
Neste artigo, você aprenderá:
- O que são o Apache Airflow e o Apache Spark e o que eles oferecem.
- Por que orquestrar a API Web Unlocker da Bright Data com o Airflow e o Spark é uma estratégia poderosa para geração de leads.
- Como construir um pipeline de ponta a ponta que coleta, processa e armazena dados de negócios estruturados em escala.
Antes de nos aprofundarmos em ferramentas específicas e na implementação, vamos estabelecer os conceitos fundamentais e ver como eles se conectam dentro de um fluxo de trabalho de geração de leads.
O que é o Apache Airflow?
O Apache Airflow é uma plataforma de orquestração de fluxos de trabalho de código aberto para a criação, programação e monitoramento programáticos de pipelines de dados. Originalmente desenvolvido na Airbnb, ele permite que engenheiros de dados definam fluxos de trabalho como grafos acíclicos direcionados (DAGs) usando Python puro, oferecendo controle total sobre dependências de tarefas, novas tentativas, programação e alertas.
Seu principal objetivo é ajudar você a executar pipelines de dados complexos e com várias etapas de maneira confiável. Isso é alcançado por meio de um rico ecossistema de operadores (para Bash, Python, HTTP, Spark, SQL e outros), uma interface visual na web para monitorar execuções, lógica integrada de repetição e alertas, e integrações nativas com plataformas de nuvem como AWS, GCP e Azure.
Com uma compreensão da orquestração de fluxos de trabalho já estabelecida, vamos examinar o lado do processamento de dados do pipeline.
O Apache Spark é um mecanismo de análise unificado para processamento de dados em grande escala. Ele fornece uma estrutura de computação distribuída capaz de processar conjuntos de dados massivos na memória em um cluster de máquinas, tornando-o significativamente mais rápido do que os sistemas tradicionais de processamento baseados em disco.
O Spark suporta processamento em lote, streaming, consultas SQL, aprendizado de máquina e computação de grafos por meio de uma API unificada disponível em Python (PySpark), Scala, Java e R. Para cargas de trabalho intensivas em dados, como limpeza, deduplicação, enriquecimento e transformação de grandes volumes de dados comerciais coletados, o Spark é a ferramenta padrão do setor.
Apache Airflow vs Apache Spark: Qual é a diferença?
Se você é novo nessa pilha, é fácil confundir os dois, já que eles costumam aparecer juntos. Mas eles servem a propósitos muito diferentes:
- O Apache Airflow é um orquestrador. Ele decide quando executar tarefas, em que ordem, como lidar com falhas e como monitorar o pipeline geral. Ele não processa dados por si só.
- O Apache Spark é um processador de dados. Ele pega dados brutos ou semiestruturados e os transforma em escala usando computação distribuída por vários núcleos ou máquinas.
Eles se complementam muito bem. O Airflow agenda e aciona suas tarefas do Spark no momento certo e na sequência correta, enquanto o Spark lida com o trabalho pesado da transformação de dados. Neste tutorial, você verá como o Airflow orquestra todo o pipeline de ponta a ponta: acionando o Bright Data para coletar listagens de negócios, entregando os resultados brutos ao Spark para limpeza e enriquecimento e gravando os leads finais em um banco de dados.
Por que integrar o Bright Data a um pipeline Airflow + Spark?
O Airflow oferece um SimpleHttpOperator e um PythonOperator que permitem chamar qualquer API REST como uma tarefa do pipeline. Isso significa que você pode acionar a coleta de dados da web como uma etapa de primeira classe em seu DAG, juntamente com suas tarefas de transformação e carregamento.
No entanto, para injetar dados comerciais confiáveis e estruturados em seu pipeline em escala, você precisa de uma fonte capaz de lidar com medidas anti-bot, segmentação geográfica e saída estruturada sem a necessidade de manutenção de Scrapers personalizados. É aqui que entra a API Web Unlocker da Bright Data.
A API Web Unlocker oferece acesso a qualquer página da web pública, independentemente de proteção contra bots, requisitos de renderização de JavaScript ou restrições geográficas. Você envia uma solicitação POST com uma URL de destino, e a Bright Data retorna o conteúdo da página. Sem código de automação de navegador, sem gerenciamento de Proxy, sem tratamento de CAPTCHA.
Essa abordagem é especialmente útil para:
- Pipelines de geração de leads que coletam periodicamente novas listagens de empresas de diretórios e as alimentam em um CRM ou ferramenta de divulgação.
- Fluxos de trabalho de pesquisa de mercado que agregam dados comerciais entre regiões ou setores para análise competitiva.
- Sistemas de enriquecimento de dados que acrescentam detalhes de contato, tamanho da empresa ou classificação setorial a um banco de dados de leads existente.
- Plataformas de inteligência de vendas que monitoram mudanças nas listagens de empresas e acionam alertas quando as empresas-alvo atualizam seus perfis.
Ao combinar o agendamento e a orquestração do Airflow com o processamento distribuído de dados do Spark e a infraestrutura de dados da web da Bright Data, você pode construir um mecanismo de geração de leads de nível de produção que funciona de forma autônoma.
Como construir um pipeline de geração de leads com Airflow, Spark e Bright Data
Nesta seção guiada, você criará um pipeline de ponta a ponta que consiste em três etapas principais:
- Busca listagens de empresas: uma tarefa do Airflow chama a API Web Unlocker da Bright Data para coletar resultados de pesquisa das Páginas Amarelas em três cidades.
- Valida os dados coletados: uma segunda tarefa lê os resultados salvos e confirma se os dados foram coletados com sucesso.
- Processa com o Spark: uma tarefa do PySpark limpa, desduplica e pontua os registros brutos.
Observação: esta é uma das muitas arquiteturas possíveis. Você pode gravar a saída do Spark em um data warehouse como o BigQuery ou o Snowflake, enviá-la diretamente para um CRM por meio de sua API ou alimentá-la em uma etapa de enriquecimento baseada em LLM para pontuação automatizada de leads.
Siga as instruções abaixo para construir um pipeline automatizado de geração de leads com a API Web Unlocker da Bright Data no Apache Airflow e no Spark!
Pré-requisitos
Para acompanhar, você precisa de:
- Uma conta da Bright Data com uma zona do Web Unlocker ativa. Faça login no seu painel da Bright Data, vá para Configurações da conta e copie seu token de API. Ele estará no formato UUID. Anote também o nome da sua zona.
- Docker Desktop (macOS ou Windows) OU um ambiente Python nativo (Ubuntu/Linux). Consulte a Etapa 1 para ambas as opções.
Etapa 1: Configuração do projeto
Instale o Docker Desktop e certifique-se de que ele esteja em execução antes de continuar. Nas configurações do Docker Desktop, vá para Recursos e aloque pelo menos 5 GB de memória. A pilha de contêineres múltiplos do Airflow precisa disso.
Etapa 2: Crie a estrutura do seu projeto
Crie um diretório de trabalho e as pastas necessárias para o Airflow:
mkdir airflow-lead-pipeline && cd airflow-lead-pipeline
mkdir dags spark_jobs logs plugins configA estrutura do seu projeto ficará assim:
airflow-lead-pipeline/
├── dags/
│ └── lead_generation_dag.py
├── spark_jobs/
│ └── process_leads.py
├── logs/
├── plugins/
├── config/
├── Dockerfile
└── docker-compose.yamlEtapa 3: Configurar o Docker Compose
Baixe o arquivo oficial do Airflow Docker Compose:
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.7.3/docker-compose.yaml'Crie um Dockerfile no mesmo diretório. Isso estende a imagem base do Airflow para adicionar a biblioteca requests:
FROM apache/airflow:2.7.3
RUN pip install requests pysparkAbra o arquivo docker-compose.yaml. Encontre o bloco x-airflow-common próximo ao topo e adicione build: . diretamente abaixo da linha image:
x-airflow-common:
&airflow-common
image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.7.3}
build: .Além disso, certifique-se de que a linha _PIP_ADDITIONAL_REQUIREMENTS esteja vazia. O Dockerfile é o local correto para dependências, não esta variável de ambiente:
_PIP_ADDITIONAL_REQUIREMENTS: ""Por fim, adicione uma montagem de volume para spark_jobs/ na lista volumes: do mesmo bloco. O arquivo padrão monta apenas dags/, logs/, plugins/ e config/, portanto, o contêiner do worker não conseguirá encontrar seu arquivo de trabalho do Spark sem essa adição:
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/spark_jobs:/opt/airflow/spark_jobsO restante do arquivo permanece exatamente como foi baixado. Por padrão, ele fornece o CeleryExecutor com o Redis como broker de mensagens e o PostgreSQL como banco de dados de metadados, as pastas dags/, logs/, config/ e plugins/ montadas como volumes a partir da pasta do seu projeto, credenciais padrão com nome de usuário airflow e senha airflow, e um serviço airflow-init que é executado uma vez na primeira inicialização para migrar o banco de dados e criar o usuário admin.
Compile a imagem personalizada e inicie todos os serviços:
docker compose build
docker compose up -dAguarde cerca de 60 segundos e, em seguida, verifique se todos os seis contêineres estão em bom estado:
docker compose psSaída esperada:

Abra http://localhost:8080 no seu navegador e faça login com o nome de usuário airflow e a senha airflow.
Etapa 4: Escreva o DAG do Airflow
Crie o arquivo dags/lead_generation_dag.py:
import json
import requests
from datetime import datetime, timedelta
from pathlib import Path
from airflow import DAG
from airflow.operators.python import PythonOperator
API_KEY = "seu-token-api-brightdata-aqui"
Zona = "web_unlocker1"
BASE_URL = "https://api.brightdata.com/request"
RAW_DATA_PATH = "/tmp/brightdata_raw/leads.json"
HEADERS = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
TARGETS = [
"https://www.yellowpages.com/search?search_terms=software+company&geo_location_terms=San+Francisco+CA",
"https://www.yellowpages.com/search?search_terms=marketing+agency&geo_location_terms=New+York+NY",
"https://www.yellowpages.com/search?search_terms=fintech+startup&geo_location_terms=Austin+TX",
]
default_args = {
"owner": "data-team",
"retries": 2,
"retry_delay": timedelta(minutes=5),
}
def fetch_business_listings(**context):
results = []
for url in TARGETS:
print(f"Buscando: {url}")
response = requests.post(
BASE_URL,
headers=HEADERS,
json={
"zona": ZONA,
"url": url,
"format": "raw",
"data_format": "markdown",
},
timeout=60,
)
response.raise_for_status()
results.append({
"url": url,
"content": response.text,
"status": response.status_code,
})
print(f"Recuperados {len(response.text)} caracteres de {url}")
Path(RAW_DATA_PATH).parent.mkdir(parents=True, exist_ok=True)
with open(RAW_DATA_PATH, "w") as f:
json.dump(results, f, indent=2)
print(f"Salvei {len(results)} páginas em {RAW_DATA_PATH}")
context["ti"].xcom_push(key="record_count", value=len(results))
def validate_output(**context):
count = context["ti"].xcom_pull(key="record_count", task_ids="fetch_listings")
with open(RAW_DATA_PATH) as f:
data = json.load(f)
print(f"Validação aprovada: {count} páginas coletadas")
for item in data:
print(f" URL: {item['url']} | Status: {item['status']} | Tamanho: {len(item['content'])} caracteres")
com DAG(
dag_id="brightdata_lead_generation",
default_args=default_args,
description="Coletar leads de negócios usando o Bright Data Web Unlocker",
schedule_interval="0 6 * * 1",
start_date=datetime(2026, 3, 12),
catchup=False,
tags=["lead-generation", "brightdata"],
) as dag:
fetch_listings = PythonOperator(
task_id="fetch_listings",
python_callable=fetch_business_listings,
)
validate_data = PythonOperator(
task_id="validate_data",
python_callable=validate_output,
)
fetch_listings >> validate_dataSubstitua your-brightdata-api-token-here pelo seu token de API real e atualize ZONA para corresponder ao nome da sua zona no Web Unlocker.
Vamos explicar o que cada parte faz:
API_KEYeZONE: Suas credenciais da Bright Data. O token da API é o token no formato UUID das configurações da sua conta, não uma senha da zona.TARGETS: Três URLs de pesquisa do Yellow Pages cobrindo empresas de software em São Francisco, agências de marketing em Nova York e startups de fintech em Austin.fetch_business_listings: percorre cada URL de destino e envia uma solicitação POST para a API do Web Unlocker. A Bright Data lida com medidas anti-bot, rotação de Proxy e renderização de JavaScript, retornando o conteúdo da página como Markdown. Os resultados são salvos em disco, e a contagem de registros é enviada para o armazenamento XCom do Airflow para que a próxima tarefa possa lê-los.validate_output: Lê o arquivo salvo e registra cada URL, status HTTP e tamanho do conteúdo. Isso funciona como uma verificação leve da qualidade dos dados antes do processamento posterior.fetch_listings >> validate_data: O operador>>define a dependência da tarefa. A validação só é executada após o sucesso da busca.
Importante: Sempre defina
start_datecomo a data de hoje ecatchup=Falseao implantar pela primeira vez um DAG com uma programação recorrente. Se você definirstart_datecomo uma data passada comcatchup=True, o Airflow enfileira uma execução de preenchimento retroativo para cada intervalo perdido desde essa data. Para uma programação semanal iniciada há dez semanas, isso significa dez execuções simultâneas competindo por slots de worker no momento em que você reativa o DAG.
Etapa 5: Escreva o trabalho de transformação PySpark
Crie o arquivo spark_jobs/process_leads.py:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, trim, regexp_replace, when, lit
import sys
def main(input_path: str, output_path: str):
spark = SparkSession.builder
.appName("BrightData Lead Processing")
.config("spark.sql.adaptive.enabled", "true")
.getOrCreate()
raw_df = spark.read.option("multiLine", True).json(input_path)
cleaned_df = raw_df.select(
trim(col("name")).alias("company_name"),
trim(col("phone")).alias("phone"),
trim(col("website")).alias("website"),
trim(col("address")).alias("address"),
trim(col("city")).alias("city"),
trim(col("state")).alias("state"),
trim(col("category")).alias("industry"),
col("rating").cast("float").alias("rating"),
col("reviews_count").cast("integer").alias("reviews_count"),
)
.filter(col("company_name").isNotNull())
.filter(col("phone").isNotNull())
.dropDuplicates(["company_name", "phone"])
enriched_df = cleaned_df.withColumn(
"lead_score",
when(
(col("rating") >= 4.0) & (col("reviews_count") >= 50), lit("hot")
).when(
(col("rating") >= 3.0) & (col("reviews_count") >= 10), lit("warm")
).otherwise(lit("cold"))
).withColumn(
"website_clean",
regexp_replace(col("website"), "^https?://", "")
)
enriched_df.write.mode("overwrite").parquet(output_path)
print(f"Processados {enriched_df.count()} leads. Saída gravada em {output_path}")
spark.stop()
if __name__ == "__main__":
main(sys.argv[1], sys.argv[2])Esta tarefa realiza quatro ações. Ela carrega o JSON bruto gravado pelo fetch_listings a partir do disco. Ela limpa os dados normalizando espaços em branco, convertendo campos numéricos e descartando registros com nome ou número de telefone ausentes. Ela desduplica registros por nome da empresa e número de telefone para remover listagens duplicadas entre cidades. Por fim, atribui uma pontuação a cada registro com a etiqueta lead_score: empresas com classificação de 4,0 ou superior e pelo menos 50 avaliações são marcadas como “quentes”, aquelas com classificação de 3,0 ou superior e pelo menos 10 avaliações são marcadas como “mornas”, e todas as outras são marcadas como “frias”.
Etapa 6: Acionar e monitorar o pipeline
Com seu arquivo DAG na pasta dags/, o Airflow o detecta automaticamente em até 30 segundos.
Usuários do Docker, retomem e acionem o DAG:
docker compose exec --user airflow airflow-scheduler airflow dags unpause brightdata_lead_generation
docker compose exec --user airflow airflow-scheduler airflow dags trigger brightdata_lead_generation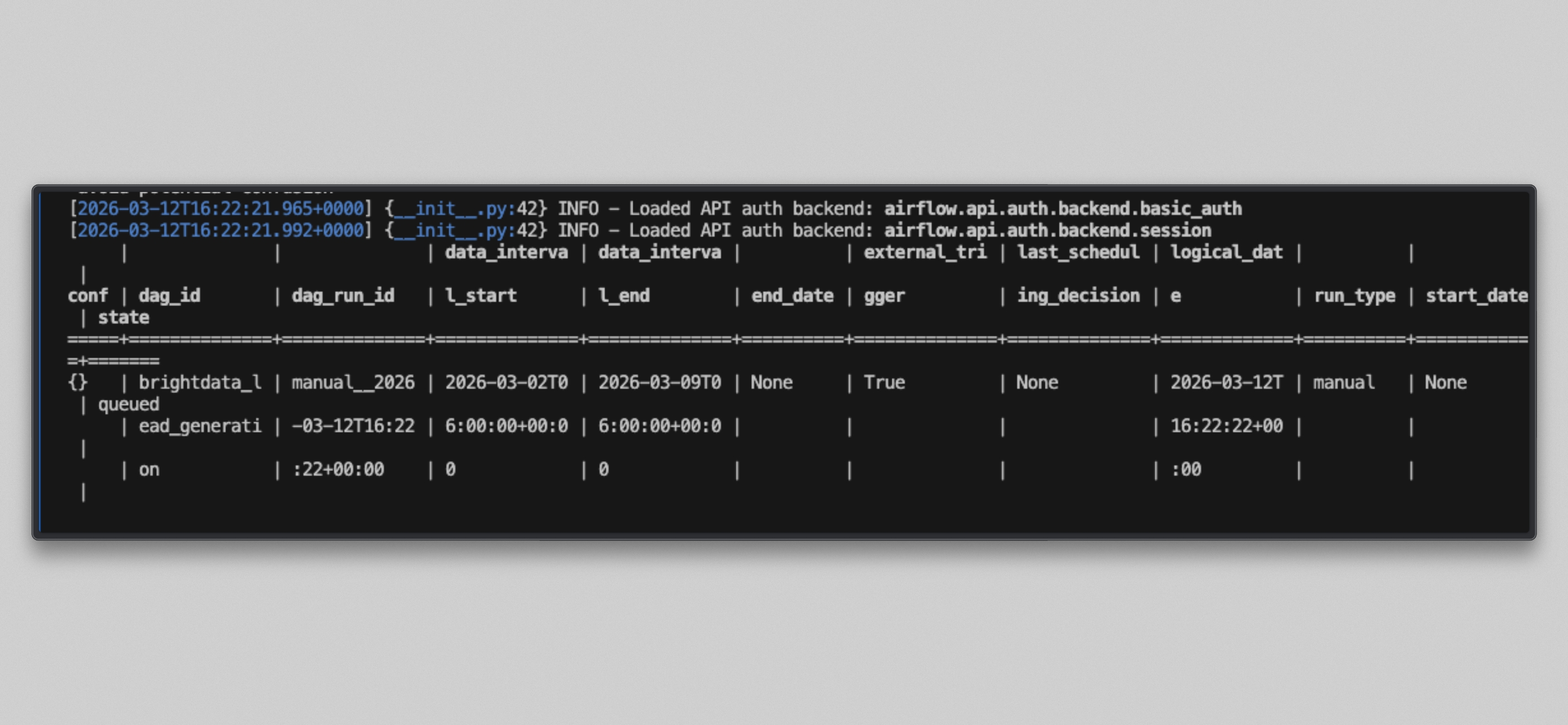
Observe os logs do worker:
docker compose logs airflow-worker -f --tail=20Você verá uma saída como esta assim que as tarefas forem executadas:
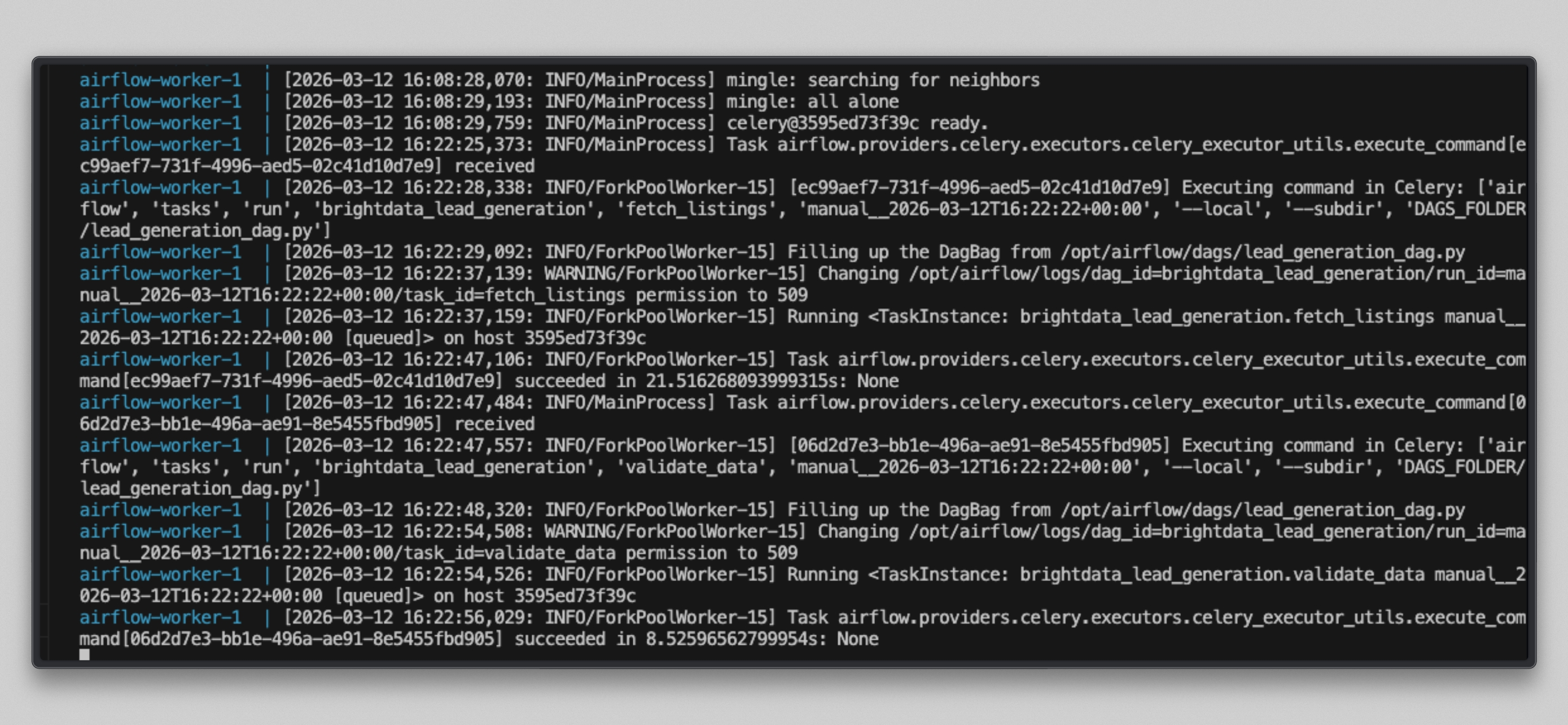
Abra http://localhost:8080, clique no DAG brightdata_lead_generation e alterne para a visualização Grid. Cada bloco de tarefa fica verde à medida que é concluído. Clique em qualquer bloco de tarefa e selecione Log para ver a saída em tempo real, incluindo cada URL buscada e a contagem de caracteres retornada pela Bright Data.
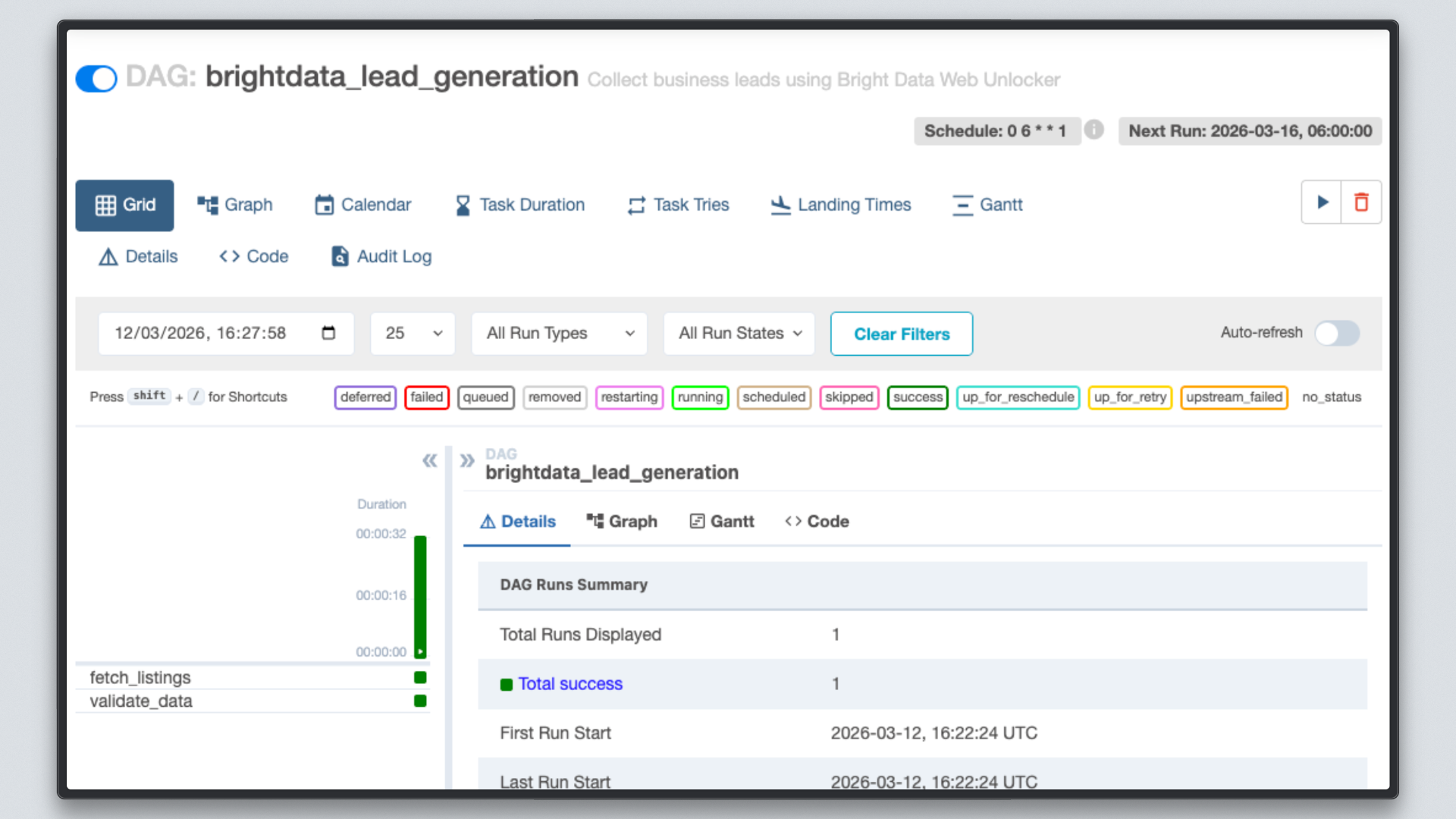
Etapa 7: Inspecione os resultados
Quando ambas as tarefas estiverem verdes, verifique o arquivo de saída.
Usuários do Docker:
docker compose exec --user airflow airflow-worker cat /tmp/brightdata_raw/leads.jsonUsuários nativos do Ubuntu:
cat /tmp/brightdata_raw/leads.jsonVocê verá uma matriz JSON com três entradas, uma por URL de destino:
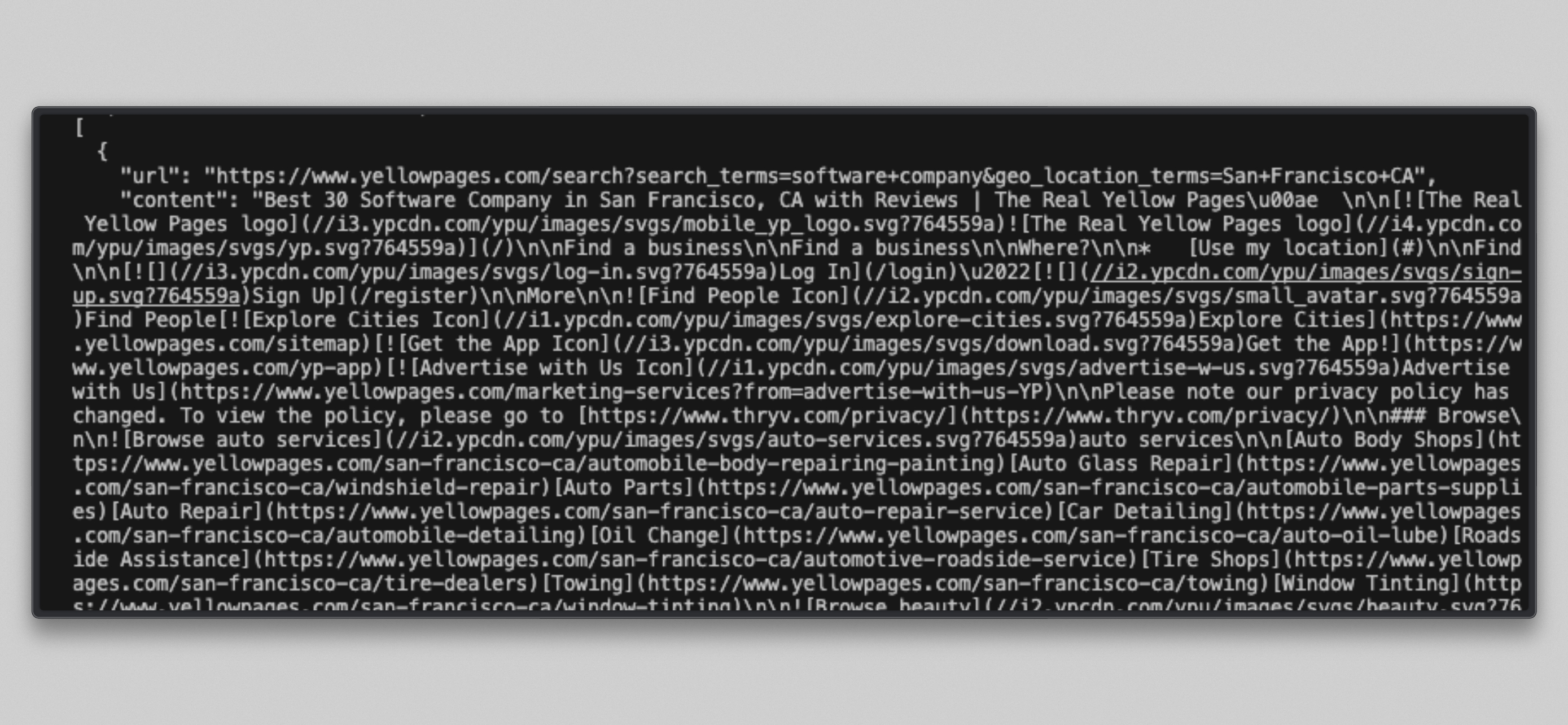
Observação: algumas URLs do Yellow Pages podem retornar uma mensagem
de bad_endpointse o site estiver restrito no modo de acesso imediato da Bright Data. Isso é normal. A Bright Data exibe o erro na resposta em vez de falhar silenciosamente. Entre em contato com seu Gerente de conta da Bright Data se precisar de acesso total a um site restrito.
Por fim, execute a tarefa do Spark com a saída:
docker compose exec --user airflow airflow-worker python /opt/airflow/spark_jobs/process_leads.py
/tmp/brightdata_raw/leads.json
/tmp/brightdata_processed/leadsIsso grava arquivos Parquet limpos e pontuados em /tmp/brightdata_processed/leads, prontos para serem carregados no PostgreSQL ou em qualquer sistema downstream.
A API do Web Unlocker forneceu conteúdo novo e em tempo real do Yellow Pages, e seu pipeline automaticamente limpou, pontuou e armazenou esse conteúdo sem escrever uma única linha de código de scraping ou gerenciamento de Proxy. Coletar listagens de empresas manualmente é notoriamente difícil devido aos sistemas de detecção de bots e à limitação de taxa. Ao usar o Web Unlocker da Bright Data, você pode buscar com confiabilidade o conteúdo de páginas de qualquer site público em qualquer região, sem precisar manter nenhuma infraestrutura.
Indo além
Este pipeline é uma base funcional, e você pode expandi-lo em várias direções:
- Substitua o sistema de arquivos local pelo Amazon S3 ou Google Cloud Storage para a camada de dados intermediária, de modo que o pipeline funcione entre workers distribuídos.
- Adicione uma etapa de enriquecimento com LLM entre o processamento do Spark e o carregamento do banco de dados, usando a API da OpenAI ou da Anthropic para gerar resumos de contato personalizados para cada lead promissor.
- Troque a saída local por um envio direto de CRM para o Salesforce, HubSpot ou Pipedrive usando os operadores de provedor existentes do Airflow.
- Adicione uma tarefa de verificação de qualidade de dados usando o Great Expectations ou o SQLCheckOperator do Airflow para validar a contagem de registros e a integridade dos campos antes de confirmar os dados.
Dimensionar a tarefa do Spark para um cluster gerenciado usando AWS EMR, - Google Dataproc ou Databricks, atualizando a URL de conexão do Spark no Airflow; o DAG e o código PySpark permanecem os mesmos.
- Use a API SERP da Bright Data como uma tarefa de coleta paralela para enriquecer cada lead com notícias recentes ou dados de visibilidade de pesquisa.
As possibilidades são praticamente infinitas!
Conclusão
Neste artigo, você construiu um pipeline funcional de geração de leads combinando a API Web Unlocker da Bright Data, o Apache Airflow e o Apache Spark.
O Airflow lida com agendamento, lógica de repetição, gerenciamento de dependências e observabilidade. O Spark lida com a limpeza distribuída, a deduplicação e a pontuação de dados brutos de negócios. A Bright Data elimina a parte mais difícil: coletar conteúdo de páginas atualizadas da web sem gerenciar Proxies, escrever código de Scraper ou lutar contra sistemas anti-bot.
Ao contrário das ferramentas de automação sem código, essa pilha oferece controle total sobre todas as camadas do pipeline: parâmetros de coleta, lógica de transformação, esquema de saída e cadência de agendamento. Ela se integra naturalmente a qualquer plataforma de dados moderna e se adapta ao seu volume de dados.
Para construir pipelines mais robustos, explore o conjunto completo de ferramentas de coleta de dados da Bright Data, incluindo a API SERP para dados de pesquisa, o Web Unlocker para páginas com uso intenso de JavaScript e Conjuntos de dados prontos para uso em casos comuns.
Cadastre-se hoje mesmopara obter uma conta gratuita da Bright Data e comece a coletar os dados de negócios de que seu pipeline precisa.






