

-
Serviço completo
Criamos, mantemos e monitoramos o scraper para você -
Sem trabalho técnico necessário
Você simplesmente recebe os dados, sem necessidade de trabalho técnico -
Economia de tempo
Perfeito para quem tem pouco tempo — basta nos dizer o que você precisa



Wayback Machine Scraper
Extraia dados do Wayback Machine (Arquivo da Web) sem nenhum esforço. Colete dados públicos sobre o histórico de qualquer site, para qualquer finalidade.
Não é necessário cartão de crédito

- Do prompt ao scraper. Sem código necessário.
- Visualize os resultados e ajuste o código facilmente.
- Implante como um endpoint de API em minutos.
- IPs, bloqueios, renderização, tentativas - tudo gerenciado.
Confiado por 20,000+ clientes em todo o mundo
Crie seu scraper Wayback Machine em apenas alguns cliques
Escolha o domínio, descreva seus requisitos de dados e deixe nosso criador de scraper com IA gerar a API automaticamente.
- Descreva as necessidades de dados em português simples
- A IA gera instantaneamente a API do scraper
- Execute solicitações de API para resultados imediatos
- Edite o código no IDE integrado, se necessário
- Agende execuções diárias, semanais ou em intervalos personalizados
NOVO!
Mantenha scrapers funcionando com autocorreção por IA
Correções de Código por IA
Repare automaticamente o código de scraper quebrado com refatorações orientadas por IA
Atualizações rápidas de esquema
Adicione ou modifique campos de saída em segundos sem codificação manual
Menor manutenção
Reduza a manutenção contínua à medida que os scrapers se adaptam às mudanças de site e estrutura
Coleta de dados Wayback Machine simplificada

Web Scrapers
Scrapers relacionados prontos para uso
Elimine a necessidade de desenvolver e manter a infraestrutura. Simplesmente extraia grandes volumes de dados da web e garanta escalabilidade e confiabilidade usando APIs de web scraper ou scrapers sem código.
LinkedIn people profiles
ID, Name, City, Country code, Position, About, Posts, Current company, and more.
 118.2K+
118.2K+ 11.1K+
11.1K+Amazon products
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by best sellers category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by specific category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by specific keywords
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - find products by using upc numbers
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
LinkedIn company information
ID, Name, Country code, Locations, Followers, Employees in linkedin, About, Specialties, and more.
Instagram - Profiles
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Instagram - Profiles - Collect profile information by user name
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Crunchbase companies information
Name, URL, ID, Cb rank, Region, About, Industries, Operating status, and more.
Crunchbase companies information - Searching data by keyword
Name, URL, ID, Cb rank, Region, About, Industries, Operating status, and more.
Linkedin job listings information
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Linkedin job listings information - Discover new jobs by keyword
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Linkedin job listings information - Discover jobs by company URL
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Instagram - Posts
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Instagram - Posts - Collects posts from a specific URLs by using profile URL
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Google Maps full information
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - discover records by location search
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - Collect Google Maps Businesses data by place id
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - Discover new records by Customer ID
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Zillow properties listing information
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Zillow properties listing information - Discover by custom filters - location, home type and status
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Zillow properties listing information - Search by parameters on zillow and use the direct link as input
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
LinkedIn posts
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover user's articles by URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover posts by Profile URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover new posts company URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
X (formerly Twitter) - Posts
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Collecting Twitter posts URLs
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Getting x posts by array of profiles
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
TikTok - Profiles
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
TikTok - Profiles - Discover by search URL and country
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
Youtube - Videos posts
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search new youtube videos by keyword
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discover videos by channel URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search videos by keyword and then apply relevant video filters
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Collect YouTube posts by hashtags
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery records by Explore page URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery videos by podcast url
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Amazon Reviews
URL, Product name, Product rating, Product rating object, Product rating max, Rating, Author name, Asin, and more.
TikTok - Posts
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Input specific profile URL to get posts published by it
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Search posts by specific keyword or hashtag
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - discover new records by TikTok discover URL
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Facebook - Pages Posts by Profile URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Indeed job listings information
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Indeed job listings information - Collect new jobs by keyword search in specific location
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Indeed job listings information - Discover jobs by company URL
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Walmart - products
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Find new products by using specific category URL
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Collects products by specific keywords
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Discover products by using sku numbers
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
TikTok Shop
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - category
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - Collect TikTok shop products by keywords search
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - discover records by shop url
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
YouTube - Channels
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
YouTube - Channels - Collects channel by keyword related to the channel or video's of the channel
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
Reddit- Posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover Reddit posts by Subreddit URL
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discovery by keyword of Reddit posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover posts by author
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Glassdoor companies overview information
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - Search for companies by keyword
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - discover new companies by input filters
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - discover by search url
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Google maps reviews
URL, Place id, Place name, Country, Address, Review id, Reviewer name, Reviews by reviewer, and more.
Instagram - Reels
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Discover reels video from Instagram profile or direct search url
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Collect all Reels from Instagram profiles (without the post timestamp)
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Airbnb Properties Information
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
Airbnb Properties Information - Search Airbnb by location
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
Airbnb Properties Information - Discover by search url
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
X (formerly Twitter) - Profiles
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
X (formerly Twitter) - Profiles - Collect profile information by user name
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
Glassdoor companies reviews
Overview id, Review id, Review url, Rating date, Count helpful, Count unhelpful, Employee job end year, Employee length, and more.
Booking Hotel Listings
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Booking Hotel Listings -
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Yahoo Finance business information
Name, Company id, Entity type, Summary, Stock ticker, Currency, Earnings date, Exchange, and more.
Yahoo Finance business information - Discover records by keyword
Name, Company id, Entity type, Summary, Stock ticker, Currency, Earnings date, Exchange, and more.
Instagram - Comments
URL, Comment user, Comment user url, Comment date, Comment, Likes number, Replies number, Replies, and more.
Principais recursos do scraper Wayback Machine
Geração de código
Transforme prompts simples em código de scraper completo, pronto para execução.
Automação de fluxo de trabalho
Automatize todas as etapas: do planejamento e geração de esquema à criação e teste de código.
Infraestrutura baseada em nuvem
Reduza custos de hardware e manutenção - execute todo o processamento na nuvem gerenciada da Bright Data e escale instantaneamente.
Proxies integrados e desbloqueio
Execute seus scrapers como um usuário real em qualquer geolocalização com fingerprinting integrado, tentativas automáticas, Resolução de CAPTCHA e muito mais.
Workspace IDE
IDE totalmente hospedado onde você pode editar e depurar seus scrapers, com logs em tempo real.
Entrega de scraping agendada
Acione scrapers por agendamento ou via API e entregue os dados em todos os destinos de armazenamento populares
Wayback Machine Scraper Pricing
Collect data from Wayback Machine by turning prompts into ready‑to‑run scrapers with built‑in proxies and automatic unblocking.
Aceitamos esses métodos de pagamento:
Cada plano oferece acesso completo - pague menos por registro à medida que escala
Coleta de Dados
- Gerenciamento automatizado de proxies
- Renderização completa do navegador
- Resolução de CAPTCHA
Desempenho em escala
- Concorência ilimitada
- Coleta em lote e agendada
- APIs de gerenciamento de trabalho
Entrega de dados
- Validação e descoberta de dados
- Análise de dados (JSON ou CSV)
- Entrega por webhook ou API
POR BAIXO DOS PANOS
Nunca mais se preocupe com proxies e CAPTCHAs
- Rotação Automática de IP
- Solver de CAPTCHA
- Rotação de User Agent
- Cabeçalhos Personalizados
- Renderização de JavaScript
- Proxies Residenciais
API para Acesso Contínuo a Dados Wayback Machine
Extração de Dados Web Abrangente, Escalável e Compatível
API para Acesso Contínuo a Dados Wayback Machine
Extração de Dados Web Abrangente, Escalável e Compatível
Adaptado ao seu fluxo de trabalho
Obtenha dados estruturados em arquivos JSON, NDJSON ou CSV por entrega via Webhook ou API.
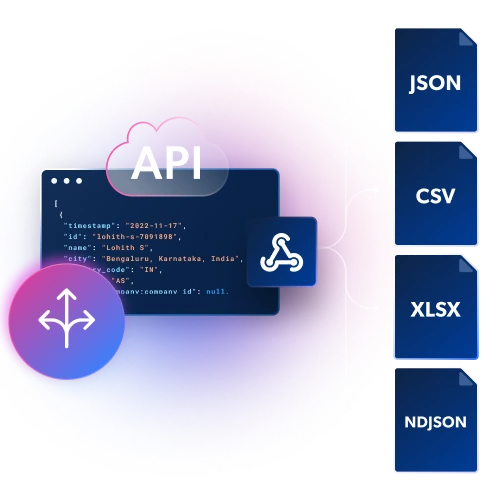
Infraestrutura integrada e desbloqueio
Obtenha controle e flexibilidade máximos sem manter infraestrutura de proxy e desbloqueio. Extraia dados facilmente de qualquer geolocalização evitando CAPTCHAs e bloqueios.

Infraestrutura comprovada
A plataforma da Bright Data impulsiona mais de 20.000 empresas em todo o mundo, oferecendo tranquilidade com 99,99% de uptime, acesso a 400M+ IPs de usuários reais cobrindo 195 países.

Conformidade líder do setor
Nossas práticas de privacidade estão em conformidade com as leis de proteção de dados, incluindo o marco regulatório de proteção de dados da UE, GDPR e CCPA.

API para Acesso Contínuo a Dados Wayback Machine
Extração de Dados Web Abrangente, Escalável e Compatível
FLEXÍVEL
Adaptado ao seu fluxo de trabalho
Obtenha dados estruturados em arquivos JSON, NDJSON ou CSV por entrega via Webhook ou API.ESCALÁVEL
Infraestrutura integrada e desbloqueio
Obtenha controle e flexibilidade máximos sem manter infraestrutura de proxy e desbloqueio. Extraia dados facilmente de qualquer geolocalização evitando CAPTCHAs e bloqueios.ESTÁVEL
Infraestrutura comprovada
A plataforma da Bright Data impulsiona mais de 20.000 empresas em todo o mundo, oferecendo tranquilidade com 99,99% de uptime, acesso a mais de 150 milhões de IPs de usuários reais cobrindo 195 países.COMPATÍVEL
Conformidade líder do setor
Nossas práticas de privacidade estão em conformidade com as leis de proteção de dados, incluindo o marco regulatório de proteção de dados da UE, GDPR e CCPA.Por que 20,000+ clientes escolhem a Bright Data
100% Conformidade
Os dados coletados são obtidos de forma ética e em conformidade com todas as leis de privacidade.
Suporte Global 24/7
Uma equipe dedicada de profissionais de dados está aqui para ajudar.
Cobertura Completa de Dados
Acesse 400 million+ IPs globais para fazer scraping de dados de qualquer site.
Qualidade de Dados Incomparável
Tecnologias avançadas e métodos de validação para dados de qualidade.
Infraestrutura Poderosa
Faça scraping de dados em grande volume sem ser bloqueado.
Soluções Personalizadas
Obtenha soluções sob medida para atender necessidades e objetivos únicos.
A Bright Data é utilizada pelas principais marcas do mundo
Ajudamos empresas a crescer com gerenciamento de dados seguro, escalável e flexível.
 Recomendo o uso dos produtos da Bright Data para qualquer empresa, especialmente no setor financeiro. A Bright Data é confiável e está em conformidade com as normas, o serviço é excelente, os produtos são impecáveis e sua rede é rápida e estável.
Recomendo o uso dos produtos da Bright Data para qualquer empresa, especialmente no setor financeiro. A Bright Data é confiável e está em conformidade com as normas, o serviço é excelente, os produtos são impecáveis e sua rede é rápida e estável. Xiaolong ShiCrawler Engineer at Bitget
Xiaolong ShiCrawler Engineer at Bitget- Sem a capacidade de coletar dados públicos na internet, não podemos saber quando uma marca estava presente em todos os meios nem o seu alcance. Não há maneira de continuarmos a crescer à velocidade em que estamos sem o apoio de Bright Data.Ver agora
 Sarah MelvilleData Science Specialist
Sarah MelvilleData Science Specialist  Sem a capacidade de coletar dados públicos na internet, não podemos saber quando uma marca estava presente em todos os meios nem o seu alcance. Não há maneira de continuarmos a crescer à velocidade em que estamos sem o apoio de Bright Data. Sarah MelvilleMedia Director at YouGov Sport
Sem a capacidade de coletar dados públicos na internet, não podemos saber quando uma marca estava presente em todos os meios nem o seu alcance. Não há maneira de continuarmos a crescer à velocidade em que estamos sem o apoio de Bright Data. Sarah MelvilleMedia Director at YouGov Sport Pela minha experiência, o serviço da Bright Data tem sido inestimável. A Bright Data nos ajudou a coletar dados públicos da web suficientes para atender às nossas necessidades e, com sua equipe de suporte e desenvolvimento, otimizamos muitos de nossos processos.
Pela minha experiência, o serviço da Bright Data tem sido inestimável. A Bright Data nos ajudou a coletar dados públicos da web suficientes para atender às nossas necessidades e, com sua equipe de suporte e desenvolvimento, otimizamos muitos de nossos processos. Charmagne CruzHead of Reporting & Analytics, Business Technologies and Pricing at Shopee Philippines Inc.
Charmagne CruzHead of Reporting & Analytics, Business Technologies and Pricing at Shopee Philippines Inc.- Ter a melhor qualidade e quantidade de dados é o mais importante, e é aí que a combinação da Bright Data e da tgndata faz a diferença.Ver agora
 George KoutsoudopoulosCEO at tgndata
George KoutsoudopoulosCEO at tgndata  Estamos realmente impressionados com a confiabilidade e muito satisfeitos com a Bright Data em geral. Temos um canal de comunicação regular com nosso Gerente de conta, que é muito prestativo.
Estamos realmente impressionados com a confiabilidade e muito satisfeitos com a Bright Data em geral. Temos um canal de comunicação regular com nosso Gerente de conta, que é muito prestativo. Yorgos PanzarisCTO at Convert Group
Yorgos PanzarisCTO at Convert Group Estamos muito satisfeitos com a parceria com a Bright Data. Tudo tem corrido bem, a rede tem sido muito estável, estamos felizes com o atendimento ao cliente e a equipe de suporte é incomparável em nossa opinião.
Estamos muito satisfeitos com a parceria com a Bright Data. Tudo tem corrido bem, a rede tem sido muito estável, estamos felizes com o atendimento ao cliente e a equipe de suporte é incomparável em nossa opinião. Cheddi RaiCEO at AdRetreaver
Cheddi RaiCEO at AdRetreaver


Perguntas Frequentes sobre o Scraper Wayback Machine
O que é o Scraper personalizado Wayback Machine?
O scraper Wayback Machine é uma ferramenta poderosa projetada para automatizar a extração de dados do Wayback Machine, permitindo que os usuários coletem e processem eficientemente grandes volumes de dados de mercado de previsão para diversos casos de uso.
Como crio um Wayback Machine usando um prompt de IA?
Escolha seu site, descreva os dados em português simples e a IA gera instantaneamente um scraper pronto para execução; o scraper finalizado aparece no seu workspace IDE para testes, execução e edições conforme necessário.
Como funciona o Scraper Wayback Machine?
O Scraper Wayback Machine funciona enviando solicitações automatizadas ao Wayback Machine, extraindo os pontos de dados necessários e entregando-os em formato estruturado. Esse processo garante coleta de dados precisa e rápida.
Preciso de servidores ou proxies próprios para executar o scraper Wayback Machine?
Não. Ao iniciar um job pelo IDE, o scraper é executado na infraestrutura da Bright Data - completa com rotação de proxy integrada, geotargeting, lógica de CAPTCHA/desbloqueio e auto-scaling. Você não mantém servidores ou pools de proxies; basta executar o scraper e a plataforma cuida de tudo de ponta a ponta.
O Scraper Wayback Machine está em conformidade com as regulamentações de proteção de dados?
Sim, o Scraper Wayback Machine foi projetado para estar em conformidade com as regulamentações de proteção de dados, incluindo GDPR e CCPA. Ele garante que todas as atividades de coleta de dados sejam realizadas de forma ética e legal.
É necessário programar?
Não é necessário programar para gerar o scraper Wayback Machine - o AI Scraper Studio o cria a partir do seu prompt. Você ainda precisará de conhecimento básico de conceitos de web scraping para configurar e usar o scraper, e pode opcionalmente refinar o código gerado automaticamente no IDE integrado.
Vocês oferecem suporte para o Scraper Wayback Machine?
Sim, oferecemos suporte dedicado para o Scraper Wayback Machine. Nossa equipe de suporte está disponível 24/7 para auxiliá-lo com quaisquer dúvidas ou problemas que você encontrar ao usar a API.
Quais métodos de entrega estão disponíveis?
JSON por padrão, com opções para CSV, Parquet ou carregamentos diretos para S3, GCS, Azure Blob, BigQuery e Snowflake.
Quais formatos de arquivo estão disponíveis?
JSON, NDJSON, JSON lines, CSV e arquivos .gz (comprimidos).