

Neste guia, você aprenderá:
- O que é o LlamaIndex.
- Por que os agentes de IA criados com o LlamaIndex devem ser capazes de realizar pesquisas na Web.
- Como criar um agente de IA LlamaIndex com recursos de pesquisa na Web.
Vamos mergulhar de cabeça!
O que é o LlamaIndex?
O LlamaIndex é uma estrutura Python de código aberto para a criação de aplicativos alimentados por LLMs. Ele serve como uma ponte entre os dados não estruturados e os LLMs. Em particular, ele facilita a orquestração de fluxos de trabalho de LLM em uma variedade de fontes de dados.
Com o LlamaIndex, você pode criar fluxos de trabalho e agentes de IA prontos para a produção. Eles podem pesquisar e recuperar informações relevantes, sintetizar insights, gerar relatórios detalhados, realizar ações automatizadas e muito mais.
No momento em que este artigo foi escrito, ela é uma das bibliotecas de crescimento mais rápido no ecossistema de IA, com mais de 42 mil estrelas no GitHub.
Por que integrar dados de pesquisa na Web ao seu agente de IA LlamaIndex?
Em comparação com outras estruturas de agentes de IA, o LlamaIndex foi criado para resolver uma das maiores limitações dos LLMs. Essa limitação é a falta de conhecimento atualizado do mundo real.
Para resolver esse problema, o LlamaIndex oferece integrações com vários conectores de dados que permitem a ingestão de conteúdo de várias fontes. Agora, você pode se perguntar: qual é a fonte de dados mais valiosa para um agente de IA?
Para responder a essa pergunta, é útil considerar quais fontes de dados são usadas para treinar LLMs. Os LLMs bem-sucedidos receberam a maior parte de seus dados de treinamento da Web, a maior e mais diversificada fonte de dados públicos.
Se você quiser que o agente de IA do LlamaIndex ultrapasse os dados de treinamento estáticos, o principal recurso de que ele precisa é a capacidade de pesquisar na Web e aprender com o que encontrar. Portanto, seu agente deve ser capaz de extrair informações estruturadas das páginas de pesquisa resultantes (chamadas de “SERPs“). Em seguida, processe e aprenda de forma significativa com elas.
O desafio é que a raspagem de SERP se tornou muito mais difícil devido às recentes repressões do Google a scripts simples de raspagem. É por isso que você precisa de uma ferramenta que se integre ao LlamaIndex e simplifique esse processo. É aí que entra a integração com o Bright Data do LlamaIndex!
A Bright Data lida com o trabalho complexo de raspagem de SERP. Por meio de sua ferramenta search_engine, ela permite que seu agente LlamaIndex realize consultas de pesquisa e receba resultados estruturados no formato Markdown ou JSON.
Isso é o que seu agente de IA precisa para estar preparado para responder a perguntas, tanto agora quanto no futuro. Veja como essa integração funciona no próximo capítulo!
Crie um agente LlamaIndex que possa pesquisar na Web usando ferramentas de dados brilhantes
Neste guia passo a passo, você verá como criar um agente de IA Python com o LlamaIndex que pode pesquisar na Web.
Ao fazer a integração com a Bright Data, você permitirá que seu agente acesse dados novos, contextuais e avançados de pesquisa na Web. Para obter mais detalhes, consulte nossa documentação oficial.
Siga as etapas abaixo para criar seu agente SERP de IA com base em dados da Bright Data usando o LlamaIndex!
Pré-requisitos
Para acompanhar este tutorial, você precisa do seguinte:
- Python 3.9 ou superior instalado em seu computador (recomendamos usar a versão mais recente).
- Uma chave de API da Bright Data para integração com as APIs SERP da Bright Data.
- Uma chave de API de um LLM compatível. (Neste guia, usaremos o Gemini, que oferece suporte à integração via API gratuitamente. Ao mesmo tempo, você pode usar qualquer provedor de LLM compatível com o LlamaIndex).
Não se preocupe se você ainda não tiver uma chave de API da Gemini ou da Bright Data. Mostraremos a você como criar ambas nas próximas etapas.
Etapa 1: inicialize seu projeto Python
Comece iniciando o terminal e criando uma nova pasta para o projeto do agente de IA LlamaIndex:
mkdir llamaindex-bright-data-serp-agentllamaindex-bright-data-serp-agent/ conterá todo o código para o seu agente de IA com recursos de pesquisa na Web com a tecnologia Bright Data.
Em seguida, navegue até o diretório do projeto e crie um ambiente virtual Python dentro dele:
cd llamaindex-bright-data-serp-agent
python -m venv venvAgora, abra a pasta do projeto em seu IDE Python favorito. Recomendamos o Visual Studio Code com a extensão Python ou o PyCharm Community Edition.
Crie um novo arquivo chamado agent.py na raiz do diretório do seu projeto. A estrutura de seu projeto deve ser semelhante a esta:
llamaindex-bright-data-serp-agent/
├── venv/
└── agent.pyNo terminal, ative o ambiente virtual. No Linux ou macOS, execute:
source venv/bin/activateDe forma equivalente, no Windows, execute:
venv/Scripts/activateNas próximas etapas, você será orientado na instalação dos pacotes necessários. No entanto, se você quiser instalar tudo antecipadamente, execute:
pip install python-dotenv llama-index-tools-brightdata llama-index-llms-google-genai llama-indexObservação: Estamos instalando o llama-index-llms-google-genai porque este tutorial usa o Gemini como provedor de LLM do LlamaIndex. Se você planeja usar um provedor diferente, certifique-se de instalar a integração LLM correspondente.
Bom trabalho! Seu ambiente de desenvolvimento Python está pronto para criar um agente de IA com a integração SERP da Bright Data usando o LlamaIndex.
Etapa 2: Integrar a leitura das variáveis de ambiente
Seu agente LlamaIndex se conectará a serviços externos como Gemini e Bright Data via API. Por segurança, você nunca deve codificar chaves de API diretamente no seu código Python. Em vez disso, use variáveis de ambiente para mantê-las privadas.
Instale a biblioteca python-dotenv para facilitar o gerenciamento das variáveis de ambiente. Em seu ambiente virtual ativado, inicie:
pip install python-dotenvEm seguida, abra o arquivo agent.py e adicione as seguintes linhas na parte superior para carregar envs de um arquivo .env:
from dotenv import load_dotenv
load_dotenv()load_dotenv() procura um arquivo .env no diretório raiz do seu projeto e carrega seus valores no ambiente.
Agora, crie um arquivo .env junto com o arquivo agent.py. Sua nova estrutura de arquivos de projeto deve ser semelhante a esta:
llamaindex-bright-data-serp-agent/
├── venv/
├── .env # <-------------
└── agent.pyFantástico! Você acabou de configurar uma maneira segura de gerenciar credenciais de API confidenciais para serviços de terceiros.
Continue a configuração inicial preenchendo seu arquivo .env com as variáveis de ambiente necessárias!
Etapa 3: Configurar o Bright Data
Para se conectar às APIs SERP da Bright Data no LlamaIndex por meio do pacote de integração oficial, primeiro você precisa:
- Ative a solução Web Unlocker em seu painel de controle da Bright Data.
- Recupere seu token da API da Bright Data.
Siga as etapas abaixo para concluir a configuração!
Se você ainda não tem uma conta na Bright Data, [crie uma](). Se já tiver uma conta, faça login. No painel de controle, clique no botão “Get proxy products” (Obter produtos proxy):
Você será direcionado para a página “Proxies & Scraping Infrastructure”:
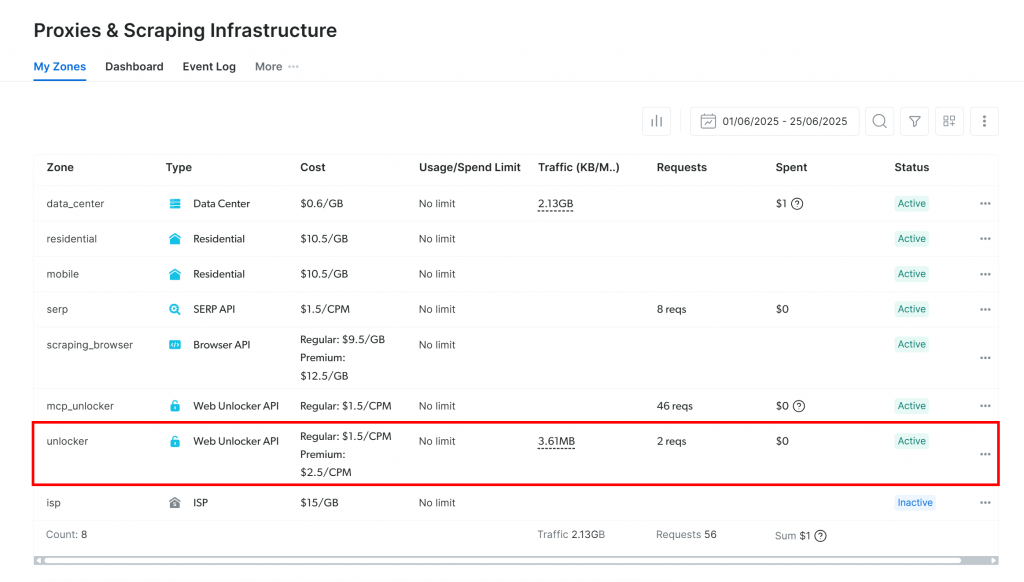
Se você já vir uma zona ativa da API do Web Unlocker (como na imagem acima), está tudo pronto. Anote o nome da zona (por exemplo, unlocker), pois você o usará em seu código posteriormente.
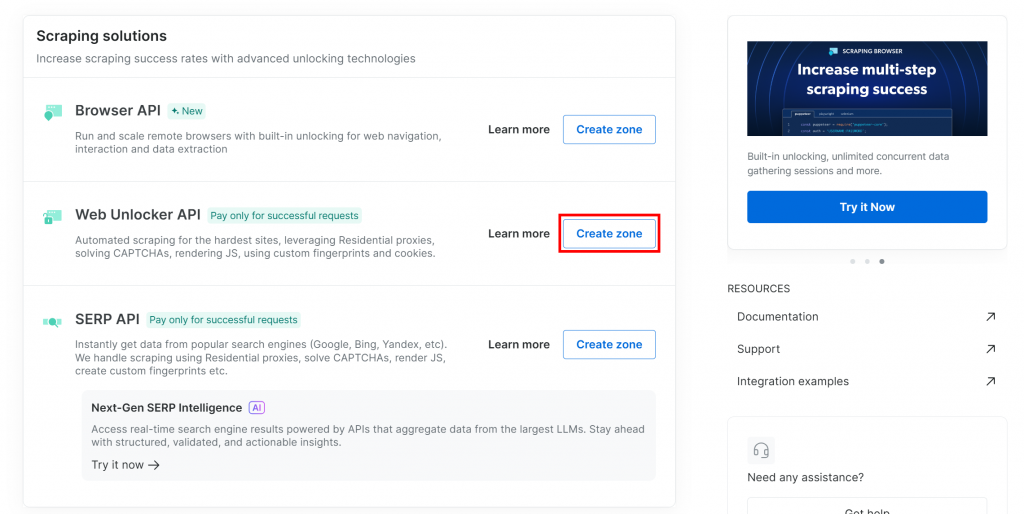
Se você ainda não tiver uma zona do Web Unlocker, role para baixo até a seção “API do Web Unlocker” e pressione o botão “Criar zona”:
Por que usar a API do Web Unlocker em vez da API SERP dedicada?
A integração do LlamaIndex SERP da Bright Data opera por meio da API do Web Unlocker. Especificamente, quando configurado corretamente, o Web Unlocker funciona da mesma forma que as APIs SERP dedicadas. Em resumo, ao configurar uma zona de API do Web Unlocker com a integração da LlamaIndex Bright Data, você também obtém automaticamente acesso às APIs SERP.
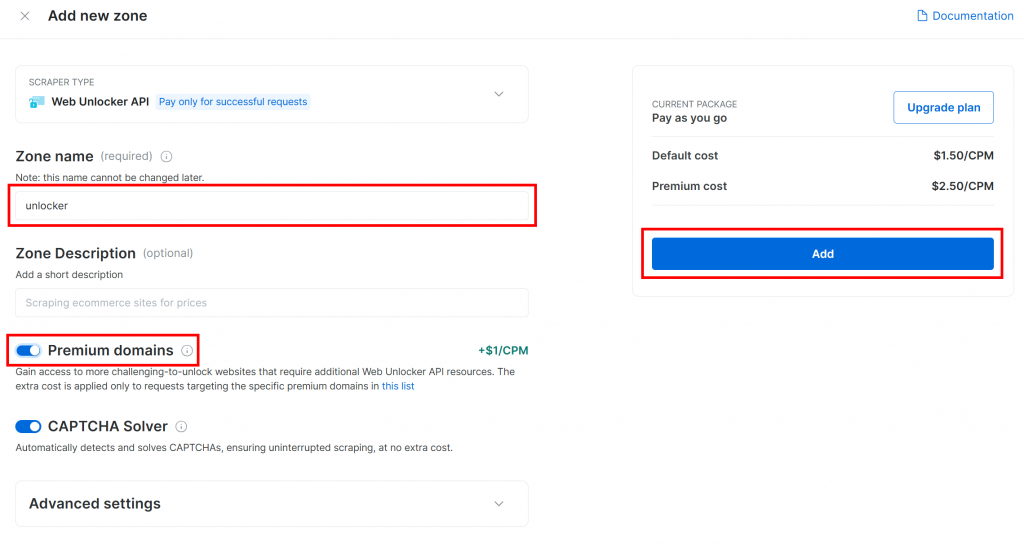
Dê um nome à sua nova zona, como unlocker, ative todos os recursos avançados para melhorar o desempenho e clique em “Add” (Adicionar):
Depois de criada, você será redirecionado para a página de configuração da zona:
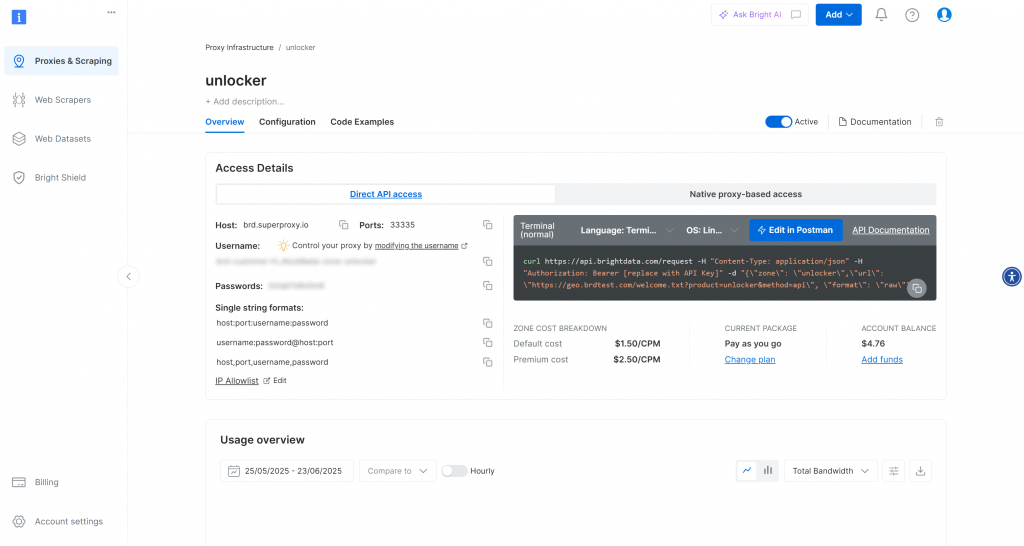
Certifique-se de que o botão de ativação esteja definido para o status “Active” (Ativo). Isso confirma que sua zona está pronta para uso.
Em seguida, siga o guia oficial da Bright Data para gerar sua chave de API. Depois de obter sua chave, armazene-a com segurança em seu arquivo .env da seguinte forma:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Substitua o pelo valor real da chave da API.
Muito bom! Configure a ferramenta SERP da Bright Data em seu script de agente LlamaIndex.
Etapa 4: Acesse a ferramenta SERP LlamaIndex da Bright Data
Em agent.py, comece carregando sua chave da API da Bright Data no ambiente:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Certifique-se de importar os da biblioteca padrão do Python:
import osEm seu ambiente virtual ativado, instale o pacote de ferramentas LlamaIndex Bright Data:
pip install llama-index-tools-brightdataEm seguida, importe a classe BrightDataToolSpec em seu arquivo agent.py:
from llama_index.tools.brightdata import BrightDataToolSpecCrie uma instância do BrightDataToolSpec, fornecendo sua chave de API e o nome da zona do Web Unlocker:
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker", # Replace with the name of your Web Unlocker zone
verbose=True,
)Substitua o valor da zona pelo nome da zona da API do Web Unlocker que você configurou anteriormente (nesse caso, é unlocker).
Observe que a configuração de verbose=True é útil durante o desenvolvimento. Dessa forma, a biblioteca imprimirá registros úteis quando o agente LlamaIndex fizer solicitações por meio do Bright Data.
Agora, o BrightDataToolSpec fornece várias ferramentas, mas aqui estamos nos concentrando na ferramenta search_engine. Ela pode consultar o Google, o Bing, o Yandex e outros, retornando resultados em Markdown ou JSON.
Para extrair apenas essa ferramenta, escreva:
brightdata_serp_tools = brightdata_tool_spec.to_tool_list(["search_engine"])A matriz passada para to_tool_list() funciona como um filtro, incluindo apenas a ferramenta denominada search_engine.
Observação: Por padrão, o LlamaIndex escolherá a ferramenta mais apropriada para uma determinada solicitação do usuário. Portanto, a filtragem de ferramentas não é estritamente necessária. Como este tutorial trata especificamente da integração dos recursos SERP da Bright Data, faz sentido limitá-lo à ferramenta search_engine para maior clareza.
Excelente! A Bright Data agora está integrada e pronta para alimentar seu agente LlamaIndex com recursos de pesquisa na web.
Etapa nº 5: Conectar um modelo LLM
As instruções nesta etapa usam o Gemini como o provedor de LLM para essa integração. Um bom motivo para escolher o Gemini é que ele oferece acesso gratuito à API para alguns de seus modelos.
Para começar a usar o Gemini no LlamaIndex, instale o pacote de integração necessário:
pip install llama-index-llms-google-genaiEm seguida, importe a classe GoogleGenAI em agent.py:
from llama_index.llms.google_genai import GoogleGenAIAgora, inicialize o Gemini LLM da seguinte forma:
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)Neste exemplo, estamos usando o modelo gemini-2.5-flash. Sinta-se à vontade para escolher qualquer outro modelo Gemini compatível.
Nos bastidores, a classe GoogleGenAI procura automaticamente uma variável de ambiente chamada GEMINI_API_KEY. Ela usa a chave de API lida a partir desse ambiente para se conectar às APIs Gemini.
Configure-o abrindo seu arquivo .env e adicionando:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"Substitua o pelo espaço reservado com sua chave real da API do Gemini. Se você ainda não tiver uma, poderá obtê-la gratuitamente seguindo o guia oficial de recuperação da API do Gemini.
Observação: Se você quiser usar um provedor de LLM diferente, o LlamaIndex oferece suporte a várias opções. Basta consultar a documentação oficial do LlamaIndex para obter instruções de configuração.
Muito bem! Agora você tem todas as peças fundamentais para criar um agente de IA LlamaIndex que pode pesquisar na Web.
Etapa nº 6: Definir o agente LlamaIndex
Primeiro, instale o pacote principal do LlamaIndex:
pip install llama-indexEm seguida, em seu arquivo agent.py, importe a classe FunctionAgent:
from llama_index.core.agent.workflow import FunctionAgentFunctionAgent é um agente de IA especializado do LlamaIndex que pode interagir com ferramentas externas, como a ferramenta SERP da Bright Data que você configurou anteriormente.
Inicialize o agente com seu LLM e a ferramenta SERP da Bright Data da seguinte forma:
agent = FunctionAgent(
tools=brightdata_serp_tools,
llm=llm,
verbose=True, # Useful while developing
system_prompt="""
You are a helpful assistant that can retrieve SERP results in JSON format.
"""
)Isso cria um agente de IA que processa a entrada do usuário por meio do seu LLM e pode chamar as ferramentas SERP da Bright Data para realizar pesquisas na Web em tempo real quando necessário. Observe o argumento system_prompt, que define a função e o comportamento do agente. Novamente, o sinalizador verbose=True é útil para inspecionar a atividade interna.
Maravilhoso! A integração do LlamaIndex + Bright Data SERP está concluída. A próxima etapa é implementar o REPL para uso interativo.
Etapa nº 7: criar o REPL
REPL, abreviação de “Read-Eval-Print Loop“, é um padrão de programação interativa em que você insere comandos, faz com que eles sejam avaliados e vê os resultados.
Nesse contexto, o REPL funciona da seguinte forma:
- Você descreve a tarefa que deseja que o agente de IA execute.
- O agente de IA executa a tarefa, fazendo pesquisas on-line, se necessário.
- Você vê a resposta impressa no terminal.
Esse loop continua indefinidamente até que você digite "exit".
No agent.py, adicione essa função assíncrona para lidar com a lógica do REPL:
async def main():
print("Gemini-based agent with web searching capabilities powered by Bright Data. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = await agent.run(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")Essa função REPL:
- Aceita a entrada do usuário da linha de comando por meio de
input(). - Processa a entrada usando o agente LlamaIndex com tecnologia Gemini e Bright Data por meio de
agent.run(). - Exibe a resposta de volta ao console.
Como agent.run() é assíncrono, a lógica do REPL deve estar dentro de uma função assíncrona. Execute-a desta forma na parte inferior do seu arquivo:
if __name__ == "__main__":
asyncio.run(main())Não se esqueça de importar o asyncio:
import asyncioAqui vamos nós! O agente de IA LlamaIndex com ferramentas de raspagem de SERP está pronto.
Etapa 8: Junte tudo e execute o agente de IA
Isso é o que seu arquivo agent.py deve conter:
from dotenv import load_dotenv
import os
from llama_index.tools.brightdata import BrightDataToolSpec
from llama_index.llms.google_genai import GoogleGenAI
from llama_index.core.agent.workflow import FunctionAgent
import asyncio
# Load environment variables from the .env file
load_dotenv()
# Read the Bright Data API key from the envs
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Set up the Bright Data Tools
brightdata_tool_spec = BrightDataToolSpec(
api_key=BRIGHT_DATA_API_KEY,
zone="unlocker", # Replace with the name of your Web Unlocker zone
verbose=True, # Useful while developing
)
# Get only the "search_engine" (SERP scraping) tool
brightdata_serp_tools = brightdata_tool_spec.to_tool_list(["search_engine"])
# Configure the connection to Gemini
llm = GoogleGenAI(
model="models/gemini-2.5-flash",
)
# Create the LlamaIndex agent powered by Gemini and connected to Bright Data tools
agent = FunctionAgent(
tools=brightdata_serp_tools,
llm=llm,
verbose=True, # Useful while developing
system_prompt="""
You are a helpful assistant that can retrieve SERP results in JSON format.
"""
)
# Async REPL loop
async def main():
print("Gemini-based agent with web searching capabilities powered by Bright Data. Type 'exit' to quit.n")
while True:
# Read the user request for the AI agent from the CLI
request = input("Request -> ")
# Terminate the execution if the user type "exit"
if request.strip().lower() == "exit":
print("nAgent terminated")
break
try:
# Execute the request
response = await agent.run(request)
print(f"nResponse ->:n{response}n")
except Exception as e:
print(f"nError: {str(e)}n")
if __name__ == "__main__":
asyncio.run(main())Execute seu agente SERP LlamaIndex com:
python agent.pyQuando o script for iniciado, você verá um prompt como este em seu terminal:

Tente solicitar ao seu agente algo que exija novas informações, por exemplo:
Write a short Markdown report on the new AI protocols, including some real-world links for further reading.Para realizar essa tarefa com eficiência, o agente de IA precisa pesquisar na Web informações atualizadas.
O resultado será:
Isso foi muito rápido, então vamos detalhar o que aconteceu:
- O agente detecta a necessidade de pesquisar “novos protocolos de IA” e chama a API SERP da Bright Data por meio da ferramenta search_engine usando este URL de entrada:
https://www.google.com/search?q=new%20AI%20protocols&num=10&brd_json=1. - A ferramenta busca de forma assíncrona os dados SERP no formato JSON da API de pesquisa do Google da Bright Data.
- O agente passa a resposta JSON para o Gemini LLM.
- O Gemini processa os novos dados e gera um relatório Markdown claro e preciso com links relevantes.
Nesse caso, o agente de IA retornou:
## New AI Protocols: A Brief Report
The rapid advancement of Artificial Intelligence has led to the emergence of new protocols designed to enhance interoperability, communication, and data handling among AI systems and with external data sources. These protocols aim to standardize how AI agents interact, leading to more scalable and integrated AI deployments.
Here are some of the key new AI protocols:
### 1. Model Context Protocol (MCP)
The Model Context Protocol (MCP) is an open standard that facilitates secure, two-way connections between AI-powered tools and various data sources. It fundamentally changes how AI assistants interact with the digital world by allowing them to access and utilize external information more effectively. This protocol is crucial for enabling AI models to communicate with external data sources and for building more capable and context-aware AI applications.
**Further Reading:**
* **Introducing the Model Context Protocol:** [https://www.anthropic.com/news/model-context-protocol](https://www.anthropic.com/news/model-context-protocol)
* **How A Simple Protocol Is Changing Everything About AI:** [https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/](https://www.forbes.com/sites/craigsmith/2025/04/07/how-a-simple-protocol-is-changing-everything-about-ai/)
* **The New Model Context Protocol for AI Agents:** [https://evergreen.insightglobal.com/the-new-model-context-protocol-for-ai-agents/](https://evergreen.insightglobal.com/the-new-model-context-protocol-for-ai-agents/)
* **Model Context Protocol: The New Standard for AI Interoperability:** [https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/](https://techstrong.ai/aiops/model-context-protocol-the-new-standard-for-ai-interoperability/)
* **Hot new protocol glues together AI and apps:** [https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-source](https://www.axios.com/2025/04/17/model-context-protocol-anthropic-open-source)
### 2. Agent2Agent Protocol (A2A)
The Agent2Agent Protocol (A2A) is a cross-platform specification designed to enable AI agents to communicate with each other, securely exchange information, and coordinate actions. This protocol is vital for fostering collaboration among different AI agents, allowing them to work together on complex tasks and delegate responsibilities across various enterprise systems.
**Further Reading:**
* **Announcing the Agent2Agent Protocol (A2A):** [https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/](https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/)
* **What Every AI Engineer Should Know About A2A, MCP & ACP:** [https://medium.com/@elisowski/what-every-ai-engineer-should-know-about-a2a-mcp-acp-8335a210a742](https://medium.com/@elisowski/what-every-ai-engineer-should-know-about-a2a-mcp-acp-8335a210a742)
* **What a new AI protocol means for journalists:** [https://www.dw.com/en/what-coding-agents-and-a-new-ai-protocol-mean-for-journalists/a-72976193](https://www.dw.com/en/what-coding-agents-and-a-new-ai-protocol-mean-for-journalists/a-72976193)
### 3. Agent Communication Protocol (ACP)
The Agent Communication Protocol (ACP) is an open standard specifically for agent-to-agent communication. Its purpose is to transform the current landscape of siloed AI agents into interoperable agentic systems, promoting easier integration and collaboration between them. ACP provides a standardized messaging framework for structured communication.
**Further Reading:**
* **MCP, ACP, and Agent2Agent set standards for scalable AI:** [https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html](https://www.cio.com/article/3991302/ai-protocols-set-standards-for-scalable-results.html)
* **What is Agent Communication Protocol (ACP)?** [https://www.ibm.com/think/topics/agent-communication-protocol](https://www.ibm.com/think/topics/agent-communication-protocol)
* **MCP vs A2A vs ACP: AI Protocols Explained:** [https://www.bluebash.co/blog/mcp-vs-a2a-vs-acp-agent-communication-protocols/](https://www.bluebash.co/blog/mcp-vs-a2a-vs-acp-agent-communication-protocols/)
These emerging protocols are crucial steps towards a more interconnected and efficient AI ecosystem, enabling more sophisticated and collaborative AI applications across various industries.Observe que a resposta do agente de IA inclui protocolos recentes e links atualizados publicados após a última atualização de treinamento do Gemini. Isso destaca o valor da integração de recursos de pesquisa na Web em tempo real.
Mais especificamente, a resposta inclui links contextuais que se aproximam do que você encontraria ao pesquisar “novos protocolos de IA” no Google:
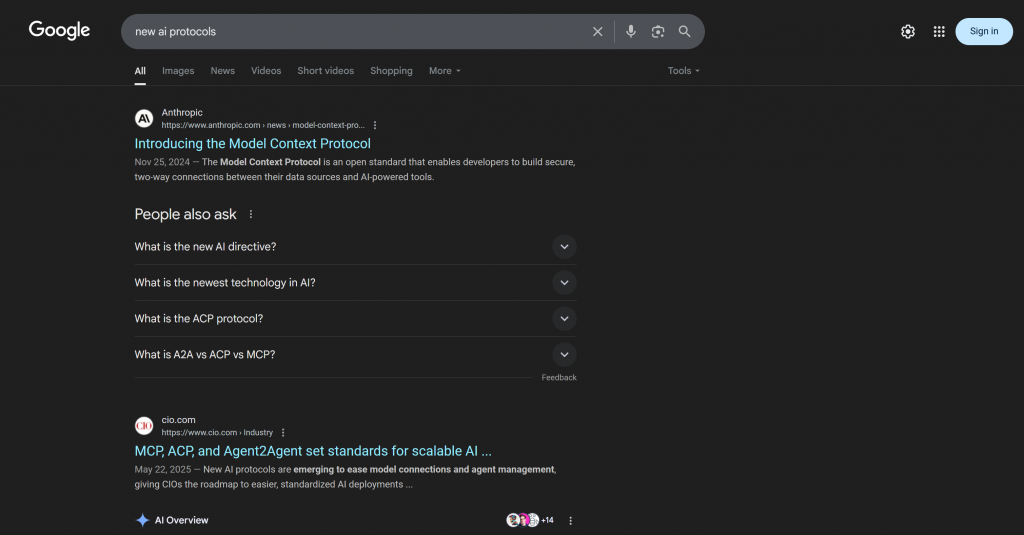
Observe que a resposta inclui muitos dos mesmos links que você encontraria na SERP real de “novos protocolos de IA” (pelo menos no momento em que este artigo foi escrito).
E pronto! Agora você tem um agente de IA do LlamaIndex com recursos de raspagem de mecanismos de pesquisa, com a tecnologia da Bright Data.
Etapa #9: Próximas etapas
O atual agente de IA SERP do LlamaIndex é apenas um exemplo simples que usa somente a ferramenta search_engine da Bright Data.
Em cenários mais avançados, é provável que você não queira restringir seu agente a uma única ferramenta. Em vez disso, é melhor dar ao seu agente acesso a todas as ferramentas disponíveis e escrever um prompt de sistema claro que ajude o LLM a decidir quais delas usar para cada objetivo.
Por exemplo, você poderia estender seu prompt para ir um pouco além e:
- Realizar várias consultas de pesquisa.
- Selecione os N principais links dos resultados da SERP.
- Visite essas páginas e extraia o conteúdo delas em Markdown.
- Aprenda com essas informações para produzir um resultado mais rico e detalhado.
Para obter mais orientações sobre a integração com todas as ferramentas disponíveis, consulte nosso tutorial sobre a criação de agentes de IA com o LlamaIndex e o Bright Data.
Conclusão
Neste artigo, você aprendeu a usar o LlamaIndex para criar um agente de IA capaz de pesquisar na Web por meio do Bright Data. Essa integração permite que seu agente execute consultas de pesquisa nos principais mecanismos de pesquisa, incluindo Google, Bing, Yandex e muitos outros.
Lembre-se de que o exemplo abordado aqui é apenas um ponto de partida. Se você planeja desenvolver agentes mais avançados, precisará de ferramentas robustas para recuperar, validar e transformar dados da Web em tempo real. É exatamente isso que a infraestrutura de IA da Bright Data para agentes oferece.
Crie uma conta gratuita na Bright Data e comece a explorar nossas ferramentas de dados de IA autêntica hoje mesmo!




