

Este blog discutirá a concorrência e o paralelismo em detalhes para ajudá-lo a escolher o melhor conceito para sua aplicação.
O que é concorrência?
Em termos simples, a concorrência é um conceito usado no desenvolvimento de software para lidar com várias tarefas simultaneamente. No entanto, em teoria, ela não executa todas as tarefas ao mesmo tempo. Em vez disso, permite que o sistema ou aplicativo gerencie várias tarefas simultaneamente, alternando rapidamente entre elas, criando uma ilusão de processamento paralelo. Esse processo também é conhecido como intercalação de tarefas.
Por exemplo, considere um servidor web que precisa lidar com várias solicitações de usuários.
- O usuário 1 envia uma solicitação ao servidor para recuperar dados.
- O usuário 2 envia uma solicitação ao servidor para fazer upload de um arquivo.
- O usuário 3 envia uma solicitação ao servidor para recuperar imagens.
Sem a simultaneidade, cada usuário deve esperar até que a solicitação anterior seja atendida.
- Etapa 1: a CPU começa a processar a solicitação de recuperação de dados na thread 1.
- Etapa 2: enquanto o thread 1 aguarda o resultado, a CPU inicia o processo de upload do arquivo no thread 2.
- Etapa 3: enquanto o thread 2 aguarda o upload do arquivo, a CPU inicia a recuperação de imagens no thread 3.
- Etapa 4: Em seguida, a CPU alterna entre essas três threads com base na disponibilidade de recursos para concluir todas as três tarefas simultaneamente.
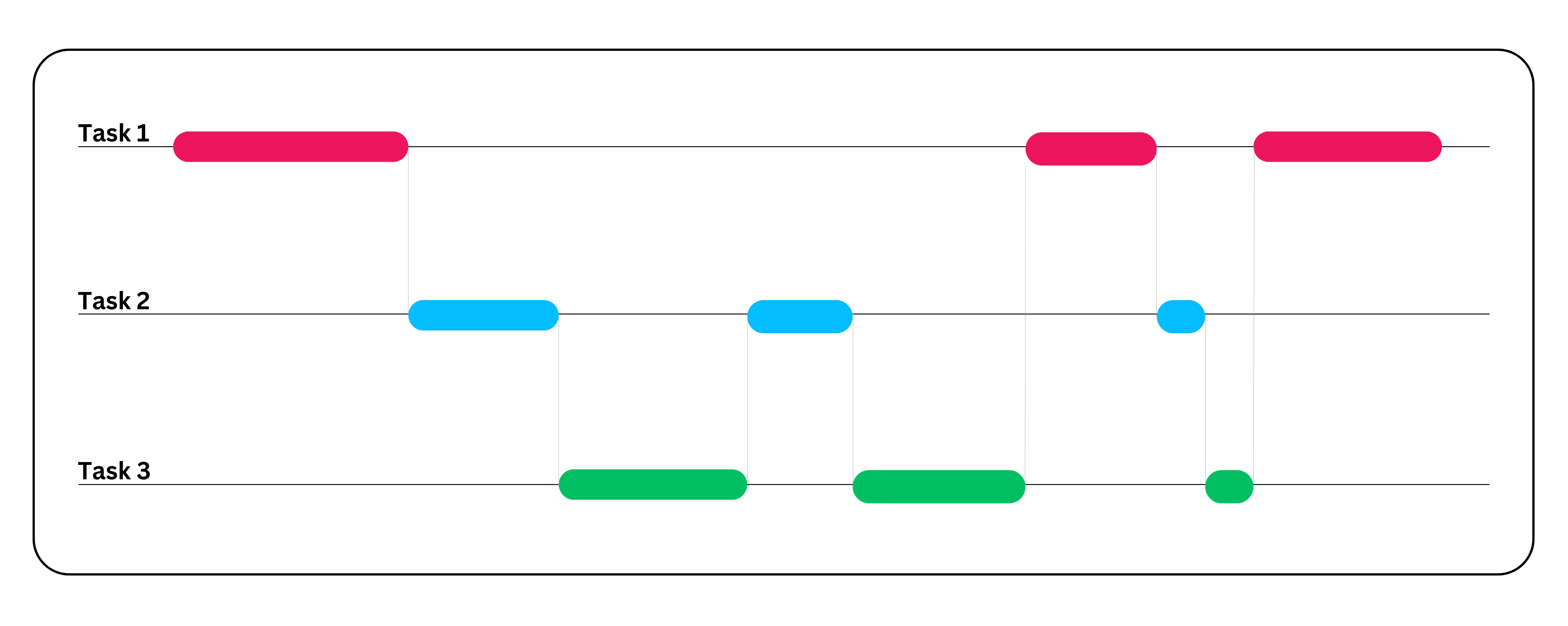
Em comparação com a abordagem de execução síncrona, a abordagem de concorrência é muito mais rápida e extremamente útil para ambientes single-core, a fim de melhorar o tempo de resposta geral do sistema, a utilização de recursos e os recursos de rendimento do sistema. No entanto, a concorrência não se limita ao single-core; ela também pode ser implementada em ambientes multi-core.
Casos de uso da concorrência
- Interfaces de usuário responsivas.
- Servidores web.
- Sistemas em tempo real.
- Operações de rede e E/S.
- Processamento em segundo plano.
Diferentes modelos de concorrência
Com a crescente complexidade e exigências das aplicações modernas, os desenvolvedores introduziram novos modelos de concorrência para resolver as deficiências da abordagem tradicional. Aqui estão alguns modelos de concorrência importantes e suas utilizações:
1. Multitarefa cooperativa
Nesse modelo, as tarefas voluntariamente cedem o controle ao agendador em pontos apropriados, permitindo que ele processe outras tarefas. Essa cedência geralmente ocorre quando a tarefa está ociosa ou aguardando operações de E/S. Esse é um dos modelos mais fáceis de implementar, pois a troca de contexto é gerenciada dentro do código do aplicativo.
Exemplos:
- Sistemas embarcados leves
- Versões antigas do Microsoft Windows (Windows 3.x)
- Mac OS clássico
Aplicações no mundo real:
- Aplicações que utilizam corrotinas, como Python asyncio e Kotlin coroutines.
2. Multitarefa preemptiva
O sistema operacional ou o agendador de tempo de execução força as tarefas a parar e aloca tempo de CPU para outras tarefas com base em um algoritmo de agendamento. Esse modelo garante que todas as tarefas recebam uma parcela igual do tempo de CPU. No entanto, ele requer uma troca de contexto mais complexa.
Exemplos:
- Threads Java gerenciados pela JVM.
- Módulo de threads Python.
Aplicações no mundo real:
- Sistemas operacionais modernos (Windows, macOS, Linux)
- Servidores web.
3. Concorrência orientada a eventos
Neste modelo, as tarefas são divididas em pequenas operações não bloqueantes e enfileiradas em uma fila. Em seguida, elas recebem tarefas da fila, executam a ação necessária e passam para a próxima, mantendo o sistema interativo.
Exemplos:
- Node.js (ambiente de execução JavaScript).
- Padrão async/await do JavaScript.
- Biblioteca asyncio do Python.
Aplicações no mundo real:
- Servidores web como Node.js.
- Aplicações de chat em tempo real.
4. Modelo de ator
Usa atores para enviar e receber mensagens de forma assíncrona. Cada ator processa uma mensagem por vez, evitando o estado compartilhado e reduzindo a necessidade de bloqueios.
Exemplos:
- Estrutura Akka (Java/Scala).
- Linguagem de programaçãoErlang.
- Microsoft Orleans (aplicativos .NET distribuídos).
Aplicações no mundo real:
- Sistemas distribuídos.
- Sistemas de telecomunicações.
- Sistemas de processamento de dados em tempo real.
5. Programação reativa
Este modelo permite criar fluxos de dados (observáveis) e definir como eles devem ser processados (operadores) e como devem reagir (observadores). Ocorrem alterações nos dados ou eventos, que se propagam automaticamente pelos fluxos para todos os observadores inscritos. Essa abordagem facilita o gerenciamento de dados e eventos assíncronos, fornecendo uma maneira clara e declarativa de lidar com fluxos de dados complexos.
Exemplos:
Aplicações no mundo real:
- Pipelines de processamento de dados em tempo real.
- Interfaces de usuário interativas.
- Aplicações que exigem tratamento de dados dinâmico e responsivo.
O que é paralelismo?
O paralelismo é outro conceito popular usado no desenvolvimento de software para lidar com várias tarefas simultaneamente. Ao contrário da concorrência, que cria a ilusão de processamento paralelo ao alternar rapidamente entre tarefas, o paralelismo realmente executa várias tarefas simultaneamente usando vários núcleos de CPU ou processadores. Envolve dividir tarefas maiores em subtarefas menores e independentes que podem ser executadas em paralelo. Esse processo é conhecido como decomposição de tarefas.
Por exemplo, considere um aplicativo de processamento de dados que gera relatórios após realizar análises e executar simulações. Sem paralelismo, isso será executado como uma grande tarefa, levando um tempo significativo para ser concluído. Mas, se você optar pelo paralelismo, a tarefa será concluída muito mais rapidamente por meio da decomposição de tarefas.
Veja como o paralelismo funciona:
- Etapa 1: Divida a tarefa principal em subtarefas independentes. Essas subtarefas devem poder ser executadas sem esperar por entradas de outras tarefas. No entanto, se houver alguma dependência, você precisará programá-las adequadamente para garantir que sejam executadas na ordem correta. Neste exemplo, presumirei que não há dependências entre as subtarefas.
- Subtarefa 1: Realizar análise de dados.
- Subtarefa 2: Gerar relatórios.
- Subtarefa 3: Executar simulações.
- Etapa 2: Atribuir três subtarefas a três núcleos.
- Etapa 3: Por fim, combine os resultados de cada subtarefa para obter o resultado final da tarefa original.
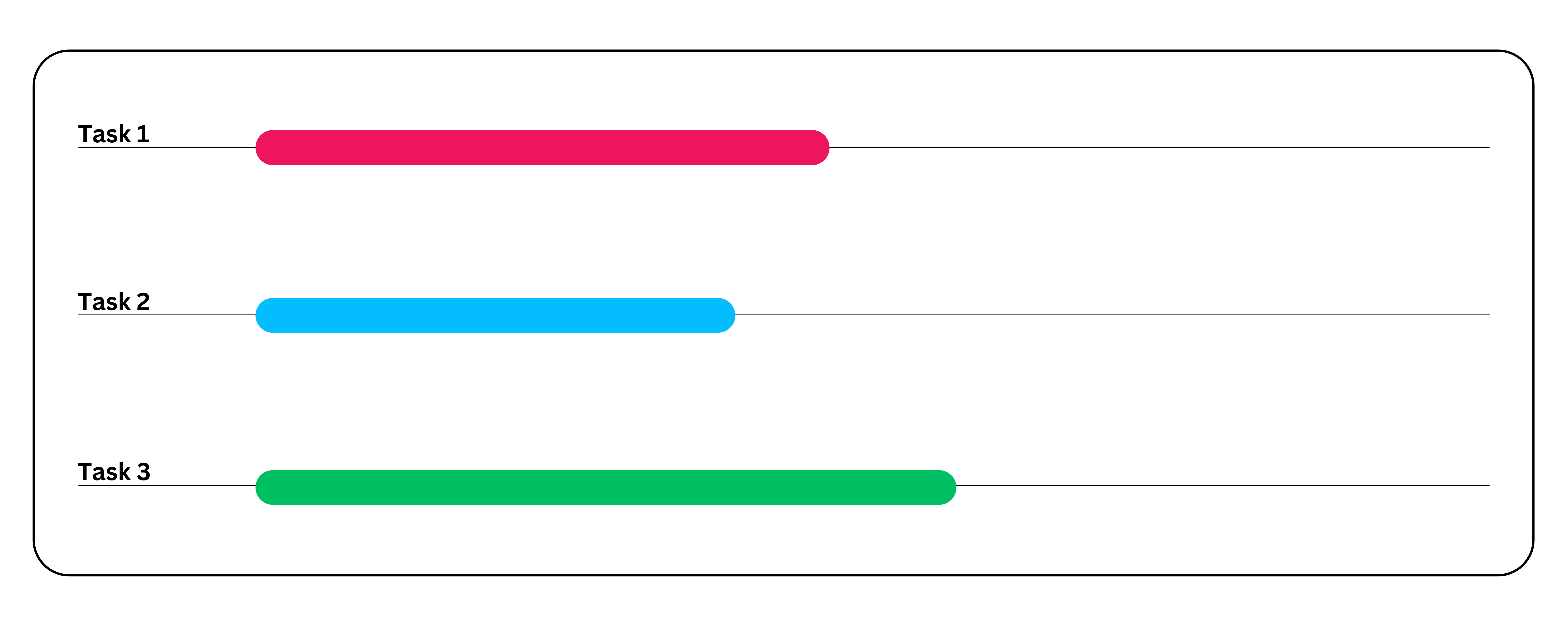
Casos de uso do paralelismo
- Cálculos científicos e simulações.
- Processamento de dados.
- Processamento de imagens.
- Aprendizado de máquina.
- Análise de risco.
Diferentes modelos de paralelismo
Semelhante à concorrência, o paralelismo também possui vários modelos diferentes para utilizar processadores multi-core de forma eficiente e recursos de computação distribuídos. Aqui estão alguns modelos-chave de paralelismo e seus usos:
1. Paralelismo de dados
Este modelo distribui os dados por vários processadores e executa a mesma operação em cada subconjunto de dados simultaneamente. É particularmente eficaz para tarefas que podem ser facilmente divididas em subtarefas independentes.
Exemplos:
- OperaçõesSIMD (Single Instruction, Multiple Data, ou Instrução Única, Dados Múltiplos).
- Processamento paralelo de matrizes.
- Estrutura MapReduce.
Aplicações no mundo real:
- Processamento de imagens e sinais
- Análise de dados em grande escala
- Simulações científicas
2. Paralelismo de tarefas
O paralelismo de tarefas envolve a divisão da tarefa geral em tarefas menores e independentes que podem ser executadas simultaneamente em diferentes processadores. Cada tarefa realiza uma operação diferente.
Exemplos:
- Paralelismo baseado em threads em Java.
- Tarefas paralelas em .NET.
- Threads POSIX.
Aplicações no mundo real:
- Servidores web que lidam com múltiplas solicitações de clientes.
- Implementações de algoritmos paralelos.
- Sistemas de processamento em tempo real.
3. Paralelismo em pipeline
No paralelismo em pipeline, as tarefas são divididas em etapas, e cada etapa é processada em paralelo. Os dados fluem através do pipeline, com cada etapa operando simultaneamente.
Exemplos:
- Comandos de pipeline do Unix.
- Pipelines de processamento de imagens.
- Pipelines de processamento de dados em ferramentas ETL (Extract, Transform, Load).
Aplicações no mundo real:
- Processamento de vídeo e áudio.
- Aplicações de streaming de dados em tempo real.
- Automação da linha de produção e montagem.
4. Modelo Fork/Join
Este modelo envolve dividir uma tarefa em subtarefas menores (fork), executá-las em paralelo e, em seguida, combinar os resultados (join). É útil para algoritmos de dividir para conquistar.
Exemplos:
- Estrutura Fork/Join em Java.
- Algoritmos recursivos paralelos (por exemplo, mergesort paralelo).
- Intel Threading Building Blocks (TBB).
Aplicações no mundo real:
- Tarefas computacionais complexas, como classificação de grandes conjuntos de dados.
- Algoritmos recursivos.
- Cálculos científicos em grande escala.
5. Paralelismo de GPU
O paralelismo de GPU aproveita os recursos de processamento massivamente paralelo das unidades de processamento gráfico (GPUs) para executar milhares de threads simultaneamente, tornando-o ideal para tarefas altamente paralelas.
Exemplos:
- CUDA (Compute Unified Device Architecture) da NVIDIA.
- OpenCL (Open Computing Language).
- TensorFlow para aprendizado profundo.
Aplicações no mundo real:
- Aprendizado de máquina e aprendizado profundo.
- Renderização gráfica em tempo real.
- Computação científica de alto desempenho.
Concorrência x paralelismo
Agora que você já tem um bom entendimento de como a concorrência e o paralelismo funcionam, vamos compará-los em vários aspectos para ver como podemos tirar o melhor proveito de ambos.
1. Utilização de recursos
- Concorrência: executa várias tarefas em um único núcleo, compartilhando recursos entre as tarefas. Por exemplo, a CPU alterna entre tarefas durante períodos de inatividade ou espera.
- Paralelismo: usa vários núcleos ou processadores para executar tarefas simultaneamente.
2. Foco
- Concorrência: concentra-se em gerenciar várias tarefas ao mesmo tempo.
- Paralelismo: concentra-se na execução de várias tarefas ao mesmo tempo.
3. Execução de tarefas
- Concorrência: Tarefas executadas de maneira intercalada. A rápida troca de contexto da CPU cria uma ilusão de execução paralela.
- Paralelismo: as tarefas são executadas de forma verdadeiramente paralela em diferentes processadores ou núcleos.
4. Troca de contexto
- Concorrência: A troca frequente de contexto ocorre quando a CPU alterna entre tarefas para dar a aparência de execução simultânea. Às vezes, isso pode afetar negativamente o desempenho se as tarefas ficarem frequentemente ociosas.
- Paralelismo: Troca de contexto mínima ou inexistente, uma vez que as tarefas são executadas em núcleos ou processadores separados.
5. Casos de uso
- Concorrência: Tarefas vinculadas a E/S, como E/S de disco, comunicação de rede ou entrada do usuário.
- Paralelismo: tarefas vinculadas à CPU que exigem processamento intensivo, como cálculos matemáticos, análise de dados e processamento de imagens.

Podemos usar simultaneidade e paralelismo juntos?
Com base na comparação acima, podemos observar que a concorrência e o paralelismo se complementam em muitas situações. Mas antes de entrarmos em exemplos do mundo real, vamos ver como essa combinação funciona nos bastidores em um ambiente multi-core. Para isso, vamos considerar um servidor web que realiza leitura, gravação e análise de dados.
Etapa 1: Identificação de tarefas
Primeiro, você precisa identificar as tarefas vinculadas a E/S e as tarefas vinculadas à CPU em seu aplicativo. Neste caso:
- Limitada por E/S – Leitura e gravação de dados.
- Limitada pela CPU – Análise de dados.
Etapa 2: Execução simultânea
As tarefas de leitura e gravação de dados podem ser executadas em threads separadas dentro de um único núcleo, pois são tarefas vinculadas a E/S. O servidor usa um loop de eventos para gerenciar essas tarefas e alterna rapidamente entre threads, intercalando a execução da tarefa. Você pode usar uma biblioteca de programação assíncrona como Python asyncio para implementar esse comportamento de simultaneidade.
Etapa 3: Execução paralela
Vários núcleos podem ser atribuídos a tarefas limitadas pela CPU para lidar com elas em paralelo. Nesse caso, a análise de dados pode ser dividida em várias subtarefas e cada subtarefa será executada em um núcleo independente. Você pode usar uma estrutura de execução paralela como Python concurrent.futures para implementar esse comportamento.
Etapa 4: Sincronização e coordenação
Às vezes, threads em execução em núcleos diferentes podem depender uns dos outros. Em tais situações, mecanismos de sincronização como bloqueios e semáforos são necessários para garantir a integridade dos dados e evitar condições de corrida.
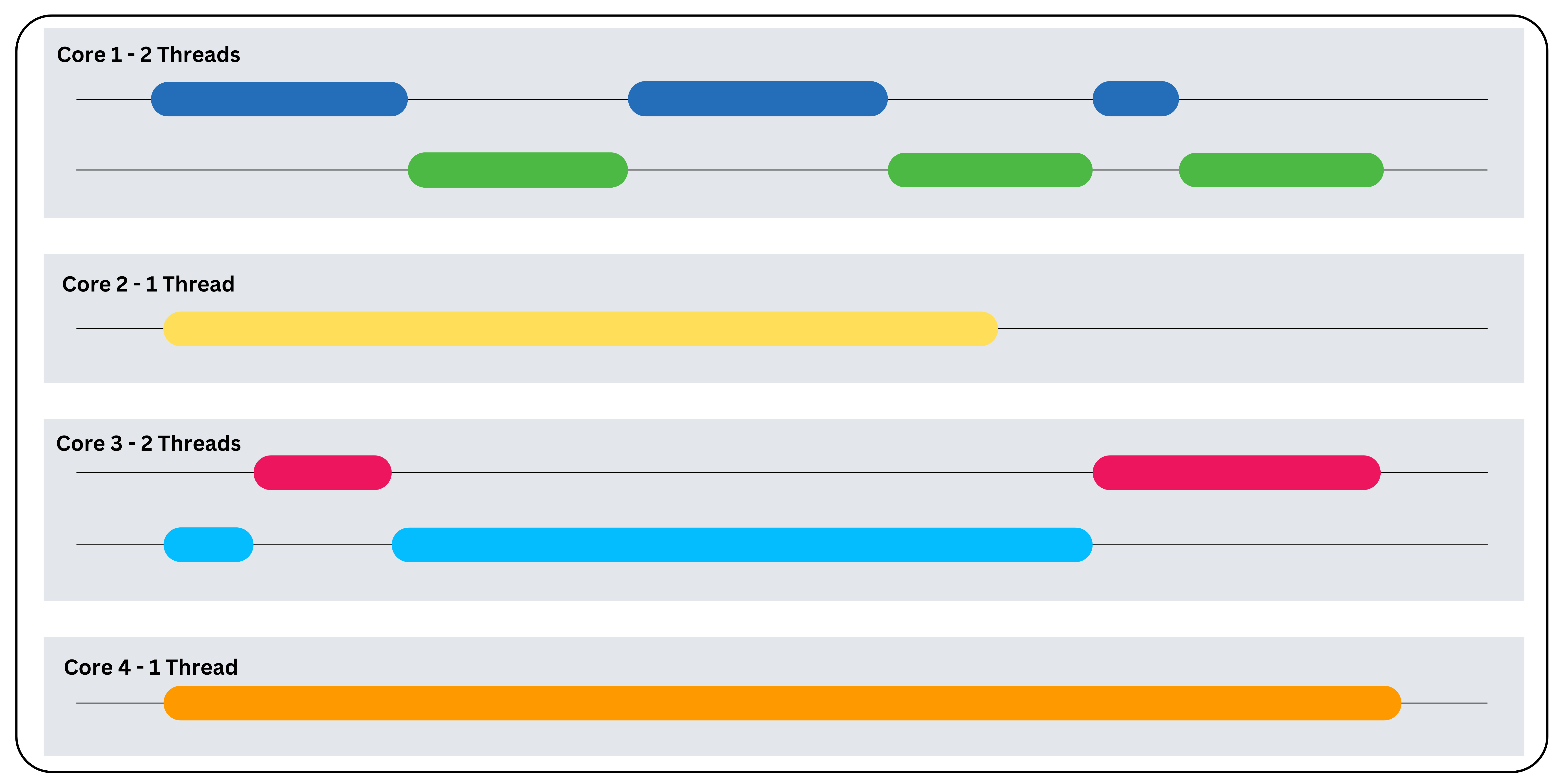
O trecho de código abaixo mostra como usar a concorrência e o paralelismo na mesma aplicação usando Python:
import asyncio
from concurrent.futures import ProcessPoolExecutor
import os
# Simular tarefa vinculada a E/S (leitura de dados)
async def read_data():
await asyncio.sleep(1) # Simular atraso de E/S
data = [1, 2, 3, 4, 5] # Dados fictícios
print("Leitura de dados concluída")
return data
# Simular tarefa vinculada a E/S (gravação de dados)
async def write_data(data):
await asyncio.sleep(1) # Simular atraso de E/S
print(f"Gravação de dados concluída: {data}")
# Simular tarefa vinculada à CPU (análise de dados)
def analyze_data(data):
print(f"Análise de dados iniciada na CPU: {os.getpid()}")
result = [x ** 2 for x in data] # Simular computação
print(f"Análise de dados concluída na CPU: {os.getpid()}")
return result
async def handle_request():
# Concorrência: ler dados de forma assíncrona
data = await read_data()
# Paralelismo: analisar dados em paralelo
loop = asyncio.get_event_loop()
with ProcessPoolExecutor() as executor:
analyzed_data = await loop.run_in_executor(executor, analyze_data, data)
# Concorrência: gravar dados de forma assíncrona
await write_data(analyzed_data)
async def main():
# Simular o tratamento de várias solicitações
await asyncio.gather(handle_request(), handle_request())
# Executar o servidor
asyncio.run(main())
Exemplos reais de combinação de concorrência e paralelismo
Agora, vamos discutir alguns casos de uso comuns em que podemos combinar concorrência e paralelismo para obter o desempenho ideal.
1. Processamento de dados financeiros
As principais tarefas de um sistema de processamento de dados financeiros incluem coleta, processamento e análise de dados, além de atender às operações diárias.
- A concorrência é usada para buscar dados financeiros de vários recursos, como o mercado de ações, usando operações de E/S assíncronas.
- Analisar os dados coletados para gerar relatórios. Essa é uma tarefa que exige muito da CPU, e o paralelismo é usado para executá-la em paralelo, sem afetar as operações diárias.
2. Processamento de vídeo
As principais tarefas de um sistema de processamento de vídeo incluem upload, codificação/decodificação e análise de arquivos de vídeo.
- A concorrência pode ser usada para lidar com várias solicitações de upload de vídeo usando operações de E/S assíncronas. Isso permite que os usuários enviem vídeos sem esperar que outros uploads sejam concluídos.
- O paralelismo é usado para tarefas que exigem muito da CPU, como codificação, decodificação e análise de arquivos de vídeo.
3. Extração de dados
As principais tarefas de um serviço de extração de dados incluem buscar dados de vários sites e realizar Parsing dos dados coletados para obter insights.
- A obtenção de dados pode ser tratada usando a simultaneidade. Isso garante que a coleta de dados seja eficiente e não seja bloqueada enquanto aguarda respostas.
- O paralelismo é usado para processar os dados coletados em vários núcleos da CPU. Ele melhora o processo de tomada de decisão da organização, fornecendo relatórios em tempo real.
Conclusão
Concorrência e paralelismo são dois conceitos-chave usados no desenvolvimento de software para melhorar o desempenho das aplicações. A concorrência permite que várias tarefas sejam executadas simultaneamente, enquanto o paralelismo acelera o processamento de dados usando vários núcleos de CPU. Embora tenham funcionalidades distintas, sua integração pode melhorar significativamente o desempenho de aplicações com tarefas vinculadas a E/S e CPU.
As ferramentas da Bright Data, como as APIs Web Scraper, as funções Web Scraper e o Navegador de scraping, foram projetadas para explorar totalmente essas técnicas e ajudá-lo com os desafios comuns do Scraping de dados da web. Elas usam operações assíncronas para coletar dados de várias fontes simultaneamente e processamento paralelo para analisar e organizar os dados rapidamente. Portanto, escolher um provedor de dados como a Bright Data, que já integrou simultaneidade e paralelismo em seu núcleo, pode economizar tempo e esforço, pois você não precisará implementar esses conceitos do zero durante o Scraping de dados.
Comece o teste grátis hoje mesmo!





