

HtmlUnit é um navegador sem cabeça que permite modelar páginas HTML. Depois de modelar a página programaticamente, você pode interagir com ela executando tarefas como preencher formulários, enviá-los e navegar entre páginas. Pode ser utilizado para a raspagem de dados da web para extrair dados para posterior manipulação, bem como para criar testes automatizados para verificar se o seu programa cria páginas web como esperado.
Raspagem da web com HtmlUnit
Para implementar a raspagem da web utilizando a HtmlUnit e o Gradle, será utilizado o IDE IntelliJ IDEA; no entanto, pode utilizar qualquer IDE ou editor de código que preferir.
O IntelliJ suporta uma integração totalmente funcional com o Gradle e pode ser descarregado no sítio de JetBrains. O Gradle é uma ferramenta de automatização de construção que suporta a construção e criação de pacotes para a sua aplicação. Também lhe permite adicionar e gerir dependências sem problemas. O Gradle e as extensões do Gradle são instalados e ativados por predefinição nas versões mais recentes do IntelliJ IDEA.
Todo o código para este tutorial pode ser encontrado neste repositório do GitHub.
Criar um projeto Gradle
Para criar um projeto Gradle no IntelliJ IDE, selecione Ficheiro > Novo > Projeto nas opções de menu e será aberto um novo assistente de projeto. Introduza o nome do projeto e selecione a localização desejada:

Tem de selecionar a linguagem Java, uma vez que vai criar uma aplicação de raspagem de dados da web em Java utilizando a HtmlUnit. Além disso, selecione o sistema de construção Gradle. Em seguida, clique em Criar. Isso criará um projeto Gradle com uma estrutura padrão e todos os arquivos necessários. Por exemplo, o arquivo build.gradle contém todas as dependências necessárias para criar este projeto:
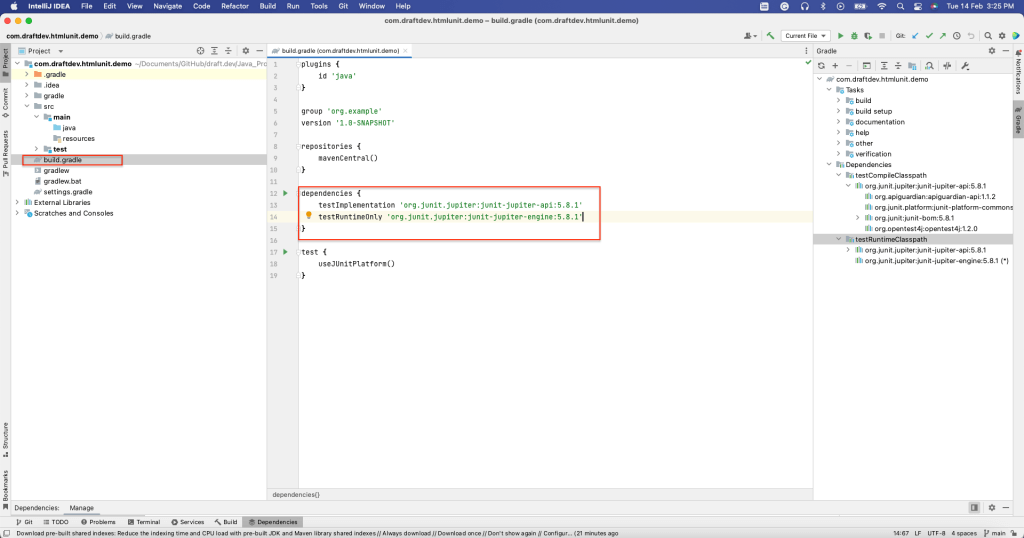
Instalar HtmlUnit
Para instalar HtmlUnit como uma dependência, abra a janela Dependências selecionando Ver > Janelas de ferramentas > Dependências.
Em seguida, procure “htmlunit” e selecione Adicionar:
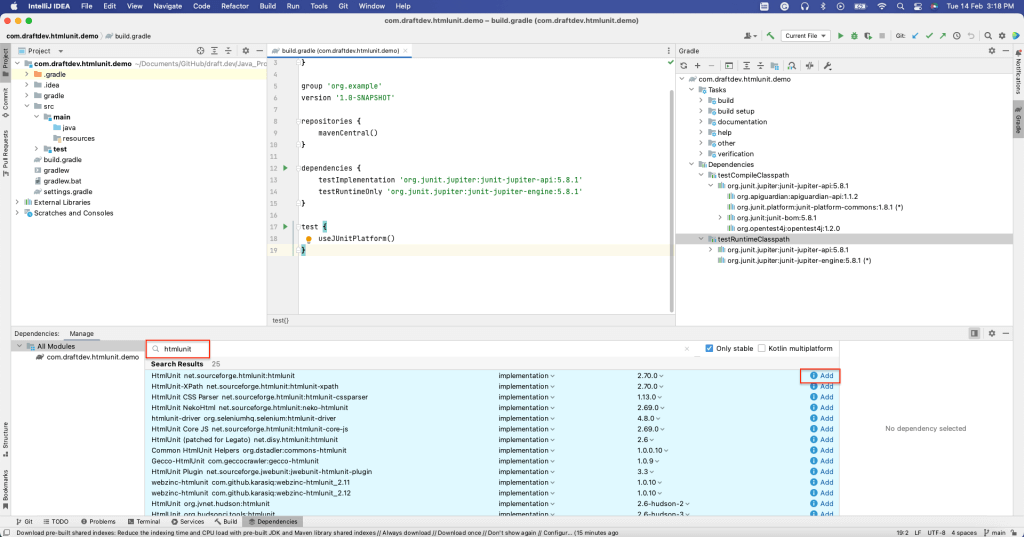
Você deve ser capaz de ver que HtmlUnit foi instalado na seção dependências do arquivo build.gradle:

Agora que instalou HtmlUnit, está na altura de raspar dados de páginas web estáticas e dinâmicas.
Raspar uma página estática
Nesta seção, aprenderá a raspar HtmlUnit Wiki, uma página web estática. Esta página web contém elementos como o título, o índice, a lista de subtítulos e o conteúdo de cada subtítulo.
Cada elemento de uma página web HTML tem atributos. Por exemplo, ID é um atributo que identifica de forma exclusiva um elemento no documento HTML completo e Nome é um atributo que identifica esse elemento. O atributo Nome não é único, e mais de um elemento no documento HTML pode ter o mesmo nome. Os elementos de uma página web podem ser identificados através de qualquer um dos atributos.
Em alternativa, também é possível identificar elementos utilizando o seu XPath. O XPath utiliza uma sintaxe semelhante a um caminho para identificar e navegar por elementos no HTML da página web.
Você usará esses dois métodos para identificar os elementos na página HTML nos exemplos a seguir.
Para raspar uma página web, você precisa criar um WebClient de HtmlUnit. O WebClient representa um navegador dentro da sua aplicação Java. Inicializar um WebClient é semelhante a iniciar um navegador para exibir a página web.
Para inicializar um WebClient, use o seguinte código:
WebClient webClient = new WebClient(BrowserVersion.CHROME);
Este código inicializa o navegador Chrome. Outros navegadores também são suportados.
Você pode obter a página web usando o método getPage() disponível no objeto webClient. Assim que tiver a página web, pode raspar os dados da página web utilizando vários métodos.
Para obter o título da página, use o método getTitleText(), conforme demonstrado no código a seguir:
String webPageURl = u0022https://en.wikipedia.org/wiki/HtmlUnitu0022;n try {nn HtmlPage page = webClient.getPage(webPageURl);n n System.out.println(page.getTitleText());n n } catch (FailingHttpStatusCodeException | IOException e) {n n e.printStackTrace();n n }
O título da página será então impresso:
HtmlUnit - Wikipedia
Para dar mais um passo em frente, vamos buscar todos os elementos H2 disponíveis na página web. Neste caso, os H2s estão disponíveis em duas seções da página:
- Na barra lateral esquerda, onde são apresentados os conteúdos: Como pode ver, o título da seção Conteúdo é um elemento H2.
- No corpo principal da página: Todos os subtítulos são elementos H2.
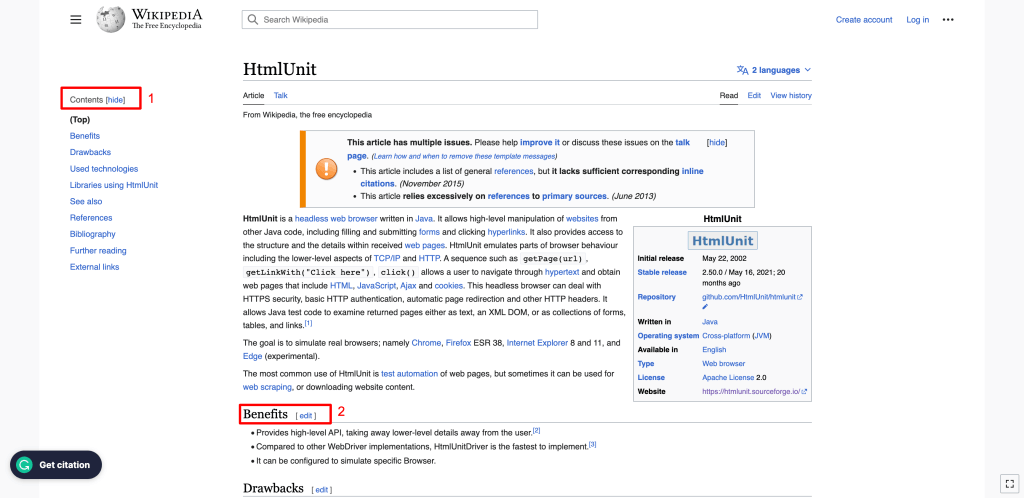
Para obter todos os H2s no corpo do conteúdo, pode utilizar o XPath dos elementos H2. Para encontrar o XPath, clique com o botão direito do rato em qualquer elemento H2 e selecione Inspecionar. Em seguida, clique com o botão direito do rato no elemento realçado e selecione Copiar > Copiar XPath completo:
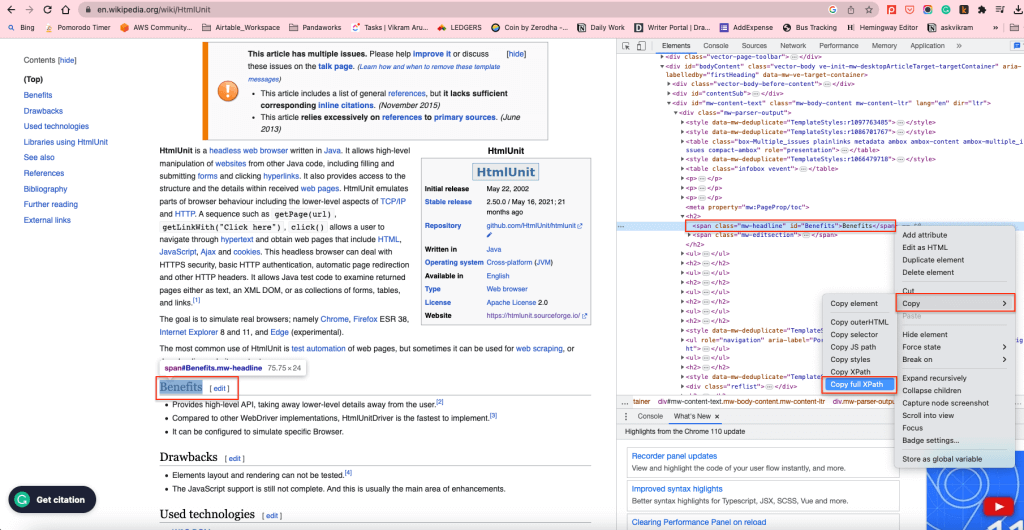
Isto copiará o XPath para a área de transferência. Por exemplo, o elemento XPath dos H2s no corpo do conteúdo é /html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/h2.
Para obter todos os elementos H2 utilizando o seu XPath, pode utilizar o método getByXpath():
String xPath = u0022/html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/h2u0022;nn String webPageURL = u0022https://en.wikipedia.org/wiki/HtmlUnitu0022;n n try {n HtmlPage page = webClient.getPage(webPageURL);nn //Get all the headings using its XPath+n Listu003cHtmlHeading2u003e h2 = (Listu003cHtmlHeading2u003e)(Object) page.getByXPath(xPath);n n //print the first heading text contentn System.out.println((h2.get(0)).getTextContent());nn } catch (FailingHttpStatusCodeException | IOException e) {n n e.printStackTrace();n n }
O conteúdo de texto do primeiro elemento H2 será impresso da seguinte forma:
Benefits[edit]
Da mesma forma, pode obter os elementos através do seu ID utilizando o método getElementById() e pode obter os elementos através do seu nome utilizando o método getElementByName().
Na seção seguinte, utilizará estes métodos para raspar uma página web dinâmica.
Raspar uma página web dinâmica usando HtmlUnit
Nesta seção, você aprenderá sobre as capacidades de preenchimento de formulários e de clicar em botões do HtmlUnit, preenchendo o formulário de início de sessão e enviando-o. Aprenderá também a navegar em páginas web utilizando o navegador sem cabeça.
Para ajudar a demonstrar a raspagem dinâmica da web, vamos utilizar o sítio web Hacker News. Eis o aspeto da página de início de sessão:

O código seguinte é o código do formulário HTML para a página anterior. Pode obter este código clicando com o botão direito do rato na etiqueta de início de sessão e clicando em Inspecionar:
u003cform action=u0022loginu0022 method=u0022postu0022u003enu003cinput type=u0022hiddenu0022 name=u0022gotou0022 value=u0022newsu0022u003enu003ctable border=u00220u0022u003enu003ctbodyu003enu003ctru003eu003ctdu003eusername:u003c/tdu003eu003ctdu003eu003cinput type=u0022textu0022 name=u0022acctu0022 size=u002220u0022 autocorrect=u0022offu0022 spellcheck=u0022falseu0022 autocapitalize=u0022offu0022 autofocus=u0022trueu0022u003eu003c/tdu003eu003c/tru003enu003ctru003eu003ctdu003epassword:u003c/tdu003eu003ctdu003eu003cinput type=u0022passwordu0022 name=u0022pwu0022 size=u002220u0022u003eu003c/tdu003eu003c/tru003eu003c/tbodyu003eu003c/tableu003eu003cbru003enu003cinput type=u0022submitu0022 value=u0022loginu0022u003eu003c/formu003e
Para preencher o formulário utilizando HtmlUnit, obtenha a página web utilizando o objeto webClient. A página contém dois formulários: Iniciar sessão e Criar conta. Pode obter o formulário de início de sessão utilizando o método getForms().get(0). Em alternativa, pode utilizar o método getFormByName() se os formulários tiverem um nome único.
Em seguida, é necessário obter as entradas do formulário (ou seja, os campos de nome de usuário e palavra-passe) utilizando o método getInputByName() e o atributo nome.
Defina o valor do nome de usuário e da palavra-passe nos campos de entrada utilizando o método setValueAttribute() e obtenha o botão Enviar utilizando o método getInputByValue(). Também pode clicar no botão utilizando o método click().
Assim que o botão for clicado, e se o início de sessão for bem sucedido, a página de destino do botão Enviar será devolvida como o objeto HTMLPage, que pode ser utilizado para outras operações.
O código a seguir demonstra como obter o formulário, preenchê-lo e enviá-lo:
HtmlPage page = null;nnString webPageURl = u0022https://en.wikipedia.org/wiki/HtmlUnitu0022;nn try {n // Get the first pagenn HtmlPage signUpPage = webClient.getPage(webPageURL);nn // Get the form using its index. 0 returns the first form.n HtmlForm form = signUpPage.getForms().get(0);nn //Get the Username and Password field using its namen HtmlTextInput userField = form.getInputByName(u0022acctu0022);n HtmlInput pwField = form.getInputByName(u0022pwu0022);n n //Set the User name and Password in the appropriate fieldsn userField.setValueAttribute(u0022draftdemoacctu0022);n pwField.setValueAttribute(u0022test@12345u0022);nn //Get the submit button using its Valuen HtmlSubmitInput submitButton = form.getInputByValue(u0022loginu0022);nn //Click the submit button, and it'll return the target page of the submit buttonn page = submitButton.click();nnn } catch (FailingHttpStatusCodeException | IOException e) {n e.printStackTrace();n }
Assim que o formulário for enviado e o início de sessão for bem sucedido, será encaminhado para a página inicial do usuário, onde o nome de usuário é apresentado no canto direito:
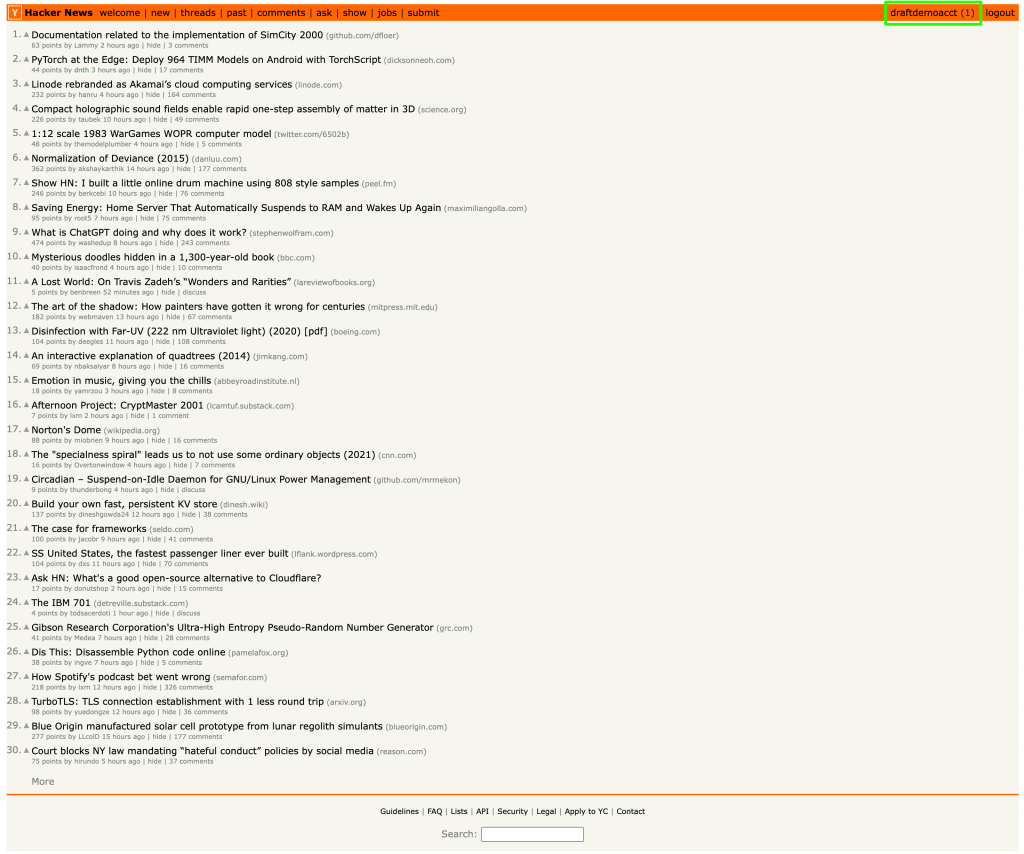
O elemento do nome de usuário tem o ID “me” (eu). Pode obter o nome de usuário utilizando o método getElementById() e passar o ID “me”, como demonstrado no código seguinte:
System.out.println(page.getElementById(u0022meu0022).getTextContent());
O nome de usuário da página web é raspado e exibido como saída:
draftdemoacct
Em seguida, é necessário navegar para a segunda página do sítio Hacker News, clicando no botão de hiperligação Mais no final da página:

Para obter o objeto do botão Mais, obtenha o XPath do botão Mais utilizando a opção Inspecionar e obtenha o primeiro objeto de link utilizando o índice 0:
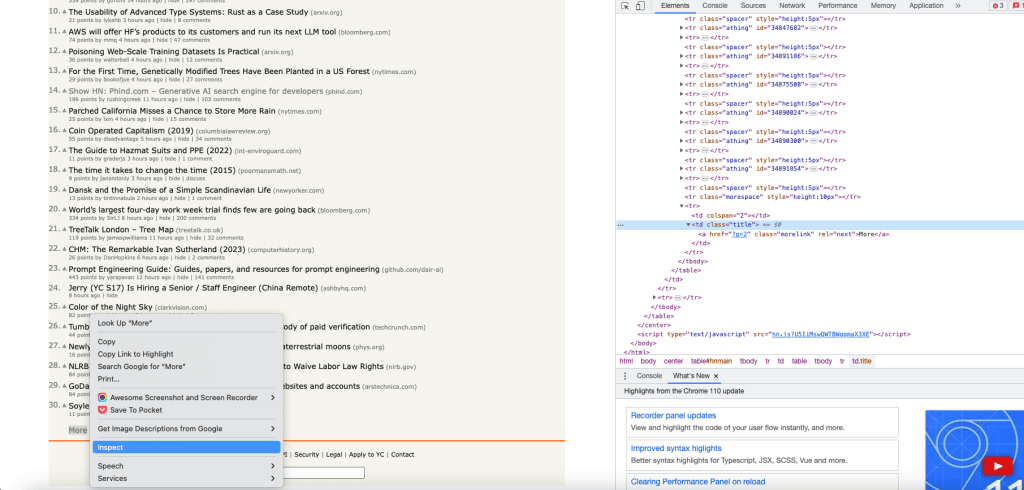
Clique na ligação Mais utilizando o método click(). O link será clicado e a página de destino do link será devolvida como um objeto HtmlPage:
HtmlPage nextPage = null;nn try {n Listu003cHtmlAnchoru003e links = (Listu003cHtmlAnchoru003e)(Object)page.getByXPath(u0022html/body/center/table/tbody/tr[3]/td/table/tbody/tr[92]/td[2]/au0022);n n HtmlAnchor anchor = links.get(0);n n nextPage = anchor.click();nn } catch (IOException e) {n throw new RuntimeException(e);n }
Nesta altura, deve ter a segunda página no objeto HtmlPage.
Pode imprimir o URL da HtmlPage para verificar se a segunda página foi carregada com êxito:
System.out.println(nextPage.getUrl().toString());
A seguir está o URL da segunda página:
https://news.ycombinator.com/news?p=2
Cada página do sítio Hacker News tem trinta entradas. É por esta razão que as entradas da segunda página começam com o número de série 31.
Vamos recuperar o ID da primeira entrada na segunda página e ver se é igual a 31. Como antes,
obtenha o XPath da primeira entrada usando a opção Inspecionar. Em seguida, obtenha a primeira entrada da lista e exiba seu conteúdo de texto:
String firstItemId = null;nn Listu003cObjectu003e entries = nextPage.getByXPath(u0022/html/body/center/table/tbody/tr[3]/td/table/tbody/tr[1]/td[1]/spanu0022);nn HtmlSpan span = (HtmlSpan) (entries.get(0));nn firstItemId = span.getTextContent();n n System.out.println(firstItemId);
O ID da primeira entrada agora é exibido:
31.
Este código mostra-lhe como preencher o formulário, clicar nos botões e navegar nas páginas web utilizando HtmlUnit.
Conclusão
Neste artigo, você aprendeu como raspar sítios estáticos e dinâmicos com HtmlUnit. Também aprendeu sobre algumas das capacidades avançadas do HtmlUnit, ao raspar páginas web e convertê-las em dados estruturados.
Ao fazer isso com um IDE como o IntelliJ IDEA, você precisa encontrar atributos de elemento inspecionando-os manualmente e escrever funções de raspagem do zero usando os atributos de elemento. Em comparação, o IDE para Raspador da Web da Bright Data fornece uma infraestrutura de proxy de desbloqueio robusta, funções de raspagem úteis e modelos de código para sítios populares. Uma infraestrutura de proxy eficiente é necessária quando se trata de raspar uma página web sem problemas de bloqueio de IP e limitação de taxa. O proxy também ajuda a emular um usuário de uma localização geográfica diferente.
Talk to one of Bright Data’s experts and find the right solution for your business.





