

TL;DR: Este tutorial vai ensinar-lhe como extrair dados de um sítio em Ruby e porque é que é uma das linguagens mais eficazes para raspagem.
Este guia abordará:
- O Ruby é bom para a raspagem da web?
- As melhores gemas de Ruby para raspagem da web
- Construir um raspador da web em Ruby
O Ruby é bom para a raspagem da web?
Ruby é uma linguagem de programação interpretada, de código aberto e de tipagem dinâmica que suporta o desenvolvimento funcional, orientado a objetos e processual. Foi concebido para ser simples, com uma sintaxe elegante que é fácil de escrever e natural de ler. O seu foco na produtividade tornou-o uma escolha popular em várias aplicações, incluindo a raspagem da web.
Em particular, o Ruby é uma excelente escolha para a raspagem devido à vasta gama de bibliotecas de terceiros disponíveis. São as chamadas “gemas” e há uma para quase todas as tarefas. Quando se trata de recuperar informações da web de forma programática, existem gemas para descarregar páginas, analisar o seu conteúdo HTML e extrair dados das mesmas.
Em resumo, a raspagem da web em Ruby não é apenas possível, mas também fácil graças às muitas bibliotecas disponíveis. Vamos descobrir quais são as mais populares!
As melhores gemas de Ruby para raspagem da web
Aqui estão as três melhores bibliotecas de raspagem da web para Ruby:
- Nokogiri(鋸): Uma biblioteca robusta e flexível de análise de HTML e XML com uma API completa para atravessar e manipular documentos HTML/XML, facilitando a extração de dados relevantes dos mesmos.
- Mechanize: Uma biblioteca com funcionalidade de navegador sem cabeça que fornece uma API de alto nível para automatizar a interação com sítios web. Pode armazenar e enviar cookies, lidar com redireccionamentos, seguir links e enviar formulários. Além disso, fornece um histórico para manter o registo dos sítios visitados.
- Selenium: Uma ligação de Ruby da estrutura mais popular para executar testes automatizados em páginas web. Pode dar instruções a um navegador para interagir com um sítio web como faria um usuário humano. Esta tecnologia desempenha um papel fundamental para contornar as soluções antibot e os sítios de raspagem que dependem do JavaScript para renderizar ou recuperar dados.
Pré-requisitos
Antes de escrever algum código, é necessário instalar o Ruby no seu computador. Siga o guia abaixo relacionado com o seu sistema operativo.
Instalar o Ruby no macOS
Por padrão, o Ruby está incluído no macOS desde a versão 10.11 (El Capitan), lançada em 2015. Considerando que o macOS depende nativamente do Ruby para fornecer algumas funcionalidades, você não deve tocá-lo. A atualização da versão nativa do Ruby com brew install ruby ou update ruby mac não é recomendada, pois pode quebrar algumas funcionalidades incorporadas.
Instalar o Ruby no Windows
Descarregue o pacote RubyInstaller, inicie-o e siga o assistente de instalação para configurar o Ruby. Poderá ser necessário reiniciar o sistema. A partir do Windows 10, também pode utilizar o Subsistema Windows para Linux para instalar o Ruby, seguindo as instruções abaixo.
Instalar o Ruby no Linux
A melhor maneira de configurar um ambiente Ruby no Linux é instalá-lo através de um gestor de pacotes.
Em Debian e Ubuntu, iniciar:
sudo apt-get install ruby-fullNoutras distribuições, o comando de terminal a executar é diferente. Consulte o guia no sítio oficial para ver todos os sistemas de gestão de pacotes suportados.
Independentemente do seu sistema operativo, pode agora verificar se o Ruby está a funcionar com:
ruby -vIsso deve imprimir algo como:
ruby 3.2.2 (2023-03-30 revision e51014f9c0)Ótimo! Está agora pronto para começar a raspar a web com Ruby!
Construir um raspador da web em Ruby
Nesta secção, verá como criar um raspador da web com Ruby. Este script automatizado recupera dados da página inicial da Bright Data. Em detalhe, irá:
- Ligar ao sítio de destino
- Selecionar os elementos HTML de interesse no DOM
- Extrair dados dos mesmos
- Converter os dados extraídos em formatos fáceis de explorar, como CSV e JSON
No momento em que escrevem, isso é o que os usuários veem quando visitam a página web de destino:
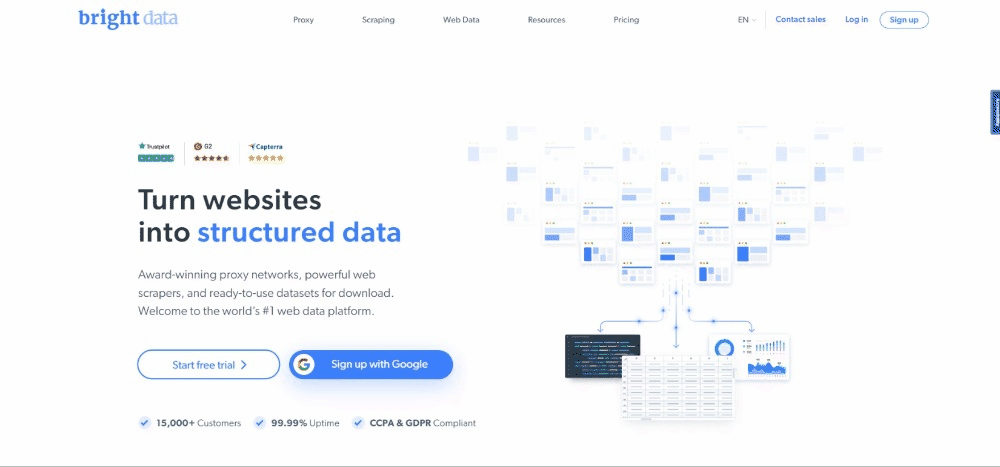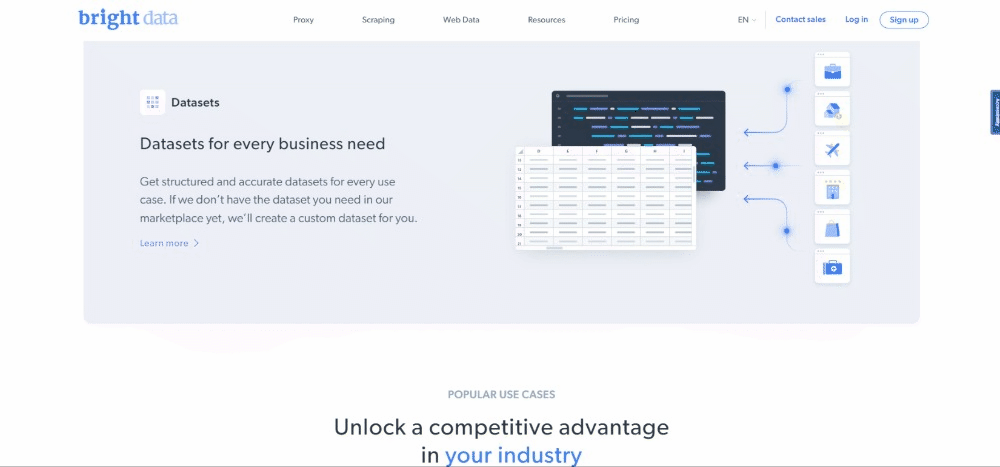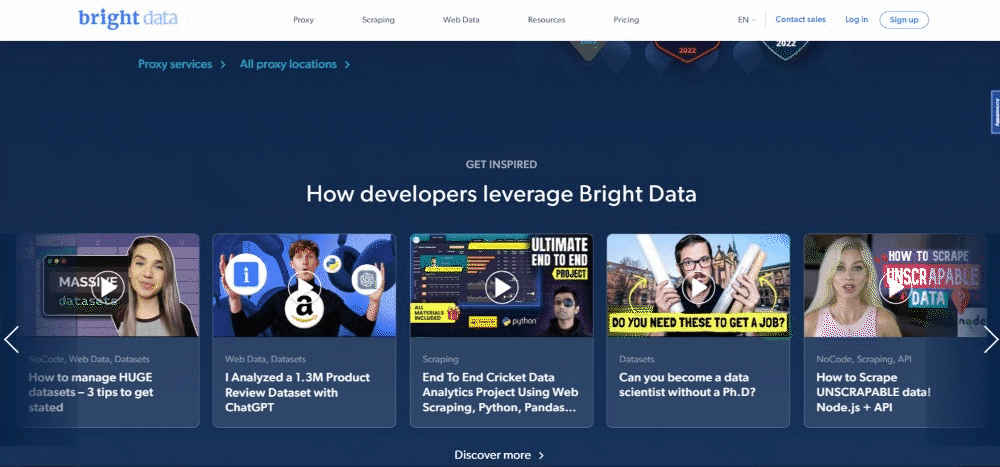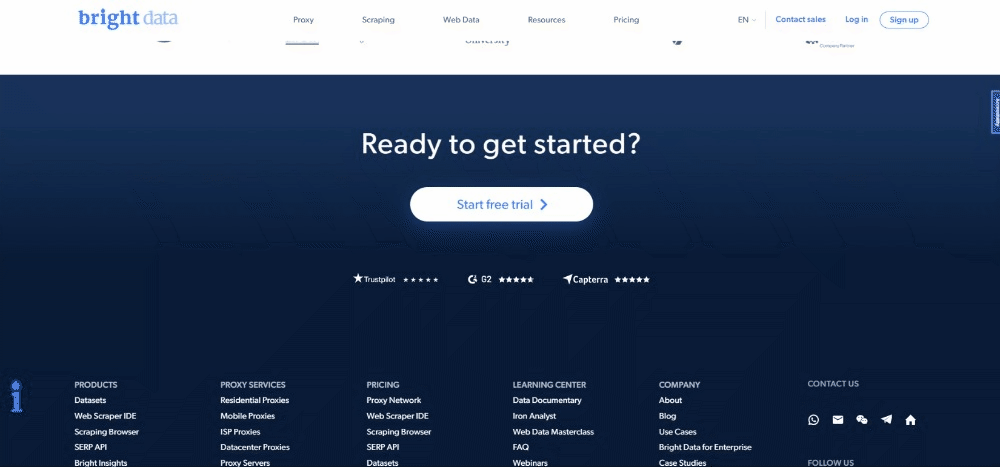
Tenha em conta que a página inicial da BrightData muda frequentemente e poderá não ser a mesma quando você ler este artigo.
O objetivo específico da raspagem é obter a informação do caso de utilização contida nos seguintes cartões:
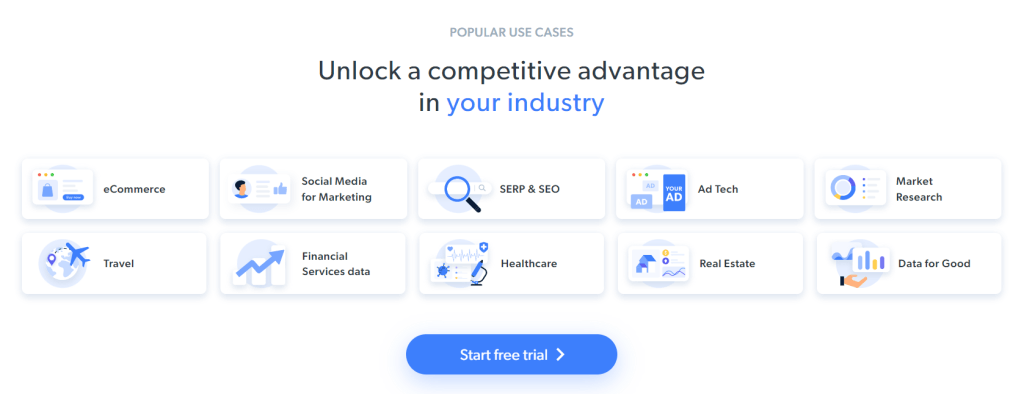
Siga o tutorial passo-a-passo abaixo e aprenda a fazer raspagem da web com Ruby!
Passo 1: Inicializar um projeto em Ruby
Antes de começar, é necessário configurar o seu projeto em Ruby. Inicie o terminal, crie a pasta do projeto e insira-a com:
mkdir ruby-web-scraper
cd ruby-web-scraperO diretório ruby-web-scraper conterá seu raspador.
Em seguida, inicialize um arquivo scraper.rb dentro da pasta do projeto com o seguinte conteúdo:
puts "Hello, World!"O trecho acima é o script de Ruby mais fácil possível.
Verifique se funciona, executando-o no seu terminal:
ruby scraper.rbIsto deve imprimir esta mensagem:
Hello, World!Está na altura de importar o seu projeto para o seu IDE e começar a definir alguma lógica avançada de raspagem com Ruby! Neste guia, verá como configurar o Visual Studio Code (VS Code) para desenvolvimento em Ruby. Ao mesmo tempo, qualquer outro IDE de Ruby serve.
Uma vez que o VS Code não suporta o Ruby nativamente, primeiro tem de adicionar a extensão de Ruby. Inicie o Visual Studio Code, clique no ícone “Extensões” na barra esquerda e escreva “Ruby” na entrada de pesquisa na parte superior.
Clique no botão “Instalar” no primeiro elemento para adicionar recursos de realce de Ruby ao VS Code. Aguarde até que o plug-in seja adicionado ao IDE. Em seguida, abra a pasta ruby-web-scraper com “Ficheiro“, “Abrir pasta…”
Clique no ficheiro scraper.rb na barra “EXPLORER” para começar a editar o ficheiro:
Passo 2: Escolher a biblioteca de raspagem
Construir um raspador da web em Ruby torna-se mais fácil com a biblioteca certa. Por este motivo, deve adotar uma das gemas apresentadas anteriormente. Para descobrir qual a biblioteca Ruby de raspagem da web que melhor se adequa aos seus objetivos, tem de passar algum tempo a analisar o seu sítio alvo.
Por esse motivo, visite a página de destino em seu navegador, clique com o botão direito do rato em um local em branco no fundo e clique na opção “Inspecionar“. Isto irá abrir as ferramentas de desenvolvimento do seu navegador. No Chrome, aceda ao separador “Rede” e explore a seção “Fetch/XHR“.
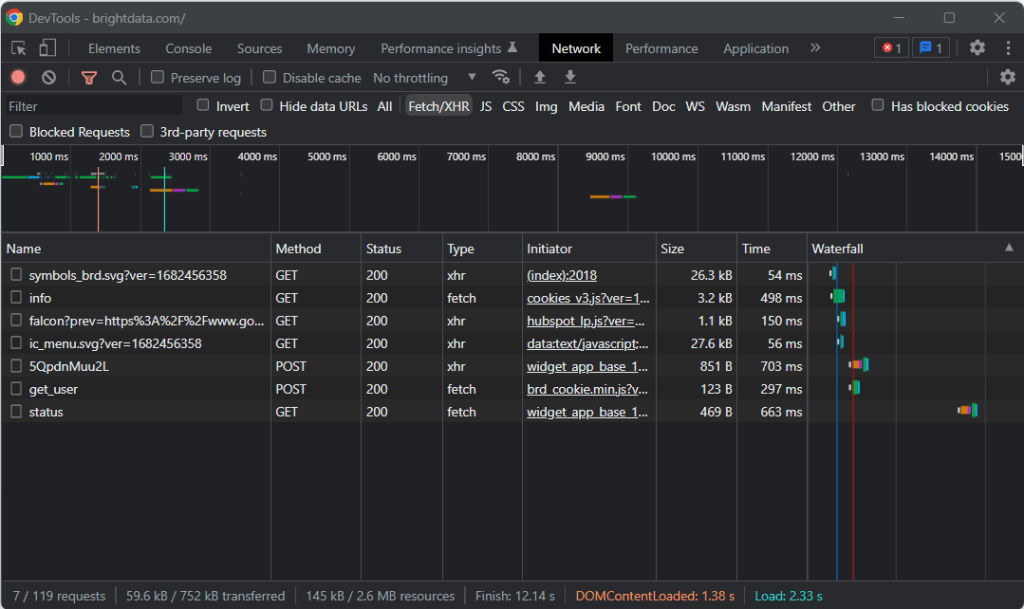
Como você pode observar na captura de tela acima, há apenas sete pedidos AJAX. Se analisar cada chamada XHR, verificará que não envolve dados significativos. Isso significa que a página de destino não recupera conteúdo no momento da renderização. Assim, o documento HTML devolvido pelo servidor já contém todos os dados a mostrar aos usuários.
Isso prova que a página web de destino não usa JavaScript para fins de recuperação ou renderização de dados. Em outras palavras, você não precisa de uma gema com recursos de navegador sem cabeça para executar a raspagem da web. Você ainda pode usar Mecanize ou Selenium, mas eles só adicionariam algumas despesas gerais de desempenho. Afinal, executam uma instância do navegador nos bastidores, o que consome recursos.
Em resumo, deve optar por um analisador HTML/XML simples como o Nokogiri. Instale-o através da gema nokogiri com:
gem install nokogiriPode então importar a biblioteca adicionando a seguinte linha no topo do seu ficheiro scraper.rb:
require "nokogiri"Certifique-se de que o seu IDE de Ruby não reporte erros, e pode agora raspar alguns dados em Ruby!
Passo 3: Utilizar o HTTParty para obter a página de destino
Para analisar o documento HTML da página de destino, primeiro é necessário descarregá-lo através de um pedido HTTP GET. O Ruby vem com um cliente HTTP incorporado chamado Net::HTTP, mas a sua sintaxe é um pouco complicada e não intuitiva. Em vez disso, deve utilizar HTTParty, que é a biblioteca Ruby mais popular para efetuar pedidos HTTP.
Instale-o através da gema httparty com:
gem install httparty
Then, import it in the scraper.rb file:
require "httparty"
Use HTTParty to connect to the target page with:
response = HTTParty.get("https://brightdata.com/")O método get() permite-lhe efetuar um pedido GET ao URL passado como parâmetro. O campo response.body conterá o documento HTML devolvido pelo servidor.
Note-se que o pedido HTTP efetuado através de get() pode falhar. Quando isso acontece, o HTTParty levanta uma exceção e detém a execução do seu script com um erro. Podem existir inúmeras razões por detrás de uma falha, mas o que normalmente acontece é que uma tecnologia antibot adotada pelo sítio alvo intercetou e bloqueou os seus pedidos automáticos. Os sistemas antirraspagem mais básicos tendem a filtrar os pedidos sem um cabeçalho HTTP de Usuário-Agente válido. Consulte o nosso artigo para saber mais sobre Usuários-Agentes para a raspagem da Web.
Como qualquer outro cliente HTTP, o HTTParty utiliza um Usuário-Agente de reserva. Este é geralmente muito diferente dos agentes utilizados pelos navegadores populares, tornando os seus pedidos facilmente detetáveis por soluções antibot. Para evitar ser bloqueado por causa disso, pode especificar um Usuário-Agente válido no HTTParty da seguinte forma:
response = HTTParty.get("https://brightdata.com/", {
headers: { "User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"},
})O pedido efetuado através desse get() aparecerá agora ao servidor como vindo do Google Chrome 112.
Isto é o que o scraper.rb contém atualmente:
require "nokogiri"
require "httparty"
# get the target page
response = HTTParty.get("https://brightdata.com/", {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
},
})
# scraping logic...
Passo 4: Analisar o documento HTML com o Nokogiri
Para analisar o documento HTML associado à página web de destino, passe o seu conteúdo à função de HTML() Nokogiri:
doc = Nokogiri::HTML(response.body)Pode agora utilizar a API de manipulação e exploração do DOM oferecida através da variável doc. Especificamente, os dois métodos mais importantes para selecionar elementos HTML são:
- xpath(): Retorna a lista de nós HTML que correspondem à consulta XPath
- css(): Devolve a lista de nós HTML que correspondem ao seletor de CSS passado como parâmetro
Ambas as abordagens funcionam, mas as consultas CSS são normalmente a forma mais fácil de expressar o que se procura.
Passo 5: Definir os seletores de CSS para os elementos HTML de interesse
Para compreender como selecionar os elementos HTML desejados na página de destino, é necessário analisar o DOM. Visite a página inicial da Bright Data no seu navegador, clique com o botão direito do rato num dos cartões de interesse e selecione “Inspecionar“:
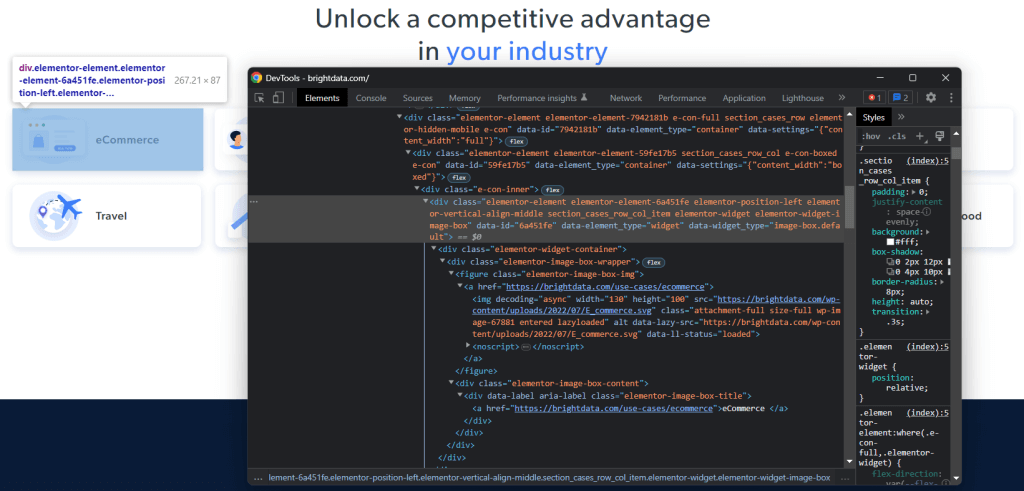
Reserve algum tempo para explorar o código HTML na seção DevTools. Cada cartão de caso de utilização é um
- Um <figure> com um elemento HTML <img> que mostra a imagem associada ao sector e um elemento <a> que contém o URL da página do sector.
- Um elemento HTML <div> que armazena o nome do sector numa etiqueta <a>.
O objetivo da extração de dados do raspador de Ruby é obter o URL da imagem, o URL da página e o nome do sector de cada cartão.
Para definir bons seletores de CSS, preste atenção às classes de CSS atribuídas aos nós DOM de interesse. Verificará que pode obter todos os cartões de casos de utilização com o seletor de CSS a seguir:
.section_cases_row_col_itemDado um cartão, é possível selecionar os nós que armazenam os dados relevantes dos seus filhos <figure> e <div> com:
- figure img
- figure a
- .elementor-image-box-content a
Passo 6: Raspar dados de uma página web com Nokogiri
Agora é necessário utilizar o Nokogiri para obter os dados desejados da página HTML de destino.
Antes de mergulhar na lógica de raspagem de dados, não se esqueça de que você precisa de algumas estruturas de dados onde armazenar os dados coletados. Para o efeito, é possível definir uma classe UseCase numa única linha com um Struct:
UseCase = Struct.new(:image, :url, :name)Em Ruby, um Struct permite-lhe agrupar um ou mais atributos na mesma classe de dados. A estrutura acima tem os três atributos correspondentes às informações a obter de cada cartão de caso de utilização.
Inicialize uma matriz vazia de UseCase e implemente a lógica de raspagem de dados para a preencher:
# initialize the list of objects
# that will store all retrieved data
use_cases = []
# select all use case HTML elements
use_case_cards = doc.css(".section_cases_row_col_item")
# iterate over the HTML cards
use_case_cards.each do |use_case_card|
# extract the data of interest
image = use_case_card.at_css("figure img").attribute("data-lazy-src").value
url = use_case_card.at_css("figure a").attribute("href").value
name = use_case_card.at_css(".elementor-image-box-content a").text
# instantiate an UseCase object with the
# collected data
use_case = UseCase.new(url, image, name)
# add the UseCase instance to the array
# of scraped objects
use_cases.push(use_case)
endO trecho acima seleciona todos os cartões de caso de uso e itera sobre eles. Em seguida, raspa de cada cartão o URL da imagem, o URL da página do setor e o nome com at_css(). Esta é uma função de Nokogiri que devolve o primeiro elemento que corresponde à consulta CSS e representa um atalho para:
image = use_case_card.css("figure img").first.attribute("data-lazy-src").valueFinalmente, usa os dados recuperados para instanciar um novo objeto UseCase e adicioná-lo à lista.
O raspagem da web utilizando Ruby com Nokogiri é bastante simples. Com attribute(), pode selecionar um atributo do elemento HTML atual. Em seguida, o campo de valor permite-lhe obter o seu valor. Da mesma forma, o campo de texto devolve diretamente todo o texto contido no nó HTML atual como uma cadeia simples.
Agora, você pode ir além e raspar também as páginas do setor de casos de uso. Você pode seguir os links descobertos aqui e implementar uma nova lógica de raspagem adaptada aos mesmos. Bem-vindo ao mundo do rastejamento da web e da raspagem da web!
Fantástico! Acabou de aprender como atingir os seus objetivos de raspagem com Ruby. No entanto, ainda há algumas lições a aprender.
Passo 7: Exportar os dados raspados
Após o each() loop, use_cases conterá os dados raspados em objetos de Ruby. Este não é o melhor formato para fornecer dados a outras equipas. Felizmente, o Ruby tem capacidades incorporadas de conversão para CSV e JSON. Saiba como exportar os dados recuperados para CSV e JSON.
Para exportar CSV, importe a seguinte gema:
import "csv"Faz parte da API estândar de Ruby e fornece uma interface completa para lidar com ficheiros e dados CSV.
Você pode aproveitá-la para exportar a matriz use_cases para um ficheiro .csv de saída, como se segue:
# populate the CSV output file
CSV.open("output.csv", "wb") do |csv|
# write the CSV header
csv << ["url", "image", "name"]
# transfrom each use case scraped info to a
# CSV record
use_cases.each do |use_case|
csv << use_case
end
endO trecho acima cria o ficheiro .csv de saída. Em seguida, o abre e o inicializa com o registo de cabeçalho. Depois, itera sobre a matriz use_cases e anexa-a ao ficheiro CSV. Ao utilizar o operador <<, o Ruby converte automaticamente cada instância de use_case numa matriz de cadeias de caracteres, conforme exigido pela classe CSV incorporada.
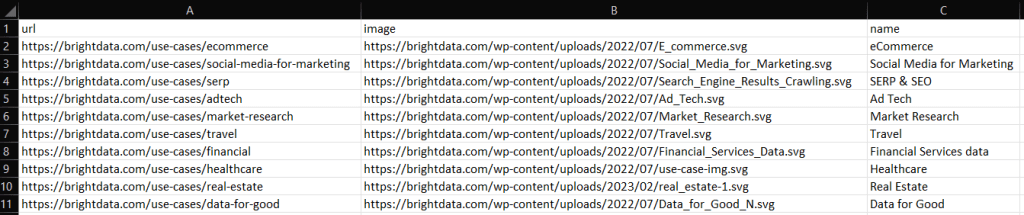
Tente executar o script com:
ruby scraper.rbUm ficheiro output.csv contendo os dados abaixo será produzido no diretório raiz do seu projeto:
Da mesma forma, pode exportar use_cases para output.json:
# propulate the JSON output file
File.open("output.json", "wb") do |json|
json << JSON.pretty_generate(use_cases.map { |u| Hash[u.each_pair.to_a] })
endIsto irá gerar o seguinte ficheiro JSON:
[
{
"image": "https://brightdata.com/use-cases/ecommerce",
"url": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"name": "eCommerce "
},
// ...
{
"image": "https://brightdata.com/use-cases/data-for-good",
"url": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"name": "Data for Good"
}
]Et voilà! Agora você já sabe como converter uma matriz de structs para CSV e JSON em Ruby!
Passo 8: Juntar tudo
Aqui está o código completo do raspador de Ruby:
# scraper.rb
require "nokogiri"
require "httparty"
require "csv"
# get the target page
response = HTTParty.get("https://brightdata.com/", {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
},
})
# parse the HTML document retrieved with the GET request
doc = Nokogiri::HTML(response.body)
# define a class where to keep the scraped data
UseCase = Struct.new(:image, :url, :name)
# initialize the list of objects
# that will store all retrieved data
use_cases = []
# select all use case HTML elements
use_case_cards = doc.css(".section_cases_row_col_item")
# iterate over the HTML cards
use_case_cards.each do |use_case_card|
# extract the data of interest
image = use_case_card.at_css("figure img").attribute("data-lazy-src").value
url = use_case_card.at_css("figure a").attribute("href").value
name = use_case_card.at_css(".elementor-image-box-content a").text
# instantiate an UseCase object with the
# collected data
use_case = UseCase.new(url, image, name)
# add the UseCase instance to the array
# of scraped objects
use_cases.push(use_case)
end
# populate the CSV output file
CSV.open("output.csv", "wb") do |csv|
# write the CSV header
csv << ["url", "image", "name"]
# transfrom each use case scraped info to a
# CSV record
use_cases.each do |use_case|
csv << use_case
end
end
# propulate the JSON output file
File.open("output.json", "wb") do |json|
json << JSON.pretty_generate(use_cases.map { |u| Hash[u.each_pair.to_a] })
endEm cerca de 50 linhas de código, é possível criar um script de raspagem em Ruby!
Conclusão
Neste tutorial, você entendeu porque o Ruby é uma ótima linguagem para raspar a Internet. Também teve a oportunidade de ver quais são as melhores bibliotecas de gemas de Ruby para raspagem da web, porquê e que funcionalidades oferecem. Em seguida, mergulhou em como usar o Nokogiri e a API padrão de Ruby para construir um raspador de Ruby que pode raspar um alvo do mundo real. Como você viu, a raspagem de dados com Ruby requer poucas linhas de código.
No entanto, não subestime os desafios existentes quando se trata de extrair dados de páginas web. É por esta razão que um número crescente de sítios tem vindo a implementar sistemas antibot e antirraspagem para proteger os seus dados. Estas tecnologias são capazes de detetar os pedidos efetuados pelo seu script de Ruby de raspagem e impedir o acesso ao sítio. Felizmente, é possível criar um raspador da web que pode contornar esses bloqueios com o IDE para Raspador da Web de última geração da Bright Data.
Não quer lidar com a raspagem da web, mas está interessado em dados da web? Explore os nossos conjuntos de dados prontos a utilizar.






