

Neste guia sobre o Scrapy Splash, você aprenderá:
- O que é o Scrapy Splash
- Como usar o Scrapy Splash em Python em um tutorial passo a passo
- Técnicas avançadas de raspagem com o Splash no Scrapy
- Limitações ao fazer scraping de sites com essa ferramenta
Vamos mergulhar de cabeça!
O que é o Scrapy Splash?
O Scrapy Splash refere-se à integração entre essas duas ferramentas:
- Scrapy: Uma biblioteca de estrutura de rastreamento de código aberto em Python para extrair os dados de que você precisa de sites.
- Splash: um navegador leve e sem cabeça projetado para renderizar páginas da Web com muito JavaScript.
Você deve estar se perguntando por que uma ferramenta poderosa como o Scrapy precisa do Splash. Bem, o Scrapy só pode lidar com sites estáticos, pois depende de recursos de análise de HTML (especificamente, do Parsel). No entanto, ao raspar sites dinâmicos, você precisa lidar com a renderização de JavaScript. Uma solução comum é usar um navegador automatizado, que é exatamente o que o Splash oferece.
Com o Scrapy Splash, você pode enviar uma solicitação especial – conhecida como SplashRequest - paraum servidor Splash. Esse servidor renderiza totalmente a página executando JavaScript e retorna o HTML processado. Assim, ele permite que o Scrapy Spider recupere dados de páginas dinâmicas.
Em resumo, você precisa do Scrapy Splash se:
- Você está trabalhando com sites com muito JavaScript que o Scrapy sozinho não consegue extrair.
- Você prefere uma solução leve em comparação com o Selenium ou o Playwright.
- Você deseja evitar a sobrecarga de executar um navegador completo para raspagem.
Se o Scrapy Splash não atender às suas necessidades, considere estas alternativas:
- Selênio: Um recurso completo de automação do navegador para raspagem de sites com muito JavaScript, que oferece extensões interessantes como o Selenium Wire.
- Playwright: Uma ferramenta de automação de navegador de código aberto que oferece automação consistente entre navegadores e uma API robusta, compatível com várias linguagens de programação.
- Puppeteer: Uma biblioteca Node.js de código aberto desenvolvida que fornece uma API de alto nível para automatizar e controlar o Chrome por meio do protocolo DevTools.
Scrapy Splash em Python: Um tutorial passo a passo
Nesta seção, você entenderá como usar o Scrapy Splash para recuperar dados de um site. A página de destino será uma versão especial renderizada em JavaScript do popular site “Quotes to Scrape“:

É como o habitual “Quotes to Scrape”, mas usa a rolagem infinita para carregar dados dinamicamente por meio de solicitações AJAX acionadas por JavaScript.
Requisitos
Para replicar este tutorial usando o Scrapy Splash em Python, seu sistema deve atender aos seguintes requisitos:
- Python 3.10.1 ou superior.
- Docker 27.5.1 ou superior.
Se você não tiver essas duas ferramentas instaladas em seu computador, siga os links acima.
Pré-requisitos, dependências e integração com o Splash
Suponha que você chame a pasta principal do seu projeto de scrapy_splash/. Ao final desta etapa, a pasta terá a seguinte estrutura:
scrapy_splash/
└── venv/Onde venv/ contém o ambiente virtual. Você pode criar o diretório do ambiente virtual venv/ da seguinte forma:
python -m venv venvPara ativá-lo, no Windows, execute:
venvScriptsactivateDe forma equivalente, no macOS e no Linux, execute:
source venv/bin/activateNo ambiente virtual ativado, instale as dependências com:
pip install scrapy scrapy-splashComo pré-requisito final, você precisa extrair a imagem do Splash via Docker:
docker pull scrapinghub/splashEm seguida, inicie o contêiner:
docker run -it -p 8050:8050 --rm scrapinghub/splashPara obter mais informações, siga as instruções de integração do Docker com base no sistema operacional.
Depois de iniciar o contêiner do Docker, aguarde até que o serviço Splash registre a mensagem abaixo:
Server listening on http://0.0.0.0:8050A mensagem indica que o Splash já está disponível em http://0.0.0.0:8050. Visite esse URL em seu navegador e você deverá ver a página a seguir:
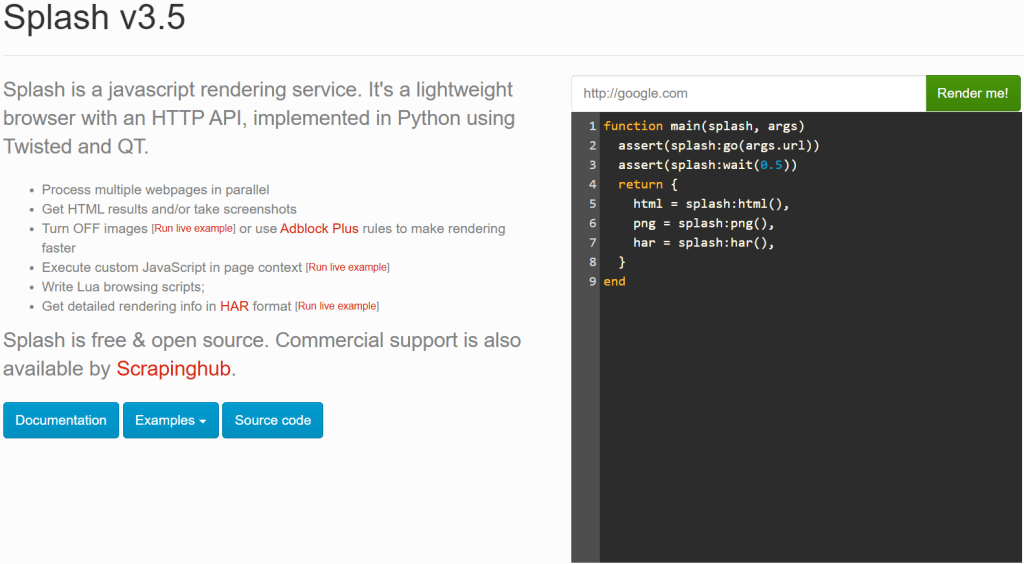
Dependendo de sua configuração, seguir a URL http://0.0.0.0:8050 pode não mostrar o serviço Splash funcionando. Nesse caso, tente usar uma das seguintes opções:
http://localhost:8050http://127.0.0.1:8050
Observação: lembre-se de que a conexão com o servidor Splash deve permanecer aberta durante o uso do Scrapy-Splash. Em outras palavras, se você usou a CLI para executar o contêiner do Docker, mantenha esse terminal aberto e use um terminal separado para as próximas etapas deste procedimento.
Maravilhoso! Agora você tem o que precisa para extrair páginas da Web com o Scrapy Splash.
Etapa 1: iniciar um novo projeto do Scrapy
Dentro da pasta principal scrapy_splash/, digite o comando abaixo para iniciar um novo projeto Scrapy:
scrapy startproject quotesCom esse comando, o Scrapy criará uma pasta quotes/. Dentro dela, ele gerará automaticamente todos os arquivos de que você precisa. Esta é a estrutura de pastas resultante:
scrapy_splash/
├── quotes/
│ ├── quotes/
│ │ ├── spiders/
│ │ ├── __init__.py
│ │ ├── items.py
│ │ ├── middlewares.py
│ │ ├── pipelines.py
│ │ └── settings.py
│ │
│ └── scrapy.cfg
└── venv/ Perfeito! Você iniciou um novo projeto Scrapy.
Etapa 2: Gerar a aranha
Para gerar um novo spider para rastrear o site de destino, navegue até a pasta quotes/:
cd quotesEm seguida, gere uma nova aranha com:
scrapy genspider words https://quotes.toscrape.com/scrollVocê obterá o seguinte resultado:
Created spider 'words' using template 'basic' in module:
quotes.spiders.wordsComo você pode ver, o Scrapy criou automaticamente um arquivo words.py dentro da pasta spiders/. O arquivo words.py contém o seguinte código:
import scrapy
class WordsSpider(scrapy.Spider):
name = "words"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["https://quotes.toscrape.com/scroll"]
def parse(self, response):
passIsso logo conterá a lógica de raspagem necessária da página de destino dinâmica.
Viva! Você gerou a aranha para raspar o site de destino.
Etapa 3: Configurar o Scrapy para usar o Splash
Agora você precisa configurar o Scrapy para que ele possa usar o serviço Splash. Para isso, adicione as seguintes configurações ao arquivo settings.py:
# Set the Splash local server endpoint
SPLASH_URL = "http://localhost:8050"
# Enable the Splash downloader middleware
DOWNLOADER_MIDDLEWARES = {
"scrapy_splash.SplashCookiesMiddleware": 723,
"scrapy_splash.SplashMiddleware": 725,
"scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware": 810,
}
# Enable the Splash deduplication argument filter
SPIDER_MIDDLEWARES = {
"scrapy_splash.SplashDeduplicateArgsMiddleware": 100,
}Nas configurações acima:
SPLASH_URLdefine o ponto de extremidade para o servidor Splash local. É para lá que o Scrapy enviará solicitações de renderização de JavaScript.DOWNLOADER_MIDDLEWARESpermite que middlewares específicos interajam com o Splash. Em particular: o espaço reservado Polylang não modifica
O SPIDER_MIDDLEWARESgarante que as solicitações com os mesmos argumentos do Splash não sejam duplicadas, o que é útil para reduzir a carga desnecessária e aumentar a eficiência.
Para obter informações mais detalhadas sobre essas configurações, consulte a documentação oficial do Scrapy-Splash.
Muito bom! Agora o Scrapy pode se conectar ao Splash e usá-lo programaticamente para renderização de JavaScript.
Etapa 4: Definir o script Lua para renderização em JavaScript
O Scrapy agora pode se integrar ao Splash para renderizar páginas da Web que dependem de JavaScript, como a página de destino deste guia. Para definir a lógica personalizada de renderização e interação, você precisa usar scripts Lua. Isso ocorre porque o Splash depende de scripts Lua para interagir com páginas da Web via JavaScript e controlar o comportamento do navegador de forma programática.
Especificamente, adicione o script Lua abaixo ao words.py:
script = """
function main(splash, args)
splash:go(args.url)
-- custom rendering script logic...
return splash:html()
end
"""No trecho acima, a variável script contém a lógica Lua que o Splash executará no servidor. Em particular, esse script instrui o Splash a:
- Navegue até a URL definida com o método
splash:go(). - Retorna o conteúdo HTML renderizado com o método
splash:html().
Use o script Lua acima em uma função start_requests() dentro da classe WordsSpider:
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script}
)O método start_requests() acima substitui o start_requests() padrão do Scrapy. Dessa forma, o Scrapy Splash pode executar o script Lua para recuperar o HTML renderizado em JavaScript da página. A execução do script Lua ocorre por meio do argumento "lua_source": script no método SplashRequest(). Além disso, observe o uso do ponto de extremidade "execute" do Splash (que você aprenderá mais em breve).
Não se esqueça de importar o SplashRequest do Scrapy Splash:
from scrapy_splash import SplashRequestSeu arquivo words.py agora está equipado com o script Lua correto para acessar o conteúdo renderizado em JavaScript na página!
Etapa nº 5: Definir a lógica de análise de dados
Antes de começar, inspecione um elemento HTML de citação na página de destino para entender como analisá-lo:

Lá, você pode ver que os elementos de cotação podem ser selecionados com .quote. Com uma citação, você pode obter:
- O texto da citação de
.text. - O autor da citação de
.author. - As tags de citação de
.tags.
A lógica de raspagem para recuperar todas as citações da página de destino pode ser definida por meio do método parse() a seguir:
def parse(self, response):
# Retrieve CSS selectors
quotes = response.css(".quote")
for quote in quotes:
yield {
"text": quote.css(".text::text").get(),
"author": quote.css(".author::text").get(),
"tags": quote.css(".tags a.tag::text").getall()
}parse() processa a resposta retornada pelo Splash. Em detalhes, ele:
- Extrai todos os elementos
divcom a classequoteusando o seletor CSS".quote". - Itera sobre cada elemento
de citaçãopara extrair o nome, o autor e a tag de cada citação.
Muito bem! A lógica de raspagem do Scrapy Splash está completa.
Etapa nº 6: Junte tudo e execute o script
É assim que o arquivo words.py final deve se parecer:
import scrapy
from scrapy_splash import SplashRequest
# Lua script for JavaScript rendering
script = """
function main(splash, args)
splash:go(args.url)
return splash:html()
end
"""
class WordsSpider(scrapy.Spider):
name = "words"
start_urls = ["https://quotes.toscrape.com/scroll"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script}
)
def parse(self, response):
quotes = response.css(".quote")
for quote in quotes:
yield {
"text": quote.css(".text::text").get(),
"author": quote.css(".author::text").get(),
"tags": quote.css(".tags a.tag::text").getall()
}Execute o script com este comando:
scrapy crawl wordsEsse é o resultado esperado:
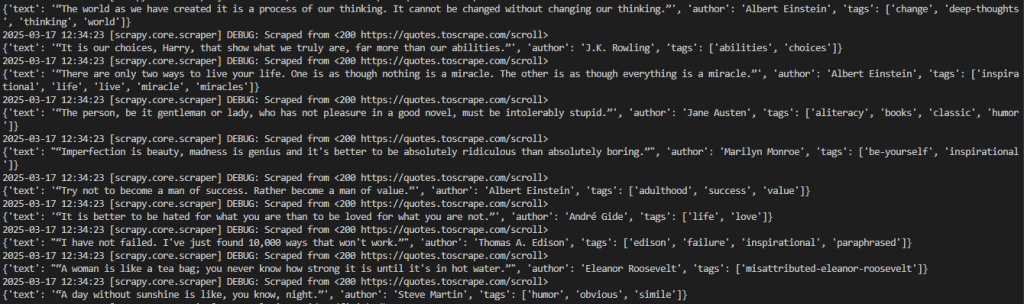
O resultado desejado pode ser melhor visualizado da seguinte forma:
2026-03-18 12:21:55 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/scroll>
{'text': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”', 'author': 'Albert Einstein', 'tags': ['change', 'deep-thoughts', 'thinking', 'world']}
2026-03-18 12:21:55 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/scroll>
{'text': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”', 'author': 'J.K. Rowling', 'tags': ['abilities', 'choices']}
# omitted for brevity...
2026-03-18 12:21:55 [scrapy.core.engine] INFO: Closing spider (finished)Observe que a saída contém os dados de interesse.
Observe que se você remover o método start_requests() da classe Words``Spider, o Scrapy não retornará nenhum dado. Isso ocorre porque, sem o Splash, ele não pode renderizar páginas que exigem JavaScript.
Muito bom! Você concluiu seu primeiro projeto Scrapy Splash.
Uma observação sobre respingos
O Splash é um servidor que se comunica por HTTP. Isso permite que você extraia páginas da Web com o Splash usando qualquer cliente HTTP, chamando seus pontos de extremidade. Os pontos de extremidade que ele fornece são:
execute: Executa um script de renderização Lua personalizado e retorna seu resultado.render.html: Retorna o HTML da página renderizada por javascript.render.png: Retorna uma imagem (no formato PNG) da página renderizada por javascript.render.jpeg: Retorna uma imagem (no formato JPEG) da página renderizada por javascript.render.har: Retorna informações sobre a interação do Splash com um site no formato HAR.render.json: Retorna um dicionário codificado em JSON com informações sobre a página da Web renderizada por javascript. Ele pode incluir HTML, PNG e outras informações, com base nos argumentos passados.
Para saber mais sobre como esses pontos de extremidade funcionam, considere o ponto de extremidade render.html. Conecte-se ao endpoint com este código Python:
# pip install requests
import requests
import json
# URL of the Splash endpoint
url = "http://localhost:8050/render.html"
# Sending a POST request to the Splash endpoint
payload = json.dumps({
"url": "https://quotes.toscrape.com/scroll" # URL of the page to render
})
headers = {
"content-type": "application/json"
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Esse snippet define:
- A instância do Splash no localhost como o URL que faz uma chamada para o ponto de extremidade
render.html. - A página de destino a ser raspada dentro da
carga útil.
Execute o código acima e você obterá o HTML renderizado de toda a página:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Quotes to Scrape</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>Embora o Splash possa lidar com HTML renderizado em JavaScript de forma independente, o uso do Scrapy Splash com o SplashRequest facilita muito a raspagem da Web.
Scrapy Splash: técnicas avançadas de raspagem
No parágrafo anterior, você concluiu um tutorial básico do Scrapy com a integração do Splash. É hora de experimentar algumas técnicas avançadas de raspagem com o Scrapy Splash!
Gerenciando a rolagem avançada
A página de destino contém citações que são carregadas dinamicamente via AJAX graças à rolagem infinita:
Para gerenciar a interação com a rolagem infinita, é necessário alterar o script Lua da seguinte forma:
script = """
function main(splash, args)
local scroll_delay = 1.0 -- Time to wait between scrolls
local max_scrolls = 10 -- Maximum number of scrolls to perform
local scroll_to = 1000 -- Pixels to scroll down each time
splash:go(args.url)
splash:wait(scroll_delay)
local scroll_count = 0
while scroll_count < max_scrolls do
scroll_count = scroll_count + 1
splash:runjs("window.scrollBy(0, " .. scroll_to .. ");")
splash:wait(scroll_delay)
end
return splash:html()
end
"""Esse script modificado se baseia nessas variáveis:
max_scrollsdefine o número máximo de rolagens a serem executadas. Esse valor pode precisar ser alterado com base na quantidade de conteúdo que você deseja extrair da página.scroll_toespecifica o número de pixels a serem rolados para baixo a cada vez. Seu valor pode precisar ser ajustado, dependendo do comportamento da página.splash:runjs()executa a função JavaScriptwindow.scrollBy()para rolar a página para baixo pelo número especificado de pixels.splash:wait()garante que o script aguarde antes de carregar o novo conteúdo. O tempo de espera (em segundos) é definido pela variávelscroll_delay.
Em termos mais simples, o script Lua acima simula um número definido de rolagens em um cenário de página da Web de rolagem infinita.
O código no arquivo words.py terá a seguinte aparência:
import scrapy
from scrapy_splash import SplashRequest
# Lua script for infinite scrolling
script = """
function main(splash, args)
local scroll_delay = 1.0 -- Time to wait between scrolls
local max_scrolls = 10 -- Maximum number of scrolls to perform
local scroll_to = 1000 -- Pixels to scroll down each time
splash:go(args.url)
splash:wait(scroll_delay)
local scroll_count = 0
while scroll_count < max_scrolls do
scroll_count = scroll_count + 1
splash:runjs("window.scrollBy(0, " .. scroll_to .. ");")
splash:wait(scroll_delay)
end
return splash:html()
end
"""
class WordsSpider(scrapy.Spider):
name = "words"
start_urls = ["https://quotes.toscrape.com/scroll"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script}
)
def parse(self, response):
# Retrieve CSS selectors
quotes = response.css("div.quote")
for quote in quotes:
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("span small.author::text").get(),
"tags": quote.css("div.tags a.tag::text").getall()
}Execute o script usando o comando abaixo:
scrapy crawl wordsO rastreador imprimirá todas as citações extraídas de forma consistente com a variável max_scrolls. Esse é o resultado esperado:
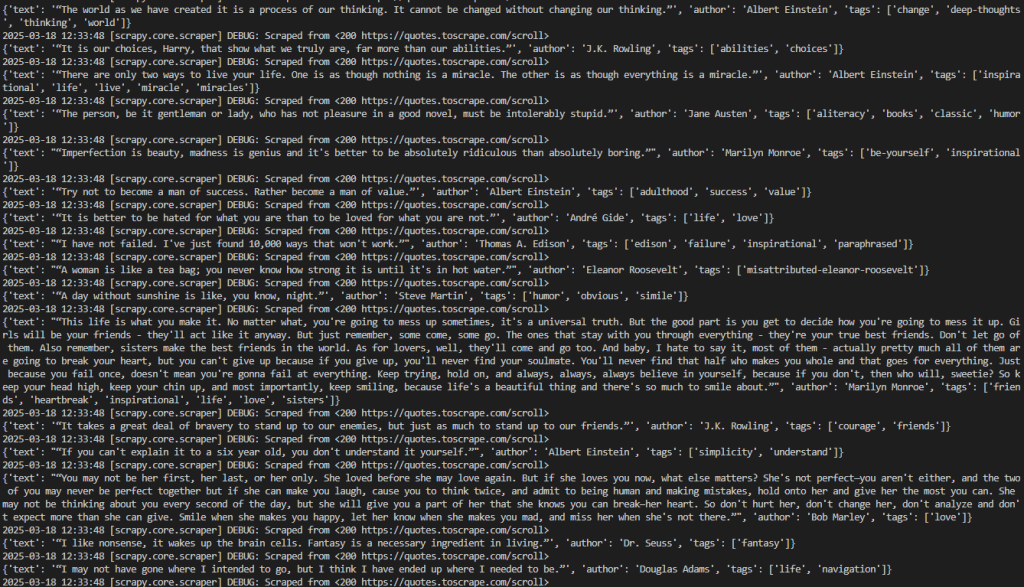
Observe que o resultado agora inclui muito mais citações do que antes. Isso confirma que as páginas foram roladas para baixo com sucesso e que novos dados foram carregados e extraídos.
Perfeito! Agora você aprendeu a gerenciar a rolagem infinita com o Scrapy Splash.
Esperar pelo elemento
As páginas da Web podem recuperar dados dinamicamente ou renderizar nós no navegador. Isso significa que o DOM final pode levar algum tempo para ser renderizado. Para evitar erros ao recuperar dados de um site, você deve sempre esperar que um elemento seja carregado na página antes de interagir com ele.
Neste exemplo, o elemento a ser aguardado será o texto da primeira citação:

Para implementar a lógica de espera, escreva um script Lua da seguinte forma:
script = """
function main(splash, args)
splash:go(args.url)
while not splash:select(".text") do
splash:wait(0.2)
print("waiting...")
end
return { html=splash:html() }
end
"""Esse script cria um loop while que aguarda 0,2 segundos se o elemento de texto estiver na página. Para verificar se o elemento .text está na página, você pode usar o método splash:select().
Esperar pelo tempo
Como as páginas da Web com conteúdo dinâmico levam tempo para serem carregadas e renderizadas, é possível aguardar alguns segundos antes de acessar o conteúdo HTML. Isso pode ser feito por meio do método splash:wait() da seguinte forma:
script = """
function main(splash, args)
splash:wait(args.wait)
splash:go(args.url)
return { html=splash:html() }
end
"""Nesse caso, os segundos que o script deve esperar são expressos no método SplashRequest() com um argumento de script Lua.
Por exemplo, defina"wait" : 2.0 para dizer ao script Lua para esperar 2 segundos:
import scrapy
from scrapy_splash import SplashRequest
script = """
function main(splash, args)
splash:wait(args.wait)
splash:go(args.url)
return { html=splash:html() }
end
"""
class WordsSpider(scrapy.Spider):
name = "words"
start_urls = ["https://quotes.toscrape.com/scroll"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script, "wait": 2.0} # Waiting for 2 seconds
)
# ...Observação: uma espera rígida(splash:wait()) é útil para testes locais, pois garante que a página seja carregada antes de prosseguir. Essa abordagem não é ideal para produção, pois adiciona atrasos desnecessários, prejudicando o desempenho e a escalabilidade. Além disso, não é possível saber com antecedência o tempo certo de espera.
Muito bem! Você aprendeu a esperar um determinado período de tempo no Scrapy Splash.
Limitações do uso do Scrapy Splash
Neste tutorial, você aprendeu a usar o Scrapy Splash para extrair dados da Web em diferentes cenários. Embora essa integração seja simples, ela tem algumas desvantagens.
Por exemplo, a configuração do Splash exige a execução de um servidor Splash separado com o Docker, o que aumenta a complexidade da sua infraestrutura de raspagem. Além disso, a API de script Lua do Splash é um pouco limitada em comparação com ferramentas mais modernas, como Puppeteer e Playwright.
Entretanto, como em todos os navegadores sem cabeça, a maior limitação vem do próprio navegador. As tecnologias antirrastreamento podem detectar quando um navegador está sendo automatizado em vez de usado normalmente, levando a bloqueios de script.
Esqueça esses desafios com o Scraping Browser, umnavegador de raspagem dedicado baseado em nuvem, projetado para escalabilidade infinita. Ele inclui a solução de CAPTCHA, o gerenciamento de impressões digitais do navegador e o desvio de anti-bot, para que você não precise se preocupar em ser bloqueado.
Conclusão
Neste artigo, você aprendeu o que é o Scrapy Splash e como ele funciona. Você começou com os conceitos básicos e, em seguida, explorou cenários de raspagem mais complexos.
Você também descobriu as limitações da ferramenta, principalmente sua vulnerabilidade a sistemas anti-bot e anti-raspagem. Para superar esses desafios, o Scraping Browser é uma excelente solução. Essa é apenas uma das muitas soluções de coleta de dados da Bright Data que você pode experimentar:
- Serviços de proxy: Quatro tipos diferentes de proxies para contornar restrições de localização, incluindo mais de 150 milhões de IPs residenciais
- APIs do Web Scraper: Pontos de extremidade dedicados para extrair dados da Web novos e estruturados de mais de 100 domínios populares.
- API SERP: API para lidar com todo o gerenciamento de desbloqueio contínuo para SERP e extrair uma página
Inscreva-se agora na Bright Data e comece sua avaliação gratuita para testar nossas soluções de raspagem.





