

Google Flights é um serviço de reserva de voos amplamente usado que fornece uma grande variedade de dados, incluindo preços de voos, horários e detalhes da companhia aérea. Infelizmente, o Google não oferece uma API pública para acessar esses dados. No entanto, a raspagem de dados na web pode ser uma ótima alternativa para extrair esses dados.
Neste artigo, mostrarei como criar um raspador robusto do Google Flights usando Python. Analisaremos cada etapa para garantir que tudo esteja claro.
Por que fazer raspagem de dados no Google Flights?
A captura de voos do Google oferece várias vantagens, incluindo:
- Rastreio de preços de voos ao longo do tempo
- Análise de tendências de preços
- Identificação dos melhores horários para reservar voos
- Comparando preços em diferentes datas e companhias aéreas
Para viajantes, isso faz com que você encontre as melhores ofertas e economize dinheiro. Para empresas, ajuda na análise de mercado, na inteligência competitiva e no desenvolvimento de estratégias de preços eficazes.
Construindo o raspador de dados do Google Flights
O raspador que construímos permitirá que você insira detalhes como aeroporto de partida, destino, data da viagem e tipo de passagem (somente ida ou ida e volta). Se você estiver reservando uma viagem de ida e volta, também precisará fornecer uma data de retorno. O raspador de dados cuidará do resto: ele carrega todos os voos disponíveis, coleta os dados e salva os resultados em um arquivo JSON para análise posterior.
Se você é iniciante em raspagem de dados na web com Python, confira este tutorial para começar.
1. Quais dados você pode extrair do Google Flights?
O Google Flights fornece muitos dados, incluindo nomes de companhias aéreas, horários de partida e chegada, duração total, número de paradas, preços de passagens e dados de impacto ambiental (por exemplo, emissões de CO2).
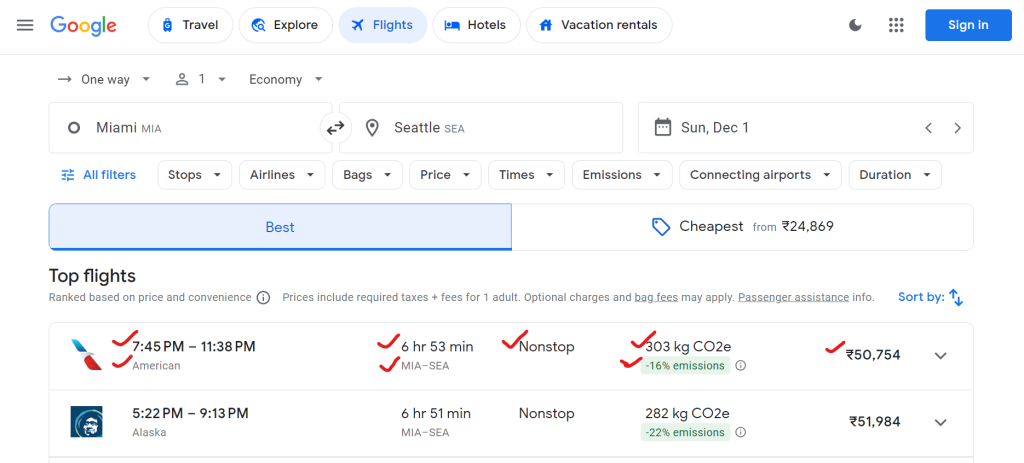
Aqui está um exemplo dos dados que você pode coletar:
{
"airline": "Alaska",
"departure_time": "5:22 PM",
"arrival_time": "9:13 PM",
"duration": "6 hr 51 min",
"stops": "Nonstop",
"price": "₹51,984",
"co2_emissions": "282 kg CO2e",
"emissions_variation": "-22% emissions"
}
2. Configurando o ambiente
Primeiro, vamos configurar o ambiente em seu sistema para executar o raspador.
# Create a virtual environment (optional)
python -m venv flight-scraper-env
# Activate the virtual environment
# On Windows:
.flight-scraper-envScriptsactivate
# On macOS/Linux:
source flight-scraper-env/bin/activate
# Install required packages
pip install playwright tenacity asyncio
# Install Playwright browsers
playwright install chromium
Playwright é ideal para automatizar navegadores e interagir com páginas dinâmicas da web, como o Google Flights. Usamos o Tenacity para implementar um mecanismo de repetição.
Se você é novo no Playwright, não deixe de conferir o guia sobre raspagem de dados na web com o Playwright.
3. Definindo classes de dados
Usando a classe de dados do Python, você pode estruturar perfeitamente os parâmetros de pesquisa e os dados de voo.
from dataclasses import dataclass
from typing import Optional
@dataclass
class SearchParameters:
departure: str
destination: str
departure_date: str
return_date: Optional[str] = None
ticket_type: str = "One way"
@dataclass
class FlightData:
airline: str
departure_time: str
arrival_time: str
duration: str
stops: str
price: str
co2_emissions: str
emissions_variation: str
Aqui, a classe SearchParameters armazena detalhes da pesquisa de voos, como partida, destino, datas e tipo de passagem, enquanto a classe FlightData armazena dados sobre cada voo, incluindo companhia aérea, preço, emissões de CO2 e outros detalhes relevantes.
4. Lógica de raspagem de dados na classe FlightScraper
A lógica principal de raspagem está encapsulada na classe FlightScraper . Aqui está uma análise detalhada:
4.1 Definindo seletores CSS
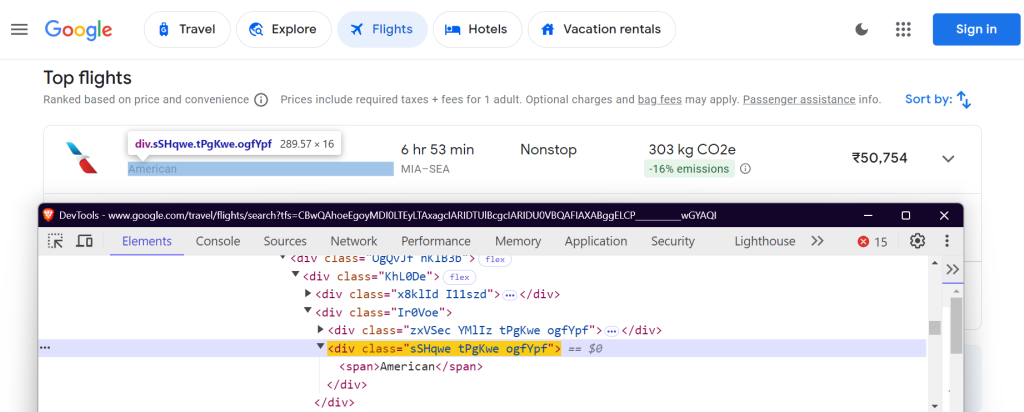
Você precisa localizar elementos específicos na página do Google Flights para extrair dados. Isso é feito usando seletores CSS. Veja como os seletores são definidos na classe FlightScraper :
class FlightScraper:
SELECTORS = {
"airline": "div.sSHqwe.tPgKwe.ogfYpf",
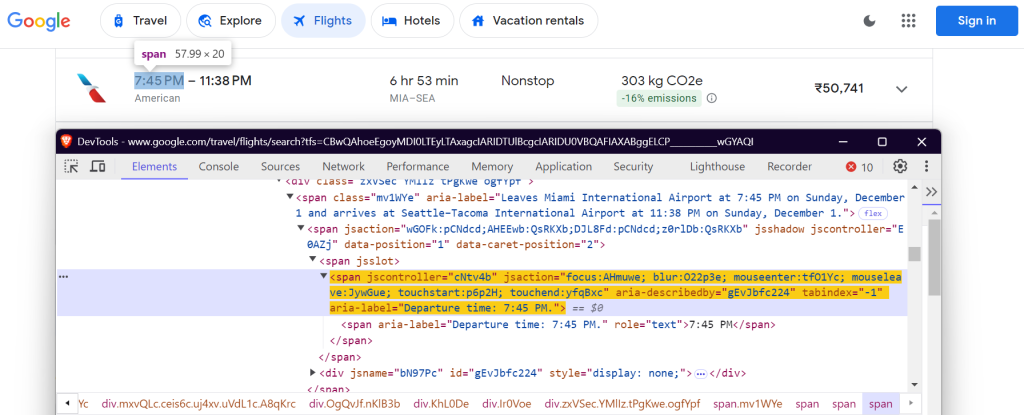
"departure_time": 'span[aria-label^="Departure time"]',
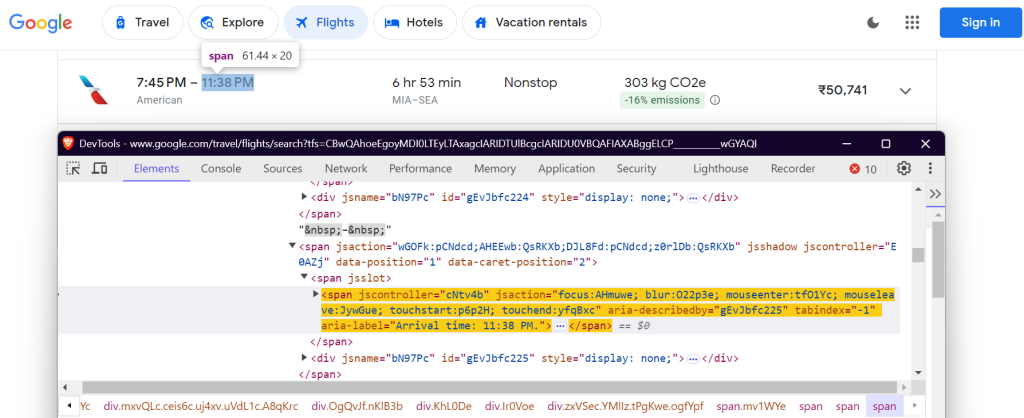
"arrival_time": 'span[aria-label^="Arrival time"]',
"duration": 'div[aria-label^="Total duration"]',
"stops": "div.hF6lYb span.rGRiKd",
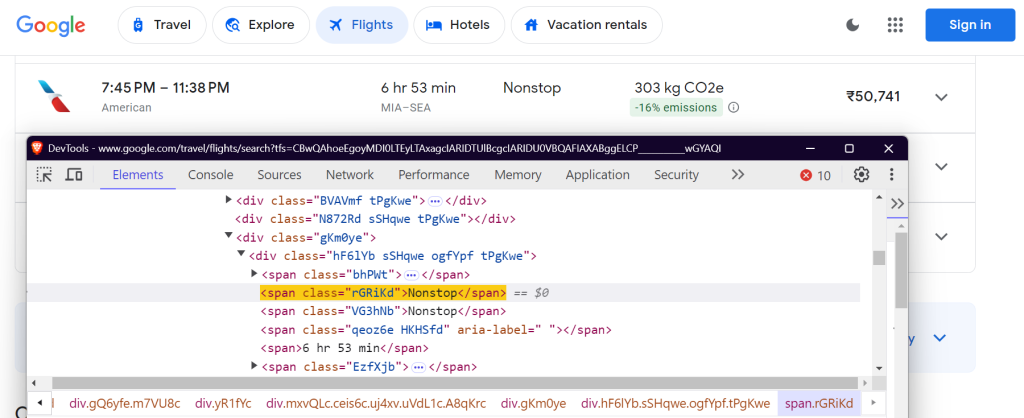
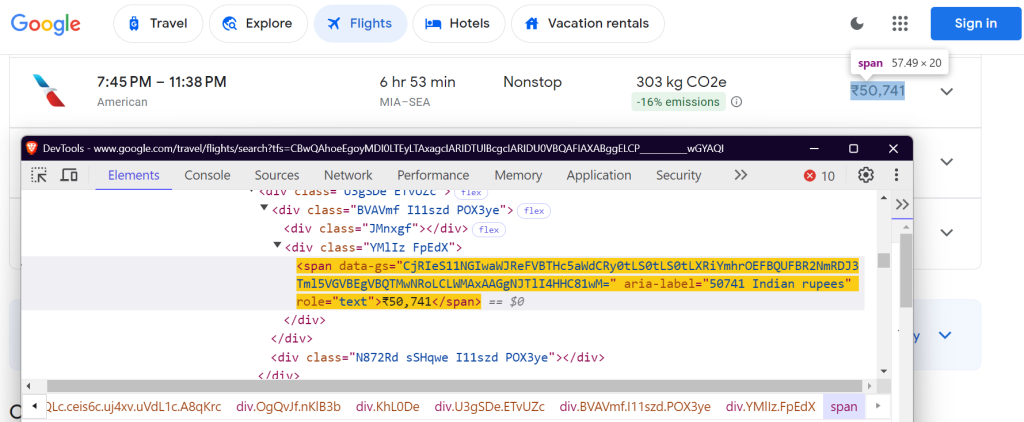
"price": "div.FpEdX span",
"co2_emissions": "div.O7CXue",
"emissions_variation": "div.N6PNV",
}
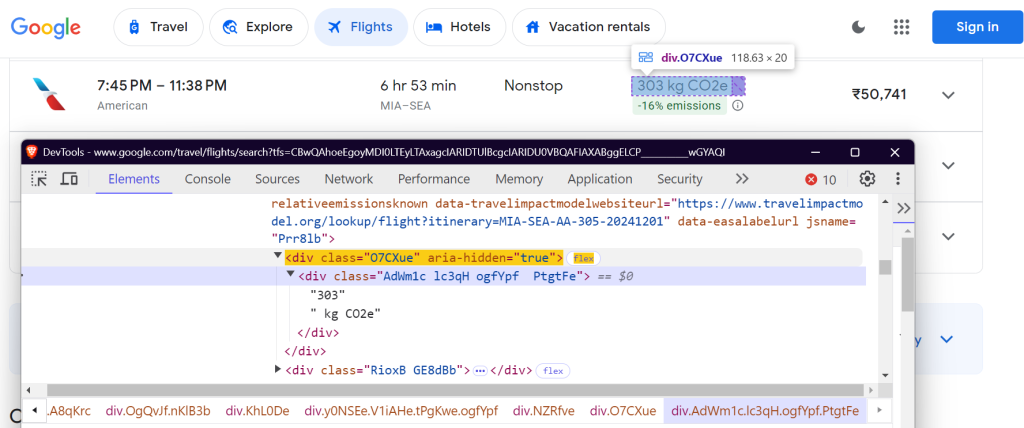
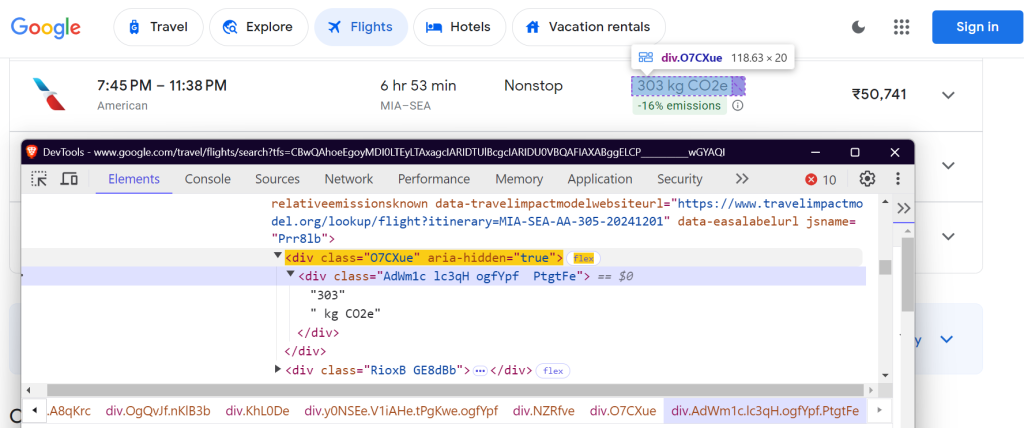
Esses seletores têm como alvo o nome da companhia aérea, os horários dos voos, a duração, as paradas, o preço e os dados de emissões.
Nome da companhia aérea:
Horário de partida:
Horário de chegada:
Duração do voo:

Número de paradas:
Preço:
CO2e:
Variação das emissões de CO2:
4.2 Preenchendo o formulário de pesquisa
O método _fill_search_form simula o preenchimento do formulário de pesquisa com detalhes de partida, destino e data:
async def _fill_search_form(self, page, params: SearchParameters) -> None:
# First, let's pick our ticket type
ticket_type_div = page.locator("div.VfPpkd-TkwUic[jsname='oYxtQd']").first
await ticket_type_div.click()
await page.wait_for_selector("ul[aria-label='Select your ticket type.']")
await page.locator("li").filter(has_text=params.ticket_type).nth(0).click()
# Now, let's fill in our departure and destination
from_input = page.locator("input[aria-label='Where from?']")
await from_input.click()
await from_input.fill("")
await page.keyboard.type(params.departure)
# ... rest of the form filling code
4.3 Carregando todos os resultados
O Google Flights usa paginação para carregar voos. Você precisa clicar no botão “Mostrar mais voos” para carregar todos os voos disponíveis:
async def _load_all_flights(self, page) -> None:
while True:
try:
more_button = await page.wait_for_selector(
'button[aria-label*="more flights"]', timeout=5000
)
if more_button:
await more_button.click()
await page.wait_for_timeout(2000)
else:
break
except:
break
4.4 Extraindo dados de voo
Depois que os voos estiverem carregados, você poderá fazer a raspagem de dados dos detalhes de voos:
async def _extract_flight_data(self, page) -> List[FlightData]:
await page.wait_for_selector("li.pIav2d", timeout=30000)
await self._load_all_flights(page)
flights = await page.query_selector_all("li.pIav2d")
flights_data = []
for flight in flights:
flight_info = {}
for key, selector in self.SELECTORS.items():
element = await flight.query_selector(selector)
flight_info[key] = await self._extract_text(element)
flights_data.append(FlightData(**flight_info))
return flights_data
5. Adicionando um mecanismo para tentar novamente
Para tornar nosso raspador mais confiável, adicione a lógica para tentar novamente usando a biblioteca tenacity :
@retry(stop=stop_after_attempt(3), wait=wait_fixed(5))
async def search_flights(self, params: SearchParameters) -> List[FlightData]:
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) ..."
)
# ... rest of the search implementation
6. Salvando resultados extraídos
Salve os dados de voo extraídos em um arquivo JSON para análise futura.
def save_results(self, flights: List[FlightData], params: SearchParameters) -> str:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = (
f"flight_results_{params.departure}_{params.destination}_{timestamp}.json"
)
output_data = {
"search_parameters": {
"departure": params.departure,
"destination": params.destination,
"departure_date": params.departure_date,
"return_date": params.return_date,
"search_timestamp": timestamp,
},
"flights": [vars(flight) for flight in flights],
}
filepath = os.path.join(self.results_dir, filename)
with open(filepath, "w", encoding="utf-8") as f:
json.dump(output_data, f, indent=2, ensure_ascii=False)
return filepath
7. Executando o raspador
Veja como executar o raspador do Google Flights:
async def main():
scraper = FlightScraper()
params = SearchParameters(
departure="MIA",
destination="SEA",
departure_date="2024-12-01",
# return_date="2024-12-30",
ticket_type="One way",
)
try:
flights = await scraper.search_flights(params)
print(f"Successfully found {len(flights)} flights")
except Exception as e:
print(f"Error during flight search: {str(e)}")
if __name__ == "__main__":
asyncio.run(main())
Resultados finais
Depois de executar o raspador, seus dados de voo serão salvos em um arquivo JSON da seguinte forma:
{
"search_parameters": {
"departure": "MIA",
"destination": "SEA",
"departure_date": "2024-12-01",
"return_date": null,
"search_timestamp": "20241027_172017"
},
"flights": [
{
"airline": "American",
"departure_time": "7:45 PM",
"arrival_time": "11:38 PM",
"duration": "6 hr 53 min",
"stops": "Nonstop",
"price": "₹50,755",
"co2_emissions": "303 kg CO2e",
"emissions_variation": "-16% emissions"
},
{
"airline": "Alaska",
"departure_time": "5:22 PM",
"arrival_time": "9:13 PM",
"duration": "6 hr 51 min",
"stops": "Nonstop",
"price": "₹51,984",
"co2_emissions": "282 kg CO2e",
"emissions_variation": "-22% emissions"
},
{
"airline": "Alaska",
"departure_time": "9:00 AM",
"arrival_time": "12:40 PM",
"duration": "6 hr 40 min",
"stops": "Nonstop",
"price": "₹62,917",
"co2_emissions": "325 kg CO2e",
"emissions_variation": "-10% emissions"
}
]
}
Você pode encontrar o código completo no meu GitHub Gist.
Desafios comuns para escalar a raspagem de dados do Google Flights
Ao escalar a raspagem de dados do Google Flights, desafios como bloqueio de IP e CAPTCHAs são comuns. Por exemplo, se você enviar muitas solicitações em pouco tempo usando um raspador, os sites podem bloquear seu endereço IP. Para evitar isso, você pode usar a rotação manual de IP ou optar por um dos principais serviços de proxy. Se você não tiver certeza sobre qual tipo de proxy é melhor para o seu tipo de uso, confira nosso guia sobre os melhores proxies para raspagem de dados na web.
Outro desafio é lidar com CAPTCHAs. Os sites costumam usá-los quando suspeitam do tráfego de bots, bloqueando seu scraper até que o CAPTCHA seja resolvido. Lidar com isso manualmente é demorado e complexo.
Então, qual é a solução? Vamos falar sobre isso a seguir!
A solução: ferramentas de raspagem na web da Bright Data
A Bright Data oferece uma variedade de soluções projetadas para simplificar e escalar seus esforços de raspagem de dados na web de forma eficiente. Vamos explorar como a Bright Data pode ajudar você a superar esses desafios comuns.
1. Proxies Residenciais
Os proxies residenciais da Bright Data oferecem a capacidade de acessar e rastrear sites de destino sofisticados. Proxies residenciais permitem que você roteie solicitações de raspagem de dados na web através de conexões residenciais legítimas. Suas solicitações aparecerão nos sites de destino como provenientes de usuários genuínos em uma região ou área específica. Como resultado, eles são uma solução eficaz para acessar páginas protegidas por medidas contra raspagem de dados baseadas em IP.
2. Web Unlocker
O Web Unlocker da Bright Data é perfeito para criar projetos que enfrentam CAPTCHAs ou restrições. Em vez de lidar manualmente com esses problemas, o Web Unlocker os trata automaticamente, adaptando-se às mudanças nos blocos do site com uma alta taxa de sucesso (normalmente 100%). Você simplesmente envia uma solicitação e o Web Unlocker cuida do resto.
3. Scraping Browser
O Scraping Browser da Bright Data é outra ferramenta poderosa para desenvolvedores que usam navegadores headless, como Puppeteer ou Playwright. Ao contrário dos navegadores headless tradicionais, o Scraping Browser lida com a resolução de CAPTCHA, a impressão digital do navegador, novas tentativas e muito mais — tudo automaticamente — para que você possa se concentrar na coleta de dados sem se preocupar com as restrições do site.
Conclusão
Este artigo discutiu como coletar dados do Google Flights usando Python e Playwright. Embora a raspagem de dados manual possa ser eficaz, ela geralmente traz desafios como banimentos de IP e a necessidade de manutenção contínua de scripts. Para simplificar e aprimorar seus esforços de coleta de dados, considere aproveitar as soluções da Bright Data, como proxies residenciais, Web Unlocker e Scraping Browser.
Inscreva-se para um teste gratuito com a Bright Data hoje mesmo!
Além disso, explore nossos guias sobre como coletar outros serviços do Google, como Dados de resultados de pesquisa do Google, Google Trends, Google Scholare Google Maps.





