

Se você estiver interessado em extrair dados da web, Crawlee pode ajudar. É um mecanismo de extração rápido e interativo usado por cientistas de dados, desenvolvedores e pesquisadores para coletar dados da web. O Crawlee é fácil de configurar e oferece recursos como rotação de proxy e tratamento de sessões. Esses recursos são cruciais para extrair dados de sites grandes ou dinâmicos sem bloquear seu endereço IP, garantindo uma coleta de dados tranquila e ininterrupta.
Neste tutorial, você aprenderá a usar o Crawlee para extrair dados da web. Você começará com um exemplo básico de web scraping e avançará para conceitos mais avançados, como gerenciamento de sessões e extração de páginas dinâmicas.
Como extrair dados da web com o Crawlee
Antes de começar este tutorial, verifique se você tem os seguintes pré-requisitos instalados na sua máquina:
- Node.js
- npm: normalmente já vem com o Node.js. Você pode verificar a instalação executando
node -vounpm -vno seu terminal. - Um editor de código de sua escolha: este tutorial usa Visual Studio Code.
Extração básica de dados da web com Crawlee
Após se certificar que tem todos os pré-requisitos, vamos começar copiando o site Books to Scrape, que é perfeito para aprender, pois fornece uma estrutura HTML simples.
Abra seu terminal ou shell e comece inicializando um projeto Node.js com os seguintes comandos:
mkdir crawlee-tutorial
cd crawlee-tutorial
npm init -y
Em seguida, instale a biblioteca Crawlee com o seguinte comando:
npm install crawlee
Para extrair dados de qualquer site de forma eficaz, você precisa inspecionar a página da web que deseja copiar para obter os detalhes das tags HTML do site. Para fazer isso, abra o site em seu navegador e navegue até as Developer Tools clicando com o botão direito do mouse em qualquer lugar da página. Em seguida, clique em Inspect ou Inspect element:
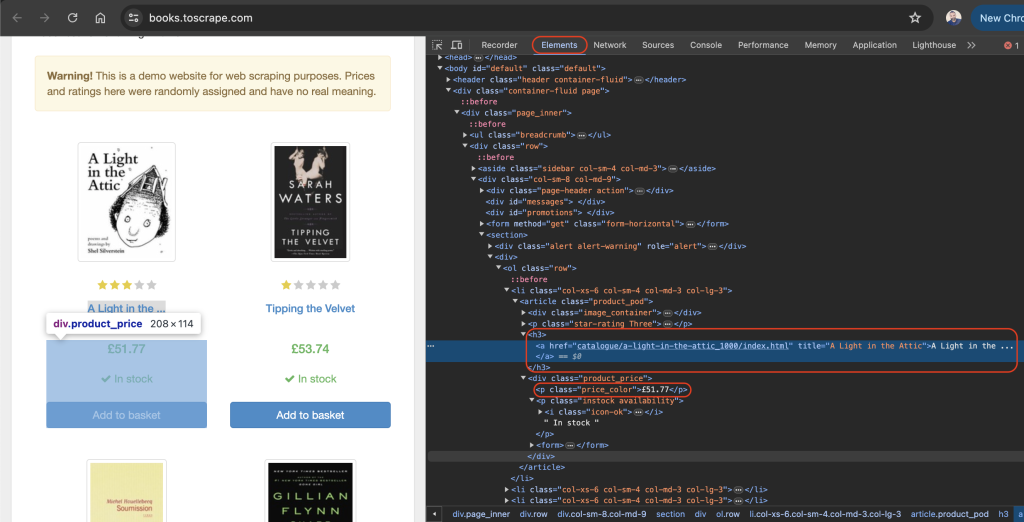
A guia Elements deve estar ativa por padrão, e essa guia representa o layout HTML da página da web. Neste exemplo, cada livro exibido é colocado em uma tag HTML article com a classe product_pod. Em cada artigo, o título do livro está contido em uma tag h3. O título real do livro está contido no atributo title da tag a localizada dentro do elemento h3. O preço do livro está localizado dentro da etiqueta p com a classe price_color:
No diretório raiz do seu projeto, crie um arquivo chamado scrape.js e adicione o seguinte código:
const { CheerioCrawler } = require('crawlee');
const crawler = new CheerioCrawler({
async requestHandler({ request, $ }) {
const books = [];
$('article.product_pod').each((index, element) => {
const title = $(element).find('h3 a').attr('title');
const price = $(element).find('.price_color').text();
books.push({ title, price });
});
console.log(books);
},
});
crawler.run(['https://books.toscrape.com/']);
Nesse código, você usa CheerioCrawler do crawlee para extrair títulos e preços de livros de https://books.toscrape.com/. O rastreador busca conteúdo HTML, extrai dados de elementos <article class="product_pod"> usando uma sintaxe semelhante a jQuery e registra os resultados no console.
Depois de adicionar o código anterior ao seu arquivo scrape.js, você pode executar o código com o seguinte comando:
node scrape.js
Uma variedade de títulos e preços de livros será gerada no seu terminal:
…output omitted…
{
title: 'The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics',
price: '£22.60'
},
{ title: 'The Black Maria', price: '£52.15' },
{
title: 'Starving Hearts (Triangular Trade Trilogy, #1)',
price: '£13.99'
},
{ title: "Shakespeare's Sonnets", price: '£20.66' },
{ title: 'Set Me Free', price: '£17.46' },
{
title: "Scott Pilgrim's Precious Little Life (Scott Pilgrim #1)",
price: '£52.29'
},
…output omitted…
Rotação de proxy com Crawlee
Um proxy é o intermediário entre seu computador e a internet. Quando você usa um proxy, ele envia suas solicitações da web para o servidor proxy, que as encaminha para o site de destino. O servidor proxy envia de volta a resposta do site, e o proxy oculta seu endereço IP e evita que você tenha uma taxa limitada ou que seu IP seja banido.
O Crawlee facilita a implementação do proxy porque vem com tratamento de proxy integrado, que lida com novas tentativas e erros de forma eficiente. O Crawlee também suporta uma variedade de configurações de proxy para implementar proxies rotativos.
Na seção a seguir, você configurará um proxy obtendo primeiro um proxy válido. Em seguida, você verificará se suas solicitações estão passando pelos proxies.
Configure um proxy
Proxies gratuitos geralmente não são recomendados porque podem ser lentos e não seguros e podem não ter o suporte necessário para tarefas confidenciais na web. Em vez disso, considere usar Bright Data, um serviço de proxy seguro, estável e confiável. Ele também oferece testes gratuitos, para que você possa testá-lo antes de tomar uma decisão.
Para usar a Bright Data, clique no botão Iniciar teste gratuito na página inicial e preencha as informações necessárias para criar uma conta.
Após criar sua conta, faça login, acesse o painel de controle Bright Data, vá até Proxies & Scraping Infrastructure e selecione Residential Proxies para adicionar um novo proxy:
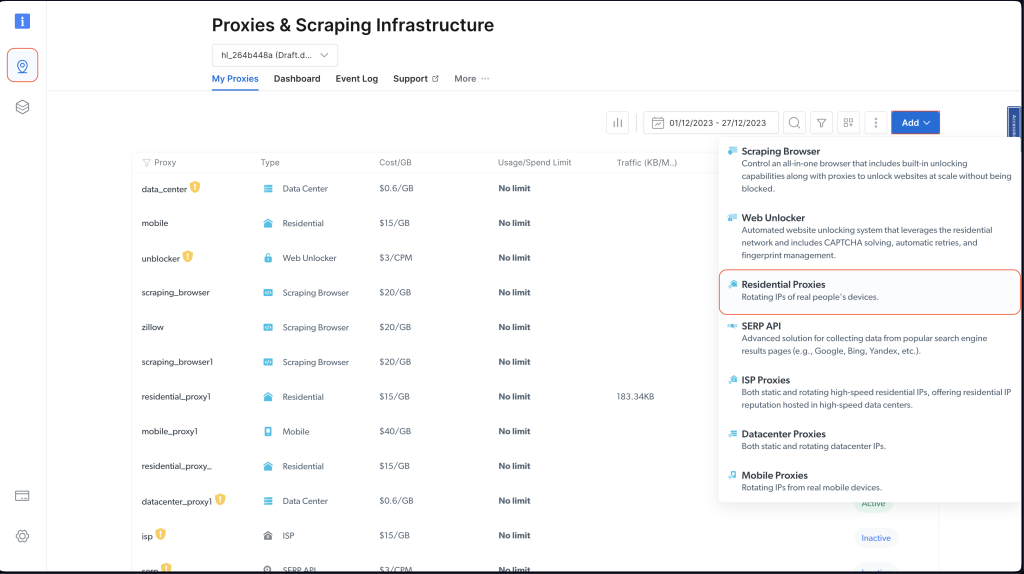
Mantenha as configurações padrão e finalize a criação do seu proxy residencial clicando em Add:
Caso lhe seja solicitada a instalação de um certificado, você pode selecionar Proceed without certificate. No entanto, para casos de produção e de uso real, você deve configurar o certificado para evitar uso indevido caso suas informações de proxy sejam expostas.
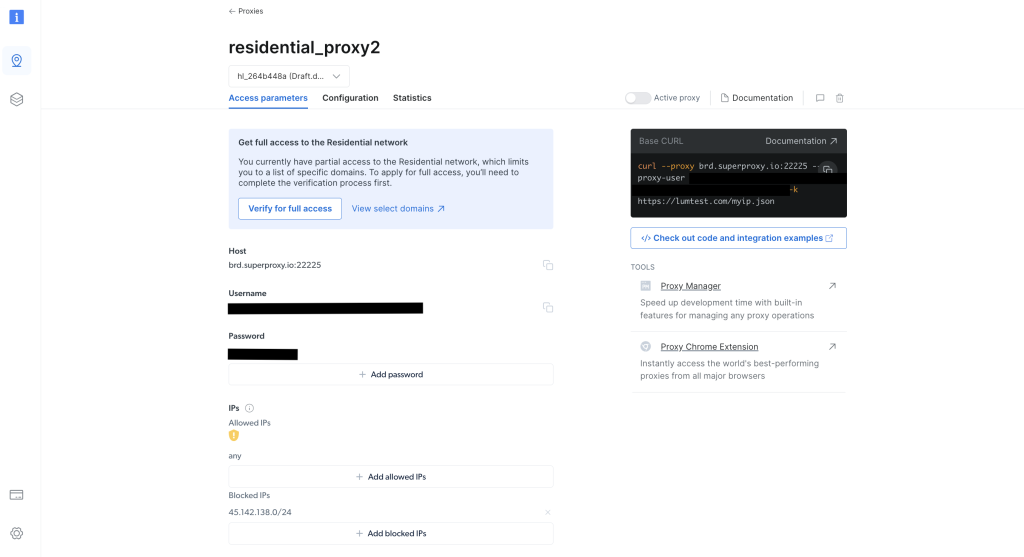
Depois de criado, anote as credenciais do proxy, incluindo host, porta, nome de usuário e senha. Você precisará delas no próximo passo:
No diretório raiz do seu projeto, execute o seguinte comando para instalar a biblioteca axios:
npm install axios
Você usa a biblioteca axios para fazer uma solicitação GET para http://lumtest.com/myip.json, que retorna os detalhes do proxy que você está usando toda vez que executa o script.
Em seguida, no diretório raiz do seu projeto, crie um arquivo chamado scrapeWithProxy.js e adicione o seguinte código:
const { CheerioCrawler } = require("crawlee");
const { ProxyConfiguration } = require("crawlee");
const axios = require("axios");
const proxyConfiguration = new ProxyConfiguration({
proxyUrls: ["http://USERNAME:PASSWORD@HOST:PORT"],
});
const crawler = new CheerioCrawler({
proxyConfiguration,
async requestHandler({ request, $, response, proxies }) {
// Make a GET request to the proxy information URL
try {
const proxyInfo = await axios.get("http://lumtest.com/myip.json", {
proxy: {
host: "HOST",
port: PORT,
auth: {
username: "USERNAME",
password: "PASSWORD",
},
},
});
console.log("Proxy Information:", proxyInfo.data);
} catch (error) {
console.error("Error fetching proxy information:", error.message);
}
const books = [];
$("article.product_pod").each((index, element) => {
const title = $(element).find("h3 a").attr("title");
const price = $(element).find(".price_color").text();
books.push({ title, price });
});
console.log(books);
},
});
crawler.run(["https://books.toscrape.com/"]);
Nota: certifique-se de substituir
HOST,PORT,USERNAMEePASSWORDpelas suas credenciais.
Neste código, você está usando CheerioCrawler do crawlee para coletar informações de https://books.toscrape.com/ usando um proxy especificado. Você configura o proxy com ProxyConfiguration; depois, busca e registra os detalhes do proxy usando uma solicitação GET para http://lumtest.com/myip.json. Finalmente, você extrai os títulos e preços dos livros usando a sintaxe do tipo jQuery da Cheerio e registra os dados copiados no console.
Agora, você pode executar e testar o código para garantir que os proxies estejam funcionando:
node scrapeWithProxy.js
Você verá resultados semelhantes aos anteriores, mas, desta vez, suas solicitações são encaminhadas por meio de proxies da Bright Data. Você também deve ver os detalhes do proxy logado no console:
Proxy Information: {
country: 'US',
asn: { asnum: 21928, org_name: 'T-MOBILE-AS21928' },
geo: {
city: 'El Paso',
region: 'TX',
region_name: 'Texas',
postal_code: '79925',
latitude: 31.7899,
longitude: -106.3658,
tz: 'America/Denver',
lum_city: 'elpaso',
lum_region: 'tx'
}
}
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
{ title: 'Soumission', price: '£50.10' },
{ title: 'Sharp Objects', price: '£47.82' },
{ title: 'Sapiens: A Brief History of Humankind', price: '£54.23' },
{ title: 'The Requiem Red', price: '£22.65' },
…output omitted..
Se você executar o script novamente com node scrapingWithBrightData.js, verá que um endereço IP de outro local está sendo usado pelo servidor proxy da Bright Data. Isso valida que a Bright Data alterna locais e IPs toda vez que você executa seu script de extração de dados. Essa rotação é importante para contornar bloqueios ou proibições de IP dos sites de destino.
Nota: na
proxyConfiguration, você poderia ter passado IPs de proxy diferentes, mas como a Bright Data faz isso por você, você não precisa especificar os IPs.
Gerenciamento de sessões com Crawlee
As sessões ajudam a manter o estado em várias solicitações, o que é útil para sites que usam cookies ou sessões de login.
Para gerenciar uma sessão, crie um arquivo chamado scrapeWithSessions.js no diretório raiz do seu projeto e adicione o seguinte código:
const { CheerioCrawler, SessionPool } = require("crawlee");
(async () => {
// Open a session pool
const sessionPool = await SessionPool.open();
// Ensure there is a session in the pool
let session = await sessionPool.getSession();
if (!session) {
session = await sessionPool.createSession();
}
const crawler = new CheerioCrawler({
useSessionPool: true, // Enable session pool
async requestHandler({ request, $, response, session }) {
// Log the session information
console.log(`Using session: ${session.id}`);
// Extract book data and log it (for demonstration)
const books = [];
$("article.product_pod").each((index, element) => {
const title = $(element).find("h3 a").attr("title");
const price = $(element).find(".price_color").text();
books.push({ title, price });
});
console.log(books);
},
});
// First run
await crawler.run(["https://books.toscrape.com/"]);
console.log("First run completed.");
// Second run
await crawler.run(["https://books.toscrape.com/"]);
console.log("Second run completed.");
})();
Aqui, você está usando o CheerioCrawler e o SessionPool do crawlee para coletar dados de https://books.toscrape.com/. Você inicializa um pool de sessões e, em seguida, configura o rastreador para utilizar essa sessão. A função requestHandler registra as informações da sessão e extrai títulos e preços dos livros usando seletores semelhantes a jQuery da Cheerio. O código faz duas execuções de scraping consecutivas e registra o ID da sessão em cada execução.
Execute e teste o código para validar se diferentes sessões estão sendo usadas:
node scrapeWithSessions.js
Você provavelmente verá resultados semelhantes aos de antes, mas desta vez, também verá o ID da sessão para cada execução:
Using session: session_GmKuZ2TnVX
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
…output omitted…
Using session: session_lNRxE89hXu
[
{ title: 'A Light in the Attic', price: '£51.77' },
{ title: 'Tipping the Velvet', price: '£53.74' },
…output omitted…
Se você executar o código novamente, verá que um ID de sessão diferente está sendo usado.
Tratamento de conteúdo dinâmico com Crawlee
Se você está lidando com sites dinâmicos (ou seja, sites que vêm com conteúdo preenchido por JavaScript), a extração de dados da web pode ser extremamente desafiadora porque você precisa renderizar JavaScript para acessar os dados. Para lidar com essas situações, o Crawlee se integra ao Puppeteer, que é um navegador headless que pode renderizar JavaScript e interagir com o site de destino da mesma forma que um humano faria.
Para demonstrar essa funcionalidade, vamos extrair o conteúdo desta página do YouTube. Como sempre, antes de copiar qualquer coisa, certifique-se de revisar as regras e termos de serviço dessa página.
Depois de revisar os termos de serviço, crie um arquivo chamado scrapeDynamicContent.js no diretório raiz do seu projeto e adicione o seguinte código:
const { PuppeteerCrawler } = require("crawlee");
async function scrapeYouTube() {
const crawler = new PuppeteerCrawler({
async requestHandler({ page, request, enqueueLinks, log }) {
const { url } = request;
await page.goto(url, { waitUntil: "networkidle2" });
// Scraping first 10 comments
const comments = await page.evaluate(() => {
return Array.from(document.querySelectorAll("#comments #content-text"))
.slice(0, 10)
.map((el) => el.innerText);
});
log.info(`Comments: ${comments.join("n")}`);
},
launchContext: {
launchOptions: {
headless: true,
},
},
});
// Add the URL of the YouTube video you want to scrape
await crawler.run(["https://www.youtube.com/watch?v=wZ6cST5pexo"]);
}
scrapeYouTube();
Depois execute o código com o seguinte comando:
node scrapeDynamicContent.js
Nesse código, você usa o PuppeteerCrawler da biblioteca Crawlee para extrair comentários de vídeos do YouTube. Você começa inicializando um rastreador que navega até um URL de vídeo específico do YouTube e espera que a página seja totalmente carregada. Depois que a página é carregada, o código avalia o conteúdo da página para extrair os primeiros dez comentários selecionando elementos com o seletor CSS especificado #comments #content-text. Os comentários são, então, registrados no console.
Seu resultado deve incluir os primeiros dez comentários relacionados ao vídeo selecionado:
INFO PuppeteerCrawler: Starting the crawler.
INFO PuppeteerCrawler: Comments: Who are you rooting for?? US Marines or Ex Cons
Bro Mateo is a beast, no lifting straps, close stance.
ex convict doing the pushups is a monster.
I love how quick this video was, without nonsense talk and long intros or outros
"They Both have combat experience" is wicked
That military guy doing that deadlift is really no joke.. ...
One lives to fight and the other fights to live.
Finally something that would test the real outcome on which narrative is true on movies
I like the comradery between all of them. Especially on the Bench Press ... Both team members quickly helped out on the spotting to protect from injury. Well done.
I like this style, no youtube funny business. Just straight to the lifts
…output omitted…
Você pode encontrar todo o código usado neste tutorial no GitHub.
Conclusão
Neste artigo, você aprendeu como usar o Crawlee para extrair dados da web e viu como ele pode ajudar a melhorar a eficiência e a confiabilidade de seus projetos de web scraping.
Lembre-se de sempre respeitar o arquivo robots.txt e os termos de serviço do site de destino ao extrair dados.
Pronto para aprimorar seus projetos de web scraping com dados, ferramentas e proxies de nível profissional? Explore a plataforma competa de extração de dados da web da Bright Data, oferecendo conjuntos de dados prontos para uso e serviços de proxy avançados para agilizar seus esforços de coleta de dados.
Inscreva-se agora e comece seu teste gratuito!





