

O Node.js surgiu como uma opção poderosa para a criação de Scrapers de dados, oferecendo conveniência para desenvolvimentos tanto do lado do cliente quanto do lado do servidor. Seu extenso catálogo de bibliotecas torna o Scraping de dados da web com o Node.js uma tarefa fácil. Neste artigo, o cheerio será destaque e suas capacidades serão exploradas para um Scraping de dados da web eficiente.
O cheerio é uma biblioteca rápida e flexível para analisar e manipular documentos HTML e XML. Ele implementa um subconjunto de recursos do jQuery, o que significa que qualquer pessoa familiarizada com o jQuery se sentirá à vontade com a sintaxe do cheerio. Nos bastidores, o cheerio usa as bibliotecas parse5 e, opcionalmente, htmlparser2 para analisar documentos HTML e XML.
Neste artigo, você criará um projeto que usa o cheerio e aprenderá como extrair dados de sites dinâmicos e páginas estáticas.
Scraping de dados com o cheerio
Antes de começar este tutorial, certifique-se de que o Node.js esteja instalado no seu sistema. Se ainda não o tiver, você pode instalá-lo usando a documentação oficial.
Depois de instalar o Node.js, crie um diretório chamado cheerio-demo e acesse-o com o comando cd:
mkdir cheerio-demo u0026u0026 cd cheerio-demon
Em seguida, inicialize um projeto npm no diretório:
npm init -yn
Instale os pacotes cheerio e Axios:
npm install cheerio axiosn
Crie um arquivo chamado index.js, que é onde você escreverá o código para este tutorial. Em seguida, abra esse arquivo em seu editor favorito para começar.
A primeira coisa que você precisa fazer é importar os módulos necessários:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);n
Neste tutorial, você irá extrair a página Books to Scrape, uma área de testes pública para testar Scrapers de dados. Primeiro, você usará o Axios para fazer uma solicitação GET à página da web com o seguinte código:
axios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n n});n
O objeto de resposta na chamada de retorno contém o código HTML da página da web na propriedade de dados. Esse HTML precisa ser passado para a função load do módulo cheerio. Essa função retorna uma instância do CheerioAPI, que será usada para acessar e manipular o DOM para o restante do código. Observe que a instância do CheerioAPI é armazenada em uma variável chamada $, que é uma referência à sintaxe do jQuery:
axios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);n});n
Localizando elementos
O cheerio suporta o uso de seletores CSS e XPath para selecionar elementos da página. Se você já usou jQuery, vai achar a sintaxe familiar — passe o seletor CSS para a função $(). Use essa sintaxe para encontrar e extrair informações na primeira página do site Books to Scrape.
Acesse https://books.toscrape.com/ e abra o Console do desenvolvedor. Pesquise na guia Inspecionar elemento, onde você aprenderá mais sobre a estrutura HTML da página. Nesse caso, você pode ver que todas as informações sobre os livros estão contidas nas tags de artigo com a classe product-pod:
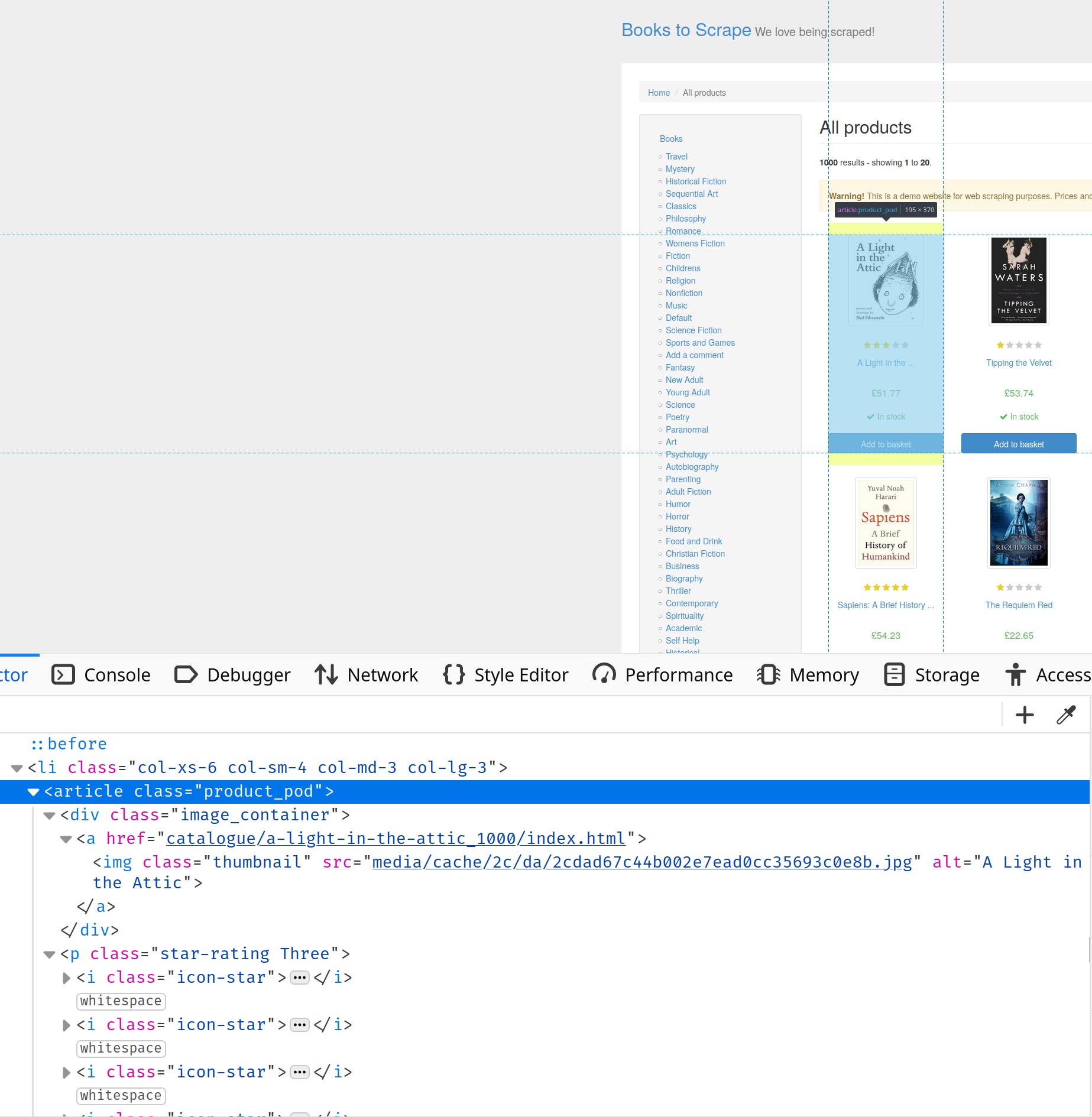
Para selecionar os livros, você precisa usar o seletor CSS article.product_pod desta forma:
$(u0022article.product_podu0022);n
Essa função retorna uma lista de todos os elementos que correspondem ao seletor. Você pode usar o método each para iterar sobre a lista:
$(u0022article.product_podu0022).each( (i, element) =u003e {nn});n
Dentro do loop, você pode usar a variável element para extrair os dados.
Tente extrair o título dos livros na primeira página. Voltando ao console Inspecionar Elemento, você pode ver como os títulos são armazenados:

Você verá que precisa encontrar um h3, que é um filho da variável element. Dentro do h3, há um elemento a que contém o título do livro. Você pode usar o método find com um seletor CSS para encontrar os filhos de um elemento, mas inicialmente, você precisa passar o elemento por $ para convertê-lo em uma instância do Cheerio:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);nn});n
Agora, você pode encontrar o a dentro do titleH3:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022);n});n
Observação:
titleH3já é uma instância doCheerio, então você não precisa passá-lo por$.
Extraindo texto
Depois de selecionar um elemento, você pode obter o texto desse elemento usando o método text.
Modifique o exemplo anterior para extrair o título do livro chamando o método text no resultado do método find:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nn console.log(title);n});n
O código completo deve ficar assim:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);nnaxios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);nn $(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nn console.log(title);n });n});n
Execute o código com node index.js e você deverá ver o seguinte resultado:
A Light in the ...nTipping the VelvetnSoumissionnSharp ObjectsnSapiens: A Brief History ...nThe Requiem RednThe Dirty Little Secrets ...nThe Coming Woman: A ...nThe Boys in the ...nThe Black MarianStarving Hearts (Triangular Trade ...nShakespeare's SonnetsnSet Me FreenScott Pilgrim's Precious Little ...nRip it Up and ...nOur Band Could Be ...nOlionMesaerion: The Best Science ...nLibertarianism for BeginnersnIt's Only the Himalayasn
Navegando no DOM: localizando filhos e irmãos
Depois de extrair os títulos, é hora de extrair o preço e a disponibilidade de cada livro. O Inspect Element revela que tanto o preço quanto a disponibilidade estão armazenados em um div com a classe product_price. Você pode selecionar esse div com o seletor CSS .product_price, mas como você já abordou os seletores CSS, a seguir discutiremos outra maneira de fazer isso:
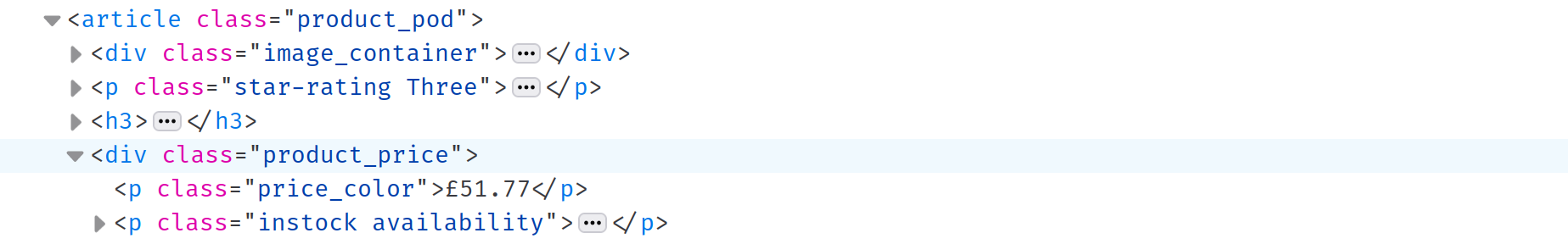
Observação: o
divé um irmão dotitleH3que você selecionou anteriormente. Ao chamar o métodonextdotitleH3, você pode selecionar o próximo irmão:
const priceDiv = titleH3.next();n
Você já viu que pode usar o método find para encontrar os filhos de um elemento com base em seletores CSS. Você também pode selecionar todos os filhos com o método children e, em seguida, usar o método eq para selecionar um filho específico. Isso é equivalente ao seletor CSS nth-child.
Nesse caso, o preço é o primeiro filho do priceDiv e a disponibilidade é o segundo filho do priceDiv. Isso significa que você pode selecioná-los com priceDiv.children().eq(0) e priceDiv.children().eq(1), respectivamente. Faça isso e imprima o preço e a disponibilidade:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nnn const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();n console.log(title, price, availability);n});n
Agora, ao executar o código, é exibida a seguinte saída:
A Light in the ... £51.77 In stocknTipping the Velvet £53.74 In stocknSoumission £50.10 In stocknSharp Objects £47.82 In stocknSapiens: A Brief History ... £54.23 In stocknThe Requiem Red £22.65 In stocknThe Dirty Little Secrets ... £33.34 In stocknThe Coming Woman: A ... £17.93 In stocknThe Boys in the ... £22.60 In stocknThe Black Maria £52.15 In stocknStarving Hearts (Triangular Trade ... £13.99 In stocknShakespeare's Sonnets £20.66 In stocknSet Me Free £17.46 In stocknScott Pilgrim's Precious Little ... £52.29 In stocknRip it Up and ... £35.02 In stocknOur Band Could Be ... £57.25 In stocknOlio £23.88 In stocknMesaerion: The Best Science ... £37.59 In stocknLibertarianism for Beginners £51.33 In stocknIt's Only the Himalayas £45.17 In stockn
Acessando atributos
Até agora, você navegou pelo DOM e extraiu textos dos elementos. Também é possível extrair atributos de um elemento usando o cheerio, que é o que você fará nesta seção. Aqui, você extrairá a classificação dos livros lendo a lista de classes dos elementos.
A classificação dos livros tem uma estrutura interessante. As classificações estão contidas em uma tag p. Cada tag p tem exatamente cinco estrelas, mas as estrelas são coloridas usando CSS com base no nome da classe do elemento p. Por exemplo, em um p com a classe star-rating.Four, as quatro primeiras estrelas são coloridas de amarelo, denotando uma classificação de quatro estrelas:

Para extrair a classificação de um livro, você precisa extrair os nomes de classe do elemento p. O primeiro passo é encontrar o parágrafo que contém a classificação:
const ratingP = $(element).find(u0022p.star-ratingu0022);n
Passando o nome do atributo para o método attr, você pode ler os atributos de um elemento. Neste caso, você precisa ler a lista de classes, que é demonstrada no código a seguir:
const starRating = ratingP.attr('class');n
A lista de classes tem a seguinte forma: classificação por estrelas X, onde X é um dos seguintes valores: Um, Dois, Três, Quatro e Cinco. Isso significa que você precisa dividir a lista de classes por espaço e pegar o segundo elemento. O código a seguir faz isso e converte a classificação textual em uma classificação numérica:
const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];n
Se você juntar tudo, seu código ficará assim:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nnn const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();nn const ratingP = $(element).find(u0022p.star-ratingu0022);n const starRating = ratingP.attr('class');n const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];nn console.log(title, price, availability, rating);n});n
A saída ficará assim:
A Light in the ... £51.77 In stock 3nTipping the Velvet £53.74 In stock 1nSoumission £50.10 In stock 1nSharp Objects £47.82 In stock 4nSapiens: A Brief History ... £54.23 In stock 5nThe Requiem Red £22.65 In stock 1nThe Dirty Little Secrets ... £33.34 In stock 4nThe Coming Woman: A ... £17.93 In stock 3nThe Boys in the ... £22.60 In stock 4nThe Black Maria £52.15 In stock 1nStarving Hearts (Triangular Trade ... £13.99 In stock 2nShakespeare's Sonnets £20.66 In stock 4nSet Me Free £17.46 In stock 5nScott Pilgrim's Precious Little ... £52.29 In stock 5nRip it Up and ... £35.02 In stock 5nOur Band Could Be ... £57.25 In stock 3nOlio £23.88 In stock 1nMesaerion: The Best Science ... £37.59 In stock 1nLibertarianism for Beginners £51.33 In stock 2nIt's Only the Himalayas £45.17 In stock 2n
Salvando os dados
Depois de extrair os dados da página da web, geralmente você vai querer salvá-los. Existem várias maneiras de fazer isso, como salvar em um arquivo, salvar em um banco de dados ou alimentar um pipeline de processamento de dados. Nesta seção, você aprenderá a maneira mais simples de todas: salvar dados em um arquivo CSV.
Para fazer isso, instale o pacote node-csv:
npm install csvn
Em index.js, importe os módulos fs e csv-stringify:
const fs = require(u0022fsu0022);nconst { stringify } = require(u0022csv-stringifyu0022);n
Para gravar um arquivo local, você precisa criar um WriteStream:
const filename = u0022scraped_data.csvu0022;nconst writableStream = fs.createWriteStream(filename);n
Declare os nomes das colunas, que são adicionados ao arquivo CSV como cabeçalhos:
const columns = [n u0022titleu0022,n u0022ratingu0022,n u0022priceu0022,n u0022availabilityu0022n];n
Crie um stringifier com os nomes das colunas:
const stringifier = stringify({ header: true, columns: columns });n
Dentro da função each, você usará o stringifier para gravar os dados:
$(u0022article.product_podu0022).each( (i, element) =u003e {n ...nn const data = { title, rating, price, availability };n stringifier.write(data);nn});n
Por fim, fora da função each, você precisa gravar o conteúdo do stringifier na variável writableStream:
stringifier.pipe(writableStream);n
Neste ponto, seu código deve ficar assim:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);nconst fs = require(u0022fsu0022);nconst { stringify } = require(u0022csv-stringifyu0022);nnconst filename = u0022scraped_data.csvu0022;nconst writableStream = fs.createWriteStream(filename);nnconst columns = [n u0022titleu0022,n u0022ratingu0022,n u0022priceu0022,n u0022availabilityu0022n];nconst stringifier = stringify({ header: true, columns: columns });nnaxios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);nn $(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();n n const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();n const ratingP = $(element).find(u0022p.star-ratingu0022);n const starRating = ratingP.attr('class');n const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];nn console.log(title, price, availability, rating);nn const data = { title, rating, price, availability };n stringifier.write(data);nn });nn stringifier.pipe(writableStream);nn});n
Execute o código, e ele deve criar um arquivo scraped_data.csv com os dados coletados dentro:
title,rating,price,availabilitynA Light in the ...,3,£51.77,In stocknTipping the Velvet,1,£53.74,In stocknSoumission,1,£50.10,In stocknSharp Objects,4,£47.82,In stocknSapiens: A Brief History ...,5,£54.23,In stocknThe Requiem Red,1,£22.65,In stocknThe Dirty Little Secrets ...,4,£33.34,In stocknThe Coming Woman: A ...,3,£17.93,In stocknThe Boys in the ...,4,£22.60,In stocknThe Black Maria,1,£52.15,In stocknStarving Hearts (Triangular Trade ...,2,£13.99,In stocknShakespeare's Sonnets,4,£20.66,In stocknSet Me Free,5,£17.46,In stocknScott Pilgrim's Precious Little ...,5,£52.29,In stocknRip it Up and ...,5,£35.02,In stocknOur Band Could Be ...,3,£57.25,In stocknOlio,1,£23.88,In stocknMesaerion: The Best Science ...,1,£37.59,In stocknLibertarianism for Beginners,2,£51.33,In stocknIt's Only the Himalayas,2,£45.17,In stockn
Conclusão
Como você viu aqui, a biblioteca cheerio facilita o Scraping de dados da web com sua sintaxe semelhante à jQuery e operação extremamente rápida. Neste artigo, você aprendeu a fazer o seguinte:
- Carregar e realizar o Parsing de uma página da web HTML com o cheerio
- Encontrar elementos com seletores CSS
- Extrair dados de elementos
- Navegar pelo DOM
- Salvar dados coletados no armazenamento de arquivos local
Você pode encontrar o código completo no GitHub.
No entanto, o cheerio é apenas um analisador HTML, portanto, não pode executar código JavaScript. Isso significa que você não pode usá-lo para coletar páginas da web dinâmicas e aplicativos de página única. Para coletar esses dados, você precisa ir além do cheerio e procurar ferramentas complexas como Selenium ou Playwright. E é aí que entra a Bright Data. As vastas soluções de Scraping de dados da Bright Data incluem um Selenium Scraping Browser e um Playwright Scraping Browser. Para saber mais sobre os produtos, você pode visitar nossa documentação do Navegador de scraping.





