

Neste guia, você aprenderá:
- O que é um Scraper do Alibaba e como ele funciona
- Os tipos de dados que você pode recuperar automaticamente do Alibaba
- Como criar um script de scraping do Alibaba usando Python
Vamos começar!
O que é um Scraper do Alibaba?
Um scraper do Alibaba é umbot de Scraping de dadosprojetado para extrair automaticamente dados das páginas do Alibaba. Ele funciona simulando o comportamento de navegação de um usuário para navegar pelas páginas do Alibaba. Ele lida com interações como paginação e recupera informações estruturadas, como detalhes do produto, preços e dados da empresa.
Dados que você pode extrair do Alibaba
O Alibaba é um tesouro de informações valiosas, como:
- Detalhes do produto: nomes, descrições, imagens, faixas de preço, informações do vendedor e muito mais.
- Informações da empresa: nomes de empresas, detalhes do fabricante, informações de contato e classificações.
- Feedback do cliente: classificações, avaliações de produtos e muito mais.
- Logística e disponibilidade: status do estoque, quantidades mínimas de pedido, opções de envio e muito mais.
- Categorias e tags: categorias de produtos, tags relevantes ou rótulos.
Veja como extraí-los!
Extraindo dados do Alibaba em Python: guia passo a passo
Nesta seção, você aprenderá a criar um Scraper do Alibaba em um tutorial guiado.
O objetivo é orientá-lo na criação de um script Python que extraia automaticamente os dados da página “laptop” do Alibaba:
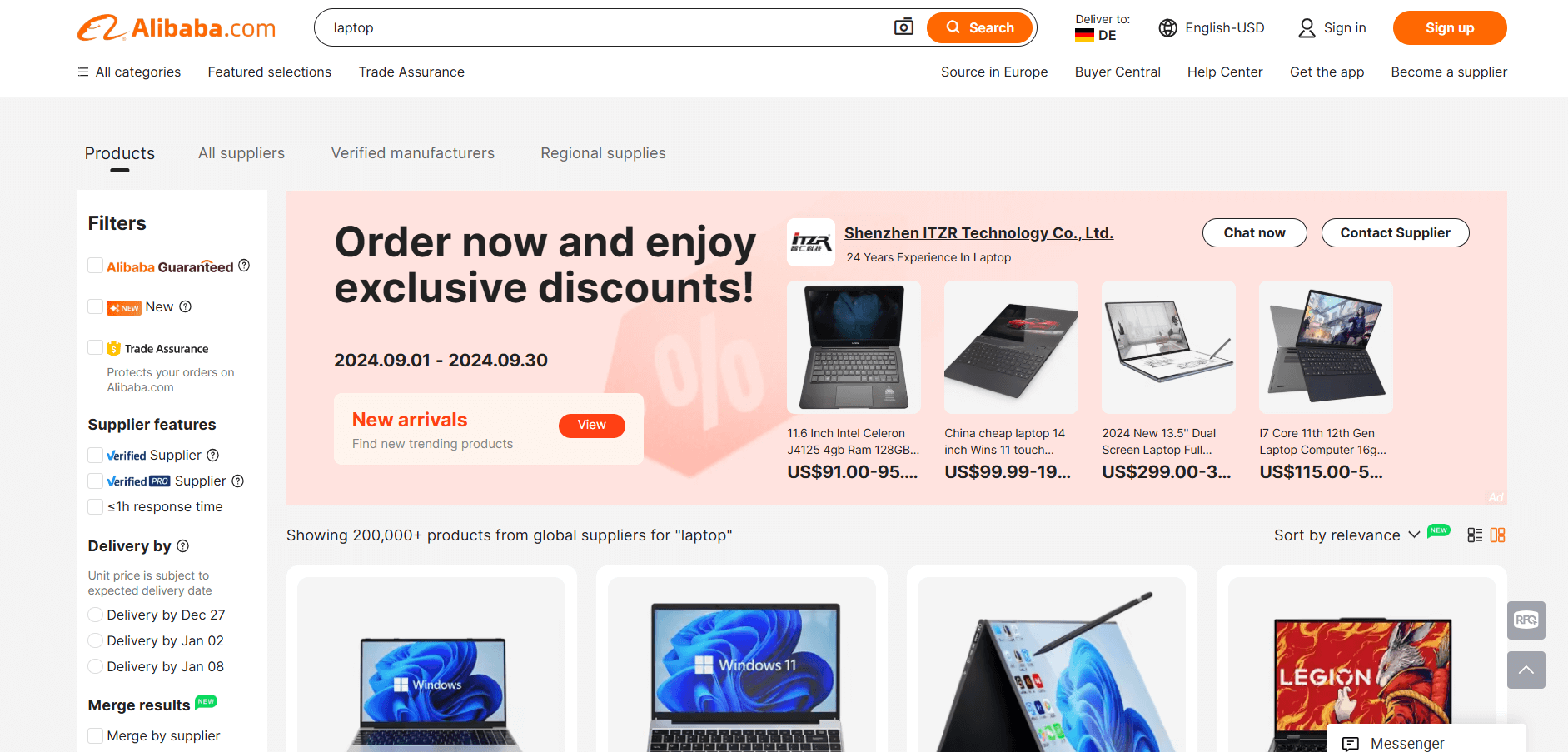
Pronto? Siga as etapas abaixo!
Etapa 1: Configuração do projeto
Primeiro, verifique se você tem o Python 3 instalado em sua máquina. Caso contrário, baixe-o e siga o assistente de instalação.
Agora, use o comando abaixo para criar um diretório para o seu projeto:
mkdir alibaba-scraper
A pasta alibaba-scraper é onde você colocará o Scraper Python Alibaba.
Digite-o no terminal e crie um ambiente virtual dentro dele:
cd alibaba-Scraper
python -m venv env
Carregue a pasta do projeto em seu IDE Python favorito, como o Visual Studio Code com a extensão Python ou o PyCharm Community Edition.
Crie um arquivo scraper.py no diretório do projeto, que agora deve conter esta estrutura de arquivos:

O Scraper.py é atualmente um script Python em branco, mas em breve conterá a lógica de scraping desejada.
No terminal do IDE, ative o ambiente virtual. No Linux ou macOS, execute este comando:
./env/bin/activate
De forma equivalente, no Windows, execute:
env/Scripts/activate
Ótimo, seu ambiente Python para o Scraping de dados do Alibaba está pronto!
Etapa 2: Selecione a biblioteca de scraping
O objetivo agora é determinar se o Alibaba usa páginas dinâmicas ou estáticas. Para fazer isso, abra a página de destino do Alibaba no seu navegador no modo de navegação anônima. Em seguida, clique com o botão direito do mouse no fundo, selecione “Inspecionar”, acesse a guia “Rede”, filtre por “Fetch/XHR” e recarregue a página:
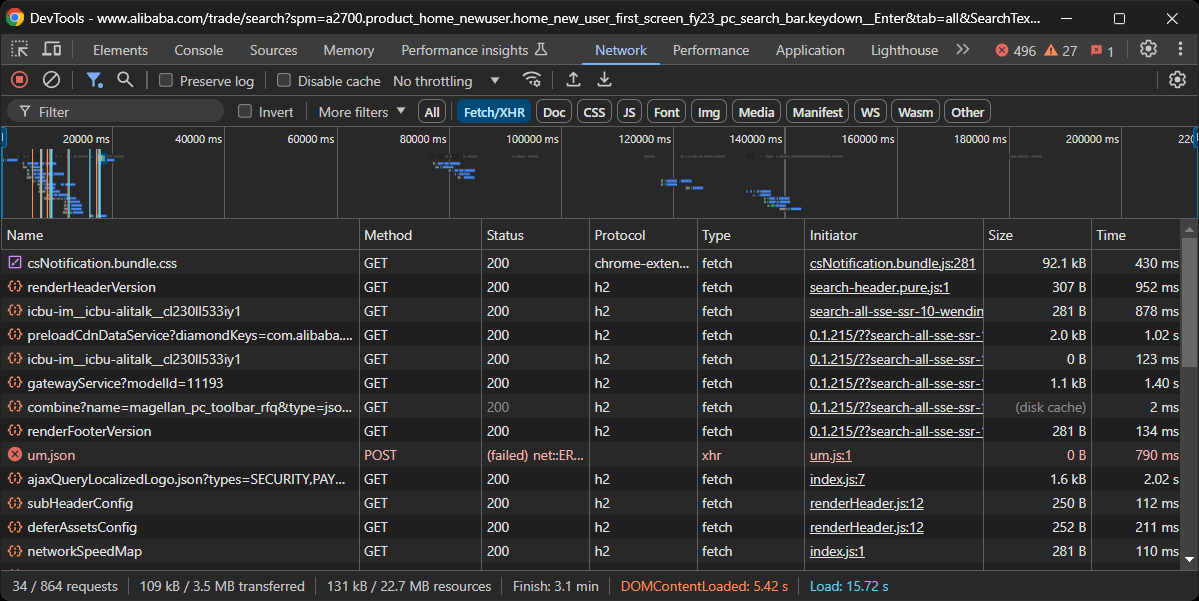
Nesta seção do DevTools, observe se a página faz alguma solicitação dinâmica significativa. Neste caso, ela faz, o que indica que a página é dinâmica. Uma análise mais aprofundada revela que a página usa JavaScript para renderização.
Em outras palavras, você precisa de uma ferramenta de automação de navegador como o Selenium para fazer o Scraping de dados do Alibaba de maneira eficaz. Saiba mais em nosso tutorial sobre Scraping de dados com Selenium.
O Selenium permite controlar programaticamente um navegador da web, simulando interações do usuário e permitindo que você faça scraping de conteúdo renderizado por JavaScript. É hora de instalá-lo e começar a usá-lo!
Etapa 3: Instale e configure o Selenium
Em um ambiente virtual ativado, instale o Selenium com este comando:
pip install -U selenium
Importe o Selenium no Scraper.py e crie um objeto WebDriver:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# inicializar uma instância do driver web do Chrome
driver = webdriver.Chrome(service=Service())
O código acima inicializa uma instância do WebDriver para controlar uma instância do Chrome. Observe que o Alibaba possui algumas medidas anti-scraping que podem bloquear navegadores headless.
Portanto, você não deve definir o sinalizador --headless. Como solução alternativa, considere explorar o Playwright Stealth.
Na última linha do seu Scraper, lembre-se de fechar o web driver:
driver.quit()
Ótimo! Você está totalmente configurado para começar a fazer scraping no Alibaba.
Etapa 4: conecte-se à página de destino
Use o método get() exposto pelo objeto Selenium WebDriver para visitar a página desejada:
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
driver.get(url)
O arquivo scraper.py agora conterá estas linhas de código:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# inicializar uma instância do driver web Chrome
driver = webdriver.Chrome(service=Service())
# a url da página de destino
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
# conectar-se à página de destino
driver.get(url)
# lógica de scraping...
# fechar o navegador
driver.quit()
Coloque um ponto de interrupção de depuração na linha final e inicie o script com o depurador. Aqui está o que você deve ver:
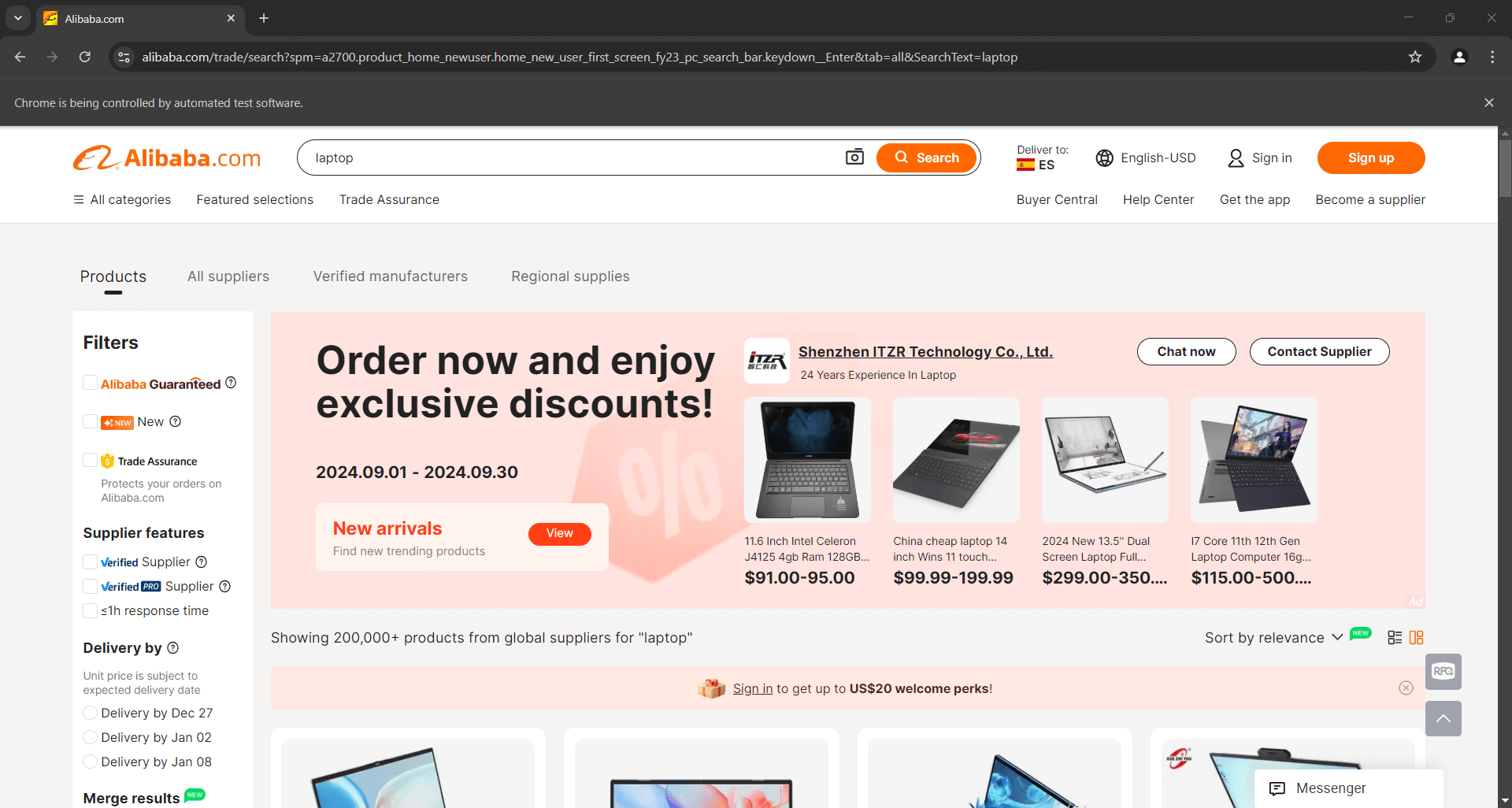
A mensagem “O Chrome está sendo controlado por um software de teste automatizado” certifica que o Selenium está controlando o Chrome conforme o esperado. Muito bem!
Etapa 5: selecione os elementos do produto
Como a página de produtos do Alibaba contém vários produtos, primeiro você precisa inicializar uma estrutura de dados para armazenar os dados coletados. Uma matriz funcionará perfeitamente para essa finalidade:
produtos = []
Em seguida, inspecione os elementos HTML dos produtos na página para entender:
- Como selecioná-los
- Quais dados eles contêm
- Como extrair esses dados
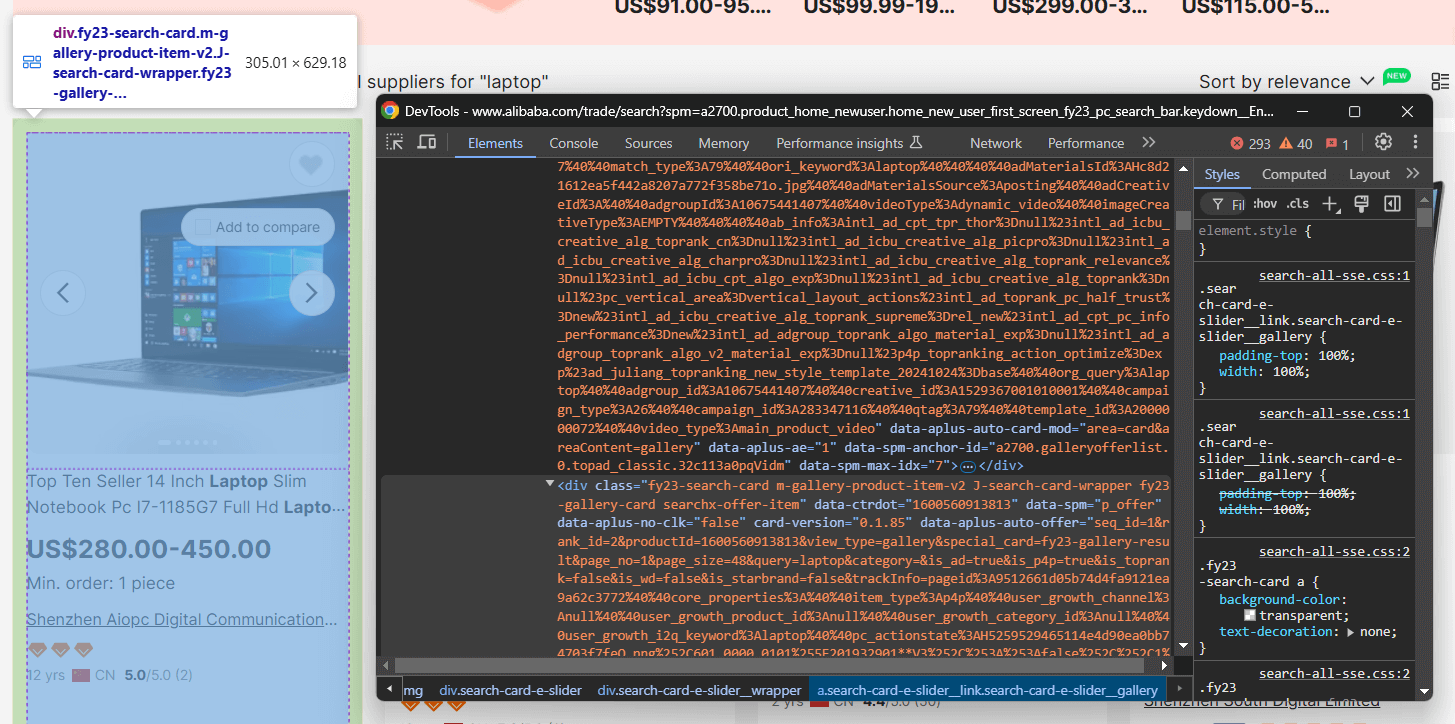
Aqui, você pode ver que cada elemento do produto é um nó .m-gallery-product-item-v2.
Use o Selenium para selecionar todos os elementos do produto:
product_elements = driver.find_elements(By.CSS_SELECTOR, ".m-gallery-product-item-v2")
find_elements() aplica a estratégia de seletor fornecida para recuperar elementos na página. No caso acima, a estratégia de seletor é um seletor CSS.
Não se esqueça de importar By:
from selenium.webdriver.common.by import By
Itere sobre os elementos selecionados e prepare-se para extrair dados de cada um deles:
para product_element em product_elements:
# extraia dados de cada elemento do produto
Ótimo! Você está um passo mais perto de extrair dados do Alibaba com sucesso.
Etapa 6: extraia os elementos do produto
Inspecione um elemento do produto para entender sua estrutura HTML:
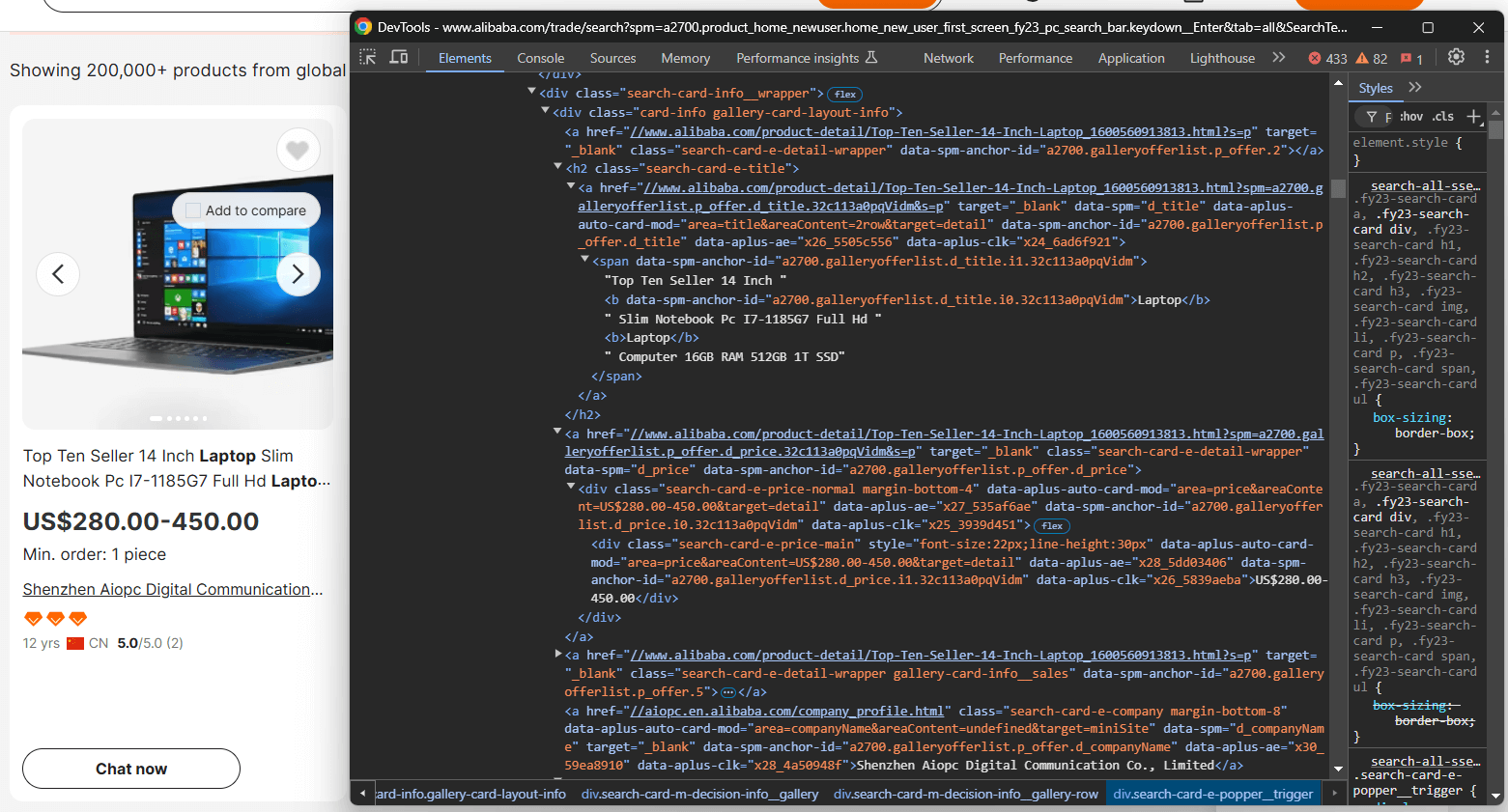
Aqui você pode ver que é possível extrair:
- A imagem do produto de
.search-card-e-slider__img - A descrição do produto de
.search-card-e-title - A faixa de preço do produto de
.search-card-e-price-main - A empresa/fabricante de
.search-card-e-company
No loop for, traduza essas informações em lógica de extração:
img_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-slider__img")
img = img_element.get_attribute("src")
description_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-title")
description = description_element.text.strip()
price_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-price-main")
price = price_element.text.strip()
company_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-company")
company = company_element.text.strip()
find_element() recupera o único elemento que corresponde ao seletor CSS fornecido. Em seguida, você pode acessar seu conteúdo de texto com o atributo text. Para obter o valor do atributo HTML de um nó, use o método get_attribute().
Use os dados coletados para preencher um dicionário de produtos e adicioná-lo à matriz de produtos:
produto = {
"img": img,
"description": description,
"price": price,
"company": company
}
produtos.append(produto)
Fantástico! A lógica de extração de dados do Alibaba está completa.
Etapa 7: Exporte os dados coletados para CSV
Atualmente, seus dados coletados estão armazenados na matriz de produtos. Para torná-los acessíveis e compartilháveis com outras pessoas, você precisa exportá-los para um formato legível, como um arquivo CSV.
Utilize o código a seguir para criar e preencher um arquivo CSV com os dados coletados:
csv_file_name = "products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["image", "description", "price", "company"])
# escreva a linha do cabeçalho
writer.writeheader()
# escreva as linhas de dados do produto
for product in products:
writer.writerow(product)
Não se esqueça de importar csv da Biblioteca Padrão do Python:
import csv
Uau! Seu scraper Aliaba está completo.
Etapa 8: Junte tudo
Abaixo está o código final do seu script de raspagem do Alibaba:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
# inicialize uma instância do driver web Chrome
driver = webdriver.Chrome(service=Service())
# a URL da página de destino
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
# conecte-se à página de destino
driver.get(url)
# onde armazenar os dados extraídos
produtos = []
# selecionar todos os elementos do produto na página
elementos_do_produto = driver.find_elements(By.CSS_SELECTOR, ".m-gallery-product-item-v2")
# iterar sobre os nós do produto e extrair dados deles
para elemento_do_produto em elementos_do_produto:
# extrair os detalhes do produto
img_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-slider__img")
img = img_element.get_attribute("src")
description_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-title")
description = description_element.text.strip()
price_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-price-main")
price = price_element.text.strip()
company_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-company")
company = company_element.text.strip()
# criar um dicionário de produtos com os
# dados extraídos
product = {
"img": img,
"description": description,
"price": price,
"company": company
}
# adicionar os dados do produto à matriz
products.append(product)
# definir o nome do arquivo CSV de saída
csv_file_name = "products.csv"
# abrir o arquivo no modo de gravação e criar um gravador CSV
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["img", "description", "price", "company"])
# escreva a linha do cabeçalho
writer.writeheader()
# escreva as linhas de dados do produto
for product in products:
writer.writerow(product)
# feche o navegador
driver.quit()
Em pouco mais de 60 linhas de código, você acabou de criar um Scraper do Alibaba em Python!
Inicie o Scraper com o seguinte comando:
python3 script.py
Ou, no Windows:
python script.py
Um arquivo products.csv aparecerá na pasta do seu projeto. Abra-o e você verá:
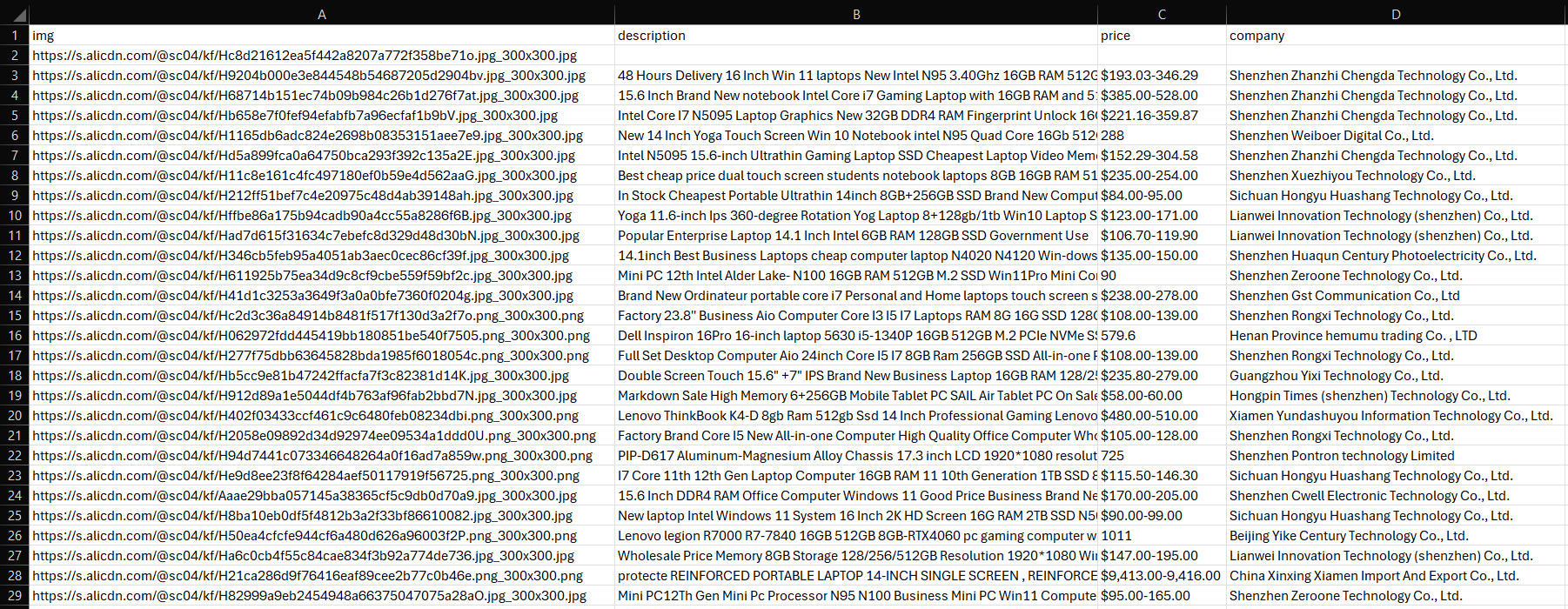
Et voilà! Missão cumprida. Os próximos passos? Cuide da paginação, implante seu script, automatize sua execução e refine-o ainda mais para obter o desempenho ideal!
Conclusão
Neste tutorial passo a passo, você aprendeu o que é um Scraper do Alibaba e os tipos de dados que ele pode recuperar. Você também viu como criar um script Python para extrair produtos do Alibaba usando menos de 100 linhas de código.
O problema é que o scraping do Alibaba traz desafios. A plataforma emprega medidas anti-bot rigorosas e adota interações como paginação, que tornam o processo de scraping mais complexo. Criar uma solução de scraping do Alibaba escalável e eficaz pode ser bastante exigente.
Esqueça esses desafios com nossa API Alibaba Scraper! Essa solução dedicada permite recuperar dados do site de destino por meio de chamadas de API simples, sem risco de ser bloqueado.
Se o Scraping de dados não é sua abordagem preferida, mas você ainda está interessado nos dados dos produtos, explore nossos Conjuntos de dados do Alibaba prontos para uso!
Crie uma conta gratuita na Bright Data hoje mesmo para experimentar nossas APIs de Scraper ou explorar nossos Conjuntos de dados.





