

Neste guia de raspagem da Web da Goutte, você aprenderá:
- O que é a biblioteca PHP Goutte
- Como usá-lo para raspagem da Web em um tutorial passo a passo
- Alternativas ao Goutte para raspagem da Web
- As limitações dessa abordagem e as possíveis soluções
Vamos mergulhar de cabeça!
O que é Goutte?
Goutte é uma biblioteca PHP para raspagem de tela e rastreamento da Web, oferecendo uma API intuitiva para navegar em sites e extrair dados de respostas HTML/XML. Ela inclui um cliente HTTP integrado e recursos de análise de HTML, permitindo que você recupere páginas da Web por meio de solicitações HTTP e as processe para raspagem de dados.
Observação: a partir de 1º de abril de 2023, o Goutte não é mais mantido e agora é considerado obsoleto. No entanto, até o momento em que este texto foi escrito, ele ainda funciona de forma confiável.
Como realizar a raspagem da Web com o Goutte: guia passo a passo
Siga esta seção do tutorial passo a passo e veja como usar o Goutte para extrair dados do site “Hockey Teams“:
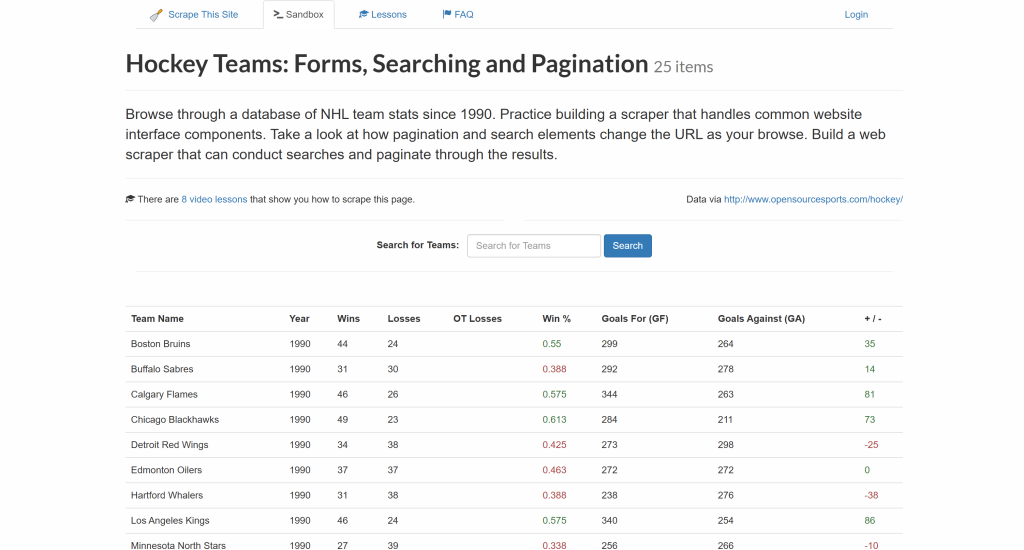
O objetivo é extrair os dados da tabela acima e exportá-los para um arquivo CSV.
Chegou a hora de aprender a realizar a coleta de dados da Web com o Goutte!
Etapa 1: Configuração do projeto
Antes de começar, certifique-se de que seu sistema atenda aos requisitos do Goutte – PHP7.1 ou superior. Para verificar sua versão atual do PHP, execute o seguinte comando:
php -vO resultado deve ser semelhante a este:
PHP 8.4.3 (cli) (built: Jan 19 2026 14:20:58) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.4.3, Copyright (c) Zend Technologies
with Zend OPcache v8.4.3, Copyright (c), by Zend TechnologiesSe a sua versão do PHP for inferior à 7.1, você precisará atualizá-la antes de continuar.
Em seguida, lembre-se de que o Goutte será instalado por meio do Composer, um gerenciador de dependências para PHP. Se o Composer não estiver instalado em seu sistema, faça o download no site oficial e siga as instruções de instalação.
Agora, crie um novo diretório para seu projeto Goutte e navegue até ele no terminal:
mkdir goutte-parser
cd goutte-parserEm seguida, use o comando composer init para inicializar um projeto do Composer dentro da pasta:
composer initO Composer solicitará que você insira detalhes do projeto, como nome e descrição do pacote. As respostas padrão funcionarão, mas fique à vontade para personalizá-las de acordo com seus objetivos.
Agora, abra a pasta do projeto em seu IDE PHP favorito. O Visual Studio Code com a extensão PHP ou o IntelliJ WebStorm são boas opções.
Crie um arquivo index.php vazio na pasta do projeto, que deve conter:
php-html-parser/
├── vendor/
├── composer.json
└── index.phpAbra o index.php e adicione a seguinte linha de código para importar as bibliotecas do Composer:
<?php
require_once __DIR__ . "/vendor/autoload.php";
// scraping logic...Em breve, esse arquivo conterá a lógica de raspagem da Goutte.
Agora você pode executar seu script usando esse comando:
php index.phpMuito bom! Você está pronto para começar a extrair dados com o Goutte em PHP.
Etapa 2: Instalar e configurar o Goutte
Instale o Goutte com o comando Compose abaixo:
composer require fabpot/goutteIsso adicionará a dependência do fabpot/goutte ao seu arquivo composer.json, que agora incluirá:
"require": {
"fabpot/goutte": "^4.0"
}Em index.php, importe o Goutte adicionando a seguinte linha de código:
use GoutteClient;Isso expõe o cliente HTTP da Goutte que você pode usar para se conectar a uma página de destino, analisar seu HTML e extrair dados dela. Veja como fazer isso na próxima etapa!
Etapa 3: obtenha o HTML da página de destino
Primeiro, crie um novo cliente Goutte HTTP:
$client = new Client();Nos bastidores, a classe Client do Goutte é simplesmente um invólucro do componente BrowserKitHttpBrowser do Symfony. Veja-o em ação em nosso guia sobre coleta de dados da Web com o Laravel.
Em seguida, armazene o URL da página da Web de destino em uma variável e use o método request() para buscar seu conteúdo:
$url = "https://www.scrapethissite.com/pages/forms/";
$crawler = $client->request("GET", $url);Isso envia uma solicitação GET para a página da Web, recupera o documento HTML e o analisa para você. Especificamente, o objeto $crawler fornece acesso a todos os métodos do componente DomCrawler do Symfony. $crawler é o objeto que você usará para navegar e extrair dados da página.
Incrível! Agora você tem tudo o que precisa para a coleta de dados da Web do Goutte.
Etapa 4: Prepare-se para extrair os dados de interesse
Antes de extrair dados, você deve se familiarizar com a estrutura HTML da página de destino.
Primeiro, lembre-se de que os dados de interesse são apresentados em linhas dentro de uma tabela. Como essa tabela contém várias linhas, uma matriz é uma ótima estrutura de dados para armazenar os dados extraídos:
$teams = [];Agora, concentre-se na estrutura HTML da tabela. Visite a página de destino em seu navegador, clique com o botão direito do mouse na tabela que contém os dados de interesse e selecione a opção “Inspect” (Inspecionar):
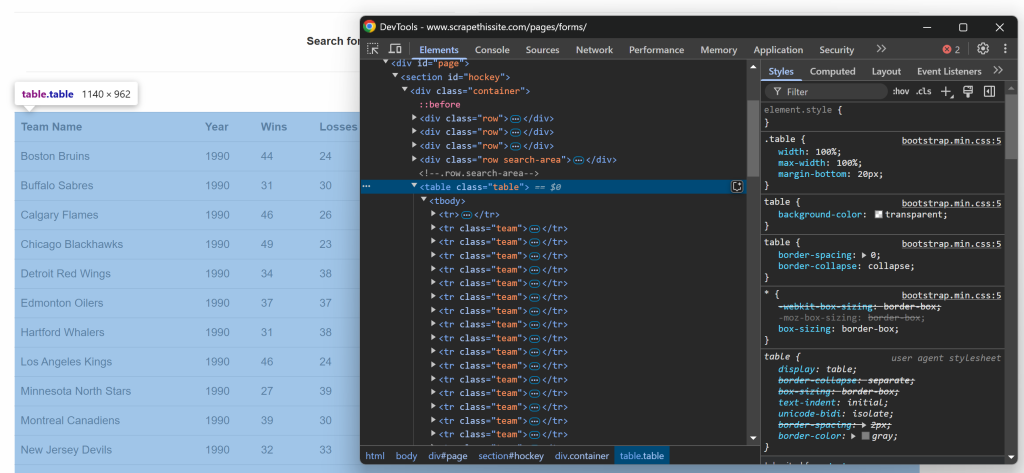
No DevTools, você verá que a tabela tem uma classe de tabela e está contida em um elemento
id=``"``hockey``". Isso significa que você pode direcionar a tabela usando o seguinte seletor CSS:
#hockey .tableAplique o seletor CSS para selecionar o nó da tabela usando o método $crawler->filter():
$table = $crawler->filter("#hockey .table");Em seguida, observe que cada linha é representada por um elemento
team. Selecione todas as linhas e itere sobre elas, preparando-se para extrair dados delas:
$table->filter("tr.team")->each(function ($tr) use (&$teams) {
// data extraction logic...
});Maravilhoso! Agora você tem um esqueleto pronto para a coleta de dados do Goutte.
Etapa nº 5: implementar a lógica de extração de dados
Assim como antes, desta vez inspecione as linhas dentro da tabela:
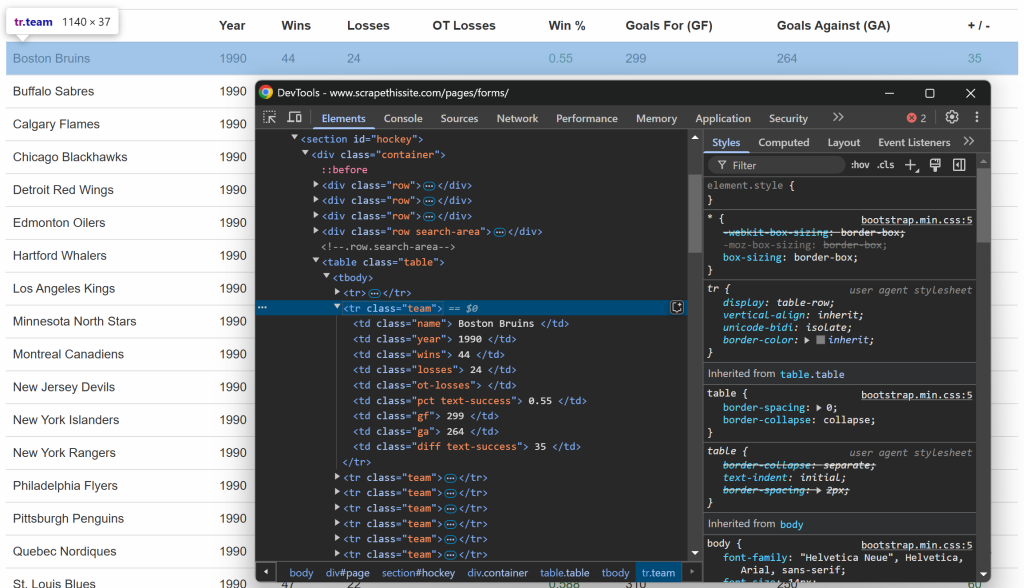
O que você pode notar é que cada linha contém as seguintes informações em colunas dedicadas:
- Nome da equipe → dentro do elemento
.name - Ano da estação → dentro do elemento
.year - Número de vitórias → dentro do elemento
.wins - Número de perdas → dentro do elemento
.losses - Perdas com horas extras → dentro do elemento
.ot-losses - Porcentagem de vitórias → dentro do elemento
.pct - Gols marcados (Goals For – GF) → dentro do elemento
.gf - Gols sofridos (Gols contra – GA) → dentro do elemento
.ga - Diferença de gols → dentro do elemento
.diff
Para recuperar uma única informação, você precisa aplicar essas duas etapas:
- Selecione o elemento HTML usando
filter() - Extraia seu conteúdo de texto usando o método
text()e remova todos os espaços extras comtrim()
Por exemplo, você pode extrair o nome da equipe com:
$teamElement = $tr->filter(".name");
$team = trim($teamElement->text());Da mesma forma, estenda essa lógica a todas as outras colunas:
$yearElement = $tr->filter(".year");
$year = trim($yearElement->text());
$winsElement = $tr->filter(".wins");
$wins = trim($winsElement->text());
$lossesElement = $tr->filter(".losses");
$losses = trim($lossesElement->text());
$otLossesElement = $tr->filter(".ot-losses");
$otLosses = trim($otLossesElement->text());
$pctElement = $tr->filter(".pct");
$pct = trim($pctElement->text());
$gfElement = $tr->filter(".gf");
$gf = trim($gfElement->text());
$gaElement = $tr->filter(".ga");
$ga = trim($gaElement->text());
$diffElement = $tr->filter(".diff");
$diff = trim($diffElement->text());Depois de extrair os dados de interesse da linha, armazene-os na matriz $teams:
$teams[] = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"ot_losses" => $otLosses,
"win_perc" => $pct,
"goals_for" => $gf,
"goals_against" => $ga,
"goal_diff" => $diff
];Depois de percorrer todas as linhas, o array $teams conterá:
Array
(
[0] => Array
(
[team] => Boston Bruins
[year] => 1990
[wins] => 44
[losses] => 24
[ot_losses] =>
[win_perc] => 0.55
[goals_for] => 299
[goals_against] => 264
[goal_diff] => 35
)
// ...
[24] => Array
(
[team] => Chicago Blackhawks
[year] => 1991
[wins] => 36
[losses] => 29
[ot_losses] =>
[win_perc] => 0.45
[goals_for] => 257
[goals_against] => 236
[goal_diff] => 21
)
)Excelente! A raspagem de dados da Goutte foi realizada com sucesso.
Etapa nº 6: implementar a lógica de rastreamento
Agora, não se esqueça de que o site de destino apresenta dados em várias páginas, mostrando apenas uma parte de cada vez. Abaixo da tabela, há um elemento de paginação que fornece links para todas as páginas:

Portanto, você pode gerenciar a paginação em seu script de raspagem com estas etapas simples:
- Selecione os elementos do link de paginação
- Extrair os URLs das páginas paginadas
- Visite cada página e aplique a lógica de raspagem desenvolvida anteriormente
Comece inspecionando os elementos do link de paginação:
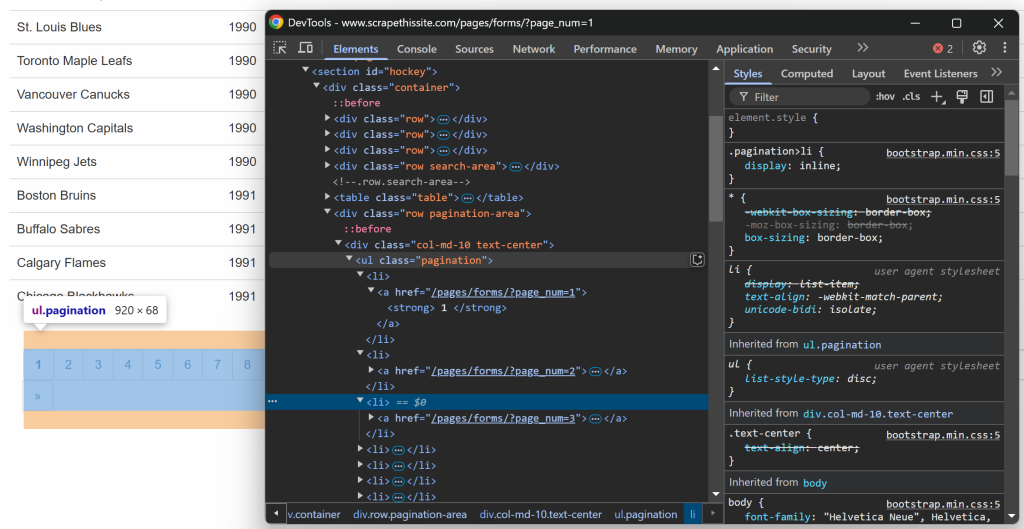
Observe que você pode selecionar todos os links de paginação usando o seletor CSS a seguir:
.pagination li aPara implementar a etapa 2 e coletar todos os URLs de paginação, use esta lógica:
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});Isso inicializa uma lista de URLs que armazenará os links de paginação, começando com o URL da primeira página. Em seguida, seleciona todos os elementos de paginação e itera sobre eles, adicionando novos URLs à matriz $urls somente se eles ainda não estiverem presentes. Como os URLs na página são relativos, eles devem ser convertidos em URLs absolutos antes de serem adicionados à lista.
Como o tratamento da paginação só deve ser executado uma vez e não está diretamente ligado à extração de dados, é melhor envolvê-lo em uma função:
function getPaginationUrls($client, $url)
{
// connect to the first page of the site
$crawler = $client->request("GET", $url);
// initialize the list of URLs to scrape with the current URL
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});
return $urls;
}Você pode chamar a função getPaginationUrls() da seguinte forma:
$urls = getPaginationUrls($client, "https://www.scrapethissite.com/pages/forms/?page_num=1");Após a execução, $urls conterá todas as URLs paginadas:
Array
(
[0] => https://www.scrapethissite.com/pages/forms/?page_num=1
[1] => https://www.scrapethissite.com/pages/forms/?page_num=2
[2] => https://www.scrapethissite.com/pages/forms/?page_num=3
[3] => https://www.scrapethissite.com/pages/forms/?page_num=4
[4] => https://www.scrapethissite.com/pages/forms/?page_num=5
[5] => https://www.scrapethissite.com/pages/forms/?page_num=6
[6] => https://www.scrapethissite.com/pages/forms/?page_num=7
[7] => https://www.scrapethissite.com/pages/forms/?page_num=8
[8] => https://www.scrapethissite.com/pages/forms/?page_num=9
[9] => https://www.scrapethissite.com/pages/forms/?page_num=10
[10] => https://www.scrapethissite.com/pages/forms/?page_num=11
[11] => https://www.scrapethissite.com/pages/forms/?page_num=12
[12] => https://www.scrapethissite.com/pages/forms/?page_num=13
[13] => https://www.scrapethissite.com/pages/forms/?page_num=14
[14] => https://www.scrapethissite.com/pages/forms/?page_num=15
[15] => https://www.scrapethissite.com/pages/forms/?page_num=16
[16] => https://www.scrapethissite.com/pages/forms/?page_num=17
[17] => https://www.scrapethissite.com/pages/forms/?page_num=18
[18] => https://www.scrapethissite.com/pages/forms/?page_num=19
[19] => https://www.scrapethissite.com/pages/forms/?page_num=20
[20] => https://www.scrapethissite.com/pages/forms/?page_num=21
[21] => https://www.scrapethissite.com/pages/forms/?page_num=22
[22] => https://www.scrapethissite.com/pages/forms/?page_num=23
[23] => https://www.scrapethissite.com/pages/forms/?page_num=24
)Perfeito! Você acabou de implementar o rastreamento da Web no Goutte.
Etapa nº 7: Extraia dados de todas as páginas
Agora que você tem todos os URLs de página armazenados em uma matriz, pode extraí-los um a um:
- Iteração sobre a lista
- Recuperação e análise do conteúdo HTML de cada URL
- Extração dos dados necessários
- Armazenamento das informações extraídas na matriz
$teams.
Implemente a lógica acima da seguinte forma:
$teams = [];
// iterate over all pages and scrape them all
foreach ($urls as $_ => $url) {
// logging which page the scraper is currently working on
echo "Scraping webpage "$url"...n";
// retrieve the HTML of the current page and parse it
$crawler = $client->request("GET", $url);
// $table = $crawler-> ...
// data extraction logic
}Observe a instrução echo para registrar a página atual em que o scraper está operando. Essa informação é útil para entender o que o script está fazendo durante a execução.
Que lindo! Só falta exportar os dados extraídos para um formato legível por humanos, como CSV.
Etapa 8: Exportar os dados extraídos para CSV
No momento, os dados extraídos são armazenados na matriz $teams. Para torná-los acessíveis a outras equipes e mais fáceis de analisar, exporte-os para um arquivo CSV.
O PHP oferece suporte integrado para exportação de CSV por meio da função fputcsv(). Use-a para gravar os dados extraídos em um arquivo chamado teams.csv, conforme abaixo:
// open the output file for writing
$file = fopen("teams.csv", "w");
// write the header row
fputcsv($file, ["Team Name", "Year", "Wins", "Losses", "OT Losses", "Win %","Goals For (GF)", "Goals Against (GA)", "+ / -"]);
// append each team as a new row
foreach ($teams as $team) {
fputcsv($file, [
$team["team"],
$team["year"],
$team["wins"],
$team["losses"],
$team["ot_losses"],
$team["win_perc"],
$team["goals_for"],
$team["goals_against"],
$team["goal_diff"]
]);
}
// close the file
fclose($file);Missão concluída! O raspador Goutte está totalmente funcional.
Etapa nº 9: Juntar tudo
Seu script de raspagem da Web do Goutte deve conter agora:
<?php
require_once __DIR__ . "/vendor/autoload.php";
use GoutteClient;
function getPaginationUrls($client, $url)
{
// connect to the first page of the site
$crawler = $client->request("GET", $url);
// initialize the list of URLs to scrape with the current URL
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});
return $urls;
}
// initialize a new Goutte HTTP client
$client = new Client();
// get the URLs of the pages to scrape
$urls = getPaginationUrls($client, "https://www.scrapethissite.com/pages/forms/?page_num=1");
// where to store the scraped data
$teams = [];
// iterate over all pages and scrape them all
foreach ($urls as $_ => $url) {
// logging which page the scraper is currently working on
echo "Scraping webpage "$url"...n";
// retrieve the HTML of the current page and parse it
$crawler = $client->request("GET", $url);
// select the table element with the data of interest
$table = $crawler->filter("#hockey .table");
// iterate over each row and extract data from them
$table->filter("tr.team")->each(function ($tr) use (&$teams) {
// data extraction logic
$teamElement = $tr->filter(".name");
$team = trim($teamElement->text());
$yearElement = $tr->filter(".year");
$year = trim($yearElement->text());
$winsElement = $tr->filter(".wins");
$wins = trim($winsElement->text());
$lossesElement = $tr->filter(".losses");
$losses = trim($lossesElement->text());
$otLossesElement = $tr->filter(".ot-losses");
$otLosses = trim($otLossesElement->text());
$pctElement = $tr->filter(".pct");
$pct = trim($pctElement->text());
$gfElement = $tr->filter(".gf");
$gf = trim($gfElement->text());
$gaElement = $tr->filter(".ga");
$ga = trim($gaElement->text());
$diffElement = $tr->filter(".diff");
$diff = trim($diffElement->text());
// add the scraped data to the array
$teams[] = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"ot_losses" => $otLosses,
"win_perc" => $pct,
"goals_for" => $gf,
"goals_against" => $ga,
"goal_diff" => $diff
];
});
}
// open the output file for writing
$file = fopen("teams.csv", "w");
// write the header row
fputcsv($file, ["Team Name", "Year", "Wins", "Losses", "OT Losses", "Win %","Goals For (GF)", "Goals Against (GA)", "+ / -"]);
// append each team as a new row
foreach ($teams as $team) {
fputcsv($file, [
$team["team"],
$team["year"],
$team["wins"],
$team["losses"],
$team["ot_losses"],
$team["win_perc"],
$team["goals_for"],
$team["goals_against"],
$team["goal_diff"]
]);
}
// close the file
fclose($file);Inicie-o com este comando:
php index.phpO raspador registraria a seguinte saída:
Scraping webpage "https://www.scrapethissite.com/pages/forms/?page_num=1"...
// omitted for brevity..
Scraping webpage "https://www.scrapethissite.com/pages/forms/?page_num=24"...No final da execução, um arquivo teams.csv contendo esses dados aparecerá na pasta do projeto:
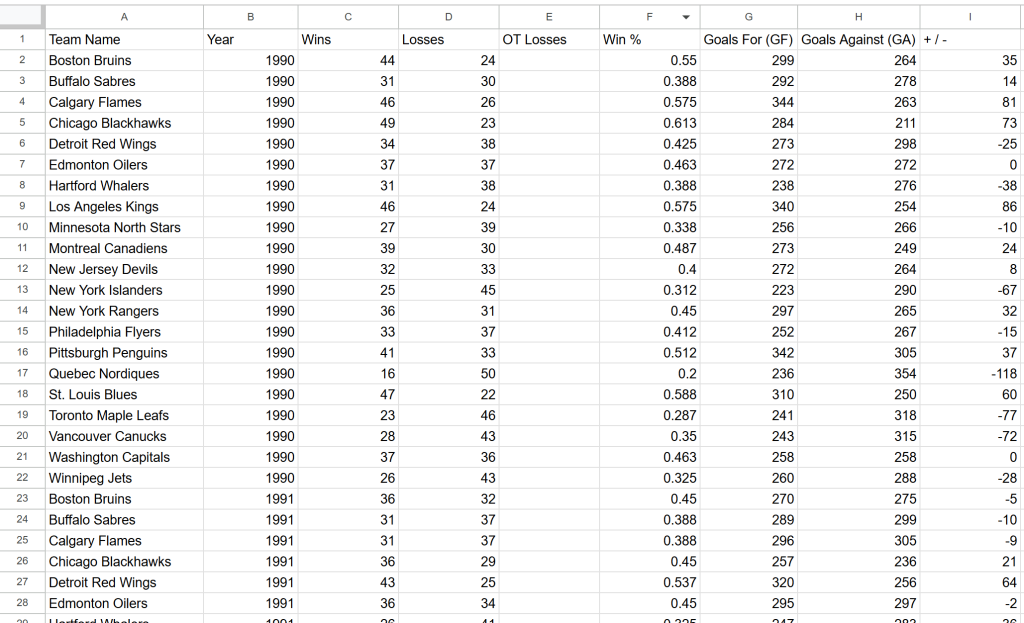
E pronto! Os dados exatos do site de destino agora estão disponíveis em um formato estruturado.
Alternativas à biblioteca PHP Goutte para raspagem da Web
Conforme mencionado no início deste artigo, o Goutte está obsoleto e não é mais mantido. Isso significa que você deve considerar soluções alternativas.
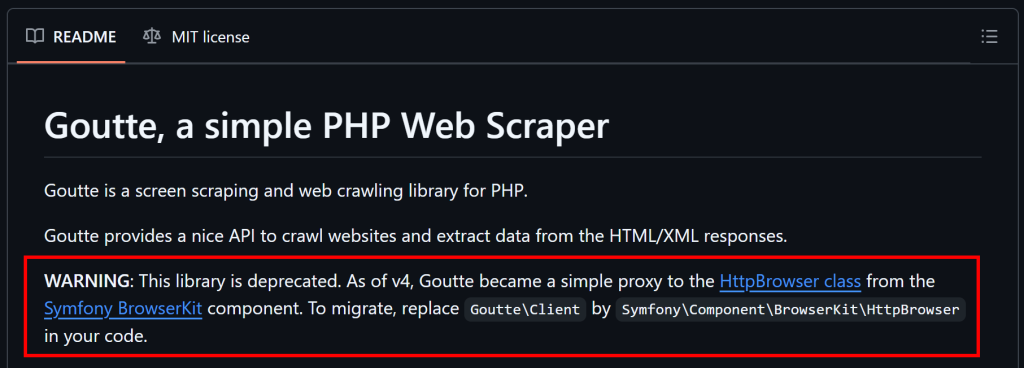
Conforme explicado no GitHub, como o Goutte v4 se tornou essencialmente um proxy para a classe HttpBrowser do Symfony, você deve migrar para ele. Para isso, você só precisa instalar essas bibliotecas:
composer require symfony/browser-kit symfony/http-clientEm seguida, substitua:
use GoutteClient;com
use SymfonyComponentBrowserKitHttpBrowser;Por fim, remova o Goutte como uma dependência em seu projeto. A API subjacente permanece a mesma, portanto, você não deve precisar alterar muito em seu script.
Em vez do Goutte, você também pode combinar um cliente HTTP com um analisador de HTML. Algumas alternativas recomendadas:
- Guzzle ou cURL para fazer solicitações HTTP.
DomHTMLDocument, Simple HTML DOM Parser ouDomCrawlerpara analisar HTML em PHP.
Todas essas alternativas oferecem mais flexibilidade e garantem que seu script de raspagem da Web permaneça sustentável a longo prazo.
Limitações dessa abordagem de raspagem da Web
O Goutte é uma ferramenta avançada, mas seu uso para raspagem da Web tem várias limitações:
- A biblioteca está obsoleta
- Sua API não é mais mantida
- Ele está sujeito a limitadores de taxa e bloqueios antirrastreamento
- Ele não pode lidar com páginas dinâmicas que dependem de JavaScript
- Ele tem suporte limitado a proxy integrado, o que é essencial para evitar proibições de IP
Algumas dessas limitações podem ser atenuadas com o uso de bibliotecas alternativas ou abordagens diferentes, conforme abordado em nosso guia sobre raspagem da Web com PHP. Ainda assim, você sempre enfrentará medidas antirrastreamento que só podem ser contornadas usando uma API do Web Unlocker.
Uma API do Web Unlocker é um ponto de extremidade de raspagem especializado, projetado para contornar as proteções antibot e recuperar o HTML bruto de qualquer página da Web. Usá-la é tão simples quanto fazer uma chamada à API e analisar o conteúdo retornado. Essa abordagem se integra perfeitamente ao Goutte (ou aos componentes atualizados do Symfony), conforme demonstrado neste artigo.
Conclusão
Neste guia, você explorou o que é o Goutte e o que ele oferece para raspagem da Web por meio de um tutorial passo a passo. Como essa biblioteca está obsoleta, você também teve a oportunidade de explorar algumas de suas alternativas.
Independentemente da biblioteca de raspagem PHP que você escolher, o maior desafio é que a maioria dos sites protege seus dados usando tecnologias anti-bot e anti-raspagem. Esses mecanismos podem detectar e bloquear solicitações automatizadas, tornando ineficazes os métodos tradicionais de raspagem.
Felizmente, a Bright Data oferece um conjunto de soluções para evitar qualquer problema:
- Web Unlocker: Uma API que contorna as proteções antirrastreamento e fornece HTML limpo de qualquer página da Web com o mínimo de esforço.
- Navegador de raspagem: Um navegador controlável e baseado em nuvem com renderização de JavaScript. Ele lida automaticamente com CAPTCHAs, impressão digital do navegador, novas tentativas e muito mais para você. Integra-se perfeitamente ao Panther ou ao Selenium PHP.
- APIs de raspagem da Web: Endpoints para acesso programático a dados estruturados da Web de dezenas de domínios populares.
Não quer lidar com raspagem da Web, mas ainda está interessado em “dados on-line da Web”? Explore nossos conjuntos de dados prontos para uso!
Inscreva-se agora na Bright Data e comece sua avaliação gratuita para testar nossas soluções de raspagem.






