

Se você estiver interessado no scraping de dados, entender HTML é fundamental, pois todos os sites são construídos com essa linguagem. O scraping de dados pode ser usado em todos os tipos de cenários e pode ajudar a coletar dados de sites sem APIs, realizar monitoramento de preços de produtos, criar listas de leads, conduzir pesquisas acadêmicas e muito mais.
Neste artigo, você aprenderá os fundamentos do HTML e como extrair, analisar e processar dados usando Python.
Interessado em um guia detalhado sobre Scraping de dados em Python? Clique aqui.
Como fazer scraping de sites e extrair HTML
Antes de começar este tutorial, vamos dedicar um momento para revisar os componentes essenciais do HTML.
Introdução ao HTML
HTML é uma coleção de tags que informam ao navegador sobre a estrutura e os elementos de um site. Por exemplo,<h1> Texto </h1>informa ao navegador que o trecho de texto após a tag é um título, e<a href=""> link </a>identifica um hiperlink.
Um atributo HTML fornece informações adicionais sobre uma tag. Por exemplo, o atributohrefpara a tag<a> </a>fornece informações sobre a URL da página para a qual o atributo está apontando.
Classes e IDssão atributos essenciais para identificar com precisão os elementos de uma página. As classes agrupam elementos semelhantes para estilizá-los de forma consistente usando CSS ou manipulá-los uniformemente com JavaScript. As classes são direcionadas usando.class-name.
No site W3Schools, os grupos de classes têm a seguinte aparência:
<div class="city">
<h2>Londres</h2>
<p>Londres é a capital da Inglaterra.</p>
</div>
<div class="city">
<h2>Paris</h2>
<p>Paris é a capital da França.</p>
</div>
<div class="city">
<h2>Tóquio</h2>
<p>Tóquio é a capital do Japão.</p>
</div>
Você pode ver como cada título e bloco de cidade é envolvido por um div que tem a mesma classe de cidade.
Em contrapartida, os IDs são exclusivos para cada elemento (ou seja, dois elementos não podem ter o mesmo ID). Por exemplo, os seguintes H1s têm IDs exclusivos e podem ser estilizados/manipulados de forma exclusiva:
<h1 id="header1">Olá, mundo!</h1>
<h1 id="header2">Lorem Ipsum Dolor</h1>
A sintaxe para direcionar elementos com IDs é #id-name.
Agora que você conhece os fundamentos do HTML, vamos começar o Scraping de dados.
Configure seu ambiente de scraping
Este tutorial usa Python, pois oferece muitas bibliotecas de scraping de HTML e a linguagem é fácil de aprender. Para verificar se o Python está instalado no seu computador, execute o seguinte comando no PowerShell (Windows) ou no seu terminal (macOS):
python3
Se o Python estiver instalado, você verá o número da versão; caso contrário, receberá uma mensagem de erro. Vá em frente einstale o Python, se ainda não o tiver.
Em seguida, crie uma pasta chamadaWebScrapere crie um arquivo dentro da pastaWebScraperchamadoscraper.py. Em seguida, abra-o no ambiente de desenvolvimento integrado (IDE) de sua escolha.O Visual Studio Codeé usado aqui:
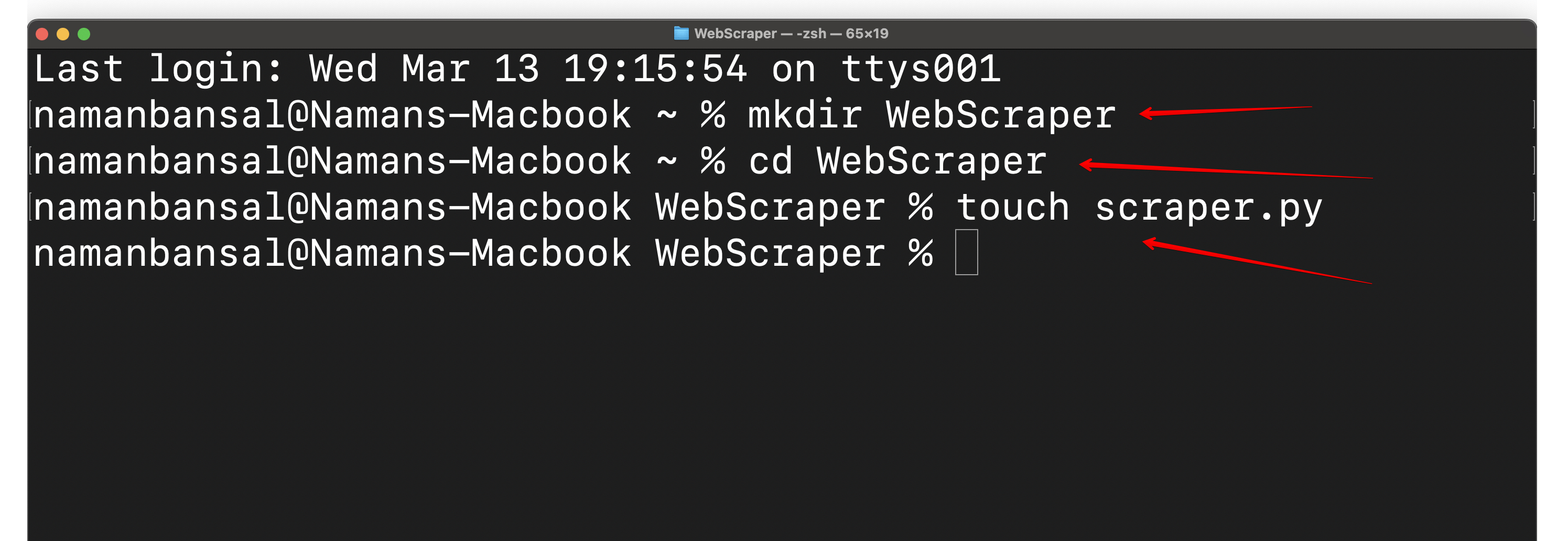
Um IDE é um aplicativo multifuncional que permite aos programadores escrever código, depurá-lo, testar programas, criar automação e muito mais. Você o utilizará aqui para codificar seu Scraper HTML.
Em seguida, você precisa separar sua instalação global do Python do seu projeto de scraping criando um ambiente virtual. Isso ajuda a evitar conflitos de dependência e mantém todo o aplicativo organizado.
Para fazer isso, instale a biblioteca virtualenv usando o seguinte comando:
pip3 install virtualenv
Navegue até a pasta do seu projeto:
cd WebScraper
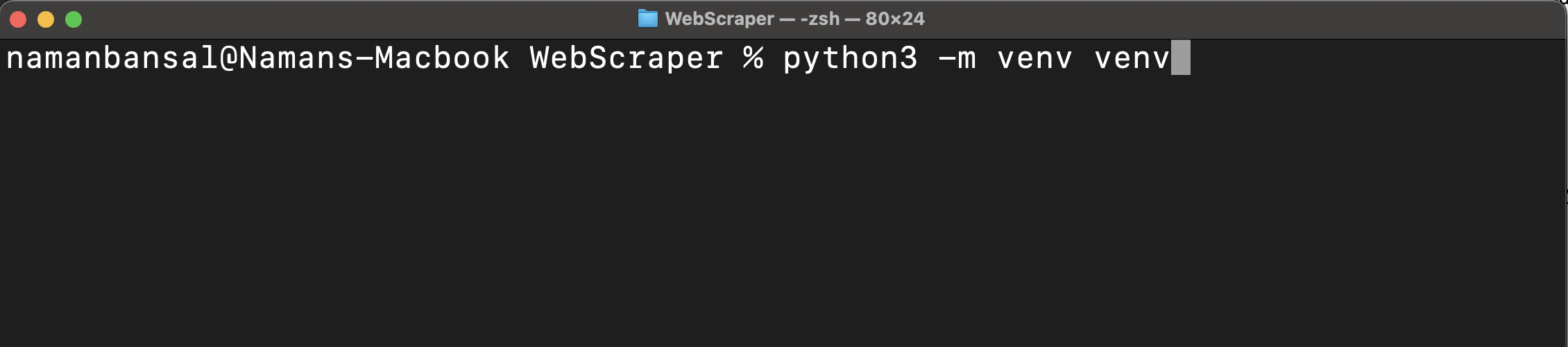
Em seguida, crie um ambiente virtual:
python<versão> -m venv <nome-do-ambiente-virtual>
Este comando cria uma pasta para todos os pacotes e scripts dentro da pasta do seu projeto:
Agora, você precisa ativar o ambiente virtual usando um dos seguintes comandos (com base na sua plataforma):
source <nome-do-ambiente-virtual>/bin/activate #No MacOS e Linux
<nome-do-ambiente-virtual>/Scripts/activate.bat #No CMD
<nome-do-ambiente-virtual>/Scripts/Activate.ps1 #No Powershell
Após a ativação bem-sucedida, você verá o nome do seu ambiente virtual no lado esquerdo da tela:
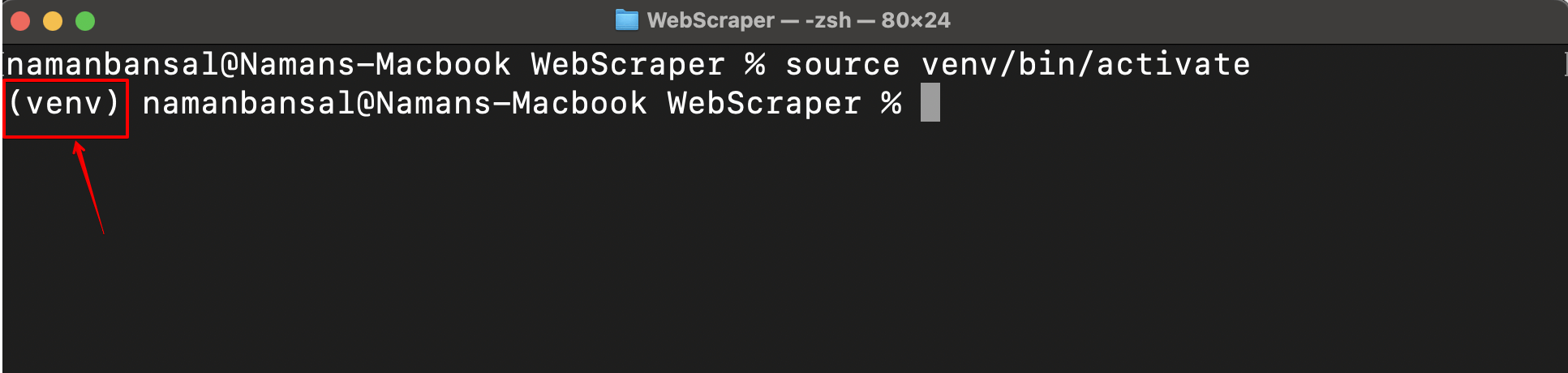
Agora que seu ambiente virtual está ativado, você precisa instalar uma biblioteca de Scraping de dados. Existem inúmeras opções, incluindo Playwright, Selenium, Beautiful Soup e Scrapy. Aqui, você utiliza o Playwright porque é fácil de usar, suporta vários navegadores, pode lidar com conteúdo dinâmico e oferece um modo headless (scraping sem interface gráfica do usuário (GUI)).
Execute pip install pytest-playwright para instalar o Playwright; em seguida, instale os navegadores necessários com playwright install.
Após instalar o Playwright, você estará pronto para começar o Scraping de dados.
Extraia HTML de um site
A primeira etapa de qualquer projeto de Scraping de dados é identificar o site que você deseja extrair. Aqui, você utiliza este site de teste.
Em seguida, você precisa identificar as informações que deseja extrair da página. Neste caso, é o conteúdo HTML completo da página.
Depois de identificar as informações que você está tentando extrair, você pode começar a codificar o Scraper. Em Python, o primeiro passo éimportar as bibliotecas necessárias para o Playwright. O Playwright permite importar dois tipos de APIs:sync e async. A biblioteca async é usada apenas ao escrever código assíncrono, então você importa a biblioteca sync com o seguinte comando:
from playwright.sync_api import sync_playwright
Após importar a biblioteca sync, você precisa declarar uma função Python usando o seguinte trecho de código:
def main():
#O restante do código estará dentro desta função
Como você pode ver na nota anterior, você escreve seu código de Scraping de dados dentro desta função.
Normalmente, para obter informações de um site, você abriria um navegador da web, criaria uma nova guia e visitaria esse site. Para fazer o scraping do site, você precisa traduzir essas ações em código, e é para isso que você usará o Playwright.A documentaçãodeles mostra que você pode chamar async_apiimportada anteriormente e abrir um navegador com este trecho:
com sync_playwright() como p:
browser = p.chromium.launch(headless=False)
Ao adicionar headless=False dentro dos colchetes, você poderá ver o conteúdo do site.
Depois de abrir o navegador, abra uma nova guia e acesse a URL de destino:
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static")
except:
print("Error")
Observação: as linhas anteriores precisam ser adicionadas abaixo das linhas anteriores, que iniciaram o navegador. Todo esse código fica dentro da função principal e dentro de um arquivo.
Este trecho de código envolve a funçãogoto()dentro de umbloco try-exceptpara um melhor tratamento de erros.
Quando você insere a URL de um site na barra de pesquisa, é necessário aguardar o carregamento. Para imitar isso no código, você pode usar o seguinte:
page.wait_for_timeout(7000) #valor em milissegundos entre colchetes
Observação: as linhas anteriores precisam ser adicionadas abaixo das linhas anteriores.
Por fim, é hora de extrair todo o conteúdo HTML da página usando esta linha de código:
print(page.content())
O código completo para extrair o HTML de uma página fica assim:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static")
except:
print("Erro")
page.wait_for_timeout(7000)
print(page.content())
main()
No Visual Studio Code, o HTML extraído tem a seguinte aparência:
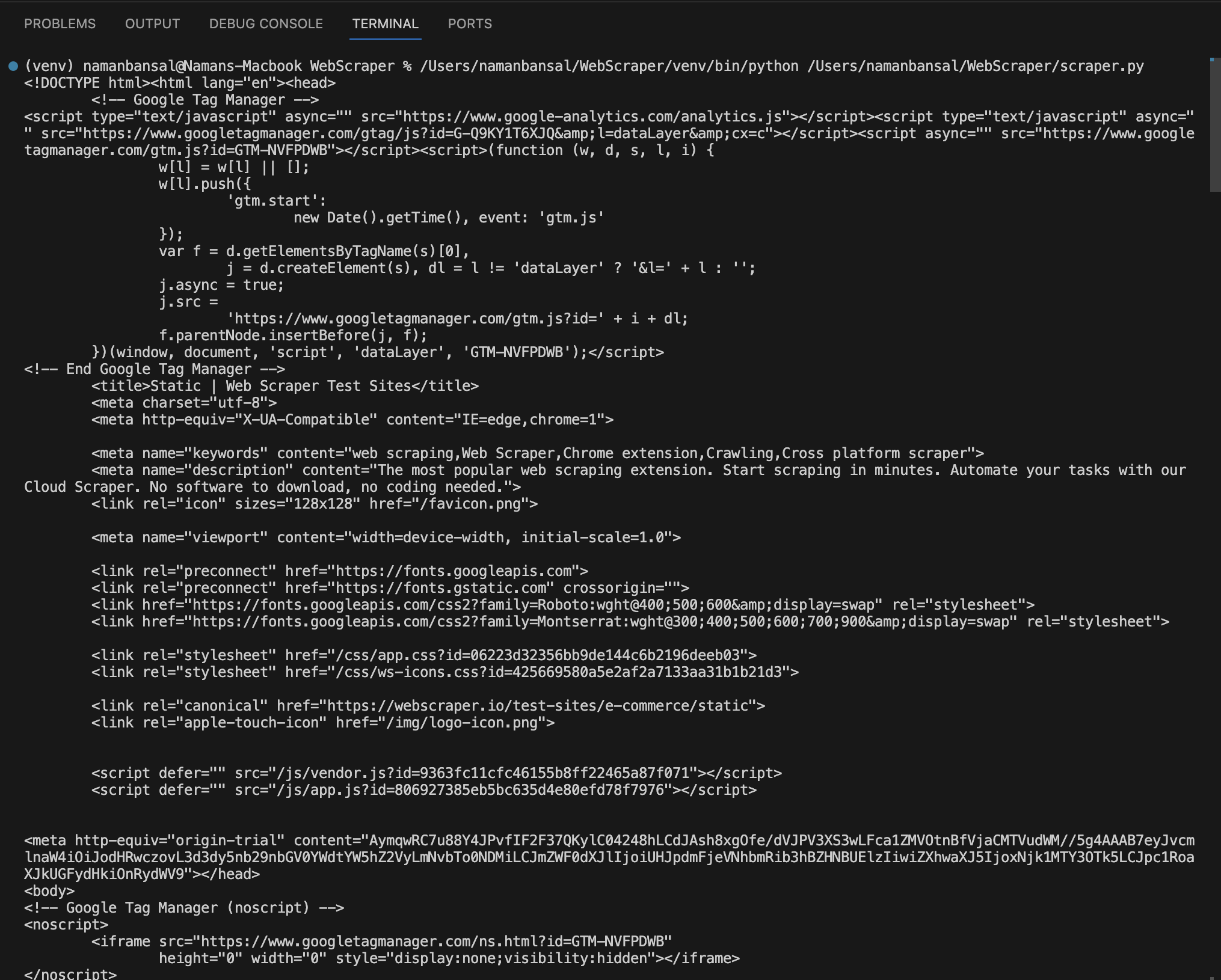
Extrair HTML usando atributos específicos
Anteriormente, você extraiu todos os elementos da página da Web do Scraper; no entanto, o Scraping de dados não é útil a menos que você se limite a extrair apenas as informações necessárias. Nesta seção, você extrai apenas os títulos de todos os laptops na primeira página do site:
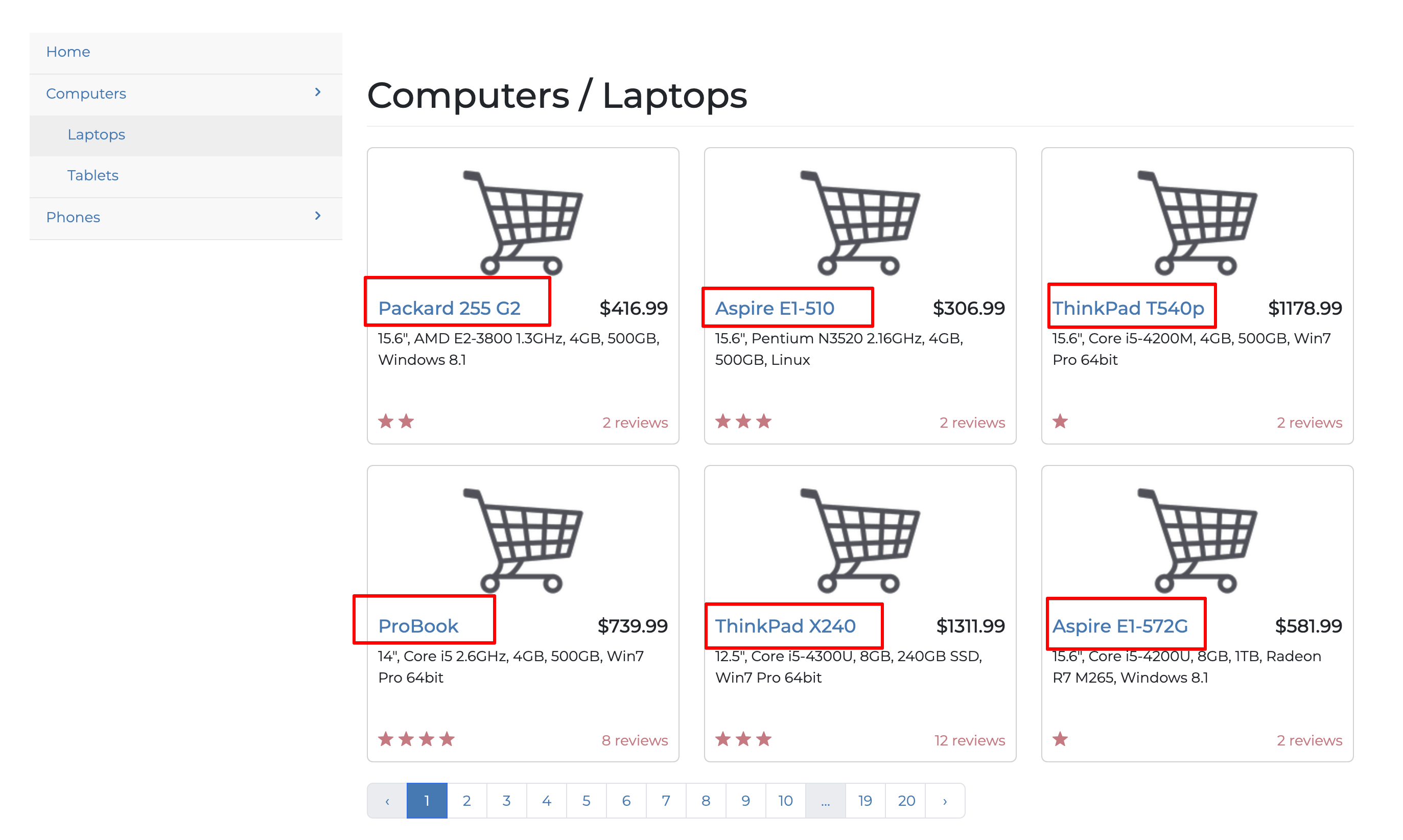
Para extrair elementos específicos, você precisa entender a estrutura do site de destino. Você pode fazer isso clicando com o botão direito do mouse e selecionando a opçãoInspecionar, como mostrado a seguir:
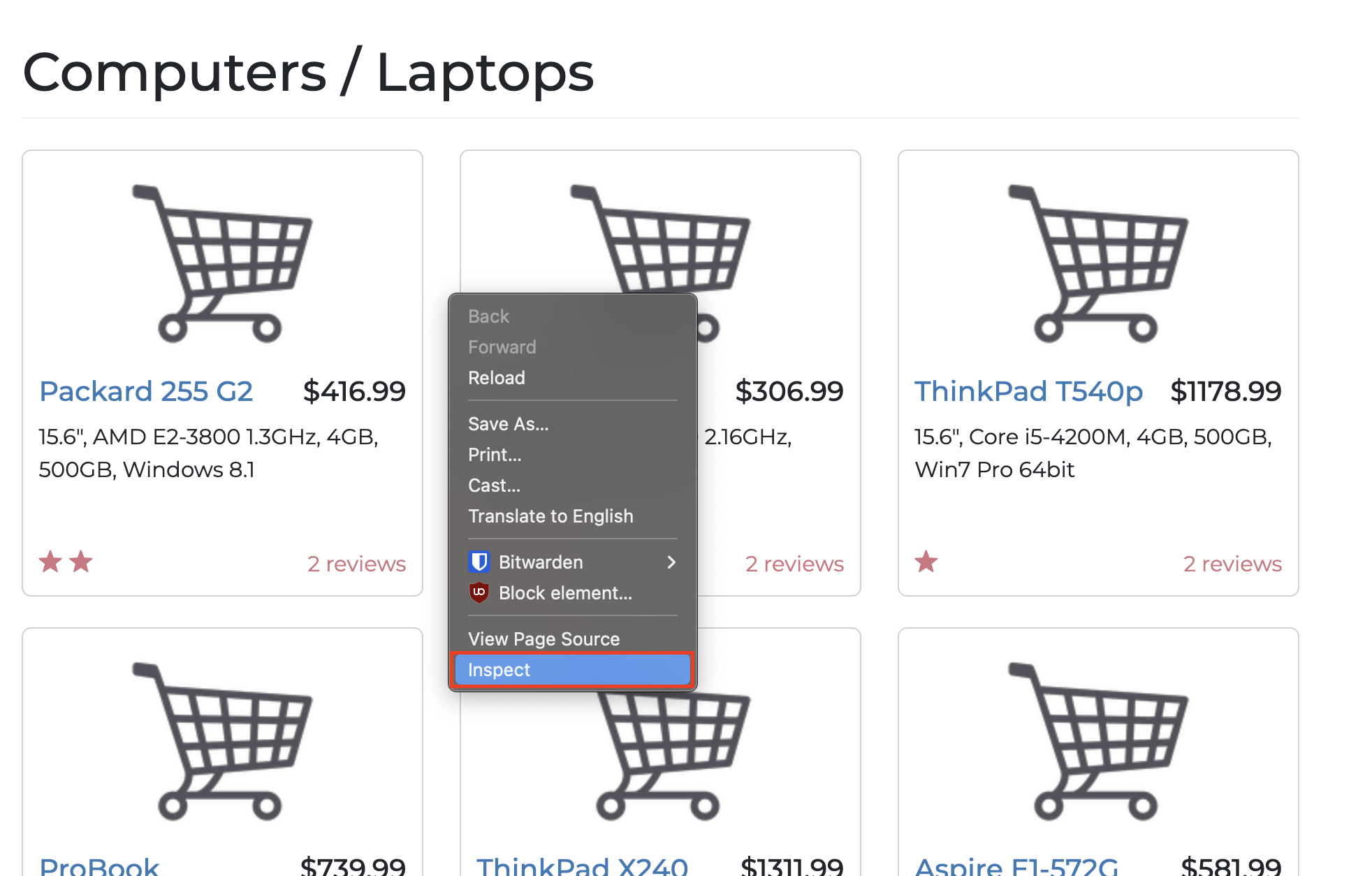
Como alternativa, você pode usar estes atalhos de teclado:
- Para macOS, useCmd + Option + I
- Para Windows, useControl + Shift + C
Esta é a estrutura da página de destino:
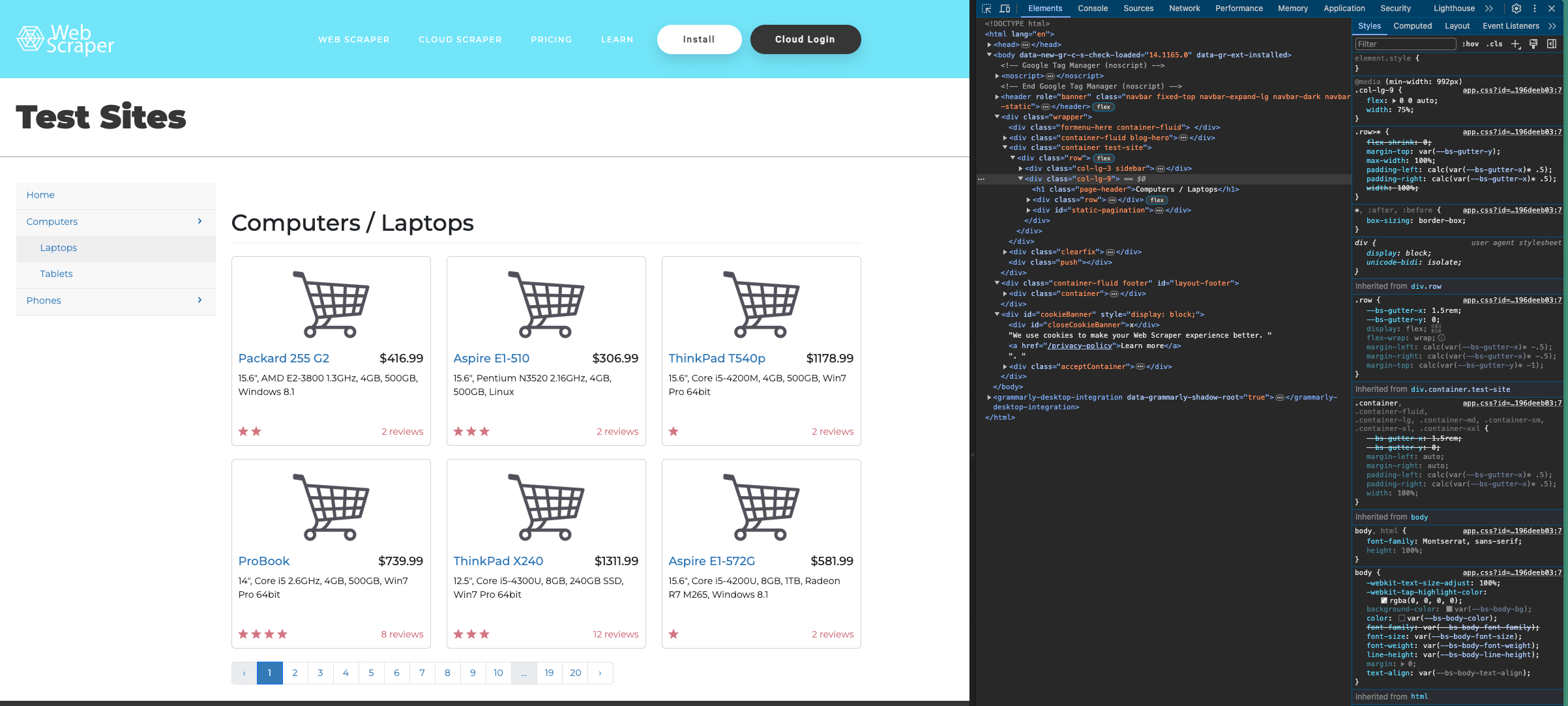
Você pode visualizar o código de um item específico em uma página usando a ferramenta de seleção no canto superior esquerdo da janelaInspecionar:

Selecione um dos títulos de laptop na janelaInspecionar:
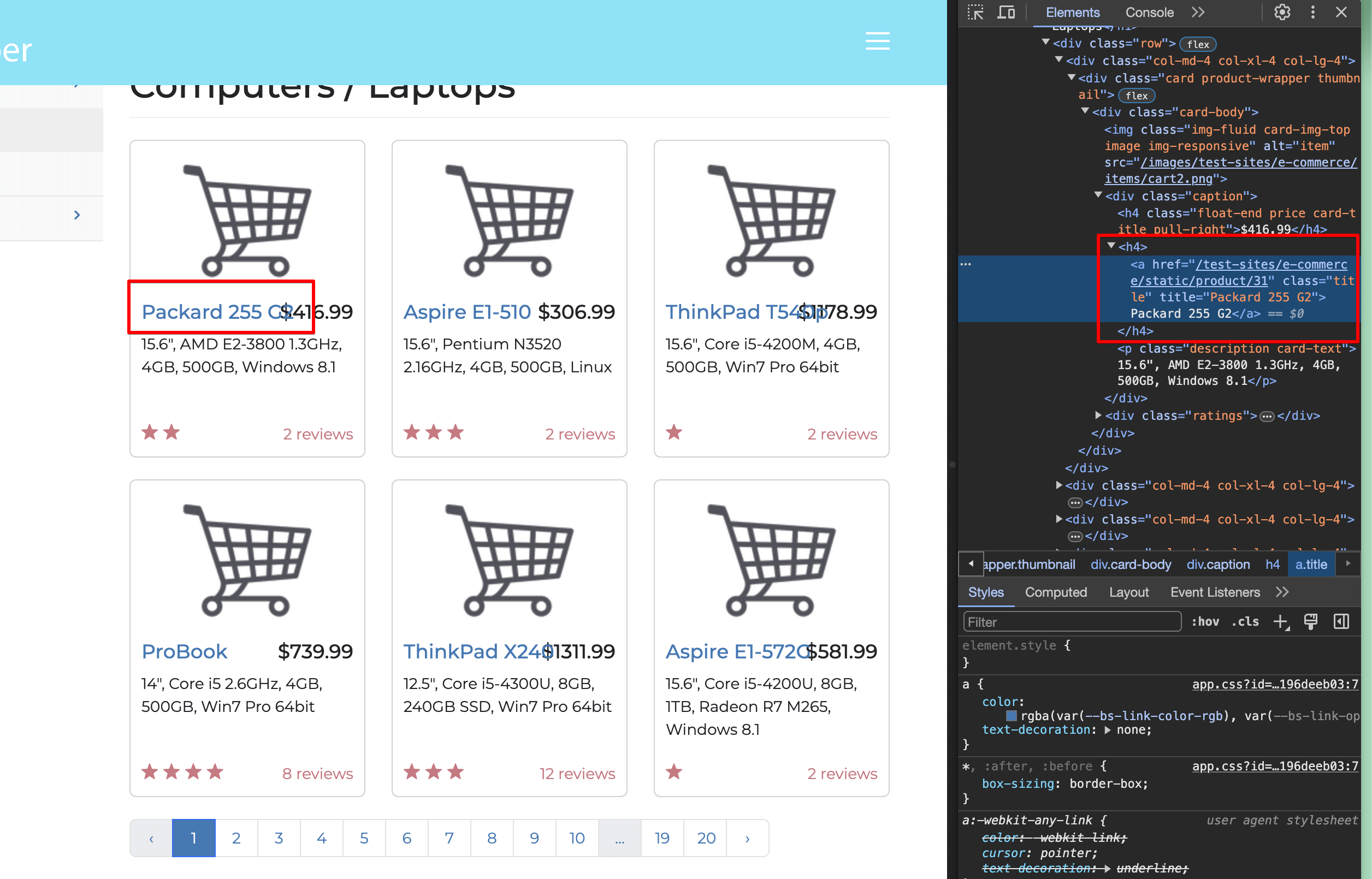
Você pode ver que o título está dentro de uma tag <a> </a>, que é envolvida por uma tag h4, e o link tem uma classe de título. Isso significa que você está procurando tags <a href> (URLs) dentro de tags <h4> que têm uma classe de título.
Para criar um programa de scraping que vise com precisão esses elementos, você precisa importar as bibliotecas para criar uma função Python, iniciar o navegador e navegar até o site de destino:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Erro")
page.wait_for_timeout(7000)
Observe que a URL de destino dentro da função page.goto() foi atualizada para apontar para a primeira página que contém a lista de laptops.
Depois de criar o programa de scraping, você precisa localizar o elemento de destino com base na análise da estrutura do seu site. O Playwright possui uma ferramenta chamadalocalizadoresque permite localizar elementos em uma página com base em vários atributos, como os seguintes:
get_by_label()localiza o elemento alvo usando o rótulo associado a um elemento.get_by_text()localiza o elemento alvo usando o texto que o elemento contém.get_by_alt_text()localiza o elemento alvo e executa ações em imagens usando seu texto alternativo.get_by_test_id()localiza o elemento alvo usando o ID de teste de um elemento.
Você pode consultara documentação oficialpara obter mais métodos para localizar elementos.
Para extrair todos os títulos dos laptops, você precisa localizar as tags <h4>, pois elas envolvem todos os títulos dos laptops. Você pode usar o localizador get_by_role() para encontrar elementos com base em sua função, como botões, caixas de seleção e títulos. Isso significa que, para encontrar todos os títulos da página, você precisa escrever o seguinte:
titles = page.get_by_role("heading").all()
Depois disso, você pode imprimi-lo em seu console com o seguinte código:
print(titles)
Após a impressão, você notará que ele fornece uma matriz de elementos:
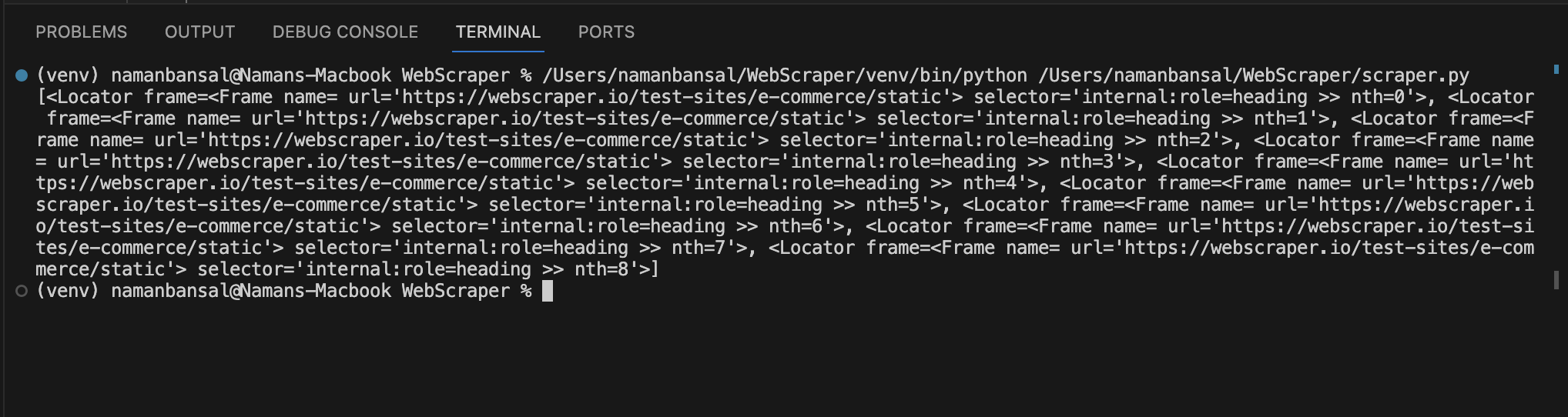
Essa saída não inclui títulos, mas faz referência a elementos que correspondem às condições do seletor. Você deve percorrer esses elementos para encontrar uma tag <a> com uma classe de título e o texto dentro dela.
É recomendável usar o localizador CSS para encontrar um elemento com base em seu caminho e classe, e você pode usar a função all_inner_texts() para extrair o texto interno de um elemento assim:
para título em títulos:
laptop = título.localizador("a.title").all_inner_texts()
Ao executar este código, sua saída deve ficar assim:
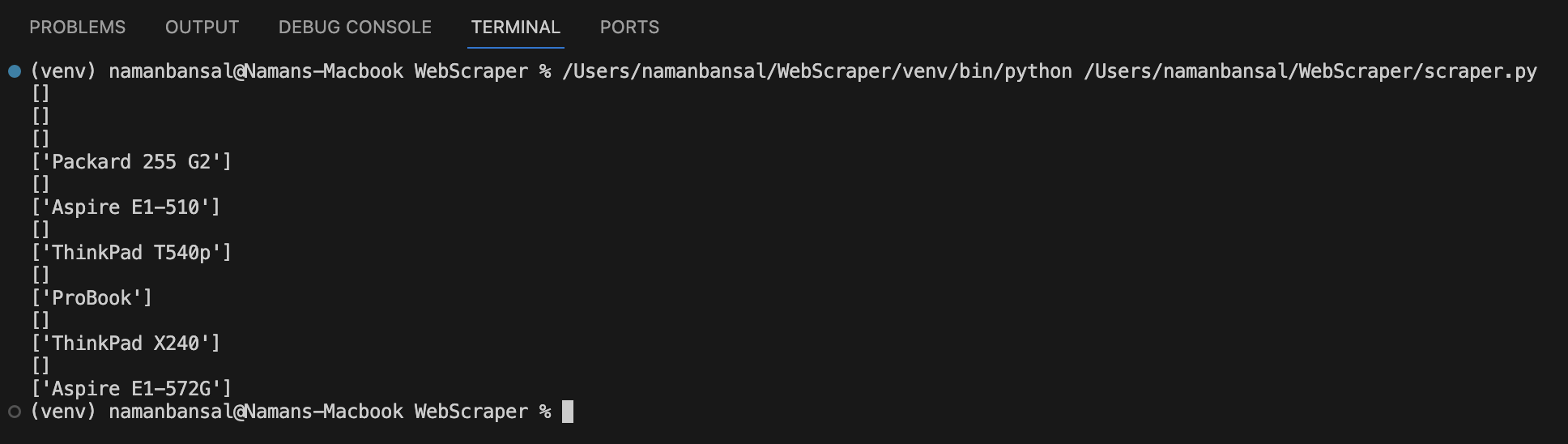
Para rejeitar matrizes sem valores, escreva o seguinte:
if len(laptop) == 1:
print(laptop[0])
Depois de rejeitar matrizes sem valores, você terá criado com sucesso um programa de scraping que extrai apenas elementos específicos.
Aqui está o código completo para este Scraper:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
página = browser.new_page()
tente:
página.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
exceto:
imprimir("Erro")
página.esperar_por_tempo_limite(7000)
títulos = página.obter_por_função("título").todos()
para título em títulos:
laptop = título.localizador("a.título").todos_textos_internos()
se len(laptop) == 1:
imprimir(laptop[0])
main()
Interagir com elementos
Vamos dar um passo adiante e criar um programa que extraia os títulos da primeira página que contém laptops, navegue até a segunda página e extraia esses títulos também.
Como você já sabe como extrair títulos de uma página, só precisa descobrir como navegar para a próxima página de laptops.
Você já deve ter notado os botõesde paginaçãona página em que está atualmente.
Você deve localizaro 2e clicar nele usando seu programa de scraping. Ao inspecionar a página, você verá que o elemento necessário é um elemento de lista (tag<li>) e tem o texto interno2:
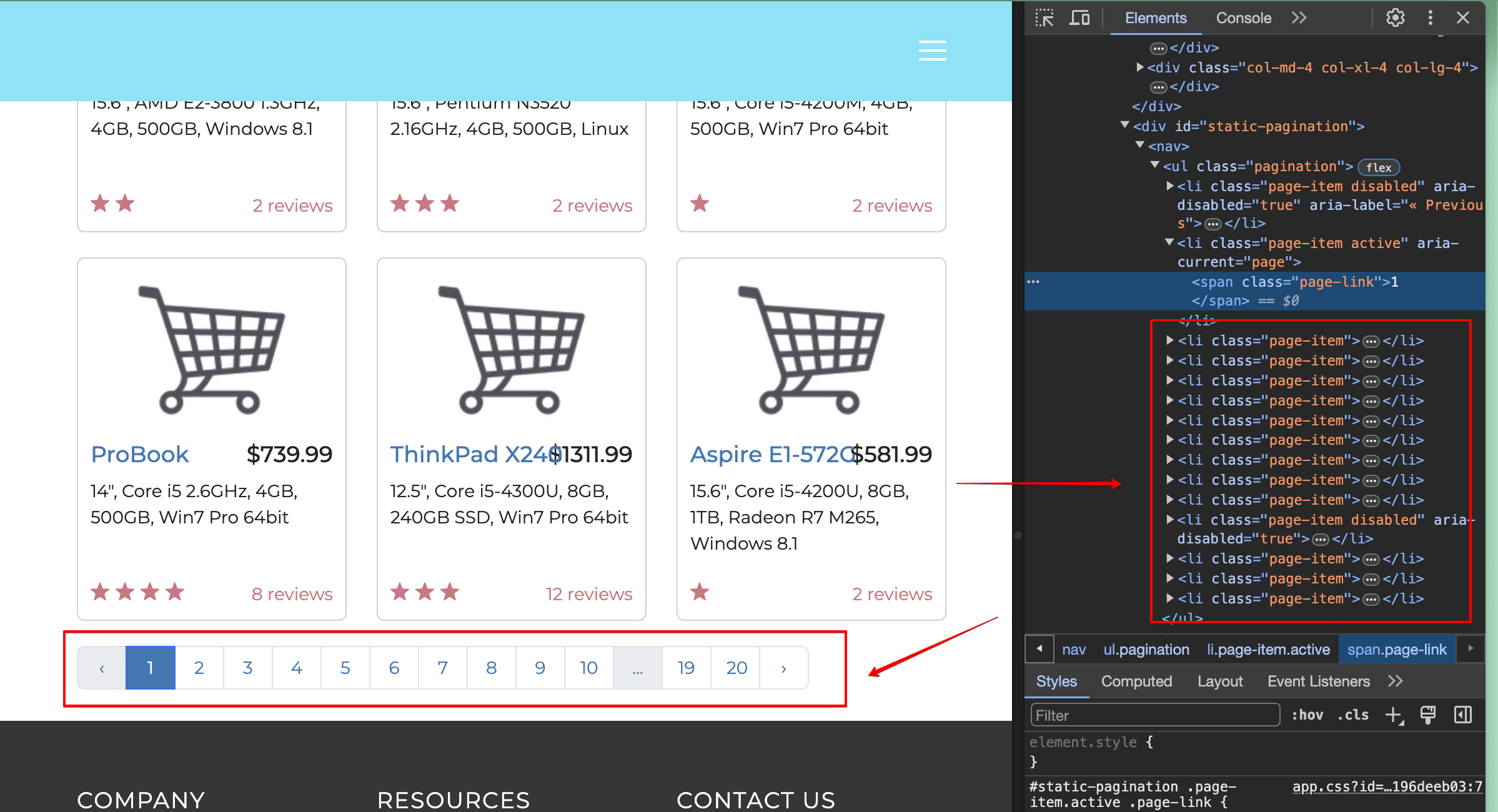
Isso significa que você pode usar o seletor get_by_role() para encontrar um item da lista e o seletor get_by_text() para encontrar um elemento com 2 como texto.
Veja como codificá-lo em seu arquivo:
page.get_by_role("listitem").get_by_text("2", exact=True)
Isso encontra um elemento que corresponde a duas condições: primeiro, ele deve ser um item de lista e, segundo, deve ter 2 como texto.
exact=True é um argumento de função para encontrar o elemento com o texto fornecido.
Para clicar no botão, altere o código anterior para que fique assim:
page.get_by_role("listitem").get_by_text("2", exact=True).click()
Neste código, a função click() clica no elemento fornecido.
Aguarde o carregamento da página e extraia todos os títulos novamente:
page.wait_for_timeout(5000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
Seu bloco de código completo deve ficar assim:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Erro")
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
para título em títulos:
laptop = título.localizador("a.title").all_inner_texts()
se len(laptop) == 1:
imprimir(laptop[0])
página.obter_por_função("listitem").obter_por_texto("2", exato=Verdadeiro).clicar()
página.esperar_por_tempo_limite(5000)
títulos = página.obter_por_função("título").todos()
para título em títulos:
laptop = título.localizador("a.title").todos_textos_internos()
se len(laptop) == 1:
imprimir(laptop[0])
main()
Extraia HTML e grave-o em um CSV
Se você não armazenar e analisar os dados coletados, eles serão inúteis. Nesta seção, você criará um programa avançado que recebe a entrada do usuário para o número de páginas de laptops a serem coletadas, extrai os títulos e os armazena em um arquivo CSV na pasta do seu projeto.
Para este programa, você precisa de uma biblioteca CSV pré-instalada, que pode ser importada usando o seguinte comando:
import csv
Depois de instalar a biblioteca CSV, você precisa descobrir como visitará um número variável de páginas, dependendo da entrada do usuário.
Se você observar a estrutura da URL do site, verá que cada página de laptops é indicada usando um parâmetro de URL. Por exemplo, a URL da segunda página no diretório de laptops é https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page=2.
Você pode visitar páginas diferentes alterando o parâmetro de URL ?page=2 com valores numéricos diferentes. Isso significa que você precisa pedir ao usuário para inserir o número de páginas a serem rastreadas com o seguinte comando:
pages = int(input("digite o número de páginas a serem extraídas: "))
Para visitar cada página de 1 até o número de páginas inserido pelo usuário, você usa um loop for como este:
for i in range(1, pages+1):
Dentro dessa função range, você usa 1 e pages+1 como argumentos da função para representar os valores em que o loop começa e termina. O segundo argumento da função é excluído do loop. Por exemplo, se a função range for range(1,5), o programa fará um loop apenas de 1 a 4.
Em seguida, você precisa visitar cada página inserindo o valoricomo parâmetro de URL na iteração. Você pode adicionar variáveis a uma string usandof-strings do Python.
Ao gerar uma string, você coloca um f antes das aspas para indicar que se trata de uma string f. Dentro das aspas, você pode usar chaves para indicar variáveis.
Aqui está um exemplo de como você pode usar f-strings para imprimir variáveis junto com strings:
print(f"O valor da variável é {nome_da_variável_aqui}")
Voltando ao Scraper, você pode utilizar f-strings escrevendo este bloco de código no arquivo:
tente:
page.goto(f"https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page={i}")
exceto:
imprimir("Erro")
Aguarde o carregamento da página com uma função de tempo limite e extraia os títulos usando o seguinte:
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
Depois de obter todos os elementos do título, você precisa abrir seu arquivo CSV, percorrer cada título, extrair o texto necessário e gravá-lo em seu arquivo.
Para abrir um arquivo CSV, use a seguinte sintaxe:
com open("laptops.csv", "a") como csvfile:
Aqui, você está abrindo o arquivolaptops.csvcom o modo append (a). Você usa o modo append aqui porque não quer perder os dados antigos toda vez que o arquivo é aberto. Se o arquivo não existir, a biblioteca cria um na pasta do projeto.O CSV oferece vários modospara você abrir um arquivo, incluindo os seguintes:
- ré a opção padrão usada se nada for especificado. Ele abre o arquivo somente para leitura.
- wabre um arquivo somente para gravação. Sempre que um arquivo é aberto, os dados anteriores são sobrescritos.
- aabre um arquivo para acrescentar dados. Os dados anteriores não são sobrescritos.
- r+abre um arquivo para leitura e gravação.
- xcria um novo arquivo.
Abaixo do código anterior, você precisadeclarar um objetowriterque permite manipular o arquivo CSV:
writer = csv.writer(csvfile)
Em seguida, faça um loop sobre cada elemento do título e extraia o texto com o seguinte:
para título em títulos:
laptop = título.localizador("a.title").all_inner_texts()
Isso fornece várias matrizes, cada uma contendo o título de laptops individuais. Para rejeitar matrizes vazias, escreva o seguinte código condicional no arquivo CSV:
if len(laptop) == 1:
writer.writerow([laptop[0]])
A função writerow permite escrever novas linhas em um arquivo CSV.
Aqui está o código completo do programa:
from playwright.sync_api import sync_playwright
import csv
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
pages = int(input("digite o número de páginas a serem extraídas: "))
para i no intervalo (1, páginas+1):
tente:
página.goto(f"https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page={i}")
exceto:
imprima("Erro")
página.esperar_por_tempo_limite(7000)
títulos = página.obter_por_função("título").todos()
com abrir("laptops.csv", "a") como arquivo_csv:
escritor = csv.escritor(arquivo_csv)
para título em títulos:
laptop = título.localizador("a.title").all_inner_texts()
se len(laptop) == 1:
escritor.writerow([laptop[0]])
navegador.fechar()
main()
Após executar este código, seu arquivo CSV deverá ficar assim:
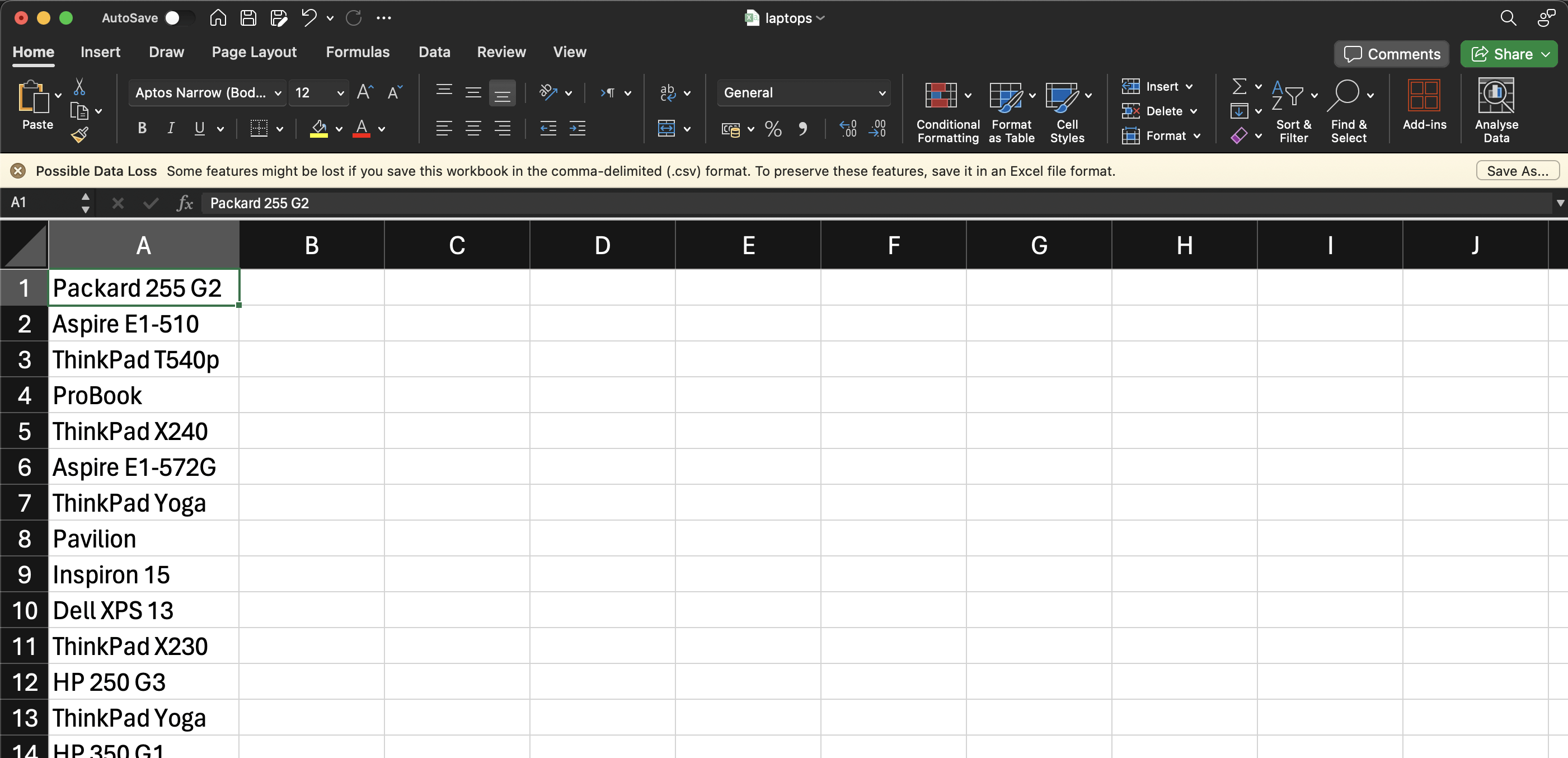
Conclusão
Neste artigo, você aprendeu como extrair, realizar Parsing e armazenar HTML usando Python.
Embora este tutorial tenha sido relativamente simples, em um cenário real, você provavelmente encontraria vários obstáculos durante a extração, incluindo CAPTCHAs, limites de taxa, alterações no layout do site ou requisitos regulatórios. Felizmente,a Bright Datapode ajudar. A Bright Data oferece ferramentas comoProxies residenciais avançadospara melhorar sua extração, umIDEWebScraperpara criar scrapers em escala e umWeb Unblockerpara desbloquear sites públicos, incluindo a resolução de CAPTCHAs. Essas ferramentas podem ajudá-lo a coletar dados precisos em escala e superar obstáculos. Além disso, o compromisso da Bright Data com a extração ética garante que você permaneça dentro dos termos de serviço do site e das regulamentações legais.
Com a plataforma rica em recursos da Bright Data, você pode se concentrar em extrair os dados valiosos de que precisa, deixando para trás as complexidades do Scraping de dados. Comece seu Teste grátis hoje mesmo!





