







 Bypass Location Restrictions
Bypass Location Restrictions
To scrape data, you’ll need to ensure that your scrapers are not blocked by your target website due to your location. Proxies allow you to bypass location restrictions, but the quality of proxies varies across providers, and you’ll get what you pay for. Scraping smoothly requires proxies with comprehensive global coverage and IPs that are verified as legitimate. Otherwise, you’ll keep getting blocked and waste time. Automate Website Unlocking Management
Automate Website Unlocking Management
Another dimension to web scraping that you’ll need to keep in mind is unblocking management and adjusting to site changes. Websites are increasingly able to use bot-detection software and sophisticated blocking mechanisms. To complete a scraping project well, you must account for bypassing CAPTCHA, rotating proxies, browser fingerprinting, and selecting headers, cookies, and Javascript rendering. Automate Website Unlocking Management
Automate Website Unlocking ManagementInteract with Websites
Many data scraping projects will require you to interact with websites to retrieve your data (hovering, navigating pages, etc.), or may require JavaScript rendering. These scraping projects will therefore require that you use a browser for these interactions. When scaling your data collection, you’ll need an extensive infrastructure to host many browsers.
Build Scrapers
The last dimension of web scraping involves building the scraper itself, which will define, collect, parse, and deliver your data. A scraper will clean your data and deliver it in a structured format and can then be exported in the format of your choice (JSON, CSV, Excel).
 Proxy Networks
Proxy Networks
- Bypasses location restrictions
 In-house infrastructure
In-house infrastructure- Unlocking management
- Scraper
- Browser (if necessary)
Web Unlocker
- Bypasses location restrictions
- Automates unlocking management
- In-house infrastructure
- Scrapers
- Doesn’t work with browsers
Scraping Browser
- Bypass location restrictions
- Automate unlocking management
- Interact with websites
- Scrapers
Web Scraper IDE
- Bypasses location restrictions
- Automates unlocking management
- Interact with websites
- Build scrapers





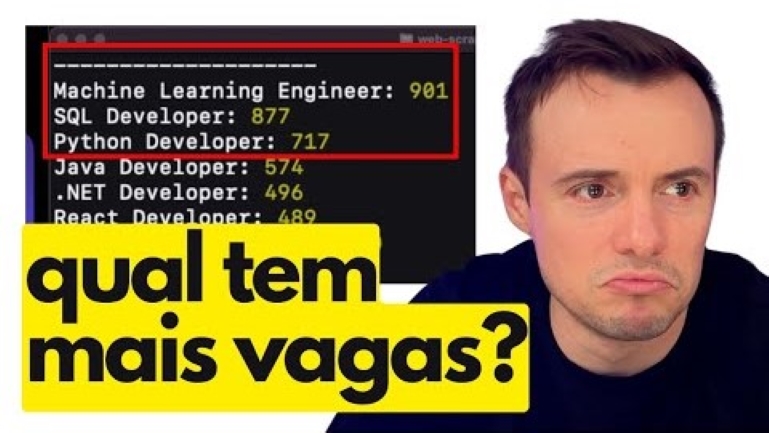




























































Proxy Networks
4 types of proxies to bypass location restrictions, including 72 million+ residential IPs Learn more ›

Web Unlocker
API to handle all ongoing site unlocking management for you, and extract one URL Learn more ›

SERP API
API to handle all ongoing unlocking management for SERP and extracts one page Learn more ›

Scraping Browser
Puppeteer & Playwright-compatible browser with built-in unlocking activities Learn more ›

Web Scraper IDE
IDE to build scrapers on Bright Data infrastructure, with built-in unlocking & browsers Learn more ›















