

A Wikipedia é uma fonte de informação extensa e abrangente, contendo milhões de artigos que cobrem quase todos os tópicos. Para pesquisadores, cientistas de dados e desenvolvedores, esses dados abrem inúmeras oportunidades, desde a construção de Conjuntos de dados de aprendizado de máquina até a realização de pesquisas acadêmicas. Neste artigo, vamos guiá-lo passo a passo pelo processo de extração de dados da Wikipedia.
Usando a API Bright Data Wikipedia Scraper
Se você deseja extrair dados da Wikipedia de maneira eficiente, a API Bright Data Wikipedia Scraper é uma ótima alternativa ao Scraping de dados manual. Essa poderosa API automatiza o processo, tornando muito mais fácil coletar grandes volumes de informações.
Principais casos de uso:
- Coletar explicações sobre uma ampla variedade de tópicos
- Comparar informações da Wikipedia com outras fontes de dados
- Realizar pesquisas usando grandes conjuntos de dados
- Extrair imagens da Wikipedia Commons
Você pode obter seus dados em formatos como JSON, CSV e .gz, e ele oferece suporte a várias opções de entrega, incluindo Amazon S3, Google Cloud Storage e Microsoft Azure.
Com apenas uma chamada de API, você pode acessar uma grande quantidade de dados de forma rápida e fácil!
Como extrair dados da Wikipedia usando Python
Siga este tutorial passo a passo para extrair dados da Wikipedia usando Python.
1. Configuração e pré-requisitos
Antes de começar, certifique-se de que seu ambiente de desenvolvimento esteja configurado corretamente:
- Instale o Python: baixe e instale a versão mais recente do Python no site oficial do Python.
- Escolha um IDE: use um IDE como PyCharm, Visual Studio Code ou Jupyter Notebook para seu trabalho de desenvolvimento.
- Conhecimento básico: certifique-se de estar familiarizado com seletores CSS e confortável com o uso do DevTools do navegador para inspecionar elementos da página.
Se você é novo no Python, leia este guia sobre como fazer scraping com Python para obter instruções detalhadas.
Em seguida, crie um novo projeto usando o Poetry, uma ferramenta de gerenciamento de dependências que simplifica o gerenciamento de pacotes e ambientes virtuais no Python.
poetry new wikipedia-Scraper
Este comando irá gerar a seguinte estrutura de projeto:
wikipedia-Scraper/
├── pyproject.toml
├── README.md
├── wikipedia_Scraper/
│ └── __init__.py
└── tests/
└── __init__.py
Navegue até o diretório do projeto e instale as dependências necessárias:
cd wikipedia-Scraper
poetry add requests beautifulsoup4 pandas lxml
Primeiro, o BeautifulSoup é usado para realizar o Parsing de documentos HTML e XML, facilitando a navegação e a extração de elementos específicos de páginas da web. A biblioteca requests lida com o envio de solicitações HTTP e a recuperação do conteúdo de páginas da web. O Pandas é uma ferramenta poderosa para manipular e analisar os dados coletados, particularmente útil ao trabalhar com tabelas. Por fim, o lxml é usado para acelerar o processo de Parsing, melhorando o desempenho do BeautifulSoup.
Em seguida, ative o ambiente virtual e abra a pasta do projeto em seu editor de código preferido (VS Code, neste caso):
poetry shell
code .
Abra o arquivo pyproject.toml para verificar as dependências do seu projeto. Ele deve ter a seguinte aparência:
[tool.poetry.dependencies]
python = "^3.12"
requests = "^2.32.3"
beautifulsoup4 = "^4.12.3"
pandas = "^2.2.3"
lxml = "^5.3.0"
Por fim, crie um arquivo main.py dentro da pasta wikipedia_scraper, onde você escreverá sua lógica de scraping. Sua estrutura de projeto atualizada deve ficar assim:
wikipedia-Scraper/
├── pyproject.toml
├── README.md
├── wikipedia_Scraper/
│ ├── __init__.py
│ └── main.py
└── tests/
└── __init__.py
Seu ambiente está configurado e você está pronto para começar a escrever o código Python para fazer o scraping da Wikipedia.
2. Conectando-se à página da Wikipedia desejada
Para começar, conecte-se à página da Wikipedia desejada. Neste exemplo, vamos extrair a seguinte página da Wikipedia.
Aqui está um trecho de código simples para se conectar a uma página da Wikipedia usando Python:
import requests # Para fazer solicitações HTTP
from bs4 import BeautifulSoup # Para realizar o Parsing do conteúdo HTML
def connect_to_wikipedia(url):
response = requests.get(url) # Envie uma solicitação GET para a URL
# Verificar se a solicitação foi bem-sucedida
if response.status_code == 200:
return BeautifulSoup(response.text, "html.parser") # Analisar e retornar o HTML
else:
print(f"Falha ao recuperar a página. Código de status: {response.status_code}")
return None # Retorne None se a solicitação falhar
wikipedia_url = "<https://en.wikipedia.org/wiki/Cristiano_Ronaldo>"
soup = connect_to_wikipedia(wikipedia_url) # Obtenha o objeto soup para o URL especificado
No código, a biblioteca Python requests permite enviar uma solicitação HTTP para a URL e, com o BeautifulSoup, você pode realizar o Parsing do conteúdo HTML da página.
3. Inspecionando a página
Para extrair dados de forma eficaz, você precisa entender a estrutura do DOM (Document Object Model) da página da web. Por exemplo, para extrair todos os links da página, você pode direcionar as tags <a>, conforme mostrado abaixo:
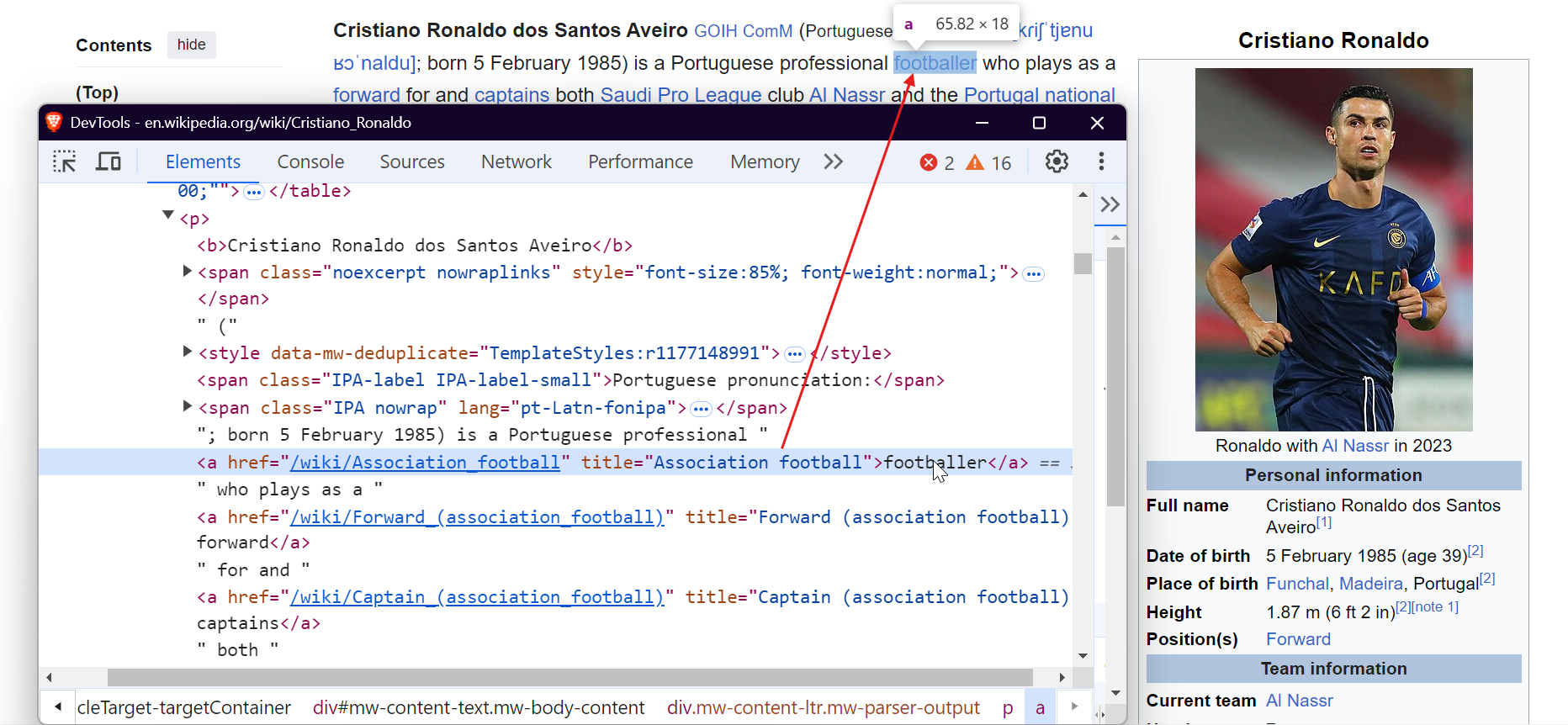
Para extrair imagens, segmente as tags <img> e extraia o atributo src para obter as URLs das imagens.
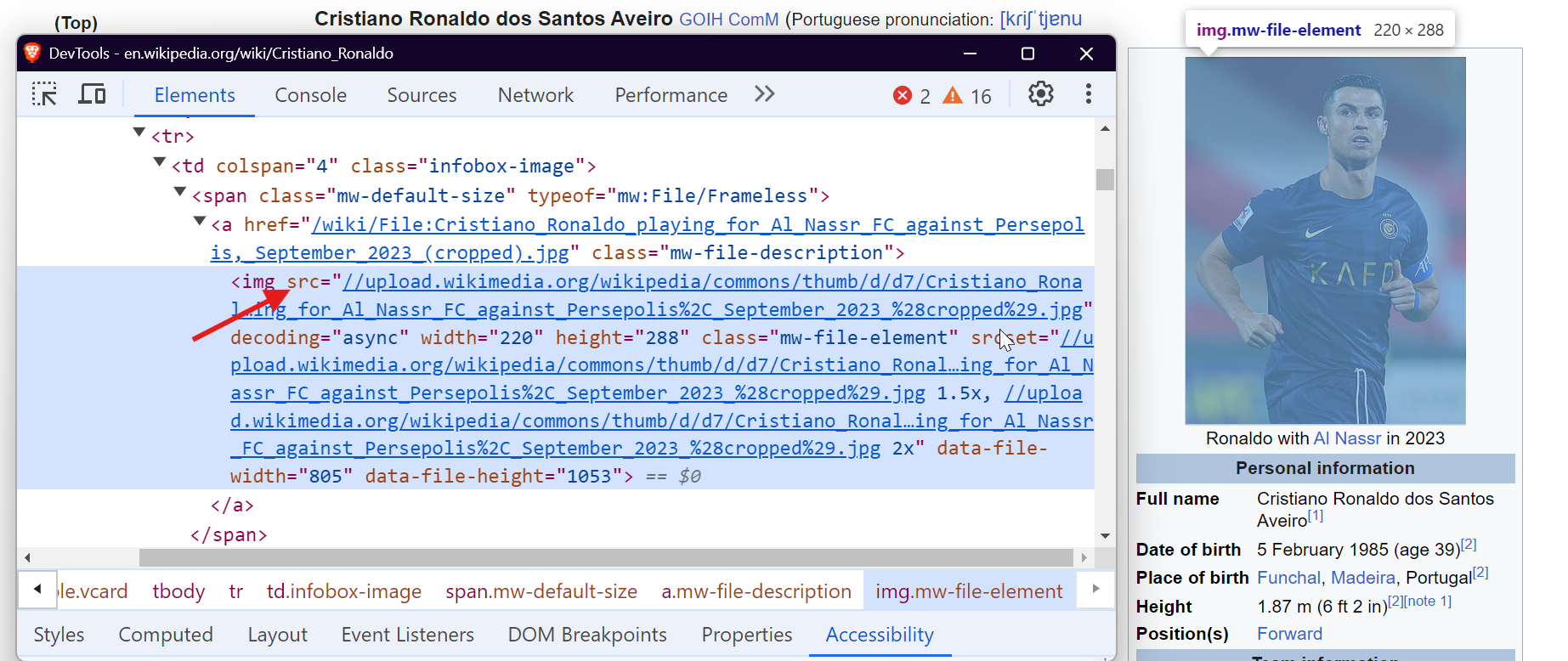
Para extrair dados de tabelas, você pode direcionar a tag <table> com a classe wikitable. Isso permite que você reúna todas as linhas e colunas da tabela e extraia os dados necessários.
Para extrair parágrafos, basta direcionar as tags <p> que contêm o conteúdo textual principal da página.
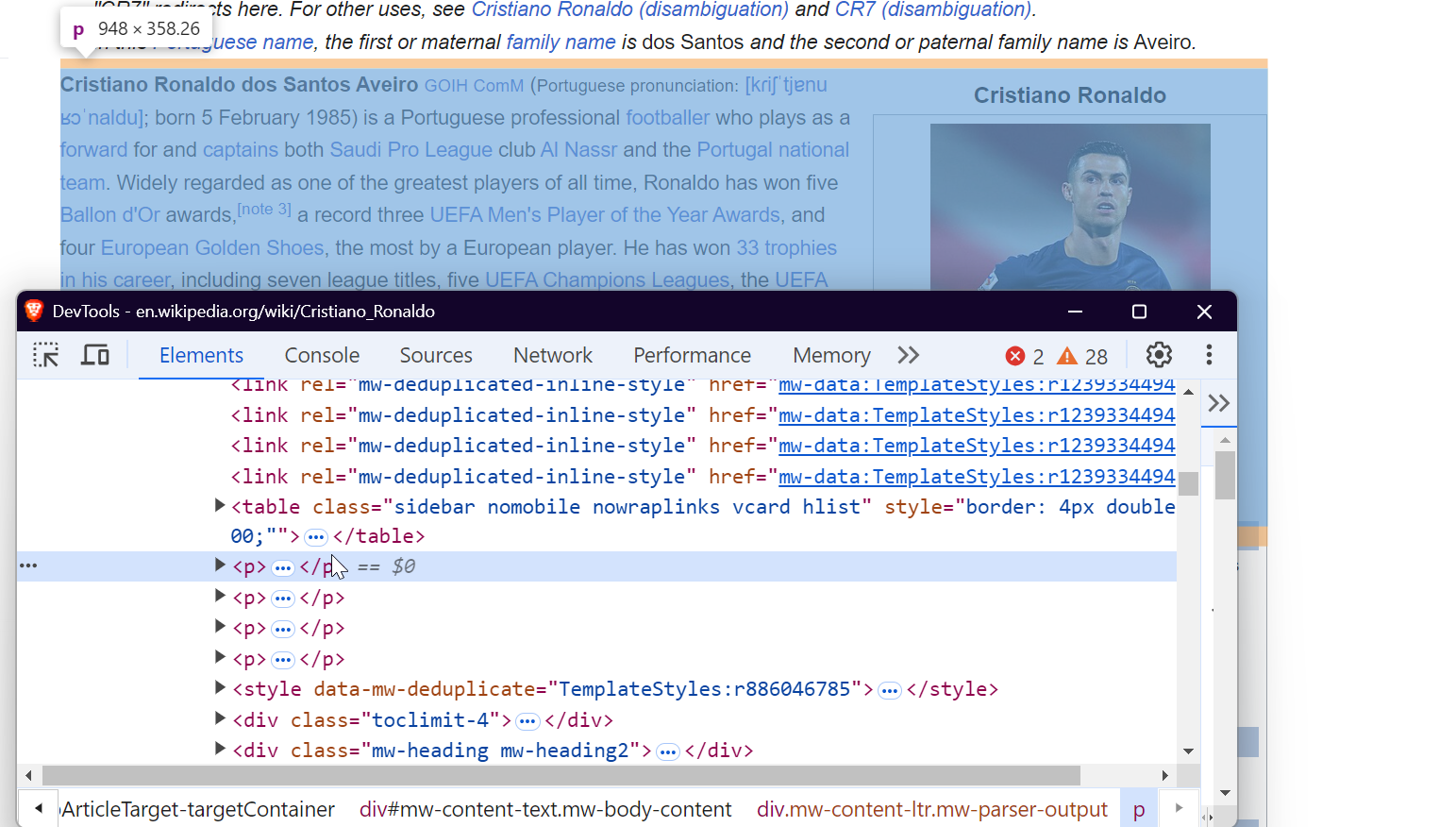
É isso! Ao direcionar esses elementos específicos, você pode extrair os dados desejados de qualquer página da Wikipedia.
4. Extraindo links
Os artigos da Wikipedia contêm links internos e externos que direcionam os usuários para tópicos relacionados, referências ou recursos externos. Para extrair todos os links de uma página da Wikipedia, você pode usar o seguinte código:
def extract_links(soup):
links = []
for link in soup.find_all("a", href=True): # Encontre todas as tags âncora com o atributo href
url = link["href"]
if not url.startswith("http"): # Verifique se a URL é relativa
url = "<https://en.wikipedia.org>" + url # Converta links relativos em URLs absolutas
links.append(url)
return links # Retorne a lista de links extraídos
A função soup.find_all('a', href=True) recupera todas as tags <a> na página que contêm um atributo href, o que inclui links internos e externos. O código também garante que os URLs relativos estejam formatados corretamente.
O resultado pode ser semelhante a:
<https://en.wikipedia.org#Early_life>
<https://en.wikipedia.org#Club_career>
<https://en.wikipedia.org/wiki/Real_Madrid>
<https://en.wikipedia.org/wiki/Portugal_national_football_team>
5. Extraindo parágrafos
Para extrair conteúdo textual de um artigo da Wikipedia, você pode direcionar as tags <p>, que contêm o corpo principal do texto. Veja como extrair parágrafos usando o BeautifulSoup:
def extrair_parágrafos(soup):
parágrafos = [p.get_text(strip=True) for p in soup.find_all("p")] # Extrair texto das tags de parágrafo
return [p for p in parágrafos if p and len(p) > 10] # Retornar parágrafos com mais de 10 caracteres
Essa função captura todos os parágrafos da página, filtrando aqueles vazios ou muito curtos para evitar conteúdo irrelevante, como citações ou palavras isoladas.
Um exemplo de resultado:
Cristiano Ronaldo dos Santos AveiroGOIHComM (pronúncia em português: [kɾiʃˈtjɐnuʁɔˈnaldu]; nascido em 5 de fevereiro de 1985) é um jogador de futebol profissional português que joga como atacante e capitão do clube Al Nassr, da Liga Profissional Saudita, e da seleção nacional de Portugal. Amplamente considerado um dos maiores jogadores de todos os tempos, Ronaldo ganhou cinco prêmios Ballon d'Or, [nota 3] um recorde de três prêmios de Jogador do Ano da UEFA e quatro Chuteiras de Ouro Europeias, o maior número para um jogador europeu. Ele ganhou 33 troféus em sua carreira, incluindo sete títulos de liga, cinco Ligas dos Campeões da UEFA, o Campeonato Europeu da UEFA e a Liga das Nações da UEFA. Ronaldo detém os recordes de maior número de partidas (183), gols (140) e assistências (42) na Liga dos Campeões, maior número de partidas (30), assistências (8), gols no Campeonato Europeu (14), gols internacionais (133) e partidas internacionais (215). Ele é um dos poucos jogadores a ter feito mais de 1.200 partidas profissionais, o maior número para um jogador de campo, e marcou mais de 900 gols oficiais na carreira profissional por clubes e pela seleção, tornando-se o maior artilheiro de todos os tempos.
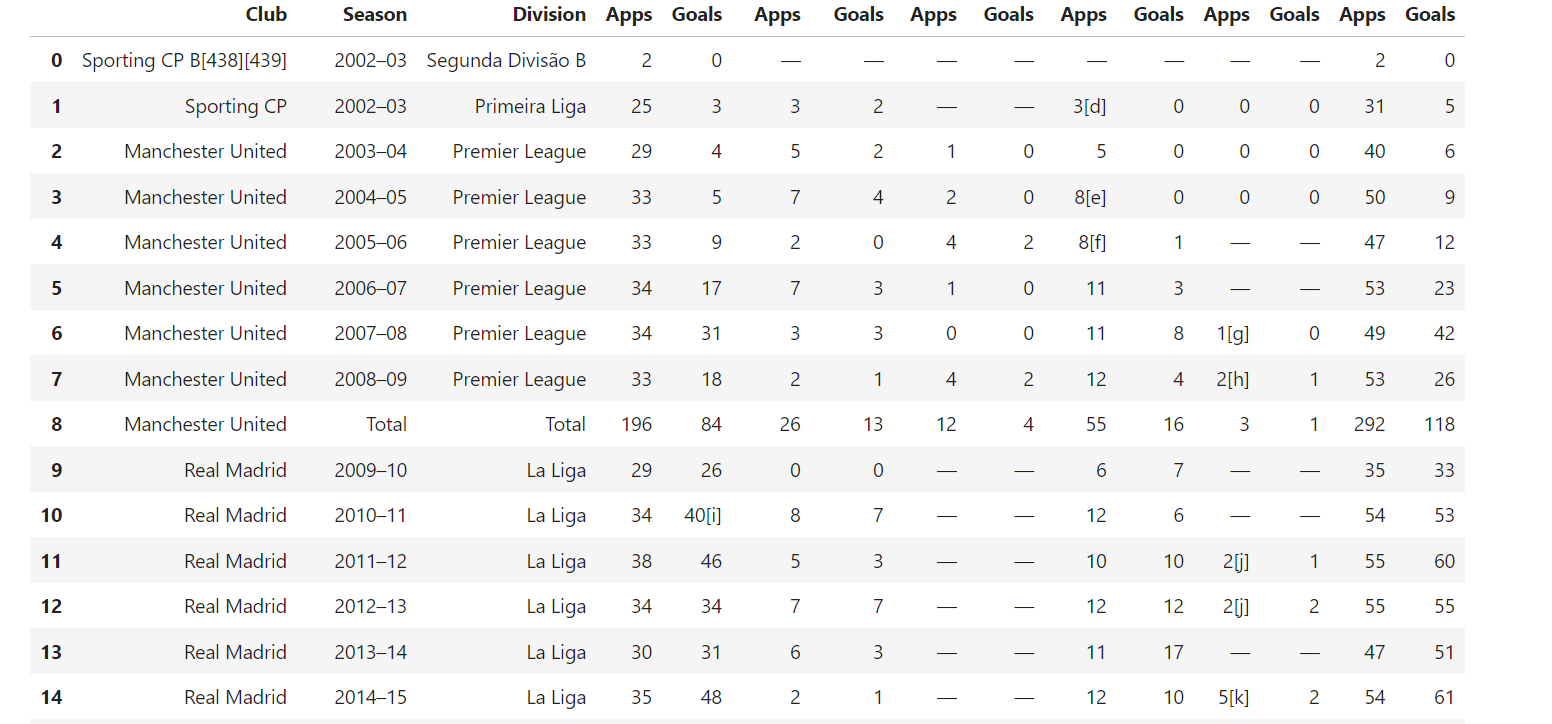
6. Extraindo tabelas
A Wikipedia frequentemente inclui tabelas com dados estruturados. Para extrair essas tabelas, use este código:
def extrair_tabelas(soup):
tabelas = []
para tabela em soup.find_all("table", {"class": "wikitable"}): # Encontre tabelas com a classe 'wikitable'
tabela_html = StringIO(str(table)) # Converta o HTML da tabela em string
df = pd.read_html(table_html)[0] # Ler a tabela HTML em um DataFrame
tables.append(df)
return tables # Retornar lista de DataFrames
Esta função encontra todas as tabelas com a classe wikitable e usa pandas.read_html() para convertê-las em DataFrames para manipulação posterior.
Exemplo de resultado:
7. Extraindo imagens
As imagens são outro recurso valioso que você pode extrair da Wikipedia. A função a seguir captura URLs de imagens da página:
def extrair_imagens(soup):
imagens = []
para img em soup.find_all("img", src=True): # Encontrar todas as tags de imagem com o atributo src
img_url = img["src"]
if not img_url.startswith("http"): # Prefixar 'https:' para URLs relativas
img_url = "https:" + img_url
if "static/images" not in img_url: # Excluir imagens estáticas ou não relevantes
images.append(img_url)
return images # Retornar a lista de URLs de imagens
Esta função localiza todas as imagens (tags<img> ) na página, acrescenta https: às URLs relativas e filtra as imagens que não fazem parte do conteúdo, garantindo que apenas as imagens relevantes sejam extraídas.
Exemplo de resultado:
<https://upload.wikimedia.org/wikipedia/commons/d/d7/Cristiano_Ronaldo_2018.jpg>
<https://upload.wikimedia.org/wikipedia/commons/7/76/Cristiano_Ronaldo_Signature.svgb>
8. Salvando os dados extraídos
Depois de extrair os dados, o próximo passo é salvá-los para uso posterior. Vamos salvar os dados em arquivos separados para links, imagens, parágrafos e tabelas.
def store_data(links, images, tables, paragraphs):
# Salvar links em um arquivo de texto
with open("wikipedia_links.txt", "w", encoding="utf-8") as f:
for link in links:
f.write(f"{link}n")
# Salvar imagens em um arquivo JSON
com open("wikipedia_images.json", "w", encoding="utf-8") como f:
json.dump(images, f, indent=4)
# Salvar parágrafos em um arquivo de texto
com open("wikipedia_paragraphs.txt", "w", encoding="utf-8") como f:
para para em parágrafos:
f.write(f"{para}nn")
# Salvar cada tabela como um arquivo CSV separado
para i, tabela em enumerate(tabelas):
tabela.to_csv(f"wikipedia_table_{i+1}.csv", index=False, encoding="utf-8-sig")
A função store_data organiza os dados coletados:
- Os links são salvos em um arquivo de texto.
- As URLs das imagens são salvas em um arquivo JSON.
- Os parágrafos são armazenados em outro arquivo de texto.
- As tabelas são salvas em arquivos CSV.
Essa organização facilita o acesso e o trabalho com os dados posteriormente.
Confira nosso guia para saber mais sobre como realizar Parsing e serializar dados para JSON em Python.
Juntando tudo
Agora, vamos combinar todas as funções para criar um Scraper completo que extrai e salva dados de uma página da Wikipedia:
import requests
from bs4 import BeautifulSoup
import pandas as pd
from io import StringIO
import json
# Extrair todos os links da página
def extract_links(soup):
links = []
for link in soup.find_all("a", href=True):
url = link["href"]
if not url.startswith("http"):
url = "<https://en.wikipedia.org>" + url
links.append(url)
return links
# Extrair URLs de imagens da página
def extrair_imagens(soup):
imagens = []
para img em soup.find_all("img", src=True):
img_url = img["src"]
se img_url não começar com "http":
img_url = "https:" + img_url
se "static/images" não estiver em img_url: # Excluir imagens estáticas indesejadas
images.append(img_url)
retornar images
# Extrair todas as tabelas da página
def extrair_tabelas(soup):
tabelas = []
para tabela em soup.find_all("table", {"class": "wikitable"}):
table_html = StringIO(str(table))
df = pd.read_html(table_html)[0] # Converter tabela HTML para DataFrame
tables.append(df)
return tables
# Extrair parágrafos da página
def extrair_parágrafos(soup):
parágrafos = [p.get_text(strip=True) para p em soup.find_all("p")]
retornar [p para p em parágrafos se p e len(p) > 10] # Filtrar parágrafos vazios ou curtos
# Armazene os dados extraídos em arquivos separados
def store_data(links, images, tables, paragraphs):
# Salve os links em um arquivo de texto
with open("wikipedia_links.txt", "w", encoding="utf-8") as f:
for link in links:
f.write(f"{link}n")
# Salvar imagens em um arquivo JSON
com open("wikipedia_images.json", "w", encoding="utf-8") como f:
json.dump(images, f, indent=4)
# Salvar parágrafos em um arquivo de texto
com open("wikipedia_paragraphs.txt", "w", encoding="utf-8") como f:
para para em parágrafos:
f.write(f"{para}nn")
# Salvar cada tabela como um arquivo CSV
para i, tabela em enumerate(tabelas):
tabela.to_csv(f"wikipedia_table_{i+1}.csv", index=False, encoding="utf-8-sig")
# Função principal para extrair uma página da Wikipedia e salvar os dados extraídos
def scrape_wikipedia(url):
response = requests.get(url) # Buscar o conteúdo da página
soup = BeautifulSoup(response.text, "html.parser") # Analisar o conteúdo com BeautifulSoup
links = extrair_links(soup)
imagens = extrair_imagens(soup)
tabelas = extrair_tabelas(soup)
parágrafos = extrair_parágrafos(soup)
# Salvar todos os dados extraídos em arquivos
armazenar_dados(links, imagens, tabelas, parágrafos)
# Exemplo de uso: extrair a página da Wikipedia de Cristiano Ronaldo
if __name__ == "__main__":
scrape_wikipedia("<https://en.wikipedia.org/wiki/Cristiano_Ronaldo>")
Ao executar o script, vários arquivos serão criados no seu diretório:
wikipedia_images.jsoncontendo todas as URLs das imagens.wikipedia_links.txtcom todos os links da página.wikipedia_paragraphs.txtcontendo os parágrafos extraídos.- Arquivos CSV para cada tabela encontrada na página (por exemplo,
wikipedia_table_1.csv,wikipedia_table_2.csv).
O resultado pode ser semelhante a:

É isso! Você extraiu e armazenou com sucesso os dados da Wikipedia em arquivos separados.
Configurando a API do Bright Data Wikipedia Scraper
Configurar e usar a API do Bright Data Wikipedia Scraper é simples e pode ser feito em apenas alguns minutos. Siga estas etapas para começar rapidamente e começar a coletar dados da Wikipedia com facilidade.
Etapa 1: crie uma conta Bright Data
Acesse o site da Bright Data e faça login na sua conta. Se você ainda não tem uma conta, crie uma — é grátis para começar. Siga estas etapas:
- Acesse o site da Bright Data.
- Clique em Teste grátis e siga as instruções para criar sua conta.
- Quando estiver no seu painel, localize o ícone do cartão de crédito na barra lateral esquerda para acessar a página “Faturamento ”.
- Adicione um método de pagamento válido para ativar sua conta.
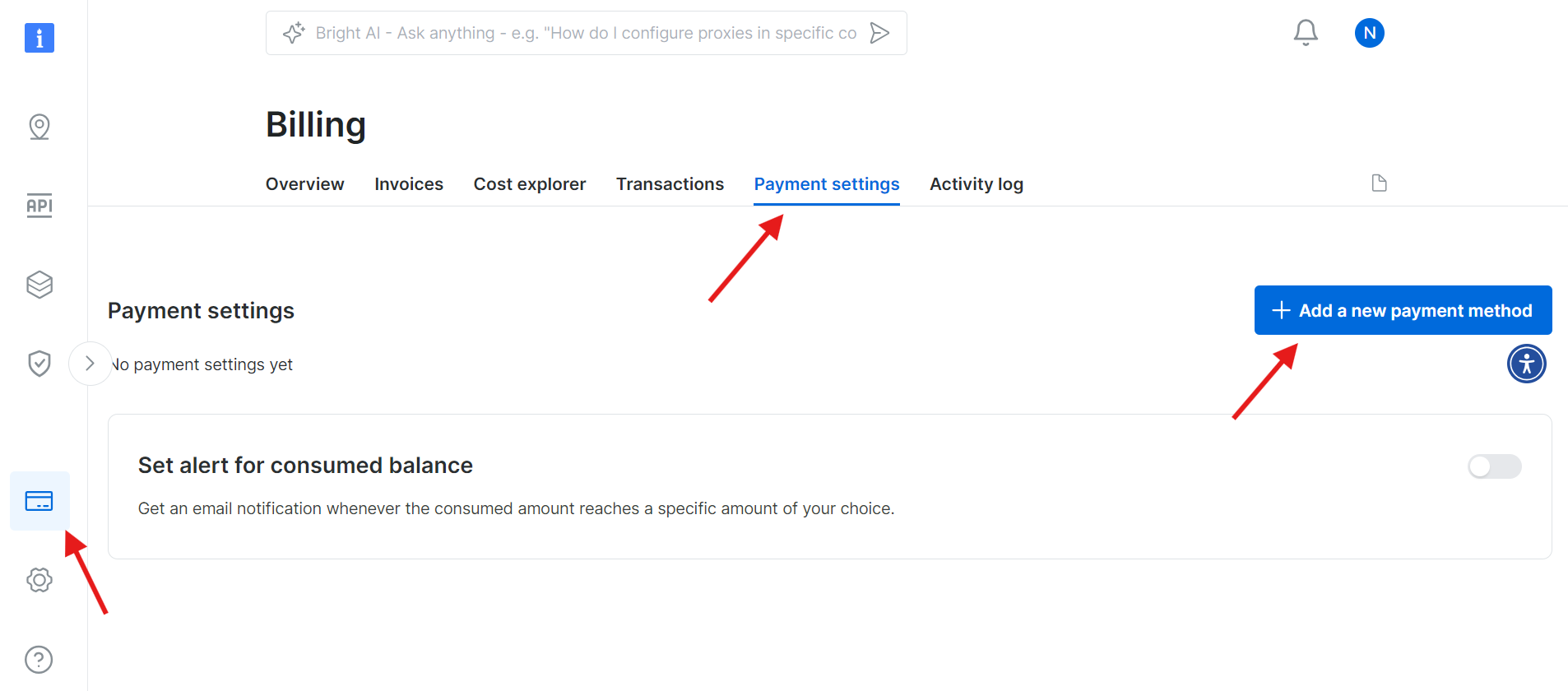
Depois que sua conta for ativada com sucesso, navegue até a seção API do Web Scraper no painel. Aqui, você pode pesquisar qualquer API do Web Scraper que deseja usar. Para nossos propósitos, pesquise Wikipedia.
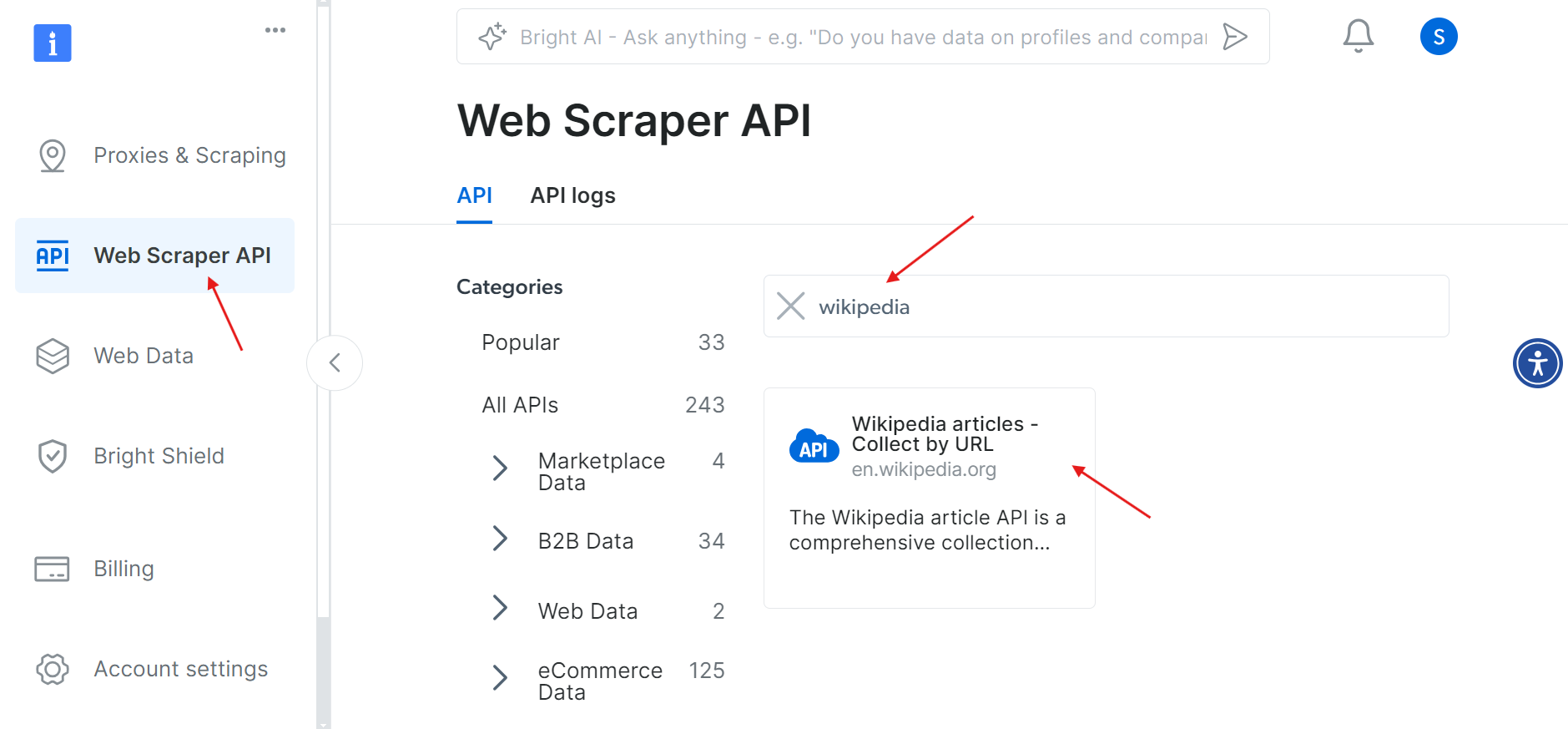
Clique na opção Artigos da Wikipedia – Coletar por URL. Isso permitirá que você colete artigos da Wikipedia simplesmente fornecendo as URLs.
Etapa 2: Comece a configurar uma chamada de API
Depois de clicar, você será direcionado para uma página onde poderá configurar sua chamada de API.
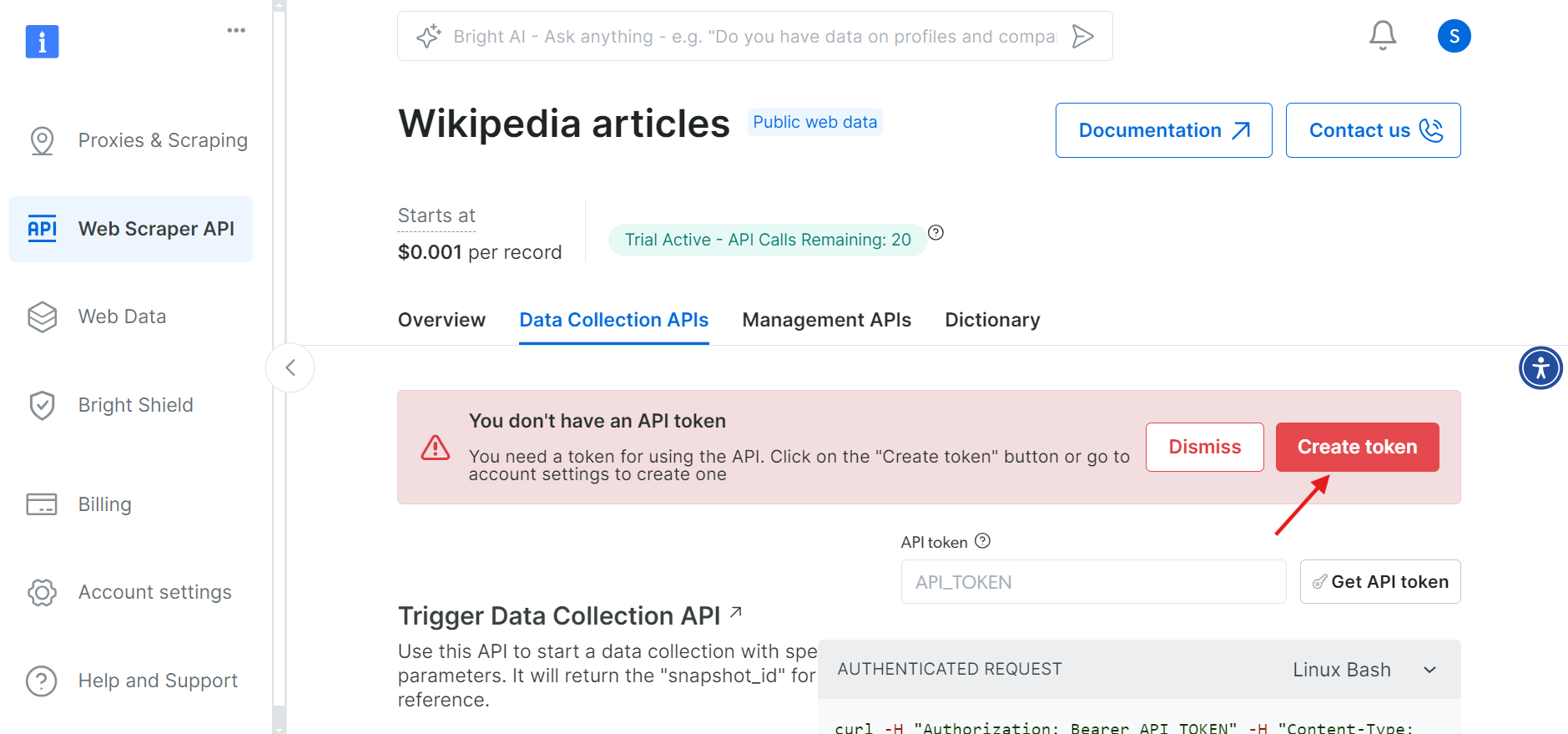
Antes de continuar, você precisa criar um token de API para autenticar suas chamadas de API. Clique no botão Criar token e copie o token gerado. Mantenha esse token em segurança, pois você precisará dele mais tarde.
Etapa 3: defina os parâmetros e gere a chamada de API
Agora que você tem seu token, está pronto para configurar sua chamada de API. Forneça os URLs das páginas da Wikipedia que deseja extrair e, no lado direito, um comando cURL será gerado com base em sua entrada.
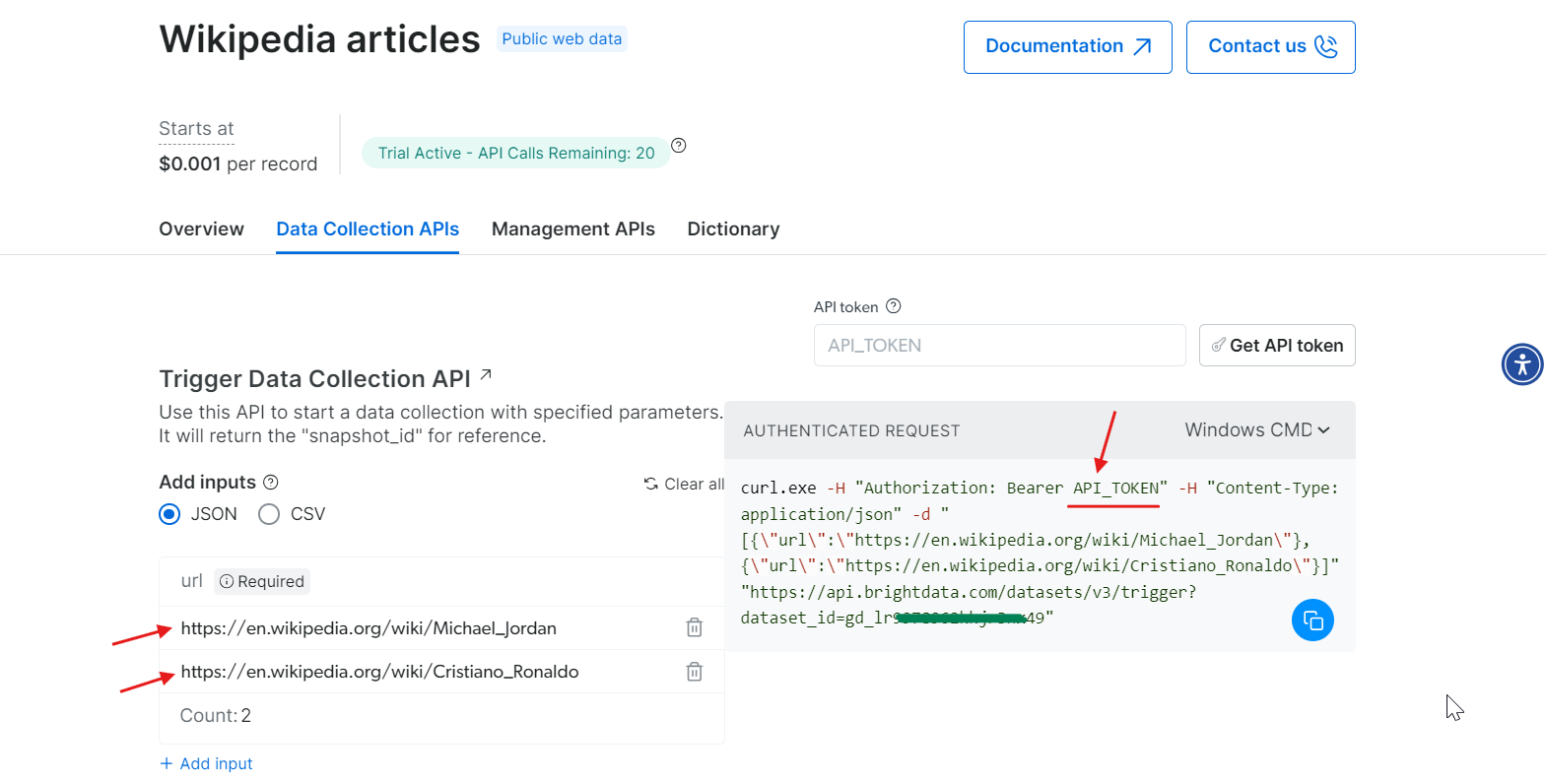
Copie o comando cURL, substitua API_Token pelo seu token real e execute-o no seu terminal. Isso irá gerar um snapshot_id, que você usará para recuperar os dados extraídos.
Etapa 4: Recuperar os dados
Usando o snapshot_id que você gerou, agora você pode recuperar os dados. Basta colar esse ID no campo Snapshot ID, e a API irá gerar automaticamente um novo comando cURL no lado direito. Você pode usar esse comando para extrair os dados. Além disso, você pode escolher o formato do arquivo para os dados, como JSON, CSV ou outras opções disponíveis.
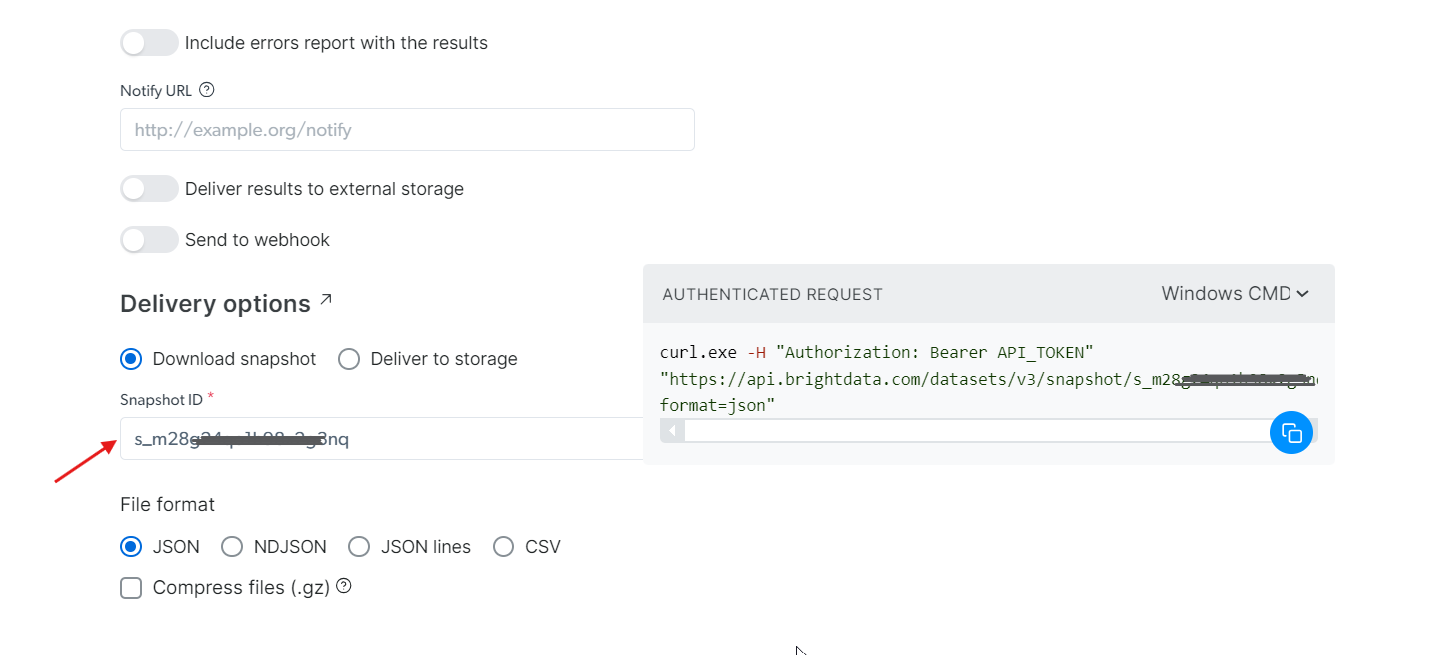
Você também tem a opção de enviar os dados para diferentes serviços de armazenamento, como Amazon S3, Google Cloud Storage ou Microsoft Azure Storage.
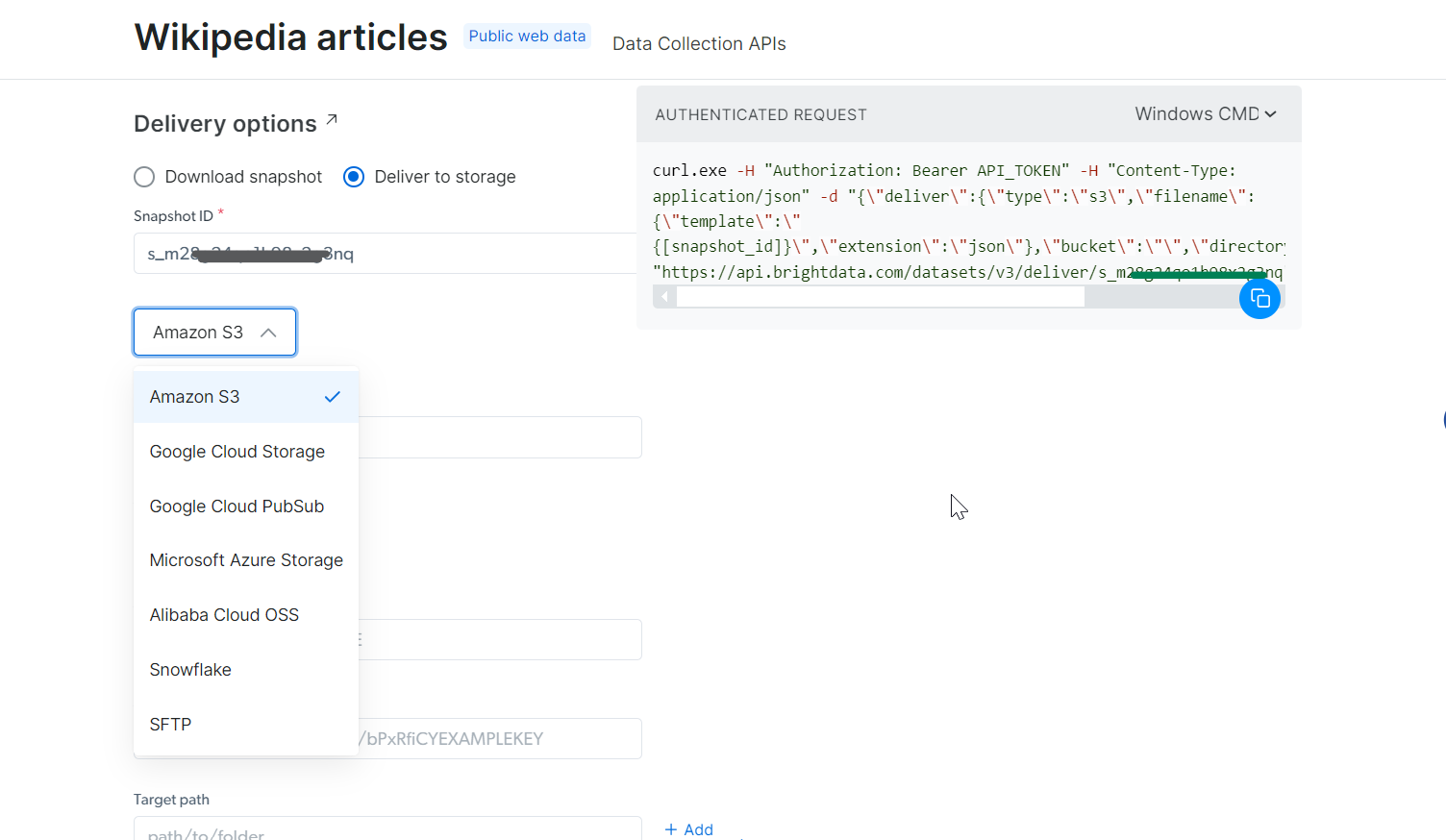
Etapa 5: execute o comando
Para este exemplo, vamos supor que você deseja obter os dados em um arquivo JSON. Escolha JSON como o formato do arquivo e copie o comando cURL gerado. Se você deseja salvar os dados diretamente em um arquivo, basta adicionar -o my_data.json ao final do comando cURL. Se preferir armazenar esses dados em sua máquina local, adicionar -o armazenará automaticamente os dados no arquivo especificado.
Execute-o em seu terminal e você terá todos os dados extraídos em apenas alguns segundos!
curl.exe -H "Authorization: Bearer 50xxx52c-xxxx-xxxx-xxxx-2748xxxxx487" "<HTTPS://api.brightdata.com/conjuntos-de-dados/v3/snapshot/s_mxxg2xxxxx2g3nq?format=json>" -o my_data.json
Não quer lidar com o Scraping de dados da Wikipedia, mas ainda precisa dos dados? Considere comprar um conjunto de dados da Wikipedia.
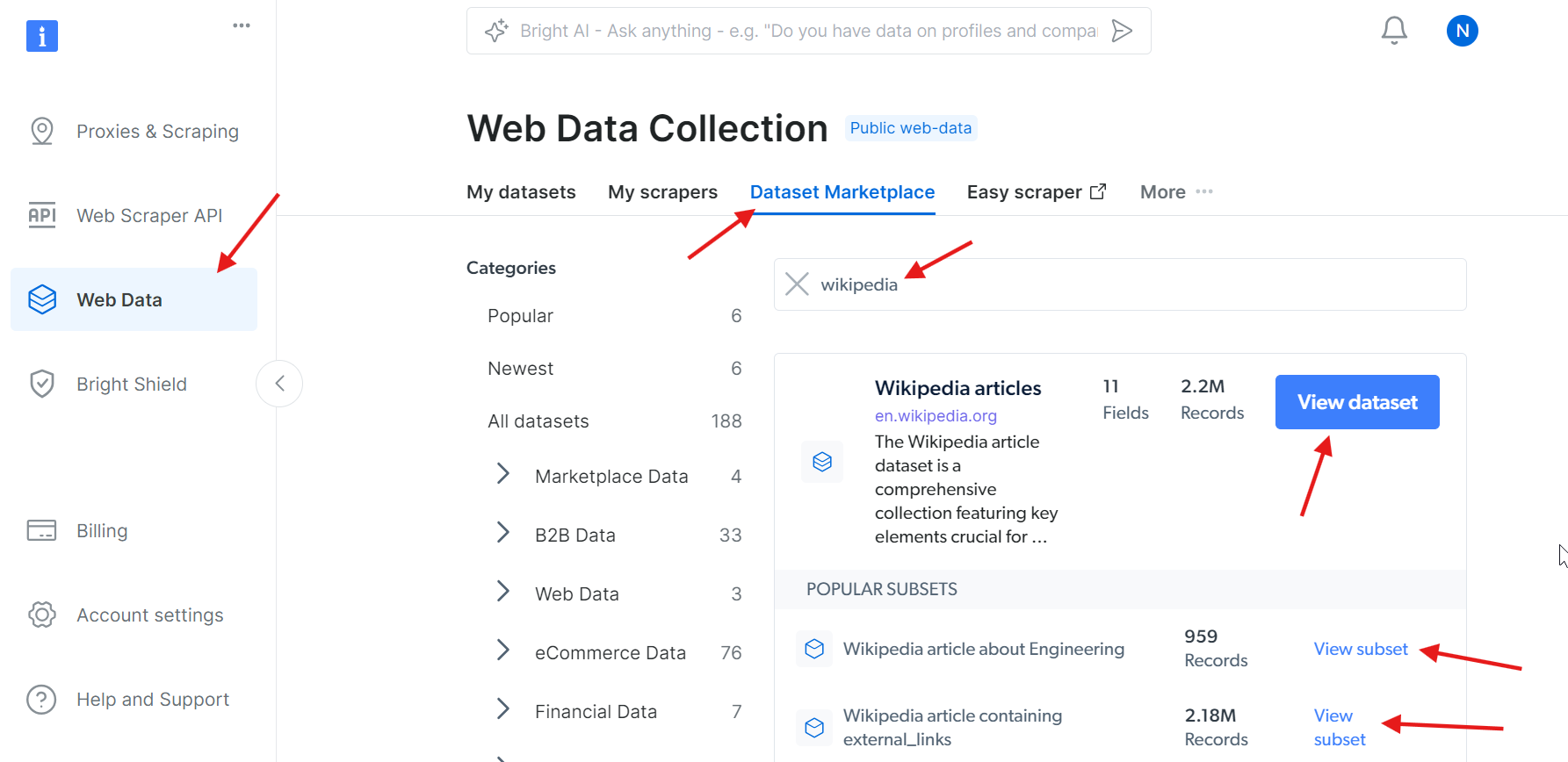
Sim, é simples assim!
Conclusão
Este artigo abordou tudo o que você precisa para começar a fazer scraping da Wikipedia usando Python. Extraímos com sucesso uma variedade de dados, incluindo URLs de imagens, conteúdo de texto, tabelas e links internos e externos. No entanto, para uma extração de dados mais rápida e eficiente, usar a API Wikipedia Scraper da Bright Data é uma solução simples.
Quer fazer scraping de dados em outros sites? Registre-se agora e experimente nossa API de Scraper. Comece seu teste grátis hoje mesmo!





