

Neste tutorial, você aprenderá como criar um script em Python para fazer raspagem de dados da seção “As pessoas também perguntam” do Google. Isso inclui perguntas frequentes relacionadas à sua consulta de pesquisa e contém informações valiosas.
Vamos lá!
Entendendo o recurso “As pessoas também perguntam” do Google
“As pessoas também perguntam” (PAA) é uma seção nos SERPs do Google (páginas de resultados de mecanismos de pesquisa) que apresenta uma lista dinâmica de perguntas relacionadas à consulta de pesquisa:

Esta seção ajuda você a explorar mais profundamente os tópicos relacionados à sua consulta de pesquisa. Lançado pela primeira vez por volta de 2015, o PAA aparece nos resultados de pesquisa como uma série de perguntas expansíveis. Quando uma pergunta é clicada, ela se expande para revelar uma breve resposta proveniente de uma página da web relevante, junto com um link para a fonte:
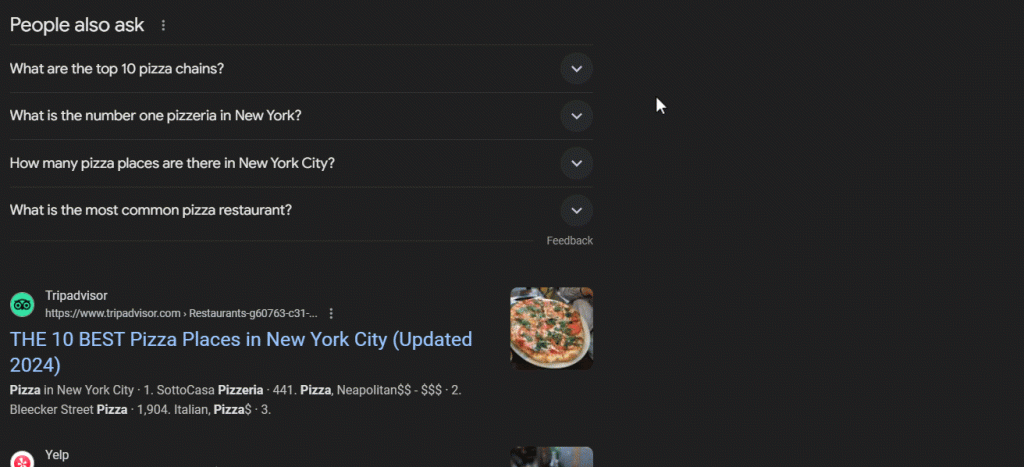
A seção “As pessoas também perguntam” é atualizada com frequência e se adapta com base nas pesquisas dos usuários, oferecendo informações novas e relevantes. Novas perguntas são carregadas dinamicamente à medida que você abre os menus suspensos.
Fazendo raspagem de dados da seção “As pessoas também perguntam” do Google: guia passo a passo
Siga esta seção orientada e aprenda a criar um script em Python para fazer raspagem de dados da seção “As pessoas também perguntam” de um SERP do Google.
O objetivo final é coletar os dados contidos em cada pergunta na seção “As pessoas também perguntam” da página. Se, em vez disso, você tiver interesse em fazer raspagem de dados do Google, siga nosso tutorial sobre Raspagem de dados de SERP.
Passo 1: configuração do projeto
Antes de começar, certifique-se de ter o Python 3 instalado em sua máquina. Caso contrário, baixe-o, execute o instalador e siga o assistente de instalação.
Em seguida, use os comandos abaixo para inicializar um projeto do Python com um ambiente virtual:
mkdir people-also-ask-scraper
cd people-also-ask-scraper
python -m venv env
O diretório people-also-ask-scraper representa a pasta do projeto do seu raspador PAA do Python.
Carregue a pasta do projeto em seu IDE Python favorito. PyCharm Community Edition ou Visual Studio Code com a extensão Python são duas ótimas opções.
Na pasta do projeto, crie um arquivo scraper.py . Agora é um script em branco, mas em breve conterá a lógica de raspagem de dados:

No terminal do IDE, ative o ambiente virtual. No Linux ou no macOS, execute este comando:
./env/bin/activate
Como alternativa, no Windows, execute:
env/Scripts/activate
Ótimo, agora você tem um ambiente Python para seu raspador de dados!
Passo 2: instalar o Selenium
O Google é uma plataforma que requer interação do usuário. Além disso, forjar um URL de pesquisa válido do Google pode ser um desafio. Então, a melhor maneira de trabalhar com o mecanismo de busca é dentro de um navegador.
Em outras palavras, para fazer raspagem de dados da seção “As pessoas também perguntam”, você precisa de uma ferramenta de automação do navegador. Se você não está familiarizado com esse conceito, ferramentas de automação de navegador permitem que você renderize e interaja com páginas da web dentro de um navegador controlável. Uma das melhores opções em Python é o Selenium!
Instale o Selenium executando o comando abaixo em um ambiente virtual Python ativado:
pip install selenium
O pacote selenium pip será adicionado às dependências do seu projeto. Isso pode demorar um pouco, então seja paciente.
Para obter mais detalhes sobre como usar essa ferramenta, leia nosso guia sobre raspagem de dados na web com Selenium.
Ótimo, agora você tem tudo o que precisa para começar a raspagem de dados das páginas do Google!
Etapa 3: navegar até a página inicial do Google
Importe o Selenium no scraper.py e inicialize um objeto WebDriver para controlar uma instância do Chrome no modo headless:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
O trecho acima cria uma instância do Chrome WebDriver , o objeto para controlar programaticamente uma janela do Chrome. A opção --headless configura o Chrome para ser executado no modo headless. Para fins de depuração, comente essa linha para que você possa observar as ações do script automatizado em tempo real.
Em seguida, use o método get () para se conectar à página inicial do Google:
driver.get("https://google.com/")
Não se esqueça de liberar os recursos do driver no final do script:
driver.quit()
Junte tudo e você terá:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google home page
driver.get("https://google.com/")
# scraping logic...
# close the browser and free up the resources
driver.quit()
Fantástico, você está pronto para fazer raspagem de dados de sites dinâmicos!
Etapa 4: lidar com a caixa de diálogo de cookies do GDPR
Observação: se você não estiver localizado na UE (União Europeia), você pode pular esta etapa.
Execute o script scraper.py no modo headed (com interface). Isso abrirá brevemente uma janela do navegador Chrome exibindo uma página do Google antes que o comando quit () a feche. Se você estiver na União Europeia, você vera o seguinte:
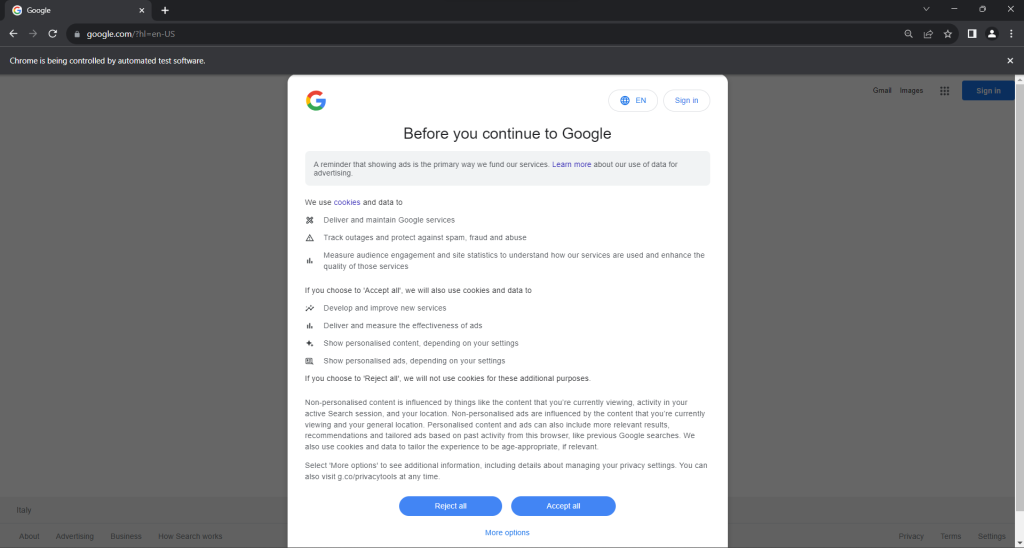
A mensagem “O Chrome está sendo controlado por software de teste automatizado.” garante que o Selenium está controlando o Chrome conforme desejado.
Usuários da UE recebem uma caixa de diálogo de política de cookies por motivos de GDPR . Se esse for o seu caso, você precisará lidar com isso se quiser interagir com a página subjacente. Caso contrário, você pode pular para a etapa 5.
Abra uma página do Google no modo de navegação anônima e inspecione a caixa de diálogo de cookies do GDPR. Clique com o botão direito do mouse e escolha a opção “Inspecionar”:
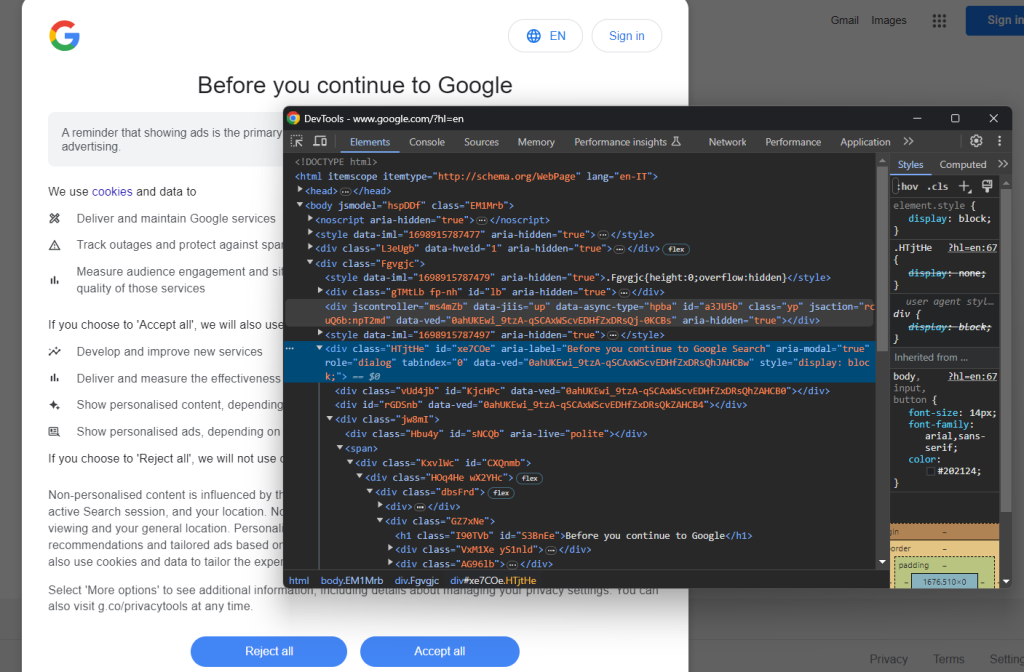
Note que você pode localizar o elemento HTML da caixa de diálogo com:
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
find_element() é um método fornecido pelo Selenium para localizar elementos HTML na página por meio de diferentes estratégias. Nesse caso, usamos um seletor CSS.
Não se esqueça de importar By da seguinte forma:
from selenium.webdriver.common.by import By
Agora, foque no botão “Aceitar tudo”:
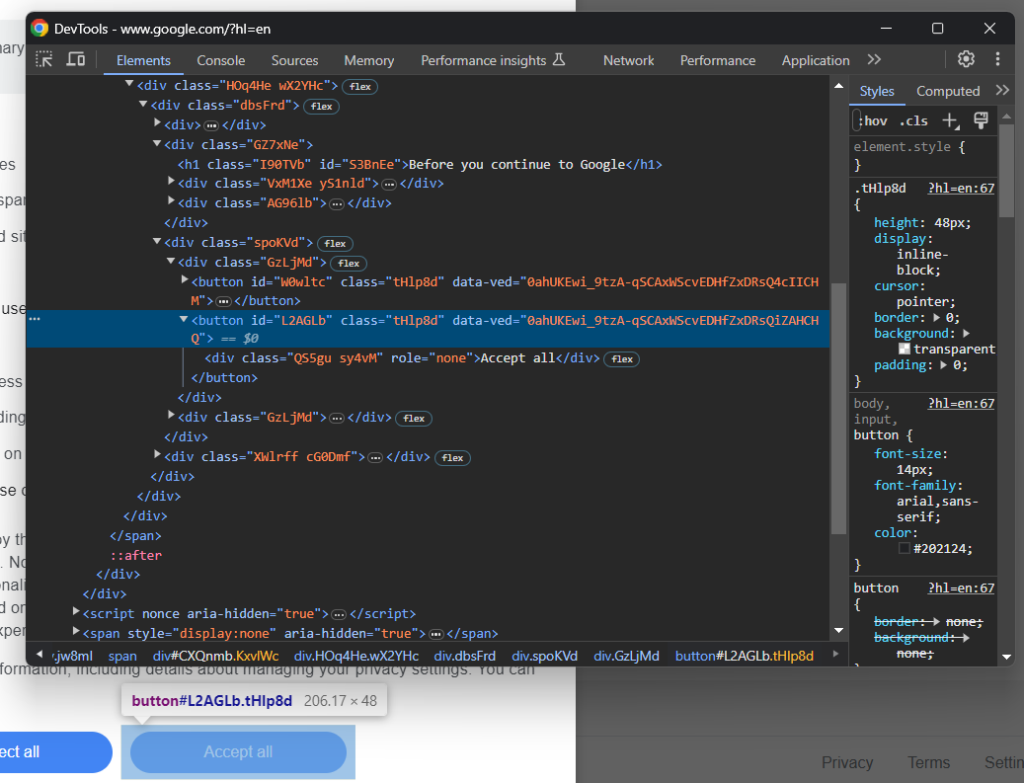
Como você pode ver, não há uma maneira fácil de selecioná-lo, pois sua classe CSS parece ter sido gerada aleatoriamente. Então, você pode coletá-lo usando uma expressão XPath que tem como alvo seu conteúdo:
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
Esta instrução localizará o primeiro botão na caixa de diálogo cujo texto contém a string “Aceitar”. Para obter mais informações, leia nosso guia sobre XPath versus seletor CSS.
Veja como tudo se encaixa para lidar com a caixa de diálogo opcional de cookies do Google:
try:
# select the dialog and accept the cookie policy
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
if accept_button is not None:
accept_button.click()
except NoSuchElementException:
print("Cookie dialog not present")
A instrução click() clica no botão “Aceitar tudo” para fechar a caixa de diálogo e permitir a interação do usuário. Se a caixa de diálogo da política de cookies não estiver presente, NoSuchElementException será lançada em seu lugar. O script fará a captura e continuará.
Lembre-se de importar o NoSuchElementException:
from selenium.common import NoSuchElementException
Muito bem! Você está pronto(a) para acessar a página com a seção “As pessoas também perguntam”.
Etapa 5: enviar o formulário de pesquisa
Acesse a página inicial do Google em seu navegador e inspecione o formulário de pesquisa. Clique com o botão direito sobre ele e selecione a opção “Inspecionar”:
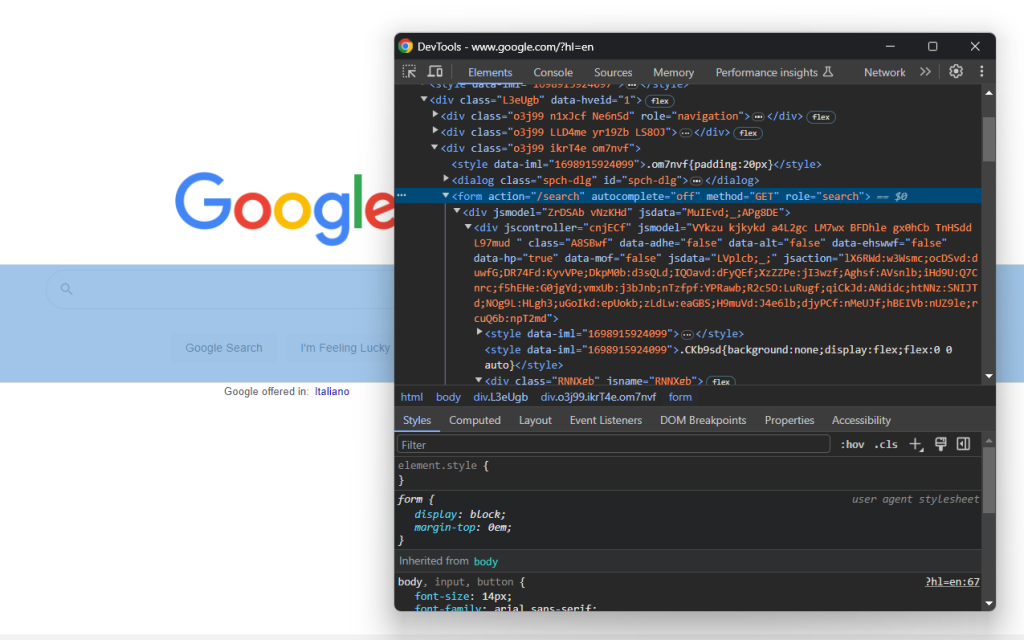
Esse elemento não tem classe CSS, mas você pode selecioná-lo por meio do atributo action :
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
Se você pulou a etapa 4, importe By com:
from selenium.webdriver.common.by import By
Expanda o código HTML do formulário e dê uma olhada na área de texto de pesquisa:
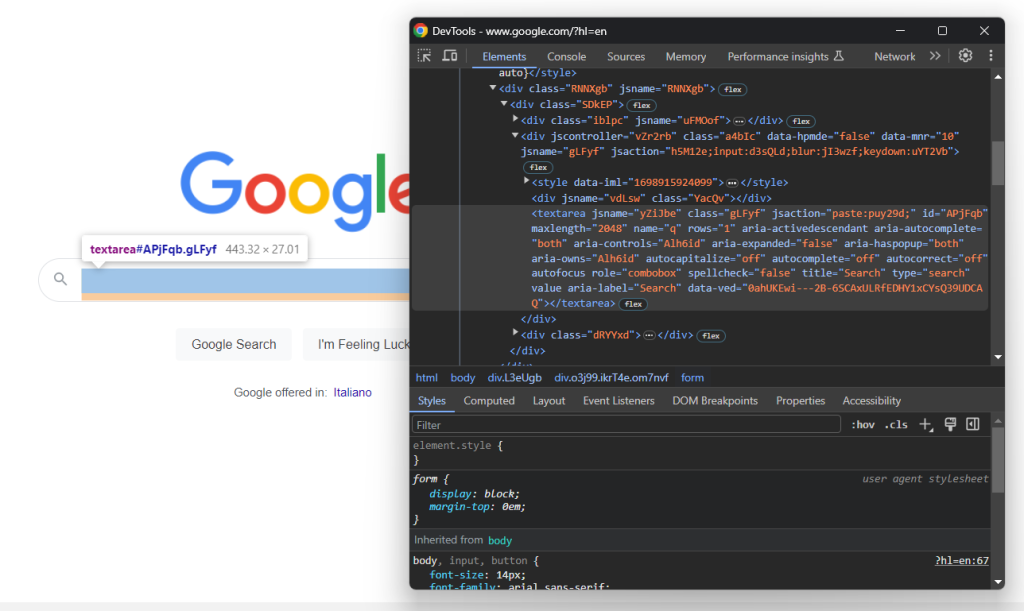
A classe CSS desse nó parece ter sido gerada aleatoriamente. Assim, selecione-o por meio de seu atributo aria-label . Em seguida, use o método send_keys() para digitar a consulta de pesquisa de destino:
search_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
search_query = "Bright Data"
search_textarea.send_keys(search_query)
Neste exemplo, a consulta de pesquisa é “Bright Data”, mas qualquer outra pesquisa é válida.
Envie o formulário para acionar uma mudança de página:
search_form.submit()
Excelente! O navegador controlado agora será redirecionado para a página do Google que contém a seção “As pessoas também perguntam”.
Se você executar o script no modo headed (com interface), isso é o que você deve ver antes do fechamento do navegador:
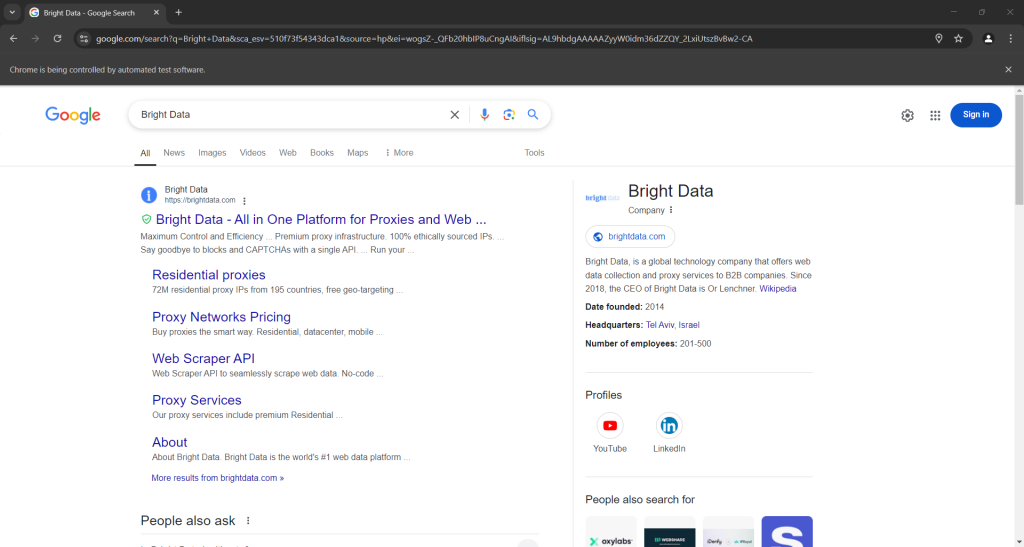
Observe a seção “As pessoas também perguntam” na parte inferior da captura de tela acima.
Etapa 6: selecionar o nó “As pessoas também perguntam”
Inspecione o elemento HTML “As pessoas também perguntam”:
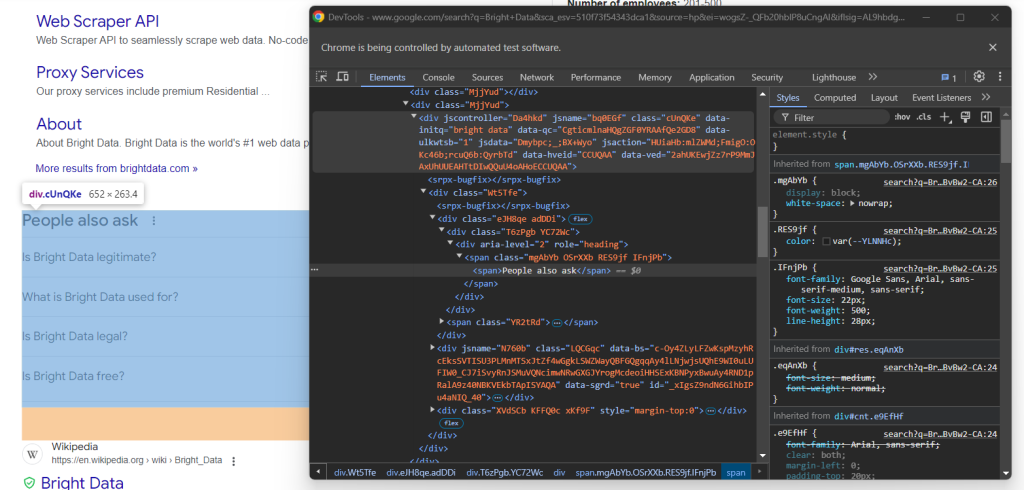
Novamente, não há uma maneira fácil de selecioná-lo. Desta vez, o que você pode fazer é recuperar o elemento <div> com os atributos jscontroller, jsname e jsaction que contém um div com role=heading com o texto “As pessoas também perguntam”:
people_also_ask_div = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((
By.XPATH, "//div[@jscontroller and @jsname and @jsaction][.//div[@role='heading' and contains(., 'People also ask')]]"
))
)
WebDriverWait é uma classe especial do Selenium que pausa o script até que uma condição específica seja atendida na página. Acima, ele espera até 5 segundos para que o elemento HTML desejado apareça. Isso é necessário para permitir que a página carregue completamente após o envio do formulário.
A expressão XPath usada em presence_of_element_located() é complexa, mas descreve com precisão os critérios necessários para selecionar o elemento “As pessoas também perguntam”.
Não esqueça de adicionar as importações necessárias:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
É hora de fazer a raspagem de dados da seção “As pessoas também perguntam” do Google!
Etapa 7: fazer a raspagem de dados da seção “As pessoas também perguntam”
Primeiro, inicialize uma estrutura de dados para armazenar os dados raspados:
people_also_ask_questions = []
Deve ser uma matriz, pois a seção “As pessoas também perguntam” contém várias perguntas.
Agora, inspecione a lista suspensa da primeira pergunta no nó “As pessoas também perguntam”:
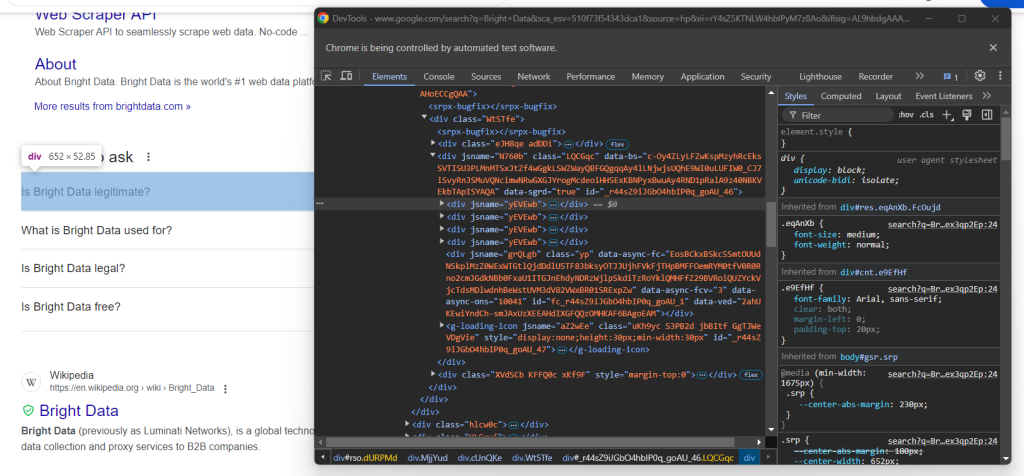
Aqui, você pode ver que os elementos de interesse são os elementos filhos do data-sgrd="true" <div> dentro do elemento “As pessoas também perguntam”, com apenas o atributo jsname . Os últimos dois elementos filhos são usados pelo Google como espaços reservados e são preenchidos dinamicamente à medida que você abre os menus suspensos.
Selecione os menus suspensos de perguntas com a seguinte lógica:
people_also_ask_inner_div = people_also_ask_div.find_element(By.CSS_SELECTOR, "[data-sgrd='true']")
people_also_ask_inner_div_children = people_also_ask_inner_div.find_elements(By.XPATH, "./*")
for child in people_also_ask_inner_div_children:
# if the current element is a question dropdown
if child.get_attribute("jsname") is not None and child.get_attribute("class") == '':
# scraping logic...
Clique no elemento para expandi-lo:
child.click()
Em seguida, concentre-se no conteúdo dentro dos elementos da pergunta:
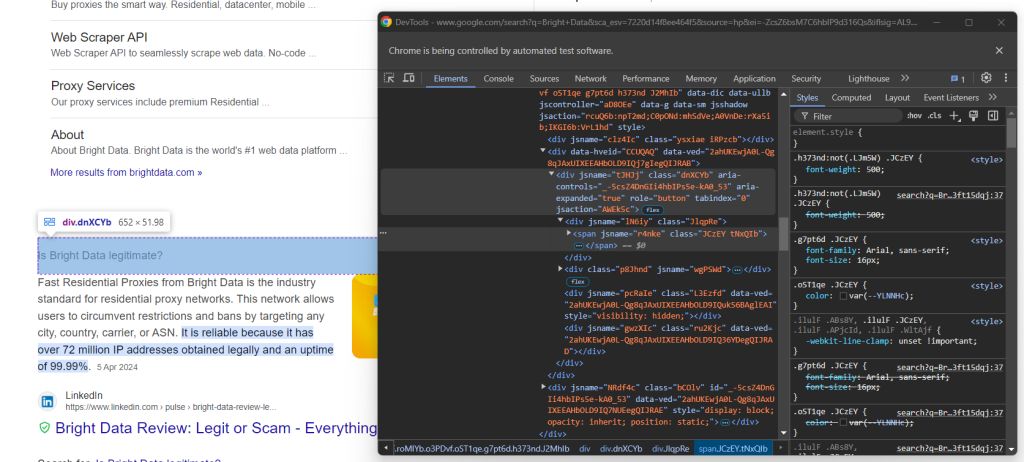
Observe que a pergunta está contida no <span> dentro do nó aria-expanded="true" . Faça a raspagem de dados da seguinte forma:
question_title_element = child.find_element(By.CSS_SELECTOR, "[aria-expanded='true'] span")
question_title = question_title_element.text
Em seguida, inspecione o elemento de resposta:
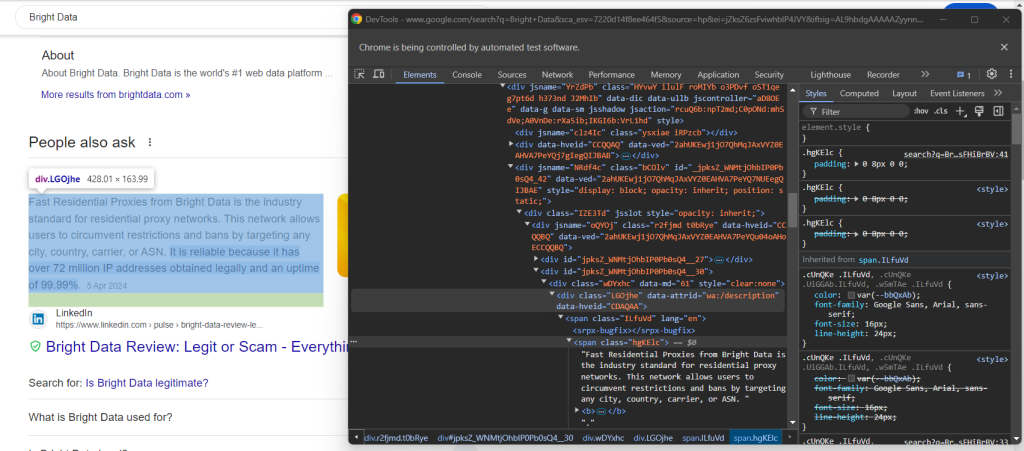
Observe como você pode recuperá-lo coletando o texto no nó <span> com o atributo lang dentro do elemento data-attrid="wa:/description" :
question_description_element = child.find_element(By.CSS_SELECTOR, "[data-attrid='wa:/description'] span[lang]")
question_description = question_description_element.text
Em seguida, inspecione a imagem opcional na caixa de resposta:
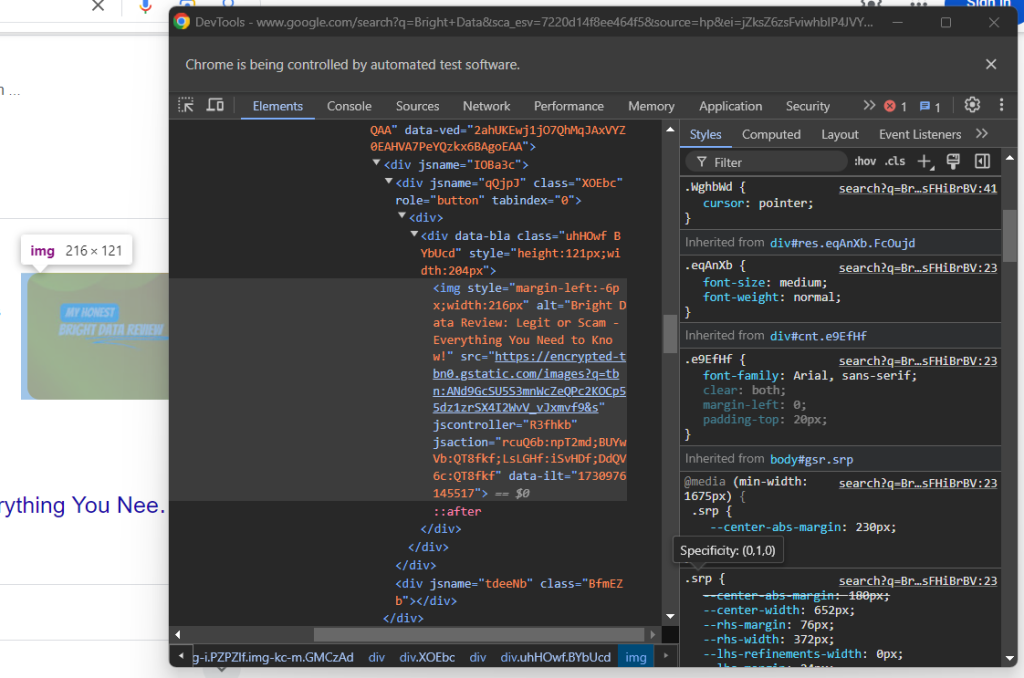
Você pode obter a URL acessando o atributo src do elemento <img> com o atributo data-ilt :
try:
question_image_element = child.find_element(By.CSS_SELECTOR, "img[data-ilt]")
question_image = question_image_element.get_attribute("src")
except NoSuchElementException:
question_image = None
Como o elemento de imagem é opcional, você deve envolver o código acima com um bloco try ... except . Se o nó não estiver presente na pergunta atual, find_element() gerará NoSuchElementException. O código fará a interceptação e seguirá em frente, nesse caso,
Se você pulou a etapa 4, importe a exceção:
from selenium.common import NoSuchElementException
Por fim, inspecione a seção de origem:
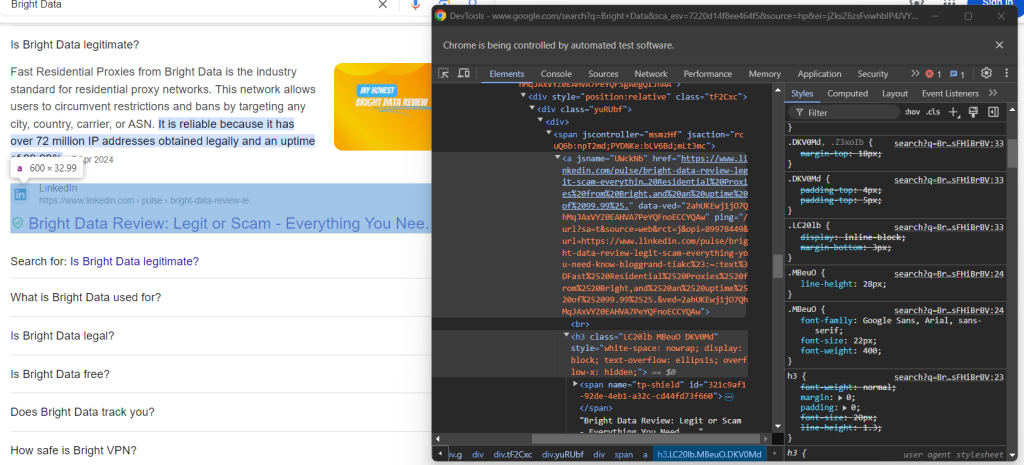
Você pode obter a URL da fonte selecionando o elemento pai <a> do elemento <h3> :
question_source_element = child.find_element(By.XPATH, ".//h3/ancestor::a")
question_source = question_source_element.get_attribute("href")
Use os dados raspados para preencher um novo objeto e adicioná-lo ao array people_also_ask_questions :
people_also_ask_question = {
"title": question_title,
"description": question_description,
"image": question_image,
"source": question_source
}
people_also_ask_questions.append(people_also_ask_question)
Muito bem! Você acabou de fazer a raspagem de dados da seção “As pessoas também perguntam” de uma página do Google.
Passo 8: exportar os dados raspados para CSV
Se você imprimir people_also_ask_questions, você verá o seguinte resultado:
[{'title': 'Is Bright Data legitimate?', 'description': 'Fast Residential Proxies from Bright Data is the industry standard for residential proxy networks. This network allows users to circumvent restrictions and bans by targeting any city, country, carrier, or ASN. It is reliable because it has 400M+ monthly IP addresses obtained legally and an uptime of 99.99%.', 'image': 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSU5S3mnWcZeQPc2KOCp55dz1zrSX4I2WvV_vJxmvf9&s', 'source': 'https://www.linkedin.com/pulse/bright-data-review-legit-scam-everything-you-need-know-bloggrand-tiakc#:~:text=Fast%20Residential%20Proxies%20from%20Bright,and%20an%20uptime%20of%2099.99%25.'}, {'title': 'What is Bright Data used for?', 'description': "Bright Data is the world's #1 web data platform, supporting the public data needs of over 22,000 organizations in nearly every industry. Using our solutions, organizations research, monitor, and analyze web data to make better decisions.", 'image': None, 'source': "https://brightdata.com/about#:~:text=Bright%20Data%20is%20the%20world's,data%20to%20make%20better%20decisions."}, {'title': 'Is Bright Data legal?', 'description': "Bright Data's platform, technology, and network (collectively, “Services”) are meant for legitimate and legal purposes only and are subject to the Bright Data Master Service Agreement.", 'image': None, 'source': "https://brightdata.com/acceptable-use-policy#:~:text=Bright%20Data's%20platform%2C%20technology%2C%20and,Bright%20Data%20Master%20Service%20Agreement."}, {'title': 'Is Bright Data free?', 'description': 'Bright Data offers four free proxy solutions to meet various needs: Anonymous Proxies: These top-performing anonymous proxies let you access websites anonymously, routing traffic through a vast Residential IP Network of 400M+ monthly IPs, concealing your true location.', 'image': None, 'source': 'https://brightdata.com/solutions/free-proxies#:~:text=Bright%20Data%20offers%20four%20free,IPs%2C%20concealing%20your%20true%20location.'}]
Claro, isso é ótimo, mas seria muito melhor se estivesse em um formato que você pudesse compartilhar facilmente com outros membros da equipe. Então, exporte people_also_ask_questions para um arquivo CSV!
Importe o pacote csv da biblioteca padrão do Python:
import csv
Em seguida, use-o para preencher um arquivo CSV de saída com seus dados SERP:
csv_file = "people_also_ask.csv"
header = ["title", "description", "image", "source"]
with open(csv_file, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(people_also_ask_questions)
Finalmente! Seu script de raspagem de dados da seção “As pessoas também perguntam” está concluído.
Passo 9: juntar tudo
Seu script final scraper.py deve conter o seguinte código:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google home page
driver.get("https://google.com/")
# deal with the optional Google cookie GDPR dialog
try:
# select the dialog and accept the cookie policy
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
if accept_button is not None:
accept_button.click()
except NoSuchElementException:
print("Cookie dialog not present")
# select the search form
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# select the textarea and fill it out
search_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
search_query = "Bright Data"
search_textarea.send_keys(search_query)
# submit the form to perform a Google search
search_form.submit()
# wait up to 5 seconds for the "People also ask" section
# to be on the page after page change
people_also_ask_div = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((
By.XPATH, "//div[@jscontroller and @jsname and @jsaction][.//div[@role='heading' and contains(., 'People also ask')]]"
))
)
# where to store the scraped data
people_also_ask_questions = []
# select the question dropdowns and iterate over them
people_also_ask_inner_div = people_also_ask_div.find_element(By.CSS_SELECTOR, "[data-sgrd='true']")
people_also_ask_inner_div_children = people_also_ask_inner_div.find_elements(By.XPATH, "./*")
for child in people_also_ask_inner_div_children:
# if the current element is a question dropdown
if child.get_attribute("jsname") is not None and child.get_attribute("class") == '':
# expand the element
child.click()
# scraping logic
question_title_element = child.find_element(By.CSS_SELECTOR, "[aria-expanded='true'] span")
question_title = question_title_element.text
question_description_element = child.find_element(By.CSS_SELECTOR, "[data-attrid='wa:/description'] span[lang]")
question_description = question_description_element.text
try:
question_image_element = child.find_element(By.CSS_SELECTOR, "img[data-ilt]")
question_image = question_image_element.get_attribute("src")
except NoSuchElementException:
question_image = None
question_source_element = child.find_element(By.XPATH, ".//h3/ancestor::a")
question_source = question_source_element.get_attribute("href")
# populate the array with the scraped data
people_also_ask_question = {
"title": question_title,
"description": question_description,
"image": question_image,
"source": question_source
}
people_also_ask_questions.append(people_also_ask_question)
# export the scraped data to a CSV file
csv_file = "people_also_ask.csv"
header = ["title", "description", "image", "source"]
with open(csv_file, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(people_also_ask_questions)
# close the browser and free up the resources
driver.quit()
Em 100 linhas de código, você acabou de criar um raspador de dados da seção PAA!
Verifique se ele funciona ao executá-lo. No Windows, inicie o raspador com:
python scraper.py
Como alternativa, no Linux ou no macOS, execute:
python3 scraper.py
Aguarde a execução do raspador terminar, e um arquivo people_also_ask.csv aparecerá no diretório raiz do seu projeto. Abra e você verá:
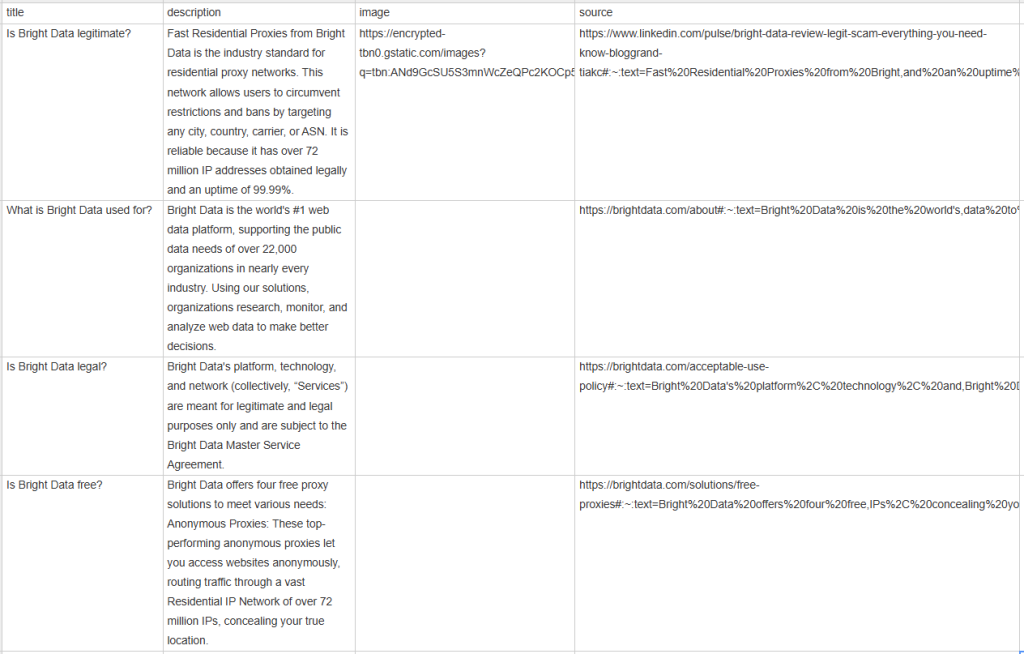
Parabéns, missão cumprida!
Conclusão
Neste tutorial, você aprendeu o que é a seção “As pessoas também perguntam” nas páginas do Google, os dados que ela contém e como fazer raspagem de dados usando Python. Como você aprendeu aqui, criar um script simples para extrair dados automaticamente requer apenas algumas linhas de código Python.
Embora a solução apresentada funcione bem para projetos pequenos, ela não é prática para raspagem de dados em grande escala. O problema é que o Google tem algumas das tecnologias anti-bots mais avançadas do setor. Portanto, ele pode bloquear você com CAPTCHAs ou proibições de IP. Além disso, escalar esse processo em várias páginas aumentaria os custos de infraestrutura.
Isso significa que é impossível fazer raspagem de dados do Google de forma eficiente e confiável? De jeito nenhum! Você simplesmente precisa de uma solução avançada que resolva esses desafios, como a API de pesquisa do Google da Bright Data.
A API de pesquisa do Google fornece um endpoint (ponto de extremidade) para recuperar dados das páginas do SERP do Google, incluindo a seção “As pessoas também perguntam”. Com uma simples chamada de API, você pode obter os dados desejados no formato JSON ou HTML. Veja como começar a usar na documentação oficial.
Inscreva-se agora e comece seu teste gratuito!





