

Resumo: Vamos aprender como construir um raspador do Yahoo Finance para extrair dados de ações para realizar análises financeiras para negociação e investimento.
Este tutorial abordará:
- Porquê raspar dados financeiros da web?
- Bibliotecas e ferramentas de raspagem de dados financeiros
- Raspagem de dados de ações do Yahoo Finance com Selenium
Porquê raspar dados financeiros da web?
A raspagem de dados financeiros da web oferece informações valiosas que são úteis em vários cenários, incluindo:
- Comércio automatizado: Ao recolher dados de mercado históricos ou em tempo real, como preços e volumes de ações, os programadores podem criar estratégias de comércio automatizadas.
- Análise técnica: Os dados históricos do mercado e os indicadores são extremamente importantes para os analistas técnicos. Estes permitem-lhes identificar padrões e tendências, ajudando-os a tomar decisões de investimento.
- Modelação financeira: Os investigadores e analistas podem recolher dados relevantes, como demonstrações financeiras e indicadores económicos, para construir modelos complexos para avaliar o desempenho da empresa, prever ganhos e avaliar oportunidades de investimento.
- Estudos de mercado: Os dados financeiros fornecem uma grande quantidade de informações sobre ações, índices de mercado e produtos básicos. A análise destes dados ajuda os investigadores a compreender as tendências do mercado, o sentimento e a saúde do setor para tomar decisões de investimento informadas.
Quando se trata de monitorizar o mercado, o Yahoo Finance é um dos sítios web financeiros mais populares. Fornece uma vasta gama de informações e ferramentas a investidores e comerciantes, tais como dados históricos e em tempo real sobre ações, obrigações, fundos mútuos, mercadorias, moedas e índices de mercado. Além disso, oferece artigos de notícias, demonstrações financeiras, estimativas de analistas, gráficos e outros recursos valiosos.
Ao raspar Yahoo Finance, pode aceder a uma grande quantidade de informações para apoiar a sua análise financeira, pesquisa e processos de tomada de decisões.
Bibliotecas e ferramentas de raspagem de dados financeiros
Python é considerada uma das melhores linguagens para raspagem graças à sua sintaxe, facilidade de utilização e ecossistema rico de bibliotecas. Consulte o nosso guia sobre a raspagem da web com Python.
Para escolher as bibliotecas de raspagem corretas de entre as muitas disponíveis, explore o Yahoo Finance no seu navegador. Verificará que a maior parte dos dados do sítio são atualizados em tempo real ou alterados após uma interação. Isto significa que o sítio se baseia fortemente em AJAX para carregar e atualizar dados de forma dinâmica, sem necessidade de recarregar a página. Por outras palavras, precisa de uma ferramenta que seja capaz de executar JavaScript.
O Selenium torna possível a raspagem de sítios web dinâmicos em Python. Apresenta o sítio nos navegadores web, executando operações de forma programática nos mesmos, mesmo que utilizem JavaScript para apresentar ou recuperar dados.
Graças ao Selenium, poderá raspar o sítio de destino com Python. Vamos aprender como!
Raspagem de dados de ações do Yahoo Finance com Selenium
Siga este tutorial passo a passo e veja como construir um script de Python para raspagem da web do Yahoo Finance.
Passo 1: Configuração
Antes de mergulhar na raspagem financeira, certifique-se de que cumpre estes pré-requisitos:
- Python 3+ instalado na sua máquina: Descarregue o instalador, faça duplo clique sobre ele e siga o assistente de instalação.
- Um IDE de Python à sua escolha: PyCharm Community Edition ou Visual Studio Code com a extensão de Python são suficientes.
Em seguida, utilize os comandos abaixo para configurar um projeto Python com um ambiente virtual:
nmkdir yahoo-finance-scraperncd yahoo-finance-scrapernpython -m venv env
Estes irão inicializar a pasta do projeto yahoo-finance-scraper. Dentro dela, adicione um ficheiro scraper.py como abaixo indicado:
print('Hello, World!')
Adicionará aqui a lógica para raspar Yahoo Finance. Neste momento, é um script de amostra que apenas imprime “Hello, World!” (Olá, mundo!)
Inicie-o para verificar se funciona com:
python scraper.py
No terminal, deve ver:
Hello, World!
Ótimo, agora tem um projeto Python para o seu raspador financeiro. Resta apenas adicionar as dependências do projeto. Instale o Selenium e o Webdriver Manager com o seguinte comando do terminal:
pip install selenium webdriver-manager
Isto pode demorar algum tempo. Seja paciente.
webdriver-manager não é estritamente necessário. No entanto, é altamente recomendável, uma vez que torna a gestão de controladores web no Selenium muito mais fácil. Graças a ele, não é necessário descarregar, configurar e importar manualmente o controlador web.
Atualizar scraper.py
nfrom selenium import webdrivernfrom selenium.webdriver.chrome.service import Service as ChromeServicenfrom webdriver_manager.chrome import ChromeDriverManagernn# initialize a web driver instance to control a Chrome windowndriver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))nn# scraping logic...nn# close the browser and free up the resourcesndriver.quit()
Este script simplesmente instancia uma instância do WebDriver de Chrome. Você a utilizará em breve para implementar a lógica de extração de dados.
Passo 2: Ligar à página web de destino
Este é o aspeto do URL de uma página de ações do Yahoo Finance:
https://finance.yahoo.com/quote/AMZN
Como pode ver, é um URL dinâmico que se altera com base no símbolo do ticker. Se não estiver familiarizado com o conceito, trata-se de uma abreviatura de cadeia de caracteres utilizada para identificar exclusivamente as ações negociadas no mercado bolsista. Por exemplo, “AMZN” é o símbolo do ticker das ações da Amazon.
Vamos modificar o script para fazer a leitura do ticker a partir de um argumento da linha de comando.
nimport sysnn# if there are no CLI parametersnif len(sys.argv) u003c= 1:n print('Ticker symbol CLI argument missing!')n sys.exit(2)nn# read the ticker from the CLI argumentnticker_symbol = sys.argv[1]nn# build the URL of the target pagenurl = f'https://finance.yahoo.com/quote/{ticker_symbol}'
sys é uma biblioteca padrão de Python que fornece acesso aos argumentos da linha de comando. Não se esqueça de que o argumento com índice 0 é o nome do seu script. Assim, é necessário direcionar o argumento com o índice 1.
Depois de ler o ticker a partir da ILC, este é utilizado numa f-string para produzir o URL de destino para raspar.
Por exemplo, suponha que lança o raspador com o ticker da Tesla “TSLA:”
python scraper.py TSLAn
O url conterá:
https://finance.yahoo.com/quote/TSLA
Se esquecer o símbolo do ticker na ILC, o programa falhará com o erro abaixo:
Ticker symbol CLI argument missing!
Antes de abrir qualquer página no Selenium, recomenda-se que defina o tamanho da janela para garantir que todos os elementos sejam visíveis:
driver.set_window_size(1920, 1080)
Pode agora utilizar o Selenium para se ligar à página de destino com:
driver.get(url)
A função get() dá instruções ao navegador para visitar a página pretendida.
Este é o aspeto do seu script de raspagem do Yahoo Finance até agora:
nfrom selenium import webdrivernfrom selenium.webdriver.chrome.service import Service as ChromeServicenfrom webdriver_manager.chrome import ChromeDriverManagernimport sysnn# if there are no CLI parametersnif len(sys.argv) u003c= 1:n print('Ticker symbol CLI argument missing!')n sys.exit(2)nn# read the ticker from the CLI argumentnticker_symbol = sys.argv[1]nn# build the URL of the target pagenurl = f'https://finance.yahoo.com/quote/{ticker_symbol}'nn# initialize a web driver instance to control a Chrome windowndriver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))n# set up the window size of the controlled browserndriver.set_window_size(1920, 1080)n# visit the target pagendriver.get(url)nn# scraping logic...nn# close the browser and free up the resourcesndriver.quit()
Se o lançar, abrirá esta janela durante uma fração de segundo antes de terminar:
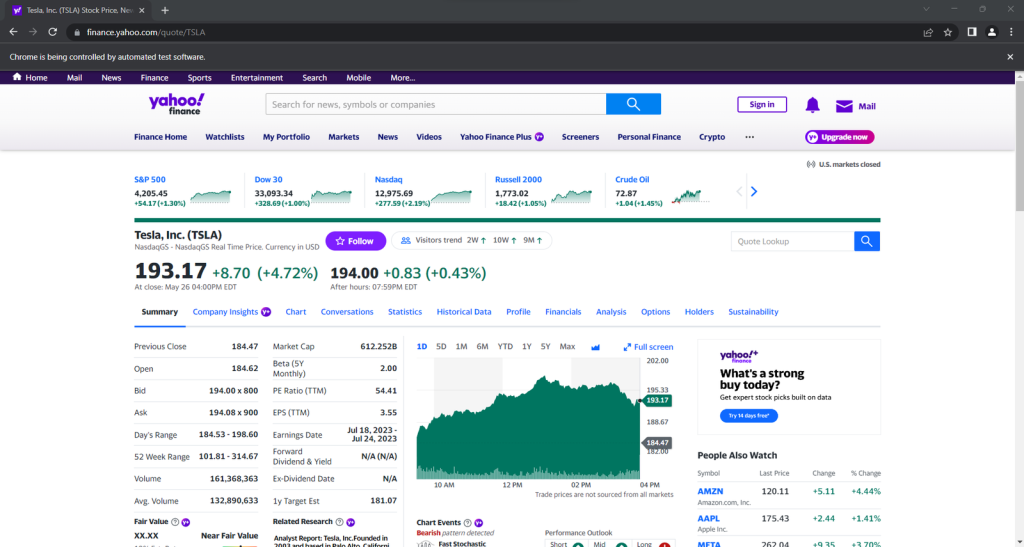
Iniciar o navegador com a IU é útil para depurar, monitorizando o que o raspador está a fazer na página web. Ao mesmo tempo, requer muitos recursos. Para evitar isso, configure o Chrome para ser executado no modo sem cabeça com:
nfrom selenium.webdriver.chrome.options import Optionsn# ...nnoptions = Options()noptions.add_argument('u002du002dheadless=new')nndriver = webdriver.Chrome(n service=ChromeService(ChromeDriverManager().install()),n options=optionsn)
O navegador controlado será agora lançado nos bastidores, sem IU.
Passo 3: Inspecionar a página de destino
Para estruturar uma estratégia de extração de dados eficaz, é necessário analisar primeiro a página web de destino. Abra o seu navegador e visite a página de ações do Yahoo.
Se estiver localizado na Europa, verá primeiro um modal que lhe pede para aceitar os cookies:
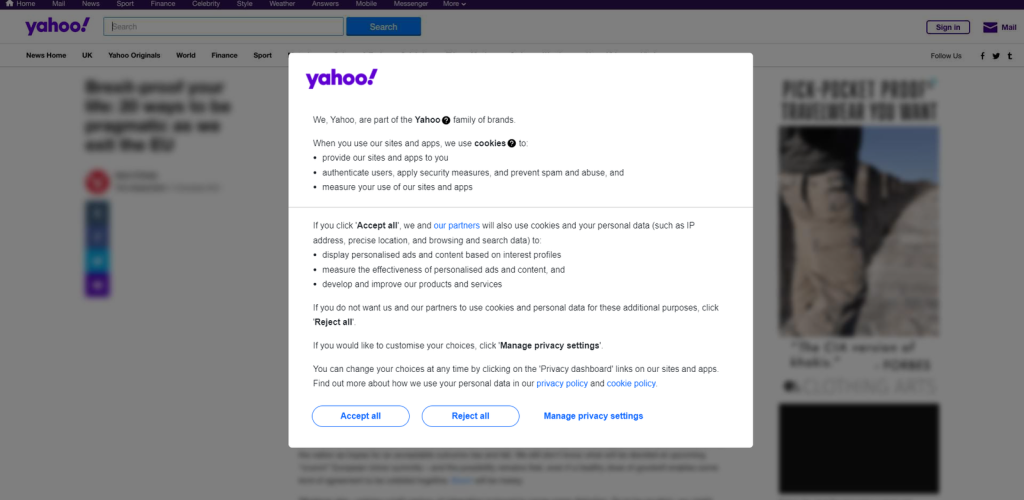
Para a fechar e continuar a visitar a página pretendida, deve clicar em “Aceitar tudo” ou “Rejeitar tudo”. Clique com o botão direito do rato no primeiro botão e selecione a opção “Inspecionar” para abrir as ferramentas de desenvolvimento do seu navegador:

Neste caso, pode selecionar esse botão com o seguinte seletor CSS:
.consent-overlay .accept-all
Utilize estas linhas de ICE para lidar com o modal de consentimento no Selenium:
ntry:n # wait up to 3 seconds for the consent modal to show upn consent_overlay = WebDriverWait(driver, 3).until(n EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))nn # click the u0022Accept allu0022 buttonn accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')n accept_all_button.click()nexcept TimeoutException:n print('Cookie consent overlay missing')
WebDriverWait permite-lhe esperar que uma condição esperada ocorra na página. Se nada acontecer no tempo limite especificado, cria uma TimeoutException. Uma vez que a sobreposição de cookies só aparece quando o seu IP de saída é europeu, pode tratar a exceção com uma instrução try-catch. Desta forma, o script continuará a ser executado quando o modal de consentimento não estiver presente.
Para que o script funcione, é necessário adicionar as seguintes importações:
nfrom selenium.webdriver.support.ui import WebDriverWaitnfrom selenium.webdriver.support import expected_conditions as ECnfrom selenium.webdriver.common.by import Bynfrom selenium.common import TimeoutException
Agora, continue a inspecionar o sítio de destino nas ferramentas de desenvolvimento e familiarize-se com a sua Estrutura do DOM.
Passo 4: Extrair os dados das ações
Como deve ter reparado no passo anterior, algumas das informações mais interessantes encontram-se nesta seção:
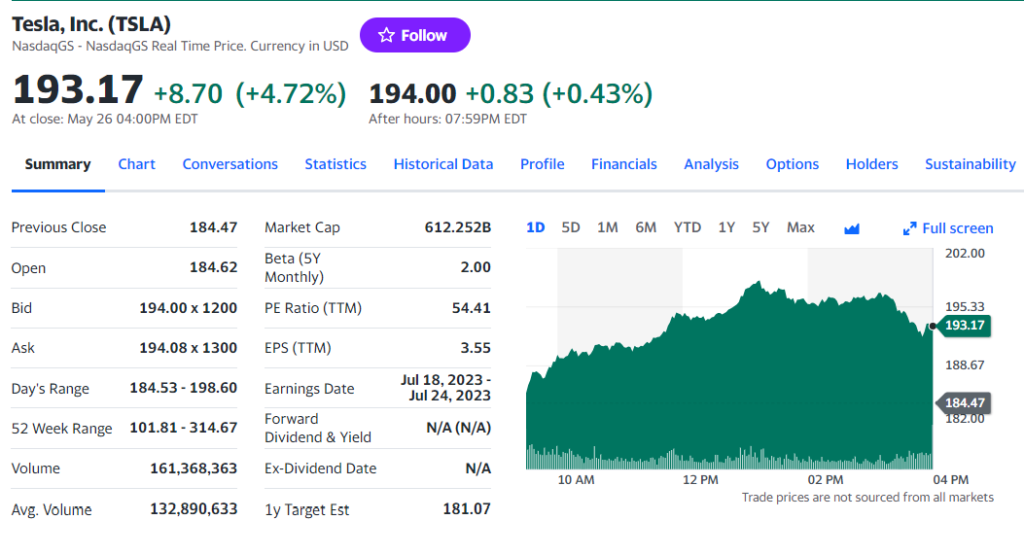
Inspecionar o elemento indicador de preço HTML:
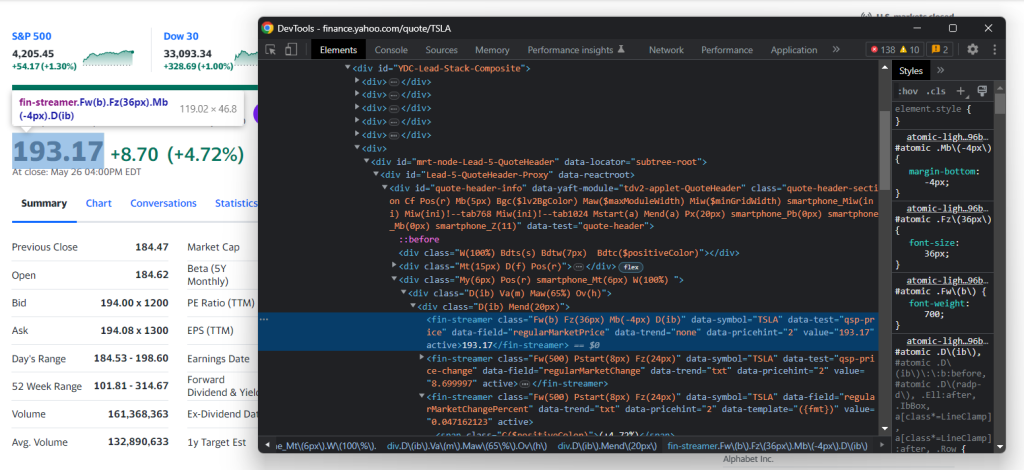
Note que as classes CSS não são úteis para definir seletores adequados no Yahoo Finance. Parecem seguir uma sintaxe especial para uma estrutura de estilo. Em vez disso, concentre-se nos outros atributos HTML. Por exemplo, pode obter o preço das ações com o seletor CSS abaixo:
[data-symbol=u0022TSLAu0022][data-field=u0022regularMarketPriceu0022]
Seguindo uma abordagem semelhante, extraia todos os dados de ações dos indicadores de preços com:
nregular_market_price = drivern .find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketPriceu0022]')n .textnregular_market_change = drivern .find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketChangeu0022]')n .textnregular_market_change_percent = drivern .find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketChangePercentu0022]')n .textn .replace('(', '').replace(')', '')n npost_market_price = drivern .find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketPriceu0022]')n .textnpost_market_change = drivern .find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketChangeu0022]')n .textnpost_market_change_percent = drivern .find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketChangePercentu0022]')n .textn .replace('(', '').replace(')', '')n
Depois de selecionar um elemento HTML através da estratégia específica do seletor CSS, pode extrair o seu conteúdo com o campo text. Uma vez que os campos de percentagem envolvem parênteses redondos, estes são removidos com replace().
Adicione-os a um dicionário de ações e imprima-o para verificar se o processo de raspagem de dados financeiros funciona como esperado:
n# initialize the dictionarynstock = {}nn# stock price scraping logic omitted for brevity...nn# add the scraped data to the dictionarynstock['regular_market_price'] = regular_market_pricenstock['regular_market_change'] = regular_market_changenstock['regular_market_change_percent'] = regular_market_change_percentnstock['post_market_price'] = post_market_pricenstock['post_market_change'] = post_market_changenstock['post_market_change_percent'] = post_market_change_percentnnprint(stock)
Execute o script no valor que pretende raspar e deverá ver algo do género:
{'regular_market_price': '193.17', 'regular_market_change': '+8.70', 'regular_market_change_percent': '+4.72%', 'post_market_price': '194.00', 'post_market_change': '+0.83', 'post_market_change_percent': '+0.43%'}
Pode encontrar outras informações úteis na tabela #quote-summary:
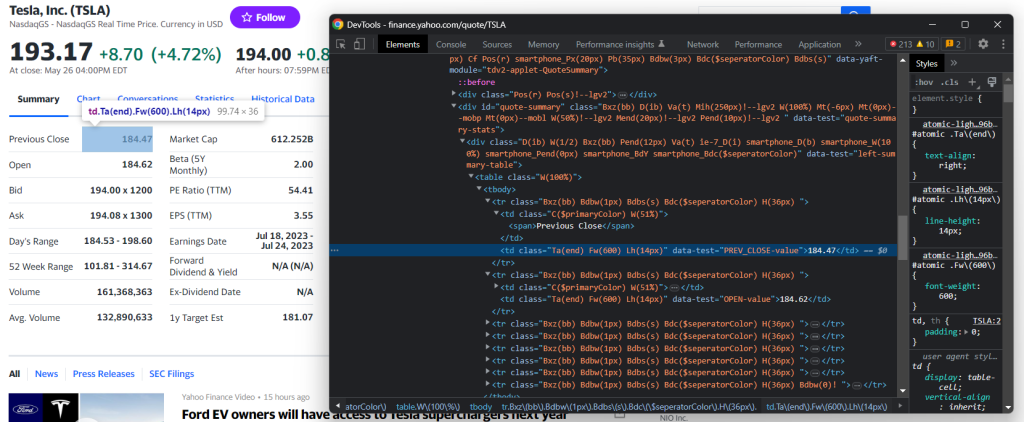
Neste caso, pode extrair cada campo de dados graças ao atributo data-test como no seletor CSS abaixo:
#quote-summary [data-test=u0022PREV_CLOSE-valueu0022]
Raspar tudo com:
nprevious_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022PREV_CLOSE-valueu0022]').textnopen_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022OPEN-valueu0022]').textnbid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022BID-valueu0022]').textnask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022ASK-valueu0022]').textndays_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022DAYS_RANGE-valueu0022]').textnweek_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022FIFTY_TWO_WK_RANGE-valueu0022]').textnvolume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022TD_VOLUME-valueu0022]').textnavg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022AVERAGE_VOLUME_3MONTH-valueu0022]').textnmarket_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022MARKET_CAP-valueu0022]').textnbeta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022BETA_5Y-valueu0022]').textnpe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022PE_RATIO-valueu0022]').textneps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EPS_RATIO-valueu0022]').textnearnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EARNINGS_DATE-valueu0022]').textndividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022DIVIDEND_AND_YIELD-valueu0022]').textnex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EX_DIVIDEND_DATE-valueu0022]').textnyear_target_est = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022ONE_YEAR_TARGET_PRICE-valueu0022]').text
Em seguida, adicione-os a stock:
nstock['previous_close'] = previous_closenstock['open_value'] = open_valuenstock['bid'] = bidnstock['ask'] = asknstock['days_range'] = days_rangenstock['week_range'] = week_rangenstock['volume'] = volumenstock['avg_volume'] = avg_volumenstock['market_cap'] = market_capnstock['beta'] = betanstock['pe_ratio'] = pe_rationstock['eps'] = epsnstock['earnings_date'] = earnings_datenstock['dividend_yield'] = dividend_yieldnstock['ex_dividend_date'] = ex_dividend_datenstock['year_target_est'] = year_target_est
Fantástico! Acabou de efetuar uma raspagem de dados financeiros da web com Python!
Passo 5: Raspar várias ações
Uma carteira de investimentos diversificada é composta por mais do que um valor. Para obter dados de todos eles, é necessário estender o script para raspar vários tickers.
Primeiro, encapsule a lógica de raspagem numa função:
ndef scrape_stock(driver, ticker_symbol):n url = f'https://finance.yahoo.com/quote/{ticker_symbol}'n driver.get(url)nn # deal with the consent modal...nn # initialize the stock dictionary with then # ticker symboln stock = { 'ticker': ticker_symbol }nn # scraping the desired data and populate n # the stock dictionary...nn return stock
Em seguida, itere sobre os argumentos do ticker da ILC e aplique a função de raspagem:
nif len(sys.argv) u003c= 1:n print('Ticker symbol CLI arguments missing!')n sys.exit(2)nn# initialize a Chrome instance with the rightn# configsnoptions = Options()noptions.add_argument('u002du002dheadless=new')ndriver = webdriver.Chrome(n service=ChromeService(ChromeDriverManager().install()),n options=optionsn)ndriver.set_window_size(1150, 1000)nn# the array containing all scraped datanstocks = []nn# scraping all market securitiesnfor ticker_symbol in sys.argv[1:]:n stocks.append(scrape_stock(driver, ticker_symbol))
No final do ciclo for, a lista de stock dos dicionários de Python conterá todos os dados do mercado de ações.
Passo 6: Exportar os dados raspados para CSV
Pode exportar os dados coletados para CSV com apenas algumas linhas de código:
nimport csvnn# ...nn# extract the name of the dictionary fieldsn# to use it as the header of the output CSV filencsv_header = stocks[0].keys()nn# export the scraped data to CSVnwith open('stocks.csv', 'w', newline='') as output_file:n dict_writer = csv.DictWriter(output_file, csv_header)n dict_writer.writeheader()n dict_writer.writerows(stocks)
Este trecho cria um ficheiro stocks.csv com open(), inicializa com uma linha de cabeçalho e preenche-o. Especificamente, DictWriter.writerows() converte cada dicionário num registo CSV e anexa-o ao ficheiro de saída.
Uma vez que o csv vem da biblioteca padrão de Python, nem sequer é necessário instalar uma dependência extra para atingir o objetivo desejado.
Começou com dados em bruto contidos numa página web e já tem dados semiestruturados armazenados num ficheiro CSV. Está na altura de dar uma vista de olhos a todo o raspador do Yahoo Finance.
Passo 7: Juntar tudo
Aqui está o ficheiro scraper.py completo:
nfrom selenium import webdrivernfrom selenium.webdriver.chrome.service import Service as ChromeServicenfrom webdriver_manager.chrome import ChromeDriverManagernfrom selenium.webdriver.chrome.options import Optionsnfrom selenium.webdriver.support.ui import WebDriverWaitnfrom selenium.webdriver.support import expected_conditions as ECnfrom selenium.webdriver.common.by import Bynfrom selenium.common import TimeoutExceptionnimport sysnimport csvnndef scrape_stock(driver, ticker_symbol):n # build the URL of the target pagen url = f'https://finance.yahoo.com/quote/{ticker_symbol}'nn # visit the target pagen driver.get(url)nn try:n # wait up to 3 seconds for the consent modal to show upn consent_overlay = WebDriverWait(driver, 3).until(n EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))nn # click the 'Accept all' buttonn accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')n accept_all_button.click()n except TimeoutException:n print('Cookie consent overlay missing')nn # initialize the dictionary that will containn # the data collected from the target pagen stock = { 'ticker': ticker_symbol }nn # scraping the stock data from the price indicatorsn regular_market_price = driver n .find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketPriceu0022]') n .textn regular_market_change = driver n .find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketChangeu0022]') n .textn regular_market_change_percent = driver n .find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022regularMarketChangePercentu0022]') n .text n .replace('(', '').replace(')', '')nn post_market_price = driver n .find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketPriceu0022]') n .textn post_market_change = driver n .find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketChangeu0022]') n .textn post_market_change_percent = driver n .find_element(By.CSS_SELECTOR, f'[data-symbol=u0022{ticker_symbol}u0022][data-field=u0022postMarketChangePercentu0022]') n .text n .replace('(', '').replace(')', '')nn stock['regular_market_price'] = regular_market_pricen stock['regular_market_change'] = regular_market_changen stock['regular_market_change_percent'] = regular_market_change_percentn stock['post_market_price'] = post_market_pricen stock['post_market_change'] = post_market_changen stock['post_market_change_percent'] = post_market_change_percentnn # scraping the stock data from the u0022Summaryu0022 tablen previous_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022PREV_CLOSE-valueu0022]').textn open_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022OPEN-valueu0022]').textn bid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022BID-valueu0022]').textn ask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022ASK-valueu0022]').textn days_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022DAYS_RANGE-valueu0022]').textn week_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022FIFTY_TWO_WK_RANGE-valueu0022]').textn volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022TD_VOLUME-valueu0022]').textn avg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022AVERAGE_VOLUME_3MONTH-valueu0022]').textn market_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022MARKET_CAP-valueu0022]').textn beta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022BETA_5Y-valueu0022]').textn pe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022PE_RATIO-valueu0022]').textn eps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EPS_RATIO-valueu0022]').textn earnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EARNINGS_DATE-valueu0022]').textn dividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022DIVIDEND_AND_YIELD-valueu0022]').textn ex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test=u0022EX_DIVIDEND_DATE-valueu0022]').textn year_target_est = driver.find_element(By.CSS_SELECTOR,n '#quote-summary [data-test=u0022ONE_YEAR_TARGET_PRICE-valueu0022]').textnn stock['previous_close'] = previous_closen stock['open_value'] = open_valuen stock['bid'] = bidn stock['ask'] = askn stock['days_range'] = days_rangen stock['week_range'] = week_rangen stock['volume'] = volumen stock['avg_volume'] = avg_volumen stock['market_cap'] = market_capn stock['beta'] = betan stock['pe_ratio'] = pe_ration stock['eps'] = epsn stock['earnings_date'] = earnings_daten stock['dividend_yield'] = dividend_yieldn stock['ex_dividend_date'] = ex_dividend_daten stock['year_target_est'] = year_target_estnn return stocknn# if there are no CLI parametersnif len(sys.argv) u003c= 1:n print('Ticker symbol CLI argument missing!')n sys.exit(2)nnoptions = Options()noptions.add_argument('u002du002dheadless=new')nn# initialize a web driver instance to control a Chrome windowndriver = webdriver.Chrome(n service=ChromeService(ChromeDriverManager().install()),n options=optionsn)nn# set up the window size of the controlled browserndriver.set_window_size(1150, 1000)nn# the array containing all scraped datanstocks = []nn# scraping all market securitiesnfor ticker_symbol in sys.argv[1:]:n stocks.append(scrape_stock(driver, ticker_symbol))nn# close the browser and free up the resourcesndriver.quit()nn# extract the name of the dictionary fieldsn# to use it as the header of the output CSV filencsv_header = stocks[0].keys()nn# export the scraped data to CSVnwith open('stocks.csv', 'w', newline='') as output_file:n dict_writer = csv.DictWriter(output_file, csv_header)n dict_writer.writeheader()n dict_writer.writerows(stocks)
Em menos de 150 linhas de código, construiu um raspador da web completo para obter dados do Yahoo Finance.
Lance-o contra as suas ações-alvo, como no exemplo abaixo:
python scraper.py TSLA AMZN AAPL META NFLX GOOG
No final do processo de raspagem, este ficheiro stocks.csv aparecerá na pasta de raiz do seu projeto:

Conclusão
Neste tutorial, percebeu porque é que o Yahoo Finance é um dos melhores portais financeiros da web e como extrair dados do mesmo. Em particular, viu como construir um raspador com Python que pode recuperar dados sobre ações. Como mostrado aqui, não é complexo e requer apenas algumas linhas de código.
Ao mesmo tempo, o Yahoo Finance é um sítio dinâmico que depende muito do JavaScript. Ao lidar com esses sítios, uma abordagem tradicional baseada numa biblioteca HTTP e num analisador HTML não é suficiente. Além disso, estes sítios populares tendem a implementar tecnologias avançadas de proteção de dados. Para os raspar, é necessário um navegador controlável que seja capaz de gerir automaticamente CAPTCHAs, impressões digitais, tentativas automáticas e muito mais. É exatamente este o objetivo da nossa nova solução: o Navegador de Raspagem!
Não quer lidar com a raspagem da web, mas está interessado em dados financeiros? Explore o nosso mercado de conjuntos de dados.






