

Neste guia, você aprenderá o seguinte:
- O que é um Scraper do AliExpress e como ele funciona
- Os tipos de dados que você pode recuperar automaticamente do AliExpress
- Como criar um script de scraping do AliExpress usando Python
Vamos começar!
O que é um Scraper do AliExpress?
Um scraper do AliExpress recupera automaticamente dados específicos das páginas do AliExpress. Ele navega pelas páginas do AliExpress imitando os hábitos de navegação do usuário. Ele transforma o conteúdo da página da web em um formato utilizável, como CSV ou JSON, e controla interações como paginação. Seu objetivo final é recuperar informações estruturadas, como imagens de produtos, detalhes de produtos, feedback de clientes, preços e muito mais.
Se você quiser saber mais sobre como criar scrapers da web, leia nosso guia sobre como criar um bot de scraping de dados.
Dados que você pode extrair do AliExpress: guia passo a passo
O AliExpress contém uma grande quantidade de informações, como:
- Detalhes do produto: nomes, descrições, imagens, faixas de preço, informações do vendedor e muito mais.
- Feedback dos clientes: avaliações, comentários sobre produtos e muito mais.
- Categorias e tags: categorias de produtos, tags relevantes ou rótulos.
É hora de aprender como coletá-los!
Extraindo dados do AliExpress em Python
Esta seção do tutorial fornece um guia passo a passo sobre como criar um Scraper do AliExpress.
O objetivo é orientá-lo na escrita de um script Python que extraia automaticamente informações da página “cadeira ergonômica” do AliExpress:
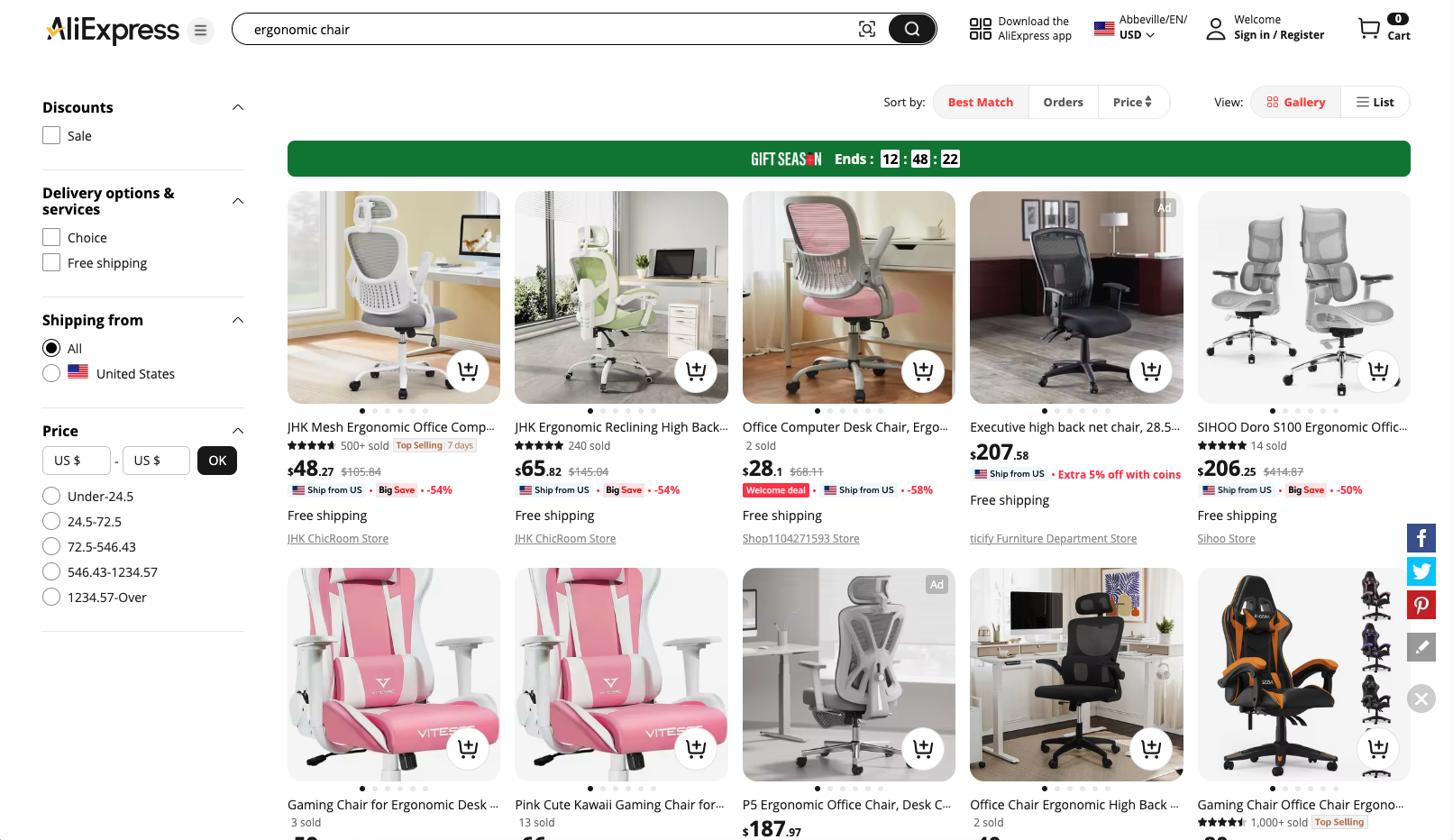
Etapa 1: Configuração do projeto
Certifique-se de que você tenha o Python 3 instalado no seu computador local. Caso contrário, baixe-o da documentação oficial e siga o assistente de instalação para configurá-lo.
Em seguida, use o comando abaixo para criar o diretório do seu projeto:
mkdir aliexpress-scraper
Este diretório conterá seu código Python.
Entre no diretório no seu terminal e crie um ambiente virtual dentro dele:
cd aliexpress-Scraper
python -m venv env
Vá em frente e carregue a pasta do projeto em seu IDE Python preferido, como o Visual Studio Code com a extensão Python.
No terminal do seu IDE, ative o ambiente virtual. Execute o seguinte comando se estiver usando macOS ou Linux:
.env/bin/activate
Da mesma forma, no Windows, use este comando:
env/Scripts/activate
Ótimo!
No diretório raiz do seu projeto, crie um arquivo scraper.py. Seu projeto agora deve ter esta estrutura de pastas:
Ótimo! Seu ambiente Python para Scraping de dados do AliExpress está pronto.
Etapa 2: selecione a biblioteca de scraping
O objetivo atual é determinar se o AliExpress emprega páginas dinâmicas ou estáticas. Navegue até a página do AliExpress desejada no modo privado ou anônimo do seu navegador. Em seguida, clique com o botão direito do mouse em um espaço vazio no fundo da página da web, escolha a opção “Inspect” (Inspecionar), navegue até a guia “Network” (Rede), aplique o filtro “Fetch/XHR” e atualize a página:
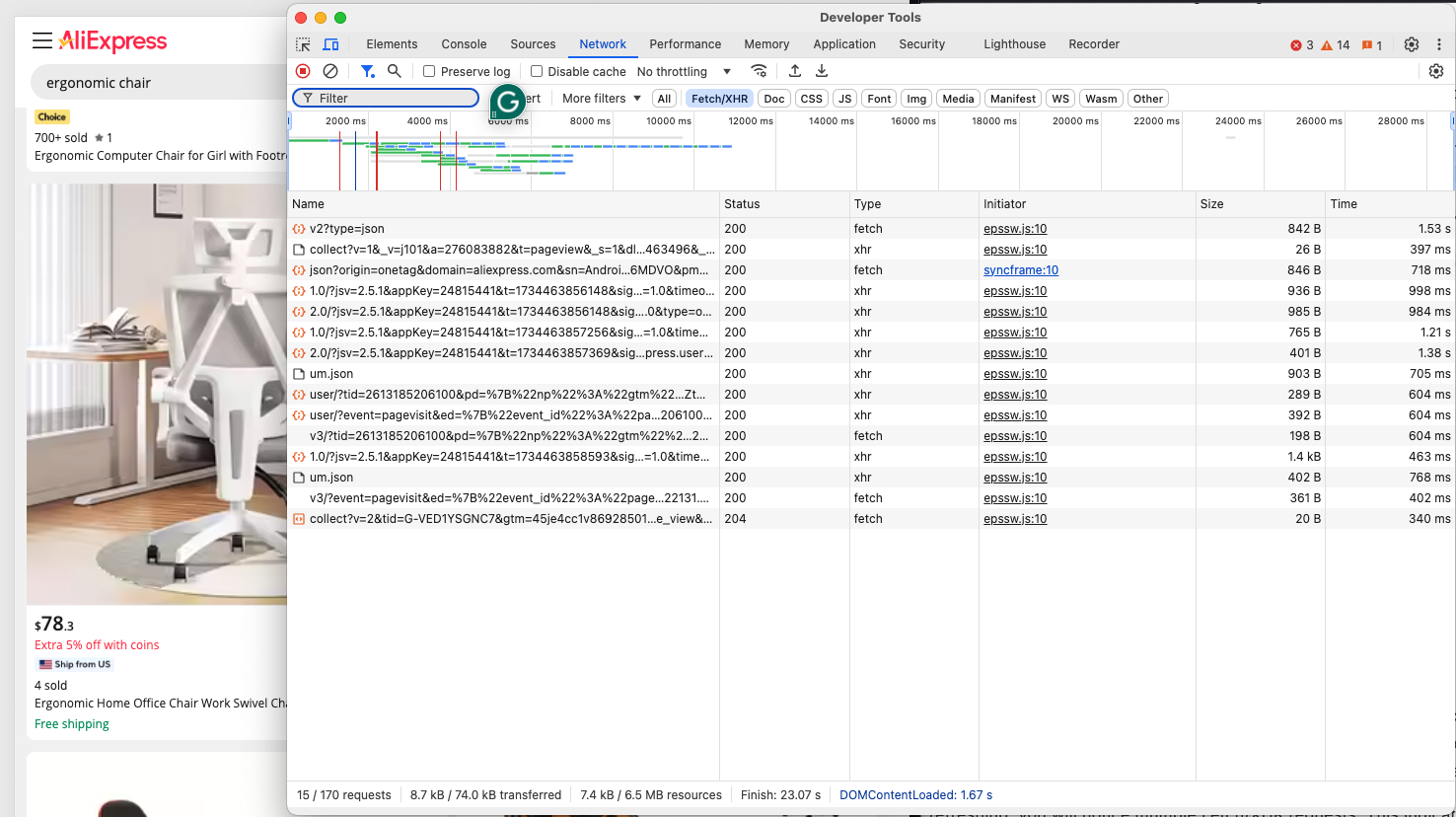
Verifique se a página faz alguma consulta dinâmica nesta seção DevTools. Depois de atualizar a página, você notará várias solicitações Fetch/XHR. Isso indica que a página usa solicitações dinâmicas para carregar conteúdo adicional. Se você der uma olhada no DOM da página em comparação com o documento HTML retornado pelo servidor, também verá que o AliExpress usa renderização JavaScript.
Para fazer o scraping do AliExpress de maneira eficaz, você precisará de uma ferramenta de automação de navegador como o Selenium, pois a página de destino depende do JavaScript para renderização. Nosso blog sobre o Scraping de dados com Selenium é um excelente recurso para iniciantes.
Com o Selenium, você pode manipular um navegador da web, imitar interações do usuário e fazer scraping de conteúdo renderizado em JavaScript. Instale-o e comece a usá-lo!
Etapa 3: Instale e configure o Selenium
No ambiente virtual ativado, instale o Selenium com este comando:
pip install -U selenium
No arquivo scraper.py, importe o WebDriver do Selenium e inicialize-o.
from selenium import webdriver
# Inicialize o driver do Chrome
driver = webdriver.Chrome()
# lógica de extração...
# Feche o driver
driver.quit()
Um WebDriver é inicializado no código acima para lidar com uma instância do Chrome. Vale a pena notar que o AliExpress possui medidas anti-scraping que podem impedir que navegadores headless acessem o site.
Portanto, não é aconselhável definir o sinalizador--headless. Em vez disso, considere uma opção alternativa, como o Playwright Stealth.
Agora que você está totalmente configurado para começar a fazer scraping do AliExpress, vamos examinar como se conectar à página de destino.
Etapa 4: conecte-se à página de destino
Use o método get() exposto pelo objeto Selenium WebDriver para visitar a página de destino. O arquivo scraper.py agora deve ficar assim:
from selenium import webdriver
# Inicializar o driver do Chrome
driver = webdriver.Chrome()
# URL da página de destino
url = "https://www.aliexpress.com/w/wholesale-ergonomic-chair.html?spm=a2g0o.productlist.search.0"
# Conecte-se à página de destino
driver.get(url)
# lógica de raspagem...
# Feche o driver
driver.quit()
Coloque um ponto de interrupção de depuração na linha final e inicie o script com o depurador. O navegador Chrome controlado deve abrir automaticamente, conforme mostrado abaixo:
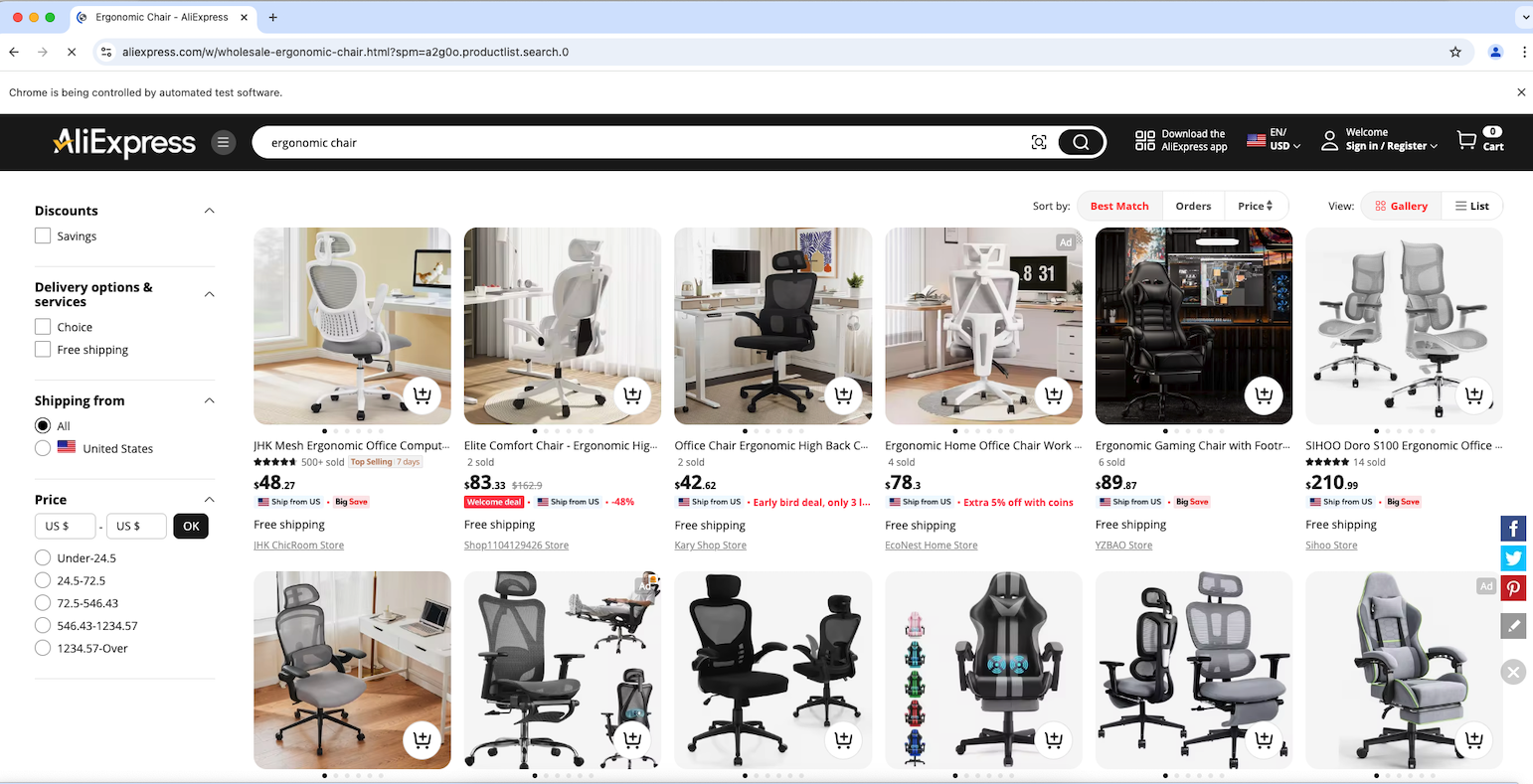
Ótimo! A notificação “O Chrome está sendo controlado por um software de teste automatizado” indica que o Selenium está controlando o Chrome com sucesso, conforme configurado.
Etapa 5: Selecione os elementos do produto
Como a página de produtos do AliExpress contém vários produtos, você deve primeiro inicializar uma estrutura de dados para armazenar os dados coletados. Para isso, uma matriz funcionará perfeitamente:
produtos = []
Para garantir que seu Scraper continue funcionando mesmo quando o layout do site mudar, você deve criar uma função auxiliar que torne seus seletores mais resistentes a essas mudanças:
def find_element_smart(parent, by_list):
"""Tente vários seletores até que um elemento seja encontrado"""
for by_type, selector in by_list:
try:
element = parent.find_element(by_type, selector)
if element.is_displayed():
return element
except:
continue
return None
A função find_element_smart() itera por uma lista de estratégias de seletor by_list para localizar um elemento dentro de um determinado elemento pai. Ela tenta cada par <by_type, selector> até encontrar um elemento visível, retornando-o se for bem-sucedida. Caso contrário, ela retorna None se nenhum elemento correspondente for encontrado.
Em seguida, inspecione os elementos HTML dos produtos na página para entender como selecioná-los, identificar o tipo de dados que eles contêm e determinar como extrair esses dados.
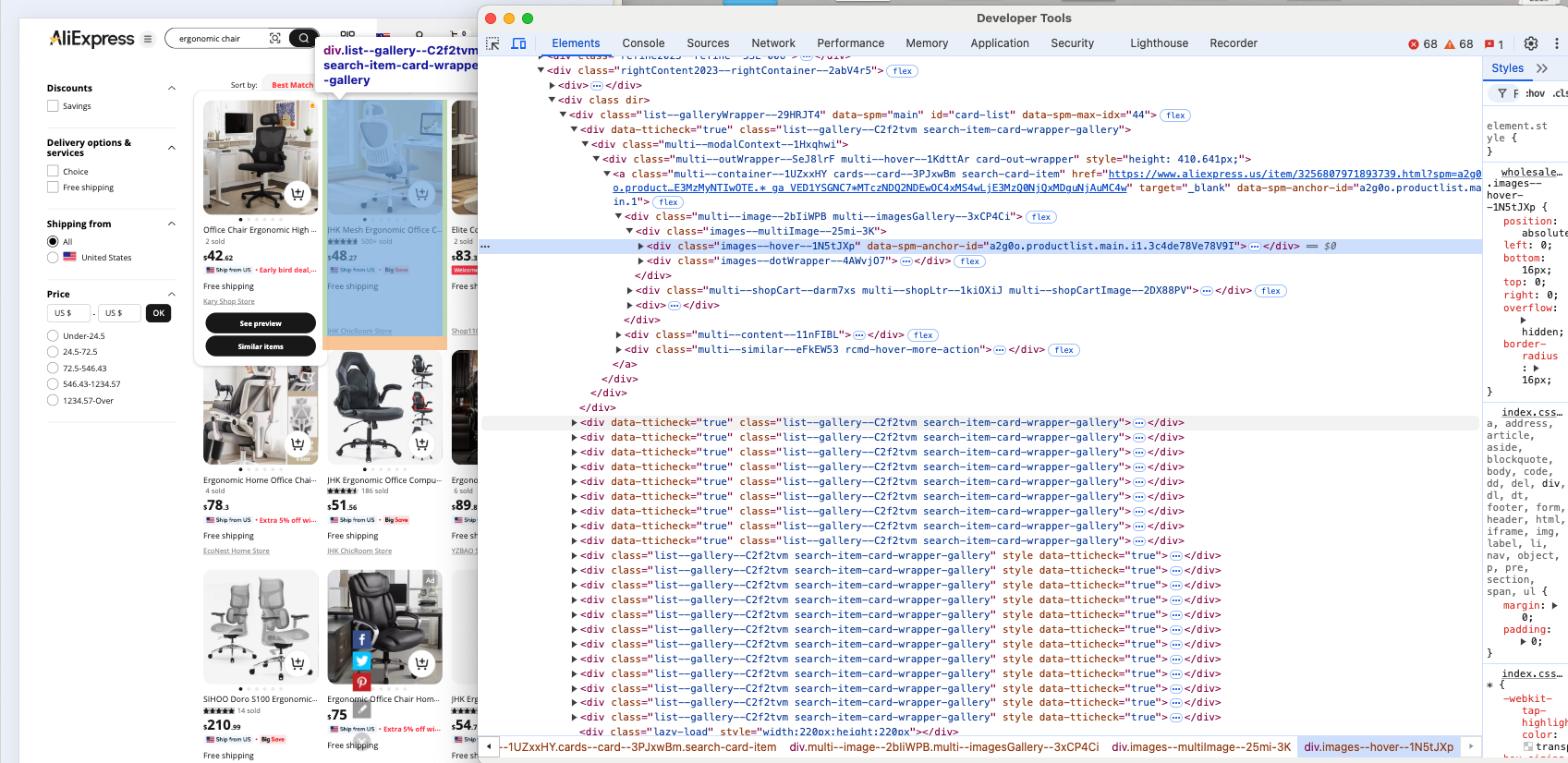
É óbvio que cada elemento do produto é um nó .list-–gallery—-C2f2tvm.
Observe que list--gallery--C2f2tvm pode mudar a qualquer momento, pois contém uma string gerada aleatoriamente. Portanto, você não deve confiar nessa classe para a seleção de elementos. Em vez disso, você deve começar encontrando produtos com base em sua estrutura, como elementos div que contêm imagens e links. Se isso não funcionar, tente procurar produtos com base em seu conteúdo ou concentre-se em elementos HTML mais específicos.
Implemente a lógica de seleção de produtos conforme abaixo:
# Encontre produtos usando padrões estruturais primeiro e, em seguida, recorra a padrões de classe
product_selectors = [
(By.XPATH, "//div[.//img and .//a[contains(@href, 'item')]]"),
(By.XPATH, "//div[.//img and .//*[contains(text(), '$')]]"),
(By.CSS_SELECTOR, "div[class*='gallery']")
]
# Aguardar e obter produtos
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div[class*='gallery']")))
produtos_encontrados = []
para tipo_seletor, seletor em seletores_de_produtos:
tente:
elementos = espere.até(EC.presence_of_all_elements_located((tipo_seletor, seletor)))
se elementos:
produtos_encontrados = elementos
break
exceto:
continue
O código acima aplica a estratégia do seletor para recuperar elementos na página com seletores CSS genéricos.
Inclua a seguinte importação em seu script Python:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
Em seguida, introduza uma instância WebDriverWait logo após inicializar o WebDriver, mas antes de qualquer interação com a página:
wait = WebDriverWait(driver, 20)
Em vez de localizar imediatamente os elementos em uma página ao fazer a extração de sites dinâmicos como o AliExpress, o WebDriverWait instrui o Scraper a ser paciente e aguardar até o tempo especificado (20 segundos, neste caso) para que os elementos apareçam. Isso é importante porque as páginas da web carregam elementos em velocidades diferentes e, sem a espera adequada, o Scraper pode trabalhar com elementos que ainda não foram carregados, causando erros.
Agora você está um passo mais perto de fazer o scraping completo do AliExpress!
Etapa 6: extraia os elementos do produto do AliExpress
Inspecione um elemento do produto para entender sua estrutura HTML:
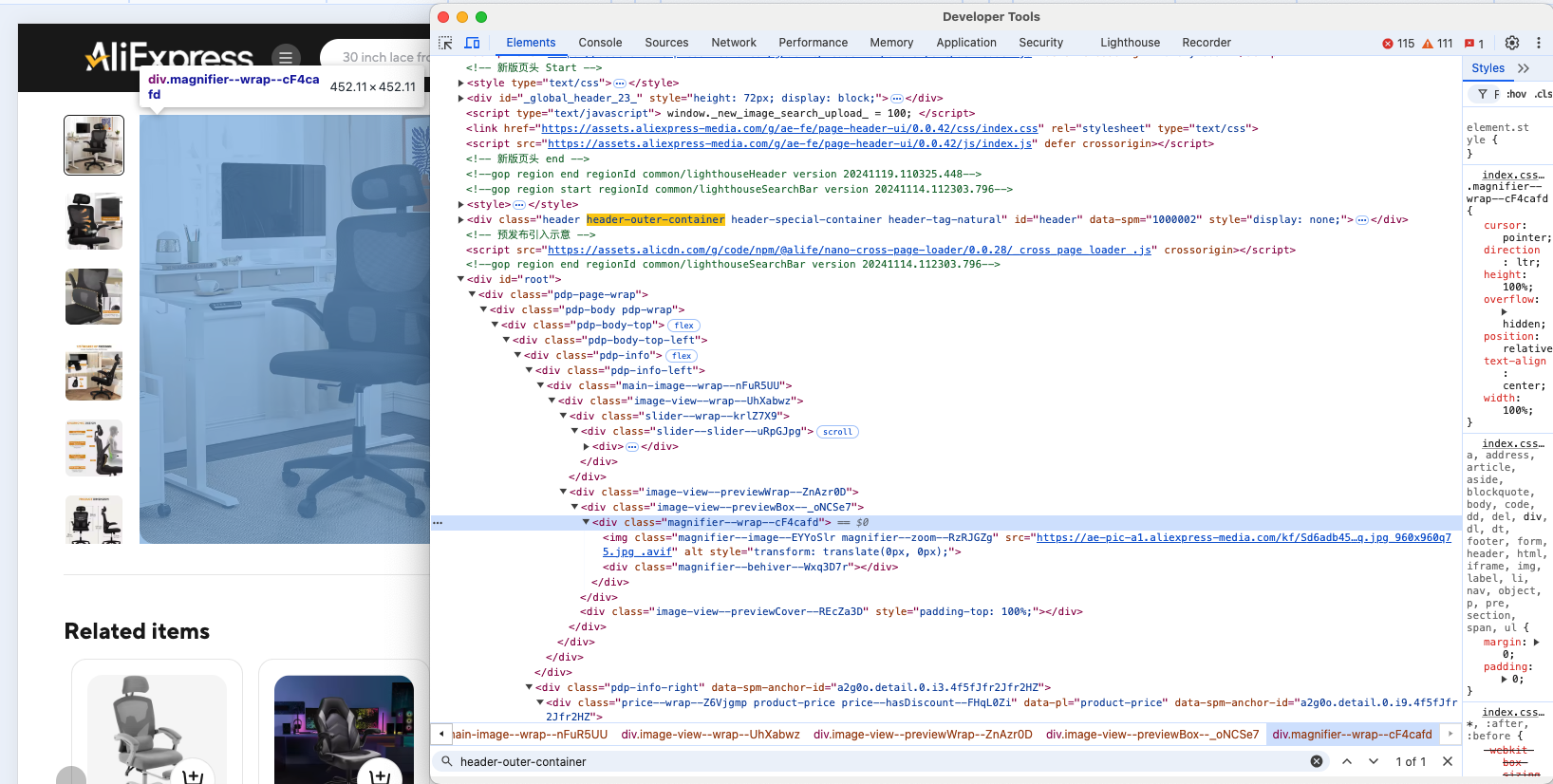
É evidente que você pode extrair a imagem do produto, URL, nome ou título, preço e desconto.
Antes de extrair cada produto, verifique se ele está visível na janela de visualização:
wait.until(EC.visibility_of(product))
Agora, configure seletores para extrair os dados de cada produto. Em vez de usar nomes de classe específicos que podem quebrar, use padrões como estes:
# Obter imagem - procurar imagens do produto por padrões de fonte
img_element = find_element_smart(product, [
(By.XPATH, ".//img[contains(@src, 'item') or contains(@src, 'product')]"),
(By.CSS_SELECTOR, "img[src*='item']"),
(By.CSS_SELECTOR, "img[class*='image']")
])
# Obter URL - procurar links do produto
url_element = find_element_smart(product, [
(By.CSS_SELECTOR, "a[href*='item']"),
(By.XPATH, ".//a[contains(@href, 'product')]")
])
# Obter título - procurar primeiro o elemento de texto mais longo
price_element = find_element_smart(product, [
(By.CSS_SELECTOR, "*[class*='price-sale']"),
(By.CSS_SELECTOR, "*[class*='price']"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
# Obter preço - procurar símbolos/padrões de moeda
elemento_preço = find_element_smart(produto, [
(By.XPATH, ".//*[contém(texto(), '$') ou contém(texto(), 'US') ou contém(texto(), 'GHS')]"),
(By.XPATH, ".//*[contém(@class, 'preço')]")
])
# Tente obter desconto, se disponível
discount_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '%') or contains(text(), 'OFF')]"),
(By.CSS_SELECTOR, "[class*='discount']")
])
A função find_element() retorna o primeiro elemento que corresponde ao seletor CSS especificado. Você pode então usar o atributo text para extrair seu conteúdo de texto.
Adicione os dados coletados à matriz de produtos e use-os para preencher um dicionário de produtos:
products.append({
"image_url": img_element.get_attribute("src"),
"product_url": url_element.get_attribute("href"),
"product_title": title_element.text.strip(),
"product_price": price_element.text.strip(),
"product_discount": discount_element.text.strip() if discount_element else "N/A"
})
Sua lógica de extração de dados está concluída e pronta para uso.
Etapa 7: Exporte os dados extraídos para CSV
Na sua configuração atual, os dados coletados são armazenados na matriz de produtos. Para torná-los compartilháveis e acessíveis a outras pessoas, você precisa exportá-los para um formato legível, como um arquivo CSV. Veja como você pode criar e preencher um arquivo CSV com os dados coletados:
# Gravar dados em CSV
csv_file_name = "aliexpress_products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
fieldnames = ["image_url", "product_url", "product_title", "product_price", "product_discount"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
for product in products:
writer.writerow(product)
Este código cria um arquivo CSV que funciona como uma planilha – cada produto recebe sua própria linha, e diferentes detalhes sobre o produto (imagem, URL, título, preço e qualquer desconto) vão para colunas separadas. Ao abrir o arquivo final aliexpress_products.csv, você verá todas as informações dos produtos do AliExpress coletadas organizadas em colunas.
Por último, a partir da Biblioteca Padrão do Python, importe a biblioteca csv em seu script:
import csv
Etapa 8: Junte tudo
Esta é a aparência do seu script de extração final depois de juntar todo o código:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
def find_element_smart(parent, by_list):
"""Tente vários seletores até encontrar um elemento"""
para by_type, selector em by_list:
tente:
elemento = pai.find_element(by_type, selector)
se elemento.is_displayed():
retorne elemento
exceto:
continue
retorne None
# Inicialize o driver
driver = webdriver.Chrome()
wait = WebDriverWait(driver, 20)
# URL de destino
url = "https://www.aliexpress.com/w/wholesale-ergonomic-chair.html?spm=a2g0o.productlist.search.0"
driver.get(url)
# Aguardar o carregamento dos produtos iniciais
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "div[class*='gallery']")))
# Onde armazenar os dados coletados
products = []
# Encontre os produtos usando padrões primeiro e, em seguida, recorra aos padrões de classe
seletores_de_produtos = [
(By.XPATH, "//div[.//img e .//a[contém(@href, 'item')]]"),
(By.XPATH, "//div[.//img e .//*[contém(texto(), '$')]]"),
(By.CSS_SELECTOR, "div[class*='gallery']")
]
# Aguardar e obter produtos
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div[class*='gallery']")))
produtos_encontrados = []
para tipo_seletor, seletor em seletores_de_produtos:
tente:
elementos = esperar.até(EC.presença_de_todos_os_elementos_localizados((tipo_seletor, seletor)))
se elementos:
produtos_encontrados = elementos
break
exceto:
continuar
# Iterar sobre o produto encontrado e extrair dados dele
para produto em produtos_encontrados:
# Esperar até que o produto esteja visível e interativo
wait.until(EC.visibility_of(product))
# Obter imagem - procurar imagens do produto por padrões de fonte
img_element = find_element_smart(product, [
(By.XPATH, ".//img[contains(@src, 'item') or contains(@src, 'product')]"),
(By.CSS_SELECTOR, "img[src*='item']"),
(By.CSS_SELECTOR, "img[class*='image']")
])
# Obter URL - procurar links do produto
url_element = find_element_smart(product, [
(By.CSS_SELECTOR, "a[href*='item']"),
(By.XPATH, ".//a[contains(@href, 'product')]")
])
# Obter título - procurar primeiro o elemento de texto mais longo
title_element = find_element_smart(product, [
(By.XPATH, ".//div[string-length(text()) > 20]"),
(By.XPATH, ".//*[contains(@class, 'title')]"),
(By.CSS_SELECTOR, "[class*='name']")
])
# Obter preço
price_element = find_element_smart(product, [
(By.CSS_SELECTOR, "*[class*='price-sale']"),
(By.CSS_SELECTOR, "*[class*='price']"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
if all([img_element, url_element, title_element, price_element]):
# Obter desconto, se disponível
elemento_desconto = find_element_smart(produto, [
(By.XPATH, ".//*[contém(texto(), '%') ou contém(texto(), 'OFF')]"),
(By.CSS_SELECTOR, "[class*='desconto']")
])
products.append({
"image_url": img_element.get_attribute("src"),
"product_url": url_element.get_attribute("href"),
"product_title": title_element.text.strip(),
"product_price": price_element.text.strip(),
"product_discount": discount_element.text.strip() se discount_element, caso contrário "N/A"
})
# Salvar resultados
csv_file_name = "aliexpress_products.csv"
com open(csv_file_name, mode="w", newline="", encoding="utf-8") como csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["image_url", "product_url", "product_title", "product_price", "product_discount"])
writer.writeheader()
writer.writerows(products)
driver.quit()
Agora, inicie o Scraper com o seguinte comando:
python Scraper.py
O script deve ser executado com sucesso, e o arquivo aliexpress_products.csv deve conter os dados extraídos, conforme mostrado:
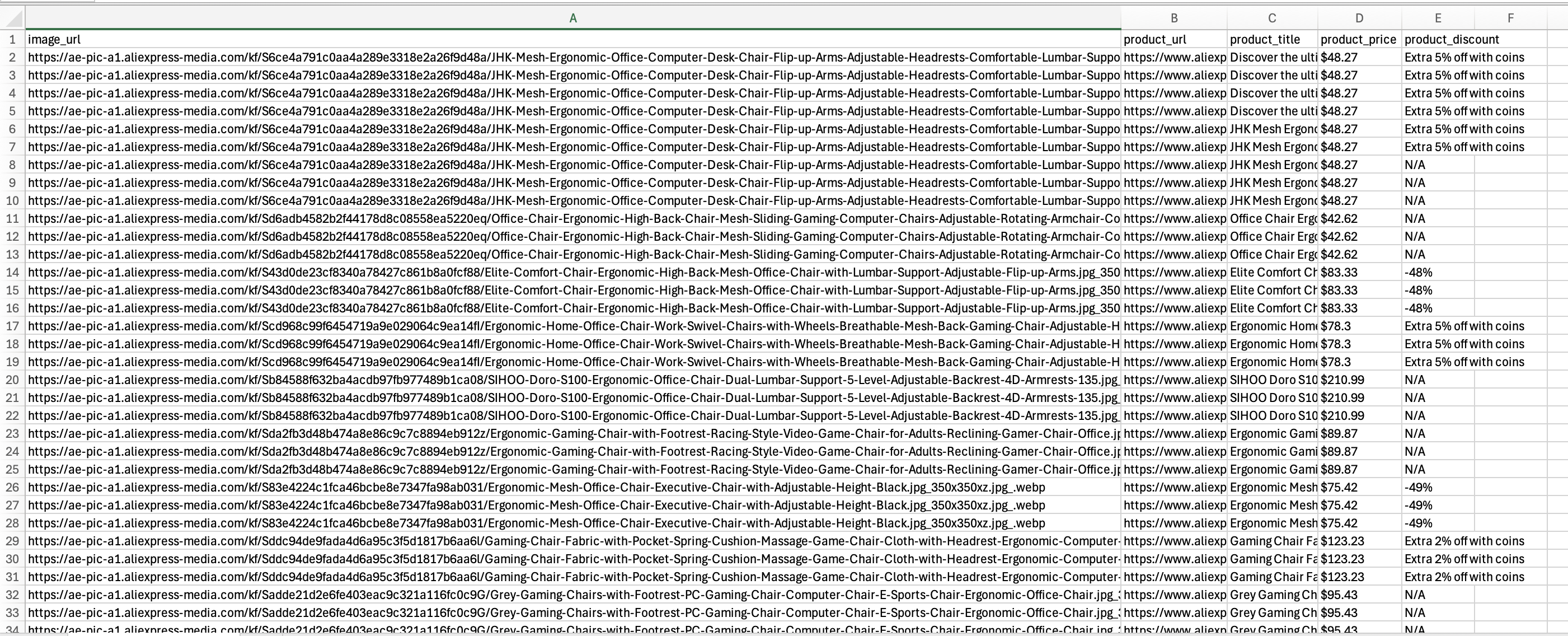
Existem várias etapas adicionais que você pode realizar após montar um script de raspagem funcional. Isso inclui automatizar o processo de execução e implementar otimizações para garantir que o Scraper continue a fornecer dados valiosos ao longo do tempo.
Conclusão
Neste guia, você explorou o que é um Scraper do AliExpress e os tipos de dados que ele pode extrair. Você também aprendeu como criar um script Python para extrair produtos do AliExpress com o mínimo de código.
No entanto, o scraping do AliExpress apresenta vários desafios. A plataforma implementa proteções anti-bot rigorosas e usa recursos como paginação, o que adiciona complexidade ao processo de scraping. Desenvolver uma solução formidável de scraping do Alibaba pode ser bastante desafiador.
Nossa API AliExpress Scraper oferece uma solução especializada que permitirá que você elimine esses desafios. Com chamadas de API diretas, você pode obter dados do site de destino de maneira integrada, mitigando o risco de ser bloqueado. Precisa dos dados rapidamente?
Quer experimentar nossas APIs de Scraper ou explorar nossos Conjuntos de dados? Crie uma conta Bright Data hoje mesmo e comece seu Teste grátis!






