Neste artigo, abordaremos:
- Explicação do pipeline ETL
- Benefícios dos pipelines ETL
- Como implementar um pipeline ETL em uma empresa
- Automatização de algumas etapas do pipeline ETL
- Perguntas frequentes sobre o pipeline ETL
Explicação sobre o pipeline ETL
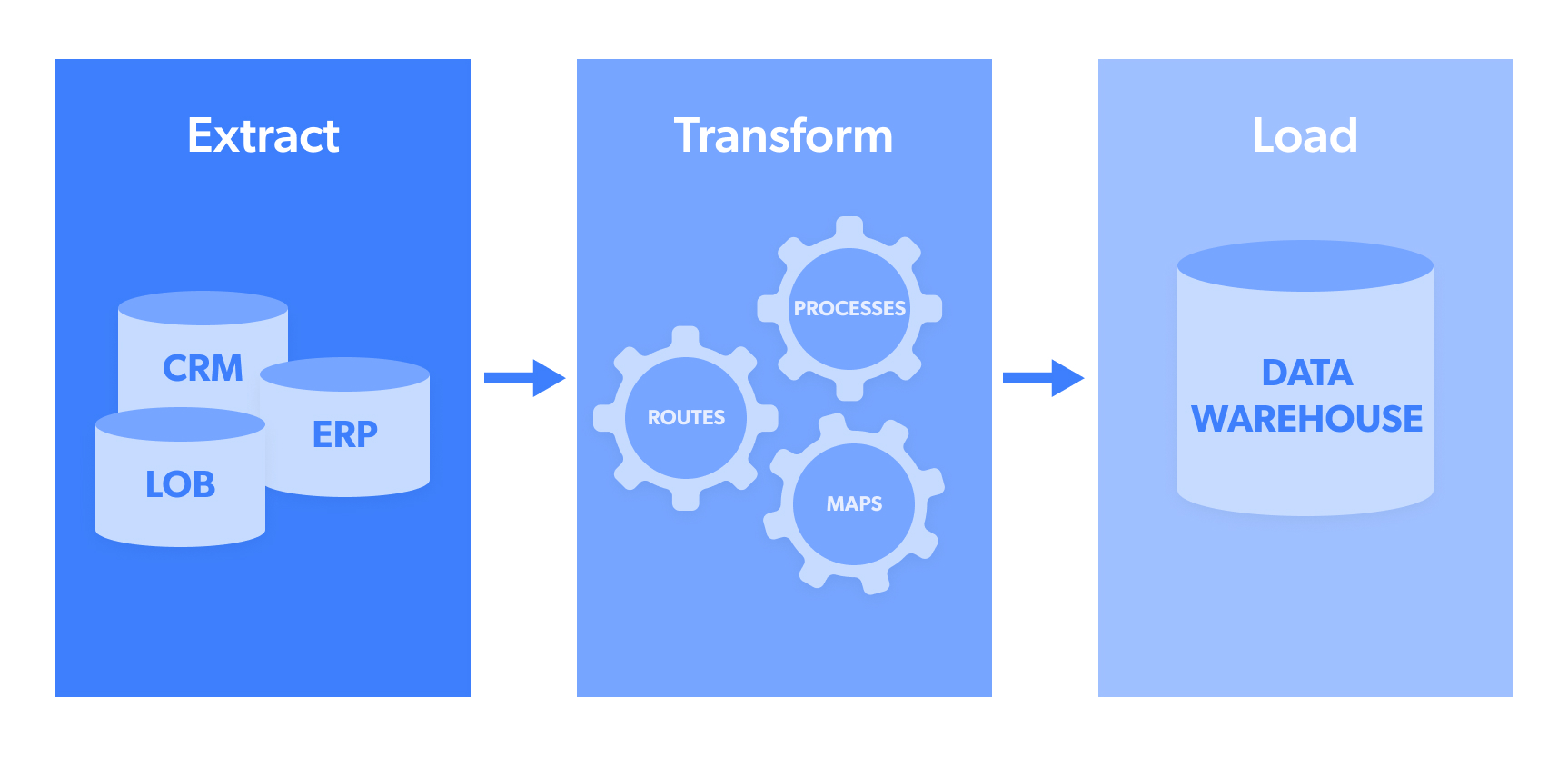
ETL significa:
- Extração: é a etapa de extração de dados de uma fonte ou pool de dados, como um banco de dados NoSQL ou um site de código aberto, como publicações populares nas redes sociais.
- Transformar: os dadosextraídos são normalmente coletados em vários formatos. “Transformação” refere-se ao processo de estruturar esses dados para que fiquem em um formato uniforme que possa ser enviado ao sistema de destino. Isso pode incluir formatos como JSON, CSV, HTML ou Microsoft Excel
- Carregar: é a transferência/upload real dos dados para um pool/armazém de dados, CRM ou banco de dados, para que possam ser analisados e gerar resultados acionáveis. Alguns dos destinos de dados mais usados incluem webhook, e-mail, Amazon S3, Google Cloud, Microsoft Azure, SFTP ou API.
Coisas a ter em mente:
- Os pipelines ETL são especialmente adequados para conjuntos de dados menores com níveis mais altos de complexidade.
- Os “pipelines ETL” são frequentemente confundidos com“pipelines de dados”— o último é um termo mais amplo para arquiteturas de coleta de dados de ciclo completo, enquanto o primeiro é um procedimento mais direcionado.
Benefícios dos pipelines ETL
Algumas das principais vantagens dos pipelines ETL incluem:
Primeiro: dados brutos de várias fontes
As empresas que buscam crescer rapidamente podem se beneficiar de arquiteturas robustas de pipeline ETL, no sentido de que podem ampliar seu escopo de visão. Isso é possível porque um bom fluxo de ingestão de dados ETL permite que as empresas coletem dados brutos em vários formatos, de várias fontes, e os insiram em seus sistemas de forma eficiente para análise. Isso significa que a tomada de decisões estará muito mais alinhada com as tendências atuais dos consumidores/concorrentes.
Segundo: Reduz o “tempo para obter insights”
Assim como em qualquer fluxo operacional, uma vez que ele é colocado em ação, o tempo entre a coleta inicial e a obtenção de insights acionáveis pode ser reduzido consideravelmente. Em vez de ter especialistas em dados revisando manualmente cada Conjunto de dados, convertendo-o para o formato desejado e, em seguida, enviando-o para o destino final, esse processo é simplificado, permitindo insights mais rápidos.
Três: Libera recursos da empresa
Com base neste último ponto, bons pipelines ETL funcionam para liberar recursos da empresa em vários níveis, incluindo a liberação de pessoal. Na verdade, as empresas:
“Gastam mais de 80% do seu tempo limpando dados em preparação para o uso de IA”.
A limpeza de dados, neste caso, entre outras coisas, refere-se à “formatação de dados”, algo que pipelines ETL sólidos cuidarão.
Como implementar um pipeline ETL em uma empresa
Aqui está um caso de uso de comércio eletrônico que pode ajudar a ilustrar como um pipeline ETL pode ser implementado em uma empresa:
Uma empresa de varejo digital precisa agregar muitos pontos de dados diferentes de várias fontes para se manter competitiva e atraente para os clientes-alvo. Alguns exemplos de fontes de dados podem incluir:
- Avaliações deixadas para fornecedores concorrentes em mercados
- Tendências de pesquisa do Google para itens/serviços
- Anúncios (texto + imagens) de empresas concorrentes
Todos esses pontos de dados podem ser coletados em diferentes formatos, como (.txt), (.csv), (.tab), SQL, (.jpg) e outros. Ter informações-alvo em vários formatos não é propício para os objetivos comerciais da empresa (ou seja, obter insights sobre concorrentes/consumidores em tempo real e fazer alterações para capturar volumes maiores de vendas).
É por esse motivo que esse fornecedor de comércio eletrônico pode optar por configurar um pipeline ETL que converte todos os formatos acima em um dos seguintes (com base em suas preferências de algoritmo/sistema de entrada):
- JSON
- CSV
- HTML
- Microsoft Excel
Digamos que eles tenham escolhido o Microsoft Excel como seu formato de saída preferido para exibir catálogos de produtos concorrentes. Um gerente de ciclo de vendas e produção pode então revisar isso rapidamente e identificar novos produtos vendidos pelos concorrentes que eles podem querer incluir em seu próprio catálogo digital.
Automatizando algumas das etapas do pipeline ETL
Muitas empresas simplesmente não têm tempo, recursos e mão de obra para configurar manualmente as operações de coleta de dados, bem como o pipeline ETL. Nesses cenários, elas optam por uma ferramenta de extração de dados da web totalmente automatizada.
Esse tipo de tecnologia permite que as empresas se concentrem em suas próprias operações comerciais, ao mesmo tempo em que aproveitam arquiteturas de pipeline ETL autônomas desenvolvidas e operadas por terceiros. Os principais benefícios dessa opção incluem:
- Extração de dados da web sem infraestrutura/código
- Sem necessidade de mão de obra técnica adicional
- Os dados são limpos, analisados e sintetizados automaticamente e entregues em um formato uniforme de sua escolha (JSON, CSV, HTML ou Microsoft Excel) – Esta etapa é a substituição do pipeline ETL, que é feita automaticamente
- Os dados são então entregues ao consumidor do lado da empresa (por exemplo, uma equipe, algoritmo ou sistema). Isso inclui webhook, e-mail, Amazon S3, Google Cloud, Microsoft Azure, SFTP ou API.
Além das ferramentas automatizadas de extração de dados, há também um atalho eficiente e útil que poucas pessoas conhecem. Muitas empresas estão acelerando o “tempo de obtenção de insights de dados” ao eliminar a necessidade de coleta de dados e pipelines ETL por completo. Elas estão fazendo isso aproveitando o poder de Conjuntos de dados prontos para uso, que já estão formatados de maneira uniforme e são entregues diretamente aos consumidores de dados internos.
Conclusão
Os pipelines ETL são uma maneira eficaz de otimizar a coleta de dados de várias fontes, diminuir o tempo necessário para obter insights acionáveis a partir dos dados e liberar mão de obra e recursos essenciais. Mas, apesar da eficiência que os pipelines ETL oferecem, eles ainda exigem bastante tempo e esforço para serem desenvolvidos e operados. É por esse motivo que muitas empresas optam por terceirizar e automatizar sua coleta de dados e fluxo de pipeline ETL usando ferramentas como a ferramenta de Scraping de dados da Bright Data. Contate-nos para encontrar a solução definitiva para o seu projeto de dados.
Perguntas frequentes sobre pipelines ETL
ETL significa Extrair, Transformar e Carregar. É o processo que permite obter dados de várias fontes e formatá-los uniformemente para ingestão por um sistema ou aplicativo de destino.
O carregamento é a etapa final do processo ETL, que envolve o upload dos dados em um formato uniforme para um pool ou armazém de dados, para que possam ser processados/analisados/derivados insights a partir deles. Os três principais tipos de carregamento incluem: 1. Carregamentos iniciais 2. Carregamentos incrementais 3. Atualizações completas
Sim, é possível criar um pipeline ETL com Python. Para isso, são necessárias várias ferramentas, incluindo o “Luigi” para gerenciar o fluxo de trabalho, o “Pandas” para processamento de dados e movimentação.