

A pesquisa manual de conteúdo em dezenas de resultados de pesquisa do Google leva muito tempo e, muitas vezes, deixa passar insights importantes dispersos em várias fontes. A raspagem tradicional da Web fornece HTML bruto, mas não tem a inteligência necessária para sintetizar as informações em narrativas coerentes. Este guia mostra como criar um sistema com tecnologia de IA que raspa automaticamente os resultados de SERP do Google, analisa o conteúdo usando incorporação e gera artigos ou esboços abrangentes.
Você aprenderá:
- Como criar um pipeline automatizado de pesquisa para artigo usando Bright Data e embeddings vetoriais
- Como analisar semanticamente o conteúdo raspado e identificar temas recorrentes
- Como gerar esboços estruturados e artigos completos usando LLMs
- Como criar uma interface Streamlit interativa para geração de conteúdo
Vamos começar!
Os desafios da pesquisa para a criação de conteúdo
Os criadores de conteúdo enfrentam obstáculos significativos ao pesquisar tópicos para artigos, postagens de blog ou materiais de marketing. A pesquisa manual envolve a abertura de dezenas de guias do navegador, a leitura de artigos extensos e a tentativa de sintetizar informações de fontes diferentes. Esse processo é propenso a erros humanos, consome muito tempo e é difícil de dimensionar.
As abordagens tradicionais de raspagem da Web usando BeautifulSoup ou Scrapy fornecem texto HTML bruto, mas não têm a inteligência necessária para entender o contexto do conteúdo, identificar os principais temas ou sintetizar informações de várias fontes. O resultado é uma coleção de texto não estruturado que ainda exige um processamento manual significativo.
A combinação dos robustos recursos de raspagem da Bright Data com técnicas modernas de IA, como incorporação de vetores e grandes modelos de linguagem, automatiza todo o pipeline de pesquisa para artigo. Isso transforma horas de trabalho manual em minutos de análise automatizada.
O que estamos construindo: Sistema de pesquisa de conteúdo com tecnologia de IA
Você criará um sistema inteligente de geração de conteúdo que extrai automaticamente os resultados de pesquisa do Google para qualquer palavra-chave. O sistema extrai o conteúdo completo das páginas da Web de destino, analisa as informações usando embeddings vetoriais para identificar temas e insights e gera esboços de artigos estruturados ou rascunhos completos de artigos por meio de uma interface Streamlit intuitiva.
Pré-requisitos
Configure seu ambiente de desenvolvimento com estes requisitos:
- Python 3.9 ou superior
- Conta da Bright Data: Registre-se e crie um token de API (créditos de avaliação gratuitos disponíveis)
- Chave de API da OpenAI: Crie uma chave em seu painel do OpenAI para acesso a embeddings e LLM
- Ambiente virtual Python: Mantém as dependências isoladas
- LangChain + Vector Embeddings (FAISS): Cuida da análise e do armazenamento de conteúdo.
- Streamlit: Fornece a interface de usuário interativa, permitindo que os usuários utilizem a ferramenta.
Configuração do ambiente
Crie o diretório do seu projeto e instale as dependências. Comece configurando um ambiente virtual limpo para evitar conflitos com outros projetos Python.
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install langchain langchain-community langchain-openai streamlit "crewai-tools[mcp]" crewai mcp python-dotenvCrie um novo arquivo chamado article_generator.py e adicione as seguintes importações. Essas bibliotecas lidam com a extração da Web, o processamento de texto, as incorporações e a interface do usuário.
importar streamlit como st
importar os
importar json
from dotenv import load_dotenv
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, OpenAI
from langchain_community.vectorstores import FAISS
from mcp import StdioServerParameters
from crewai_tools import MCPServerAdapter
load_dotenv()Configuração de dados brilhantes
Armazene suas credenciais de API de forma segura usando variáveis de ambiente. Crie um arquivo .env para armazenar suas credenciais, mantendo as informações confidenciais separadas do seu código.
BRIGHT_DATA_API_TOKEN="your_bright_data_api_token_here"
BRIGHT_DATA_ZONE="seu_nome_da_zona_serp"
OPENAI_API_KEY="sua_openai_api_key_aqui"Você precisa:
- Token da API da Bright Data: Gerar a partir de seu painel de controle da Bright Data
- Zona de coleta de SERP: Criar uma nova zona do Web Scraper configurada para o Google SERP
- Chave da API da OpenAI: Para geração de texto LLM e embeddings
Configure as conexões de API em article_generator.py. Essa classe lida com toda a comunicação com a infraestrutura de raspagem da Bright Data.
classe BrightDataScraper:
def __init__(self):
self.server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": "mcp_unlocker",
"BROWSER_ZONE": "scraping_browser1",
},
)
def scrape_serp(self, keyword, num_results=10):
with MCPServerAdapter(self.server_params) as mcp_tools:
try:
if not mcp_tools:
st.warning("Não há ferramentas MCP disponíveis")
return {'results': []}
for tool in mcp_tools:
try:
tool_name = getattr(tool, 'name', str(tool))
if 'search_engine' in tool_name and 'batch' not in tool_name:
try:
if hasattr(tool, '_run'):
result = tool._run(query=keyword)
elif hasattr(tool, 'run'):
result = tool.run(query=keyword)
elif hasattr(tool, '__call__'):
result = tool(query=keyword)
else:
result = tool.search_engine(query=keyword)
if result:
return self._parse_serp_results(result)
exceto Exception as method_error:
st.warning(f "O método falhou para {tool_name}: {str(method_error)}")
continue
exceto Exception as tool_error:
st.warning(f "A ferramenta {tool_name} falhou: {str(tool_error)}")
continue
st.warning(f "Nenhuma ferramenta do mecanismo de pesquisa pôde processar: {palavra-chave}")
return {'results': []}
except Exception as e:
st.error(f "MCP scraping failed: {str(e)}")
return {'results': []}
def _parse_serp_results(self, mcp_result):
"""Analisar os resultados da ferramenta MCP no formato esperado."""
if isinstance(mcp_result, dict) and 'results' in mcp_result:
return mcp_result
elif isinstance(mcp_result, list):
return {'results': mcp_result}
elif isinstance(mcp_result, str):
return self._parse_html_search_results(mcp_result)
else:
try:
parsed = json.loads(str(mcp_result))
return parsed if isinstance(parsed, dict) else {'results': parsed}
except:
return {'results': []}
def _parse_html_search_results(self, html_content):
"""Analisar a página de resultados de pesquisa em HTML para extrair os resultados da pesquisa."""
import re
resultados = []
link_pattern = r'<a[^>]*href="([^"]*)"[^>]*>(.*?)</a>'
title_pattern = r'<h3[^>]*>(.*?)</h3>'
links = re.findall(link_pattern, html_content, re.DOTALL)
para link_url, link_text em links:
if (link_url.startswith('http') and
not any(skip in link_url for skip in [
'google.com', 'accounts.google', 'support.google',
'/search?', 'javascript:', '#', 'mailto:'
])):
clean_title = re.sub(r'<[^>]+>', '', link_text).strip()
if clean_title and len(clean_title) > 10:
results.append({
'url': link_url,
'title': clean_title[:200],
'snippet': '',
'position': len(results) + 1
})
se len(results) >= 10:
break
if not results:
specific_pattern = r'[(.*?)]((https?://[^)]+))'
matches = re.findall(specific_pattern, html_content)
for title, url in matches:
if not any(skip in url for skip in ['google.com', '/search?']):
results.append({
'url': url,
'title': title.strip(),
'snippet': '',
'position': len(results) + 1
})
se len(resultados) >= 10:
break
return {'results': results}Criação do gerador de artigos
Etapa 1: raspar SERP e páginas de destino
A base do nosso sistema é a coleta abrangente de dados. Você precisa criar um raspador que primeiro extraia os resultados da SERP do Google e, em seguida, siga esses links para coletar o conteúdo da página inteira das fontes mais relevantes.
classe ContentScraper:
def __init__(self):
self.bright_data = BrightDataScraper()
self.server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": "mcp_unlocker",
"BROWSER_ZONE": "scraping_browser1",
},
)
def extract_serp_urls(self, keyword, max_results=10):
"""Extrai URLs dos resultados da SERP do Google."""
serp_data = self.bright_data.scrape_serp(keyword, max_results)
urls = []
lista_de_resultados = serp_data.get('resultados', [])
for result in results_list:
if 'url' in result and self.is_valid_url(result['url']):
urls.append({
'url': result['url'],
'title': result.get('title', ''),
'snippet': result.get('snippet', ''),
'position': result.get('position', 0)
})
elif 'link' in result and self.is_valid_url(result['link']):
urls.append({
'url': result['link'],
'title': result.get('title', ''),
'snippet': result.get('snippet', ''),
'position': result.get('position', 0)
})
retornar urls
def is_valid_url(self, url):
"""Filtre URLs que não sejam de artigos, como imagens, PDFs ou mídias sociais."""
excluded_domains = ['youtube.com', 'facebook.com', 'twitter.com', 'instagram.com']
excluded_extensions = ['.pdf', '.jpg', '.png', '.gif', '.mp4']
return (not any(domain in url for domain in excluded_domains) and
not any(ext in url.lower() for ext in excluded_extensions))
def scrape_page_content(self, url, max_length=10000):
"""Extrair conteúdo de texto limpo de uma página da Web usando as ferramentas do Bright Data MCP."""
try:
with MCPServerAdapter(self.server_params) as mcp_tools:
if not mcp_tools:
st.warning("Não há ferramentas MCP disponíveis para raspagem de conteúdo")
return ""
for tool in mcp_tools:
try:
tool_name = getattr(tool, 'name', str(tool))
if 'scrape_as_markdown' in tool_name:
try:
if hasattr(tool, '_run'):
result = tool._run(url=url)
elif hasattr(tool, 'run'):
result = tool.run(url=url)
elif hasattr(tool, '__call__'):
result = tool(url=url)
else:
result = tool.scrape_as_markdown(url=url)
if result:
content = self._extract_content_from_result(result)
if content:
return self._clean_content(content, max_length)
exceto Exception as method_error:
st.warning(f "O método falhou para {tool_name}: {str(method_error)}")
continue
exceto Exception as tool_error:
st.warning(f "A ferramenta {tool_name} falhou para {url}: {str(tool_error)}")
continue
st.warning(f "Nenhuma ferramenta scrape_as_markdown pôde fazer o scrape: {url}")
return ""
exceto Exception as e:
st.warning(f "Falha ao coletar {url}: {str(e)}")
return ""
def _extract_content_from_result(self, result):
"""Extrair conteúdo do resultado da ferramenta MCP."""
if isinstance(result, str):
return result
elif isinstance(result, dict):
for key in ['content', 'text', 'body', 'html']:
if key in result and result[key]:
return result[key]
elif isinstance(result, list) and len(result) > 0:
return str(result[0])
return str(result) if result else ""
def _clean_content(self, content, max_length):
"""Limpar e formatar o conteúdo extraído."""
if isinstance(content, dict):
content = content.get('text', content.get('content', str(content)))
se '<' no conteúdo e '>' no conteúdo:
import re
content = re.sub(r'<script[^>]*>.*?</script>', '', content, flags=re.DOTALL | re.IGNORECASE)
content = re.sub(r'<style[^>]*>.*?</style>', '', content, flags=re.DOTALL | re.IGNORECASE)
content = re.sub(r'<[^>]+>', '', content)
lines = (line.strip() for line in content.splitlines())
chunks = (phrase.strip() for line in lines for phrase in line.split(" "))
text = ' '.join(chunk for chunk in chunks if chunk)
return text[:max_length]Esse raspador filtra de forma inteligente os URLs para se concentrar no conteúdo do artigo, evitando arquivos multimídia e links de mídia social que não fornecerão conteúdo de texto valioso para análise.
Etapa 2: Embeddings vetoriais e análise de conteúdo
Transforme o conteúdo raspado em incorporações vetoriais pesquisáveis que capturam o significado semântico e permitem a análise inteligente do conteúdo. O processo de incorporação converte o texto em representações numéricas que as máquinas entendem e comparam.
classe ContentAnalyzer:
def __init__(self):
self.embeddings = OpenAIEmbeddings(openai_api_key=os.getenv("OPENAI_API_KEY"))
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["nn", "n", ".", "!", "?", ",", " ", "", ""]
)
def process_content(self, scraped_data):
"""Converta o conteúdo extraído em embeddings e analise os temas."""
todos_textos = []
metadados = []
para item em scraped_data:
if item['content']:
chunks = self.text_splitter.split_text(item['content'])
for chunk in chunks:
all_texts.append(chunk)
metadata.append({
'url': item['url'],
'title': item['title'],
'position': item['position']
})
if not all_texts:
raise ValueError("Nenhum conteúdo disponível para análise")
vectorstore = FAISS.from_texts(all_texts, self.embeddings, metadatas=metadata)
return vectorstore, all_texts, metadata
def identify_themes(self, vectorstore, query_terms, k=5):
"""Use a pesquisa semântica para identificar os principais temas e tópicos."""
theme_analysis = {}
for term in query_terms:
similar_docs = vectorstore.similarity_search(term, k=k)
theme_analysis[term] = {
'relevant_chunks': len(similar_docs),
'key_passages': [doc.page_content[:200] + "..." for doc in similar_docs[:3]],
'sources': list(set([doc.metadata['url'] for doc in similar_docs]))
}
return theme_analysis
def generate_content_summary(self, all_texts, metadata):
"""Gera um resumo estatístico do conteúdo extraído."""
total_words = sum(len(text.split()) for text in all_texts)
total_chunks = len(all_texts)
avg_chunk_length = total_words / total_chunks if total_chunks > 0 else 0
return {
'total_sources': len(set(meta['url'] for meta in metadata)),
'total_chunks': total_chunks,
'total_words': total_words,
'avg_chunk_length': round(avg_chunk_length, 1)
}O analisador divide o conteúdo em partes semânticas e cria um banco de dados vetorial pesquisável que permite a identificação inteligente de temas e a síntese de conteúdo.
Etapa 3: Gerar artigo ou esboço com o LLM
Transforme o conteúdo analisado em resultados estruturados usando prompts cuidadosamente elaborados que aproveitam os insights semânticos de sua análise de incorporação. O LLM pega os dados de sua pesquisa e cria um conteúdo coerente e bem estruturado.
classe ArticleGenerator:
def __init__(self):
self.llm = OpenAI(
openai_api_key=os.getenv("OPENAI_API_KEY"),
temperature=0.7,
max_tokens=2000
)
def generate_outline(self, keyword, theme_analysis, content_summary):
"""Gera um esboço de artigo estruturado com base em dados de pesquisa."""
themes_text = self._format_themes_for_prompt(theme_analysis)
outline_prompt = f"""
Com base em uma pesquisa abrangente sobre "{palavra-chave}", crie um esboço detalhado do artigo.
Resumo da pesquisa:
- Analisou {content_summary['total_sources']} fontes
- Processou {content_summary['total_words']} palavras de conteúdo
- Identificou os principais temas e percepções
Temas-chave encontrados:
{themes_text}
Crie um esboço estruturado com:
1. Título convincente
2. Gancho e visão geral da introdução
3. 4 a 6 seções principais com subseções
4. Conclusão com as principais conclusões
5. Sugestão de chamada para ação
Formate como markdown com hierarquia clara.
"""
return self.llm(outline_prompt)
def generate_full_article(self, keyword, theme_analysis, content_summary, target_length=1500):
"""Gera um rascunho de artigo completo."""
themes_text = self._format_themes_for_prompt(theme_analysis)
article_prompt = f"""
Escreva um artigo abrangente de {comprimento_alvo} palavras sobre "{palavra-chave}" com base em uma extensa pesquisa.
Fundação de pesquisa:
{themes_text}
Requisitos de conteúdo:
- Introdução envolvente que prenda os leitores
- Corpo bem estruturado com seções claras
- Incluir percepções específicas e pontos de dados da pesquisa
- Tom profissional e informativo
- Conclusão sólida com conclusões práticas
- Estrutura amigável para SEO com subtítulos
Escreva o artigo completo no formato markdown.
"""
return self.llm(article_prompt)
def _format_themes_for_prompt(self, theme_analysis):
"""Formatar análise de tema para consumo do LLM."""
formatted_themes = []
para tema, dados em theme_analysis.items():
theme_info = f "**{theme}**: Encontrado em {data['relevant_chunks']} seções de conteúdon"
theme_info += f "Principais percepções: {data['key_passages'][0][:150]}...n"
theme_info += f "Sources: {len(data['sources'])} referências exclusivasn"
formatted_themes.append(theme_info)
return "n".join(formatted_themes)O gerador cria dois formatos de saída distintos: esboços estruturados para planejamento de conteúdo e artigos completos para publicação imediata. Ambos os resultados são baseados na análise semântica do conteúdo extraído.
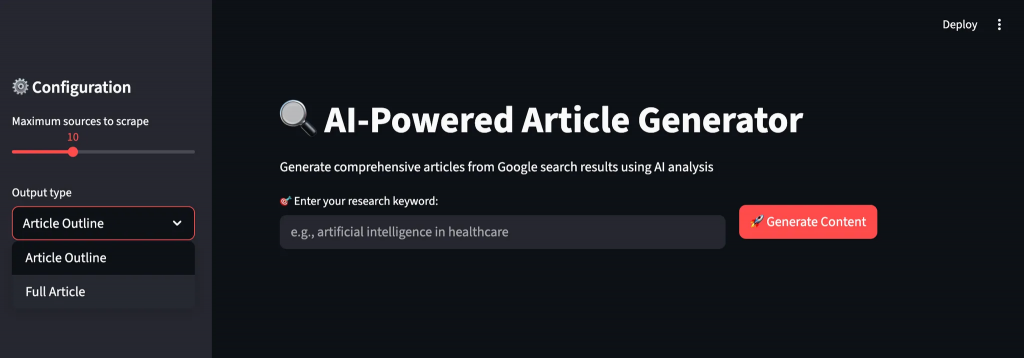
Etapa 4: Criar a interface de usuário do Streamlit
Crie uma interface intuitiva que guie os usuários pelo fluxo de trabalho de geração de conteúdo com feedback em tempo real e opções de personalização. A interface torna as operações complexas de IA acessíveis a usuários não técnicos.
def main():
st.set_page_config(page_title="AI Article Generator", page_icon="📝", layout="wide")
st.title("🔍 Gerador de artigos com tecnologia de IA")
st.markdown("Gerar artigos abrangentes a partir de resultados de pesquisa do Google usando análise de IA")
scraper = ContentScraper()
analyzer = ContentAnalyzer()
generator = ArticleGenerator()
st.sidebar.header("⚙️ Configuration")
max_sources = st.sidebar.slider("Maximum sources to scrape", 5, 20, 10)
output_type = st.sidebar.selectbox("Output type", ["Article Outline", "Full Article"])
target_length = st.sidebar.slider("Contagem de palavras-alvo (artigo completo)", 800, 3000, 1500)
col1, col2 = st.columns([2, 1])
com col1:
keyword = st.text_input("🎯 Digite sua palavra-chave de pesquisa:", placeholder="por exemplo, inteligência artificial na área de saúde")
com col2:
st.write("")
generate_button = st.button("🚀 Generate Content", type="primary")
if generate_button and keyword:
try:
progress_bar = st.progress(0)
status_text = st.empty()
status_text.text("🔍 Raspando os resultados de pesquisa do Google...")
barra_de_progresso.progresso(0,2)
urls = scraper.extract_serp_urls(keyword, max_sources)
st.success(f "Encontrou {len(urls)} URLs relevantes")
status_text.text("📄 Extraindo conteúdo de páginas da Web...")
barra_de_progresso.progresso(0,4)
dados_raspados = []
para i, url_data em enumerate(urls):
content = scraper.scrape_page_content(url_data['url'])
scraped_data.append({
'url': url_data['url'],
'title': url_data['title'],
'content': conteúdo,
'position': url_data['position']
})
progress_bar.progress(0,4 + (0,3 * (i + 1) / len(urls)))
status_text.text("🧠 Analisando o conteúdo com AI embeddings...")
barra_de_progresso.progresso(0,75)
vectorstore, all_texts, metadata = analyzer.process_content(scraped_data)
query_terms = [keyword] + keyword.split()[:3]
theme_analysis = analyzer.identify_themes(vectorstore, query_terms)
content_summary = analyzer.generate_content_summary(all_texts, metadata)
status_text.text("✍️ Gerando conteúdo com tecnologia de IA...")
barra_de_progresso.progresso(0,9)
se output_type == "Article Outline":
result = generator.generate_outline(keyword, theme_analysis, content_summary)
else:
result = generator.generate_full_article(keyword, theme_analysis, content_summary, target_length)
barra_de_progresso.progresso(1,0)
status_text.text("✅ Geração de conteúdo concluída!")
st.markdown("---")
st.subheader(f"📊 Análise de pesquisa para '{palavra-chave}'")
col1, col2, col3, col4 = st.columns(4)
com col1:
st.metric("Sources Analyzed", content_summary['total_sources'])
com col2:
st.metric("Content Chunks", content_summary['total_chunks'])
com col3:
st.metric("Total Words", content_summary['total_words'])
com col4:
st.metric("Avg Chunk Size", f"{content_summary['avg_chunk_length']} words")
com st.expander("🎯 Temas-chave identificados"):
for theme, data in theme_analysis.items():
st.write(f "**{theme}**: {data['relevant_chunks']} seções relevantes encontradas")
st.write(f "Exemplo de percepção: {data['key_passages'][0][:200]}...")
st.write(f "Fontes: {len(data['sources'])} referências exclusivas")
st.write("---")
st.markdown("---")
st.subheader(f"📝 Generated {output_type}")
st.markdown(result)
st.download_button(
label="💾 Download Content",
data=result,
file_name=f"{keyword.replace(' ', '_')}_{output_type.lower().replace(' ', '_')}.md",
mime="text/markdown"
)
except Exception as e:
st.error(f"❌ Generation failed: {str(e)}")
st.write("Por favor, verifique suas credenciais de API e tente novamente.")
if __name__ == "__main__":
main()A interface do Streamlit oferece um fluxo de trabalho intuitivo com acompanhamento do progresso em tempo real, parâmetros personalizáveis e visualização imediata da análise da pesquisa e do conteúdo gerado. Os usuários baixam seus resultados em formato markdown para edição ou publicação posterior.
Execução do gerador de artigos
Execute o aplicativo para começar a gerar conteúdo a partir de pesquisas na Web. Abra seu terminal e navegue até o diretório de seu projeto.
streamlit run article_generator.pyVocê verá o fluxo de trabalho inteligente do sistema à medida que ele processa suas solicitações:
- Extrai resultados de pesquisa abrangentes do SERP do Google com filtragem de relevância
- Extrai o conteúdo completo das páginas da Web de destino com proteção anti-bot
- Processa o conteúdo semanticamente usando embeddings vetoriais e identificação de temas
- Analisa padrões recorrentes e insights importantes em várias fontes
- Gera conteúdo estruturado com fluxo adequado e formatação profissional
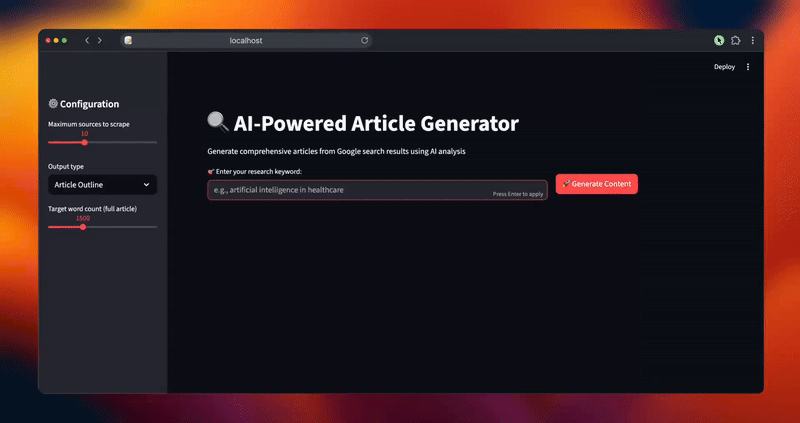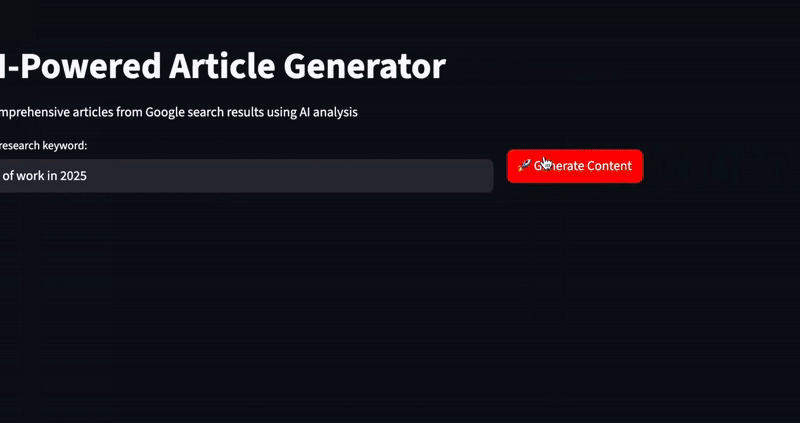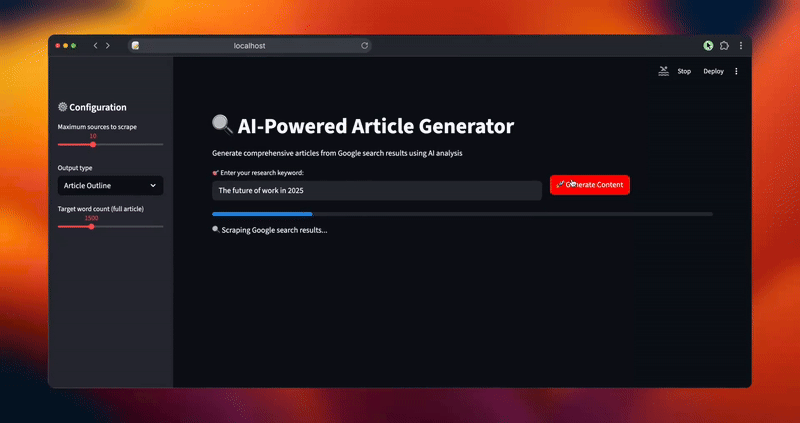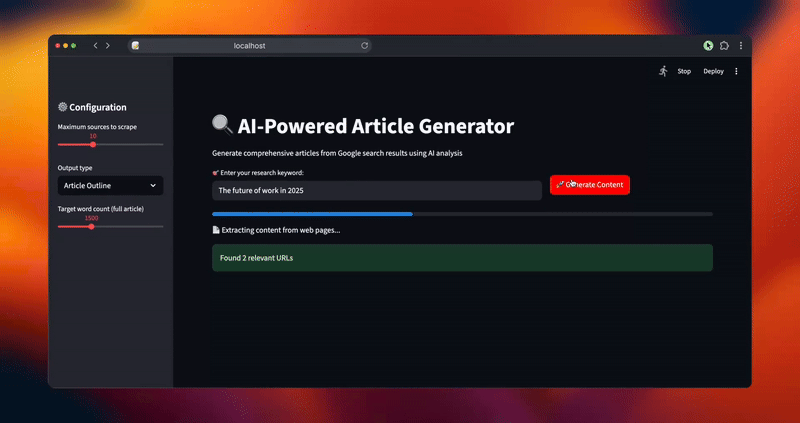
Considerações finais
Agora você tem um sistema completo de geração de artigos que coleta automaticamente dados de pesquisa de várias fontes e os transforma em conteúdo abrangente. O sistema realiza a análise semântica do conteúdo, identifica temas recorrentes entre as fontes e gera artigos estruturados ou esboços.
Você pode adaptar essa estrutura para diferentes setores modificando os alvos de raspagem e os critérios de análise. O design modular permite que você adicione novas plataformas de conteúdo, modelos de incorporação ou modelos de geração à medida que suas necessidades evoluem.
Para criar fluxos de trabalho mais avançados, explore toda a gama de soluções na infraestrutura de IA da Bright Data para buscar, validar e transformar dados da Web em tempo real.
Crie uma conta gratuita na Bright Data e comece a experimentar nossas soluções de dados da Web prontas para IA!





