

O Scraping de dados é uma técnica que envolve a extração e coleta automática de dados de sites usando ferramentas ou programas especializados. É particularmente valioso para empresas que buscam melhorar seus processos de tomada de decisão baseados em dados.
No entanto, devido às complexas estruturas HTML, ao conteúdo dinâmico e aos diversos formatos de dados encontrados na maioria dos sites, a eficácia do Scraping de dados depende das ferramentas utilizadas.
O Scrapy e o Selenium são ferramentas poderosas projetadas para facilitar o Scraping de dados. O Scrapy extrai dados de sites estáticos, enquanto o Selenium pode realizar a automação do navegador da web e extrair dados de sites dinâmicos.
Neste artigo, você comparará as duas ferramentas com base em sua facilidade de uso, desempenho e escalabilidade, adequação para diferentes tipos de conteúdo da web e recursos de integração.
Facilidade de uso
O Scrapy é uma ferramenta de Scraping de dados baseada em Python que pode ser executada em Linux, Windows, macOS e Berkeley Software Distribution (BSD). Além de ser fácil de usar, o Scrapy também oferece uma API de alto nível para tarefas de Scraping de dados, o que pode ajudar a simplificar ainda mais o processo.
Para configurar o Scrapy, basta instalá-lo e configurar alguns spiders usando código Python (isso envolve algum conhecimento dos conceitos de Scraping de dados). Quando você executa um comando Scrapy para iniciar um projeto, ele gera uma pasta dedicada ao seu projeto. Dentro dessa pasta, você encontrará arquivos Python padrão, comoitems.py,pipelines.pye settings.py. Esses arquivos são organizados em uma estrutura simplificada, facilitando o início do Scraping de dados.
O Scrapy fornece documentação detalhada, incluindo artigos e vídeos selecionados para ajudar a responder a quaisquer perguntas que você possa ter. O Scrapy também tem um subreddit ativo e uma comunidade Discord onde você pode participar de diferentes discussões ou tópicos.
Em comparação, o Selenium oferece suporte a várias linguagens de programação, incluindo Java, JavaScript, Python e C#, e é compatível com muitos dos mesmos sistemas operacionais do Scrapy, incluindo Windows, macOS e Linux. Quando comparado ao Scrapy, o Selenium não é tão fácil de aprender e requer mais tempo, esforço e, às vezes, recursos antes que uma pessoa se torne proficiente.
Para configurar o Selenium, você precisa instalar a biblioteca Selenium e, em seguida, configurar os WebDrivers que lidam com a automação do navegador. Se você estiver coletando dados de um site dinâmico que exige login, será necessário configurar a automação da web para lidar com o processo de login antes de começar a coletar quaisquer dados.
O Selenium oferece um rico conjunto de métodos de navegação que você pode personalizar para localizar facilmente elementos em uma página da web. Além disso, ele oferece cadeias de ações interativas, incluindo cliques, cliques duplos, arrastar, soltar e rolar, que permitem uma interação sem esforço com as páginas da web.
A documentação oficial do Selenium inclui diretrizes impressionantes, instruções passo a passo e tutoriais relacionados à automação da web e ao Scraping de dados.
Como o Selenium é uma ferramenta mais genérica para automação da web, ele tem uma comunidade maior e mais diversificada. Se você tiver alguma dúvida ao trabalhar com o Selenium, o grupo oficial de usuários e a comunidade subreddit podem ajudar. Ou, se você tiver uma questão que precise de resposta imediata, pode utilizar a sala de bate-papo IRC.
Desempenho e escalabilidade
A eficácia do desempenho de qualquer ferramenta de Scraping de dados depende muito de sua velocidade, pois o objetivo é coletar uma quantidade significativa de dados rapidamente.
O Scrapy se destaca na extração de conteúdo de páginas da web estáticas, resultando em uma extração de dados mais rápida do que o Selenium. Isso ocorre porque o Selenium depende de instâncias do navegador para executar diferentes interações, como clicar em botões ou preencher formulários.
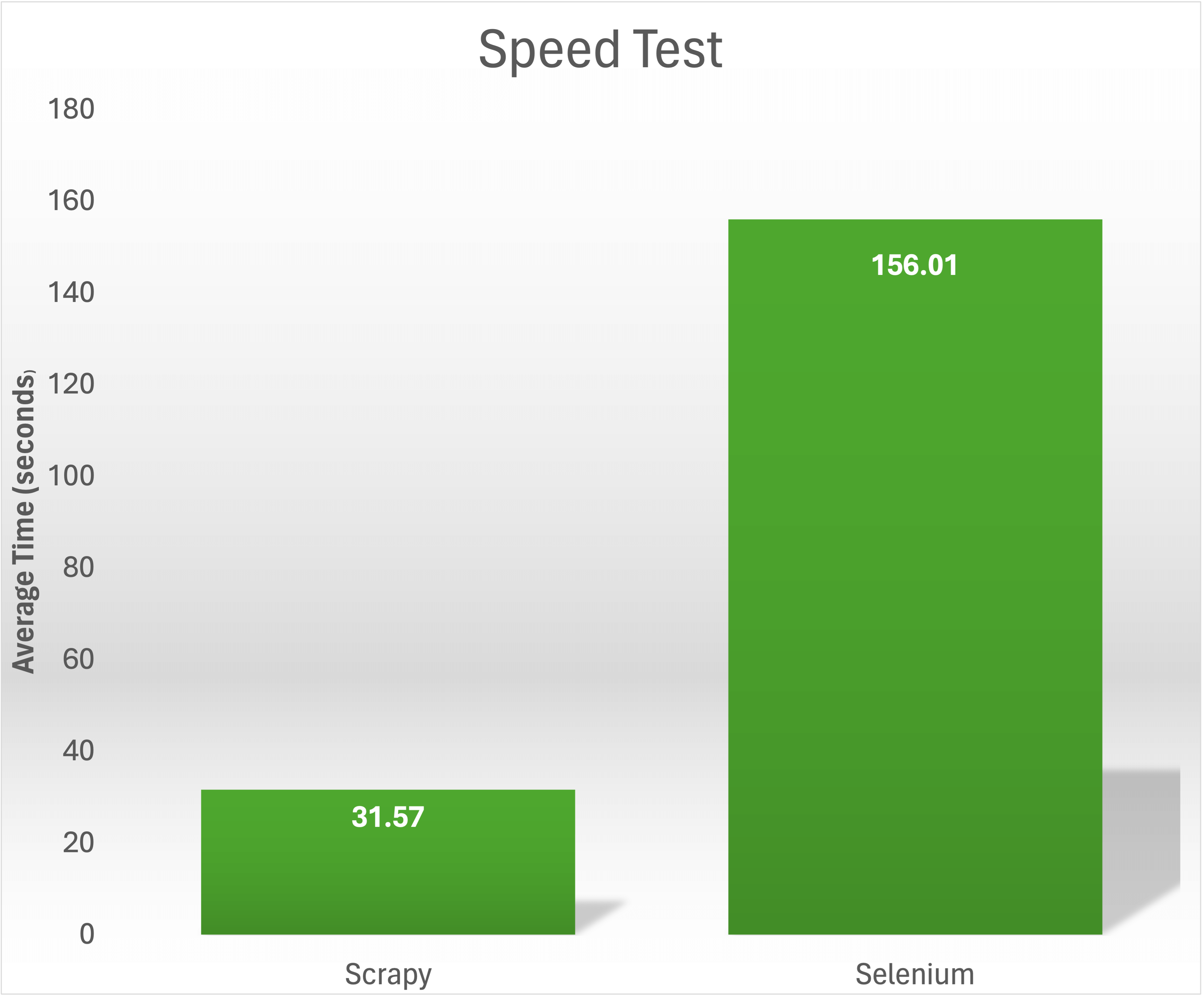
Em um teste de velocidade para coletar os títulos e preços de 1.000 livros do site https://books.toscrape.com/, o Scrapy conseguiu concluir a tarefa em 31,57 segundos. Em contrapartida, o Selenium levou em média 156,01 segundos para extrair o mesmo conteúdo:
A arquitetura do Scrapy lida com a memória de maneira eficiente, processando respostas e itens em um processo contínuo, evitando a necessidade de carregar páginas da web inteiras na memória de uma só vez. O Scrapy também possui suporte integrado para cache e extração incremental, o que melhora a escalabilidade, minimizando solicitações redundantes e processando apenas conteúdo novo ou atualizado.
Além disso, o Scrapy oferece opções para ajustar o uso da memória por meio de configurações como solicitações simultâneas, limites de profundidade e pipelines de itens. Esses recursos permitem otimizar o consumo de memória de acordo com os requisitos específicos do seu projeto de Scraping de dados.
O Selenium normalmente consome uma quantidade significativa de memória ao interagir com sites pesados em JavaScript, levando a um maior consumo de memória. Isso pode impactar negativamente sua escalabilidade e desempenho, especialmente em projetos de scraping em grande escala.
O middleware integrado do Scrapy, chamado HTTPCacheMiddleware, armazena em cache as solicitações feitas pelos spiders e suas respostas relacionadas. Você pode habilitar o cache adicionando o seguinte código aoarquivo settings.pydo seu projeto:
# Habilitar e configurar o cache HTTP (desabilitado por padrão)
HTTPCACHE_ENABLED = True
Dimensionar o Selenium para lidar com scraping de dados em grande escala requer a implantação de várias instâncias em sistemas distribuídos, levando a um aumento na demanda por recursos, como RAM e CPU.
Adequação para diferentes tipos de conteúdo da Web
A maioria dos sites na Internet apresenta páginas dinâmicas ou estáticas. Vamos dar uma olhada em como o Scrapy e o Selenium lidam com os dois tipos de páginas da Web.
Páginas da Web dinâmicas
A maioria das páginas dinâmicas é alimentada por frameworks JavaScript, como Angular e React, para atualizar o conteúdo sem recarregar a página inteira.
O Selenium pode extrair conteúdo dinâmico de vários sites, mas o Scrapy não oferece suporte inerente à extração de conteúdo dinâmico gerado por JavaScript. Você pode integrar o Scrapy a ferramentas como Selenium e Splash para obter essa funcionalidade.
Páginas da web estáticas
As páginas da web estáticas normalmente oferecem interação limitada em comparação com as dinâmicas, geralmente permitindo que os usuários apenas visualizem o conteúdo ou cliquem em links.
Como mencionado anteriormente, o Selenium pode extrair páginas estáticas, mas não é a ferramenta mais eficiente para essa tarefa. Em contrapartida, o Scrapy se destaca na extração de dados estáticos, proporcionando uma experiência suave e eficiente para coletar as informações desejadas.
Recursos de integração
O Scrapy pode ser facilmente integrado à maioria das ferramentas Python, incluindo bancos de dados como MySQL, PostgreSQL e MongoDB, para armazenar dados extraídos. Você pode até usar mapeadores objeto-relacionais (ORMs), como SQLAlchemy, para simplificar o processo de armazenamento de dados em bancos de dados relacionais. Se quiser processar e analisar seus dados mais a fundo, você pode usar o pandas, uma biblioteca popular de manipulação e análise de dados para Python.
O Scrapy também pode ser integrado a frameworks da web, como Django e Flask, para criar aplicativos da web que incorporam a funcionalidade de Scraping de dados. Além disso, a integração com o FastAPI permite que você crie APIs da web de alto desempenho com suporte assíncrono, adequado para lidar com solicitações de scraping de maneira eficiente.
Em contrapartida, o Selenium fornece drivers de navegador que atuam como intermediários entre as APIs do Selenium WebDriver e os navegadores. Você pode baixar e instalar um WebDriver para integrar com o navegador da web de sua escolha. Atualmente, o Selenium fornece drivers de navegador para Chrome, Edge, Firefox e Safari.
O Selenium também pode ser usado para testar automaticamente as funcionalidades das aplicações web; no entanto, tenha em mente que ele não possui uma estrutura de testes integrada. Você pode integrar o Selenium com outras estruturas de testes populares, incluindo CodeceptJS, Helium e Selenide.
O Selenium costumava se integrar a ferramentas de CI, como Jenkins e Travis CI, para permitir que scripts de automação fossem executados automaticamente como parte do pipeline de integração contínua e entrega contínua (CI/CD); no entanto, agora, eles executam tudo com o GitHub Actions, que oferece suporte a processos contínuos de teste e implantação.
O Scrapy pode ser integrado a diferentes provedores de serviços de Proxy, como o Bright Data, passando o IP e a porta do Proxy como um parâmetro de solicitação. Esse método é recomendado se você deseja usar um Proxy específico para o seu projeto.
Por exemplo, se você quiser integrar com um servidor Proxy, pode usar ocomando pip pip3 install scrapy parainstalar o Scrapy, assim:
#importar módulo scrapy
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
def start_requests(self):
start_urls = ["https://example.com/products"]
for url in start_urls:
yield scrapy.Request(
url=url,
callback=self.parse,
# conectar com Proxy
meta={"Proxy": "http://USERNAME:[email protected]:22225"},
)
def parse(self, response):
para livro em response.css(".book-card"):
yield {
"title": livro.css(".title ::text").get(),
"price": livro.css(".price-wrapper ::text").get(),
}
Aqui, você importa o Scrapy e define uma classechamada BookSpider herdadada classe spider do Scrapy para extrair uma lista de livros do site.Ométodostart_requests()inicia solicitações com URLs e Proxies especificados, eométodoparse()extrai títulos e preços de livros usando seletores CSS.
Em contrapartida, o Selenium oferece suporte à integração direta de Proxy por meio de vários drivers de navegador, como ChromeDriver e geckodriver. Você só precisa configurar o Selenium WebDriver para rotear suas solicitações HTTP por meio de um servidor Proxy.
Por exemplo, você pode integrar o Selenium com Proxies especificando o IP e a porta do Proxy fornecidos pela Bright Data, desta forma:
#importar módulos selenium
de selenium importar webdriver
de selenium.webdriver.common.proxy importar Proxy, ProxyType
# Configuração do proxy
proxy_address = "http://USERNAME:[email protected]"
proxy_port = "22225"
# Opções do Selenium: integrar com credenciais de Proxy da Bright Data
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=%s:%s' % (proxy_address, proxy_port))
# Instanciação do webdriver do Selenium
driver = webdriver.Chrome(options=options)
# Exemplo de uso: extração de uma página da web
url = "https://example.com"
driver.get(url)
print(driver.page_source)
# Fechar o driver
driver.quit()
Aqui, você importa os módulos Selenium necessários e configura o Proxy. Em seguida, configura o Chrome para usar servidores Proxy definidos, instancia um WebDriver, extrai uma página da web ("https://example.com"), imprime a fonte da página e fecha o WebDriver para concluir o processo.
Conclusão
Neste artigo, você comparou duas ferramentas populares de Scraping de dados: Scrapy e Selenium.
O Scrapy é uma ferramenta de raspagem baseada em Python fácil de usar, ideal para extração de dados em sites estáticos. Em contrapartida, o Selenium oferece recursos de automação e raspagem usando várias linguagens de programação, suporta vários navegadores da web e é a melhor opção para raspar conteúdo dinâmico e renderizado em JavaScript.
Seja qual for a ferramenta que você decidir usar, é recomendável usar uma plataforma de dados como a Bright Data. Ela pode ajudá-lo a adicionar funcionalidades aos seus scripts de Scraping de dados para evitar restrições geográficas, bloqueios e resolver CAPTCHAs. Você também pode utilizar a API e o SDK da Bright Data para atender a uma gama mais ampla de requisitos de Scraping de dados, garantindo a eficiência, velocidade, precisão e escalabilidade do seu projeto de Scraping de dados. Interessado em levar sua coleta de dados ainda mais longe? Adquira um conjunto de dados personalizado (amostras gratuitas disponíveis).




