

Neste tutorial sobre como contornar o CAPTCHA do Selenium, você aprenderá:
- O que são CAPTCHAs e se eles podem ser evitados
- Como evitar um CAPTCHA no Selenium
- O que fazer se um CAPTCHA ainda aparecer
Vamos começar!
O que são CAPTCHAs e é possível evitá-los?
CAPTCHA, abreviação de “Completely Automated Public Turing test to tell Computers and Humans Apart” (Teste de Turing público completamente automatizado para diferenciar computadores de humanos), é um mecanismo projetado para diferenciar usuários humanos de bots. Ele apresenta desafios fáceis para os humanos, mas difíceis para as máquinas resolverem. Provedores de CAPTCHA bem conhecidos incluem Google reCAPTCHA, hCaptcha e BotDetect.
Os tipos populares de CAPTCHA incluem:
- Desafios baseados em texto: os usuários precisam digitar uma sequência de letras e números distorcidos.
- Desafios baseados em imagens: os usuários precisam identificar objetos específicos em uma grade de imagens.
- Desafios baseados em áudio: os usuários devem digitar as palavras que ouvem.
- Desafios de quebra-cabeças: os usuários têm a tarefa de resolver quebra-cabeças simples, como navegar em um labirinto.
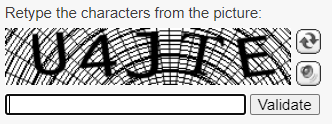
Os CAPTCHAs geralmente fazem parte de fluxos específicos do usuário, como a etapa final de um processo de envio de formulário:
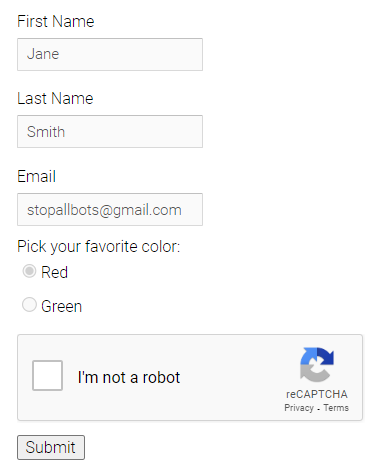
Nesses casos, os CAPTCHAs existem para garantir que os bots não concluam o fluxo do usuário. Para automatizar esses desafios, você pode usar bibliotecas ou serviços de Resolução de CAPTCHA que dependem de operadores humanos para resolver os desafios em tempo real. No entanto, CAPTCHAs codificados são incomuns devido ao seu impacto negativo na experiência do usuário.
Mais frequentemente, os CAPTCHAs fazem parte de soluções abrangentes anti-bot, como um WAF (Web Application Firewall):
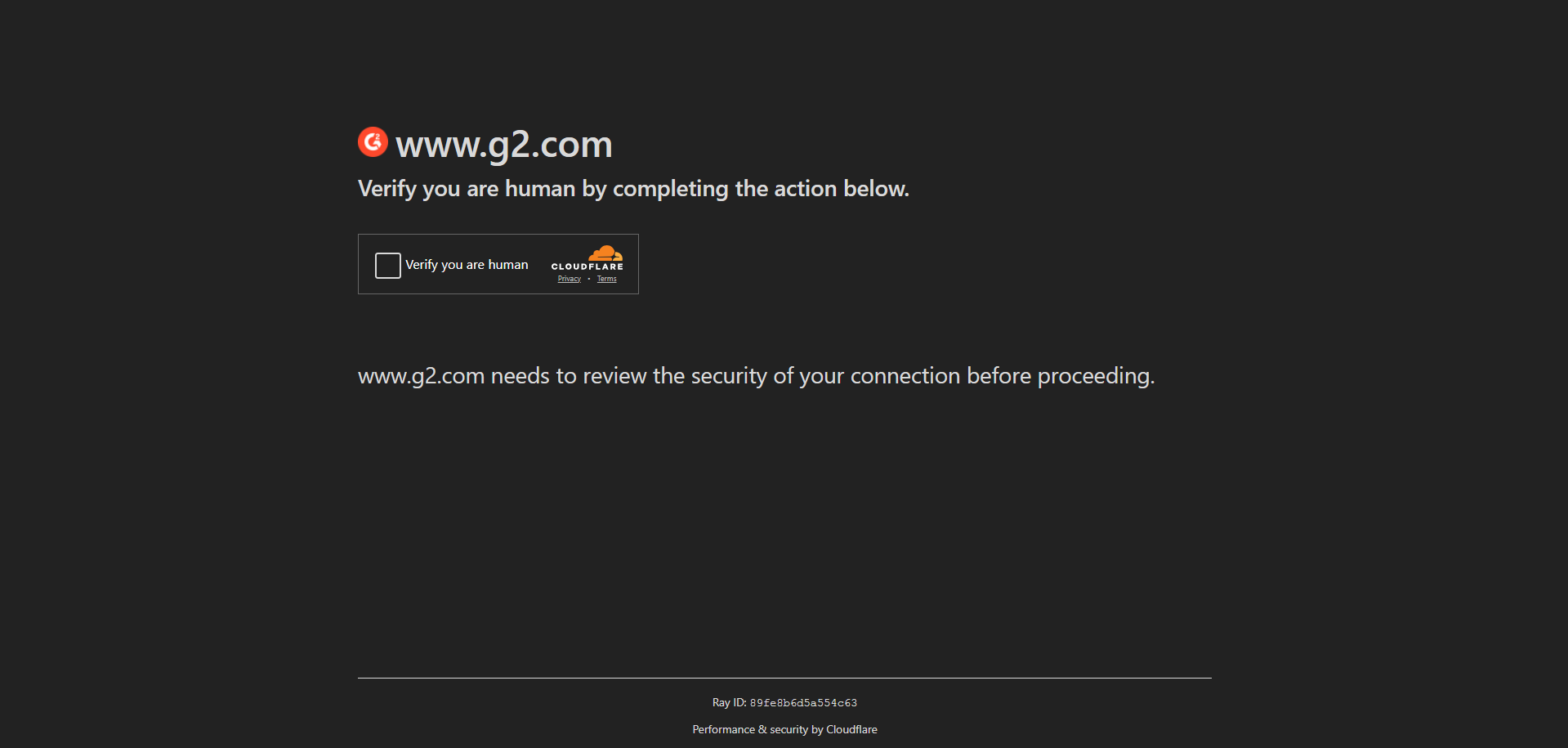
Esses sistemas exibem CAPTCHAs dinamicamente quando suspeitam de atividade de bots. Nesses casos, os CAPTCHAs podem ser contornados fazendo com que seu bot imite o comportamento humano em um navegador do mundo real. Ainda assim, isso requer a atualização constante de seus scripts para se antecipar aos novos métodos de detecção de bots.
Uma solução mais eficaz para evitar CAPTCHAs é usar uma ferramenta de última geração, como o recurso de Resolução de CAPTCHA da Bright Data. Essa ferramenta em nuvem está sempre atualizada e pode lidar com uma ampla variedade de tipos de CAPTCHA para você.
Tratamento de CAPTCHA com Selenium: tutorial passo a passo
Como você acabou de aprender, uma maneira eficaz de evitar CAPTCHAs é fazer com que seu script automatizado imite o comportamento humano enquanto controla um navegador com uma impressão digital do mundo real. Uma das melhores ferramentas para esse fim é o Selenium, uma biblioteca popular de automação de navegadores.
Nesta seção do tutorial, você aprenderá como evitar CAPTCHAs no Selenium usando um script Python. Vamos começar!
Etapa 1: crie um novo projeto Python
Antes de começar, certifique-se de ter o Python 3 e o Chrome instalados localmente.
Se você já tem um script de Scraping de dados ou teste do Selenium, pode pular as três primeiras etapas. Caso contrário, crie uma pasta para o seu projeto de demonstração de bypass de CAPTCHA do Selenium e navegue até ela no terminal:
mkdir selenium_demo
cd selenium_demoEm seguida, adicione um novo ambiente virtual Python dentro dela:
python -m venv venvAbra a pasta do projeto em seu IDE Python favorito e crie um novo arquivo chamado script.py.
Ótimo! A pasta do seu projeto agora contém um aplicativo Python.
Etapa 2: Instale o Selenium
Ative o ambiente virtual Python com o comando abaixo:
venvScriptsactivateOu, de forma equivalente, se você for um usuário Linux ou macOS:
source venv/bin/activateEm seguida, instale o Selenium através do pacote pip para selenium usando este comando:
pip install seleniumO processo de instalação pode demorar um pouco, então seja paciente.
Ótimo! Você está pronto para inicializar seu script Selenium.
Etapa 3: Configure seu script Selenium
Importe o Selenium adicionando a seguinte linha ao script.py:
from selenium import webdriverAgora, crie um objeto ChromeOptions para configurar o Chrome para iniciar no modo headless:
options = webdriver.ChromeOptions()
options.add_argument("--headless")Se você não estiver familiarizado com essa opção, saiba mais em nosso guia sobre navegadores headless.
Inicialize uma instância do Chrome WebDriver com essas opções e, por fim, feche-a com quit(). Este é o aspecto que o seu arquivo script.py deve ter atualmente:
from selenium import webdriver
# configure o Chrome para iniciar no modo headless
options = webdriver.ChromeOptions()
options.add_argument("--headless")
# inicie uma instância do Chrome
driver = webdriver.Chrome(options=options)
# lógica de automação do navegador...
# feche o navegador e libere seus recursos
driver.quit()O script acima inicia uma nova instância do Chrome no modo headless antes de fechar o navegador. Ótimo! É hora de implementar a lógica de automação do navegador.
Etapa 4: adicionar a lógica de automação do navegador
Para avaliar a lógica de bypass do CAPTCHA do Selenium, o script automatizado se conectará ao bot.sannysoft.com e fará uma captura de tela. Essa página da web especial executa vários testes no navegador para determinar se o usuário é um humano ou um bot. Se você visitar a página no seu navegador favorito, verá que todos os testes foram aprovados.
Instrua a instância do Chrome a visitar a página de destino usando o método get():
driver.get("https://bot.sannysoft.com/")Em seguida, você precisa fazer uma captura de tela de toda a página. Infelizmente, o Selenium não oferece uma função para fazer isso diretamente. Como solução alternativa, você pode definir a janela do navegador com a largura e a altura do nó <body> e, em seguida, fazer uma captura de tela:
# obter a largura e a altura do corpo
full_width = driver.execute_script("return document.body.parentNode.scrollWidth")
full_height = driver.execute_script("return document.body.parentNode.scrollHeight")
# definir a janela do navegador para a largura e altura do corpo
driver.set_window_size(full_width, full_height)
# tirar uma captura de tela de toda a página
driver.save_screenshot("screenshot.png")
# restaurar o tamanho original da janela
driver.set_window_size(original_size["width"], original_size["height"])O truque acima funcionará, e screenshot.png conterá a captura de tela de toda a página.
Junte tudo e você terá a seguinte lógica:
from selenium import webdriver
# configurar o Chrome para iniciar no modo headless
options = webdriver.ChromeOptions()
options.add_argument("--headless")
# iniciar uma instância do Chrome
driver = webdriver.Chrome(options=options)
# conectar-se à página de destino
driver.get("https://bot.sannysoft.com/")
# obter o tamanho da janela atual
original_size = driver.get_window_size()
# obter a largura e a altura do corpo
full_width = driver.execute_script("return document.body.parentNode.scrollWidth")
full_height = driver.execute_script("return document.body.parentNode.scrollHeight")
# definir a janela do navegador para a largura e altura do corpo
driver.set_window_size(full_width, full_height)
# tirar uma captura de tela de toda a página
driver.save_screenshot("screenshot.png")
# restaurar o tamanho original da janela
driver.set_window_size(original_size["width"], original_size["height"])
# fechar o navegador e liberar seus recursos
driver.quit()Inicie o arquivo script.py acima com este comando:
python script.pyO script iniciará uma instância do Chromium no modo headless, conectará-se à página desejada, fará uma captura de tela e fechará o navegador. Ao final da execução do script, um arquivo screenshot.png aparecerá na pasta raiz do projeto. Abra-o e você verá:
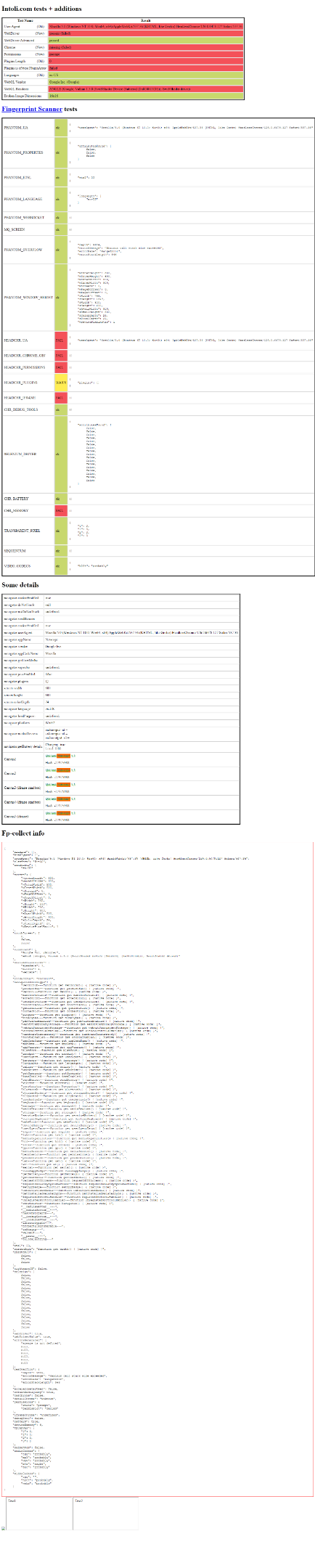
Como você pode ver pelas caixas vermelhas, o Chrome no modo headless controlado via Selenium vanilla não passa em vários testes. Isso significa que seu script provavelmente será detectado como um bot. A consequência é que um site protegido com tecnologia anti-bot pode exibir um CAPTCHA quando você interagir com ele. A solução para evitar um CAPTCHA no Selenium? O plugin Stealth!
Etapa 5: instale o plugin Selenium Stealth
O Selenium Stealth é um pacote Python projetado para tornar a instância do Chrome/Chromium controlada pelo Selenium menos detectável como um bot. O objetivo deste projeto é configurar o navegador para contornar quase todas as estratégias conhecidas de detecção de bots.
Especificamente, o Selenium Stealth modifica as propriedades do navegador para evitar vazamentos que exponham o navegador como automatizado. Se você está familiarizado com soluções de contorno anti-bot, este pacote pode ser visto como uma reimplementação do Puppeteer Stealth.
Instale o Selenium Stealth através do pacote pip selenium-stealth:
pip install selenium-stealthEm seguida, importe a biblioteca adicionando esta linha ao arquivo script.py:
from selenium_stealth import stealthPronto! Agora só falta configurar as definições de ocultação.
Etapa 6: Configure as definições Stealth para evitar CAPTCHAs
Para registrar o Selenium Stealth e configurar o Chrome WebDriver para evitar CAPTCHAs, chame a função stealth() da seguinte maneira:
stealth(
driver,
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36",
languages=["en-US", "en"],
vendor="Google Inc.",
platform="Win32",
webgl_vendor="Intel Inc.",
renderer="Intel Iris OpenGL Engine",
fix_hairline=True,
)Configure os argumentos da função como preferir, mas lembre-se de que os valores acima são suficientes para contornar a maioria das medidas anti-bot.
Muito bem! O navegador controlado pelo Selenium agora aparecerá como um navegador real usado por um usuário humano.
Etapa 7: repita o teste de detecção de bots
Abaixo está o arquivo script.js final:
from selenium import webdriver
from selenium_stealth import stealth
# configure o Chrome para iniciar no modo headless
options = webdriver.ChromeOptions()
options.add_argument("--headless")
# inicie uma instância do Chrome
driver = webdriver.Chrome(options=options)
# configure o WebDriver para evitar a detecção de bots
# com o Selenium Stealth
stealth(
driver,
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36",
languages=["en-US", "en"],
vendor="Google Inc.",
platform="Win32",
webgl_vendor="Intel Inc.",
renderer="Intel Iris OpenGL Engine",
fix_hairline=True,
)
# conectar-se à página de destino
driver.get("https://bot.sannysoft.com/")
# obter o tamanho atual da janela
original_size = driver.get_window_size()
# obter a largura e a altura do corpo
full_width = driver.execute_script("return document.body.parentNode.scrollWidth")
full_height = driver.execute_script("return document.body.parentNode.scrollHeight")
# definir a janela do navegador para a largura e altura do corpo
driver.set_window_size(full_width, full_height)
# tirar uma captura de tela de toda a página
driver.save_screenshot("screenshot.png")
# restaurar o tamanho original da janela
driver.set_window_size(tamanho_original["width"], tamanho_original["height"])
# fechar o navegador e liberar seus recursos
driver.quit()Execute novamente o script Python do Selenium para ignorar o CAPTCHA:
python script.pyDê uma olhada em screenshot.png e você verá que todos os testes de detecção de bots foram aprovados:
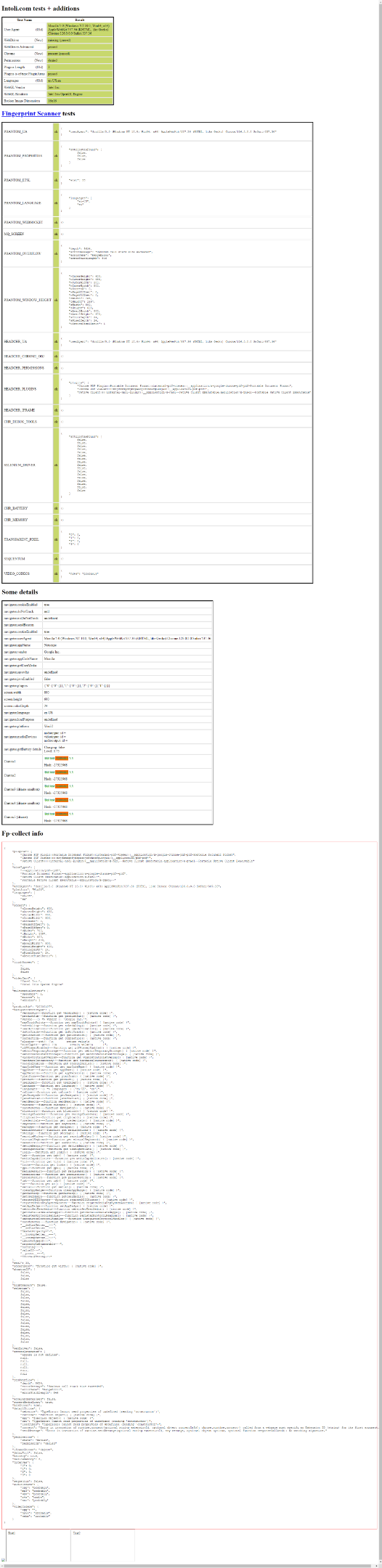
Et voilà! Agora você conhece o truque para evitar CAPTCHAs anti-bot no Selenium.
O que fazer se a solução Selenium para contornar o CAPTCHA acima não funcionar
Infelizmente, as configurações do navegador não são o único aspecto em que as soluções anti-bot se concentram. A reputação do IP é outro aspecto importante, e você não pode simplesmente alterar seu IP para um mais confiável usando uma biblioteca gratuita. Isso requer a integração do Proxy Selenium!
Em outras palavras, mesmo que você configure seu navegador de maneira ideal, os CAPTCHAs ainda podem aparecer. Para CAPTCHAs simples que exigem apenas um único clique, você pode tentar usar pacotes como selenium-recaptcha-solver ou selenium-recptcha. No entanto, essas bibliotecas funcionam apenas com o reCAPTCHA v2 e não são mais mantidas.
O principal problema com a abordagem do capítulo anterior e esses pacotes é que eles funcionam apenas contra CAPTCHAs básicos. Ao lidar com sistemas anti-bot mais complexos, como o Cloudflare, você precisa de uma solução muito mais poderosa.
Procurando uma solução CAPTCHA Selenium real? Experimente as soluções de Scraping de dados da Bright Data!
Elas vêm com recursos superiores de desbloqueio, com um recurso dedicado para a Resolução de CAPTCHA, para lidar automaticamente com reCAPTCHA, hCaptcha, px_captcha, SimpleCaptcha, GeeTest CAPTCHA, FunCaptcha, Cloudflare Turnstile, AWS WAF Captcha, KeyCAPTCHA e muitos outros.
Integrar o CAPTCHA Solver da Bright Data ao seu script é fácil, pois ele funciona com qualquer cliente HTTP ou ferramenta de automação de navegador, incluindo o Selenium.
Saiba mais sobre como usar o CAPTCHA Solver da Bright Data e confira a documentação para obter todos os detalhes de configuração.
Conclusão
Neste artigo, você viu por que os CAPTCHAs são um desafio para softwares automatizados e como lidar com eles no Selenium. Graças à biblioteca Selenium Stealth, você pode substituir as configurações padrão do Chrome para limitar a detecção de bots. No entanto, essa abordagem não é uma solução definitiva.
Independentemente de quão sofisticada seja sua lógica de contorno de CAPTCHA do Selenium, ferramentas avançadas de detecção de bots ainda serão capazes de bloqueá-lo. A solução real é conectar-se ao site de destino por meio de uma API de desbloqueio que pode retornar o HTML sem CAPTCHA de qualquer página da web.
Essa API não é um sonho. Ela existe e se chama Web Unlocker, uma API de scraping que alterna automaticamente seu IP de saída a cada solicitação por meio da integração de Proxy e lida com impressões digitais do navegador, novas tentativas automáticas e resolução de CAPTCHA para você. Lidar com CAPTCHAs nunca foi tão fácil!
Inscreva-se agora e comece seu teste grátis.



