

Todos os dados são valiosos. Os dados agregados são um dos tipos mais procurados na web. O Google Finance contém toneladas de dados agregados para diferentes mercados financeiros. Esses dados são úteis para tudo, desde bots de negociação até relatórios gerais.
Vamos começar!
Pré-requisitos
Se você tiver as habilidades certas, poderá extrair dados do Google Finance com relativa facilidade. Você precisará do seguinte para fazer o scraping do Google Finance.
- Python: você realmente só precisa de um conhecimento básico de Python. Você deve saber como lidar com variáveis, funções e loops.
- Python Requests: este é o cliente HTTP padrão do Python. Ele é usado para fazer solicitações GET, POST, PUT e DELETE em toda a web.
- BeautifulSoup: o BeautifulSoup nos dá acesso a um analisador HTML eficiente. É isso que usamos para extrair nossos dados.
Se você ainda não os instalou, pode instalar o Requests e o BeautifulSoup com os seguintes comandos.
Instalar Requests
pip install requests
Instalar o BeautifulSoup
pip install beautifulsoup4
O que extrair do Google Finance
Aqui está uma imagem da página inicial do Google Finance. Ela contém pequenas informações sobre diferentes mercados. Queremos informações detalhadas sobre vários mercados, não apenas pequenos trechos.
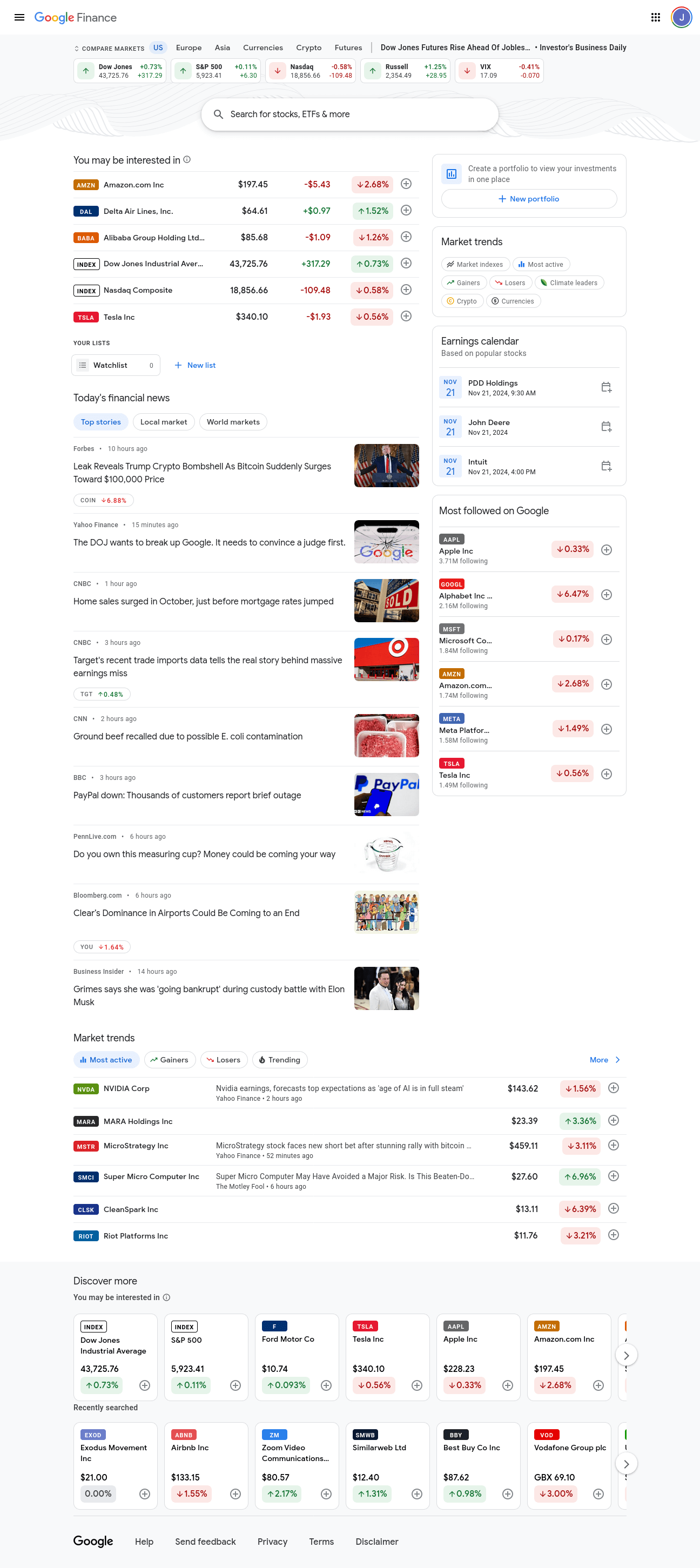
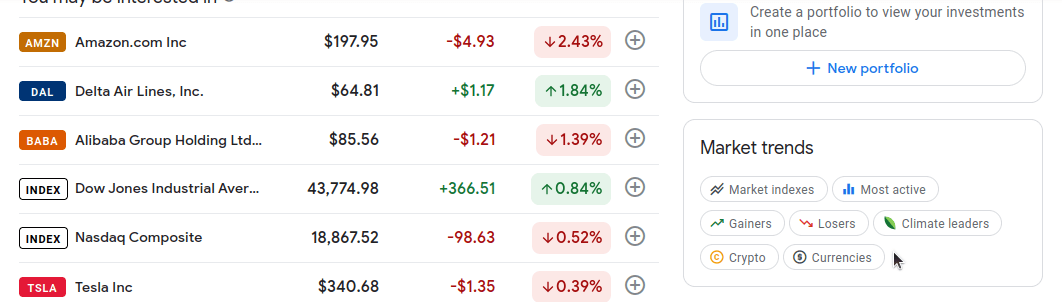
Se você rolar um pouco para baixo, verá uma seção chamada Tendências do mercado no lado direito da página. Cada bolha nesta seção leva a informações detalhadas sobre um mercado específico. Estamos interessados nos seguintes mercados: Ganhadores, Perdedores, Índices de mercado, Mais ativos e Criptomoedas.
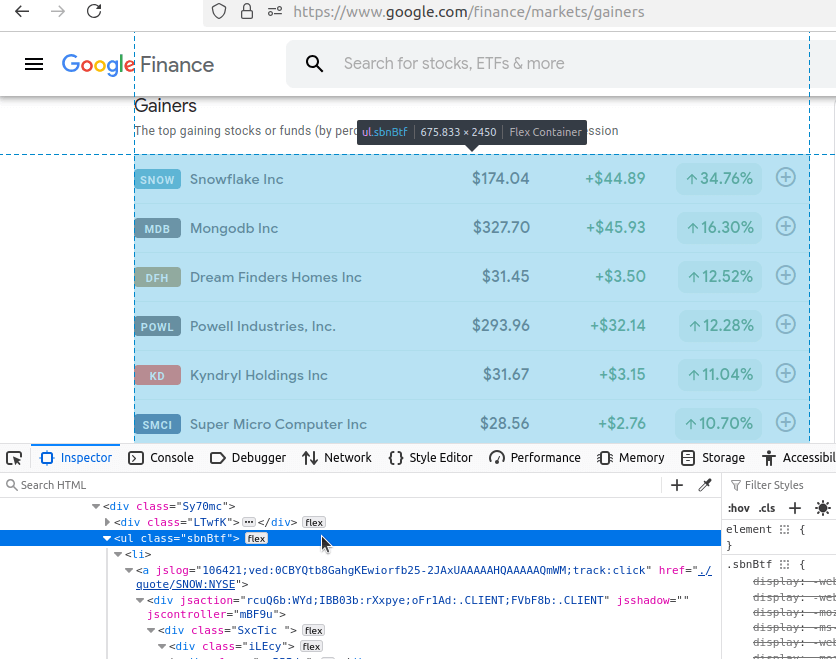
Agora, vamos clicar em cada uma dessas páginas e examiná-las. Começaremos com Ganhadores. Como você pode ver em nossa barra de endereço, nossa URL é: https://www.google.com/finance/markets/gainers. Se você olhar para o console do desenvolvedor na parte inferior, verá que todo o conjunto de dados está incorporado em uma ul, uma lista desorganizada.
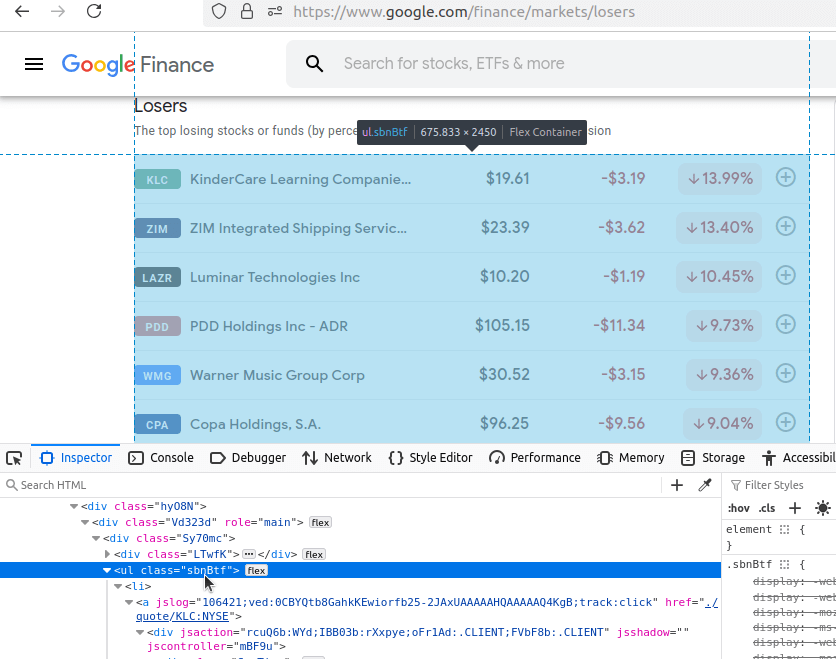
Agora, vamos dar uma olhada nos Perdedores. Nossa URL é: https://www.google.com/finance/markets/losers. Mais uma vez, nosso conjunto de dados vem incorporado em uma lista não organizada.
Aqui está a mesma imagem da página Índices de mercado. Esta página é um pouco especial. Ela contém vários elementos ul, então precisaremos acomodar isso em nosso código. O URL é: https://www.google.com/finance/markets/indexes. Você está começando a perceber uma tendência?
A página Mais ativa é mostrada abaixo. Mais uma vez, todos os nossos dados-alvo estão incorporados em um ul. Nossa URL é: https://www.google.com/finance/markets/most-active.
Por fim, vamos dar uma olhada em nossa página Crypto. Como você provavelmente já esperava, nossos dados estão dentro de um ul. Nossa URL é: https://www.google.com/finance/markets/cryptocurrencies.
Em cada uma dessas páginas, nossos dados-alvo vêm incorporados em uma lista desorganizada. Para extrair nossos dados, precisaremos encontrar esses elementos ul e extrair os elementos li (item da lista) de cada um deles. Dê uma olhada em nossa URL base: https://www.google.com/finance/markets. Cada página vem do endpoint dos mercados. Nosso formato de URL é: https://www.google.com/finance/markets/{NAME_OF_MARKET}. Temos 5 Conjuntos de dados e 5 URLs, todos estruturados da mesma maneira. Isso facilita a extração de uma grande quantidade de dados usando apenas algumas variáveis.
Extraia manualmente o Google Finance com Python
Se você conseguir evitar ser bloqueado, poderá coletar dados do Google Finance com Python Requests e BeautifulSoup. Precisamos ser capazes de coletar nossos dados. Também devemos ser capazes de armazená-los. Temos uma variedade de endpoints, mas todos eles derivam da mesma URL base: https://google.com/finance/markets/. Cada vez que buscamos uma página, precisamos encontrar os elementos ul e extrair todos os elementos li de cada lista.
Vamos revisar as funções básicas que usaremos em nosso script. Nós as chamamos de write_to_csv() e scrape_page(). Esses nomes são bastante autoexplicativos.
Funções individuais
Dê uma olhada em write_to_csv().
def write_to_csv(data, filename):
if type(data) != list:
data = [data]
print("Gravando em CSV...")
filename = f"google-finance-{filename}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Gravando dados no arquivo CSV...")
com open(filename, mode) como file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
se mode == "w":
writer.writeheader()
writer.writerows(data)
imprimir(f"Escreveu {filename} em CSV com sucesso...")
- Nossa função precisa gravar uma lista de objetos
dictem um CSV. Se nossosdadosnão forem umalista, nós os convertemos comdata = [data]. - Cada arquivo que geramos é do Google Finance, então adicionamos isso ao criar o arquivo
filename = f"google-finance-{filename}.csv". - Nosso
modopadrão é"w"(gravar), mas se o arquivo existir, mudamos nossomodopara"a"(anexar). csv.DictWriter(file, fieldnames=data[0].keys())inicializa nosso gravador de arquivos.- Se estivermos no modo de gravação, o arquivo ainda não existe, então criamos seus cabeçalhos a partir do primeiro
dicionáriodalista. - Depois de concluirmos a configuração, adicionamos nossos dados ao arquivo com
writer.writerows(data).
Agora, vamos dar uma olhada na função de scraping propriamente dita, scrape_page(). É aqui que a mágica realmente acontece. Fazemos nossa solicitação para nossa URL formatada. Em seguida, usamos o BeautifulSoup para analisar o HTML que recebemos de volta. Criamos uma lista vazia chamada scraped_data para armazenar nossos dados extraídos. Encontramos todos os elementos ul na página. Em seguida, extraímos os elementos li de cada ul que encontramos. Mas há um porém. O texto de cada item da lista está aninhado em vários elementos div. A matriz real que extraímos contém várias repetições. Para contornar isso, extraímos os itens 3, 6, 8 e 11 e os anexamos (append()) a scraped_data.
Nossa função scrape_page() está no trecho abaixo.
def scrape_page(endpoint: str):
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
soup = BeautifulSoup(response.text, "html.parser")
tables = soup.find_all("ul")
scraped_data = []
para tabela em tabelas:
list_elements = tabela.find_all("li")
para list_element em list_elements:
divs = list_element.find_all("div")
asset = {
"ticker": divs[3].text,
"name": divs[6].text,
"currency": divs[8].text[0] se endpoint != "cryptocurrencies" else "n/a",
"price": divs[8].text,
"change": divs[11].text
}
scraped_data.append(asset)
write_to_csv(scraped_data, endpoint)
- Fazemos nossa solicitação GET para este endpoint:
requests.get(f"https://google.com/finance/markets/{endpoint}"). - Usamos o analisador HTML do BeuatifulSoup em nossa
resposta:soup = BeautifulSoup(response.text, "html.parser"). - Encontramos todas as tabelas na página:
tables = soup.find_all("ul"). scraped_data = []nos fornece uma matriz para armazenar nossos resultados.- Iteramos por cada uma das tabelas que encontramos e fazemos o seguinte: “.
- Encontramos todos os itens da lista:
table.find_all("li"). - Iteramos por cada um dos itens da lista e encontramos seus elementos
div. Isso retorna uma lista chamadadivs. - Extraia o texto dos itens 3, 6, 8 e 11 dos
divse crie umdicionárioa partir dele. - Adicionamos o
dicionárioao nossoscraped_data. - As criptomoedas são precificadas por seu par de negociação, portanto, se estivermos no endpoint de criptomoedas, redefinimos nossa
moedaparan/a.
- Encontramos todos os itens da lista:
- Quando terminamos o Parsing da página, salvamos nossos
scrape_dataem um CSV:write_to_csv(scraped_data, endpoint). Passamos nosso endpoint como um nome de arquivo.
Raspagem de dados do Google Finance
Podemos colocar nossas funções acima em um script para fazer tudo funcionar. Além dessas funções, adicionamos uma lista de endpoints. Também adicionamos um main para manter nosso tempo de execução. Fique à vontade para copiar e colar o código abaixo e experimentá-lo!
import requests
from bs4 import BeautifulSoup
import csv
from pathlib import Path
endpoints = ["gainers", "losers", "indexes", "most-active", "cryptocurrencies"]
def write_to_csv(data, filename):
if type(data) != list:
data = [data]
print("Gravando em CSV...")
filename = f"google-finance-{filename}.csv"
mode = "w"
if Path(filename).exists():
mode = "a"
print("Gravando dados no arquivo CSV...")
com open(nome_do_arquivo, modo) como arquivo:
writer = csv.DictWriter(arquivo, nomes_dos_campos=data[0].keys())
se modo == "w":
writer.writeheader()
writer.writerows(data)
imprimir(f"Escreveu {nome_do_arquivo} em CSV com sucesso...")
def scrape_page(endpoint: str):
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
soup = BeautifulSoup(response.text, "html.parser")
tables = soup.find_all("ul")
scraped_data = []
para tabela em tabelas:
list_elements = tabela.find_all("li")
para list_element em list_elements:
divs = list_element.find_all("div")
asset = {
"ticker": divs[3].text,
"name": divs[6].text,
"currency": divs[8].text[0] se endpoint != "cryptocurrencies" else "n/a",
"price": divs[8].text,
"change": divs[11].text
}
scraped_data.append(asset)
write_to_csv(scraped_data, endpoint)
if __name__ == "__main__":
for endpoint in endpoints:
print("---------------------")
scrape_page(endpoint)
Quando executamos o código acima, obtemos o seguinte resultado.
---------------------
Gravando em CSV...
Gravando dados no arquivo CSV...
Google-finance-gainers.csv gravado com sucesso em CSV...
---------------------
Gravando em CSV...
Gravando dados no arquivo CSV...
Google-finance-losers.csv gravado com sucesso no CSV...
---------------------
Gravando em CSV...
Gravando dados no arquivo CSV...
Gravação bem-sucedida do google-finance-indexes.csv em CSV...
---------------------
Gravando em CSV...
Gravando dados no arquivo CSV...
Google-finance-most-active.csv gravado com sucesso em CSV...
---------------------
Gravando em CSV...
Gravando dados em arquivo CSV...
Google-finance-cryptocurrencies.csv gravado com sucesso em CSV...
Se você executar o script usando o VSCode, poderá ver os arquivos CSV aparecerem à medida que o Scraper conclui seu trabalho. Eles estão destacados na captura de tela abaixo.
Mostraremos também uma captura de tela de como cada um deles aparece no ONLYOFFICE.
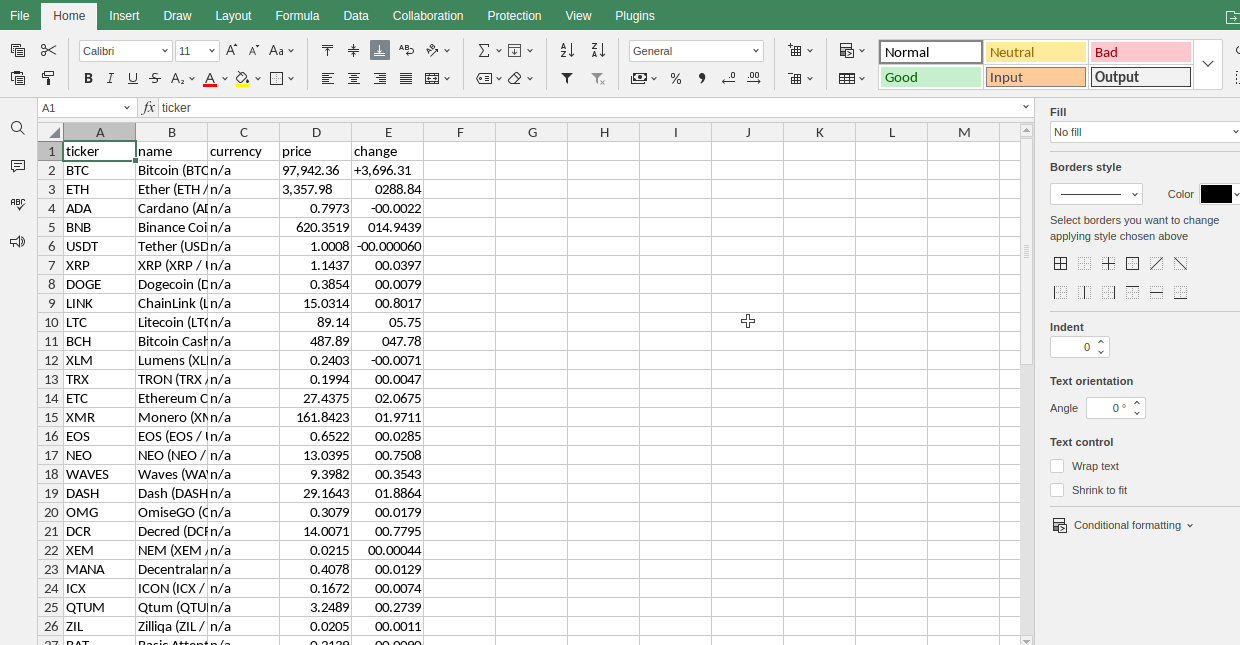
Mais ativos
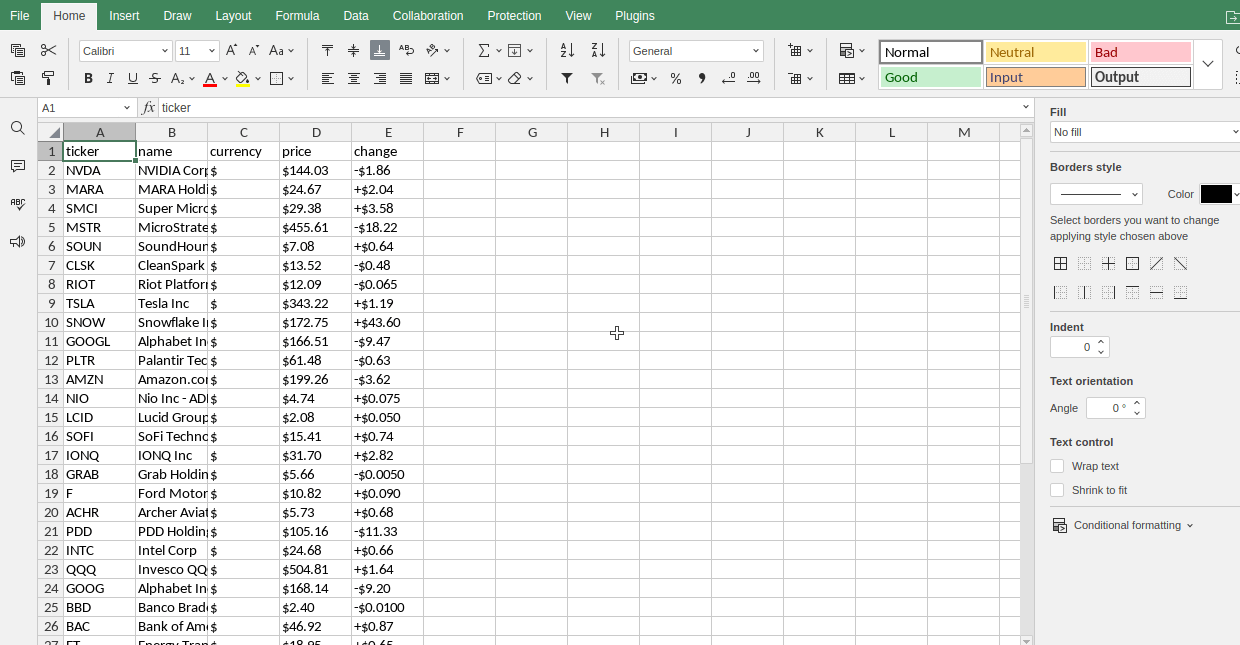
Piores
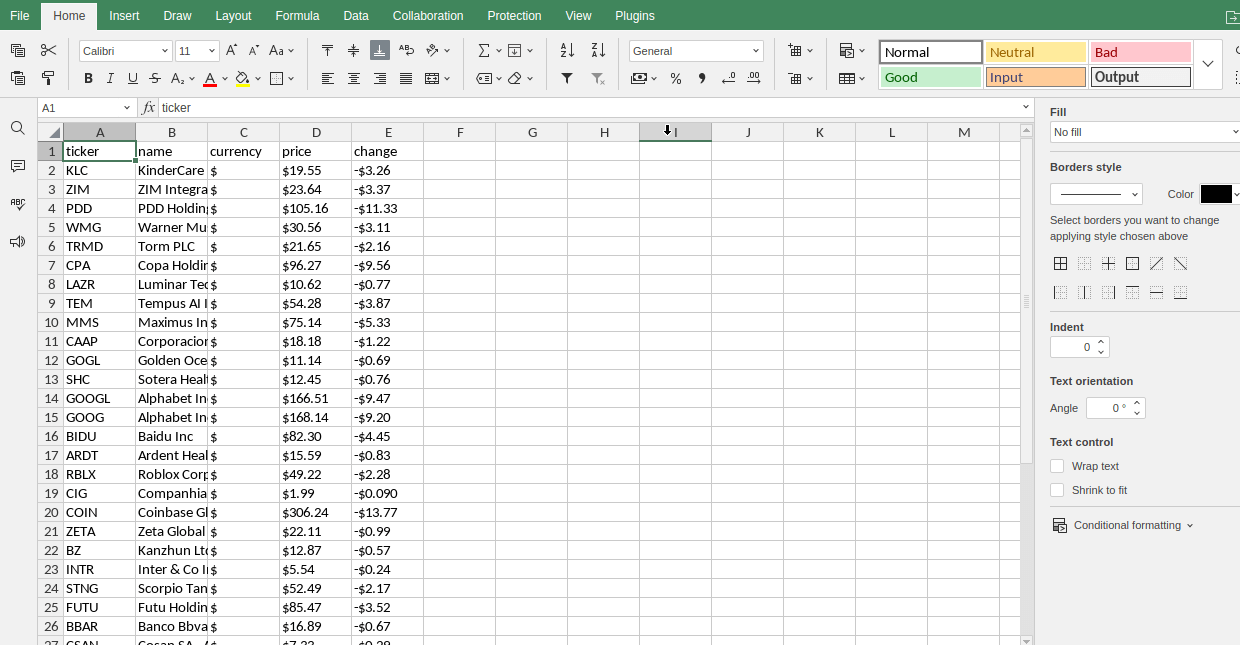
Índices
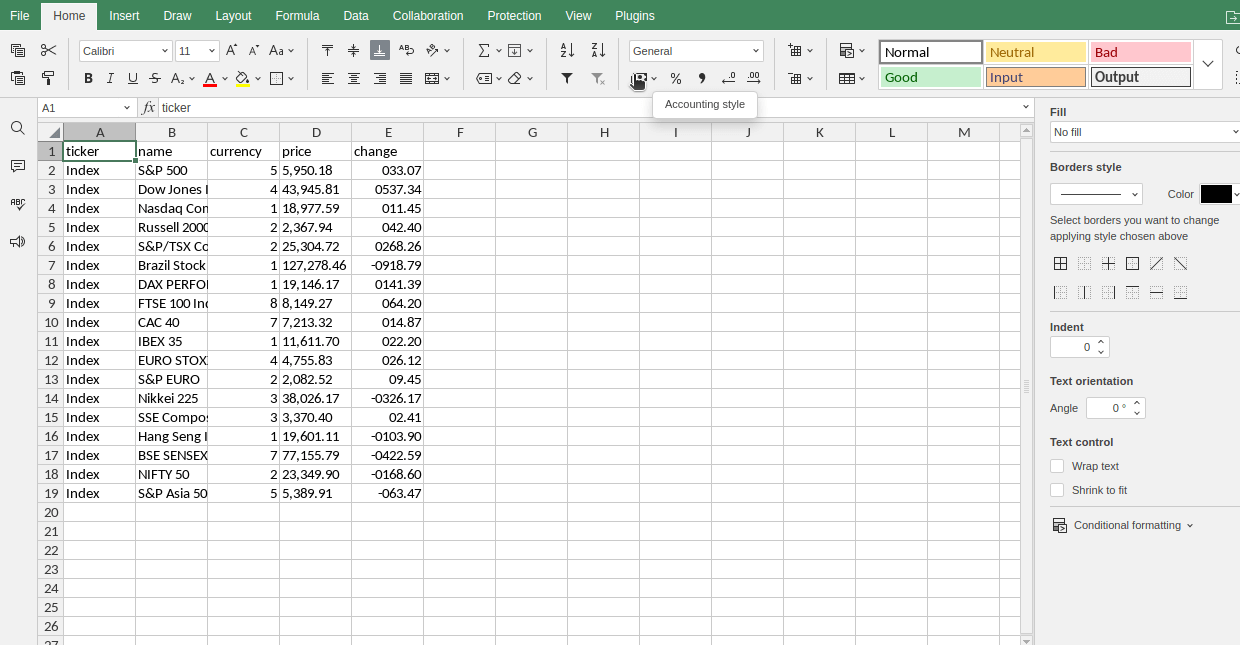
Ganhadores
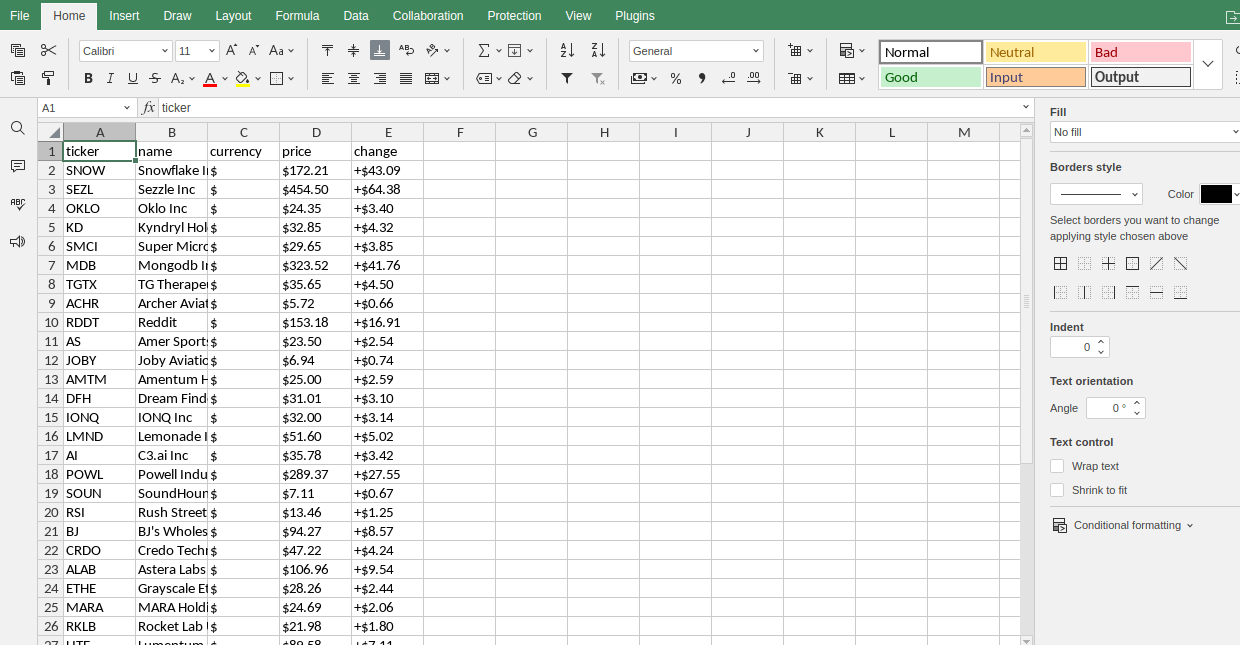
Criptomoedas
Técnicas avançadas
Tratamento da paginação
Tradicionalmente, a paginação é tratada usando números. No Google Finance, usamos nossa matriz de pontos finais para tratar a paginação. Cada item da nossa lista de pontos finais representa uma página individual que desejamos extrair. Dê uma olhada nessa lista novamente. Leia mais aqui sobre como tratar a paginação durante o Scraping de dados.
endpoints = ["ganhadores", "perdedores", "índices", "mais ativos", "criptomoedas"]
Agora, vamos ver como isso é usado. Com a paginação tradicional, você teria um endpoint ou um parâmetro de consulta no qual passaria um número. No entanto, com este Scraper, passamos o endpoint de cada página para nossa URL base.
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
Mitigar bloqueios
Durante nossos testes, não encontramos nenhum problema de bloqueio. No entanto, este mundo não é perfeito e é possível que você encontre algum problema no futuro. Existem várias táticas que você pode usar para contornar qualquer bloqueio que possa encontrar.
Agentes de usuário falsos
Quando você faz uma solicitação a um site (com um navegador ou Python Requests), seu cliente HTTP envia uma string de agente de usuário ao servidor do site. Ela é usada para identificar o aplicativo que está fazendo a solicitação. Para definir um agente de usuário falso em Python, criamos uma string de agente de usuário. Em seguida, a adicionamos aos nossos cabeçalhos.
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
headers = {
"User-Agent": USER_AGENT
}
response = requests.get(f"https://google.com/finance/markets/{endpoint}", headers=headers)
Solicitações cronometradas
Cronometrar nossas solicitações pode ser muito útil. Se algo está solicitando 200 páginas por minuto, provavelmente não é humano. Para contornar a limitação de taxa e parecer mais humano, podemos instruir nosso Scraper a esperar entre as solicitações. Isso faz com que nossa atividade de navegação pareça muito mais normal. Primeiro, você precisa importar sleep de time.
from time import sleep
Em seguida, durma por um período arbitrário entre as solicitações. Isso diminuirá a velocidade do seu Scraper e o fará parecer mais humano.
response = requests.get(f"https://google.com/finance/markets/{endpoint}")
sleep(5)
Considere usar a Bright Data
Rastrear a web pode dar muito trabalho. A Bright Data é um dos melhores provedores de Conjuntos de dados. Com nossos Conjuntos de dados, o Scraping de dados já está feito e você já tem os relatórios. Tudo o que você precisa fazer é baixá-los. Entendemos que o Scraping de dados não é para todos e que algumas pessoas simplesmente querem obter seus dados e usá-los.
Não temos um conjunto de dados do Google Finance, mas temos um conjunto de dados do Yahoo Finance. O Yahoo Finance oferece uma gama mais ampla de dados financeiros e pode facilmente atender às suas necessidades do Google Finance. Mostraremos como adquirir esse conjunto de dados abaixo.
Criando uma conta
Primeiro, você precisa criar uma conta. Acesse nossa página de registro e crie uma conta.
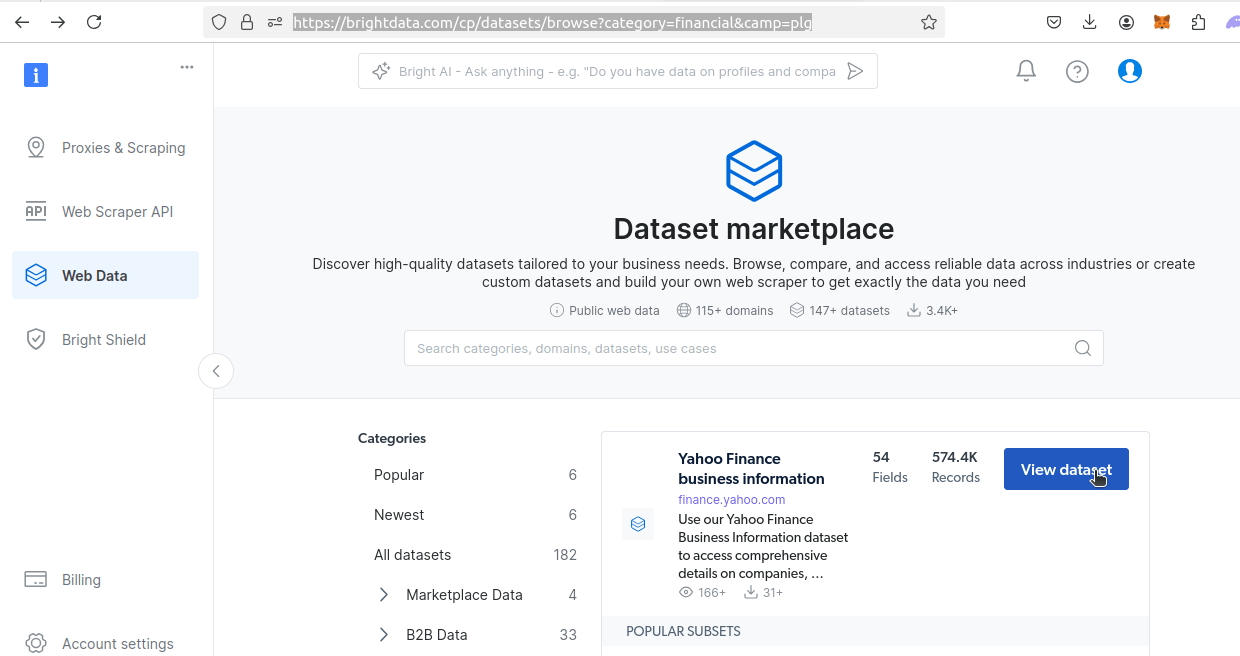
Baixando Conjuntos de dados da Bright Data
Em seguida, acesse nossa página de Conjuntos de dados financeiros. Encontre o conjunto de dados do Yahoo Finance. Clique no botão Exibir conjunto de dados.
Depois de visualizar o conjunto de dados, você terá algumas opções. Você pode baixar um conjunto de dados de amostra ou adquirir o conjunto de dados. O custo é de US$ 0,0025 por registro, com uma compra mínima de US$ 500. Se você quiser o conjunto de dados, clique em “Prosseguir com a compra” e siga o processo de checkout.
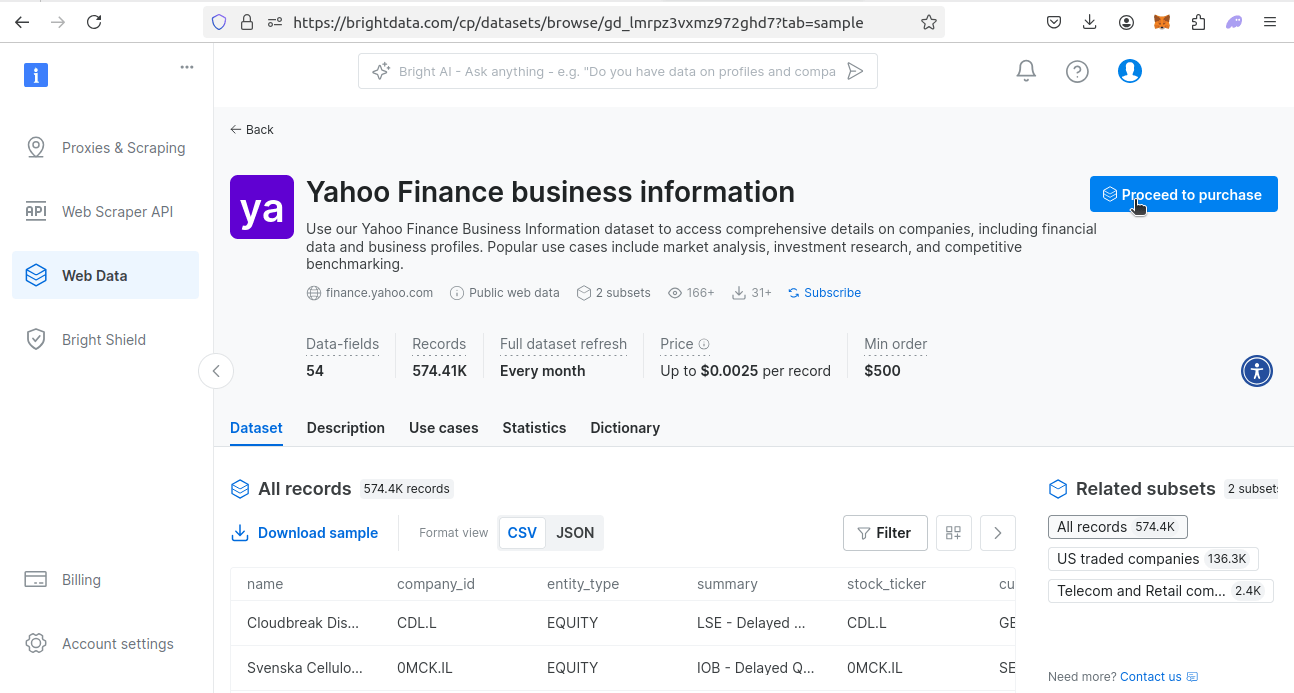
Com nossos conjuntos de dados pré-criados, a extração já está feita para você. Basta obter seus dados e seguir com o seu dia!
Conclusão
Você conseguiu! Dados agregados são uma ferramenta muito valiosa para pessoas em todo o mundo. Agora você sabe como extraí-los do Google Finance e também sabe como obtê-los do nosso conjunto de dados do Yahoo Finance! A esta altura, você já deve saber como criar um Scraper básico usando Python Requests e BeautifulSoup. Você deve saber como usar o método find_all() ao realizar Parsing de objetos de página com o BeautifulSoup.
Também abordamos alguns dos métodos mais avançados, como lidar com paginação com endpoints e mitigar técnicas de bloqueio. Use esse conhecimento e crie um Scraper ou economize tempo e trabalho baixando um de nossos Conjuntos de dados prontos para uso.
Inscreva-se agora e comece seu teste grátis hoje mesmo, incluindo amostras gratuitas de Conjuntos de dados.






