

Neste artigo, discutiremos:
- Raspagem de dados na Web com JavaScript de front-end
- Pré-requisitos
- Bibliotecas de raspagem de dados na Web para Node.js
- Conclusão
Raspagem de dados na Web com JavaScript de front-end
Quando o objetivo é a raspagem de dados na web, o JavaScript de front-end é uma solução limitada. Primeiro, porque você precisaria executar seu script de raspagem de dados na web em JavaScript diretamente do console do navegador. Essa não é uma operação cuja realização você possa programar.
Especificamente, é possível extrair dados de uma página pelo console da seguinte forma:

Segundo, se você quiser extrair dados de outras páginas da web, precisaria baixá-las via AJAX. Mas não se esqueça de que os navegadores da Web aplicam uma Política de Mesma Origem ao AJAX. Portanto, com o JavaScript de front-end, você só pode acessar páginas da web que tenham a mesma origem.
Vamos entender o que isso significa com um exemplo simples. Vamos supor que você esteja visitando uma página da brightdata.com. Então, seu script de raspagem de dados em JavaScript de front-end só poderia baixar páginas web sob o domínio brightdata.com.
Observe que isso não significa, de forma alguma, que o JavaScript não seja uma “boa tecnologia” para rastreamento na web. Na verdade, o Node.js permite que você execute JavaScript em servidores e evite as duas limitações apresentadas acima.
Agora vamos entender como você pode criar um raspador de dados na web em JavaScript com o Node.js.
Pré-requisitos
Antes de começar a trabalhar no aplicativo de raspagem de dados na web Node.js, você precisa atender à seguinte lista de pré-requisitos:
- Node.js 18+ com npm 8+: Qualquer versão LTS (Long Term Support – Suporte de longo prazo) do Node.js 18+, incluindo npm, servirá. Este tutorial é baseado no Node.js 18.12 com npm 8.19, que representa a versão LTS mais recente do Node.js no momento em que este artigo foi escrito.
- Um IDE com suporte a JavaScript: A Community Edition of IntelliJ IDEA é o IDE escolhido para este tutorial, mas qualquer outro IDE compatível com JavaScript e Node.js servirá.
Clique nos links acima e siga os assistentes de instalação para configurar tudo o que você precisa. Para verificar se o Node.js foi instalado corretamente, inicie o comando abaixo em seu terminal:
node -vEle deve retornar algo parecido com:
v18.12.1Da mesma forma, verifique se o npm foi instalado corretamente com
npm -v Isso deve retornar uma string parecida com:
8.19.2Os dois comandos acima indicam a versão do Node.js e do npm globalmente disponíveis em sua máquina, respectivamente.
Fantástico! Agora você está pronto para ver como realizar a raspagem de dados na web em JavaScript no Node.js!
Melhores bibliotecas para raspagem de dados na Web em JavaScript para Node.js
Vamos explorar as melhores bibliotecas para raspagem de dados na web em JavaScript no Node.js:
- Axios: uma biblioteca fácil de usar que ajuda você a fazer solicitações HTTP em JavaScript. Você pode usar a Axios no navegador e no Node.js, e ela representa um dos mais populares clientes HTTP em JavaScript disponíveis.
- Cheerio: Uma biblioteca leve que fornece API semelhante a jQuery para explorar documentos em HTML e XML. Você pode usar a Cheerio para analisar um documento HTML, selecionar elementos HTML e extrair dados deles. Em outras palavras, a Cheerio oferece uma API avançada de raspagem de dados na web.
- Selenium: uma biblioteca que oferece suporte a várias linguagens de programação que você pode usar para criar testes automatizados para aplicativos da web. Ela também pode ser usada por seus recursos de navegador sem interface gráfica para fins de raspagem de dados na web.
- Playwright: uma ferramenta para criar scripts de teste automatizados para aplicativos web desenvolvida pela Microsoft. Ela oferece uma forma de instruir o navegador a realizar ações específicas. Portanto, você pode usar a Playwright para raspagem de dados na web como uma solução de navegador sem interface gráfica.
- Puppeteer: uma ferramenta para automatizar testes de aplicativos web desenvolvida pela Google. A Puppeteer foi desenvolvida com base no protocolo Chrome DevTools. Assim como a Selenium e a Playwright, ela permite que você interaja programaticamente com o navegador como um usuário humano faria. Saiba mais sobre as diferenças entre a Selenium e a Puppeteer.
Como construir um raspador de dados na web em JavaScript no Node.js
Aqui, você aprenderá como criar um raspador de dados na web em JavaScript no Node.js capaz de extrair dados automaticamente de um site. Em detalhes, a página da web visada será a página inicial da Bright Data. O objetivo do processo de raspagem de dados na web do Node.js será selecionar os elementos HTML de interesse da página, recuperar dados deles e converter os dados extraídos para um formato mais útil.
No momento em que este artigo foi escrito, esta é a aparência da página inicial da Bright Data:

Como você pode observar, a página inicial da Bright Data contém muitos dados e informações em diferentes formatos, desde descrições em texto até imagens. Além disso, ela envolve muitos links úteis. Você aprenderá como recuperar todos esses dados.
Agora vamos dar uma olhada em como raspar dados com o Node.js em um tutorial passo a passo!
Etapa 1: Configuração de um projeto de Node.js
Primeiro, crie a pasta que conterá seu projeto Node.js de raspagem de dados na web com:
mkdir web-scraper-nodejsAgora é necessário ter um diretório web-scraper--nodejs vazio. Observe que você pode dar o nome que quiser à pasta do projeto. Entre na pasta com:
cd web-scraper-nodejsAgora, inicialize um projeto npm com:
npm init -yEste comando configurará um novo projeto npm para você. Observe que o sinalizador -y é necessário para fazer com que o npm inicialize um projeto padrão sem passar por um processo interativo. Se o sinalizador -y for omitido, você terá que responder a algumas perguntas no terminal.
O web-scraper-nodejs agora deve conter um package.json que se parece com o seguinte:
{
"name": "web-scraper-nodejs",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo "Error: no test specified" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}Agora, crie um arquivo index.js na pasta raiz do seu projeto e inicialize-o conforme abaixo:
// index.js
console.log("Hello, World!")Esse arquivo JavaScript conterá a lógica de raspagem de dados da web do Node.js.
Abra seu arquivo package.json e adicione o seguinte script na seção scripts:
"start": "node index.js"Agora você pode executar o comando abaixo em seu terminal para iniciar seu script Node.js:
npm run startDeve ser retornado o seguinte:
Hello, World!Isso significa que seu aplicativo Node.js está funcionando corretamente. Agora, abra o projeto em seu IDE e prepare-se para escrever alguma lógica de raspagem de dados no Node.js!
Se você for um usuário do IntelliJ IDEA, deverá ver o seguinte:

Etapa 2: Instalar a Axios e a Cheerio
É hora de instalar as dependências necessárias para implementar o raspador de dados na web no Node.js. Para descobrir quais bibliotecas de raspagem de dados na web em JavaScript você deve adotar, visite a página web visada, clique com o botão direito do mouse em uma seção em branco e selecione a opção “Inspecionar”. Isso deve abrir a janela DevTools do seu navegador. Na guia de Rede, dê uma olhada na seção Fetch/XHR.

Acima, você pode ver as solicitações AJAX realizadas pela sua página da web visada. Se você abrir as três solicitações XHR executadas pelo site, verá que elas não retornam dados interessantes. Em outras palavras, os dados desejados estão incorporados diretamente no código-fonte da página da web. Isso é o que geralmente acontece com sites renderizados do lado do servidor.
A página da web visada não depende de JavaScript para recuperar dados ou para fins de renderização. Portanto, você não precisa de uma ferramenta capaz de executar JavaScript no navegador. Em outras palavras, você não precisa usar uma biblioteca de navegador sem interface gráfica para extrair dados da página da web visada. Você até pode usar essa biblioteca, mas não ela é necessária.
Como bibliotecas que fornecem recursos de navegador sem interface gráfica abrem páginas da Web em um navegador, isso gera uma sobrecarga. Isso ocorre porque navegadores são aplicativos pesados. Essa sobrecarga pode ser facilmente evitada se você optar pela Cheerio junto com a Axios.
Portanto, instale a cheerio e a axios com:
npm install cheerio axiosEm seguida, importe a cheerio e a axios adicionando as duas linhas de código a seguir ao index.js:
// index.js
const cheerio = require("cheerio")
const axios = require("axios")Agora vamos codificar um script de raspagem de dados na web no Node.js capaz de executar raspagem de dados na web com a Cheerio e a Axios!
Etapa 3: Baixe seu site visado
Use a Axios para conectar-se ao seu site visado com as seguintes linhas de código:
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com",
})Graças ao método request() da Axios, você pode executar qualquer solicitação HTTP. Em detalhe, se você quiser baixar o código-fonte de uma página da web, precisará realizar uma solicitação HTTP GET para o URL da página. Normalmente, a Axios imediatamente retornaria uma Promise. Você pode esperar por uma Promise e obter seu valor de forma síncrona com a palavra-chave await.
Observe que se request() falhar, será gerado um Error. Isso pode acontecer por vários motivos, que vão desde um URL inválido até um servidor temporariamente indisponível. Além disso, não se esqueça de que vários implementam medidas anti-raspagem de dados. Uma das mais populares envolve o bloqueio de solicitações que não têm um cabeçalho HTTP User-Agent válido. Saiba mais sobre User-Agents para raspagem de dados na web .
Por padrão, a Axios usará o seguinte User-Agent:
axios <axios_version>Essa não é a aparência do User-Agent usado por um navegador. Portanto, as tecnologias anti-raspagem de dados da web podem detectar e bloquear seu raspador de dados na web Node.js.
Defina um cabeçalho User-Agent válido na Axios adicionando o seguinte atributo ao objeto passado para a request():
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}O atributo headers permite que você defina qualquer cabeçalho HTTP na Axios.
Seu arquivo index.js agora deve ter a seguinte aparência:
// index.js
const cheerio = require("cheerio")
const axios = require("axios")
async function performScraping() {
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
})
}
performScraping()Note que você pode usar await somente em funções marcadas com async. É por isso que você precisa incorporar sua lógica de raspagem de dados na web em JavaScript na função async performScraping().
Agora vamos passar algum tempo analisando a página visada da web para definir uma estratégia de raspagem de dados na web.
Etapa 4: inspecionar a página HTML
Se você der uma olhada na página inicial da Bright Data, verá uma lista de setores econômicos onde você pode usar a Bright Data. Esses são dados interessantes para efetuar a raspagem.
Clique com o botão direito em um desses elementos HTML e selecione “Inspecionar”:
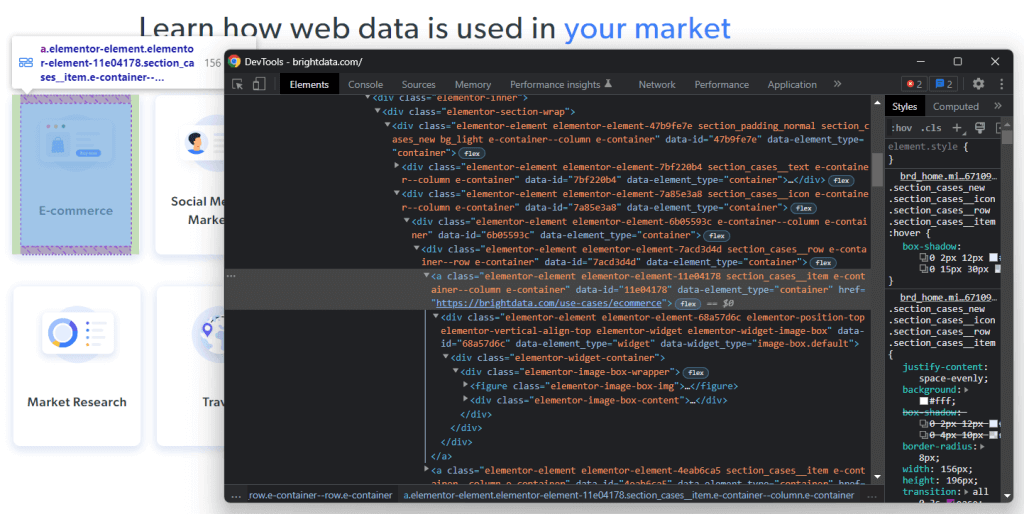
Através de análise do código HTML do nodo selecionado, você verá que o cartão é um elemento HTML <a> Especificamente, esse <a> contém:
- Um elemento HTML
<figure>contendo a imagem associada ao campo do setor econômico - Um elemento HTML
<div>contendo o nome do campo do setor econômico
Agora, observe as classes CSS que caracterizam esses elementos HTML. Ao usá-los, você poderá definir os seletores CSS necessários para selecionar esses elementos HTML do DOM. Em detalhes, observe que os cartões .e-container estão contidos no .elementor-element-7a85e3a8 <div>. Em seguida, com um cartão, você pode extrair todos os dados relevantes com os seguintes seletores CSS:
.elementor-image-box-img img.elementor-image-box-content .elementor-image-box-title
Da mesma forma, você pode aplicar a mesma lógica para definir os seletores CSS necessários para:
- Extrair os motivos pelos quais a Bright Data é líder do setor.
- Selecionar os motivos que tornam a experiência do cliente oferecida pela Bright Data a melhor do mercado.
Em outras palavras, a página da web visada tem três metas para raspagem de dados:
- Dados sobre os setores econômicos onde você pode aproveitar as vantagens do Bright Data.
- Dados sobre os motivos pelos quais a Bright Data é líder do setor.
- Dados sobre os motivos de a Bright Data oferecer a melhor experiência ao cliente no setor.
Etapa 5: Selecionar elementos HTML com a Cheerio
A Cheerio oferece várias maneiras de selecionar elementos HTML de uma página da web. Mas primeiro, é necessário inicializar a Cheerio com:
// parsing the HTML source of the target web page with Cheerio
const $ = cheerio.load(axiosResponse.data)O método load() da Cheerio aceita conteúdo HTML em formato de string. Observe que o objeto de resposta da Axios contém os dados retornados pela solicitação HTTP no atributo data. Nesse caso, data armazenará o código-fonte HTML da página da web retornada pelo servidor. Então, você passa axiosResponse.data para load() para inicializar a Cheerio.
Você deve chamar a variável Cheerio de $ porque a Cheerio compartilha basicamente a mesma sintaxe do jQuery. Dessa forma, você será capaz de copiar trechos do jQuery da Internet.
Você pode selecionar um elemento HTML com a Cheerio usando sua classe com:
const htmlElement = $(".elementClass")Da mesma forma, você pode recuperar um elemento HTML por ID com:
const htmlElement = $("#elementId")Especificamente, você pode selecionar elementos HTML ao passar qualquer seletor CSS válido para $, exatamente como faria no jQuery. Você também pode concatenar a lógica de seleção com o método find():
// retrieving the list of industry cards
const industryCards = $(".elementor-element-7a85e3a8").find(".e-container")find() dá acesso aos descendentes do elemento HTML atual filtrado por um seletor CSS. Você pode então iterar em uma lista de nodos Cheerio com o método each(), da seguinte forma:
// iterating over the list of industry cards
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// scraping logic...
})Agora vamos aprender como usar a Cheerio para extrair dados dos elementos HTML de interesse.
Etapa 6: raspe dados de uma página da web visada com a Cheerio
Você pode expandir a lógica mostrada anteriormente para extrair os dados desejados dos elementos HTML selecionados, conforme abaixo:
// initializing the data structure
// that will contain the scraped data
const industries = []
// scraping the "Learn how web data is used in your market" section
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// extracting the data of interest
const pageUrl = $(element).attr("href")
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const name = $(element).find(".elementor-image-box-content .elementor-image-box-title").text()
// filtering out not interesting data
if (name && pageUrl) {
// converting the data extracted into a more
// readable object
const industry = {
url: pageUrl,
image: image,
name: name
}
// adding the object containing the scraped data
// to the industries array
industries.push(industry)
}
})Este trecho raspador de dados da web do Node.js seleciona todos os cartões do setor econômico na página inicial da Bright Data. Em seguida, ele itera sobre todos os elementos do cartão HTML. De cada cartão, ele extrai o URL da página da web associada ao cartão, a imagem e o nome do setor econômico. Graças aos métodos attr() e text() da Cheerio, você pode recuperar o valor e o texto do atributo HTML, respectivamente. Finalmente, ele armazena os dados raspados em um objeto e os adiciona à matriz industries.
Ao final do loop each(), a matriz industries conterá todos os dados de interesse relacionados à primeira meta de raspagem. Agora vamos ver como alcançar as outras duas metas também.
Da mesma forma, é possível extrair os dados para comprovar por que a Bright Data é líder do setor da seguinte forma:
const marketLeaderReasons = []
// scraping the "What makes Bright Data
// the undisputed industry leader" section
$(".elementor-element-ef3e47e")
.find(".elementor-widget")
.each((index, element) => {
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const title = $(element).find(".elementor-image-box-title").text()
const description = $(element).find(".elementor-image-box-description").text()
const marketLeaderReason = {
title: title,
image: image,
description: description,
}
marketLeaderReasons.push(marketLeaderReason)
})Por fim, você pode extrair os dados sobre por que a Bright Data oferece uma ótima experiência ao cliente com:
const customerExperienceReasons = []
// scraping the "The best customer experience in the industry" section
$(".elementor-element-288b23cd .elementor-text-editor")
.find("li")
.each((index, element) => {
const title = $(element).find("strong").text()
// since the title is part of the text, you have
// to remove it to get only the description
const description = $(element).text().replace(title, "").trim()
const customerExperienceReason = {
title: title,
description: description,
}
customerExperienceReasons.push(customerExperienceReason)
})Parabéns! Você acabou de aprender como atingir todas as suas três metas de raspagem de dados na web no Node.js!
Lembre-se de que você pode extrair dados de outras páginas da web seguindo os links que você descobriu na página atual. É disso que trata o rastreamento na web. Portanto, você também pode definir a lógica de raspagem de dados da web para extrair dados dessas páginas.
industries, MarketLeaderReasons, CustomerExperienceReasons armazenarão todos os dados extraídos em objetos em JavaScript. Vamos aprender como convertê-los para um formato mais útil.
Etapa 7: Converter os dados extraídos para JSON
JSON é um dos melhores formatos de dados quando se trata de JavaScript. Isso ocorre porque o JSON é derivado do JavaScript e é o formato geralmente usado pela API para aceitar ou retornar dados. Portanto, é provável que você precise converter seus dados raspados de JavaScript para JSON. Isso pode ser feito facilmente usando a lógica abaixo:
// trasforming the scraped data into a general object
const scrapedData = {
industries: industries,
marketLeader: marketLeaderReasons,
customerExperience: customerExperienceReasons,
}
// converting the scraped data object to JSON
const scrapedDataJSON = JSON.stringify(scrapedData)Primeiro, você precisa criar um objeto em JavaScript contendo todos os dados extraídos. Em seguida, você pode transformar esse objeto em JavaScript para JSON com o JSON.stringify().
ScrapedDataJSON conterá os seguintes dados JSON:
{
"industries": [
{
"url": "https://brightdata.com/use-cases/ecommerce",
"image": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"name": "E-commerce"
},
// ...
{
"url": "https://brightdata.com/use-cases/data-for-good",
"image": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"name": "Data for Good"
}
],
"marketLeader": [
{
"title": "Most reliable",
"image": "https://brightdata.com/wp-content/uploads/2022/01/reliable.svg",
"description": "Highest quality data, best network uptime, fastest output "
},
// ...
{
"title": "Most efficient",
"image": "https://brightdata.com/wp-content/uploads/2022/01/efficient.svg",
"description": "Minimum in-house resources needed"
}
],
"customerExperience": [
{
"title": "You ask, we develop",
"description": "New feature releases every day"
},
// ...
{
"title": "Tailored solutions",
"description": "To meet your data collection goals"
}
]
}Parabéns! Você começou conectando-se a um site e agora pode raspar seus dados e convertê-los para JSON. Agora você está pronto para dar uma olhada no script Node.js completado para raspagem de dados na web.
Juntando tudo
Essa é a aparência do raspador de dados na web Node.js:
// index.js
const cheerio = require("cheerio")
const axios = require("axios")
async function performScraping() {
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com/",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
})
// parsing the HTML source of the target web page with Cheerio
const $ = cheerio.load(axiosResponse.data)
// initializing the data structures
// that will contain the scraped data
const industries = []
const marketLeaderReasons = []
const customerExperienceReasons = []
// scraping the "Learn how web data is used in your market" section
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// extracting the data of interest
const pageUrl = $(element).attr("href")
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const name = $(element).find(".elementor-image-box-content .elementor-image-box-title").text()
// filtering out not interesting data
if (name && pageUrl) {
// converting the data extracted into a more
// readable object
const industry = {
url: pageUrl,
image: image,
name: name
}
// adding the object containing the scraped data
// to the industries array
industries.push(industry)
}
})
// scraping the "What makes Bright Data
// the undisputed industry leader" section
$(".elementor-element-ef3e47e")
.find(".elementor-widget")
.each((index, element) => {
// extracting the data of interest
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const title = $(element).find(".elementor-image-box-title").text()
const description = $(element).find(".elementor-image-box-description").text()
// converting the data extracted into a more
// readable object
const marketLeaderReason = {
title: title,
image: image,
description: description,
}
// adding the object containing the scraped data
// to the marketLeaderReasons array
marketLeaderReasons.push(marketLeaderReason)
})
// scraping the "The best customer experience in the industry" section
$(".elementor-element-288b23cd .elementor-text-editor")
.find("li")
.each((index, element) => {
// extracting the data of interest
const title = $(element).find("strong").text()
// since the title is part of the text, you have
// to remove it to get only the description
const description = $(element).text().replace(title, "").trim()
// converting the data extracted into a more
// readable object
const customerExperienceReason = {
title: title,
description: description,
}
// adding the object containing the scraped data
// to the customerExperienceReasons array
customerExperienceReasons.push(customerExperienceReason)
})
// trasforming the scraped data into a general object
const scrapedData = {
industries: industries,
marketLeader: marketLeaderReasons,
customerExperience: customerExperienceReasons,
}
// converting the scraped data object to JSON
const scrapedDataJSON = JSON.stringify(scrapedData)
// storing scrapedDataJSON in a database via an API call...
}
performScraping()Conforme mostrado aqui, você pode criar um raspador de dados na web no Node.js em menos de 100 linhas de código. Com Cheerio e Axios, você pode baixar uma página da web em HTML, analisá-la e recuperar automaticamente todos os seus dados. Em seguida, você pode facilmente converter os dados extraídos para JSON. Isso é o que faz o raspador de dados na web Node.js.
Inicie seu raspador de dados na web no Node.js com:
npm run startE voilà! Você acabou de aprender como executar a raspagem de dados na web em JavaScript no Node.js!
Conclusão
Neste tutorial, você viu por que a raspagem de dados na web no frontend com JavaScript é uma solução limitada e por que o Node.js é uma opção melhor. Além disso, você deu uma olhada no que é necessário para criar um script Node.js de raspagem de dados na web e como você pode extrair dados da web em JavaScript. Especificamente, você aprendeu a usar a Cheerio e a Axios para criar um aplicativo de raspagem de dados na web em JavaScript no Node.js com base em um exemplo concreto. Como você aprendeu, a raspagem de dados na web com o Node.js usa apenas algumas linhas de código.
Mas lembre-se de que raspar dados na web pode não ser tão fácil. O motivo é que há muitos desafios que você pode ter que enfrentar. Especificamente, as soluções anti-raspagem de dados e anti-bots estão se tornando cada vez mais comuns. Felizmente, você pode facilmente evitar tudo isso com uma avançada ferramenta de raspagem de dados na web de última geração, fornecida pela Bright Data. Não deseja se envolver com raspagem de dados na web? Explore nossos conjuntos de dados.
Se você quiser saber mais sobre como não ser bloqueado, adote um proxy web de um dos vários serviços de proxy disponíveis ou comece a usar o avançado Desbloqueador Web.
Não sabe qual produto escolher? Entre em contato com o departamento de vendas e encontre a solução de raspagem de dados na web sob medida para você.





