

A raspagem da Web geralmente exige que você navegue por mecanismos anti-bot, carregue conteúdo dinâmico usando ferramentas de automação do navegador como o Puppeteer, use a rotação de proxy para evitar bloqueios de IP e resolva CAPTCHAs. Mesmo com essas estratégias, o dimensionamento e a manutenção de sessões estáveis continuam sendo um desafio.
Este artigo ensina você a fazer a transição da raspagem tradicional baseada em proxy para o Bright Data Scraping Browser. Saiba como automatizar o gerenciamento e o dimensionamento do proxy para reduzir os custos de desenvolvimento e manutenção. Os dois métodos serão comparados, abrangendo configuração, desempenho, escalabilidade e complexidade.
Observação: os exemplos deste artigo são para fins educacionais. Sempre consulte os termos de serviço do site de destino e cumpra as leis e os regulamentos relevantes antes de extrair quaisquer dados.
Pré-requisitos
Antes de iniciar o tutorial, verifique se você tem os seguintes pré-requisitos:
- Node.js
- Código do Visual Studio
- Uma conta gratuita da Bright Data para que você possa usar o navegador de raspagem
Comece criando uma nova pasta de projeto do Node.js onde você possa armazenar seu código.
Em seguida, abra seu terminal ou shell e crie um novo diretório usando os seguintes comandos:
mkdir scraping-tutorialrncd scraping-tutorial
Inicialize um novo projeto Node.js:
npm init -y
O sinalizador -y responde automaticamente sim a todas as perguntas, criando um arquivo package.json com as configurações padrão.
Raspagem da Web baseada em proxy
Em uma abordagem típica baseada em proxy, você usa uma ferramenta de automação de navegador como o Puppeteer para interagir com o domínio de destino, carregar conteúdo dinâmico e extrair dados. Ao fazer isso, você integra proxies para evitar proibições de IP e manter o anonimato.
Vamos criar rapidamente um script de coleta de dados da Web usando o Puppeteer que coleta dados de um site de comércio eletrônico usando proxies.
Criar um script de raspagem da Web usando o Puppeteer
Comece instalando o Puppeteer:
npm install puppeteer
Em seguida, crie um arquivo chamado proxy-scraper.js (você pode dar o nome que quiser) na pasta scraping-tutorial e adicione o seguinte código:
const puppeteer = require(u0022puppeteeru0022);rnrn(async () =u0026gt; {rn // Launch a headless browserrn const browser = await puppeteer.launch({rn headless: true,rn });rn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(books); // Print the collected datarnrn await browser.close();rn})();rn
Esse script usa o Puppeteer para extrair títulos e preços de livros das cinco primeiras páginas do site Books to Scrape. Ele inicia um navegador sem cabeçalho, abre uma nova página e navega por cada página do catálogo.
Para cada página, o script usa seletores DOM em page.evaluate() para extrair títulos e preços de livros, armazenando os dados em uma matriz. Depois que todas as páginas são processadas, os dados são impressos no console e o navegador é fechado. Essa abordagem extrai com eficiência os dados de um site paginado.
Teste e execute o código usando o seguinte comando:
node proxy-scraper.jsSeu resultado deve ser semelhante a este:
Navigating to: https://books.toscrape.com/catalogue/page-1.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-2.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-3.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-4.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-5.htmlrn[rn { title: 'A Light in the Attic', price: '£51.77' },rn { title: 'Tipping the Velvet', price: '£53.74' },rn { title: 'Soumission', price: '£50.10' },rn { title: 'Sharp Objects', price: '£47.82' },rn { title: 'Sapiens: A Brief History of Humankind', price: '£54.23' },rn { title: 'The Requiem Red', price: '£22.65' },rn…output omitted…rn {rn title: 'In the Country We Love: My Family Divided',rn price: '£22.00'rn }rn]
Configurar proxies
Os proxies são comumente empregados em configurações de raspagem para dividir as solicitações e torná-las não rastreáveis. Uma abordagem comum é manter um pool de proxies e alterná-los dinamicamente.
Coloque seus proxies em uma matriz ou armazene-os em um arquivo separado, se desejar:
const proxies = [rn u0022proxy1.example.com:portu0022, rn u0022proxy2.example.com:portu0022rn // Add more proxies herern];
Utilizar a lógica de rotação de proxy
Vamos aprimorar o código com a lógica que percorre a matriz de proxy sempre que você inicia o navegador. Atualize o proxy-scraper.js para incluir o seguinte código:
const puppeteer = require(u0022puppeteeru0022);rnrnconst proxies = [rn u0022proxy1.example.com:portu0022, rn u0022proxy2.example.com:portu0022rn // Add more proxies herern];rnrn(async () =u0026gt; {rn // Choose a random proxyrn const randomProxy =rn proxies[Math.floor(Math.random() * proxies.length)];rnrn // Launch Puppeteer with proxyrn const browser = await puppeteer.launch({rn headless: true,rn args: [rn `u002du002dproxy-server=http=${randomProxy}`,rn u0022u002du002dno-sandboxu0022,rn u0022u002du002ddisable-setuid-sandboxu0022,rn u0022u002du002dignore-certificate-errorsu0022,rn ],rn });rnrn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(`Using proxy: ${randomProxy}`);rn console.log(books); // Print the collected datarnrn await browser.close();rn})();rn
Observação: Em vez de fazer a rotação dos proxies manualmente, você pode usar uma biblioteca como a luminati-proxy para automatizar o processo.
Nesse código, um proxy aleatório é selecionado na lista de proxies e aplicado ao Puppeteer usando a opção --proxy-server=${randomProxy}. Para evitar a detecção, uma string de agente de usuário aleatória também é atribuída. A lógica de raspagem é então repetida e o proxy usado para raspar os dados do produto é registrado.
Quando você executar o código novamente, deverá ver uma saída como a anterior, mas com um acréscimo ao proxy que foi usado:
Navigating to: https://books.toscrape.com/catalogue/page-1.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-2.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-3.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-4.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-5.htmlrnUsing proxy: 115.147.63.59:8081rn…output omitted…
Desafios da raspagem baseada em proxy
Embora uma abordagem baseada em proxy possa funcionar para muitos casos de uso, você pode enfrentar alguns dos seguintes desafios:
- Bloqueios frequentes: os proxies podem ser bloqueados se o site tiver uma detecção anti-bot rigorosa.
- Custos indiretos de desempenho: a rotação de proxies e a repetição de solicitações tornam o pipeline de coleta de dados mais lento.
- Escalabilidade complexa: o gerenciamento e a rotação de um grande pool de proxies para obter desempenho e disponibilidade ideais são complexos. Requer balanceamento de carga, prevenção do uso excessivo de proxies, períodos de resfriamento e tratamento de falhas em tempo real. O desafio aumenta com as solicitações simultâneas, pois o sistema deve evitar a detecção e, ao mesmo tempo, monitorar e substituir continuamente os IPs na lista negra ou com baixo desempenho.
- Manutenção do navegador: a manutenção do navegador pode ser tecnicamente desafiadora e exigir muitos recursos. É necessário atualizar e manipular continuamente a impressão digital do navegador (cookies, cabeçalhos e outros atributos de identificação) para imitar o comportamento real do usuário e evitar controles antibot avançados.
- Sobrecarga do navegador na nuvem: os navegadores baseados na nuvem geram sobrecarga operacional adicional por meio de requisitos de recursos elevados e controle de infraestrutura complexo, o que leva a despesas operacionais elevadas. O dimensionamento das instâncias do navegador para obter um desempenho consistente complica ainda mais o processo.
DynamicScraping com o navegador Bright Data Scraping
Para ajudar com esses desafios, você pode usar uma solução de API única, como o Bright Data Scraping Browser. Isso simplifica sua operação, elimina a necessidade de rotação manual de proxy e configurações complexas do navegador e, muitas vezes, leva a uma taxa de sucesso maior na recuperação de dados.
Configure sua conta Bright Data
Para começar, faça login na sua conta da Bright Data e navegue até Proxies & Scraping, role para baixo até Scraping Browser e clique em Get Started:
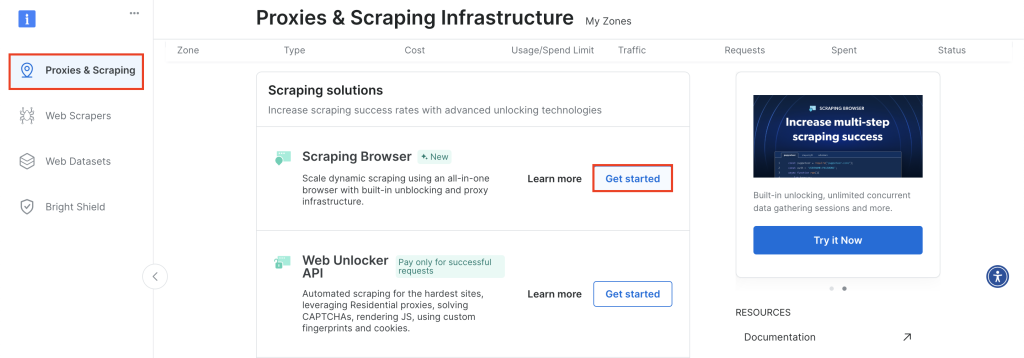
Mantenha a configuração padrão e clique em Add para criar uma nova instância do Scraping Browser:
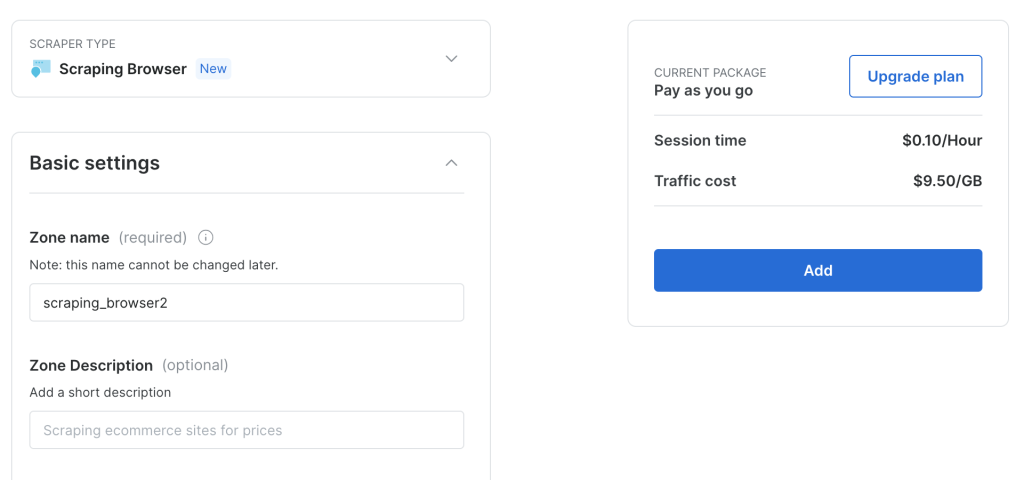
Depois de criar uma instância do navegador de raspagem, anote o URL do Puppeteer, pois você precisará dele em breve:
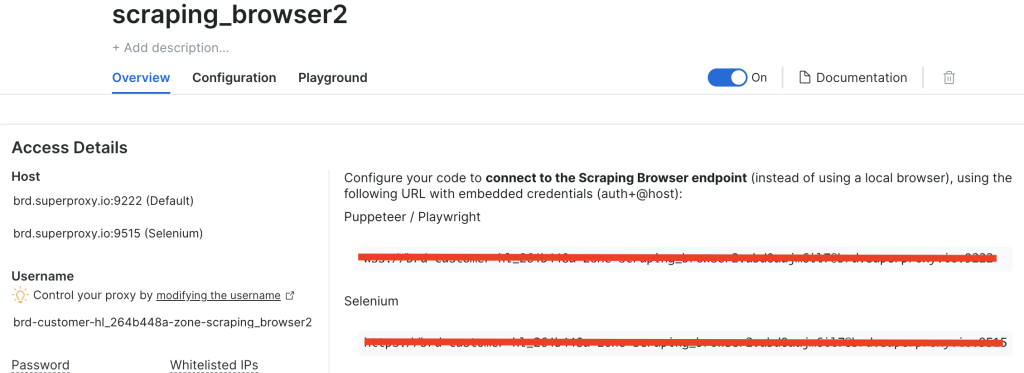
Ajuste o código para usar o navegador Bright Data Scraping
Agora, vamos ajustar o código para que, em vez de usar proxies rotativos, você se conecte diretamente ao endpoint do Bright Data Scraping Browser.
Crie um novo arquivo chamado brightdata-scraper.js e adicione o seguinte código:
const puppeteer = require(u0022puppeteeru0022);rnrn(async () =u0026gt; {rn // Choose a random proxyrn const SBR_WS_ENDPOINT = u0022YOUR_BRIGHT_DATA_WS_ENDPOINTu0022rnrn // Launch Puppeteer with proxyrn const browser = await puppeteer.connect({rn browserWSEndpoint: SBR_WS_ENDPOINT,rn });rnrn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(books); // Print the collected datarnrn await browser.close();rn})();
Certifique-se de substituir YOUR_BRIGHT_DATA_WS_ENDPOINT pelo URL que você recuperou na etapa anterior.
Esse código é semelhante ao código anterior, mas, em vez de ter uma lista de proxies e fazer malabarismos entre diferentes proxies, você se conecta diretamente ao endpoint da Bright Data.
Execute o seguinte código:
node brightdata-scraper.js
Seu resultado deve ser o mesmo de antes, mas agora não será necessário alternar manualmente os proxies ou configurar os agentes de usuário. O Bright Data Scraping Browser cuida de tudo, desde a rotação de proxy até o desvio de CAPTCHAs, garantindo a coleta ininterrupta de dados.
Transforme o código em um ponto de extremidade expresso
Se você quiser integrar o Bright Data Scraping Browser em um aplicativo maior, considere expô-lo como um endpoint Express.
Comece instalando o Express:
npm install express
Crie um arquivo chamado server.js e adicione o seguinte código:
const express = require(u0022expressu0022);rnconst puppeteer = require(u0022puppeteeru0022);rnrnconst app = express();rnconst PORT = 3000;rnrn// Needed to parse JSON bodies:rnapp.use(express.json());rnrn// Your Bright Data Scraping Browser WebSocket endpointrnconst SBR_WS_ENDPOINT =rn u0022wss://brd-customer-hl_264b448a-zone-scraping_browser2:[email protected]:9222u0022;rnrn/**rn POST /scraperrn Body example:rn {rn u0022baseUrlu0022: u0022https://books.toscrape.com/catalogue/page-u0022rn }rn*/rnapp.post(u0022/scrapeu0022, async (req, res) =u0026gt; {rn const { baseUrl } = req.body;rnrn if (!baseUrl) {rn return res.status(400).json({rn success: false,rn error: 'Missing u0022baseUrlu0022 in request body.',rn });rn }rnrn try {rn // Connect to the existing Bright Data (Luminati) Scraping Browserrn const browser = await puppeteer.connect({rn browserWSEndpoint: SBR_WS_ENDPOINT,rn });rnrn const page = await browser.newPage();rn const books = [];rnrn // Example scraping 5 pages of the base URLrn for (let i = 1; i {rn const data = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u0026gt; {rn const title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn const price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn data.push({ title, price });rn });rn return data;rn });rnrn books.push(...pageBooks);rn }rnrn // Close the browser connectionrn await browser.close();rnrn // Return JSON with the scraped datarn return res.json({rn success: true,rn books,rn });rn } catch (error) {rn console.error(u0022Scraping error:u0022, error);rn return res.status(500).json({rn success: false,rn error: error.message,rn });rn }rn});rnrn// Start the Express serverrnapp.listen(PORT, () =u0026gt; {rn console.log(`Server is listening on http://localhost:${PORT}`);rn});
Nesse código, você inicializa um aplicativo Express, aceita payloads JSON e define uma rota POST /scrape. Os clientes enviam um corpo JSON contendo o baseUrl, que é encaminhado para o endpoint do Bright Data Scraping Browser com o URL de destino.
Execute seu novo servidor Express:
node server.js
Para testar o ponto de extremidade, você pode usar uma ferramenta como o Postman (ou qualquer outro cliente REST de sua escolha) ou pode usar o curl do terminal ou do shell da seguinte forma:
curl -X POST http://localhost/scrape rn-H 'Content-Type: application/json' rn-d '{u0022baseUrlu0022: u0022https://books.toscrape.com/catalogue/page-u0022}'rn
Seu resultado deve ser semelhante a este:
{rn u0022successu0022: true,rn u0022booksu0022: [rn {rn u0022titleu0022: u0022A Light in the Atticu0022,rn u0022priceu0022: u0022£51.77u0022rn },rn {rn u0022titleu0022: u0022Tipping the Velvetu0022,rn u0022priceu0022: u0022£53.74u0022rn },rn {rn u0022titleu0022: u0022Soumissionu0022,rn u0022priceu0022: u0022£50.10u0022rn },rn {rn u0022titleu0022: u0022Sharp Objectsu0022,rn u0022priceu0022: u0022£47.82u0022rn },rn {rn u0022titleu0022: u0022Sapiens: A Brief History of Humankindu0022,rn u0022priceu0022: u0022£54.23u0022rn },rn {rn u0022titleu0022: u0022The Requiem Redu0022,rn u0022priceu0022: u0022£22.65u0022rn },rn {rn u0022titleu0022: u0022The Dirty Little Secrets of Getting Your Dream Jobu0022,rn u0022priceu0022: u0022£33.34u0022rn },rn {rn u0022titleu0022: u0022The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhullu0022,rn u0022priceu0022: u0022£17.93u0022rn },rn rn ... output omitted...rn rn {rn u0022titleu0022: u0022Judo: Seven Steps to Black Belt (an Introductory Guide for Beginners)u0022,rn u0022priceu0022: u0022£53.90u0022rn },rn {rn u0022titleu0022: u0022Joinu0022,rn u0022priceu0022: u0022£35.67u0022rn },rn {rn u0022titleu0022: u0022In the Country We Love: My Family Dividedu0022,rn u0022priceu0022: u0022£22.00u0022rn }rn ]rn}
A seguir, um diagrama que mostra o contraste entre a configuração manual (proxy rotativo) e a abordagem do Bright Data Scraping Browser:
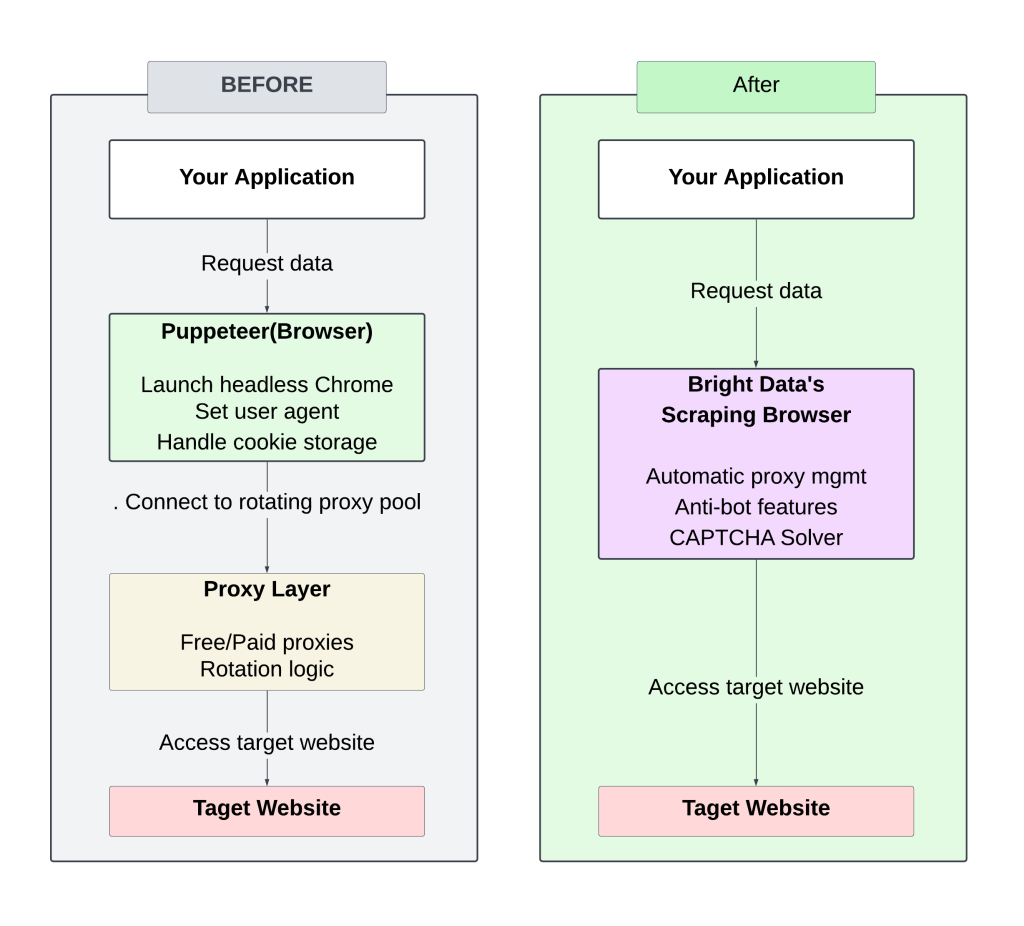
O gerenciamento de proxies rotativos manuais exige atenção e ajustes constantes, o que resulta em bloqueios frequentes e escalabilidade limitada.
O uso do Bright Data Scraping Browser simplifica o processo, eliminando a necessidade de gerenciar proxies ou cabeçalhos, além de proporcionar tempos de resposta mais rápidos por meio de uma infraestrutura otimizada. Suas estratégias anti-bot integradas aumentam as taxas de sucesso, tornando menos provável que você seja bloqueado ou sinalizado.
Todo o código para este tutorial está disponível neste repositório do GitHub.
Calcular o ROI
A mudança de uma configuração manual de raspagem baseada em proxy para o Bright Data Scraping Browser pode reduzir significativamente o tempo e os custos de desenvolvimento.
Configuração tradicional
A extração diária de sites de notícias requer o seguinte:
- Desenvolvimento inicial: cerca de 50 horas (US$ 5.000 a US$ 100/hora)
- Manutenção contínua: aproximadamente 10 horas/mês (US$ 1.000) para atualizações de código, infraestrutura, dimensionamento e gerenciamento de proxy
- Custos de proxy/IP: ~$250 USD/mês (varia de acordo com as necessidades de IP)
Custo mensal total estimado: ~$1.250 USD
Configuração do navegador do Bright Data Scraping
- Tempo de desenvolvimento: 5 a 10 horas (US$ 1.000)
- Manutenção: ~2-4 horas/mês ($200 USD)
- Não é necessárioproxy ou gerenciamento de infraestrutura
- Custos de serviço da Bright Data:
- Uso de tráfego: US$ 8,40/GB(por exemplo, 30GB/mês = US$ 252)
Custo mensal total estimado: ~$450 USD
A automação do gerenciamento de proxy e o dimensionamento do Bright Data Scraping Browser reduzem os custos iniciais de desenvolvimento e a manutenção contínua, tornando a raspagem de dados em grande escala mais eficiente e econômica.
Conclusão
A transição de uma configuração tradicional de raspagem da Web baseada em proxy para o Bright Data Scraping Browser elimina o incômodo da rotação de proxy e do tratamento manual anti-bot.
Além de buscar HTML, a Bright Data também oferece ferramentas adicionais para otimizar a extração de dados:
- Web Scrapers para ajudar a organizar sua extração de dados
- API do Web Unlocker para fazer scraping de sites mais difíceis
- Conjuntos de dados para que você possa acessar dados pré-coletados e estruturados
Essas soluções podem simplificar seu processo de raspagem, reduzir as cargas de trabalho e melhorar a escalabilidade.





