

Neste guia, você aprenderá:
- O que é o Agno e por que ele é uma excelente opção para criar fluxos de trabalho agênticos.
- Por que a raspagem da Web desempenha uma função tão valiosa nos agentes de IA.
- Como integrar o Agno com suas ferramentas integradas do Bright Data para criar um agente de raspagem da Web.
Vamos mergulhar de cabeça!
O que é Agno?
O Agno é uma estrutura Python de pilha completa para a criação de sistemas multiagentes que aproveitam a memória, o conhecimento e o raciocínio avançado. Ele permite a criação de agentes de IA sofisticados para uma ampla gama de casos de uso. Eles abrangem desde agentes simples que usam ferramentas até equipes de agentes colaborativos com estado e determinismo.
O Agno é independente de modelo, tem alto desempenho e coloca o raciocínio no centro de seu projeto. Ele oferece suporte a entradas e saídas multimodais, orquestração complexa de vários agentes, pesquisa agêntica integrada com bancos de dados vetoriais e tratamento completo de memória/sessão.
No momento em que este artigo foi escrito, a Agno é uma das bibliotecas de código aberto mais populares para a criação de agentes de IA, com mais de 29 mil estrelas no GitHub:
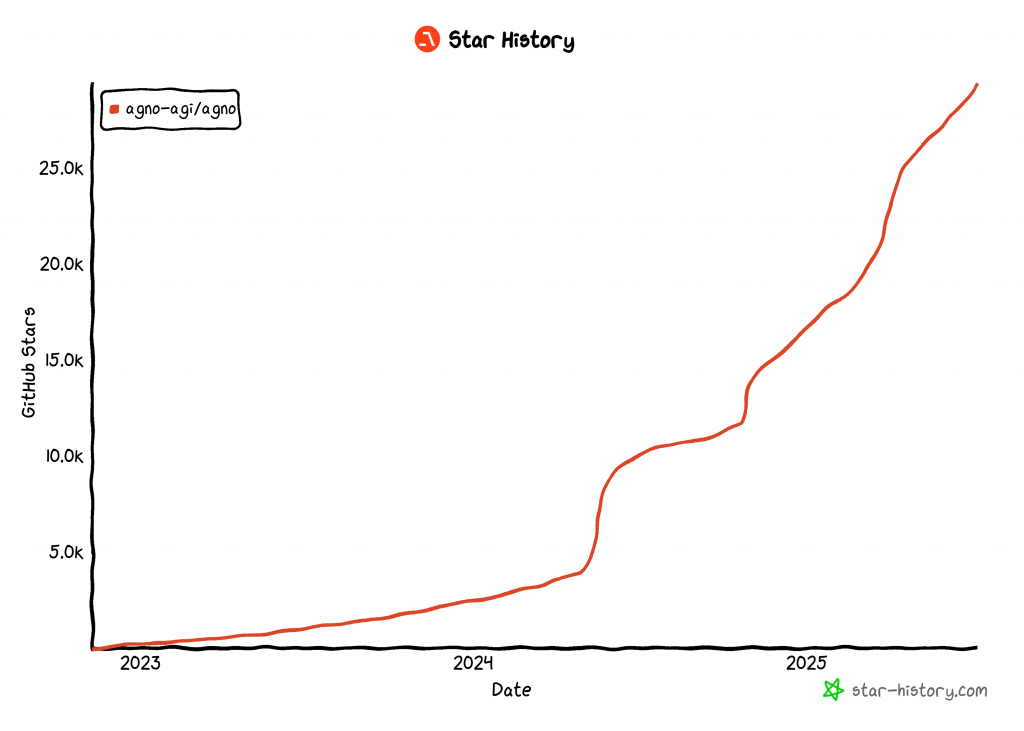
Seu rápido crescimento destaca a rapidez com que a Agno está ganhando força na comunidade de desenvolvedores e de IA.
Por que o Agentic Web Scraping é tão útil
A raspagem tradicional da Web se baseia na escrita de regras rígidas de análise de dados para extrair dados de páginas específicas da Web. O problema? Os sites mudam sua estrutura com frequência, o que significa que você precisa atualizar constantemente sua lógica de raspagem. Isso resulta em altos custos de manutenção e pipelines frágeis.
É por isso que a raspagem da Web com IA está ganhando apoio. Em vez de criar scripts de análise personalizados, você pode usar um modelo de IA para extrair dados diretamente do HTML de uma página da Web com apenas um simples comando. Essa abordagem é tão popular que muitas ferramentas de raspagem de IA surgiram recentemente.
Ainda assim, a raspagem da Web por IA se torna ainda mais avançada quando incorporada em uma arquitetura de IA agêntica. Em particular, você pode criar um agente de raspagem da Web dedicado ao qual outros agentes de IA podem se conectar. Isso é possível em fluxos de trabalho com vários agentes ou por meio de protocolos de IA como o A2A do Google.
O Agno torna tudo isso possível. Ele permite que você crie agentes de raspagem de IA autônomos ou ecossistemas complexos de vários agentes. No entanto, os LLMs comuns não foram projetados para uma raspagem eficiente da Web. Eles geralmente não conseguem se conectar a sites com fortes defesas contra bots – ou pior, podem “alucinar” e retornar dados falsos.
Para resolver essas limitações, a Agno se integra nativamente com a Bright Data por meio de ferramentas de raspagem dedicadas. Com essas ferramentas, seu agente de IA pode extrair dados novos e estruturados de qualquer site.
Para evitar bloqueios e interrupções, a Bright Data supera desafios como impressão digital TLS, impressão digital de navegador e dispositivo, CAPTCHAs, proteções Cloudflare e muito mais para você. Depois que os dados são recuperados, eles são inseridos no LLM para interpretação e análise, seguindo as instruções originais da tarefa.
Explore como integrar as ferramentas da Bright Data em um agente Agno para obter um nível superior de raspagem da Web!
Como integrar ferramentas de dados brilhantes para raspagem da Web na Agno
Nesta seção passo a passo, você verá como usar o Agno para criar um agente de IA de coleta de dados da Web. Ao integrar as ferramentas do Bright Data, você dará ao seu agente Agno a capacidade de extrair dados de qualquer página da Web.
Siga as instruções abaixo para criar seu agente de raspagem com a tecnologia Bright Data no Agno!
Pré-requisitos
Para seguir este tutorial, verifique se você tem o seguinte:
- Python 3.7 ou superior instalado localmente (recomendamos usar a versão mais recente).
- Uma chave de API da Bright Data.
- Uma chave de API para um provedor de LLM compatível (neste caso, usaremos o Gemini porque ele é gratuito para uso via API, mas qualquer provedor de LLM compatível serve).
Não se preocupe se você ainda não tiver uma chave de API da Bright Data ou uma chave de API da Gemini. Nós o orientaremos sobre como criá-las nas próximas etapas.
Etapa 1: Configuração do projeto
Abra um terminal e crie um novo diretório para o projeto do agente Agno AI, que usará o Bright Data para raspagem da Web:
mkdir agno-web-scraperA pasta agno-web-scraper conterá todo o código Python para seu agente Agno de coleta de dados.
Em seguida, navegue até o diretório do projeto e configure um ambiente virtual dentro dele:
cd agno-web-scraper
python -m venv venvAgora, carregue o projeto em seu IDE Python favorito. Recomendamos o Visual Studio Code com a extensão Python ou o PyCharm Community Edition.
Dentro da pasta do projeto, crie um novo arquivo chamado scraper.py. Sua estrutura de diretórios deve ser semelhante a esta:
agno-web-scraper/
├── venv/
└── scraper.pyAtive o ambiente virtual em seu terminal. No Linux ou macOS, execute:
source venv/bin/activateDe forma equivalente, no Windows, execute este comando:
venv/Scripts/activateNas próximas etapas, você será orientado na instalação dos pacotes Python necessários. Se você preferir instalar tudo agora, no ambiente virtual ativado, execute:
pip install agno python-dotenv google-genai requestsObservação: estamos instalando o google-genai porque este tutorial usa o Gemini como provedor de LLM. Se você planeja usar um LLM diferente, certifique-se de instalar a biblioteca apropriada para esse provedor.
Está tudo pronto! Agora você tem um ambiente de desenvolvimento Python pronto para criar um fluxo de trabalho agêntico de raspagem usando o Agno e o Bright Data.
Etapa 2: Configurar a leitura das variáveis de ambiente
Seu agente de raspagem Agno se conectará a serviços de terceiros, como Bright Data e Gemini, por meio de integrações de API. Para manter as coisas seguras, evite codificar suas chaves de API diretamente no código Python. Em vez disso, armazene-as como variáveis de ambiente.
Para facilitar o carregamento de variáveis de ambiente, adote a biblioteca python-dotenv. Com seu ambiente virtual ativado, instale-o executando:
pip install python-dotenvEm seguida, em seu arquivo scraper.py, importe a biblioteca e chame load_dotenv() para carregar suas variáveis de ambiente:
from dotenv import load_dotenv
load_dotenv()Essa função permite que seu script leia variáveis de um arquivo .env local. Vá em frente e crie um arquivo .env na raiz do diretório do seu projeto:
agno-web-scraper/
├── venv/
├── .env # <-----------
└── scraper.pyMaravilhoso! Agora você está preparado para lidar com segurança com seus segredos de integração usando variáveis de ambiente.
Etapa 3: Configurar dados brilhantes
As ferramentas do Bright Data integradas ao Agno lhe dão acesso a várias soluções de coleta de dados. Neste tutorial, vamos nos concentrar na integração desses dois produtos específicos de raspagem:
- API do Web Unlocker: Uma API de raspagem avançada que supera as proteções de bots, fornecendo acesso a qualquer página da Web no formato Markdown.
- APIs do Web Scraper: Pontos de extremidade especializados para extrair eticamente dados novos e estruturados de sites populares, como LinkedIn, Amazon e muitos outros.
Para usar essas ferramentas, você precisa:
- Configure a solução Web Unlocker em sua conta da Bright Data.
- Obtenha seu token da API da Bright Data para autenticar solicitações às APIs do Web Unlocker e do Web Scraper.
Siga as instruções abaixo para fazer isso!
Primeiro, se você ainda não tiver uma conta da Bright Data, inscreva-se gratuitamente. Se já tiver, faça login e abra seu painel de controle. Aqui, clique no botão “Get proxy products” (Obter produtos proxy):
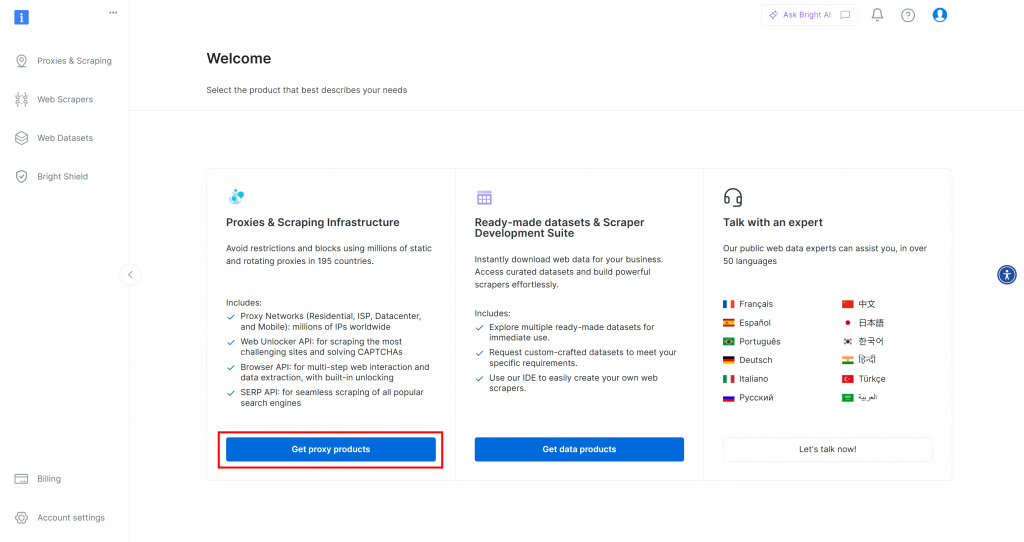
Você será redirecionado para a página “Proxies & Scraping Infrastructure”:
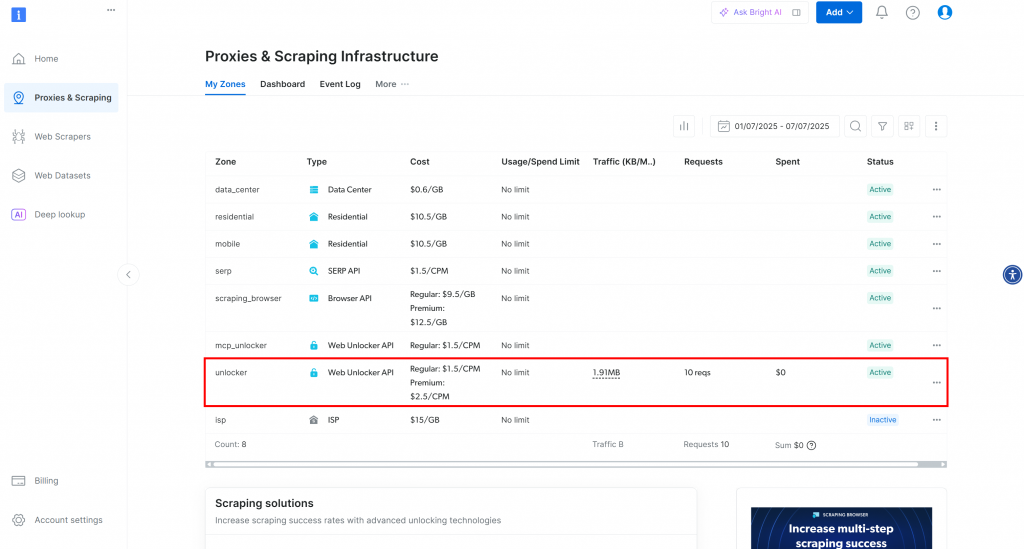
Nessa página, você verá as soluções da Bright Data já configuradas. Neste exemplo, uma zona do Web Unloker está ativada. O nome dessa zona é “unblocker” (você precisará dele mais tarde ao integrá-lo ao seu script).
Se você ainda não tiver uma zona do Web Unlocker, role para baixo até o cartão “API do Web Unlocker” e clique em “Criar zona”:
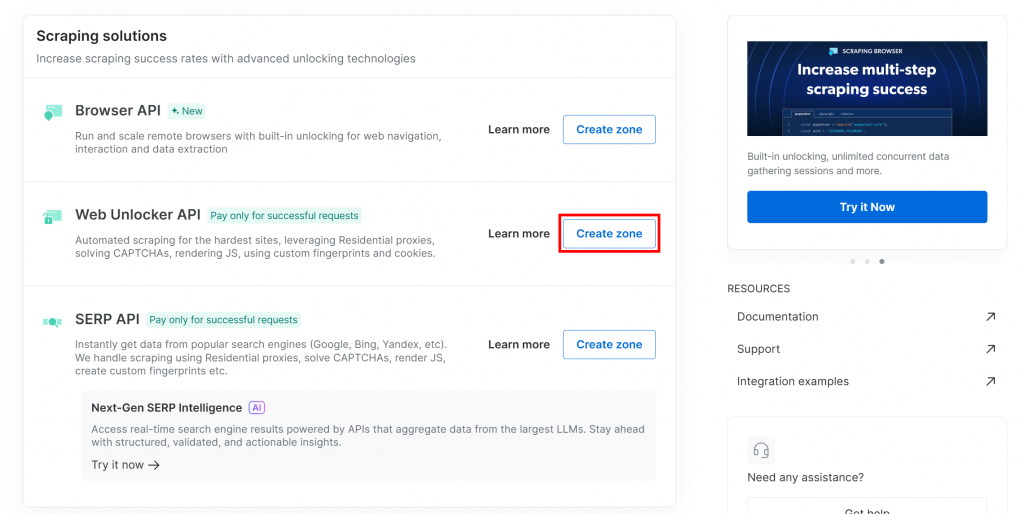
Dê um nome à sua zona (como “unlocker”), ative os recursos avançados para obter o melhor desempenho e pressione o botão “Add” (Adicionar):
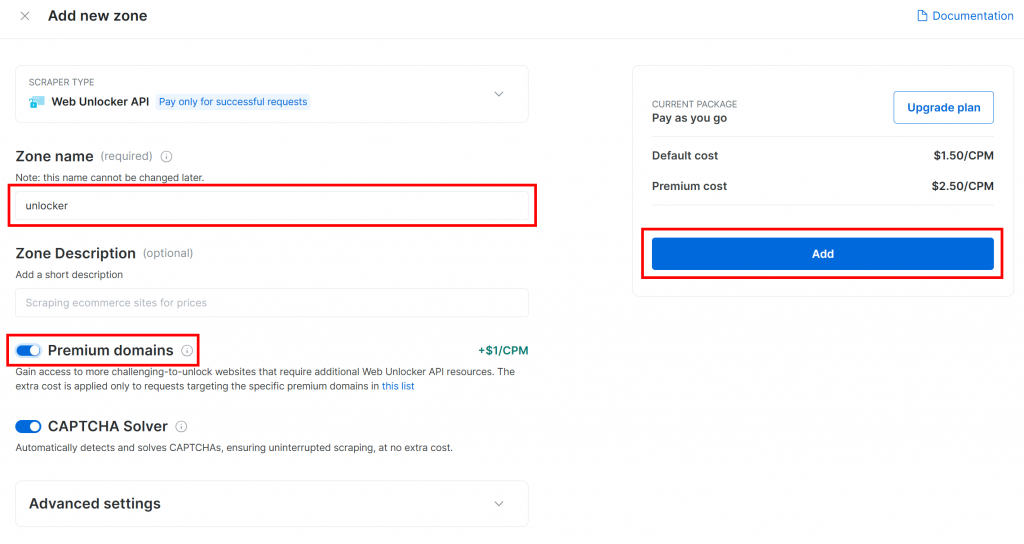
Você será levado à página da sua nova zona. Certifique-se de que o botão de alternância esteja definido para o status “Active” (Ativo), o que confirma que o produto está pronto para ser usado:
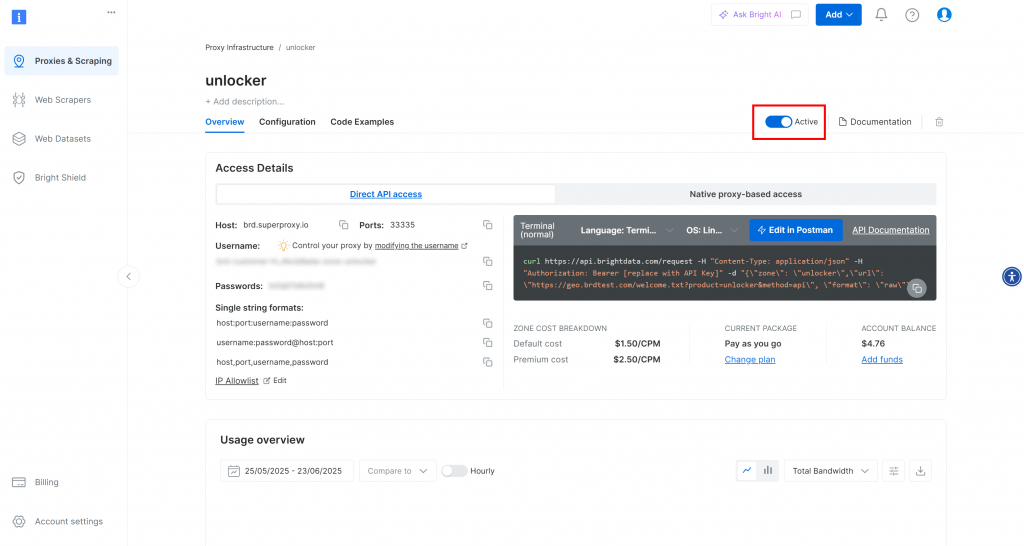
Agora, siga a documentação oficial da Bright Data para gerar sua chave de API. Depois de obtê-la, adicione-a ao seu arquivo .env desta forma:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Substitua o pelo valor real da chave da API.
Perfeito! Chegou a hora de integrar as ferramentas da Bright Data ao seu script do agente Agno para raspagem autêntica da Web.
Etapa 4: Integrar as ferramentas de dados Agno Bright para raspagem da Web
Na pasta de seu projeto, com o ambiente virtual ativado, instale o Agno executando:
pip install agnoLembre-se de que o pacote agno já inclui suporte integrado para as ferramentas do Bright Data. Portanto, você não precisa de nenhum pacote extra específico de integração.
O único pacote adicional necessário é a biblioteca Python Requests, que as ferramentas da Bright Data usam para chamar os produtos que você configurou anteriormente por meio da API. Instale as solicitações com:
pip install requestsEm seu arquivo scraper.py, importe as ferramentas de coleta de dados Bright Data da agno:
from agno.tools.brightdata import BrightDataToolsEm seguida, inicialize as ferramentas da seguinte forma:
bright_data_tools = BrightDataTools(
web_unlocker_zone="unlocker", # Replace with your Web Unlocker API zone name
search_engine=False,
)Substitua "unlocker" pelo nome real de sua zona do Bright Data Web Unlocker.
Observe também que search_engine está definido como False, uma vez que não estamos usando a ferramenta SERP API neste exemplo, que se concentra puramente na raspagem da Web.
Dica: em vez de codificar os nomes das zonas, você pode carregá-los do arquivo .env. Para fazer isso, adicione esta linha ao seu arquivo .env:
BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>"Substitua o espaço reservado pelo nome real da zona do Web Unlocker. Em seguida, você pode remover o argumento web_unlocker_zone da BrightDataTools. A classe pegará automaticamente o nome da zona de seu ambiente.
Observação: Para se conectar à Bright Data, a BrightDataTools procura sua chave de API na variável de ambiente BRIGHT_DATA_API_KEY. É por isso que a adicionamos ao seu arquivo .env na etapa anterior.
Incrível! Integre o Gemini para potencializar seu fluxo de trabalho agêntico de raspagem da Web Agno.
Etapa 5: Configurar o modelo LLM do Gemini
É hora de se conectar ao Gemini, o provedor de LLM escolhido neste tutorial. Comece instalando o pacote google-genai:
pip install google-genaiEm seguida, importe a classe de integração Gemini da Agno:
from agno.models.google import GeminiAgora, inicialize seu modelo LLM da seguinte forma:
llm_model = Gemini(id="gemini-2.5-flash")No trecho acima, gemini-2.5-flash é o nome do modelo Gemini que você deseja que o agente utilize. Sinta-se à vontade para substituí-lo por qualquer outro modelo Gemini compatível (lembre-se apenas de que alguns deles não são gratuitos para uso via API).
Nos bastidores, a biblioteca google-genai espera que a chave da API do Gemini seja armazenada em uma variável de ambiente chamada GOOGLE_API_KEY. Para configurá-la, adicione a seguinte linha ao seu arquivo .env:
GOOGLE_API_KEY="<YOUR_GOOGLE_API_KEY>"Substitua o pelo espaço reservado com sua chave de API real. Se você ainda não tiver uma, siga o guia oficial para gerar uma chave de API Gemini.
Observação: se quiser se conectar a um provedor de LLM diferente, consulte a documentação oficial para obter instruções de configuração.
Fantástico! Agora você tem todos os componentes principais necessários para criar seu agente de raspagem Agno.
Etapa nº 6: Definir o agente de raspagem
Em seu arquivo scraper.py, configure seu agente de raspagem Agno da seguinte forma:
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)Isso cria um objeto Agno Agent que usa o LLM configurado para processar prompts e aproveita as ferramentas do Bright Data para raspagem da Web.
Não se esqueça de adicionar essa importação na parte superior de seu arquivo:
from agno.agent import AgentExcelente! Tudo o que resta é enviar uma consulta ao seu agente e exportar os dados extraídos.
Etapa nº 7: Consultar o agente de raspagem Agno
Leia o prompt da CLI e passe-o para o agente de coleta de dados Agno para execução:
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)A primeira linha usa a função input() integrada do Python para ler um prompt digitado pelo usuário. O prompt deve descrever a tarefa de raspagem ou a pergunta que você deseja que o agente manipule. A segunda linha [chama run()] no agente para processar o prompt e executar a tarefa](https://docs.agno.com/agents/run#running-your-agent).
Para exibir a resposta bem formatada em seu terminal, use:
pprint_run_response(response)Importe essa função auxiliar do Agno da seguinte forma:
from agno.utils.pprint import pprint_run_responsepprint_run_response imprime a resposta do agente de IA. Mas você provavelmente também deseja extrair e salvar os dados raspados brutos retornados pela ferramenta Bright Data. Vamos tratar disso na próxima etapa!
Etapa nº 8: Exportar os dados extraídos
Ao executar uma tarefa de raspagem, o agente de raspagem da Web Agno chama as ferramentas configuradas do Bright Data nos bastidores. Garantir que seu script também exporte os dados brutos retornados por essas ferramentas agrega muito valor ao seu fluxo de trabalho. O motivo é que você pode reutilizar esses dados em outros cenários (por exemplo, análise de dados) ou em outros casos de uso agêntico.
Atualmente, seu agente de raspagem tem acesso a esses dois métodos de ferramenta do BrightDataTools:
scrape_as_markdown(): Extrai qualquer página da Web e retorna o conteúdo no formato Markdown.web_data_feed(): Recupera dados JSON estruturados de sites populares como LinkedIn, Amazon, Instagram e outros.
Assim, dependendo da tarefa, a saída de dados raspados pode estar no formato Markdown ou JSON. Para lidar com ambos os casos, você pode ler a saída bruta do resultado da ferramenta em response.tools[0].result. Em seguida, tente analisá-la como JSON. Se isso falhar, você tratará os dados extraídos como Markdown.
Implemente a lógica acima com estas linhas de código:
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data) Não se esqueça de importar json da biblioteca padrão do Python:
import jsonExcelente! Seu fluxo de trabalho do agente de raspagem da Web Agno está concluído.
Etapa nº 9: Juntar tudo
Esse é o código final de seu arquivo scraper.py:
from dotenv import load_dotenv
from agno.tools.brightdata import BrightDataTools
from agno.models.google import Gemini
from agno.agent import Agent
from agno.utils.pprint import pprint_run_response
import json
# Load the environment variables from the .env file
load_dotenv()
# Configure the Bright Data tools for Agno integration
bright_data_tools = BrightDataTools(
web_unlocker_zone="web_unlocker", # Replace with your Web Unlocker API zone name
search_engine=False, # As the SERP API tool is not required in this use case
)
# The LLM that will be used by the AI scraping agent
llm_model = Gemini(id="gemini-2.5-flash")
# Define your Agno agent with Bright Data tools
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)
# Print the agent response in the terminal
pprint_run_response(response)
# Export the scraped data
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data)Em menos de 50 linhas de código, você criou um fluxo de trabalho de raspagem orientado por IA que pode extrair dados de qualquer página da Web. Esse é o poder de combinar a Bright Data com a Agno para o desenvolvimento de agentes!
Etapa 10: Execute seu agente de raspagem Agno
Em seu terminal, inicie o agente de raspagem da Web Agno executando:
python scraper.pyVocê será solicitado a inserir uma solicitação. Tente algo como:
Give me a short summary from "https://www.reuters.com/sports/formula1/hulkenberg-rids-himself-unwanted-record-239th-attempt-2025-07-06/"Você deverá ver um resultado semelhante a este:
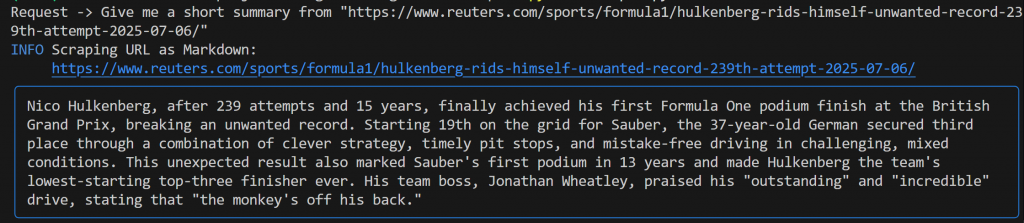
Essa saída inclui:
- O prompt original que você enviou.
- Um registro que mostra qual ferramenta do Bright Data foi usada para raspagem. Nesse caso, ele confirma que
scrape_as_markdown()foi invocado. - Um resumo em formato Markdown gerado pelo Gemini, destacado por um retângulo azul.
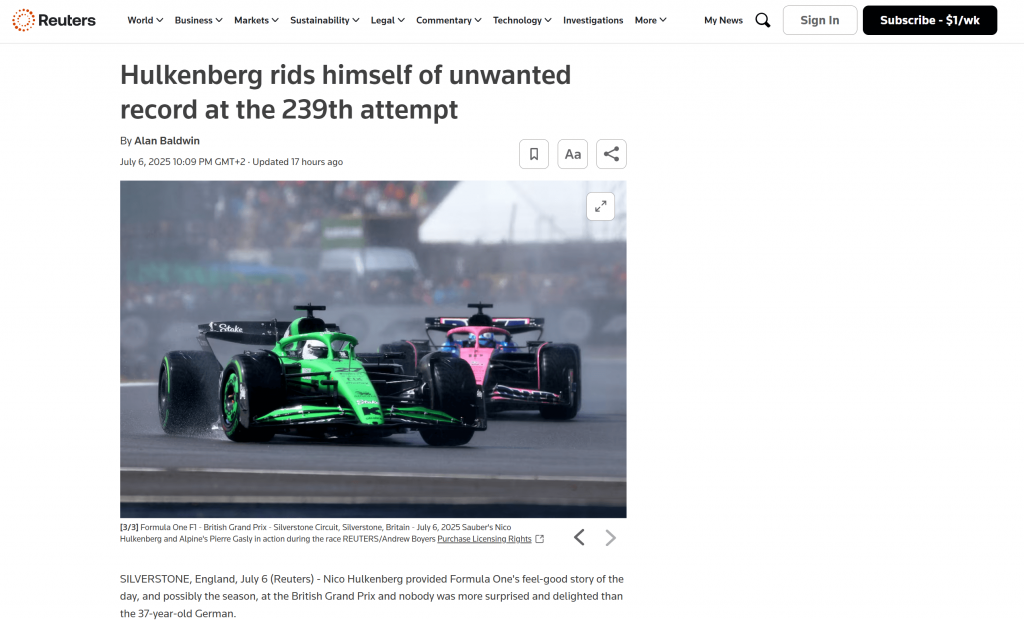
Se você olhar dentro da pasta raiz do seu projeto, verá um novo arquivo chamado output.md. Abra-o em qualquer visualizador Markdown e você obterá uma versão Markdown do conteúdo da página extraída:

Como você pode ver, a saída Markdown da Bright Data captura com precisão o conteúdo da página da Web original:
Agora, tente iniciar seu agente de raspagem novamente com uma solicitação diferente e mais específica:
Summarize the main features of the product on this Amazon page: "https://www.amazon.com/PlayStation%C2%AE5-console-slim-PlayStation-5/dp/B0CL61F39H/" Dessa vez, seu resultado pode ser parecido com o seguinte:
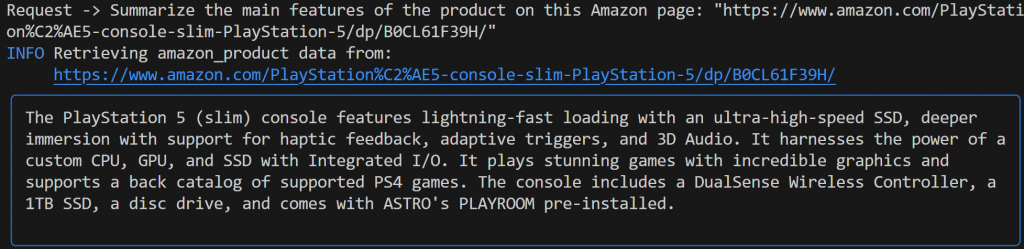
Observe como o agente Agno com tecnologia Gemini escolheu automaticamente a ferramenta web_data_feed, que está corretamente configurada para raspagem estruturada das páginas de produtos da Amazon.
Como resultado, agora você encontrará um arquivo output.json na pasta do projeto. Abra-o e cole seu conteúdo em qualquer visualizador JSON:
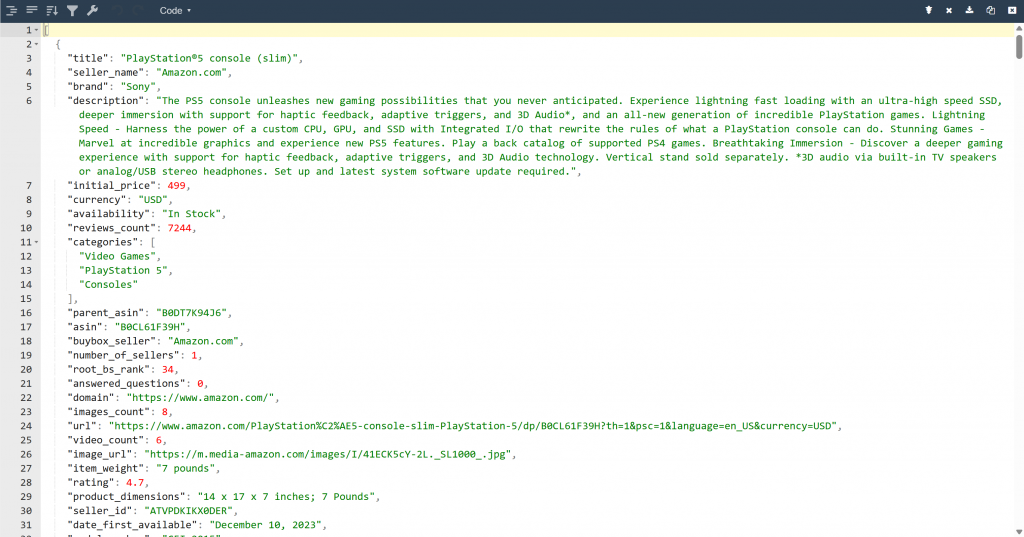
Observe como a ferramenta Bright Data extraiu com perfeição os dados JSON estruturados dessa página da Amazon:
Esses dois exemplos mostram como seu agente pode agora recuperar dados de praticamente qualquer página da Web. Isso é verdade até mesmo para sites complexos, como o da Amazon, que são famosos por suas defesas anti-scraping rígidas (como o famoso CAPTCHA da Amazon).
E pronto! Você acabou de experimentar a raspagem perfeita da Web em seu agente de IA, com a tecnologia das ferramentas Bright Data e Agno.
Próximas etapas
O agente de raspagem da Web que você acabou de criar com o Agno é apenas o começo. A partir daqui, você pode explorar várias maneiras de expandir e aprimorar seu projeto:
- Incorporar uma camada de memória: Use o banco de dados vetorial nativo da Agno para armazenar os dados que seu agente coleta por meio do Bright Data. Isso dá ao seu agente memória de longo prazo, abrindo caminho para casos de uso avançados, como o RAG autêntico.
- Crie uma interface fácil de usar: Crie uma interface de usuário simples na Web ou no desktop para que os usuários possam conversar com seu agente de forma natural e coloquial (semelhante à interação com o ChatGPT ou o Gemini). Isso torna sua ferramenta de raspagem muito mais acessível.
- Explore integrações mais avançadas: O Agno oferece uma variedade de ferramentas e recursos que podem ampliar as habilidades do seu agente muito além da raspagem. Mergulhe na documentação do Agno para obter inspiração sobre como conectar mais fontes de dados, usar LLMs diferentes ou orquestrar fluxos de trabalho de agentes em várias etapas.
Conclusão
Neste artigo, você aprendeu a usar o Agno para criar um agente de IA para raspagem da Web. Isso foi possível graças à integração integrada da Agno com as ferramentas Bright Data. Elas equipam o LLM escolhido com a capacidade de extrair dados de qualquer site.
Lembre-se de que este foi apenas um exemplo simples. Se você quiser desenvolver agentes mais avançados, precisará de soluções para buscar, validar e transformar dados da Web em tempo real. Isso é especificamente o que você pode encontrar na infraestrutura de IA da Bright Data.
Crie uma conta gratuita na Bright Data e comece a fazer experiências com nossas ferramentas de raspagem prontas para IA!




