

Neste artigo, você aprenderá:
- O que é o Amazon SageMaker e o valor que ele traz para o machine learning.
- Por que os dados da web são essenciais para uma engenharia de features bem-sucedida.
- Onde obter dados da web de alta qualidade para engenharia de features e outros cenários de machine learning.
- Como realizar engenharia de features no Amazon SageMaker usando conjuntos de dados com dados da web.
Vamos lá!
O Que É o Amazon SageMaker?
Amazon SageMaker é um serviço totalmente gerenciado criado para ajudá-lo a construir, treinar e implantar modelos de machine learning e aplicações de IA em escala. Ele oferece um ambiente unificado e completo para análise e IA.
Ele permite acessar dados de múltiplas fontes, sejam eles armazenados em data lakes do Amazon S3, data warehouses do Redshift ou sistemas de terceiros e federados. Tudo isso com segurança e governança de nível empresarial.
Em resumo, o SageMaker simplifica os fluxos de trabalho de ML e acelera o desenvolvimento de modelos, desde a engenharia de features até a implantação. Estes são os principais recursos e capacidades que ele oferece:
- SageMaker Unified Studio: Um ambiente de desenvolvimento único para construir, treinar e implantar modelos de ML e IA generativa usando infraestrutura totalmente gerenciada e ferramentas integradas.
- Desenvolvimento de modelos e MLOps: Inclui templates prontos, HyperPod e JumpStart para prototipagem rápida, treinamento e operacionalização de modelos.
- Suporte a IA generativa: Crie e escale aplicações com o Amazon Bedrock e aproveite assistentes de IA integrados como o Amazon Q Developer.
- Processamento de dados e análise SQL: Prepare, analise e integre dados usando frameworks open-source no Amazon Athena, EMR, Glue e Redshift.
- Arquitetura lakehouse: Unifica o acesso a dados isolados em diferentes sistemas de armazenamento para suportar análise e IA abrangentes.
Uma Introdução à Engenharia de Features com Dados da Web
Engenharia de features é o processo de transformar dados brutos em variáveis significativas, chamadas “features”, que os modelos de machine learning podem utilizar de forma mais eficaz. Em vez de alimentar um modelo com dados não processados, a ideia é criar métricas derivadas que capturem melhor os padrões no conjunto de dados de origem.
Exemplos incluem agregar valores, normalizar pontuações, combinar variáveis relacionadas ou criar razões que destacam relações entre diferentes campos. Uma boa engenharia de features pode ter um impacto maior no desempenho do modelo do que a escolha do algoritmo em si. Isso porque features bem projetadas ajudam os modelos a identificar sinais que, de outra forma, permaneceriam ocultos.
Os dados da web são particularmente valiosos para a engenharia de features porque refletem a atividade do mundo real em escala. Sites públicos contêm grandes quantidades de informações sobre empresas, produtos, empregos, avaliações, preços e comportamento dos usuários. Esses sinais podem ser transformados em features como indicadores de popularidade, métricas de demanda de mercado, pontuações de sentimento ou tendências de contratação, melhorando significativamente o desempenho dos seus pipelines de machine learning.
No entanto, trabalhar com dados da web também apresenta vários desafios. Os dados podem ser ruidosos, incompletos ou inconsistentes, o que pode afetar bastante a qualidade dos dados de entrada. Além disso, muitos sites adotam medidas anti-bot.
Portanto, usar scraping de dados para alimentar machine learning é complicado. Os dados coletados precisam ser limpos, validados e preparados antes de serem usados em um pipeline de ML.
Onde Obter Dados da Web de Alta Qualidade em Grandes Volumes
Como você já deve ter entendido, os dados da web desempenham um papel fundamental na engenharia de features. Ao mesmo tempo, obtê-los de forma confiável e pronta para uso empresarial é difícil. Coletar dados de algumas páginas pode parecer simples se você seguir um roteiro de scraping de dados, mas fazer isso de forma consistente em muitos domínios ou em um site grande é muito mais complexo.
Os sites frequentemente mudam sua estrutura, impõem limites de taxa e implantam proteções anti-bot que bloqueiam requisições automatizadas. Além disso, mesmo quando você consegue coletar os dados, garantir que sejam de alta qualidade, completos e atualizados pode ser desafiador.
Por esse motivo, muitas organizações dependem de empresas de conjuntos de dados da web e provedores de dados web como a Bright Data. Essas plataformas oferecem acesso a grandes quantidades de dados da web para que você não precise construir e manter uma infraestrutura de scraping.
Bright Data oferece centenas de conjuntos de dados de mais de 215 domínios web populares, com mais de 17 bilhões de registros no total. Esses conjuntos de dados contêm dados da web continuamente atualizados, estruturados, prontos para uso e otimizados para aplicações de ML e IA. Explore o marketplace de conjuntos de dados!
Se os conjuntos de dados pré-coletados não atenderem às suas necessidades, a Bright Data também oferece APIs de Scraping de Dados e outras ferramentas de coleta de dados. Essas ferramentas ajudam você a recuperar dados frescos de sites sob demanda sem precisar lidar com os desafios do scraping.
O que diferencia a Bright Data é sua infraestrutura de coleta de dados. Ela é construída sobre uma rede global de proxies com mais de 150 milhões de IPs em mais de 195 países, alcançando 99,99% de uptime e 99,95% de taxa de sucesso. Essa base facilita a criação de aplicações orientadas a dados e pipelines de ML alimentados por dados da web confiáveis.
Como Realizar Engenharia de Features em Dados da Web no Amazon SageMaker
Nesta seção passo a passo, você será guiado pelo processo de realização de engenharia de features no Amazon SageMaker.
Você começará com um conjunto de dados do Glassdoor da Bright Data, fará o upload para o Amazon S3, carregará em um notebook do SageMaker e aplicará a engenharia de features para criar métricas significativas. Depois que as features estiverem preparadas, você as usará para treinar um modelo de machine learning preditivo para alta satisfação dos funcionários.
Lembre-se de que este é apenas um exemplo, e muitos outros casos de uso são possíveis.
Siga as instruções!
Pré-requisitos
Para seguir este guia, certifique-se de ter:
- Uma conta AWS (mesmo em avaliação gratuita).
- Uma conta Bright Data.
- Um bucket S3 definido em sua conta AWS.
- Conhecimento básico de Python, especialmente em desenvolvimento de machine learning e ciência de dados.
A partir de agora, assumiremos que o nome do seu bucket S3 é bright-data-sagemaker:
Passo #1: Obtenha o Conjunto de Dados de Entrada da Bright Data
O primeiro passo é obter os dados da web de entrada. Para a engenharia de features, é melhor começar com um conjunto de dados grande e de alta qualidade. Neste exemplo, aproveitaremos as extensas coleções de conjuntos de dados da Bright Data, com foco em um conjunto de dados do Glassdoor, conforme planejado anteriormente.
Alternativa: Se preferir coletar novos dados, você pode usar uma das APIs de Scraping de Dados da Bright Data para obter conjuntos de dados frescos, estruturados e prontos para ML. Essas APIs oferecem uma opção de entrega que pode enviar dados diretamente para sua conta Amazon S3, tornando a integração com o SageMaker perfeita.
Agora, se você ainda não tem uma conta Bright Data, comece criando uma. Caso contrário, basta fazer login.
No painel de controle da Bright Data, selecione a opção de menu “Web Datasets”. Navegue até a aba “Dataset marketplace” para explorar os conjuntos de dados disponíveis:
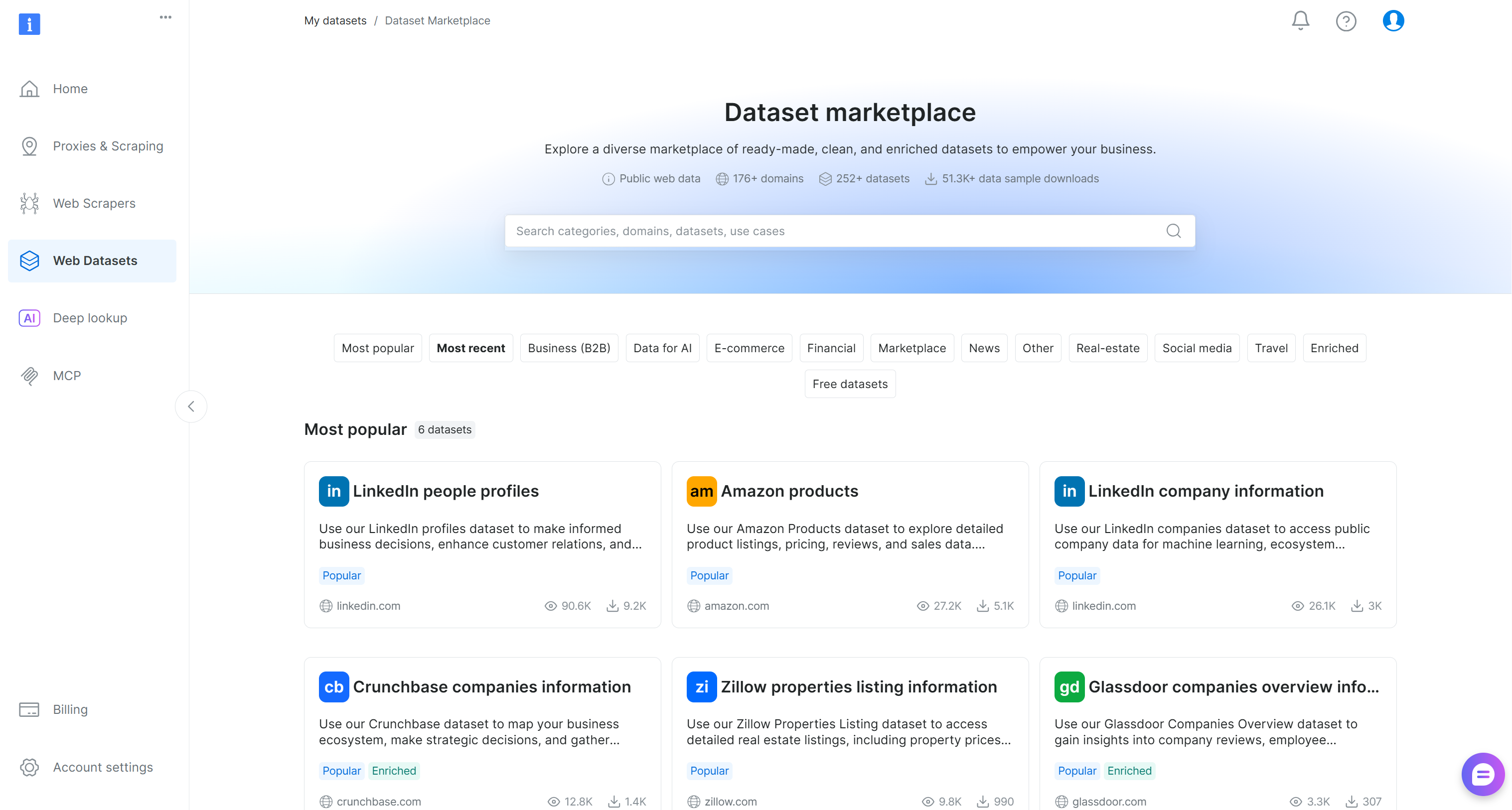
Aqui, você pode explorar mais de 200 conjuntos de dados coletados via scraping de mais de 155 domínios, contendo bilhões de registros.
Agora, procure o conjunto de dados “Glassdoor companies overview information” e abra sua página:
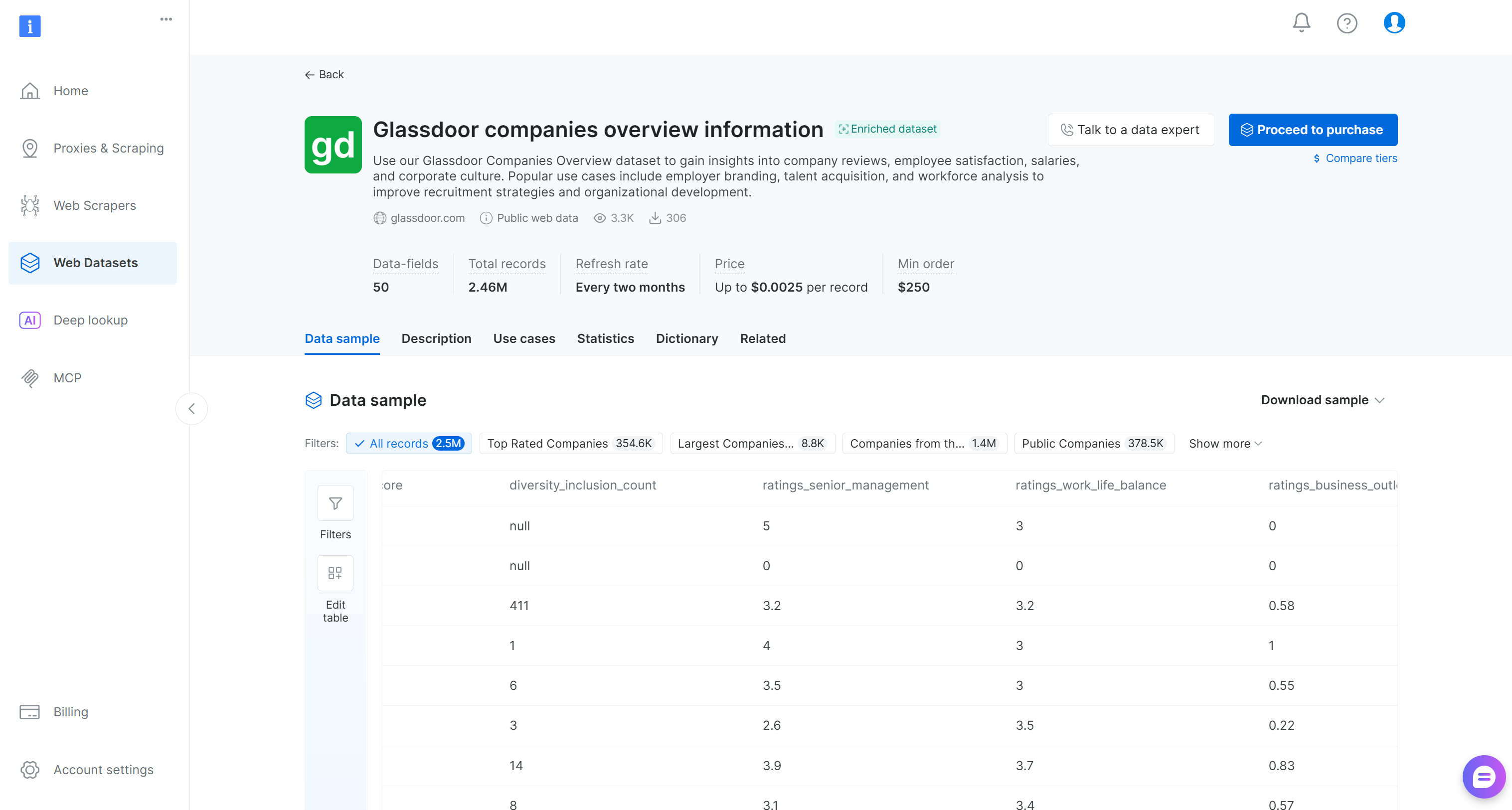
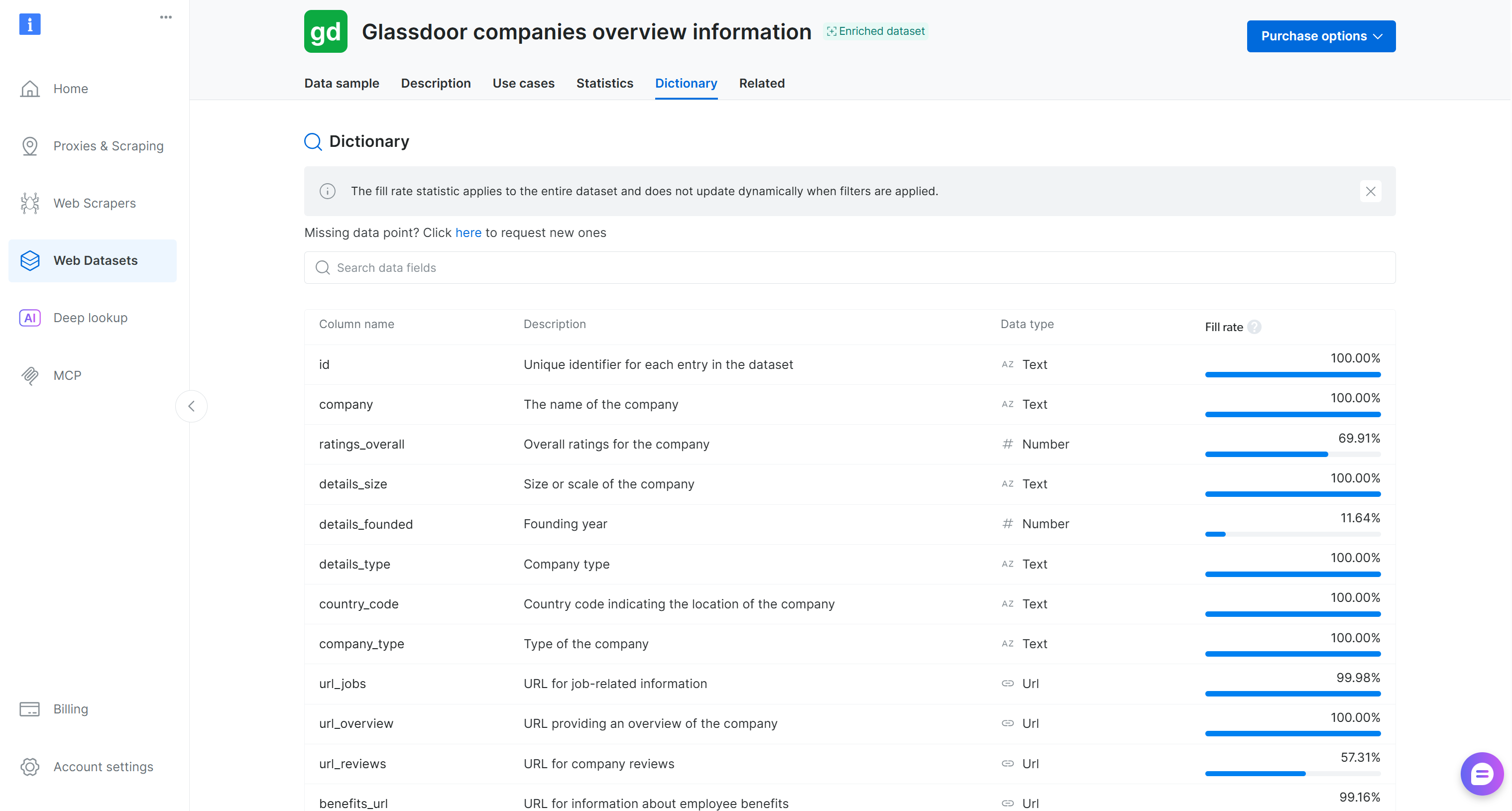
Este conjunto de dados inclui avaliações de empresas, pontuações de satisfação dos funcionários, salários e informações sobre cultura corporativa. Os casos de uso mais comuns incluem employer branding, aquisição de talentos e análise de força de trabalho. Ele contém mais de 2,46 milhões de entradas com 50 campos de dados.
Você pode optar por comprar um subconjunto filtrado ou baixar uma amostra gratuita. Em um cenário de produção, quanto maior o conjunto de dados de entrada, mais confiáveis serão os resultados da sua engenharia de features.
Para este tutorial, como é apenas um exemplo, usaremos a amostra gratuita. Para obtê-la, clique no dropdown “Download sample” e selecione a opção “Download as JSON”:
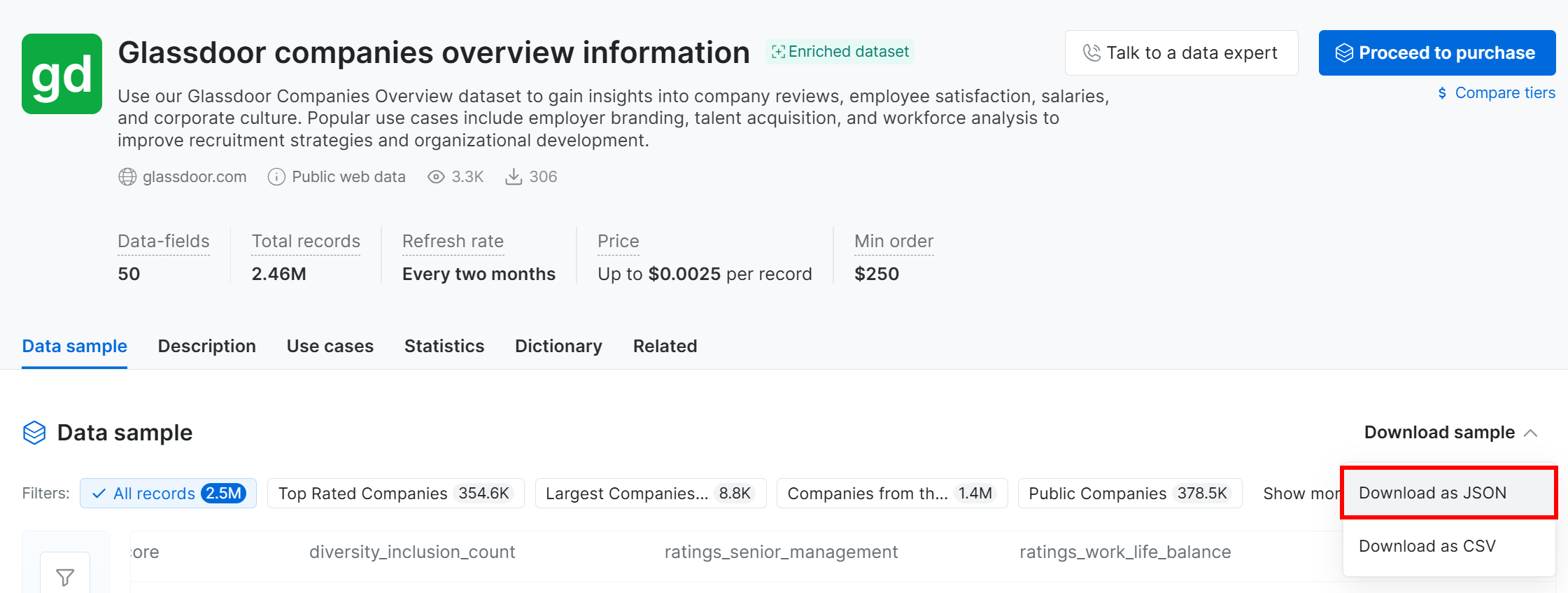
Você receberá um arquivo de amostra chamado Glassdoor companies overview information.json. Este arquivo contém 1.000 registros de empresas, cada um com 50 campos.
Renomeie o arquivo para glassdoor-companies.json e prepare-se para fazer o upload para o seu bucket S3. Ele será usado como entrada para o seu notebook de engenharia de features do SageMaker. Muito bem!
Passo #2: Faça o Upload dos Dados da Web para o Seu Bucket S3
Acesse a página do seu bucket Amazon S3 e clique no botão “Upload” para adicionar o arquivo glassdoor-companies.json. Após o upload, ele aparecerá no seu bucket assim:

Alternativamente, você pode usar um dos muitos clientes do Amazon S3 para fazer o upload do arquivo.
Lembre-se: Com as APIs de Scraping de Dados da Bright Data, você pode enviar dados coletados diretamente para o Amazon S3.
Ótimo! Agora você tem alguns dados da web de entrada para a engenharia de features no Amazon SageMaker.
Passo #3: Comece a Usar o Amazon SageMaker
Faça login no Console AWS e pesquise por “SageMaker”. Selecione o serviço para abrir sua página principal:
Clique no botão “Get started” para iniciar sua experiência com o Amazon SageMaker.
Na página de configuração, para uma configuração automática do IAM, verifique se “Auto-create a new role with admin permissions” está selecionado. Continue pressionando o botão “Set up”:
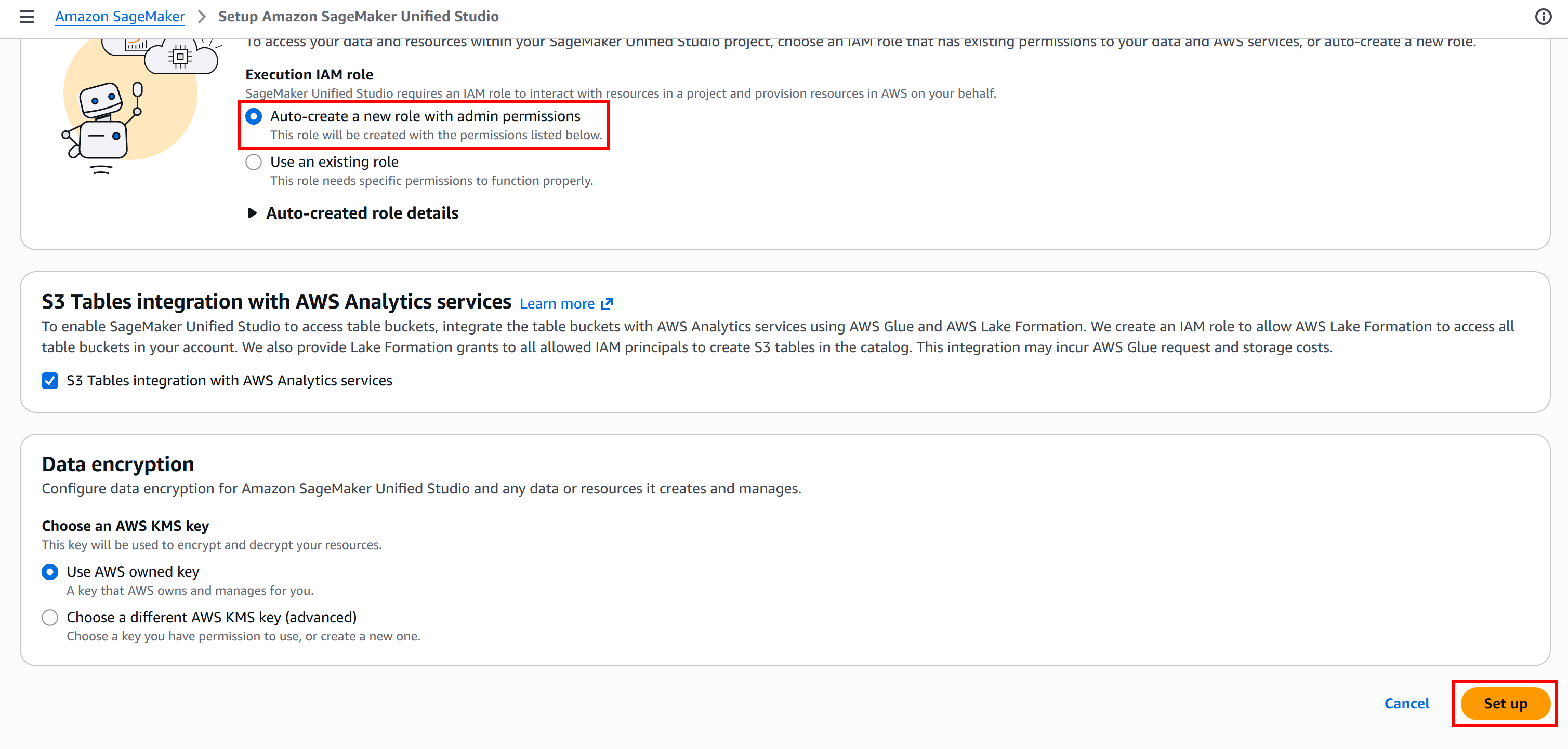
O processo de inicialização pode levar alguns minutos, então tenha paciência. Durante a execução, você verá uma mensagem “Setting up Amazon SageMaker Unified Studio…”.
Após a conclusão da configuração, você chegará à seguinte página:
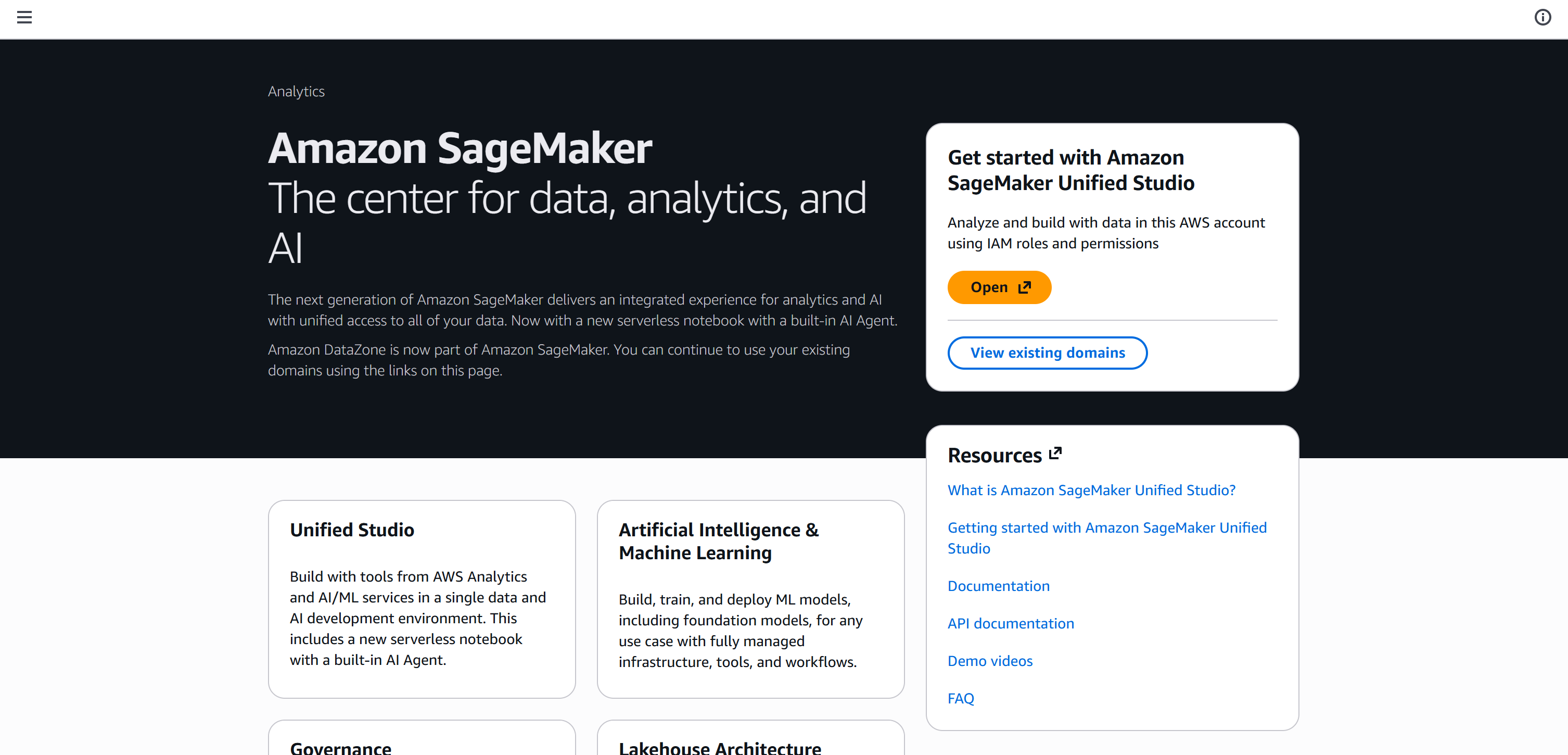
Clique em “Open” para iniciar o Amazon SageMaker Unified Studio:
A partir daqui, você pode explorar e gerenciar seu ambiente SageMaker, incluindo o desenvolvimento e execução de notebooks. Ótimo!
Passo #4: Crie um Novo Notebook
No Amazon SageMaker Unified Studio, clique no botão “Build in the notebook” para criar um novo notebook:

É assim que o seu novo notebook do SageMaker deve parecer:
Considere dar ao seu notebook um nome descritivo, como “Company Data Feature Engineering”.
Um notebook do Amazon SageMaker é uma instância de computação de machine learning gerenciada que executa o Jupyter Notebook. Ele fornece tudo o que você precisa para preparar e processar dados, escrever e testar código de treinamento, implantar modelos no SageMaker hosting e validar seus modelos.
Maravilhoso! Agora você tem todos os blocos de construção para implementar a lógica de engenharia de features no SageMaker.
Passo #5: Carregue os Dados da Web de Entrada
O primeiro passo é carregar os dados da web do Glassdoor da Bright Data no seu notebook do SageMaker.
No painel “Data Explorer” à esquerda, expanda o dropdown “Buckets”. Localize seu bucket S3 e encontre o arquivo glassdoor-companies.json. Clique no menu de hambúrguer ao lado do arquivo e selecione a opção “Read as dataframe”:
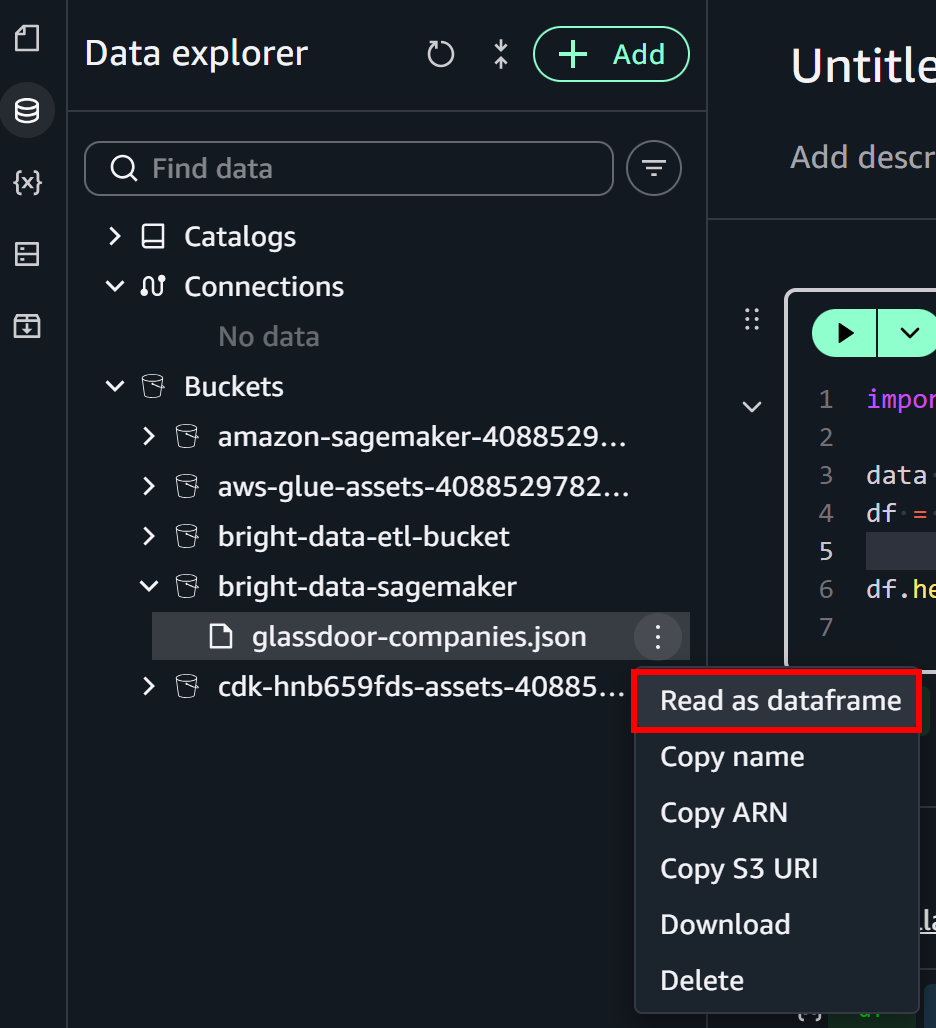
Isso preencherá a célula inicial do notebook com a lógica para carregar o arquivo do S3:
import pandas as pd
data = pd.read_json("s3://bright-data-sagemaker/glassdoor-companies.json")Nota: Substitua bright-data-sagemaker pelo nome do seu bucket S3.
Complete a lógica de importação de dados na primeira célula da seguinte forma:
import pandas as pd
# Load the input data from the S3 bucket
data = pd.read_json("s3://bright-data-sagemaker/glassdoor-companies.json")
# Normalize the structured JSON fields
df = pd.json_normalize(data.to_dict(orient="records"))
# Print the first 10 lines
df.head(10)Este trecho de código carrega e pré-processa um conjunto de dados JSON de um bucket S3 para análise em Python. Ele usa pd.read_json() para ler o arquivo e depois pd.json_normalize() para achatar campos JSON aninhados em um DataFrame tabular. Por fim, df.head(10) exibe as primeiras 10 linhas, fornecendo uma prévia rápida dos dados estruturados.
Execute a célula pressionando o botão “▶”. Você deve ver uma prévia como esta:
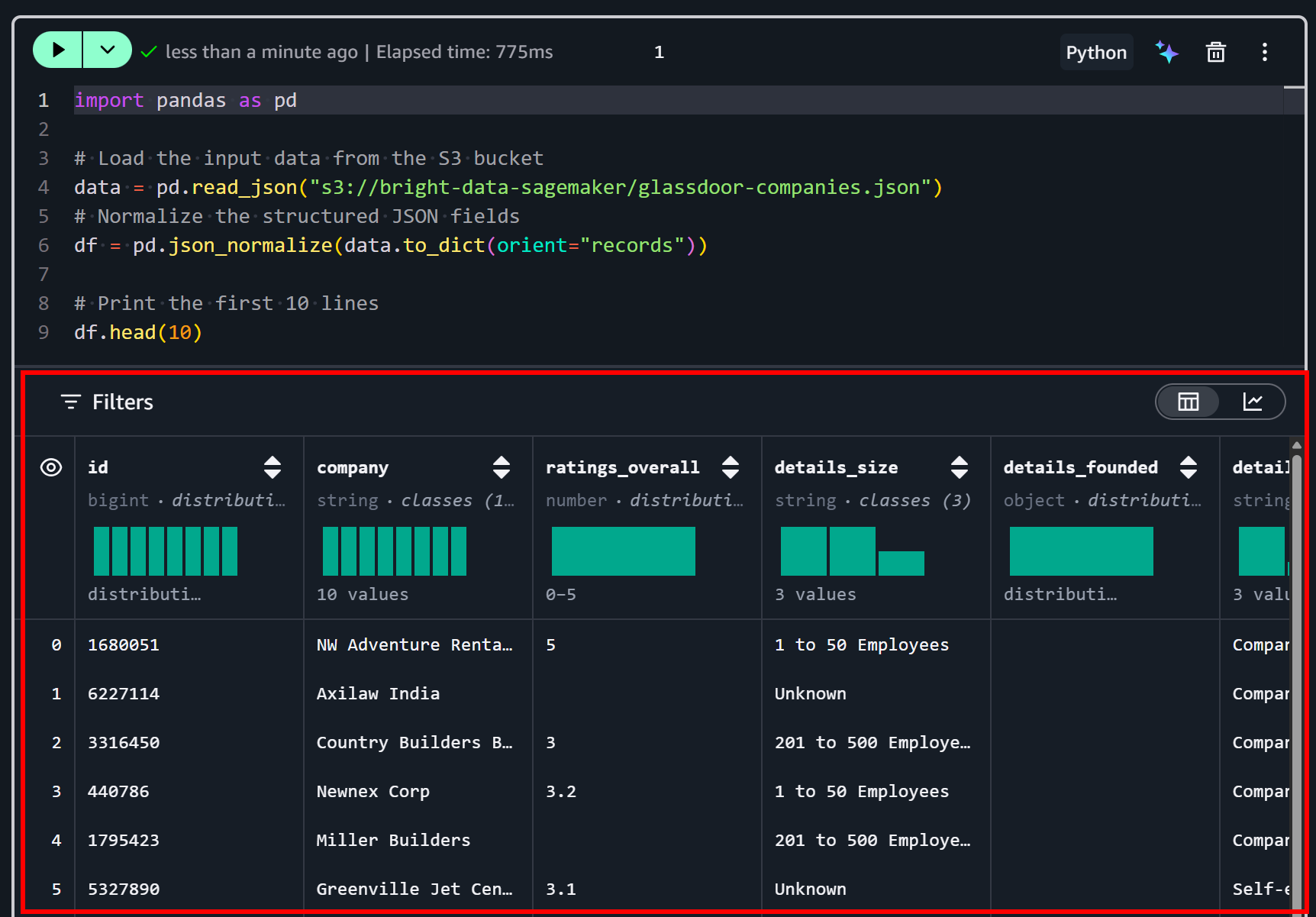
Como você pode perceber, o conjunto de dados foi carregado corretamente. Ele contém 50 campos de dados, conforme listado na aba “Dictionary” na página do conjunto de dados da Bright Data:
Você tem dados da web de entrada prontos para a engenharia de features. Fantástico!
Passo #6: Pré-Processe os Dados de Entrada
Agora que você importou seu conjunto de dados para o notebook, o próximo passo é limpar e prepará-lo para a engenharia de features.
Adicione uma nova célula no seu notebook do SageMaker e insira o seguinte código:
# Select only the columns of interest
columns = [
"company",
"ratings_overall",
"ratings_work_life_balance",
"ratings_culture_values",
"ratings_compensation_benefits",
"ratings_career_opportunities",
"ratings_senior_management",
"ratings_ceo_approval",
"reviews_count",
"jobs_count",
"salaries_count",
"benefits_count",
"details_size",
"region"
]
df = df[columns]
# Remove all rows containing missing values
df = df.dropna()Este trecho seleciona apenas as colunas de interesse, mantendo seu conjunto de dados focado em métricas e identificadores relevantes. Em seguida, utiliza df.dropna() para remover quaisquer linhas que contenham valores ausentes nas colunas selecionadas. Isso garante que seus dados estejam limpos e consistentes para a engenharia de features.
Sua nova célula ficará assim:
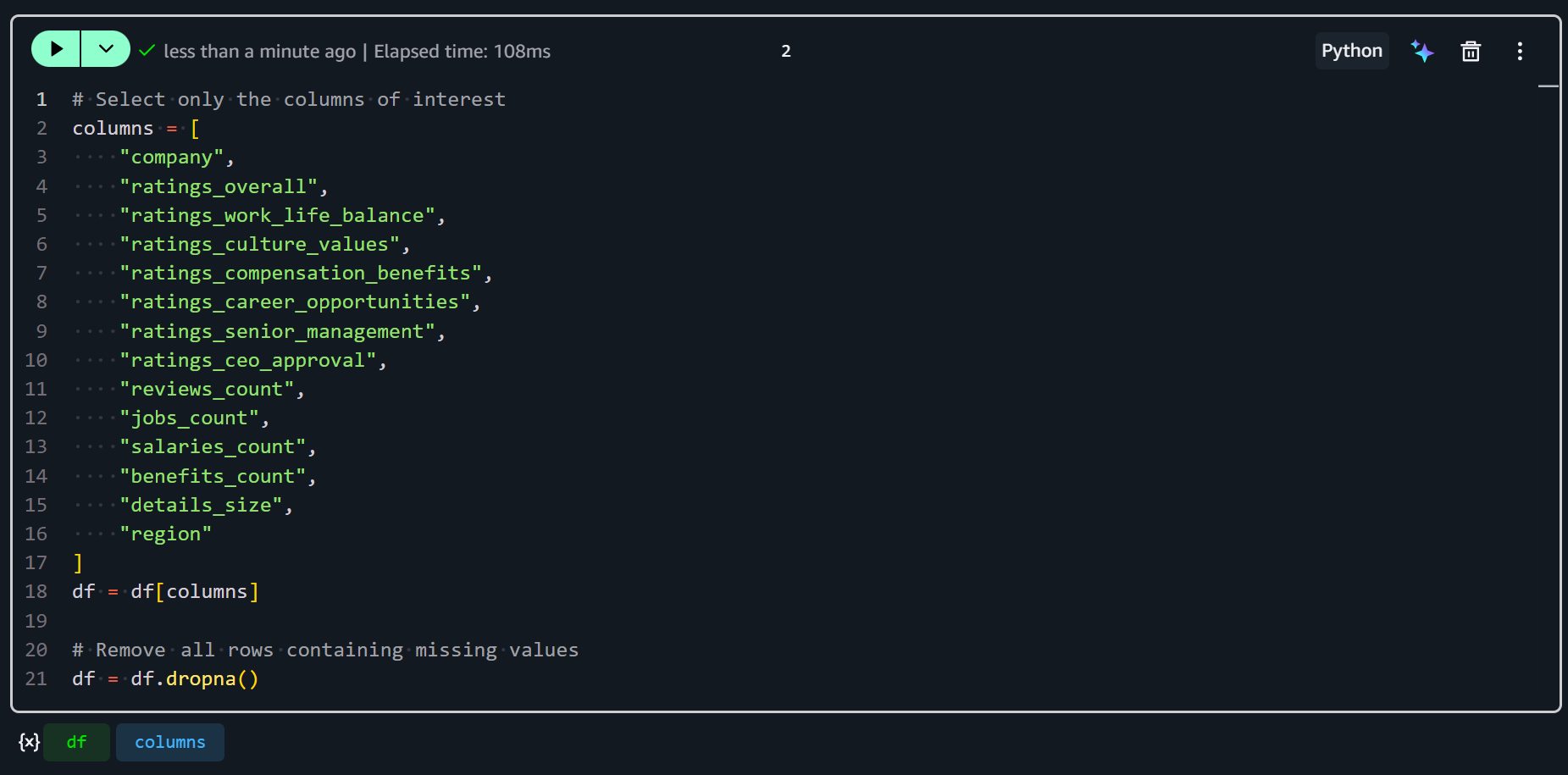
Ótimo! Seu conjunto de dados de entrada agora está pronto para a engenharia de features no SageMaker.
Passo #7: Defina as Features
É hora de definir as features que você usará para o machine learning. Lembre-se de que features são colunas derivadas que resumem ou transformam dados brutos em métricas significativas que representam melhor os padrões subjacentes.
Neste exemplo, você adicionará features que capturam cultura da empresa, remuneração, popularidade e atividade de crescimento.
Primeiro, a feature culture_score combina múltiplas avaliações relacionadas em uma única métrica que representa o ambiente cultural geral de uma empresa:
df["culture_score"] = (
df["ratings_culture_values"] +
df["ratings_work_life_balance"] +
df["ratings_senior_management"]
) / 3Ela calcula a média de três colunas de avaliação:
ratings_culture_values: Descreve o quão bem a empresa incorpora seus valores declarados.ratings_work_life_balance: Avalia a percepção dos funcionários sobre o equilíbrio entre vida pessoal e profissional.ratings_senior_management: Acompanha a percepção sobre liderança e gestão.
Somar as três avaliações e dividir por 3 produz uma pontuação normalizada. A pontuação resultante mantém a mesma escala das avaliações originais e dá peso igual a cada aspecto da cultura.
Segundo, a feature compensation_score representa uma visão combinada da satisfação dos funcionários com salário e crescimento na carreira:
df["compensation_score"] = (
df["ratings_compensation_benefits"] +
df["ratings_career_opportunities"]
) / 2Ela envolve:
ratings_compensation_benefits: Mede a satisfação dos funcionários com salário e benefícios.ratings_career_opportunities: Acompanha a satisfação dos funcionários com as oportunidades de progressão na carreira.
Ao calcular a média, a feature será escalada de forma consistente com outras pontuações para equilibrar ambos os aspectos igualmente.
Terceiro, a feature review_popularity mede com que frequência uma empresa é avaliada no Glassdoor:
df["review_popularity"] = df["reviews_count"].apply(lambda x: x ** 0.5)Isso é obtido aplicando uma transformação de raiz quadrada ao número de avaliações. Por que a raiz quadrada? Porque as contagens de avaliações costumam ser altamente assimétricas (algumas empresas têm milhares de avaliações, muitas têm muito poucas). Extrair a raiz quadrada reduz o impacto de valores extremamente altos e estabiliza a variância, facilitando o processamento e a análise.
Quarto, a feature hiring_intensity estima o quão ativamente uma empresa está contratando em relação à sua atividade de avaliações:
df["hiring_intensity"] = df["jobs_count"] / (df["reviews_count"] + 1)É calculada dividindo o número de vagas de emprego abertas (jobs_count) pelo número de avaliações mais 1 (para evitar divisão por zero para empresas sem avaliações).
Valores mais altos indicam empresas que estão contratando ativamente em comparação com quantos funcionários estão deixando avaliações. Isso pode ser um indicador de atividade de crescimento ou expansão.
Juntando tudo, você obterá:
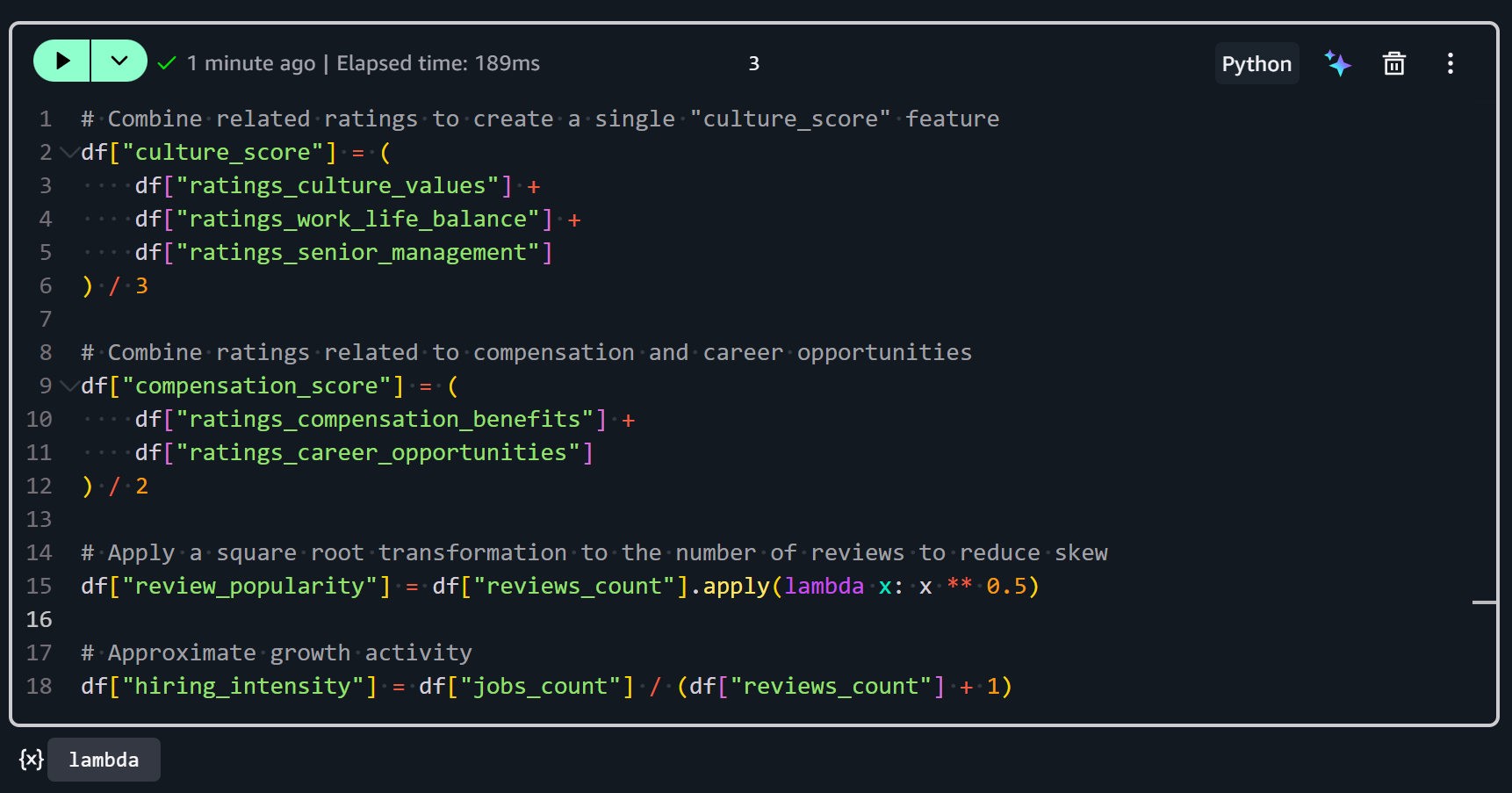
Após executar essas transformações, seu conjunto de dados agora contém features derivadas que combinam avaliações brutas e contagens em métricas mais informativas. Excelente!
Passo #8: Defina a Variável Alvo
Agora que suas features estão definidas, o próximo passo é definir a variável alvo para sua tarefa de machine learning. A variável alvo representa o resultado que você deseja que seu modelo preveja. Neste caso, você preverá se uma empresa tem alta satisfação dos funcionários.
Para definir o alvo, adicione uma nova célula no seu notebook e insira este código:
# Define the target variable
df["high_satisfaction"] = (df["ratings_overall"] >= 4).astype(int)Isso cria um campo booleano onde empresas com uma avaliação geral de 4 ou superior são marcadas como True (alta satisfação), e as demais como False (baixa satisfação).

Muitos algoritmos de machine learning requerem uma variável alvo numérica. Ao converter as avaliações de satisfação em um rótulo booleano binário 0/1, você pode treinar modelos para tarefas de classificação. Isso ajuda a prever se uma empresa provavelmente terá funcionários altamente satisfeitos com base nas features criadas. Alcance isso no próximo passo!
Passo #9: Treine o Modelo de ML para Previsão de Satisfação
Com suas features e variável alvo definidas, agora você pode treinar um modelo de machine learning para prever a alta satisfação dos funcionários.
O modelo de ML escolhido é o XGBoost, um algoritmo de gradient boosting que tem desempenho excepcional em dados tabulares e tarefas de classificação. É adequado para prever a variável high_satisfaction com base em uma mistura de features numéricas e derivadas.
Adicione uma nova célula no seu notebook e insira a lógica para treinar seu modelo com:
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
# Define the features to use for prediction
features = [
"culture_score",
"compensation_score",
"ratings_ceo_approval",
"review_popularity",
"hiring_intensity"
]
# Separate input features (X) and target variable (y)
X = df[features]
y = df["high_satisfaction"]
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Initialize the XGBoost classifier with some reasonable hyperparameters
model = XGBClassifier(
n_estimators=500,
max_depth=5,
learning_rate=0.05,
eval_metric="logloss"
)
# Train the model on the training data
model.fit(X_train, y_train)O trecho acima prepara e treina um modelo de machine learning para prever a alta satisfação dos funcionários. Ele seleciona as features de engenharia e divide os dados em conjuntos de treinamento e teste. Em seguida, inicializa um classificador XGBoost com hiperparâmetros ajustados. Por fim, ajusta o modelo aos dados de treinamento.
Execute a célula para efetivamente treinar o modelo preditivo:
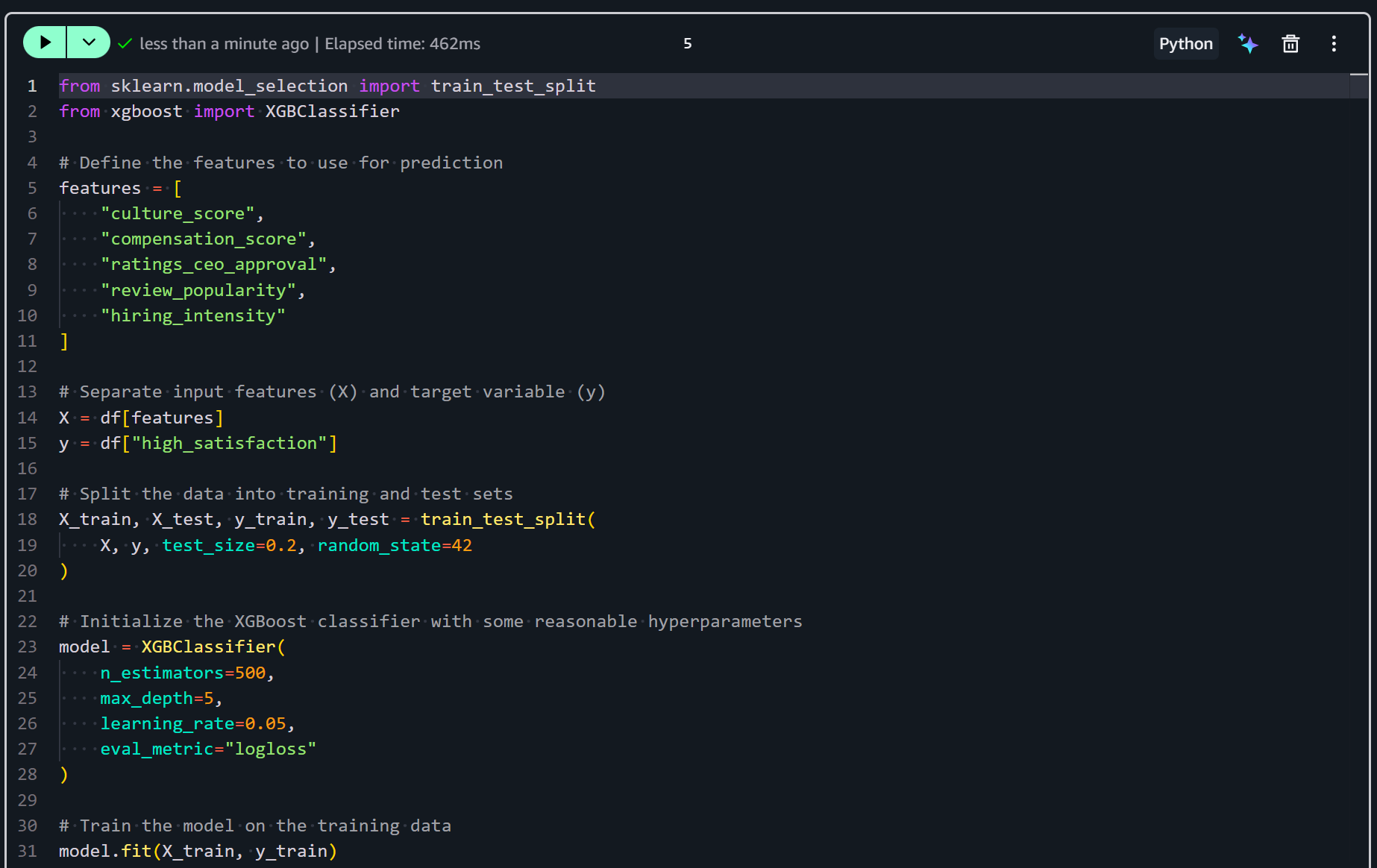
Após este passo, seu classificador XGBoost está treinado e pronto para avaliação e previsão. O próximo passo é avaliar seu desempenho!
Passo #10: Avalie o Desempenho do Modelo
O passo final é avaliar o desempenho do seu modelo em dados não vistos. Adicione uma nova célula no seu notebook com este código:
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix, roc_auc_score, accuracy_score
# Use the trained model to predict labels on the test set
pred = model.predict(X_test)
print(classification_report(y_test, pred))
# Confusion matrix
cm = confusion_matrix(y_test, pred)
print("\nConfusion Matrix:\n", cm)
# ROC-AUC score
roc = roc_auc_score(y_test, model.predict_proba(X_test)[:,1])
print("\nROC-AUC:", roc)Pressione o botão “Run All” para executar todos os passos e calcular as métricas:

Após a execução da última célula, você deve ver uma saída semelhante a esta:
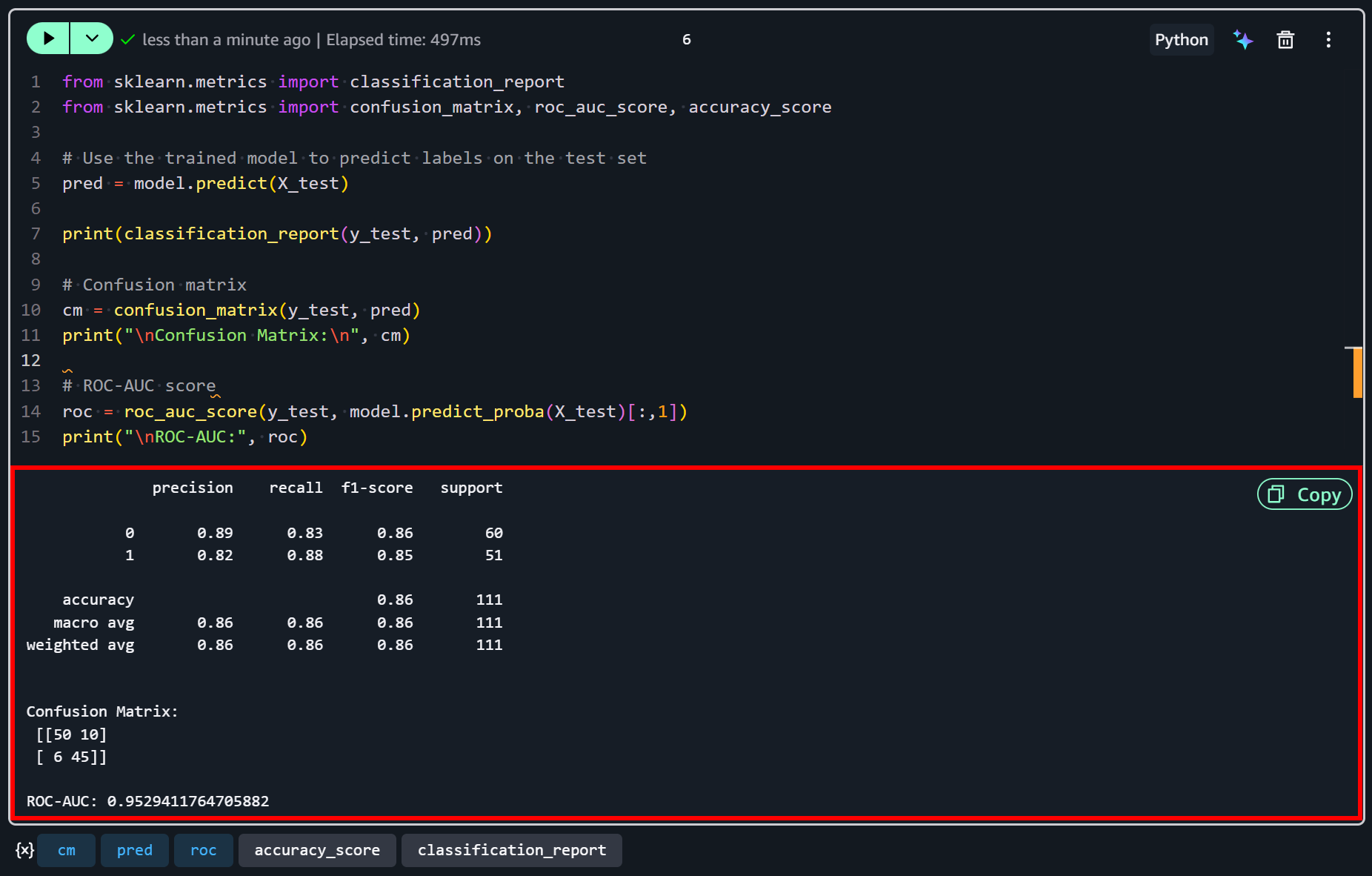
Esses resultados sugerem que o modelo tem um desempenho razoavelmente bom para este conjunto de dados de exemplo. Com uma precisão de 86% e um ROC-AUC de 0,95, ele demonstra uma forte capacidade de discriminar entre empresas com alta e baixa satisfação.
Ambas as classes mostram precisão e recall equilibrados, o que significa que o modelo é igualmente eficaz em identificar corretamente empresas com alta satisfação (1) e aquelas com menor satisfação (0).
No entanto, algumas classificações incorretas permanecem… Conforme refletido na matriz de confusão, 10 empresas de baixa satisfação foram incorretamente previstas como alta satisfação, e 6 empresas de alta satisfação foram incorretamente previstas como baixa satisfação.
Isso indica que, embora o modelo capture os principais padrões nos dados, ele não é perfeito e poderia ser melhorado com features adicionais (ou mais dados).
Et voilà! Graças ao conjunto de dados da web de entrada da Bright Data, você conseguiu realizar a engenharia de features e treinar um modelo preditivo no Amazon SageMaker. Este é apenas um dos muitos casos de uso que você pode explorar, graças à ampla variedade de conjuntos de dados da web estruturados oferecidos pela Bright Data.
Próximos Passos
O modelo atual, que prevê alta satisfação dos funcionários usando campos derivados por meio de engenharia de features, alcança resultados decentes. Ainda assim, há espaço para melhorias. Existem várias maneiras de aprimorar seu desempenho, incluindo:
- Crie mais features derivadas: Combine as avaliações existentes de novas formas. Por exemplo, você poderia calcular um
leadership_scorea partir deratings_senior_managementeratings_ceo_approval, ou umwork_life_compensation_ratiopara capturar compensações entre salário e equilíbrio entre vida pessoal e profissional. Explore razões, diferenças ou interações entre features, que podem revelar padrões ocultos. - Transforme distribuições assimétricas: Features como
reviews_countoujobs_countcostumam ser assimétricas. Já aplicamos uma transformação de raiz quadrada, mas considere transformações logarítmicas ou Box-Cox para estabilizar ainda mais a variância. - Incorpore features categóricas: Atualmente,
regionedetails_sizenão são numéricos. Codificá-los com one-hot encoding ou target encoding pode fornecer sinal preditivo adicional. - Agregue múltiplos pontos de dados: Se você puder obter tendências históricas de avaliações ou contratações, criar features como crescimento médio de
jobs_countao longo do tempo ou mudança noculture_scorepode capturar o comportamento dinâmico das empresas. - Seleção de features e análise de importância: Após o treinamento, inspecione a importância das features do XGBoost para identificar quais contribuem mais para as previsões. Você pode criar novas features inspiradas nas mais preditivas.
- Enriquecimento com dados externos: Considere mesclar outros conjuntos de dados da Bright Data para criar features mais ricas e contextuais.
Conclusão
Neste tutorial, você viu o que o Amazon SageMaker oferece para cenários de machine learning. Especificamente, você aprendeu por que conjuntos de dados coletados via scraping são excelentes fontes para engenharia de features e como eles podem ser aplicados para treinar modelos preditivos de ML.
Como demonstrado, a Bright Data oferece um rico marketplace de conjuntos de dados cobrindo centenas de domínios e bilhões de registros de dados da web. Esses conjuntos de dados são continuamente atualizados por meio de scraping de dados, tornando-os ideais para suportar fluxos de trabalho de machine learning e IA. Além disso, eles se integram perfeitamente ao Amazon SageMaker, como ilustrado neste guia.
Crie uma conta gratuita na Bright Data hoje e comece a explorar nossas soluções de dados da web!






