

Neste artigo, discutiremos:
- Desmistificando o PhantomJS
- Os prós e contras do uso do PhantomJS para rastreamento de dados
- Um guia passo a passo para a coleta de dados com o PhantomJS
- Automação de dados: alternativas mais fáceis à extração manual
Desmistificando o PhantomJS
O PhantomJS é um “navegador web sem interface gráfica”. Isso significa que ele não possui uma interface gráfica do usuário (GUI), mas funciona apenas com scripts (tornando-o mais leve, rápido e, portanto, mais eficiente). Ele pode ser usado para automatizar diferentes tarefas usando JavaScript (JS), como testar códigos ou coletar dados.
Para iniciantes, recomendo primeiro instalar o PhantomJS no seu computador usando o “npm” na sua CLI. Você pode fazer isso executando o seguinte comando:
npm install phantomjs -g
Agora, o comando “phantomjs” estará disponível para você usar.
Prós e contras do uso do PhantomJS para rastreamento de dados
O PhantomJS tem muitas vantagens, incluindo ser “headless” (sem interface gráfica), o que, como expliquei acima, o torna mais rápido, pois não é necessário carregar gráficos para testar ou recuperar informações.
O PhantomJS pode ser usado de forma eficiente para realizar:
Captura de tela
O PhantomJS pode ajudar a automatizar o processo de captura e salvamento de PNGs, JPEGs e até GIFs. Essa função facilita muito a realização da garantia de interface/experiência do usuário front-end. Por exemplo, você pode executar a linha de comando: Phantomjs amazon.js, para coletar imagens de listagens de produtos concorrentes ou para garantir que as listagens de produtos da sua empresa sejam exibidas corretamente.
Automação de páginas
Essa é uma grande vantagem do PhantomJS, pois ajuda os desenvolvedores a economizar muito tempo. Ao executar linhas de comando como Phantomjs userAgent.js, os desenvolvedores podem escrever e verificar o código JS em relação a uma página da web específica. A principal vantagem em termos de economia de tempo aqui é que esse processo pode ser automatizado e realizado sem precisar abrir um navegador.
Testes
O PhantomJS é vantajoso ao testar sites, pois simplifica o processo, assim como outras ferramentas populares de Scraping de dados, como o Selenium. A navegação sem GUI significa que a verificação de problemas pode ocorrer mais rapidamente, com códigos de erro sendo descobertos e entregues no nível da linha de comando.
Os desenvolvedores também integram o PhantomJS a diferentes tipos de sistemas de integração contínua (CI) para testar o código antes de colocá-lo em operação. Isso ajuda os desenvolvedores a corrigir códigos defeituosos em tempo real, garantindo projetos ao vivo mais tranquilos.
Monitoramento de rede/coleta de dados
O PhantomJS também pode ser usado para monitorar o tráfego/atividade da rede. Muitos desenvolvedores o programam de forma a ajudar a coletar dados específicos, tais como:
- O desempenho de uma página da web específica
- Quando linhas de código são adicionadas/removidas
- Dados de flutuação do preço das ações
- Dados de influenciadores/engajamento ao coletar sites como o Instagram
Algumas desvantagens do uso do PhantomJS incluem:
- Pode ser utilizado por pessoas mal-intencionadas para realizar ataques automatizados (principalmente devido ao fato de não usar uma interface de usuário)
- Às vezes, pode ser complicado quando se trata de testes de ciclo completo/ponta a ponta e testes funcionais.
Um guia passo a passo para a coleta de dados com o PhantomJS
O PhantomJS é muito popular entre os desenvolvedores NodeJS, por isso trazemos um exemplo de como usá-lo no ambiente NodeJS. O exemplo mostra como obter o conteúdo HTML da URL.
Primeiro passo: Configure o package.json e instale os pacotes npm
Crie uma pasta de projeto e um arquivo “package.json” nela.
{
"name": "phantomjs-example",
"version": "1.0.0",
"title": "PhantomJS Example",
"description": "PhantomJS Example",
"keywords": [
"phantom example"
],
"main": "./index.js",
"scripts": {
"inst": "rm -rf node_modules && rm package-lock.json && npm install",
"dev": "nodemon index.js"
},
"dependencies": {
"phantom": "^6.3.0"
}
}
Em seguida, execute este comando no seu terminal: $ npm install. Isso instalará o Phantom na pasta local do seu projeto “node_modules”.
Passo dois: crie um script Phantom JS
Crie um script JS e nomeie-o como “index.js”
const phantom = require('phantom');
const main = async () => {
const instance = await phantom.create();
const page = await instance.createPage();
await page.on('onResourceRequested', function(requestData) {
console.info('Requesting', requestData.url);
});
const url = 'https://example.com/';
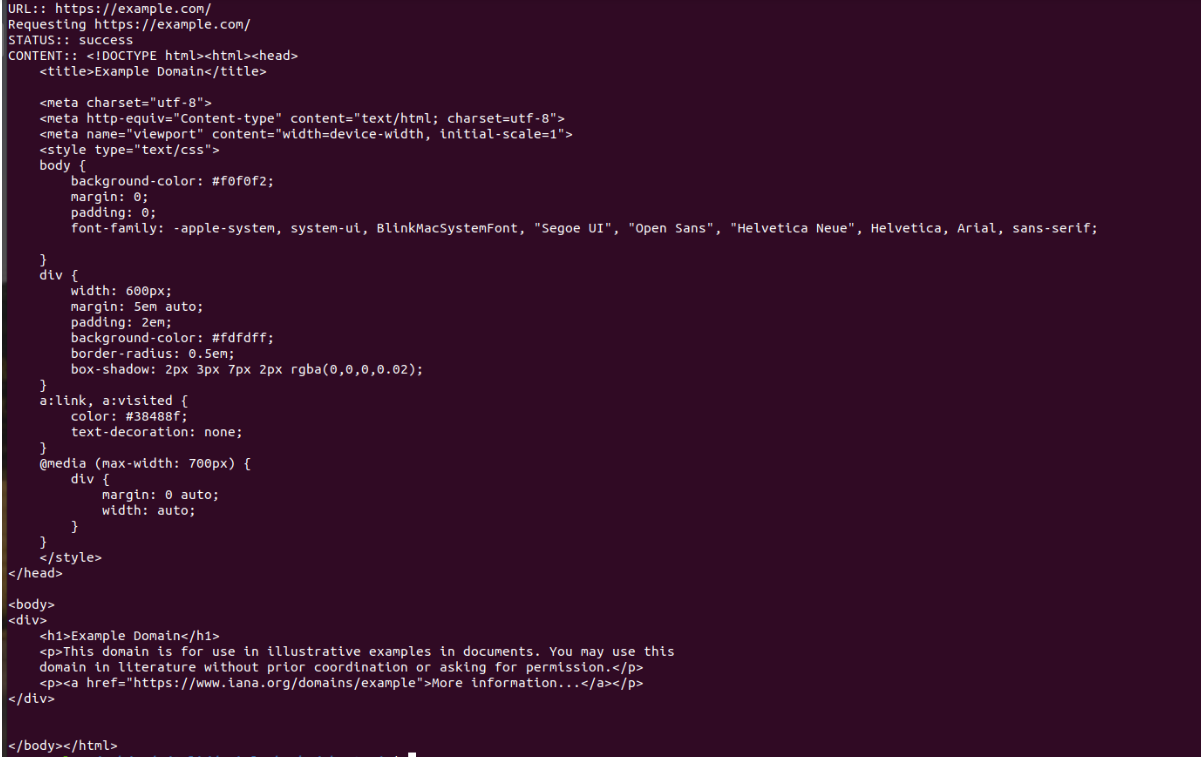
console.log('URL::', url);
const status = await page.open(url);
console.log('STATUS::', status);
const content = await page.property('content');
console.log('CONTENT::', content);
await instance.exit();
};
main().catch(console.log);Etapa três: execute o script JS
Para iniciar o script, execute no seu terminal: $ node index.js. O resultado será um conteúdo HTML.
Automação de dados: alternativas mais fáceis à extração manual
Quando se trata de extrair dados em grande escala, algumas empresas podem preferir utilizar alternativas ao PhantomJS.
Entre elas estão:
- Proxies: o Scraping de dadosda Web com proxies pode ser benéfico, pois permite que os usuários coletem dados em grande escala, enviando um número infinito de solicitações simultâneas. Os proxies também podem ajudar a resolver bloqueios de sites de destino, como limitações de taxa ou bloqueios baseados em geolocalização. Nesse caso, as empresas podem aproveitar IPs móveis e residencialis específicos de países/cidades para rotear solicitações de dados, permitindo-lhes recuperar dados mais precisos voltados para o usuário (por exemplo, preços da concorrência, campanhas publicitárias e resultados de pesquisa do Google).
- Conjuntos de dados prontos para uso: os conjuntos de dados são essencialmente “pacotes informativos” que já foram coletados e estão prontos para serem entregues a algoritmos/equipes para uso imediato. Eles geralmente incluem informações de um site de destino e são enriquecidos com sites relevantes da web (por exemplo, informações sobre produtos em uma categoria relevante entre vários fornecedores e uma variedade de mercados de comércio eletrônico). Os Conjuntos de dados também podem ser atualizados periodicamente para garantir que todos os pontos de dados estejam atualizados. A principal vantagem aqui é o investimento zero de tempo/recursos na coleta de dados, o que significa que mais tempo pode ser dedicado à análise de dados e à criação de valor para os clientes.
- APIs Web Scraper totalmente automatizadas: a API Web Scraper é uma solução de coleta de dados fácil de usar, sem código, sem infraestrutura e personalizável. Ela permite que as empresas coletem dados estruturados da web sem esforço, sem o incômodo de desenvolvimento e manutenção de software ou hardware.
Fale com um dos especialistas em dados da Bright Data para saber quais produtos melhor atendem às suas necessidades de Scraping de dados.





