

Neste guia, você verá:
- O que significa converter um site em Markdown e por que isso é útil.
- As principais abordagens para converter o HTML de uma página da Web em Markdown para sites estáticos e dinâmicos.
- Como usar o Python para converter uma página da Web em Markdown.
- As limitações dessa solução e como superá-las com o Bright Data.
Vamos nos aprofundar!
O que significa “extrair um site para Markdown”?
“Extrair um site para Markdown” significa converter seu conteúdo em Markdown.
Mais especificamente, isso se refere a pegar o HTML de uma página da Web e transformá-lo no formato de dados Markdown.
Por exemplo, conecte-se a um site, abra o DevTools e copie seu HTML:
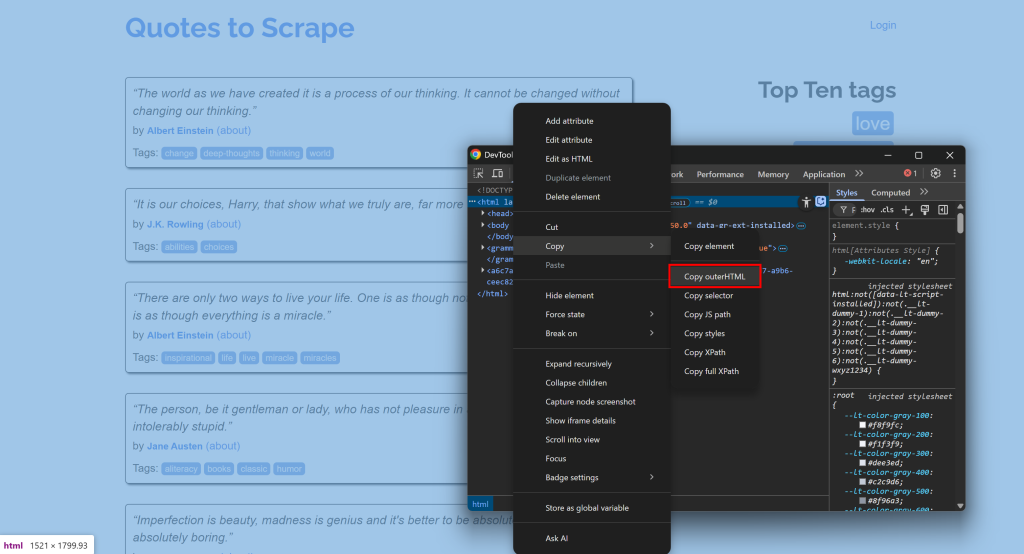
Em seguida, cole-o em um conversor de HTML para Markdown:
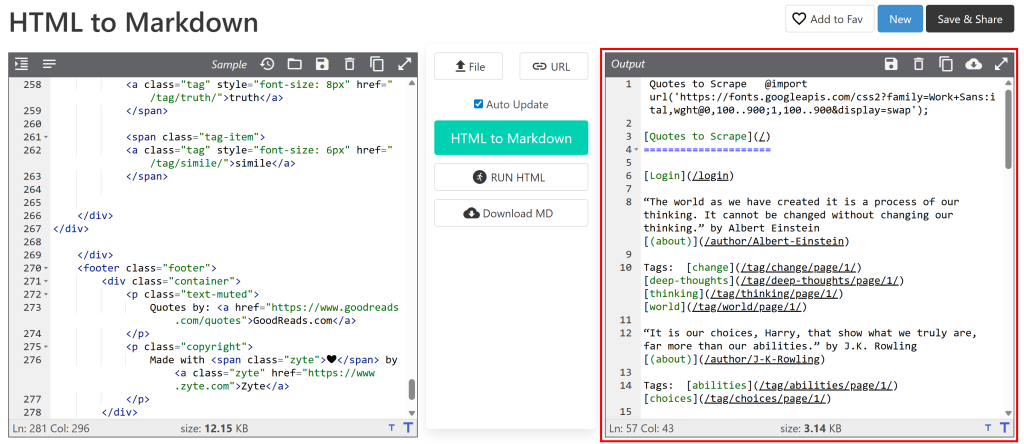
O resultado será semelhante ao documento Markdown que você deseja obter por meio do Scraping de dados. Agora, o objetivo é automatizar esse processo, e é exatamente disso que trata este artigo!
[Extra] Por que Markdown?
Por que Markdown em vez de outro formato (como texto simples)? Porque, conforme mostrado em nosso benchmark de formato de dados, o Markdown é um dos melhores formatos para ingestão de LLM. Os três principais motivos são:
- Ele preserva a maior parte da estrutura e das informações da página (por exemplo, links, imagens, cabeçalhos etc.).
- É conciso, o que leva a um uso limitado de tokens e a um processamento mais rápido da IA.
- Os LLMs tendem a entender Markdown muito melhor do que HTML simples.
É por isso que as melhores ferramentas de IA para raspagem trabalham por padrão com Markdown.
Abordagens de HTML para Markdown
Agora você sabe que raspar um site para Markdown significa simplesmente converter o HTML de suas páginas em Markdown. Em um nível mais alto, o processo se parece com o seguinte:
- Conectar-se ao site.
- Recuperar o HTML como uma string.
- Usar uma biblioteca HTML para Markdown para gerar a saída Markdown.
O desafio é que nem todas as páginas da Web são entregues da mesma forma. As duas primeiras etapas podem variar significativamente, dependendo do fato de a página de destino ser estática ou dinâmica. Vamos explorar como lidar com ambos os cenários, expandindo as etapas necessárias!
Etapa 1: conectar-se a um site
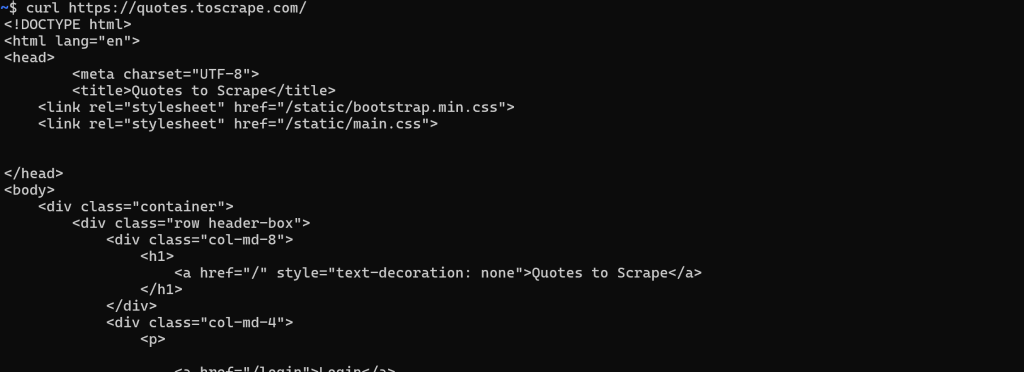
Em uma página da Web estática, o documento HTML retornado pelo servidor é exatamente o que você vê no navegador. Em outras palavras, tudo é fixo e incorporado no HTML produzido pelo servidor.
Nesse caso, a recuperação do HTML é simples. Você só precisa fazer uma solicitação HTTP GET para o URL da página com qualquer cliente HTTP:
Por outro lado, em um site dinâmico, a maior parte (ou parte) do conteúdo é recuperada via AJAX e renderizada no navegador via JavaScript. Isso significa que o documento HTML inicial retornado pelo servidor da Web contém apenas o mínimo necessário. Somente após a execução do JavaScript no lado do cliente, a página é preenchida com o conteúdo completo:

Nesses casos, você não pode simplesmente buscar o HTML com um simples cliente HTTP. Em vez disso, você precisa de uma ferramenta que possa realmente renderizar a página, como uma ferramenta de automação do navegador. Soluções como Playwright, Puppeteer ou Selenium permitem que você controle programaticamente um navegador para carregar a página de destino e obter seu HTML totalmente renderizado.
Etapa nº 2: recuperar o HTML como uma string
Para páginas da Web estáticas, esta etapa é simples. A resposta do servidor da Web à sua solicitação GET já contém o documento HTML completo como uma cadeia de caracteres. A maioria dos clientes HTTP, como o Requests do Python, fornece um método ou campo para acessar isso diretamente:
url = "https://quotes.toscrape.com/"
response = requests.get(url)
# Acessar o conteúdo HTML da página como uma cadeia de caracteres
html = response.textPara sites dinâmicos, as coisas são muito mais complicadas. Desta vez, você não está interessado no documento HTML bruto retornado pelo servidor. Em vez disso, você precisa esperar até que o navegador renderize a página, o DOM se estabilize e, então, acessar o HTML final.
Isso corresponde ao que você normalmente faria manualmente, abrindo o DevTools e copiando o HTML do nó <html>:
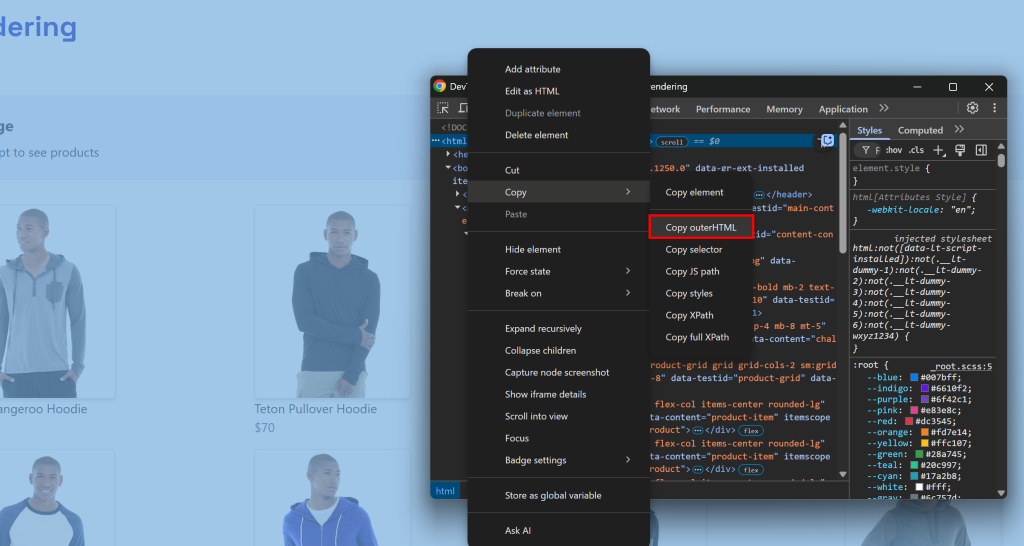
O desafio é saber quando a página terminou de ser renderizada. As estratégias comuns incluem:
- Aguardar o evento
DOMContentLoaded: É acionado quando o HTML inicial é analisado eos <script>sdiferidos são carregados e executados. Esperar por esse evento é o comportamento padrão do Playwright. - Aguardar o evento
load: É acionado quando a página inteira é carregada, incluindo folhas de estilo, scripts, iframes e imagens (exceto as carregadas lentamente). - Aguardar o evento
networkidle: Considera a renderização concluída quando não há solicitações de rede por um determinado período (por exemplo,500 msno Playwright). Isso não é confiável para sites com conteúdo de atualização em tempo real, pois nunca será acionado. - Esperar por elementos específicos: Use APIs de espera personalizadas fornecidas por estruturas de automação de navegador para esperar até que determinados elementos apareçam no DOM.
Depois que a página for totalmente renderizada, você poderá extrair o HTML usando o método/campo específico fornecido pela ferramenta de automação do navegador. Por exemplo, no Playwright:
html = await page.content()Etapa 3: usar uma biblioteca HTML para Markdown para gerar a saída Markdown
Depois de recuperar o HTML como uma string, basta alimentá-lo em uma das muitas bibliotecas HTML para Markdown disponíveis. As mais populares são:
| Biblioteca | Linguagem de programação | GitHub Stars |
|---|---|---|
markdownify |
Python | 1.8k+ |
turndown |
JavaScript/Node.js | 10k+ |
Html2Markdown |
C# | 300+ |
commonmark-java |
Java | 2.5k+ |
html-para-markdown |
Go | 3k+ |
html-para-markdown |
PHP | 1.8k+ |
Raspagem de um site para Markdown: Exemplos práticos de Python
Nesta seção, você verá trechos completos de Python para extrair um site para Markdown. Os scripts abaixo implementarão as etapas explicadas anteriormente. Observe que você pode converter facilmente a lógica em JavaScript ou em qualquer outra linguagem de programação.
A entrada será o URL de uma página da Web e a saída será o conteúdo Markdown correspondente!
Sites estáticos
Neste exemplo, usaremos as duas bibliotecas a seguir:
requests: Para fazer a solicitação GET e obter o HTML da página como uma string.markdownify: Para converter o HTML da página em Markdown.
Instale as duas com:
pip install requests markdownifyA página de destino será a página estática “Quotes to Scrape“. Você pode atingir o objetivo com o seguinte snippet:
import requests
from markdownify import markdownify as md
# O URL da página a ser extraída
url = "http://quotes.toscrape.com/"
# Recuperar o conteúdo HTML usando solicitações
response = requests.get(url)
# Obter o HTML como uma string
html_content = response.text
# Converter o conteúdo HTML em Markdown
markdown_content = md(html_content)
# Imprimir a saída do Markdown
print(markdown_content)Opcionalmente, você pode exportar o conteúdo para um arquivo .md com:
with open("page.md", "w", encoding="utf-8") as f:
f.write(markdown_content)O resultado do script será:
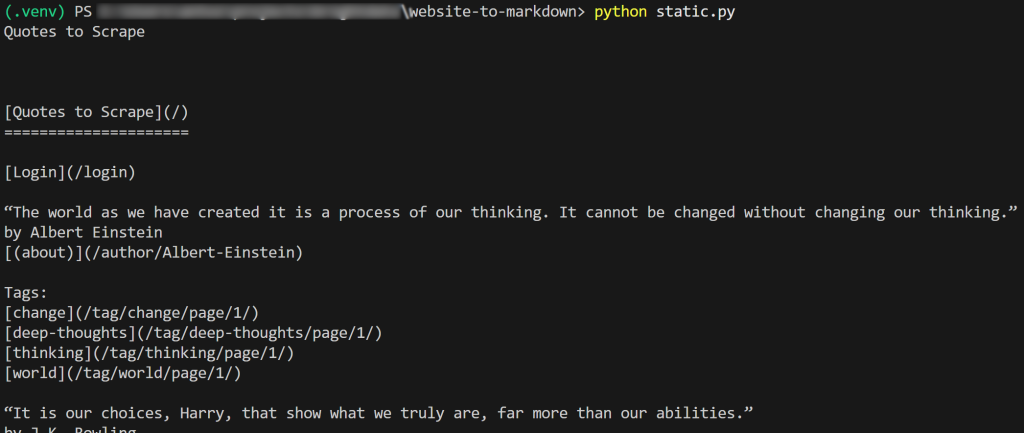
Se você copiar o Markdown de saída e colá-lo em um renderizador de Markdown, verá:
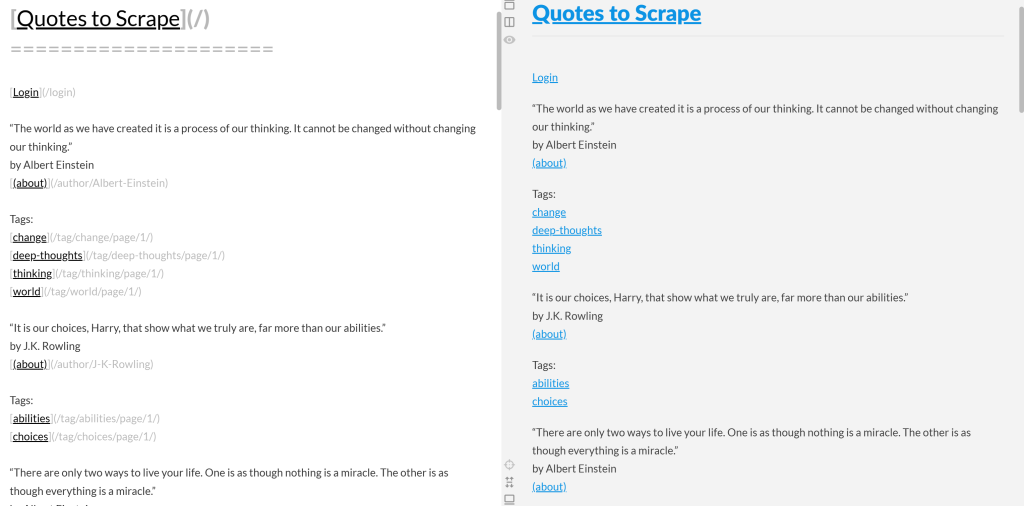
Observe como isso se parece com uma versão simplificada do conteúdo original da página “Quotes to Scrape”:
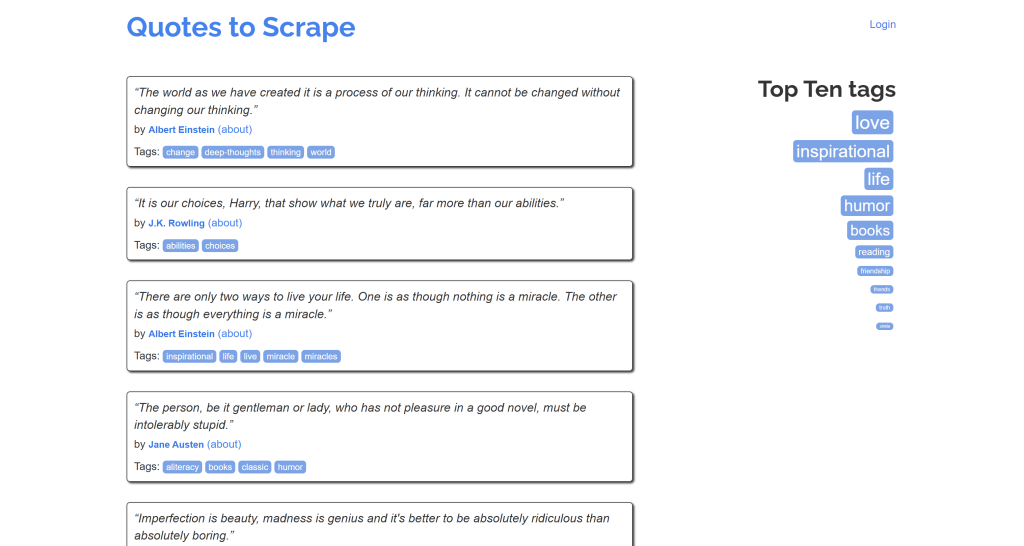
Missão concluída!
Sites dinâmicos
Aqui, utilizaremos essas duas bibliotecas:
playwright: Para renderizar a página de destino em uma instância controlada do navegador.markdownify: Para converter o DOM renderizado da página em Markdown.
Instale as duas dependências acima com:
pip install playwright markdownifyEm seguida, conclua a instalação do Playwright com:
python -m playwright installO destino será a página dinâmica “JavaScript Rendering” no site ScrapingCourse.com:
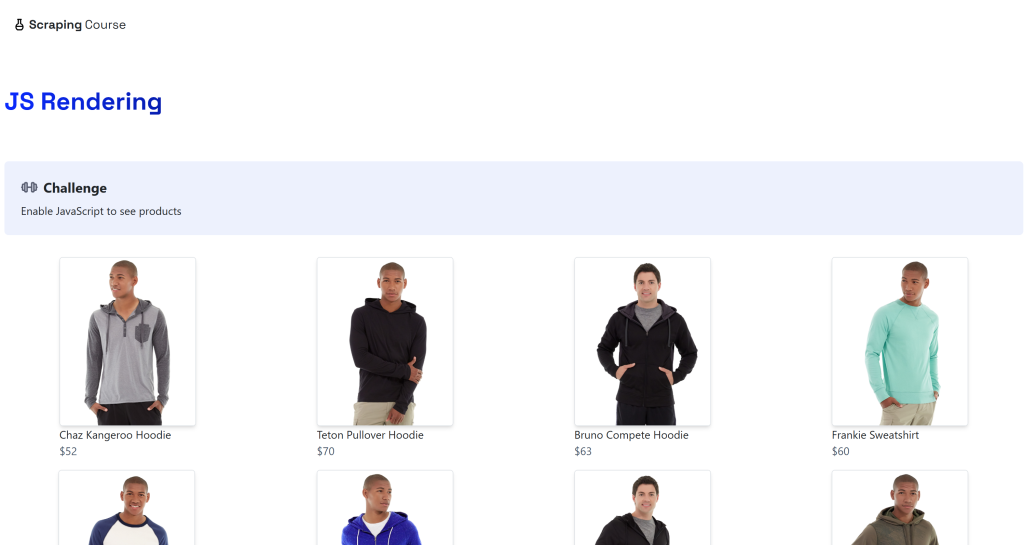
Essa página recupera dados no lado do cliente via AJAX e os renderiza usando JavaScript:
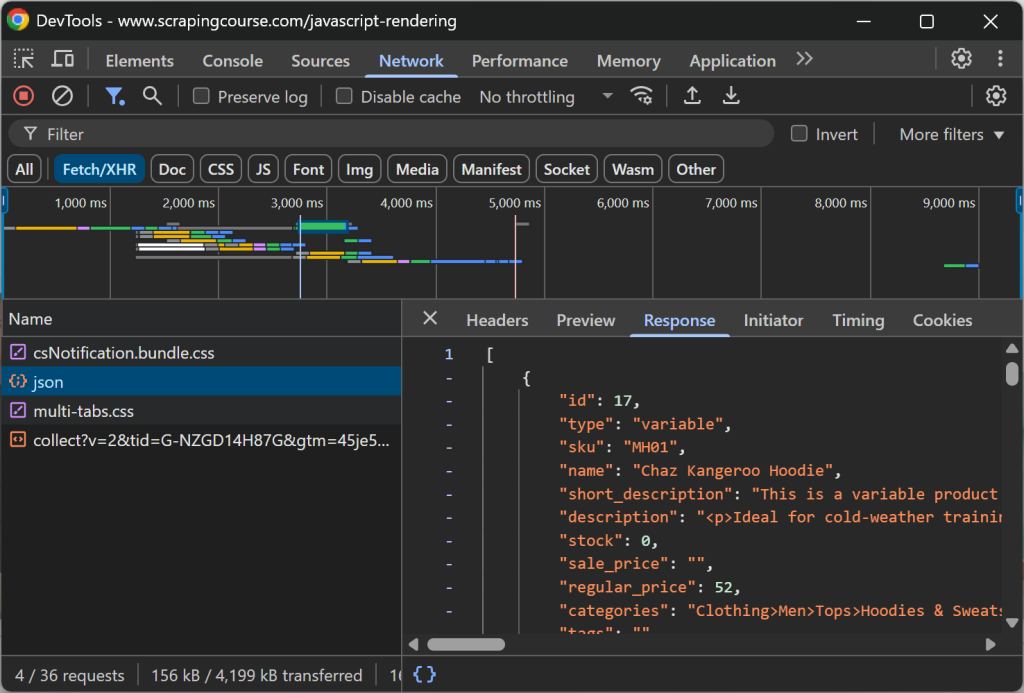
Faça o scraping de um site dinâmico para Markdown como abaixo:
from playwright.sync_api import sync_playwright
from markdownify import markdownify as md
with sync_playwright() as p:
# Iniciar um navegador sem cabeça
navegador = p.chromium.launch()
page = browser.new_page()
# URL da página dinâmica
url = "https://scrapingcourse.com/javascript-rendering"
# Navegue até a página
page.goto(url)
# Aguarde até 5 segundos para que o primeiro elemento do link do produto seja preenchido
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)
# Obter o HTML totalmente renderizado
rendered_html = page.content()
# Converter HTML em Markdown
markdown_content = md(rendered_html)
# Imprimir o Markdown resultante
print(markdown_content)
# Feche o navegador e libere seus recursos
browser.close()No snippet acima, optamos pela opção 4 (“Wait for specific elements”) porque é a mais confiável. Em detalhes, dê uma olhada nesta linha de código:
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)Isso aguarda até 5000 milissegundos (5 segundos) para que o elemento .product-link (uma tag <a> ) tenha um atributo href não vazio. Isso é suficiente para indicar que o primeiro elemento de produto na página foi renderizado, o que significa que os dados foram recuperados e o DOM agora está estável.
O resultado será:
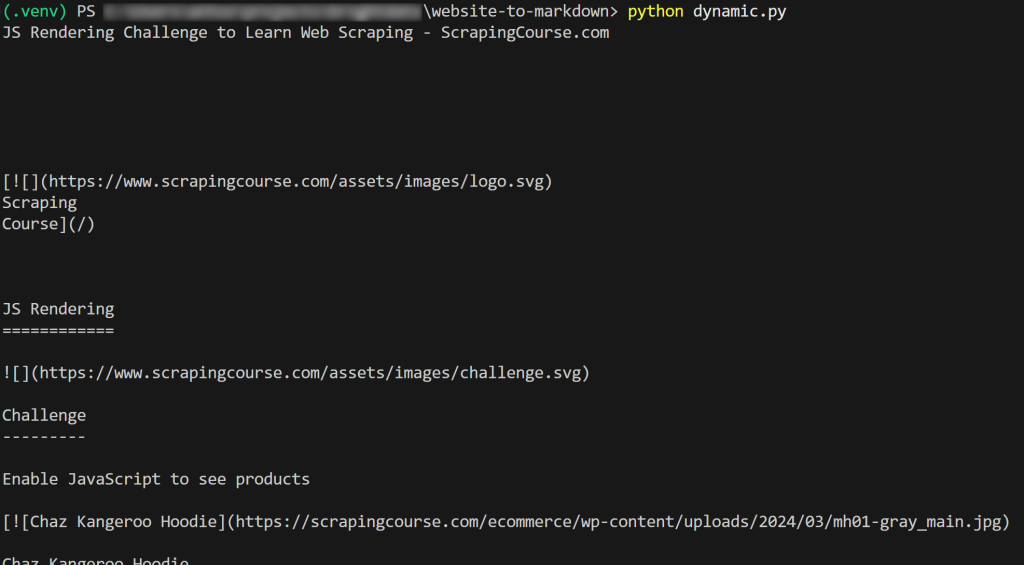
Et voilà! Você acabou de aprender a extrair dados de um site para Markdown.
Limitações dessas abordagens e a solução
Todos os exemplos desta postagem do blog têm um aspecto fundamental em comum: eles se referem a páginas que foram projetadas para serem fáceis de extrair!
Infelizmente, a maioria das páginas da Web do mundo real não é tão aberta aos bots de Scraping de dados. Muito pelo contrário, muitos sites implementam proteções contra scraping, como CAPTCHAs, proibições de IP, impressão digital do navegador e muito mais.
Em outras palavras, você não pode esperar que uma simples solicitação HTTP ou uma instrução goto() do Playwright funcione como pretendido. Ao direcionar a maioria dos sites do mundo real, você pode encontrar erros 403 Forbidden:

Ou páginas de erro/verificação humana:
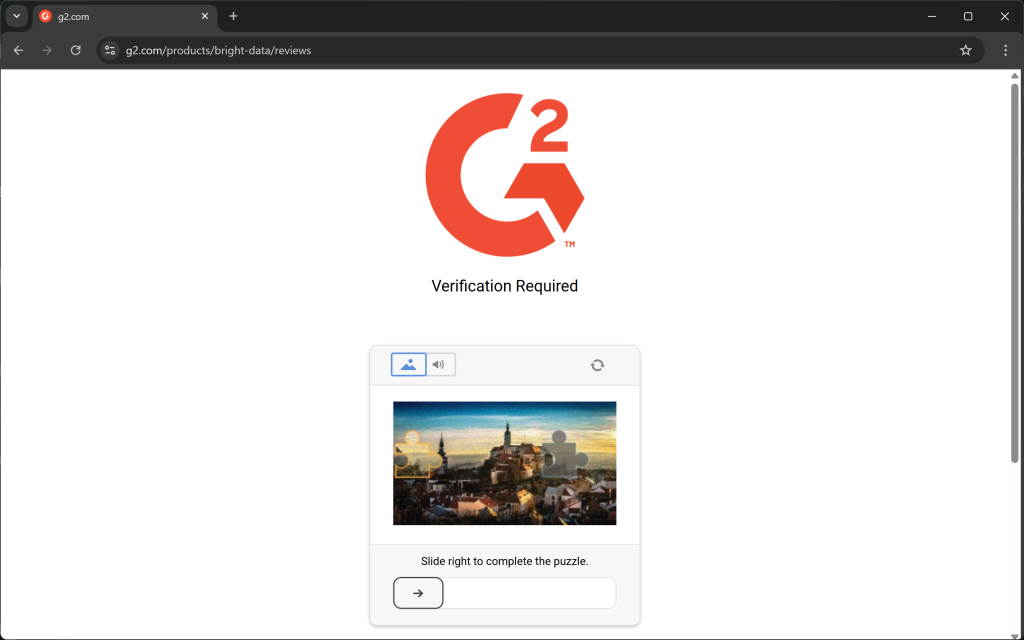
Outro aspecto importante a ser considerado é que a maioria das bibliotecas de HTML para Markdown realiza uma conversão de dados brutos. Isso pode levar a resultados indesejados. Por exemplo, se uma página contiver elementos <style> ou <script> incorporados diretamente no HTML, seu conteúdo (ou seja, código CSS e JavaScript, respectivamente) será incluído na saída do Markdown:

Isso geralmente não é desejado, especialmente se você planeja alimentar o Markdown com um LLM para processamento de dados. Afinal de contas, esses elementos de texto apenas adicionam ruído.
A solução? Contar com uma API Web Unlocker dedicada que possa acessar qualquer site, independentemente de suas proteções, e produzir Markdown pronto para LLM. Isso garante que o conteúdo extraído seja limpo, estruturado e pronto para tarefas de IA posteriores.
Scraping de dados com o Web Unlocker
O Web Unlocker da Bright Data é uma API de scraping de dados baseada em nuvem que pode retornar o HTML de qualquer página da Web. Isso é verdade independentemente das proteções antirraspagem ou antibot em vigor, e se a página é estática ou dinâmica.
A API é apoiada por uma rede Proxy de mais de 150 milhões de IPs, permitindo que você se concentre na coleta de dados, enquanto a Bright Data cuida de toda a infraestrutura de desbloqueio, renderização de JavaScript, Resolução de CAPTCHA, dimensionamento e atualizações de manutenção.
O uso é simples. Faça uma solicitação HTTP POST para o Web Unlocker com os argumentos corretos e você receberá de volta a página da Web totalmente desbloqueada. Você também pode configurar a API para retornar conteúdo no formato Markdown otimizado para LLM.
Siga o guia de configuração inicial e, em seguida, use o Web Unlocker para fazer o Scraping de dados de um site para Markdown com apenas algumas linhas de código:
# pip install requests
importar solicitações
# Substitua esses valores pelos valores corretos de sua conta da Bright Data
BRIGHT_DATA_API_KEY= "<SUA_CHAVE_API_DE_DADOS_BRIGHT>"
WEB_UNLOCKER_ZONE = "<NOME_DA_SUA_WEB_UNLOCKER_ZONE_NAME>"
# Substitua por seu URL de destino
url_to_scrape = "https://www.g2.com/products/bright-data/reviews"
# Prepare os cabeçalhos necessários
headers = {
"Authorization": f "Bearer {BRIGHT_DATA_API_KEY}", # Para autenticação
"Content-Type": "application/json"
}
# Prepare a carga útil do POST do Web Unlocker
payload = {
"url": url_to_scrape,
"Zona": WEB_UNLOCKER_ZONE,
"format" (formato): "raw",
"data_format": "markdown" # Para obter a resposta como conteúdo Markdown
}
# Fazer uma solicitação POST para a API do Bright Data Web Unlocker
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
# Obtenha a resposta do Markdown e imprima-a
markdown_content = response.text
print(markdown_content)Execute o script e você obterá:
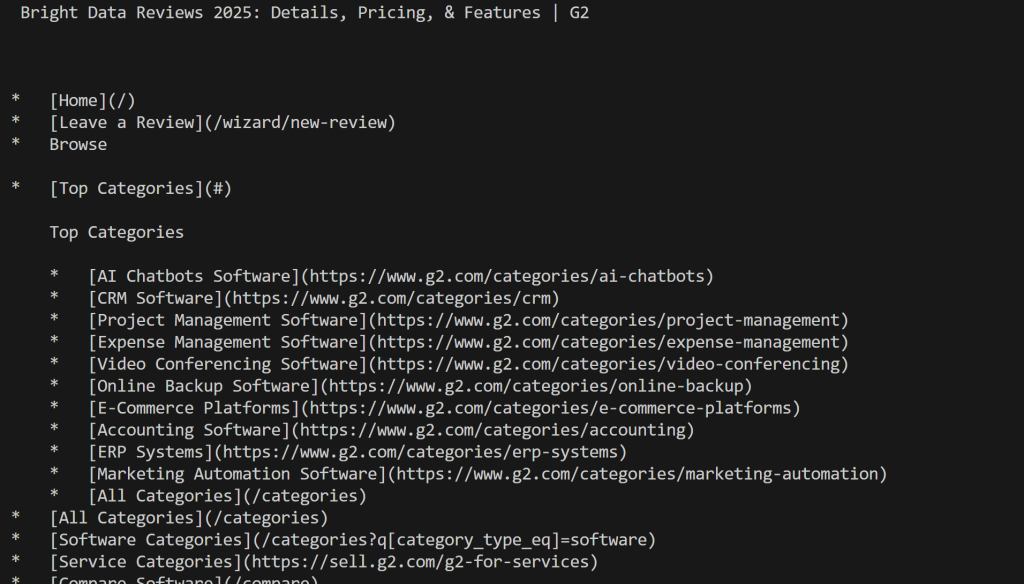
Observe como, desta vez, você não foi bloqueado pelo G2. Em vez disso, você obteve o conteúdo real do Mardkwon, conforme desejado.
Perfeito! Converter um site em Markdown nunca foi tão fácil.
Observação: esta solução está disponível em mais de 75 integrações com ferramentas de agentes de IA, como CrawlAI, Agno, LlamaIndex e LangChain. Além disso, ela pode ser usada diretamente por meio da ferramenta scrape_as_markdown no servidor Bright Data Web MCP.
Conclusão
Nesta postagem do blog, você explorou por que e como converter uma página da Web em Markdown. Conforme discutido, a conversão de HTML para Markdown nem sempre é simples devido a desafios como proteções antirraspagem e resultados de Markdown abaixo do ideal.
A Bright Data oferece cobertura com o Web Unlocker, uma API de Scraping de dados baseada em nuvem capaz de converter qualquer página da Web em Markdown otimizado para LLM. Você pode chamar essa API manualmente ou integrá-la diretamente às soluções de criação de agentes de IA ou por meio da integração do Web MCP.
Lembre-se de que o Web Unlocker é apenas uma das muitas ferramentas de dados da Web e de scraping de dados disponíveis na infraestrutura de IA da Bright Data.
Inscreva-se hoje mesmo em uma conta gratuita da Bright Data e comece a explorar nossas soluções de dados da Web prontas para IA!



