

Neste guia, você descobrirá:
- O que é um agente de pesquisa e por que os métodos tradicionais falham
- Como configurar o Bright Data para uma coleta de dados confiável
- Como criar um agente de pesquisa local alimentado por IA com a interface de usuário Streamlit
- Como integrar as APIs da Bright Data com modelos locais para obter insights estruturados
Vamos nos aprofundar na criação de seu assistente de pesquisa inteligente. Também sugerimos que você confira o Deep Lookup, o mecanismo de pesquisa com IA da Bright Data que permite pesquisar na Web como um banco de dados.
Problema do setor
- Os pesquisadores enfrentam um excesso de informações de muitas fontes, o que torna a revisão manual impraticável.
- A pesquisa tradicional envolve buscas, extração e síntese lentas e manuais.
- Os resultados geralmente são incompletos, desconectados e mal organizados.
- Ferramentas simples de raspagem fornecem dados brutos sem credibilidade ou contexto.
Solução: Agente de pesquisa
O Deep Research Agent é um sistema de IA que automatiza a pesquisa, da coleta ao relatório. Ele lida com o contexto, gerencia tarefas e fornece insights bem estruturados.
Principais componentes:
- Planner Agent: divide a pesquisa em tarefas
- SubAgentes de pesquisa: realizam pesquisas e extraem dados
- Writer Agent: compila relatórios estruturados
- Condition Agent: verifica a qualidade e aciona uma pesquisa mais profunda, se necessário
Este guia mostra como criar um sistema de pesquisa local usando as APIs da Bright Data, uma interface de usuário Streamlit e LLMs locais para privacidade e controle.
Pré-requisitos
- Conta da Bright Data com chave de API.
- Python 3.10+
- Dependências:
solicitaçõesfaissouchromadbpython-dotenvstreamlitollama(para modelos locais)
Configuração da Bright Data
Criar conta na Bright Data
- Registre-se na Bright Data
- Navegue até a seção de credenciais da API
- Gere seu token de API
Armazene suas credenciais de API de forma segura usando variáveis de ambiente. Crie um arquivo .env para armazenar suas credenciais, mantendo as informações confidenciais separadas do seu código.
BRIGHT_DATA_API_KEY="your_bright_data_api_token_here"Configuração do ambiente
# Criar o venv
python -m venv venv
source venv/bin/activate
# Instalar dependências
pip install requests openai chromadb python-dotenv streamlitImplementação
Etapa 1: Pesquisa
Esta será nossa tarefa de pesquisa.
query = "IA use cases in healthcare" (casos de uso de IA na área de saúde)Etapa 2: Obter dados
Esta etapa demonstra como obter dados da Web de forma programática usando a API de coleta de dados da Bright Data. O código envia uma consulta de pesquisa e recupera dados relevantes enquanto manipula com segurança as credenciais da API.
importar requests, os
from dotenv import load_dotenv
load_dotenv()
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": consulta, "limit": 20}
headers = {"Authorization": f "Bearer {os.getenv('BRIGHT_DATA_API_KEY')}"}
res = requests.post(url, json=payload, headers=headers)
print(res.json())Etapa 3: processar e incorporar
Esta etapa processa os dados de pesquisa obtidos e os armazena no ChromaDB, um banco de dados vetorial que permite a pesquisa semântica e a correspondência de similaridade. Isso cria uma base de conhecimento pesquisável a partir dos resultados de sua pesquisa que pode ser consultada para casos de uso de IA na área de saúde ou em qualquer outro tópico de pesquisa.
importar chromadb
from chromadb.config import Settings
# Inicialização do ChromaDB
cliente = chromadb.PersistentClient(path="./research_db")
collection = client.get_or_create_collection("research_data")
# Armazenar os resultados da pesquisa
def store_research_data(results):
documents = []
metadados = []
ids = []
for i, item in enumerate(results):
documents.append(item.get('content', ''))
metadatas.append({
'source': item.get('source', ''),
'query': query,
'timestamp': item.get('timestamp', '')
})
ids.append(f "doc_{i}")
collection.add(
documents=documents,
metadatas=metadatas,
ids=ids
)Etapa 4: Sumarização de modelo local
Esta etapa demonstra como aproveitar os modelos de linguagem ampla (LLMs) executados localmente por meio do Ollama para gerar resumos concisos do conteúdo da pesquisa. Essa abordagem mantém o processamento de dados privado e permite recursos de resumo off-line.
importar subprocess
importar json
def summarize_with_ollama(content, model="llama2"):
"""Resume o conteúdo da pesquisa usando o modelo Ollama local"""
try:
result = subprocess.run(
['ollama', 'run', model, f "Resumir o conteúdo desta pesquisa: {content[:2000]}"],
capture_output=True,
text=True,
timeout=120
)
return result.stdout.strip()
exceto Exception as e:
return f "A compactação falhou: {str(e)}"
# Exemplo de uso
research_data = res.json().get('results', [])
for item in research_data:
summary = summarize_with_ollama(item.get('content', ''))
print(f "Summary: {summary}")ollama run llama2 "Resumir casos de uso de IA no setor de saúde"IU do Streamlit
Por fim, crie uma interface de usuário completa na Web que combine a coleta de dados da Bright Data com o resumo local de IA por meio do Ollama. A interface permite que os usuários configurem parâmetros de pesquisa, executem a coleta de dados e gerem resumos de IA por meio de um painel intuitivo.
Criar app.py
importar streamlit como st
importar requests, os
from dotenv import load_dotenv
importar subprocess
importar json
load_dotenv()
st.set_page_config(page_title="Deep Research Agent", page_icon="🔎")
st.title("🔎 Agente local de pesquisa profunda com dados brilhantes")
# Configuração da barra lateral
com st.sidebar:
st.header("Configuration")
api_key = st.text_input(
"Chave da API da Bright Data",
type="password",
value=os.getenv('BRIGHT_DATA_API_KEY', '')
)
model_choice = st.selectbox(
"Ollama Model",
["llama2", "mistral", "codellama"]
)
research_depth = st.slider("Research Depth", 5, 50, 20)
# Interface principal de pesquisa
query = st.text_input("Enter research topic:", "IA use cases in healthcare")
col1, col2 = st.columns(2)
com col1:
if st.button("🚀 Run Research", type="primary"):
if not api_key:
st.error("Digite sua chave da API de dados brilhantes")
elif not query:
st.error("Por favor, digite um tópico de pesquisa")
else:
with st.spinner("Coletando dados de pesquisa..."):
# Obter dados da Bright Data
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": consulta, "limit": research_depth}
headers = {"Authorization": f "Bearer {api_key}"}
res = requests.post(url, json=payload, headers=headers)
Se res.status_code == 200:
st.success(f "Coletou com êxito {len(res.json().get('results', []))} fontes!")
st.session_state.research_data = res.json()
# Exibir resultados
for i, item in enumerate(res.json().get('results', [])):
with st.expander(f "Source {i+1}: {item.get('title', 'No title')}"):
st.write(item.get('content', 'No content available'))
else:
st.error(f "Failed to fetch data: {res.status_code}")
com col2:
if st.button("🤖 Summarize with Ollama"):
if 'research_data' in st.session_state:
with st.spinner("Gerando resumos de IA..."):
for i, item in enumerate(st.session_state.research_data.get('results', [])):
content = item.get('content', '')[:1500] # Limitar o tamanho do conteúdo
try:
result = subprocess.run(
['ollama', 'run', model_choice, f "Summarize this content: {content}"],
capture_output=True,
text=True,
timeout=60
)
summary = result.stdout.strip()
com st.expander(f "IA Summary {i+1}"):
st.write(summary)
exceto Exception as e:
st.error(f "Summarization failed for source {i+1}: {str(e)}")
else:
st.warning("Por favor, execute a pesquisa primeiro para coletar dados")
# Exibir dados brutos, se disponíveis
if 'research_data' in st.session_state:
with st.expander("View Raw Research Data"):
st.json(st.session_state.research_data)Execute o aplicativo:
streamlit run app.pyQuando você executa o aplicativo e visita a porta 8501, esta deve ser a interface do usuário:
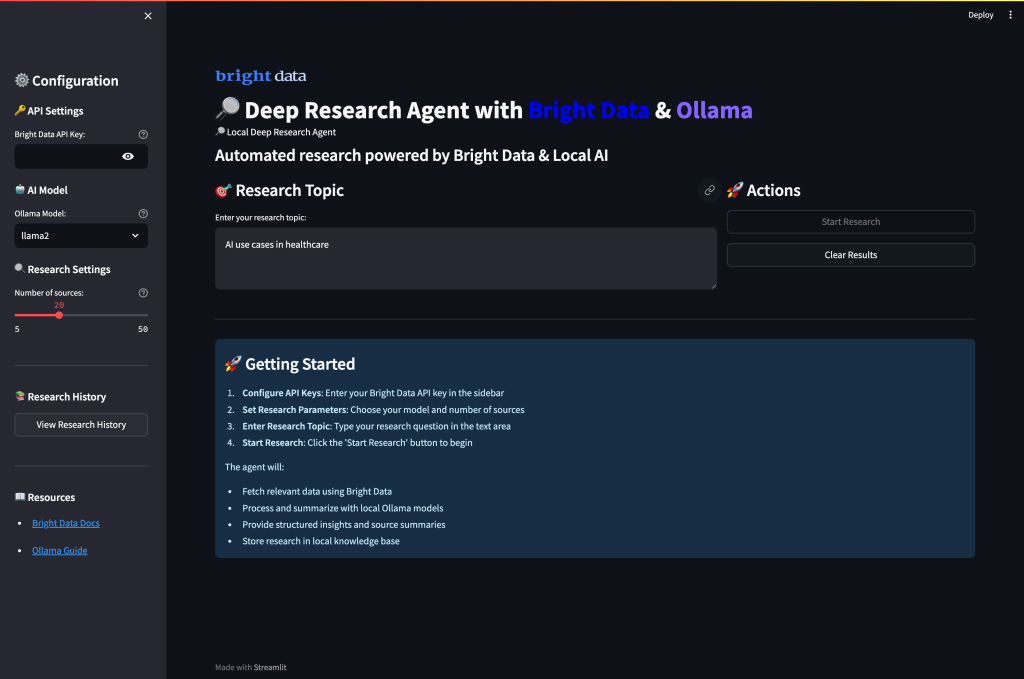
Executando seu agente de pesquisa profunda
Execute o aplicativo para começar a realizar pesquisas abrangentes com análises baseadas em IA. Abra seu terminal e navegue até o diretório do projeto.
streamlit run app.pyVocê verá o fluxo de trabalho inteligente de vários agentes do sistema à medida que ele processa suas solicitações de pesquisa:
- Fase de coleta de dados: O agente obtém dados de pesquisa abrangentes de diversas fontes da Web usando as APIs confiáveis da Bright Data, filtrando automaticamente a relevância e a credibilidade.
- Processamento de conteúdo: Cada fonte passa por uma análise inteligente, na qual o sistema extrai as principais informações, identifica os principais temas e avalia a qualidade do conteúdo usando a compreensão semântica.
- Sumarização por IA: Os modelos locais da Ollama processam os dados coletados, gerando resumos concisos, preservando insights críticos e mantendo a precisão contextual em todas as fontes.
- Síntese de conhecimento: O sistema identifica padrões recorrentes, conecta conceitos relacionados e detecta tendências emergentes por meio da análise simultânea de informações de várias fontes.
- Relatórios estruturados: Por fim, o agente compila todas as descobertas em um relatório de pesquisa abrangente com organização adequada, citações claras e formatação profissional que destaca as principais descobertas e percepções.
Pipeline de pesquisa aprimorado
Para obter recursos de pesquisa mais avançados, amplie a implementação.
Esse pipeline aprimorado cria um fluxo de trabalho de pesquisa completo que vai além do simples resumo para fornecer análise estruturada, insights importantes e descobertas acionáveis dos dados de pesquisa coletados. O pipeline integra o Bright Data para coleta de informações e modelos locais da Ollama para análise inteligente.
# advanced_research.py
def comprehensive_research_pipeline(query, api_key, model="llama2"):
"""Pipeline de pesquisa completo com coleta de dados e análise de IA"""
# Etapa 1: buscar dados da Bright Data
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": consulta, "limit": 20}
headers = {"Authorization": f "Bearer {api_key}"}
response = requests.post(url, json=payload, headers=headers)
se response.status_code != 200:
return {"error": "Falha na coleta de dados"}
research_data = response.json()
# Etapa 2: Processar e analisar com o Ollama
insights = []
for item in research_data.get('results', []):
content = item.get('content', '')
# Gerar percepções para cada fonte
analysis_prompt = f"""
Analisar esse conteúdo e fornecer insights importantes:
{content[:2000]}
Concentre-se em:
- Principais pontos e descobertas
- Dados e estatísticas importantes
- Aplicações potenciais
- Limitações mencionadas
"""
try:
result = subprocess.run(
['ollama', 'run', model, analysis_prompt],
capture_output=True,
text=True,
timeout=90
)
insights.append({
'source': item.get('source', ''),
'analysis': result.stdout.strip(),
'title': item.get('title', '')
})
exceto Exception as e:
insights.append({
'source': item.get('source', ''),
'analysis': f "Analysis failed: {str(e)}",
'title': item.get('title', '')
})
return {
'research_data': research_data,
'ai_insights': insights,
'query': consulta
}Conclusão
Este Local Deep Research Agent demonstra como criar um sistema de pesquisa automatizado que combina a coleta confiável de dados da Web da Bright Data com o processamento local de IA usando o Ollama. A implementação fornece:
- Abordagem de privacidade em primeiro lugar: Todo o processamento de IA acontece localmente com o Ollama
- Coleta de dados confiável: A Bright Data garante dados da Web estruturados e de alta qualidade
- Interface amigável ao usuário: A interface de usuário Streamlit torna a pesquisa complexa acessível
- Fluxo de trabalho personalizável: Adaptável a vários domínios e requisitos de pesquisa
O sistema aborda os principais desafios do setor, automatizando a coleta, o processamento e a análise de dados, transformando horas de pesquisa manual em minutos de geração automatizada de insights.
Para aprimorar ainda mais seus recursos de pesquisa, explore as soluções de Conjuntos de Dados da Bright Data para dados específicos do setor e considere o uso do Deep Lookup para consultar e pesquisar o maior banco de dados da Web do mundo.
Pronto para criar seu próprio agente de pesquisa? Crie uma conta gratuita na Bright Data para iniciar a coleta confiável de dados da Web e começar a transformar seus fluxos de trabalho de pesquisa hoje mesmo.






