Murray Hill East Suites', 'address': 'Murray Hill, Nova Iorque', 'distance': '1,3 milhas do centro da cidade', 'pontuação da avaliação': 8,2, 'número de avaliações': 54, 'descrição': 'EstúdioEstúdio inteiro • 1 banheiro • 1 cozinha • 398 pés²nVários tipos de cama', 'preço original': Nenhum, 'preço': '$5230'},
# omitido por brevidade...
, {'url': 'https://www.booking.com/hotel/us/renaissance-times-square.html?label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&ucfs=1&arphpl=1&checkin=2024-11-18&checkout=2024-12-18&dest_id=20088325&dest_type=city&group_adults=2&req_adults=2&no_rooms=1&group_children=0&req_children=0&hpos=12&hapos=12&sr_order=popularity&srpvid=c6926559ebaa0862&srepoch=1731939905&all_sr_blocks=2315604_274565698_0_2_0&highlighted_blocks=2315604_274565698_0_2_0&matching_block_id=2315604_274565698_0_2_0&sr_pri_blocks=2315604_274565698_0_2_0__1805400&from_sustainable_property_sr=1&from=searchresults', 'image': 'https://cf.bstatic.com/xdata/images/hotel/square600/437371642.webp?k=d1a06036e365573e326e6b0f1b045f8f43b6ad0d18e119cfb92d92cc81fa5c88&o=', 'title': 'Renaissance New York Times Square by Marriott', 'address': 'Manhattan, Nova York', 'distance': '0,6 milhas do centro da cidade', 'review_score': 8,4, 'review_count': 2209, 'description': 'Quarto King com 1 cama king size', 'original_price': '$20060', 'price': '$18054'}]
Fantástico! Agora só falta exportar essas informações para um arquivo legível, como CSV.
Etapa 8: Exportar para CSV
Importe o pacote csv da biblioteca padrão do Python:
import csv
Em seguida, use-o para exportar itens para um arquivo CSV:
# especifique o nome do arquivo CSV de saída
output_file = "properties.csv"
# exporte a lista de itens para um arquivo CSV
with open(output_file, mode="w", newline="", encoding="utf-8") as file:
#criar um objeto gravador CSV
writer = csv.DictWriter(file, fieldnames=["url", "image", "title", "address", "distance", "review_score", "review_count", "description", "original_price", "price"])
# escrever a linha do cabeçalho
writer.writeheader()
# escrever cada item como uma linha no CSV
writer.writerows(items)
Este trecho preenche um arquivo CSV chamado properties.csv usando dados das matrizes de itens. As principais funções utilizadas acima são:
open(): abre o arquivo especificado no modo de gravação com codificação UTF-8.csv.DictWriter(): Cria um gravador CSV com os nomes de campo fornecidos.writeheader(): Escreve a linha do cabeçalho no arquivo CSV com base nos nomes de campo especificados.writer.writerow(): Grava cada item do dicionário como uma linha no CSV.
Etapa 9: Junte tudo
scraper.py agora deve conter estas linhas:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.common import NoSuchElementException
import csv
def handle_no_such_element_exception(data_extraction_task):
try:
return data_extraction_task()
except NoSuchElementException as e:
return None
# criar uma instância do driver web Chrome
driver = webdriver.Chrome(service=Service())
# conectar-se à página de destino
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
# lidar com o alerta de login
tente:
# aguarde até 20 segundos para que o alerta de login apareça
close_button = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[role="dialog"] button[aria-label="Dismiss sign-in info."]"))
)
# clicar no botão Fechar
close_button.click()
exceto e:
imprimir("O modal de login não apareceu, continuando...")
# onde armazenar os dados coletados
items = []
# selecionar todos os itens de propriedade na página
property_items = driver.find_elements(By.CSS_SELECTOR, "[data-testid="property-card"]")
# iterar sobre os itens de propriedade e
# extrair dados deles
for property_item in property_items:
# lógica de coleta...
url = handle_no_such_element_exception(lambda: item_da_propriedade.find_element(By.CSS_SELECTOR, "a[data-testid="property-card-desktop-single-image"]").get_attribute("href"))
image = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "img[data-testid="image"]").get_attribute("src"))
title = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="title"]").text)
address = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="address"]").text)
distance = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="distance"]").text)
review_score = None
review_count = None
review_text = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="review-score"]").text)
if review_text is not None:
# divide a string da avaliação por n
parts = review_text.split("n")
# processe cada parte
para parte em partes:
parte = parte.strip()
# verifique se esta parte é um número (pontuação potencial da avaliação)
se parte.replace(".", "", 1).isdigit():
pontuação_da_avaliação = float(parte)
# verifique se contém a string "avaliações"
elif "avaliações" em parte:
# extrair o número antes de "reviews"
review_count = int(part.split(" ")[0].replace(",", ""))
decription = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="recommended-units"]").text)
price_element = handle_no_such_element_exception(lambda: (property_item.find_element(By.CSS_SELECTOR, "[data-testid="availability-rate-information"]")))
if price_element is not None:
original_price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[aria-hidden="true"]:not([data-testid])").text.replace(",", "")
))
preço = handle_no_such_element_exception(lambda: (
elemento_preço.find_element(By.CSS_SELECTOR, "[data-testid="preço-e-preço-com-desconto"]").text.replace(",", "")
))
# preencher um novo item com os dados extraídos
item = {
"url": url,
"image": image,
"title": title,
"address": address,
"distance": distance,
"review_score": review_score,
"review_count": review_count,
"decription": decription,
"original_price": original_price,
"price": price
}
# adicionar o novo item à lista de itens coletados
items.append(item)
# especificar o nome do arquivo CSV de saída
arquivo_de_saída = "propriedades.csv"
# exportar a lista de itens para um arquivo CSV
com open(arquivo_de_saída, modo="w", nova_linha="", codificação="utf-8") como arquivo:
#criar um objeto gravador CSV
writer = csv.DictWriter(file, fieldnames=["url", "image", "title", "address", "distance", "review_score", "review_count", "decription", "original_price", "price"])
# escreva a linha do cabeçalho
writer.writeheader()
# escreva cada item como uma linha no CSV
writer.writerows(items)
# feche o driver da web e libere seus recursos
driver.quit()
Dá para acreditar? Em apenas cerca de 110 linhas, você acabou de criar um Scraper Python para o Booking.com.
Verifique se ele funciona executando o script de raspagem. No Windows, execute o Scraper com:
python Scraper.py
Da mesma forma, no Linux ou macOS, execute:
python3 Scraper.py
Aguarde até que o script termine de ser executado. Um arquivo properties.csv aparecerá no diretório raiz do seu projeto. Abra o arquivo para visualizar os dados extraídos:
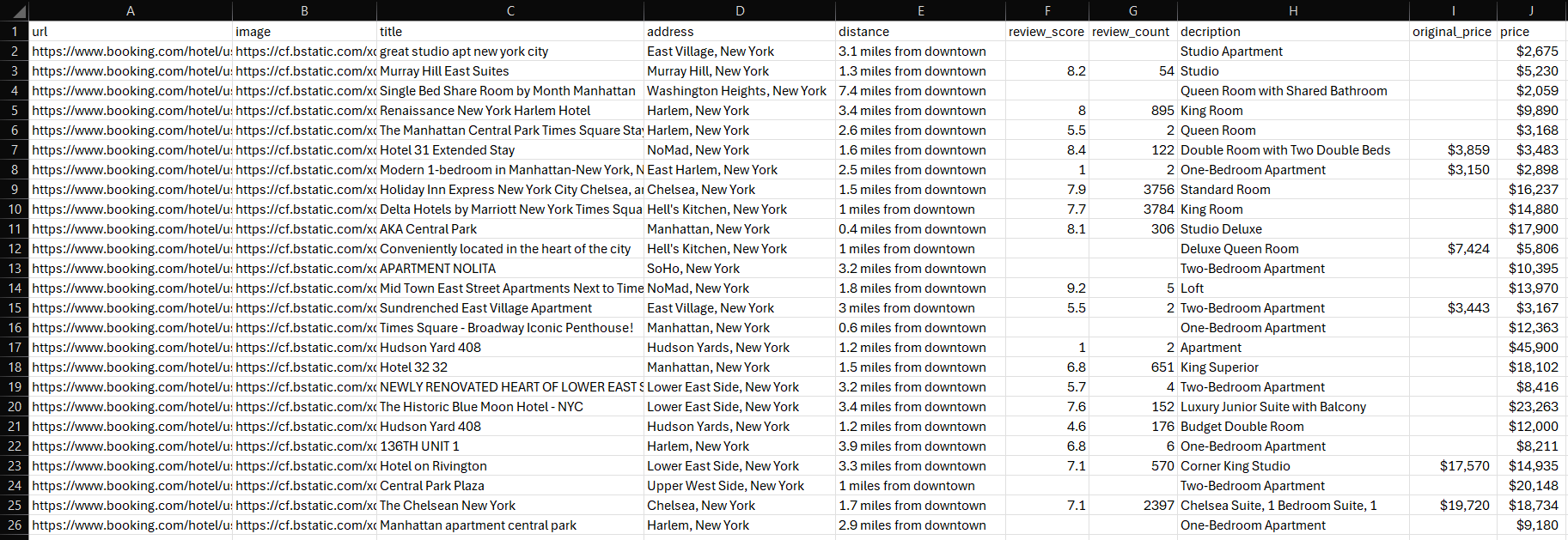
Parabéns, missão cumprida!
Conclusão
Neste tutorial, você aprendeu o que é um Scraper do Booking.com e como criar um usando Python. Como mostrado, criar um script básico para recuperar automaticamente dados do Booking.com requer apenas algumas linhas de código.
No entanto, o exemplo apresentado aqui não abordou muitos dos desafios que você pode encontrar ao fazer scraping no Booking.com. Problemas como medidas anti-navegador headless, lidar com interações do usuário para gerar resultados de pesquisa e lidar com rolagem infinita podem complicar rapidamente suas operações de scraping.
Procurando uma solução de scraping mais fácil, completa e poderosa? Experimente a API Booking Scraper da Bright Data!
A API Booking Scraper fornece pontos de extremidade poderosos para extrair dados públicos de hotéis, avaliações, classificações e muito mais. Com chamadas de API simples, você pode recuperar dados nos formatos JSON ou HTML.
Prefere soluções pré-construídas? A Bright Data também oferece Conjuntos de dados prontos para uso do Booking.com!
Crie uma conta gratuita na Bright Data hoje mesmo para experimentar nossas APIs de Scraper ou explorar nossos Conjuntos de dados.






